用于材料系统的设计优化和/或性能预测的数据驱动的表示和聚类离散化方法及系统及其应用
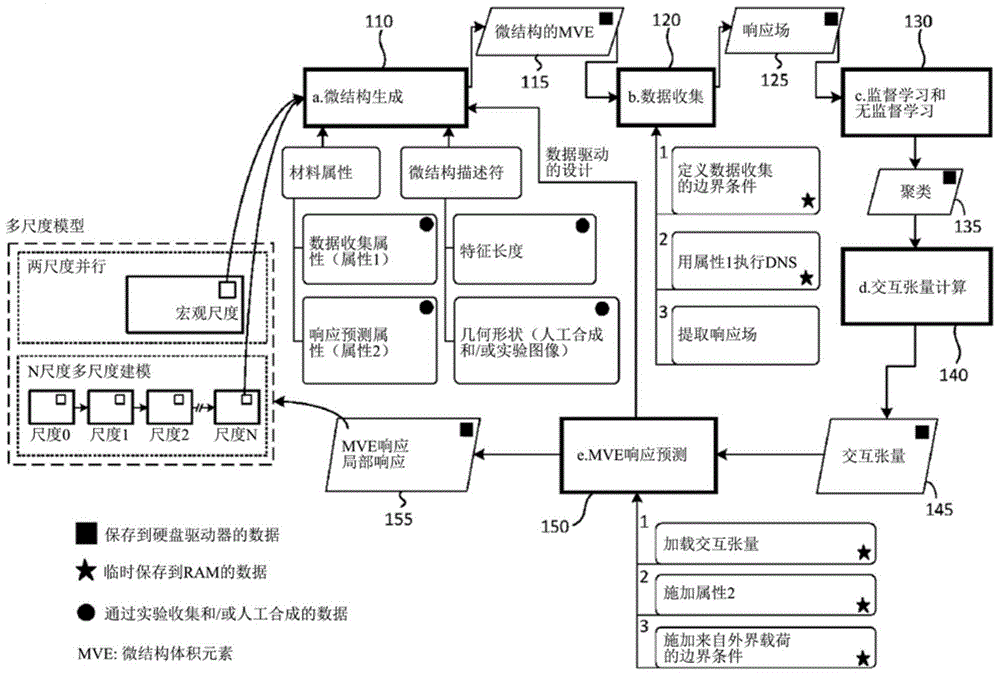
相关申请的交叉引用根据35u.s.c.§119(2),本申请要求wingkamliu、jiayinggao、chengyu和orionl.kafka于2018年9月14日提交的标题为“multiscalemodelingplatformandapplicationsofsame(多尺度建模平台及其应用)”的第62/731,381号美国临时专利申请的优先权和权益,其全部内容通过引用合并于此。本申请案涉及标题为“integratedprocess-structure-propertymodelingframeworksandmethodsfordesignoptimizationand/orperformancepredictionofmaterialsystemsandapplicationsofsame(用于材料系统的设计优化和/或预测的集成过程一结构-属性建模框架和方法及其应用)”的共同未决美国专利申请,该共同未决申请的代理人案卷号为0116936.152us2,由wingkamliu、jiayinggao、chengyu和orionl.kafka于提交本申请的同日提交并且受让人与本申请的受让人相同,其全部内容通过引用合并于此。本发明总体上涉及材料,并且更具体地,涉及一种集合非相似材料的几何形状、属性和相互作用以预测其组合的属性、性能和应用的特定方法和系统。
背景技术:
:本文提供的背景描述是为了总体上呈现本发明的上下文。在发明背景部分中讨论的主题不应当由于其仅仅在发明背景部分中提及而被认为是现有技术。类似地,在发明背景部分中提到的问题或与发明背景部分的主题相关联的问题不应被认为是现有技术中先前已经认识到的。发明背景部分的主题仅表示不同的方法。这些方法本身也可以是发明。对于本发明,当前提及的发明人在发明背景部分中所描述的范围内的工作以及在提交时可能无法以其他方式作为现有技术的说明书的各方面均未被明确或隐含地承认为现有技术。微观结构材料是各个分量的集合体。尽管存在许多近似值,但复杂材料的高保真建模通常涉及建立其微观结构的数值模型。在计算力学领域,通常使用高保真数值方法(例如有限元法(fem)、有限体积法(fvm)、快速傅立叶变换(fft)和无网格)对微观结构响应进行虚拟测试。这个过程通常需要在软件中为微观结构建立明确的网格,其中网格是微观结构的虚拟表示。这通常是空间分解,其中构成分解的离散单元的单元遵循特定规则(例如,对于fem为非负雅可比、在fft中为固定间隔网格)。尽管存在差异,但这些空间离散化仅称为“网格”。为了捕获微观结构的所有细节,网格通常需要非常精细的分辨率。如图2所示,基于空间的材料离散化类似于黎曼积分的概念。通常,由非常简单的纤维复合材料制成的细网格可包含数百万个单元。一旦构造了用于微观结构的网格,就可以将载荷施加到网格上以执行虚拟测试。可以从该虚拟测试中获得各种信息,例如材料的弹性属性、微观结构的有效强度以及用于研亢可能的微观结构故障的局部应力分布。但是,解析细网格需要大量的计算资源,例如高性能聚类计算或gpu计算,并且有限元软件的执行时间较长。对于微观结构体积单元(复杂材料微观结构的表示)或简称mve,在任何给定的尺度下,都可以使用传统数值法(例如有限元分析),当前尺度下的局部和均质化行为根据子尺度下均质化行为来计算。但是,计算时间与所有尺度上的单元总数成正比。每增加一个尺度都会增加难度。因此,如果mve包含许多单元-典型的mve可能包含o(1e6)个单元,则即使是简单的两尺度模型,计算时间也可能很长,而这将必须针对该较大尺度上的每个单元进行解决。这意味着成本很高。当用两个尺度的有限元完成时,有时称为“fe2”。由于成本的原因,这种方案的实际应用受到限制,并且几乎没有使用。因此,在本领域中存在解决上述缺陷和不足的迄今未解决的需求。技术实现要素:为了应对费时的微观结构仿真,本发明的目的之一是开发一种数据驱动的域分解方法,该方法适合于加速微观结构响应的数值仿真。