一种基于舌象特征和BMI指数的脂肪肝预测方法与流程
本发明涉及人工智能
技术领域:
,更具体的是涉及一种基于舌象特征和bmi指数的脂肪肝预测方法。
背景技术:
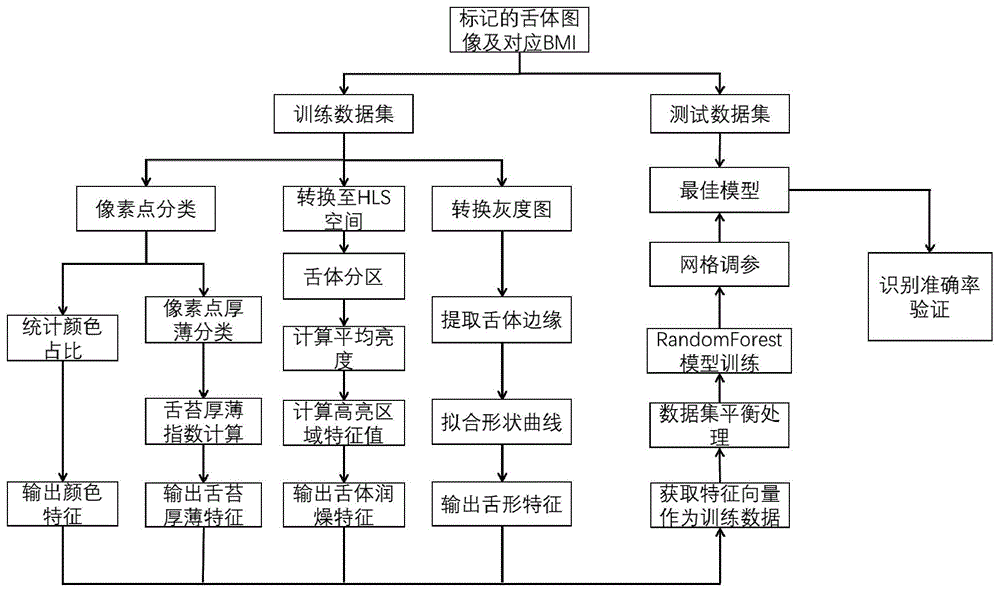
:bmi(bodymassindex)指数为体质指数,是目前国际上常用来量度体重与身高比例的工具,利用身高和体重之间的比例衡量一个人是否过瘦或过肥,而通常情况下脂肪肝患者往往由于脂肪含量过高较肥胖,因此bmi指数对判定脂肪肝具有辅助作用。传统的脂肪肝诊断往往靠医生配合辅助检查来进行确诊,比如医生根据患者病史和如肝功能,血脂,b超,ct等辅助检查项目对脂肪肝进行诊断,但是目前的诊断方法依赖于大量的先验知识,同时进行辅助检查又需要去医院,费时费力而且成本不低,十分不便利。随着技术的不断发展,目前已经有了直接使用舌体图像对脂肪肝进行预测识别的技术,但是现有技术依赖于大量标记过的数据样本,否则训练出的模型准确率并不高,并且现有模型网络结构较为复杂,计算时间较长,不利于部署。技术实现要素:本发明的目的在于:为了解决目前直接使用舌体图像对脂肪肝进行预测,依赖于大量样本,且网络结构复杂的问题,本发明提供一种基于舌象特征和bmi指数的脂肪肝预测方法。本发明为了实现上述目的具体采用以下技术方案:一种基于舌象特征和bmi指数的脂肪肝预测方法,包括:采集若干张患病和未患病的舌体图像样本及每张舌体图像样本对应的bmi指数,将舌体图像样本随机分为训练数据集和测试数据集,并将每张舌体图像样本对应的bmi指数添加到对应的训练数据集和测试数据集中;对训练数据集中的舌体图像样本进行特征提取,得到舌质舌苔颜色特征向量[pxi,pyi]、舌苔厚薄特征向量[t,m]、舌体润燥特征l和舌体胖瘦指数i;基于舌质舌苔颜色特征向量[pxi,pyi]、舌苔厚薄特征向量[t,m]、舌体润燥特征l、舌体胖瘦指数i及bmi指数构建训练特征向量[pxi,pyi,t,m,l,i,bmi],利用训练特征向量[pxi,pyi,t,m,l,i,bmi]对预设的randomforest模型进行训练,利用网格调参法对randomforest模型进行优化;利用测试数据集对randomforest模型进行测试,直至输出训练好的最佳randomforest模型;利用最佳randomforest模型对待预测舌体图像进行预测,得到预测结果。进一步的,所述对训练数据集中的舌体图像样本进行特征提取,得到舌质舌苔颜色特征向量[pxi,pyi],具体为:利用lgbm模型将舌体图像样本中的像素点分为十类,其中舌质类像素点和舌苔类像素点各五类,舌质类像素点分别是:淡色舌质、淡红舌质、红色舌质、深红舌质和绛色舌质,舌苔类像素点分别是:白色舌苔、淡黄舌苔、深黄舌苔、棕黄舌苔和灰黑舌苔;设舌质类像素点数量分别为x1,...,xi,...,x5,舌苔类像素点数量分别为y1,...,yi,...,y5,分别计算各舌质类像素点占舌质类像素点总数的百分比pxi和各舌苔类像素点占舌苔类像素点总数的百分比pyi,计算式为:则舌质舌苔颜色特征向量为[pxi,pyi]。