一种基于机器学习的难降解有机污水处理效果预测方法与流程
本发明属于污水处理领域效果预测领域,具体涉及一种有机污水处理效果预测方法。
背景技术:
煤化工、石油化工、印染、制药、造纸、农药等工业发展产生大量的多环芳烃、卤代烃、杂环化合物、有机氰化物、农药等有毒难降解有机物,这类有机物处置不当将长期存留在天然环境中,对人类健康及生态环境构成严重威胁。中国环境监测总站统计,我国环境特征污染物“黑名单”中共有14类68种优先控制的污染物,其中毒性难降解有机物有12类58种,占总数的85.29%。无论从环境保护还是经济发展角度,毒性难降解有机物治理已然成为人类社会经济可持续健康发展迫切解决的问题。当前,污水处理运行过程中的能耗非常巨大,我国污水处理厂每吨污水耗电约为0.25千瓦时,处理能耗为发达国家的两倍(gb18918-2002二级标准),导致成本过高,严重的制约了污水处理厂的建设。因此,围绕污水处理水质达标和节能降耗的关键问题,需要推进污水处理设备、管理和控制技术的相关研制和应用推广。
当前,针对污水处理控制技术的研究主要集中于闭环控制,其中pid控制可以较好的实现溶解氧的控制,但是其对环境的适应能力差,且难以保证出水水质的达标,而基于模糊系统和神经网络的智能控制方法具有极强的环境适应能力,自主学习能力,可以极大的应对以上的困难和挑战,但是以上智能方法在应对污水处理这个庞大的系统时,还是存在许多的缺陷,比如依赖专家经验,难以确定网络结构等。模型预测控制能较好的处理非线性,时滞性的对象,但是模型预测控制需要模型精度可靠,而污水处理厂的传感器往往不能提供实施可靠的数据,所以目前的各种检测和控制指标影响可能导致预测结果出现较大的误差,导致模型预测控制难以发挥效果。
技术实现要素:
本发明为了解决现有的有机污水处理效果预测方法存在预测准确率有待提高的问题。
一种基于机器学习的难降解有机污水处理效果预测方法,包括以下步骤:
步骤1、多层次异常点检测及处理:
获取污水处理中所需采集的指标数据xj,j=1,2,…m表示指标数据的类型;对每个指标数据的采样值xij进行异常检测,计算每条数据与其他数据的欧氏距离,确定阈值,剔除超过阈值的点;xij表示xj的i次采样值;
步骤2、创建多元线性回归模型:
假设从属变量y与回归变量x1,x2,...,xm存在不精确的线性依赖关系,添加误差项ε,并有ε的分布特性来刻画除x1,x2,...,xm之外的其他因素对y的影响,多元线性回归模型为:
y=β0+β1x1+...+βmxm+ε
其中,从属变量y用于表示预测结果,回归变量x1,x2,...,xm用于表示指标数据的观测值;
回归系数βk表示其它回归变量的取值给定的条件下第k个回归变量增加一个单位时,对从属变量平均响应的影响效果;k=1,2,...,m;
设(xi1,xi2,...,xim;y)为解释变量x1,x2,...,xm与变量y的n组观测值;记
则模型可写为:
y=xβ+ε
选取残差平方和作为多元线性回归的策略:
其中,