一方面,本发明涉及一种用于材料系统的设计优化和/或性能预测的方法。在一个实施例中,所述方法包括:生成所述材料系统在多个尺度上的表示,其中,某一尺度上的所述表示包括在所述尺度上作为所述材料系统的构建块的微观结构体积单元(mve);收集根据预先定义的一组材料属性和边界条件由所述材料系统的材料模型计算出的所述mve的响应场数据;将机器学习应用于所收集的响应场数据,以生成聚类,所述聚类使每个聚类内的标称响应空间中的点之间的距离最小;计算每个聚类与每个其他聚类的相互作用的相互作用张量;使用格林函数操纵控制偏微分方程(pde),以形成广义的李普曼-施温格积分方程;以及使用所生成的聚类和所计算的相互作用对所述积分方程进行求解,以得出可用于所述材料系统的所述设计优化和/或性能预测的响应预测。在一个实施例中,所述方法还包括将所得到的响应预测传递到下一更粗尺度以作为所述构建块的总体响应,并且迭代所述过程直到达到最终尺度。在一个实施例中,所述构建块是通过材料属性和结构描述符来定义的,所述材料属性和结构描述符是通过建模或实验观察而获得的,并且被编码在结构的域分解中,以用于识别所述构建块中的每个相的位置和属性。在一个实施例中,所述结构描述符包括特征长度和几何形状。在一个实施例中,选择所述边界条件以满足希尔-曼德尔条件。在一个实施例中,所收集的响应场数据包括应变集中张量、变形集中张量、应力张量(例如,pk-i应力、柯西应力)、塑性应变张量、热梯度等。在一个实施例中,所述机器学习包括无监督机器学习和/或有监督机器学习。在一个实施例中,所述机器学习是利用自组织映射(som)法、k均值聚类法等来执行的。在一个实施例中,所述聚类是通过用唯一的id对所述材料系统的所述表示内具有相同响应场的所有材料点进行标记并对具有该同一id的材料点进行分组来生成的。在一个实施例中,所生成的聚类是所述材料系统的简化表示,所述简化表示减少了表示所述材料系统所需的自由度的数量。在一个实施例中,所生成的聚类是所述材料系统的降阶mve。在一个实施例中,所计算的相互作用张量是针对所有所述成对聚类的。在一个实施例中,所述计算所述相互作用张量是利用快速傅立叶变换(fft)、数值积分或有限元法(fem)来执行的。在一个实施例中,所述pde被重新构造为李普曼-施温格方程。在一个实施例中,所述求解所述pde是用任意边界条件和材料属性执行的。在一个实施例中,将所收集的响应场数据、所生成的聚类和/或所计算的相互作用张量保存在一个或多个材料系统数据库中。在一个实施例中,所述求解所述pde是通过访问用于所生成的聚类和所计算的相互作用张量的所述一个或多个材料系统数据库来实时地执行的。另一方面,本发明涉及一种用于材料系统的设计优化和/或性能预测的方法。在一个实施例中,所述方法包括:进行脱机数据压缩,其中,所述材料系统的构建块的原始mve被压缩为聚类,并计算每个聚类与每个其他聚类的相互作用的相互作用张量;以及使用所述聚类和所计算的相互作用对控制pde进行求解,以得出可用于所述材料系统的所述设计优化和/或性能预测的响应预测。在一个实施例中,所述方法还包括将所得到的响应预测传递到下一个更粗尺度以作为所述构建块的总体响应,并且迭代所述过程直到达到最终尺度。在一个实施例中,所述构建块是通过材料属性和结构描述符来定义的,所述材料属性和结构描述符是通过建模或实验观察而获得的,并且被编码在结构的域分解中,以用于识别所述构建块中每个相的位置和属性。在一个实施例中,所述结构描述符包括特征长度和几何形状。在一个实施例中,当降阶响应预测涉及一个以上尺度时,所述方法被称为多分辨率聚类分析(mca)。在一个实施例中,选择所述边界条件以满足希尔-曼德尔条件。在一个实施例中,所述进行所述脱机数据压缩包括:收集根据预先定义的一组材料属性和边界条件由所述材料系统的材料模型计算出的所述mve的响应场数据;将机器学习应用于所收集的响应场数据,以生成聚类,所述聚类使每个聚类内的标称响应空间中的点之间的距离最小;以及针对所有成对聚类来计算所述相互作用张量。