基于机器学习方法的冠心病智能筛查装置与流程
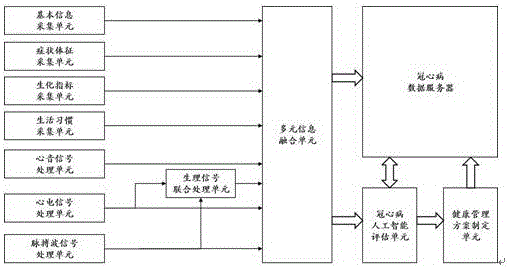
本发明涉及一种基于机器学习方法的冠心病智能筛查系统,属于冠心病筛查技术领域。
背景技术:
目前冠脉造影是冠心病检测的“金标准”,但它是有创伤性检查,费用高,对操作人员的技术要求很高,而且它是针对病人中、晚期的诊断,不适合早期筛查和健康管理。而当前的一些冠心病无创检测手段只是从某个或某几个角度评估冠心病的发病状态,准确度不高。
中国专利文献cn108577883a,公开了“一种冠心病筛查装置,包括:拾音器,用于获取心音信号;脉搏波传感器,用于获取脉搏波信号;心电传感器,用于获取心电信号;计算踝肱脉搏波速度(bapwv)和踝肱指数(abi);计算心电信号的st段电平和qrs波群宽度;将从心音、脉搏波和心电数据中提取的特征与用户病史资料和基本生理参数结合,组成特征向量;构建训练样本,采用最近邻聚类算法构建基于径向基函数神经网络的冠心病筛查模型;将所述特征向量输入筛查模型,获得筛查结果”。该装置中未考虑心电信号的st段波形特征、心脏至上肢和下肢动脉的脉搏波传播速度等指标对冠心病筛查的影响,而且未考虑胸痛、胸闷、心慌气短等冠心病的症状表现。
首先,绝大多数冠心病患者可出现暂时性心肌缺血引起的st段移位,因心内膜下心肌更容易缺血,故常见反映心内膜下心肌缺血的st段压低。胸痛等症状发作时的心电图尤其有意义,大多数冠心病患者胸痛发作时有一过性st段(抬高或压低),其中st段的动态改变是严重冠状动脉疾病的表现。因此,心电信号的st段波形特征(抬高或压低)更利于筛查冠心病。
其次,动脉弹性减退、僵硬度增加是冠状动脉病变的预测因素,而脉搏波传播速度pwv则是被广泛用来评估动脉僵硬度的一个指标。cn108577883a中提到“粥样硬化往往并非局部病变,患有主动脉粥样硬化的患者往往其冠脉也可能存在粥样硬化病变”,而臂踝脉搏波速度bapwv反映的是外周大动脉的扩张性和硬化度,相比而言,从心脏出发到上肢和下肢动脉测量点的脉搏波传播速度更能反映主动脉的硬化状态,进而更能准确评估冠状动脉的病变情况。
再次,冠心病患者最主要的症状表现就是胸痛、胸闷。冠心病分为慢性心肌缺血综合征对于慢性心肌缺血综合征来说,胸痛常由体力劳动或情绪激动所诱发,一般持续数分钟至十余分钟,休息后或服用硝酸甘油后可缓解;对于急性冠脉综合征来说,胸痛程度更为严重,持续时间更长,休息后或服用硝酸甘油后不能完全缓解。冠心病患者的症状还表现为全身乏力、心慌气短、头晕头痛等,而且上述症状在很多冠心病患者的早期就已经体现出来了。因此,将症状表现也加入到冠心病筛查模型中是非常必要的。
技术实现要素:
本发明针对现有冠心病筛查技术存在的问题,提供一种多层次多角度评估冠心病发病风险、冠心病筛查的敏感性和准确度高的基于机器学习方法的冠心病智能筛查装置。
为实现上述目的,本发明的基于机器学习方法的冠心病智能筛查装置采用以下技术方案:
该冠心病智能筛查装置,包括:
基本信息采集单元,用于被检者基本信息的收集;包括身高、体重、年龄、性别、高血压病史年限、糖尿病病史年限、血脂异常病史年限、是否服用降压药、是否服用降糖药、是否服用降脂药、高血压家族史、糖尿病家族史、血脂异常家族史中的一种或者任意几种的组合。
症状体征采集单元,用于被检者症状体征信息的收集;包括胸痛性质、胸痛持续时间、胸痛诱发因素、胸痛缓解因素、胸闷、心慌气短憋喘、多汗、恶心呕吐、嗜睡、夜间呼吸困难、乏力无力、头昏、头痛、晕厥、肺部啰音、下肢水肿中的一种或者任意几种的组合。
生化指标采集单元,用于被检者生化参数的收集;包括肌酸激酶同工酶ck-mb、心肌肌钙蛋白i、肌红蛋白mb、空腹血糖glu、总胆固醇tc、甘油三酯tg、低密度脂蛋白ldl、高密度脂蛋白hdl、同型半胱氨酸hcy、肌酐cr、尿酸ua、糖化血红蛋白ghb、血红蛋白hgb、血浆利钠肽bnp中的一种或者任意几种的组合。