步骤3、将多元线性回归的策略转化为无约束最优化问题,采用梯度下降法求解无约束最优化问题:
假设f(x)是rn上具有一阶连续偏导数的函数,要求解的无约束最优化问题是:
将神经网络的学习过程转化为求损失函数的最小值问题,选取初值x(0),不断迭代,更新x的值,使得目标函数极小化,直到收敛,最终确定损失函数的最小值,进而实现有机污水处理效果预测。
进一步地,将神经网络的学习过程转化为求损失函数的最小值问题的具体过程如下:
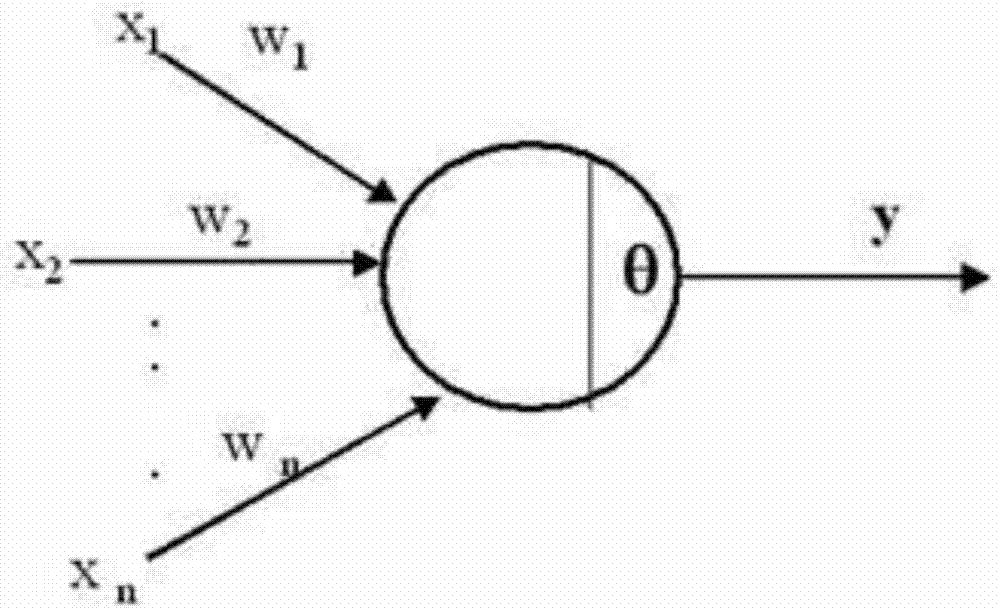
神经网络采用ann,设有n个神经元与该神经元连结,每个神经元的输入信号为xi,该神经元的输出信号为;
数学表达式为:
式中wi表示神经元i与该神经元的连接强度,或称权重值;
θ表示神经元的阈值;
f(*)表示该神经元的激活函数;
损失函数f(w)的函数值由权重值和偏置值决定;将权重值和偏置值各自组为一个n维的权重向量,分别记为wi和wj;
在空间内任意选择一个点,都能计算得到损失函数的一阶、二阶导数;
采用梯度下降最终确定损失函数的最小值。
进一步地,所述激活函数采用relu=max(0,x)。
进一步地,对每个指标数据的采样值xij进行异常检测是采用基于临近度的离群点检测实现的。
进一步地,在对每个指标数据的采样值xij进行异常检测之前通过创建辅助字典在数据集成过程中删除有缺失值的时间戳。
本发明具有以下有益效果:
本发明结合人工智能技术和模型预测控制的方法可以有效的解决对象模型不明确,非线性强的问题,其可以建立非常精确的预测模型,预测的效果与真实值之间的相对误差小于22%;保证控制策略的稳定性、精确性、鲁棒性和容错性,实现对污水处理效果非常好预测,从而提供有效的处理控制方案,能够客观的降低能耗和人工成本。
附图说明
图1人工神经网络示意图;
图2为损失函数示意图。
具体实施方式
具体实施方式一:
一种基于机器学习的难降解有机污水处理效果预测方法,包括以下步骤:
步骤1、多层次异常点检测及处理:
获取污水处理中所需采集的指标数据xj,j=1,2,…m表示指标数据的类型(如污水流量、浊度、化学需氧量等);对每个指标数据的采样值xij进行异常检测,计算每条数据与其他数据的欧氏距离,确定阈值,剔除超过阈值的点;xij表示xj的i次采样值;
由于获取的指标数据xi是基于各个传感器实时采集并存储在计算机中的,原始数据是存储在mysql数据库中一张表,该表具有三个属性:tag_id,value,time_stamp分别代表点的序号,点的值,和时间戳。数据集成的部分需要完成将此表变成一个矩阵,矩阵的行是同一时间戳下的各点的值,列是同一个点的不同时间戳的值。由于原始数据中并不是每个时间戳所有的tag_id都有值,所以在数据集成中需要去掉缺少一些点的时间戳。为了解决这一问题,通过创建辅助字典在数据集成过程中删除有缺失值的时间戳,具体代码如下:
对每个指标数据的采样值xij进行异常检测是采用基于临近度的离群点检测实现的。