在一个实施例中,所收集的响应场数据包括应变集中张量、变形集中张量、应力张量(例如,pk-i应力、柯西应力)、塑性应变张量、热梯度等。在一个实施例中,所述机器学习包括无监督机器学习和/或有监督机器学习。在一个实施例中,所述机器学习是利用som法、k均值聚类法等来执行的。在一个实施例中,所述聚类是通过用唯一的id对所述材料系统的所述表示内具有相同响应场的所有材料点进行标记并对具有该同一id的材料点进行分组来生成的。在一个实施例中,所述聚类是所述材料系统的简化表示,所述简化表示减少了表示所述材料系统所需的自由度的数量。在一个实施例中,所述聚类是所述材料系统的降阶mve。在一个实施例中,所述计算所述相互作用张量是利用fft、数值积分或fem来执行的。在一个实施例中,所述pde是李普曼-施温格方程。在一个实施例中,所述求解所述pde是利用任意边界条件和材料属性来执行的。在一个实施例中,所收集的响应场数据、所生成的聚类和/或所计算的相互作用张量被保存在一个或多个材料系统数据库中。在一个实施例中,所述求解所述pde是通过联机访问用于所生成的聚类和所计算的相互作用的所述一个或多个材料系统数据库来执行的。又一方面,本发明涉及一种存储指令的非暂时性有形计算机可读介质,所述指令在由一个或多个处理器执行时使系统执行以上公开的用于材料系统的设计优化和/或性能预测的方法。再一方面,本发明涉及一种用于材料系统的设计优化和/或性能预测的计算系统。在一个实施例中,该计算系统包括:一个或多个计算设备,其包括一个或多个处理器;以及存储指令的非暂时性有形计算机可读介质,所述指令在由所述一个或多个处理器执行时使所述一个或多个计算设备执行以上公开的用于材料系统的设计优化和/或性能预测的方法。一方面,本发明涉及一种可用于对材料系统进行高效准确多尺度建模的材料系统数据库。在一个实施例中,所述材料系统数据库包括:用于多个材料系统的聚类,每个聚类将相应材料系统的mve内的具有相同响应场的所有材料点用唯一的id进行分组;相互作用张量,每个相互作用张量表示所述相应材料系统的所有成对聚类的相互作用;以及基于所述聚类和所述相互作用张量计算的响应预测。在一个实施例中,所述聚类是通过将机器学习应用于根据预先定义的一组材料属性和边界条件由所述相应材料系统的材料模型计算出的所述mve的响应场数据来生成的。在一个实施例中,所述相互作用张量是利用fft、数值积分或fem来计算的。在一个实施例中,所述响应预测是通过使用所述聚类和所计算的相互作用求解控制pde来获得的。在一个实施例中,所述响应预测至少包括有效刚度、屈服强度、热导率、损坏开始和fip。在一个实施例中,所述材料系统数据库被构造为使得一些所述响应预测被分配为训练集,用于训练将过程/结构直接连接到所述材料系统的响应/属性的不同机器学习,而无需经历聚类和相互作用计算过程;剩余响应预测中的一些或全部被分配为验证集,用于验证所述材料系统的多尺度建模的效率和准确性。在一个实施例中,所述材料系统数据库是利用预测的降阶模型来生成的。在一个实施例中,所述预测的降阶模型包括自洽聚类分析(sca)模型、虚拟聚类分析(vca)模型和/或fem聚类分析(fca)模型。在一个实施例中,所述材料系统数据库是能够更新的、能够编辑的、能够访问的和能够搜索的。另一方面,本发明涉及一种将以上公开的材料系统数据库应用于材料系统的设计优化和/或性能预测的方法。在一个实施例中,所述方法包括:利用所述材料系统数据库的数据训练神经网络;以及在使用经过训练的神经网络执行的载荷过程中,预测所述材料系统的实时响应,其中,所述实时响应用于材料系统的设计优化和/或性能预测。在一个实施例中,所述方法还包括执行拓扑优化,以设计具有微观结构信息的结构。在一个实施例中,所述神经网络包括前馈神经网络(ffnn)和/或卷积神经网络(cnn)。另一方面,本发明涉及一种存储指令的非暂时性有形计算机可读介质,所述指令在由一个或多个处理器执行时使系统执行以上用于材料系统的设计优化和/或性能预测的方法。从下面结合附图对优选实施例的描述中,本发明的这些和其他方面将变得显而易见,尽管在不脱离本发明新颖概念的精神和范围的情况下,其中的变化和修改可能受到影响。