生活习惯采集单元,用于被检者生活习惯信息的收集;包括是否吸烟、吸烟年限、日吸烟量、是否经常被动吸烟、是否饮酒、饮酒年限、日饮酒量、饮食是否高盐高脂、每周运动状况、近期睡眠状况、近期心理状况中的一种或者任意几种的组合。
心电信号处理单元,用于心电信号的采集以及预处理,并对预处理后的心电信号进行st段波形分析和心率计算;利用心电传感器获取体表的心电信号。信号预处理是指对采集的心电信号ad转换变为数字信号,对数字信号通过滤波器进行滤波后通过放大电路进行信号放大。
心音信号处理单元,用于心音信号的采集以及预处理,并对预处理后的心音信号进行s1心音幅值、s2心音幅值和舒张期段心音样本熵计算;利用心音传感器获取体表的心音信号。
脉搏波信号处理单元,用于脉搏波信号的采集以及预处理,并对预处理后的脉搏波信号进行血压和臂踝脉搏波传播速度计算;利用脉搏波传感器获取体表的脉搏波信号。
生理信号联合处理单元,连接所述心电信号处理单元和脉搏波信号处理单元的输出端,获取预处理后的心电信号和脉搏波信号,进而计算心脏至上肢和下肢动脉的脉搏波传播速度。
多元信息融合单元,连接基本信息采集单元、症状体征采集单元、生化指标采集单元、生活习惯采集单元、心电信号处理单元、心音信号处理单元、脉搏波信号处理单元和生理信号联合处理单元的输出端,对各个单元计算和收集得到的所有信息进行汇总,构成机器学习方法的属性向量。
冠心病人工智能评估单元,连接多元信息融合单元的输出端,将所述属性向量输入至冠心病智能筛查模型中,得到冠心病评估结果。
健康管理方案制定单元,连接冠心病人工智能评估单元的输出端,根据冠心病评估结果和被检者的基本信息、症状表现、生化参数及生活习惯信息给出个性化健康管理方案。
冠心病数据服务器,连接多元信息融合单元、冠心病人工智能评估单元和健康管理方案制定单元的输出端,用于存储机器学习方法的属性向量、冠心病评估结果以及个性化健康管理方案。
所述心电信号处理单元对预处理后的心电信号进行st段波形分析和心率计算的具体步骤为:
(1)利用小波变换和模极大值法求取预处理后的心电信号的r波位置,得到心电信号的rr间期序列,进而计算出心率;
(2)利用求得的r波位置将预处理后的心电信号分段,并通过插值或抽取形成统一预定长度的多段r-r信号;
(3)利用通过深度学习建立的st段分析模型分析上述r-r信号的st段波形类型,并统计st段水平压低、st段缓慢型上升、st段弓背型抬高和t波倒置四种st段类型占所有r-r信号总数的比例,形成比例向量,作为st段波形特征。
所述心音信号处理单元对预处理后的心音信号计算s1心音幅值、s2心音幅值和舒张期段心音样本熵的具体步骤为:
(1)按照预定长度将预处理后的心音信号平均分段,并对每段信号进行香农熵计算,得到熵值序列;
(2)计算熵值序列的均值,与预定系数相乘得到熵值阈值;
(3)遍历熵值序列,寻找与熵值阈值最接近的熵值点,通过其所在的信号段得到s1心音或s2心音的起始点位置和结束点位置;
(4)利用求导和极大值法对上述起始点位置和结束点位置之间的心音信号进行处理,并结合心电信号的r波位置,求出s1心音幅值和s2心音幅值;
(5)以s2心音后100ms为起点,按照预定长度对预处理后的心音信号划分出多段舒张期段心音信号,计算每段舒张期段心音信号的样本熵,并取所有样本熵值均值为最终样本熵值。
所述脉搏波信号处理单元对血压和臂踝脉搏波传播速度计算的过程如下所述:
(1)利用示波法对脉搏波信号进行分析计算得到血压;
(2)对左侧上肢原始脉搏波信号进行滤波,得到预处理后的脉搏波信号,记为pwlb;
同理,预处理后的左侧下肢脉搏波信号记为pwla;
(3)选取pwlb的起始点位置和pwla的起始点位置计算脉搏波的传播时间δlt;