采用基于临近度的离群点检测的过程中,第一次离群点检测偏离值,检测明显偏离的分数据;通过人工设定阈值的方法剔除离群点,对于离群点采用紧邻的数据来填补空缺。而后进行第二次离群点检测在时间上是否呈连续分布。
核心代码如下:
用基于临近度的离群点检测对污水处理过程中的各个数据进行异常检测,计算每条数据与其他数据的欧氏距离,确定阈值,剔除超过阈值的点。由于该算法时间复杂度为o(n2),要处理的数据又多达千万条,考虑到所用机器为八核处理器,故本文采用多进程编程,用八个进程同时处理该任务,极大地提高了效率。
步骤2、创建多元线性回归模型:
假设从属变量y与回归变量x1,x2,...,xm存在不精确的线性依赖关系,需添加误差项ε,并有ε的分布特性来刻画除x1,x2,...,xm之外的其他因素对y的影响,所以多元线性回归模型为:
y=β0+β1x1+...+βmxm+ε
其中,从属变量y用于表示预测结果,回归变量x1,x2,...,xm用于表示指标数据的观测值;
回归系数βk表示其它回归变量的取值给定的条件下第k个回归变量增加一个单位时,对从属变量平均响应的影响效果;k=1,2,...,m;
设(xi1,xi2,...,xim;y)为解释变量x1,x2,...,xm与变量y的n组观测值;记
则模型可写为:
y=xβ+ε
选取残差平方和作为多元线性回归的策略:
其中,
步骤3、将多元线性回归的策略转化为无约束最优化问题,采用梯度下降法求解无约束最优化问题:
假设f(x)是rn上具有一阶连续偏导数的函数,要求解的无约束最优化问题是:
将神经网络的学习过程转化为求损失函数的最小值问题,选取合适的初值x(0),不断迭代,更新x的值,使得目标函数极小化,直到收敛,最终确定损失函数的最小值。
将神经网络的学习过程转化为求损失函数的最小值问题的具体过程如下:
神经网络采用ann(人工神经网络以下简称ann),设有n个神经元与该神经元连结,每个神经元的输入信号为xi,该神经元的输出信号为y,如图1所示;
数学表达式为:
式中wi表示神经元i与该神经元的连接强度,或称权重值;
θ表示神经元的阈值;
f(*)表示该神经元的激活函数;激活函数f(*)采用relu=max(0,x)。激活函数用于在ann中加入非线性因素。这个激活函数相比传统的sigmoid系有以下特征:单侧抑制,相对宽阔的兴奋边界,稀疏激活性。
损失函数f(w)的函数值由权重值和偏置值决定,损失函数f(w)的图2示,图2中w*是损失函数的最小值;将权重值和偏置值各自组为一个n维的权重向量,分别记为wi和wj;
在空间内任意选择一个点a,都能计算得到损失函数的一阶、二阶导数;一阶导数可以表示为一个向量:
同样的,损失函数的二阶导数可以表示为海森矩阵(hessianmatrix):
hi,jf(w)=d2f/(dwi·dwj),i=1,…,n,j=1,…,n;
采用梯度下降最终确定损失函数的最小值,进而实现有机污水处理效果预测。
- 还没有人留言评论。精彩留言会获得点赞!