附图说明以下附图构成本说明书的一部分,并且被包括在内以进一步说明本发明的某些方面。通过参考这些附图中的一个或多个附图,结合在此呈现的具体实施例的详细描述,可以更好地理解本发明。以下描述的附图仅用于说明目的。附图无意以任何方式限制本教导的范围。图1示意性地示出了通过根据本发明实施例的系统的数据的总体流程,其中,关键的是:加粗的框是操作,通常包括计算机代码;并且这些操作对包含在平行四边形中并且通常根据这些操作的实现方式存储在磁盘或内存中的各种数据起作用。在更复杂的操作中,列出了通常用于产生所需操作的信息或步骤;这些信息或步骤由带编号的圆角框示出。该系统以有限数量的尺度上的材料系统的表示开始。任何特定的尺度都由基本的构建块组成。构建块的大小由特征长度定义。构建块的组成是通过建模或实验观察来定义的。然后将它们编码为结构的详细空间分解(有时称为“网格”),用于描述构建块内每个相的位置和属性。这种高分辨率描述的生成被称为微观结构生成,并且可以与任何尺度有关。预定义的一组材料属性和边界条件(通常经过仔细选择和简化)被提供给直接数值求解器,以计算标称响应场。将无监督机器学习应用于这些场,以生成聚类,所述聚类使每个聚类内的标称响应空间中的点之间的距离最小。这就产生了材料构建块的简化表示。可以计算和存储每个聚类之间的相互作用(或施加到一个聚类的单位载荷对其他聚类的影响)。使用预先计算的聚类和相互作用,可以在响应预测阶段利用任意边界条件和材料属性(不一定是用于计算聚类的简化边界条件和材料属性)快速求解相关控制偏微分方程(pde)。响应预测的结果将传递到下一个更粗尺度,作为该构建块的总体响应,因此该过程将继续进行。图2示出了根据本发明实施例的通过分图(a)基于域的分解聚类和图(b)基于响应的分解聚类(例如用无监督学习)对偏微分方程进行离散化。图3示出了根据本发明实施例的具有两个或更多个可以通过该方法和系统来建模的相关长度尺度的示例材料系统。图4示出了包含3600万体素的单向碳纤维增强复合材料的mve模型。左侧的蓝色圆柱体表示碳纤维,红色的圆柱体是聚合环氧树脂基材料。在y方向上对施加的载荷的整体(均质化)响应在右上角绘制,局部应力等值线图在右下角绘制。使用80个计算机处理器来计算此单个载荷历史记录的直接数值仿真(dns)过程约需要200个小时。图5是使用传统的有限元法的两尺度多尺度问题及其复杂性的图示(顶图)。在宏观尺度上,示出了受某个边界条件影响的通用部分的网格。在这些单元内的每个材料点上,都将对与通用子尺度的行为相对应的微观尺度响应进行计算,在此示例中显示为球形夹杂物。底图是两尺度多尺度聚类法及其降阶能力的图示。在此图示中,每种颜色都表示1阶自由度,而不是顶部图示中的每个蓝色边界区域。图6示出了三步“训练”过程,作为计算宏观尺度几何形状(顶图)和微观尺度几何形状(底图)的聚类和相互作用张量的一种可能方式。图7示出了根据本发明实施例的三尺度frp建模框架。宏观尺度模型是编织层压复合材料模型,构建为有限元网格。宏观尺度模型中的每个积分点都由编织mve表示。该mve可以具有不同的丝束尺寸、丝束间距和丝束角度(所示为90°丝束角度)。介观尺度模型中的每个积分点都由udmve表示。该udmve可以具有不同的纤维方向、纤维体积分数和基质-纤维界面强度。如果使用fe网格将所有三个尺度离散化,则该全场系统的总dof(自由度)可能为3.3×1015。通过使用本发明的方法并用rom代替介观尺度和微观尺度,总dof减小到1.6×106,由此减小了9个数量级。图8示出了根据本发明实施例的从多个来源生成的mve。此金属材料示例示出了使用x射线衍射测量、根据统计描述重构并由处理模型预测的晶粒。在这种情况下,在测量或预测时,均会产生缺陷、空隙,这里以两种实验方法(x射线断层扫描和fib-sem连续切片)为例。这些输入数据被配对(在空间上),并用于mve,从而直接基于实验图像进行响应预测。图9示出了根据本发明实施例的基于多尺度聚类的过程。左图示出了udmve的原始dns描述。