(4)计算出心脏到左上肢肱动脉处的距离llb和心脏到左下肢踝部动脉处的距离lla;
(5)计算左侧臂踝脉搏波传播速度,公式如下:
(6)同理,计算出右侧臂踝脉搏波传播速度,并取左侧和右侧臂踝脉搏波传播速度的均值为最终臂踝脉搏波传播速度。
所述生理信号联合处理单元计算心脏至上肢和下肢动脉的脉搏波传播速度的过程如下所述:
(1)选取左上肢预处理后脉搏波信号pwlb的起始点位置和对应同一心动周期的心电信号的r波位置计算脉搏波的传播时间δlht;
(2)计算出心脏到左上肢肱动脉处的距离lhb;
(3)计算心脏至左上肢肱动脉的脉搏波传播速度,公式如下:
(4)同理,计算心脏至右上肢肱动脉的脉搏波传播速度rhbpwv,取lhbpwv和rhbpwv的均值作为心脏至上肢肱动脉的脉搏波传播速度hbpwv;
(5)同理,计算得到心脏至下肢踝部动脉的脉搏波传播速度hapwv。
所述冠心病人工智能评估单元中冠心病智能筛查模型的建立过程包括:
(1)构建机器学习方法的属性向量,所述属性向量包括:
根据心电信号分析计算得到的st段波形特征和心率;
根据心音信号分析计算得到的s1心音幅值、s2心音幅值和舒张期段心音样本熵;
根据脉搏波信号分析计算得到的血压和臂踝脉搏波传播速度;
根据心电信号和脉搏波信号综合分析计算得到的心脏至上肢和下肢动脉的脉搏波传播速度;
被检者基本信息;
被检者症状体征信息;
被检者生化参数;
被检者生活习惯信息;
(2)构建属性向量对应的标签数据,具体为:统计被检者的冠状动脉造影结果中各动脉分支的狭窄程度,按照预定规则划分冠心病的危险程度;
(3)收集年龄和性别均匹配的、包含各种病情的、包含属性向量和标签数据的冠心病患者和正常人的数据作为训练集样本;
(4)将属性向量作为输入,标签数据作为输出,使用支持向量机svm方法对训练集样本进行训练,构造冠心病智能筛查模型。
其中上述(2)中,统计被检者的冠状动脉造影结果中各动脉分支的狭窄程度,按照预定规则划分冠心病的危险程度,具体过程如下:
(1)所要统计分析的冠状动脉分支包括左主干、左前降支近段、左前降支中段、左前降支远段、对角支d1、对角支d2、对角支d3、左回旋支近段、左回旋支中段、左回旋支远段、钝缘支om1、钝缘支om2、钝缘支om3、右冠状动脉近段、右冠状动脉中段、右冠状动脉远段、后降支、左室后支;
(2)若所有分支的狭窄程度均未超过30%,则该被检者判定为正常人;若所有分支的狭窄程度至少有一分支超过30%,则该被检者判定为冠心病患者。
所述健康管理方案制定单元中给出的个性化健康管理方案,具体过程如下:
(1)若冠心病人工智能评估单元给出的冠心病评估结果为中低危,则针对被检者存在的一种或多种危险因素给出相应的膳食、运动、心理方面的干预措施;
(2)若给出的冠心病评估结果为高危,则给出做进一步检查的建议;如24小时动态心电图、冠状动脉ct或冠脉动脉造影等。
本发明的有益效果为:
(1)深入挖掘心电信号、心音信号和脉搏波信号,提取出可提高冠心病筛查准确度的特异性指标,包括心电信号的st段波性特征、心音信号的舒张期段样本熵等;
(2)联合同步分析心电信号与脉搏波信号,提取可反映冠状动脉硬化程度的指标,多层次多角度评估冠心病发病风险;
(3)综合考虑冠心病患者的基本信息、症状体征、生化指标和生活习惯,消除传统检测的单一指标单一结论的弊端,提高了冠心病筛查的敏感性;
(4)使用适用于小样本数据训练的支持向量机svm方法建立模型,同时增加了自学习再优化功能,使得冠心病筛查准确度不断提高。
附图说明
图1是本发明实施例中所述装置的结构原理图。
图2是本发明实施例中卷积神经网络结构示意图。
图3是本发明实施例中支持向量机基本原理示意图。
具体实施方式
