基于非参数统计的脑功能磁共振编码能量成像方法与流程
本发明涉及一种医学成像方法,尤其涉及一种基于非参数统计的脑功能磁共振编码能量成像方法。
背景技术:
众所周知,大脑是迄今为止我们所知道的最复杂、最精密的系统。由于研究脑对于人类有重要的价值,因此世界各国都在展开脑科学的探索研究,其中脑功能成像是人类研究脑的重要方法。近几十年高空间分辨率的功能磁共振成像技术是人们认识脑的一种重要的无损检测手段,并且在神经、认知和临床等多领域受到了极大关注。功能磁共振脑功能信息提取技术是将磁共振成像与大脑认知、神经科学和临床应用相结合的关键。
功能磁共振成像利用血氧水平依赖性(bloodoxygenationleveldependent,bold)对比,给我们提供了一种测量血氧流的方法,具体可参见电子科技大学张江的博士论文《脑功能磁共振成像数据处理算法及应用研究》。功能磁共振成像技术探测反映神经活动的脑血流量(cerebralbloodflow,cbf)与血氧变化,当大脑出现神经活动时,cbf与脑氧代谢率(cerebralmetabolicrateofoxygen,cmro2)增加,而且伴随着大脑神经活动的增加,局部cbf增加得比cmro2快,导致脑氧抽取率(cerebraloxygenextractionfraction)下降,从而局部血液含氧较多,脱氧血红蛋白减少,磁场畸变减小,局部磁共振信号轻微增加。bold信号的变化被用作功能磁共振成像成像信号。虽然bold效应是功能磁共振成像的基础,但是它的确切机制还仍然不是十分清楚。而且bold响应的复杂性,功能磁共振成像信号形状变化等对后续数据的分析构成了挑战。目前利用功能磁共振成像技术探测脑功能活动仍然不完善,需要进一步的发展。
功能磁共振图像时间序列信息的利用程度和信息处理技术的发展密切相关。近几十年来,无线电通信、模式识别和机器学习等信息科学的迅速发展,使得信号处理学科得到了极大的推动,信号处理的应用领域也不断扩大。随着信号处理技术的发展为分析功能磁共振图像时间序列信号,挖掘功能磁共振成像数据集内部的隐藏信息提供了新手段。近年来,高速稳健的脑功能定位方法也受到了一定的重视。因此,将信息处理技术融合到功能磁共振成像数据的脑功能活动区定位分析中,创新性地改进和发展功能磁共振成像数据功能定位分析技术,是本发明的重点。
在功能磁共振定位成像方法上,数据驱动方法不同于需要先验实验信息和模式假设的统计模型。检索关于数据驱动分析方法的文献,如主成分分析和独立成分分析(independentcomponentsanalysis,ica),它们并不需要先验实验信息和实验模式或血液动力学响应函数(hemodynamicresponsefunction,hrf),并且它们已经被许多课题组应用。但是这些数据驱动方法难以发现嵌入在数据集中的非线性结构并且在选择有意义的分解成分时也存在困难。在进行磁共振图像的脑功能定位分析时,由于功能磁共振数据量庞大使数据驱动技术在个人计算机上难于进行实际高效处理。因此,本发明首先利用标准化z分数、协方差矩阵与深度自编码技术相结合对功能磁共振数据降维,克服数据集的非线性问题和大多数非线性降维方法所不具备的逆映射问题。但是,该方法在大数据降维后也存在选取具体哪一维数据更有意义的问题,因此本发明建立了通过计算每一维的功率谱累积能量并确定平均功率最大的那维数据来作为有效数据的方法。并将该维功能磁共振数据的非参数自举统计具有显著性差异的体素作为脑功能活动探测结果。
技术实现要素:
本发明的目的就在于提供一种解决上述问题,不仅建立了一种功能磁共振成像模型,而且由于对成像数据的降维等处理也节省计算机内存等资源,利用此模型实现功能磁共振成像,基于非参数统计的脑功能磁共振编码能量成像方法。
为了实现上述目的,本发明采用的技术方案是这样的:一种基于非参数统计的脑功能磁共振编码能量成像方法,包括以下步骤:
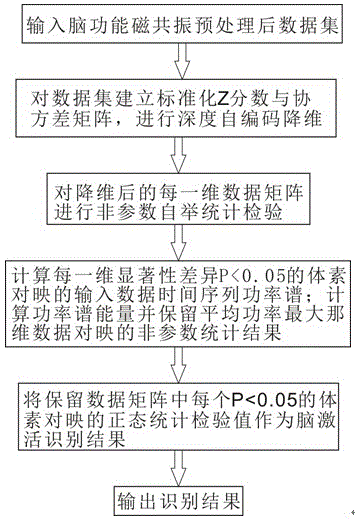
(1)对功能磁共振预处理后数据集建立标准化z分数与协方差矩阵,进行深度自编码降维;