中图示出了基于聚类的描述(示出了纤维相中的2个聚类,基质中的8个聚类),在底层体素网格上可视化。右图示出了总应力/应变的数值均质化结果。dns参考解以红色显示,并具有5%的逐点误差条。参看具有8个聚类(蓝色)和16个聚类(绿色)的降阶解。图10示出了根据本发明实施例的物理指导的nn可以在mverom之上“分层”:nn在大型的快速计算行为数据库中训练。一旦经过训练,该nn被认为包含类似于rom的微观结构信息,但是评估起来要快得多。这种替代选择使进行基于微观结构的结构优化和设计变得切实可行。图11示出了根据本发明实施例的应用示例,即复合材料设计。可以将复合材料结构设计成具有不同的微观尺度结构(例如,纤维形状)和介观尺度结构(例如,每个层中的纤维定向、每个层中的纤维定向和纤维形状以及编织复合材料的不同编织图案)。可以预测复合材料结构的关键性能指标(例如,外部载荷下的强度和最大变形)。如果那些指标不符合所需标准,则将调用优化例程以更新微观尺度和介观尺度结构,从而改善性能指标。图12示出了根据本发明实施例的编织复合材料mve域分解。图13示出了根据本发明实施例的具有35个晶粒的随机晶粒结构,其中每个晶粒被认为是不同的材料相并进行逐晶粒应力预测,每个晶粒的聚类逐渐增多(如示例5中所讨论的)。图14是根据本发明实施例的介观尺度和微观尺度之间的分层建模以及宏观尺度和介观尺度之间的并发建模的一种实现方式的图示。udmve的弹性属性被预先计算并传递给纱线,从而构成了分层建模过程。当编织mve在外部载荷下时,使用纱线(由udmve给出)和基质属性来计算其响应。当有限元(fe)模型处于外部载荷下时,使用编织mve计算其局部响应。以并发方式计算fe模型响应和编织mve响应,从而建立并发建模方案。因此实现了组合的分层建模和并发建模。图15示出了根据本发明实施例的六个载荷方向的应力和应变曲线(编织物在xy平面上是各向同性的,因此yy响应与xx响应相同,xz响应与yz响应相同,参见分图(a)),如示例8所示;以及利用应力状态可视化的3d屈服面(洋红色星号,参见分图(b))。所有星号均表示不会导致材料屈服的应力状态。本方法使得人们能够毫不费力地(使用个人计算机约一分钟)构建用于各种微观结构的屈服面并产生材料本构信息。可以建立大型编织复合材料响应数据库,以帮助设计编织复合材料以防止屈服。如果给定关于最大服务载荷的先验信息,则该数据库将提供将防止屈服发生的所有可能的编织物微观结构(例如,纱线几何形状和纱线角)和材料成分(例如,基质属性和纱线属性)。图16示出了根据本发明实施例的两阶段聚类分析法的脱机阶段和联机阶段。脱机阶段包括三个步骤,如图所示,这将生成压缩的rve数据库。然后压缩的rve能够用于预测rve的机械响应。图17示出了用平面应变以2d表示的两相周期性复合材料的例如几何形状的问题,其中蓝色是连续的基质相,黄色表示夹杂物。图18示出了根据本发明实施例的彩色等值线图,其示出了夹杂物分(分图a)和基质分(分图b)中的聚类分布。请注意,聚类无需在空间上连接。图19示出了根据本发明实施例的的逐分量幅值图。对于所有三个相互作用张量表面图而言,沿对角线方向的尖峰表明,在逐聚类应力增量中,自相互作用比其余聚类具有更大的贡献。由于均质化参考材料的假设,和沿它们的对角线方向具有相似的大小。沿对角线方向相对于基质和夹杂物相具有不同的大小,隐式地表示非均质化参考材料。图20示出了根据本发明实施例的的图。请注意,对于fca而言,这两个区域对应于不同的物理域(基质和夹杂物)。图21示出了根据本发明实施例的和图。三种方法均表现良好,预测值值处于参考解的5%之内。图22示出了根据本发明实施例的和图。在这种情况下,sca最符合dns解,而vca和fca偏离了dns解。将来将对这种偏离的原因以及vca和fca的改进进行探讨。图23示出了根据本发明实施例的应变状态的随机样本;选择了200个最终状态,并记录了四个均匀间隔的中间步骤以达到最终状态,总共获得了nt=1,000个样本。所有应变状态都将施加于rve以生成相应的应力状态。