如图1所示,本发明的冠心病智能筛查装置,包括基本信息采集单元、症状体征采集单元、生化指标采集单元、生活习惯采集单元、心电信号处理单元、心音信号处理单元、脉搏波信号处理单元、生理信号联合处理单元、多元信息融合单元、冠心病人工智能评估单元和冠心病数据服务器。利用心电传感器获取体表的心电信号,利用心音传感器获取体表的心音信号,利用脉搏波传感器获取体表的脉搏波信号,并提取上述信号的特征,结合被检者的基本信息、症状体征、生化检测指标和生活习惯构成属性向量,输入至冠心病智能筛查模型获得筛查结果。
基本信息采集单元,用于被检者基本信息的收集;包括身高、体重、年龄、性别、高血压病史年限、糖尿病病史年限、血脂异常病史年限、是否服用降压药、是否服用降糖药、是否服用降脂药、高血压家族史、糖尿病家族史、血脂异常家族史中的一种或者任意几种组合。
症状体征采集单元,用于被检者症状体征信息的收集;包括胸痛性质、胸痛持续时间、胸痛诱发因素、胸痛缓解因素、胸闷、心慌气短憋喘、多汗、恶心呕吐、嗜睡、夜间呼吸困难、乏力无力、头昏、头痛、晕厥、肺部啰音、下肢水肿中的一种或者任意几种组合。
生化指标采集单元,用于被检者生化参数的收集;包括肌酸激酶同工酶ck-mb、心肌肌钙蛋白i、肌红蛋白mb、空腹血糖glu、总胆固醇tc、甘油三酯tg、低密度脂蛋白ldl、高密度脂蛋白hdl、同型半胱氨酸hcy、肌酐cr、尿酸ua、糖化血红蛋白ghb、血红蛋白hgb、血浆利钠肽bnp中的一种或者任意几种组合。
生活习惯采集单元,用于被检者生活习惯信息的收集;包括是否吸烟、吸烟年限、日吸烟量、是否经常被动吸烟、是否饮酒、饮酒年限、日饮酒量、饮食是否高盐高脂、每周运动状况、近期睡眠状况、近期心理状况中的一种或者任意几种组合。
基本信息采集单元、症状体征采集单元、生化指标采集单元和生活习惯采集单元均可采用现有的输入终端。
心电信号处理单元,通过心电传感器采集获取体表的心电信号,并对心电信号进行预处理,并对预处理后的心电信号进行st段波形分析和心率计算。预处理是指对采集的心电信号进行ad转换变为数字信号,对数字信号通过滤波器进行滤波后通过放大电路进行信号放大。
心音信号处理单元,利用心音传感器获取体表的心音信号,对采集的心音信号进行预处理,并对预处理后的心音信号进行s1心音幅值、s2心音幅值和舒张期段心音样本熵计算。预处理是指对采集的心音信号进行ad转换变为数字信号,对数字信号通过滤波器进行滤波后通过放大电路进行信号放大。
脉搏波信号处理单元,利用脉搏波传感器获取体表的脉搏波信号,并对采集的脉搏波信号进行预处理,并对预处理后的脉搏波信号进行血压和臂踝脉搏波传播速度计算。预处理是指对采集的脉搏波信号进行ad转换变为数字信号,对数字信号通过滤波器进行滤波后通过放大电路进行信号放大。预处理过程为现有技术。
生理信号联合处理单元,连接所述心电信号处理单元和脉搏波信号处理单元的输出端,获取预处理后的心电信号和脉搏波信号,进而计算心脏至上肢和下肢动脉的脉搏波传播速度。
多元信息融合单元,连接基本信息采集单元、症状体征采集单元、生化指标采集单元、生活习惯采集单元、心电信号处理单元、心音信号处理单元、脉搏波信号处理单元和生理信号联合处理单元的输出端,对各个单元计算和收集得到的所有信息进行结构化处理,构成机器学习方法的属性向量。
冠心病人工智能评估单元,连接多元信息融合单元的输出端,将所述属性向量输入至冠心病智能筛查模型中,得到冠心病评估结果。
健康管理方案制定单元,连接冠心病人工智能评估单元的输出端,根据冠心病评估结果和被检者的基本信息、症状表现、生化参数及生活习惯信息给出一种科学合理的个性化健康管理方案。所述健康管理方案制定单元中给出的个性化健康管理方案,具体过程如下:
(1)若冠心病人工智能评估单元给出的冠心病评估结果为中低危,则针对被检者存在的一种或多种危险因素给出相应的膳食、运动、心理方面的干预措施;
(2)若给出的冠心病评估结果为高危,则给出做进一步检查的建议;如24小时动态心电图、冠状动脉ct或冠脉动脉造影等。