进一步的,所述对训练数据集中的舌体图像样本进行特征提取,得到舌苔厚薄特征向量[t,m],具体为:设舌体图像样本总像素点数量为n,对于其中任一个像素点pij,选取其5*5邻域,计算该邻域中舌质类像素点数量nij,根据nij的取值为像素点pij分配权重ωij:基于权重ωij计算舌体图像样本的苔厚指数t:然后计算舌体图像样本的苔质比m:基于苔厚指数t和苔质比m得到舌苔厚薄特征向量[t,m]。进一步的,所述对训练数据集中的舌体图像样本进行特征提取,得到舌体润燥特征l,具体为:将舌体图像样本分为10*10的区域,计算各区域平均亮度值in,取最大的平均亮度值作为全局阈值it;对舌体图像样本中所有大于全局阈值it的像素点进行八邻域生长,形成各亮斑区域;对各亮斑区域基于二分光反射原理进行分类,得到水分亮斑区,计算水分亮斑区的像素点总和l,舌体润燥特征即为l。进一步的,所述对各亮斑区域基于二分光反射原理进行分类,得到水分亮斑区,具体为:计算各亮斑区域像素点协方差矩阵的特征值λ1,λ2和λ3,确保λ1>λ2>λ3;计算对应于每个特征值λ1的特征向量v1,并对所有的特征向量v1进行归一化处理;设定阈值ε,取满足λ1>ε>λ2>λ3的亮斑区域的特征向量v1,近似估计光照方向;取满足λ1>λ2>ε>λ3和λ1>ε>λ2>λ3的亮斑区域,判断亮斑区域的特征向量v1是否与近似估计的光照方向接近,若是,则判断该亮斑区域为水分亮斑区。进一步的,所述取满足λ1>ε>λ2>λ3的亮斑区域的特征向量v1,近似估计光照方向,具体是将所选取的亮斑区域的特征向量v1的均值vmean设定为近似估计的光照方向。进一步的,所述对训练数据集中的舌体图像样本进行特征提取,得到舌体胖瘦指数i,具体为:将舌体图像样本转换为灰度图,在灰度图中提取舌体边缘点集合pedge,利用线性回归,将舌体边缘点集合中的边缘点拟合为四次曲线,则舌体胖瘦指数i的计算式为:其中,a0和a2分别为四次曲线的四次项系数和二次项系数,rl/w为舌体图像样本中舌体外接矩阵的长宽比,f为设定的长宽比阈值。进一步的,由于训练数据集中样本数量不均衡,为了保证randomforest模型的平衡,所述利用训练特征向量[pxi,pyi,t,m,l,i,bmi]对预设的randomforest模型进行训练之前,针对数量少的舌体图像样本进行上采样,向训练特征向量中的各特征添加扰动,构造新的舌体图像样本,使患病和未患病的舌体图像样本数量保持均衡。进一步的,所述利用网格调参法对randomforest模型进行优化,具体是采用f1分数作为网格调参得分方式并结合正则校验对randomforest模型进行优化。本发明的有益效果如下:1、本发明对舌体图像样本进行特征提取,然后利用提取到的舌质舌苔颜色特征向量[pxi,pyi]、舌苔厚薄特征向量[t,m]、舌体润燥特征l和舌体胖瘦指数i构建训练特征向量,通过训练特征向量训练randomforest模型,提高了脂肪肝预测效果和预测结果准确率,并且模型结构简单,占用资源较少。2、本发明的randomforest模型属于bagging算法,相较于基于boosting算法的分类模型,randomforest模型能更好的解决过拟合的干扰,并且运行速度相较于其他分类模型更具有优势,并且randomforest模型能较好地应对不均衡数据,使得模型分类效果更好。附图说明图1是本发明具体实施方式的方法流程示意图。具体实施方式为了本