图24是相关线性弹性示例的具有一个隐藏层(分图a)的ffnn网络的图示,用于连接输入层(绿色)、隐藏层(蓝色)和输出层(红色)的权重和偏差的集合函数是杨氏模量e的集合函数;以及应力-应变图(分图b),示出了ffnn如何使用线性激活函数和零偏差来解释线性弹性情况的输入应变。图25是具有多个隐藏层的ffnn的图示;nl表示层索引;nn(l)表示层l中的神经元数量。ffnn的公式在方程(1-21)中给出,具有ffnn结构的相关联解释。表示上一层和当前层中神经元id的索引i和j(例如)是层l=1中的神经元1和层l=2中的神经元2之间的权重。图26示出了根据本发明实施例的针对所有nv=150个样本的ffnnσm预测与验证数据集之间的差异的直方图。ffnn所作的大多数预测的l2范数小于2×10-5,表明了ffnn可以准确预测应力状态。图27示出了根据本发明实施例的针对x-、y-和剪切方向的sca和ffnn之间的互相关。黑色实线是基本实况,表明了所有完美的预测都应落于这些线上。ffnn预测的应力分量位于黑色实线周围,并且所有三种情况的相关系数均为1,表现出非常强的预测置信度。图28示出了根据本发明实施例的带有用于验证数据的ffnn和sca解的应力-应变图,表明了ffnn结果成功地再现了sca结果。图29示出了根据本发明实施例的具有以下设置的一维卷积神经网络的图示:填充、卷积、合并以及用于回归分析的前馈神经网络。前三个步骤可重复。图30示出了根据本发明实施例的二维卷积神经网络的图示。在训练部分中,阈值数量η*=5。在重复4次卷积之后,数据将被传递到ffnn。ffnn的输入维数变为nfl=74。ffnn中的隐藏层具有74个神经元。最后,ffnn给出了三个宏观应变分量。图31示出了根据本发明实施例的使用验证数据点的cnn预测的l2范数的直方图。cnn所做的大多数预测的l2范数小于1×10-5,表明了cnn可以准确预测应变状态。l2范数说明了cnn网络能够对验证数据做出正确的预测。图32示出根据本发明实施例的使用验证数据点的cnn所做的载荷预测以及在sca中施加的载荷。黑色实线是基本实况,表明了所有完美的预测都应落于这些线上。所有这三种情况的相关系数都高于0.99,这表明经过训练的cnn可以在预测施加应变时提供良好的准确性。图33示出了根据本发明实施例的具有ffnn的拓扑优化设置。ffnn将用于计算非线性材料响应以驱动新设计。通过这种方式,用宏观尺度中每个点的微观结构的均质化响应代替了通常用于宏观尺度的本构定律。数学上,如方程(1-36)所定义的,图34示出了根据本发明实施例的具有弹性材料响应(分图a)和非线性材料响应(分图b)的优化的束结构。比较分图a)和b),用于非线性情况的所有桁架构件的接合点都位于桁架结构的底侧。这意味着在这种情况下,材料非线性响应在确定优化的桁架结构中起着重要作用。图35示出了根据本发明实施例的具有ffnn和cnn的拓扑优化设置。对于设计区域内的每个材料点而言,考虑到微观结构的影响,使用ffnn来计算材料响应(线性还是非线性的)。使用cnn来合并微观结构损坏,与仅使用线性材料的拓扑优化相比,这将驱动新设计的优化算法。数学上,如方程(37)所定义的,如果在微观结构中任意d(x)被标记为已损坏,则包含该微观结构的设计区域中的xm点将被标记为已损坏。图36示出了根据本发明实施例的不带有损坏约束条件(分图a)和带有损坏约束条件(分图b)的优化的束结构。在分图(b)中,存在更多的桁架构件以避免局部应力集中而导致损坏(如示例1中所讨论的)。图37示出了根据本发明实施例的使用体素网格离散化的延展性材料的微观结构,其中蓝色表示基质,红色表示夹杂物:(分图a)示出了二维微观结构,(分图b)示出了三维微观结构的内部视图,其中碎裂的夹杂物由以浅灰色表示的脱粘空隙包围。图38示出了根据本发明实施例的延展性材料的微观结构:(分图a)示出了使用8个聚类离散化的二维微观结构,(分图b)示出了使用65个聚类离散化的相同二维微观结构,以及(分图c)示出了使用217个聚类离散化的三维微观结构,其中示出了基质相中的两个聚类(两个蓝色阴影),夹杂物相中的一个聚类(红色)和空隙相中的一个聚类(浅灰色)。