举例说明:若一个被检者的冠心病评估结果为中低危,且该被检者存在如下危险因素:
(a)经常在劳累或者情绪激动后感到心前区疼痛,疼痛持续时间大约为3-10分钟,休息后或者服用硝酸甘油后缓解;
(b)胸闷、乏力;
(c)空腹血糖、总胆固醇、和低密度脂蛋白均高出正常范围;
(d)吸烟30年,每日吸烟20支;
(e)饮酒30年,每日饮酒6两;
(f)饮食偏高盐;
(g)每周偶尔运动;
(h)近段时间情绪不稳定,遇事易激动。
针对该被检者给出的健康管理方案如下:
(a)合理饮食,不偏食,不过量,减少高脂肪、高胆固醇食物的食用,增加新鲜水果、蔬菜及豆制品的摄入;多食用高纤维素和菌类食物,少进食高糖高热量食物;少吃稀饭、馒头等主食,以粗粮或薯类替代;
(b)以周为单位,递减日吸烟量,直至戒烟;
(c)适量饮酒,日饮酒量控制在2两以内;
(d)用定量盐勺控制用盐量,每日用盐不超过5g;
(e)坚持每日运动,可慢跑或打太极拳1小时;
(f)经常提醒自己遇事要心平气和,增加耐性,掌握一套心理调节的方法,如呼吸放松或意念放松;
(g)家中常备速效救心丸和硝酸甘油等药物。
冠心病数据服务器,连接多元信息融合单元、冠心病人工智能评估单元和健康管理方案制定单元的输出端,用于存储机器学习方法的属性向量、冠心病评估结果以及个性化健康管理方案。
下面是本发明中冠心病智能筛查具体筛查过程进行描述。
1属性向量的构造
1.1心电信号心率的计算和st段波形特征的分析
(1)选取0.01-75hz的带通巴特沃斯滤波器对原始心电信号进行滤波;
(2)选取db6小波函数,分解层数设为2,对滤波后的心电信号进行2层小波分解后得到近似系数序列a2和细节系数序列d1,d2,将细节系数序列d1和d2置零,保留第二层近似系数序列a2,重构去噪后的心电信号;
(3)选取db6小波函数,分解层数设为10,对去噪后的心电信号进行10层小波分解后得到近似系数序列a10和细节系数序列di,i=1,2,...,10,计算第十层近似系数序列a10的均值,并以该均值构造与a10序列等同大小的序列a10′,利用近似系数序列a10′和细节系数序列di,i=1,2,...,10重构去基线漂移后的心电信号ecg;
(4)对去除噪声和基线漂移后的心电信号ecg在2至32尺度上做连续小波变换,并将变换后的数据按照对应位置进行加和处理,采用模极大值方法求出r波位置序列;
(5)对步骤(3)中的r波位置序列进行求导得到rr间期序列,计算rr间期序列的均值rrmean,进而计算心率hr,具体计算公式如下:
其中,samplerate为采样率,此处samplerate取1000hz;
(6)利用步骤(3)中的r波位置序列将心电信号ecg分成多段r-r信号,对多段r-r信号进行插值或抽取操作,最终形成长度均为900ms的多段r-r信号,输入至st段分析模型得出每段r-r信号的st段类型,统计每种st段类型(st段水平压低、st段缓慢型上升、st段弓背型抬高、t波倒置)所在r-r信号的段数,并计算其与所有r-r信号总段数的比例,形成比例向量stp,作为st段波形特征。
其中,st段分析模型是通过对大样本的r-r信号进行深度学习训练得到的,其建立过程如下:
①从大样本中取出一个样本x(xp,yp),输入至训练网络中,此处网络选择卷积神经网络。其中,xp表示一段经过处理的r-r信号,yp则表示与xp对应的st段波形类型,p=1,2,...,n,n为样本数;
②样本x(xp,yp)进入卷积神经网络后,执行前向传播过程,经过逐层变换后最终传输至输出层,得到预测输出op,其网络结构如图2所示,具体计算如下:
其中,n为卷积神经网络的层数,
③计算实际输出yp和预测输出op的误差errp:
errp=op-yp,
