一种基于RF的地中海贫血病的风险预警方法与流程
本发明涉及一种基于rf的地中海贫血病的风险预警方法,属于数据挖掘预测技术领域。
背景技术:
地中海贫血病(thalassemiadisease,td)是一种海洋性、珠蛋白基因缺陷且隐性遗传的病,多发于地中海沿岸,在我国云南(10%)、广东等地高发。其中重型的地贫患儿有立即夭折或者六岁前夭折的危险,这对患儿家庭造成了沉重打击。
基于随机森林算法的预警方法可以辅助诊断,有助于降低误诊率、节省医学资源等,进一步指导其后续的诊断及治疗过程。目前,已有骨髓干细胞移植案例,但治后效果欠佳。另外,在地中海贫血的研究方面基本停留在数据的累积分析上,在地中海贫血预警方面的研究更是欠缺。rf算法基于以上的组成加快整个挖掘预警过程。而且算法已经被广泛的应用到商业、网络安全等各个领域,但还没有应用到地中海贫血领域。
技术实现要素:
本发明要解决的技术问题是提供一种基于rf的地中海贫血病的风险预警方法,将rf算法应用到对地中海贫血病的风险预警上,起到降低医疗资源浪费的作用,提高临床诊断的准确性与高效性。
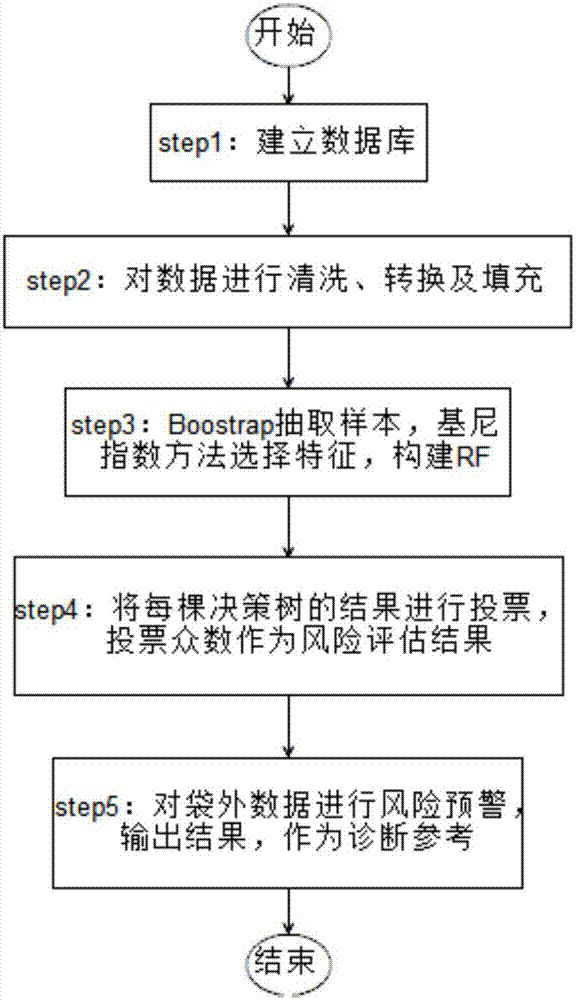
本发明的技术方案是:一种基于rf的地中海贫血病的风险预警方法,将受检者的血样编号作为标识符id,对应检验记录作为一个样例t,所有样例的集合;对样例数据集进行数据预处理,得到算法适用数据集dataset;对dataset进行boostrap重采样,随机生成训练样本traindata,并采用信息增益方法选择特征,构建随机森林算法rf模型;然后,将每棵决策树dt的分类结果进行投票,投票众数作为风险评估结果;最后,将袋外数据oob_dataset作为模型输入,输出预警结果,作为临床诊断参考。
包括如下步骤:
step1、建立数据库。根据电子台账数据,建立一个受检者记录的数据库,将受检者血样编号作为标识符id,对应检验记录作为一条样例s,每个样例s包含地中海贫血病受检者的血液及电泳检查结果,对应列为受检属性值集合tzset;
step2、数据预处理。对数据库中的样例数据集进行清洗、挖掘及填充后得到建模数据集dataset,该数据集包含n条样例,m个特征;
step3、构建模型。首先对数据集dataset采用boostrap重采样的方法采样,每次随机采样n个样本作为单棵决策树的训练数据集traindata,剩余样例组成袋外数据oob_dataset;在每个节点,算法首先随机选取m(m<<m)个变量,从中找出能够提供最佳分割效果的预警属性;算法在不剪枝的情况下生成单棵决策树,重复该步骤生成多棵cart决策树ntree,构建随机森林rf;
step4、风险评估。将每棵决策树得到的分类结果进行投票,算法取类别预测众数作为最终分类表,并得出对地中海贫血病影响较大的因子,并输出因子重要性排序;
step5、模型预警。对rf预警模型进行袋外数据oob_dataset预测,得到一个地中海贫血病的混淆矩阵conf_matrix,并根据该混淆矩阵conf_matrix计算模型性能。
具体地,所述步骤step1中,受检者记录数据库中每条信息包含受检者血常规及电泳检验结果字段,受检者血样编号作为标识符id,对应血常规及电泳检验集合的编号作为属性集tzset,检验中的每一个属性作为一个项。
具体地,所述步骤step2中,数据预处理包括电子台帐数据采集、数据挖掘及特征选择。所述数据挖掘是将获得的数据库数据经过数据清洗、数据转换以及贝叶斯算法初步填充等,得到最终的建模数据集dataset,数据集包含n条样例,m个特征。
具体地,所述步骤step3中,通过随机选择样本,保证每次学习的决策树使用不同的训练集。
具体地,所述步骤step3中,地贫属性分割度量采用cart算法的基尼指数方法,其计算公式如(1)所示;特征属性的优先选择公式如(2)所示:
其中,t为样本数据集,pj为类别j在样本t中出现的频率;nj为样本t中类别j出现的个数;s为样本数据集中样本个数;t1,t2为特征属性;s1,s2为不同划分方式。
本发明的有益效果是:提供了rf算法对地中海贫血病的风险进行预警,提高地贫患儿临床诊断的准确性与高效性,能有效避免地贫患儿出生,并起到降低医疗资源浪费的作用。
附图说明
图1是本发明的流程示意图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