图39示出了根据本发明实施例的(分图a):颗粒体积分数为20%的延展性复合材料;(分图b):针对rve在沿x方向的单向张力下的总体机械响应,sca快速收敛到fft参考系;(分图c):放大图(b)中的虚线矩形区域,可以看到只有16个聚类的sca的准确预测;(分图d):与100×100×100体素网格的fft参考系相比,使用sca可以相对较好收敛聚类数,从而使cpu时间节省了103倍以上。图40示出了根据本发明的实施例的(分图a):对于多孔rve在沿x方向的单轴张力下的整体机械响应,sca相当接近于fft参考系;(分图b):放大(分图a)中的虚线矩形区域,可以看到收敛速度相对较慢;(分图c):与使用100×100×100体素网格的fft参考系相比,使用sca可以相对较好收敛聚类数,从而使cpu时间节省了103倍以上。图41示出了根据本发明实施例的在脱粘的夹杂物中的聚类(红色阴影),其中示出了在碎裂之前(分图a)和在碎裂之后(分图b),其中丢失的聚类变成空隙。绘图方向为水平。图42示出了根据本发明实施例的冷拔和fip计算结果,示出了红色的颗粒碎片、浅灰色的空隙:(分图a)示出了未变形构造的基质中的等效塑性应变;(分图b)示出了位移重构后的变形构造的基质中的等效塑性应变;(分图c)示出了网格转移后变形构造的新体素网格上的基质中的fip。请注意,这三个图的空间尺度不同,原因是(分图b和c)中的剖面高度与(分图a)相比减少了45%。图43示出了根据本发明实施例的(分图a):颗粒体积分数为20%的延展性复合材料;(分图b):针对rve在沿x方向的单向张力下的总体机械响应,sca快速收敛到fft参考系;(分图c):放大分图(b)中的虚线矩形区域,可以看到只有16个聚类的sca的准确预测;(分图d):与使用100×100×100体素网格的fft参考系相比,使用sca可以相对较好收敛聚类数,从而使cpu时间节省了103倍以上。图44示出了根据本发明实施例的icme框架。图45示出了根据本发明实施例的环氧基质:(分图a)示出了拉应力与应变曲线;(分图b)示出了压缩应力-应变曲线。图46示出了根据本发明实施例的具有沿竖直方向定向的纤维的udcfrp板(约300mm×300mm),以及在水刀切割之后的带接片的试样。图47示出了根据本发明实施例的(分图a):具有l=120mm,w=12.7mm的试样上的斑点图案的视场;以及(分图b):用于数据分析的相关区域(彩色区域)。图48示出了根据本发明实施例的udcfrp帽形型材样本:(分图a)示出了几何形状;(分图b)示出了具有背板的样本;(分图c)示出了动态三点弯曲测试设置。图49示出了根据本发明实施例的udcfrp试件fe模型设置。在该设置中,根据本发明实施例,使用udrve计算每个积分点(标记为黑十字)处的材料响应。图50示出了根据本发明实施例的用于ud试件试样的数据库中的四个候选微观结构设置。根据本发明实施例,数据库被设计成使得用户可以根据他们的需求将各种微观结构分配给宏观尺度模型。该图中的“els”表示rve中的体素单元。图51示出了根据本发明实施例的udcfrp在宏观尺度下的横截面,在右侧示出了放大视图。图52示出了根据本发明实施例的用于使用蒙特卡洛法生成udrve的算法流程图。图53示出了根据本发明实施例的通过蒙特卡洛法生成的udrve。图54示出了根据本发明实施例的针对图50的设置1和2的udrve聚类过程。图55示出了根据本发明实施例的dns和rom的横向张力结果。dns结果(根据fem计算得出)具有误差条,表示95%的区间。根据sca计算得出的rom结果在该95%的区间内。图56示出了根据本发明实施例的udcfrp试件离轴拉伸仿真设置。图57示出了根据本发明实施例的udcfrp动态三点弯曲模型设置。图58示出了根据本发明实施例的ud试件的法向应力与法向应变。该比较表明预测与测试数据非常匹配。预测结果与实验结果之间的差异可能是由实际ud材料中的微观结构变化引起的。如示例4所述,所有材料定律严格地来自实验,没有任何校准参数。