(11)采集脑功能磁共振数据,并对脑功能磁共振的功能像数据进行预处理,得到预处理后的数据集d,
(12)对协方差矩阵用相关维数法进行本质维数估计,确定最优维数l;
(13)根据最优维数对协方差矩阵进行自编码降维,获得降维数据矩并取反,然后与步骤(11)中z分数矩阵相乘获得对应于z分数矩阵的降维数据q,
(2)对q中每一列数据向量
(3)对每一列数据向量qj,利用(2)统计结果中显著性差异p<0.05的体素对应在数据集d中的时间序列di,来计算各体素时间序列的功率谱和功率谱累积能量,并将各体素的功率谱累积能量作为各体素在时域上的平均功率;叠加每一列数据向量所有体素的平均功率作为该列数据向量的平均功率,保留平均功率最大的qj,,记为qj(max);
(4)将qj(max)中对应于p<0.05的体素作为激活体素,qj(max)的非参数统计结果作为脑激活探测识别激活值;
(5)将步骤(4)探测得到的脑激活体素,投射到结构像模板上显示成像。
作为优选:所述步骤(1)中,预处理为:将脑功能磁共振的功能像数据,先进行头动校正、准化到epi模板、空间平滑、再滤除信号的低频噪声。
作为优选:所述步骤(2)具体为:
(21)对q中每一列数据向量qj,用自举法确定其均值向量和标准差向量,并用该均值向量与标准差向量的算术平均作为该列数据qj正态分布的均值和方差;
(22)将均值、方差和显著性差异p=0.05带入qj的正态分布求逆,得出qj对应于显著性差异p=0.05的值,并将该值设为qj的阈值,利用阈值保留p<0.05的体素对映的数据值,并将保留下的数据值作为列数据向量qj的非参数统计结果,其中,利用阈值保留p<0.05的体素对映的数据值的具体操作为:判断qj中各体素对映的数据值,若大于阈值则保留,小于和等于阈值则置零。
本发明的整体思路为:基于非参数统计的脑功能磁共振编码能量成像技术,属于磁共振成像的图像后处理技术领域。该技术提出了将深度自编码、非参数自举统计与功率谱分析整合用于去处理功能磁共振成像的大数据集。通过自编码达到对功能磁共振大数据集的降维,从而减小对后续数据的处理量。将降维后的数据集通过自举统计检出激活成分,并结合各维数据的最大能量来优化选取识别结果。因此,基于非参数统计的功能磁共振编码能量成像,它不仅建立了一种功能磁共振成像模型,而且由于对成像数据的降维等处理也节省计算机内存等资源,利用此模型实现功能磁共振成像是一种新的技术尝试。
与现有技术相比,本发明的优点在于:
(1)该技术方法属于数据驱动模型不需要功能成像的先验信息,相比传统的功能磁共振统计参数成像技术,我们可不用预先知道磁共振实验设计模式。
(2)对预处理后的功能磁共振数据标准化为z分数,并计算协方差矩阵,由于协方差矩阵比原磁共振大数据数据量降低,本发明对协方差矩阵进行自编码降维相对于直接对功能磁共振大数据进行自编码降维处理降低了在个人计算机上会出现内存溢出现象。相比传统技术,本发明方法对功能磁共振数据通过自编码降维后再成像,进一步降低了后续磁共振成像的数据处理量,节省了计算资源,提高了计算效率,该方法更适合功能磁共振大数据成像;
(3)在激活体素与最优结果的选择上,本发明利用非参数自举统计与功率谱累积能量分析结合去决定最佳功能磁共振成像应该选取哪维(列)数据和哪些激活体素。避免人为经验因素对功能成像结果的影响,解决了最优成像结果的选择问题。
因此对本发明而言,它优化既有模型,在功能磁共振大数据成像领域具有很大的潜在应用前景。
因此对本发明而言,它优化既有模型,在功能磁共振大数据成像领域具有很大的潜在应用前景。
附图说明
图1为本发明主体构架图;
图2为本发明技术探测到视觉刺激的脑功能活动成像范例。
具体实施方式
下面将结合附图对本发明作进一步说明。
实施例1:参见图1,一种基于非参数统计的脑功能磁共振编码能量成像方法,其包括以下步骤:
(1)对功能磁共振预处理后数据集建立标准化z分数与协方差矩阵,进行深度自编码降维;
(11)采集脑功能磁共振数据,并对脑功能磁共振的功能像数据进行预处理,得到预处理后的数据集d,
(12)对协方差矩阵用相关维数法进行本质维数估计,确定最优维数l;