④若误差errp达到指定范围或者迭代次数达到预设次数时,训练结束;否则,继续按照极小化误差的方向反向传播调整各层系数wi,i=1,2,...,n。最后一次调整后的参数wi即为最终的模型参数。
1.2心音信号的s1和s2幅值的计算
(1)选取1-500hz的带通巴特沃斯滤波器对原始心音信号进行滤波,得到去噪后心音信号,记为pcg;
(2)对pcg进行平均分段,每段长度固定,如长度为80ms,利用香农熵计算每段信号的熵值,获得熵值序列si,i=1,2,...,m,m为段数,并计算该熵值序列的均值smean,设置阈值为smean*b,其中b为系数,此处b取0.5;
(3)遍历熵值序列si,i=1,2,...,m,若sl小于等于阈值,且sl+1大于阈值,则记录bp=l*80,p=1,2,...,p,其中p为所有符合上述条件的熵值个数,此时bp即为心音信号s1或s2的起始点;若sk大于等于阈值,且sk+1小于阈值,则记录eq=k*80,q=1,2,...,q,其中q为所有符合上述条件的熵值个数,此时eq即为心音信号s1或s2的终止点。此处p与q一致;
(4)对序列bp=l*80,p=1,2,...,p和序列eq=k*80,q=1,2,...,q进行交织重组,构成序列ss={b1,e1,b2,e2,...,bp,ep)
(5)以bi为起点,ei为终点对pcg划分多个区间,利用求导和极大值法计算出每个区间中的所有极大值,并通过阈值比较,确定该区间中s1或s2的位置;
(6)因心电信号的r波位置与心音信号的s1位置距离较短,利用1.1所述心电信号的r波位置对上述极大值进行修正,确定区间中的s1和s2,进而获得对应的s1和s2的幅值信息。计算同一被检者的多个s1幅值的均值为最终s1幅值信息,s2也进行同样处理。
1.3舒张期段心音信号的样本熵计算
(1)以1.4中所计算出的心音信号的s2后100ms为起点,长度为200ms划分出多段舒张期心音信号ds。此处长度设置为200ms是为了消除由心率个体差异和心率不齐造成的影响,而且该段长度不仅避开了高强度瓣膜音,还与最大的冠脉血流对应,有利于挖掘冠脉病变的信息;
(2)对每段舒张期段信号进行样本熵计算,具体计算如下:
①将每段舒张期心音信号按序号连续顺序组成一组2维向量,
ds(i)=[ds(i),ds(i+1)]i=1,2,...,n-1
②定义ds(i)与ds(j)间的距离d[ds(i),ds(j)]为两者对应元素中差值最大的一个,即:
d[ds(i),ds(j)]=max[x(i+k)-x(j+k)]k=0,1i,j=1,2,...,n-1
③给定阈值r,对每一个i值统计d[ds(i),ds(j)]小于r的数目,记为nr(d[ds(i),ds(j)]),统计该数组与向量总数n-2的比值,记为
其中,r取数据标准差的0.1倍;
④对所有的
⑤将每段舒张期心音信号按序号连续顺序组成一组3维向量,
ds(i)=[ds(i),ds(i+1),ds(i+2)]i=1,2,...,n-2
重复②至④步骤得到p3(r);
⑥计算样本熵:
sampleen(2,r,n)=-ln[p3(r)/p2(r)]
(1)计算所有舒张期段心音信号的样本熵的均值为最终样本熵值。
1.4血压和臂踝脉搏波传播速度的计算
(1)利用示波法对脉搏波信号进行分析计算得到血压;
(2)选取0.5-20hz的带通巴特沃斯滤波器对左侧上肢原始脉搏波信号进行滤波,得到预处理后的脉搏波信号,记为pwlb;同理,预处理后的左侧下肢脉搏波信号记为pwla;
(3)选取pwlb的起始点位置和pwla的起始点位置计算脉搏波的传播时间δlt;
(4)利用经验公式和身高计算出心脏到左上肢肱动脉处的距离llb和心脏到左下肢踝部动脉处的距离lla;
(5)计算左侧臂踝脉搏波传播速度,公式如下:
(6)同理,计算出右侧臂踝脉搏波传播速度,并取左侧和右侧臂踝脉搏波传播速度的均值为最终臂踝脉搏波传播速度。