一种基于rf的地中海贫血病的风险预警方法,将受检者的血样编号作为标识符id,对应检验记录作为一个样例t,所有样例的集合;对样例数据集进行数据预处理,得到算法适用数据集dataset;对dataset进行boostrap重采样,随机生成训练样本traindata,并采用信息增益方法选择特征,构建随机森林算法rf模型;然后,将每棵决策树dt的分类结果进行投票,投票众数作为风险评估结果;最后,将袋外数据oob_dataset作为模型输入,输出预警结果,作为临床诊断参考。
包括如下步骤:
step1、建立数据库。根据电子台账数据,建立一个受检者记录的数据库,将受检者血样编号作为标识符id,对应检验记录作为一条样例s,每个样例s包含地中海贫血病受检者的血液及电泳检查结果,对应列为受检属性值集合tzset;
step2、数据预处理。对数据库中的样例数据集进行清洗、挖掘及填充后得到建模数据集dataset,该数据集包含n条样例,m个特征;
step3、构建模型。首先对数据集dataset采用boostrap重采样的方法采样,每次随机采样n个样本作为单棵决策树的训练数据集traindata,剩余样例组成袋外数据oob_dataset;在每个节点,算法首先随机选取m(m<<m)个变量,从中找出能够提供最佳分割效果的预警属性;算法在不剪枝的情况下生成单棵决策树,重复该步骤生成多棵cart决策树ntree,构建随机森林rf;
step4、风险评估。将每棵决策树得到的分类结果进行投票,算法取类别预测众数作为最终分类表,并得出对地中海贫血病影响较大的因子,并输出因子重要性排序;
step5、模型预警。对rf预警模型进行袋外数据oob_dataset预测,得到一个地中海贫血病的混淆矩阵conf_matrix,并根据该混淆矩阵conf_matrix计算模型性能。
具体地,所述步骤step1中,受检者记录数据库中每条信息包含受检者血常规及电泳检验结果字段,受检者血样编号作为标识符id,对应血常规及电泳检验集合的编号作为属性集tzset,检验中的每一个属性作为一个项。
具体地,所述步骤step2中,数据预处理包括电子台帐数据采集、数据挖掘及特征选择。所述数据挖掘是将获得的数据库数据经过数据清洗、数据转换以及贝叶斯算法初步填充等,得到最终的建模数据集dataset,数据集包含n条样例,m个特征。
具体地,所述步骤step3中,通过随机选择样本,保证每次学习的决策树使用不同的训练集。
具体地,所述步骤step3中,地贫属性分割度量采用cart算法的基尼指数方法,其计算公式如(1)所示;特征属性的优先选择公式如(2)所示:
其中,t为样本数据集,pj为类别j在样本t中出现的频率;nj为样本t中类别j出现的个数;s为样本数据集中样本个数;t1,t2为特征属性;s1,s2为不同划分方式。
实施例1:如图1所示,一种基于rf的地中海贫血病的风险预警方法,所述方法的具体步骤如下:
step1、建立数据库。根据电子台账数据,建立一个受检者记录的数据库,将受检者血样编号作为标识符id,对应检验记录作为一条样例s,每个样例s包含地中海贫血病受检者的血液及电泳检查结果,对应列为受检属性值集合tzset;具体地:
为方便阐述本发明,假设本发明中对地中海贫血病预警的综合属性中部分属性集合如下表1所示:
step2、数据预处理。对数据库中的样例数据集进行清洗、挖掘及填充后得到建模数据集dataset,该数据集包含n条样例,m个特征;具体地:该数据集包含1300条样例,7个特征,具体特征如表1所示。
step3、构建模型。首先对数据集dataset采用boostrap重采样的方法采样,每次随机采样n个样本作为单棵决策树的训练数据集traindata,剩余样例组成袋外数据oob_dataset;在每个节点,算法首先随机选取m(m<<m)个变量,从中找出能够提供最佳分割效果的预警属性;算法在不剪枝的情况下生成单棵决策树,重复该步骤生成多棵cart决策树ntree,构建随机森林rf;具体地:随机重采样生成样本集样例数为910条,袋外数据样例为390条。
step4、通过随机选择样本,保证每次学习的决策树使用不同的训练集。
step5、所述步骤step3中,地贫属性分割度量采用cart算法的基尼指数方法,其计算公式如(1)所示;特征属性的优先选择公式如(2)所示:
其中,t为样本数据集,pj为类别j在样本t中出现的频率;nj为样本t中类别j出现的个数;s为样本数据集中样本个数;t1,t2为特征属性;s1,s2为不同划分方式;具体地:
本案例数据集包含910条样例,袋外数据包括390条样例,则得到的模型参数及结果如下表2所示:
390条袋外数据的预警结果指标计算如下表3所示:
特异度和灵敏度如下表4所示:
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!