(13)根据最优维数对协方差矩阵进行自编码降维,获得降维数据矩并取反,然后与步骤(11)中z分数矩阵相乘获得对应于z分数矩阵的降维数据q,
(2)对q中每一列数据向量
(21)对q中每一列数据向量qj,用自举法确定其均值向量和标准差向量,并用该均值向量与标准差向量的算术平均作为该列数据qj正态分布的均值和方差;
(22)将均值、方差和显著性差异p=0.05带入qj的正态分布求逆,得出qj对应于显著性差异p=0.05的值,并将该值设为qj的阈值,利用阈值保留p<0.05的体素对映的数据值,并将保留下的数据值作为列数据向量qj的非参数统计结果,其中,利用阈值保留p<0.05的体素对映的数据值的具体操作为:判断qj中各体素对映的数据值,若大于阈值则保留,小于和等于阈值则置零。
(3)对每一列数据向量qj,利用(2)统计结果中显著性差异p<0.05的体素对应在数据集d中的时间序列di,来计算各体素时间序列的功率谱和功率谱累积能量,并将各体素的功率谱累积能量作为各体素在时域上的平均功率。叠加每一列数据向量所有体素的平均功率作为该列数据向量的平均功率,保留平均功率最大的qj,记为qj(max)。
(4)将qj(max)中对应于p<0.05的体素作为激活体素,qj(max)的非参数统计结果作为脑激活探测识别激活值。
(5)将步骤(4)探测得到的脑激活体素,投射到结构像模板上显示成像。
本实施例中:数据集d建立标准化z分数矩阵具体为:
若x为向量,它的标准化z分数计算公式为:
z-scores=(x-mean(x))/std(x),std代表标准差;
若x,y为向量,它们的协方差采用如下公式计算:
实施例2:参见图1和图2,本发明对视觉刺激的功能磁共振成像的实施方式。
(1)对功能磁共振预处理后数据集建立标准化z分数与协方差矩阵,进行深度自编码降维;
(11)采集脑功能磁共振数据,并对脑功能磁共振的功能像数据进行预处理,具体为:先进行头动校正、标准化到epi模板、用12mm的半高宽对数据进行空间平滑,再用一个截止频率为1/128hz的高通滤波器用来滤除信号的低频噪声;
得到预处理后的数据集d,d是m×n矩阵;m为数据集d中体素个数,n为每个体素时间序列长度,n<<m。再对数据集d建立标准化z分数矩阵与协方差矩阵,本实施例中得到的协方差矩阵设为r,r是n×n矩阵;
(12)对协方差矩阵用相关维数法进行本质维数估计,确定最优维数l;
(13)根据最优维数对协方差矩阵进行自编码降维,获得降维数据矩r并取反r=-r,然后与步骤(11)中z分数矩阵相乘获得对应于z分数矩阵的降维数据q,
(2)对q中每一列数据向量
(21)对q中每一列数据向量qj,用自举法确定其均值向量和标准差向量,并用该均值向量与标准差向量的算术平均作为qj正态分布的均值和方差;本实施例中,自举法抽样次数设置为5000次,当然不仅限于此;
(22)将均值、方差和显著性差异p=0.05带入qj的正态分布求逆,得出qj对应于显著性差异p=0.05的值,并将该值设为qj的阈值,利用阈值保留p<0.05的体素对映的数据值,并将保留下的数据值作为列数据向量qj的非参数统计结果,其中,利用阈值保留p<0.05的体素对映的数据值的具体操作为:判断qj中各体素对映的数据值,若大于阈值则保留,小于和等于阈值则置零。
(3)对每一列数据向量qj,利用(2)统计结果中显著性差异p<0.05的体素对应在数据集d中的时间序列di,来计算各体素时间序列的功率谱和功率谱累积能量,并将各体素的功率谱累积能量作为各体素在时域上的平均功率。叠加每一列数据向量所有体素的平均功率作为该列数据向量的平均功率,保留平均功率最大的qj,记为qj(max)。
(4)将qj(max)中对应于p<0.05的体素作为激活体素,qj(max)的非参数统计结果作为脑激活探测识别激活值。
(5)将步骤(4)探测得到的脑激活体素,投射到结构像模板上显示成像。如图2所示,展示了视觉刺激的功能磁共振第7,8,9,10,11层数据的成像结果。
以上所述仅为本发明的实施案例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!