技术领域:
的人员更好的理解本发明,下面结合附图和以下实施例对本发明作进一步详细描述。实施例1如图1所示,本实施例提供一种基于舌象特征和bmi指数的脂肪肝预测方法,包括:采集若干张患病和未患病的舌体图像样本及每张舌体图像样本对应的bmi指数,本实施例中采集舌体图像样本时,以三甲医院中相关领域的专家的诊断作为先验指导,同时结合传统中医诊断时望闻问切提取的信息,有针对性的选择提取舌体图像样本,将舌体图像样本随机分为训练数据集和测试数据集,并将每张舌体图像样本对应的bmi指数添加到对应的训练数据集和测试数据集中;对训练数据集中的舌体图像样本进行特征提取,得到舌质舌苔颜色特征向量[pxi,pyi]、舌苔厚薄特征向量[t,m]、舌体润燥特征l和舌体胖瘦指数i;其中,对训练数据集中的舌体图像样本进行特征提取,得到舌质舌苔颜色特征向量[pxi,pyi],具体为:利用lgbm模型将舌体图像样本中的像素点分为十类,其中舌质类像素点和舌苔类像素点各五类,舌质类像素点分别是:淡色舌质、淡红舌质、红色舌质、深红舌质和绛色舌质,舌苔类像素点分别是:白色舌苔、淡黄舌苔、深黄舌苔、棕黄舌苔和灰黑舌苔;设舌质类像素点数量分别为x1,...,xi,...,x5,舌苔类像素点数量分别为y1,...,yi,...,y5,分别计算各舌质类像素点占舌质类像素点总数的百分比pxi和各舌苔类像素点占舌苔类像素点总数的百分比pyi,计算式为:则舌质舌苔颜色特征向量为[pxi,pyi];对训练数据集中的舌体图像样本进行特征提取,得到舌苔厚薄特征向量[t,m],具体为:设舌体图像样本总像素点数量为n,对于其中任一个像素点pij,选取其5*5邻域,计算该邻域中舌质类像素点数量nij,则nij取值范围在0-25之间,nij越大,表示该像素点邻域内舌质越多,该像素点舌苔厚薄为薄的可能性较大,因此,按舌苔又薄到厚分为6个区间,根据nij的取值为像素点pij分配权重ωij:值得注意的是,上面仅是本实施例中邻域的选取、区间的划分和临界点取值的其中一种情况,根据不同的情境,可以划分为不同数量的区间,相应的,邻域的选取和临界点取值也可以有不同选择;基于权重ωij计算舌体图像样本的苔厚指数t:然后计算舌体图像样本的苔质比m:基于苔厚指数t和苔质比m得到舌苔厚薄特征向量[t,m];对训练数据集中的舌体图像样本进行特征提取,得到舌体润燥特征l,舌体润燥特征l的计算,基于二分光反射模型,即物体上任意一点的颜色是由面反射的亮斑色和体反射的本色线性组合而成的,计算过程具体为:将舌体图像样本转换至hls空间,然后分为10*10的区域,计算各区域平均亮度值in,取最大的平均亮度值作为