1.5心脏至上肢肱动脉、下肢踝部动脉的脉搏波传播速度的计算
(1)选取1.4所述左上肢预处理后脉搏波信号pwlb的起始点位置和对应同一心动周期的心电信号的r波位置计算脉搏波的传播时间δlht;
(2)利用经验公式和身高计算出心脏到左上肢肱动脉处的距离lhb;
(3)计算心脏至左上肢肱动脉的脉搏波传播速度,公式如下:
(4)同理,可计算心脏至右上肢肱动脉的脉搏波传播速度rhbpwv,取lhbpwv和rhbpwv的均值作为心脏至上肢肱动脉的脉搏波传播速度hbpwv;
(5)同理,可计算得到心脏至下肢踝部动脉的脉搏波传播速度hapwv。
1.6被检者的基本信息
被检者的基本信息包括:身高(cm)、体重(kg)、年龄(岁)、性别(女-0,男-1)、高血压病史年限(年)、糖尿病病史年限(年)、血脂异常病史年限(年)、是否服用降压药(否-0,是-1)、是否服用降糖药(否-0,是-1)、是否服用降脂药(否-0,是-1)、高血压家族史(否-0,是-1)、糖尿病家族史(否-0,是-1)、血脂异常家族史(否-0,是-1)。
1.7被检者的症状体征信息
被检者的症状体征信息包括:
胸痛性质(无胸痛-0,针刺样\刀割样\牵扯样疼痛-1,压榨性疼痛-2,心绞痛-3,烧灼感\紧缩感-4,其它疼痛-5);
胸痛持续时间(无胸痛-0,持续几分钟至十多分钟-1,持续20分钟至几十分钟-2,持续时间超过1小时-3);
胸痛诱发因素(无明显诱发因素-0,体力劳动或情绪激动诱发-1,其它诱因-2);
胸痛缓解因素(休息后或服用硝酸甘油后几分钟内缓解-0,休息后或服用硝酸甘油后更长时间缓解-1,休息后或服用硝酸甘油后不能完全缓解-2);
胸闷(否-0,是-1)、心慌\气短\憋喘(否-0,是-1)、多汗(否-0,是-1)、恶心\呕吐(否-0,是-1)、嗜睡(否-0,是-1)、夜间呼吸困难(否-0,是-1)、乏力无力(否-0,是-1)、头昏(否-0,是-1)、头痛(否-0,是-1)、晕厥(否-0,是-1)、肺部啰音(否-0,是-1)、下肢水肿(否-0,是-1)。
1.8被检者的生化指标信息
被检者的生化指标信息包括肌酸激酶同工酶ck-mb(u/l)、心肌肌钙蛋白i(ug/l)、肌红蛋白mb(ng/ml)、空腹血糖glu(mmol/l)、总胆固醇tc(mmol/l)、甘油三酯tg(mmol/l)、低密度脂蛋白ldl(mmol/l)、高密度脂蛋白hd(mmol/l)l、同型半胱氨酸hcy(umol/l)、肌酐cr(umol/l)、尿酸ua(umol/l)、糖化血红蛋白ghb(%)、血红蛋白hgb(g/l)、血浆利钠肽bnp(pg/ml)。
1.9被检者的生活习惯信息
被检者的生活习惯信息包括是否吸烟(否-0,是-1)、吸烟年限(年)、日吸烟量(支)、是否经常被动吸烟(否-0,是-1)、是否饮酒(否-0,是-1)、饮酒年限(年)、日饮酒量(两)、饮食是否高盐高脂(否-0,是-1)、每周运动状况(规律运动-0,偶尔运动-1,不运动-2)、近期睡眠状况(睡眠良好-0,偶尔失眠-1,经常失眠-2)、近期心理状况(精神良好,遇事不急躁-0,精神不稳定,遇事急躁-1)。
2标签数据的构造
根据被检者的冠状动脉造影结果中各分支的狭窄程度,对冠心病的危险程度进行划分,具体如下:
(1)所要统计分析的动脉分支包括左主干、左前降支近段、左前降支中段、左前降支远段、对角支d1、对角支d2、对角支d3、左回旋支近段、左回旋支中段、左回旋支远段、钝缘支om1、钝缘支om2、钝缘支om3、右冠状动脉近段、右冠状动脉中段、右冠状动脉远段、后降支、左室后支;
(2)若所有分支的狭窄程度均未超过30%,则该被检者判定为正常人;若所有分支的狭窄程度至少有一分支超过30%,则该被检者判定为冠心病患者;