全局阈值it;对舌体图像样本中所有大于全局阈值it的像素点进行八邻域生长,形成各亮斑区域;对各亮斑区域基于二分光反射原理进行分类,得到水分亮斑区,具体为:计算各亮斑区域像素点协方差矩阵的特征值λ1,λ2和λ3,确保λ1>λ2>λ3;计算对应于每个特征值λ1的特征向量v1,并对所有的特征向量v1进行归一化处理;设定阈值ε,取满足λ1>ε>λ2>λ3的亮斑区域的特征向量v1,将所选取的亮斑区域的特征向量v1的均值vmean设定为近似估计的光照方向;取满足λ1>λ2>ε>λ3和λ1>ε>λ2>λ3的亮斑区域,判断亮斑区域的特征向量v1是否与近似估计的光照方向接近,若是,则判断该亮斑区域为水分亮斑区;计算水分亮斑区的像素点总和l,舌体润燥特征即为l;对训练数据集中的舌体图像样本进行特征提取,得到舌体胖瘦指数i,具体为:将舌体图像样本转换为灰度图,在灰度图中提取舌体边缘点集合pedge,利用线性回归,将舌体边缘点集合中的边缘点拟合为四次曲线,则舌体胖瘦指数i的计算式为:其中,a0和a2分别为四次曲线的四次项系数和二次项系数,rl/w为舌体图像样本中舌体外接矩阵的长宽比,f为设定的长宽比阈值;基于舌质舌苔颜色特征向量[pxi,pyi]、舌苔厚薄特征向量[t,m]、舌体润燥特征l、舌体胖瘦指数i及bmi指数构建训练特征向量[pxi,pyi,t,m,l,i,bmi],利用训练特征向量[pxi,pyi,t,m,l,i,bmi]对预设的randomforest模型进行训练,利用网格调参法对randomforest模型进行优化,具体是采用f1分数作为网格调参得分方式并结合正则校验对randomforest模型进行优化;并且由于训练数据集中样本数量不均衡,为了保证randomforest模型的平衡,在利用训练特征向量[pxi,pyi,t,m,l,i,bmi]对预设的randomforest模型进行训练之前,针对数量少的舌体图像样本进行上采样,向训练特征向量中的各特征添加扰动,构造新的舌体图像样本,使患病和未患病的舌体图像样本数量保持均衡;最后利用测试数据集对randomforest模型进行测试,直至输出训练好的最佳randomforest模型,如表一所示,为在测试数据集上的预测结果:表一准确率敏感度特异性准确率优先78%88%68%敏感度优先68%96%40%特异性优先60%30%90%敏感度特异性均衡72%72%72%然后,便可以利用最佳randomforest模型对待预测舌体图像进行预测,得到预测结果。本实施例对舌体图像样本进行特征提取,然后利用提取到的舌质舌苔颜色特征向量[pxi,pyi]、舌苔厚薄特征向量[t,m]、舌体润燥特征l和舌体胖瘦指数i构建训练特征向量,通过训练特征向量训练randomforest模型,提高了脂肪肝预测效果和预测结果准确率,并且模型结构简单,占用资源较少。以上所述,仅为本发明的较佳实施例,并不用以限制本发明,本发明的专利保护范围以权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1