(3)收集年龄和性别均匹配的、包含各种病情的、包含属性向量和标签数据的冠心病患者和正常人的数据作为训练集样本。
3支持向量机的模型构建
3.1支持向量机基本原理
支持向量机是一种建立在统计学习理论基础上的一种通用学习方法,它是根据结构风险最小化原则,着重研究在小样本情况下的统计学习规律,为解决有限样本学习问题提供了一个统一的框架。
对线性可分的样本集(xi,yi),(i=1,2,...,n),xi∈rd,yi∈{-1,1},如果可以被一个分类面方程分开,如图3所示,那么各类就具有如下特征:
yi(w*xi+b)≥1,i=1,2,...,n
此时分类间隔为2/||w||。显示最优分类面就是满足方程(1),并使
利用lagrange优化方法可以把上述求最优分类面问题转化为求其对偶问题:
满足的约束条件为:
上式中αi为lagrange系数。这是一个不等式约束下二次函数寻优的问题,根据kkt条件,存在唯一解:
αi[yi(w·xi+b)-1]=0
因此,基于最优分类面的分类规则就是下面的最优分类函数:
根据f(x)的符号来确定测试样本x的归属。
训练样本集为线性不可分时,需引入非负松弛变量,构造最优超平面问题转化为二次规划问题,即折中考虑最少错分样本和最大分类间隔,得到广义最优分类面:
f(x)=sign(w·x+b)
对非线性问题,理论上可以将输入空间通过某种非线性函数映射到一个高维特征空间,在这个空间中构造线性的最优分类超平面,这种变换比较复杂。但是注意到,在上面的对偶问题中,只涉及到训练样本之间的内积运算xi·xj。如果可以找到一个函数k(xi·xj),使得k(xi·xj)等于xi、xj在高维特征空间中的映射的内积,那么求解最优化问题和计算判别函数时就不需要计算该非线性函数了,只要一种核函数k(xi·xj)满足mercer条件,它就对应某一变化空间中的内积,可以确定一个支持向量机,从而避免特征空间维数灾问题。此时,分类函数就变为:
3.2内积核函数
核函数k(xi,xj)的要求是满足mercer定理,选择不同的核函数可以构造不同的支持向量机。目前,支持向量机普遍采用的内积核函数有:
(1)多项式核函数:k(xi,xj)=[a(x·xi)+1]d
(2)径向基核函数:
(3)两层感知器核函数:k(xi,xj)=tanh[k(x·xi)+c]
本发明采用多项式核函数。若多项式阶数d数值较小,如d=1,分类器的分类效果最差;随着d的升高,分类器的分类效果会得到提高,但当d大于某个数值时,属性空间的维数会变得很大,出现“过学习”现象,分类器的分类性能反而降低。本发明中,多项式核函数的阶数d选择6。
3.3冠心病筛查模型的构建
由于每个属性的量纲和数值范围不同,在输入至svm分类器之前,需要对1中所构造的属性向量中的每个属性进行归一化操作,具体操作如下:
其中,xi代表第i中属性的值,max{xi}和min{xi}分别为该属性的最大值和最小值。
将上述归一化后的属性向量输入至svm分类器作为输入,2中所构造的标签数据输入至svm分类器作为输出,对每个样本数据进行迭代训练即可创建基于svm的冠心病筛查模型。
4冠心病筛查模型的使用
同步采集被检者的心电信号、心音信号、压力脉搏波信号并分析计算出相关指标,结合被检者资料中的基本信息、症状体征、生化参数及生活习惯信息,按照3中所述方法构造归一化后的属性向量,将该属性向量输入至冠心病筛查系统中得出冠心病危险程度的评估结果。
此外,冠心病筛查模型可以不断从数据服务器中提取新的属性向量数据和对应的标签数据,追加到原有的训练集中进行再训练和模型参数的再调整,进而实现冠心病筛查准确性的再提高。
需要说明的是,本发明所述的属性向量中包含的属性只是一种或多种实施例的体现,这意味着与本发明所述属性相似或等同的属性均被涵盖在本发明中。此外,未详细描述的地方均为现有技术。
- 还没有人留言评论。精彩留言会获得点赞!