图59示出了根据本发明实施例的(分图a)y位移和(分图b)y应变场的等值线图。在预测和数字图像相关(dic)上施加的位移为0.9031mm。在位移分图a)中,两个黑色箭头测量条纹之间的竖直距离(从-0.250mm到-0.700mm),两者之差为3.95%。在灰度应变等值线图b)中,预测的应变场与dic相当。预测和dic图像之间的差异是由真实udcfrp材料中的微观结构变化引起的,这可能导致真实样本中的应变集中。图60示出了根据本发明实施例的(分图a)数值预测和(分图b)实验结果的试件裂纹形成。由于数值模型假设材料完美而没有微观结构变化,因此预测的图案会偏离测试结果。图61示出了根据本发明实施例的针对a)dy=1.40mm;b)dy=1.41mm;c)dy=1.42mm处的标记宏观尺度单元以及在d)dy=1.40mm;e)dy=1.41mm;f)dy=1.42mm处的局部udrve的试件局部微观结构的放大图。所有rve均以未变形的构造显示。图62示出了根据本发明实施例的在来自(分图a)预测(分图b)实验的撞击之后的ud帽形型材。侧壁上的损坏区域以黄色椭圆形标记。可以观察到,帽形型材在撞击时被向内推,并且撞击器将使帽形型材上产生凹痕。图63示出了根据本发明实施例的ud帽形型材网格,包括贯穿厚度方向上的三列单元的放大图。为了清楚起见,撞击器被隐藏起来。此设置示出了ud帽形型材网格中沿厚度方向的三列单元(每列12个单元,表示ud层压板的所有12层)的位置。每个单元由一个udrve表示,其纤维方向与给定的ud铺层相匹配。所有udrve均根据纤维方向进行颜色编码。图64示出了根据本发明实施例的在(分图a)撞击;(分图b)dz=4.85mm;和(分图c)dz=6.85mm处的帽形型材的冯·米塞斯应力等值线的等距视图。为了清楚起见,撞击器被隐藏起来。本icme框架能够实现结构级别响应和微观结构响应的可视化。在这种情况下,仅图63提到的那些单元被可视化。图65示出了根据本发明实施例的在(分图a)dz=5.91mm;(分图b)dz=6.13mm;和(分图c)dz=6.78mm处具有udcfrp微观结构演进的帽形型材的放大图。两个标记单元中的ud微观结构破坏过程被可视化。图66示出了根据本发明实施例的用于求解李普曼-施温格方程的sca流程图。图67示出了根据本发明实施例的基于弹性应变集中张量a(x)的多夹杂物系统的聚类结果。基质和夹杂物中的聚类数分别由km和ki表示。图68示出了根据本发明实施例的通过基于回归和基于投影的自洽方案预测的单轴张力和纯剪切载荷条件下的应力-应变曲线。实线表示dns结果以供比较。图69示出了根据本发明实施例的简单3d空隙几何形状的示意图。图70示出了根据本发明实施例的切掉一半的rve,其中示出了(分图a)弹性区域解和(分图b)夹杂物周围的所得聚类;(分图c)可塑性开始时的解和(分图d)所得聚类;和(分图e)充分发挥可塑性之后,(分图f)所得聚类。图71示出了根据本发明实施例的基于聚类的不同选择的单个夹杂物的总应力-应变响应。图72示出了根据本发明实施例的rve,其包括35个等轴的、随机定向的晶粒(如反极图颜色图所示),具有(a)20×20×20和(b)40×40×40个体素网格。图73示出了根据本发明实施例的分别使用cpfem和cpsca的和其中示出了具有网格尺寸和聚类数的收敛。图74示出了根据本发明实施例的六种不同情况下s33的体积图:(分图a)示出了具有cpfem的203网格;(分图b)示出了具有cpfem的303网格;(分图c)示出了具有cpfem聚类的403网格;(分图d)示出了具有35个聚类的403网格;(分图e)示出了具有70个聚类的403网格;以及(分图f)示出了具有140个聚类的403网格。在35个聚类的情况下,每个晶粒具有一个聚类,而在140个聚类的情况下,每个晶粒具有四个聚类。不透明度与应力水平成正比。图75示出了根据本发明实施例的未填充橡胶和填充橡胶的水平移位因子的温度依赖性,其中at、t和t0分别表示水平移位因子、温度和参考温度。图76示出了根据本发明实施例的未填充橡胶和填充橡胶的测量的剪切储能模量。图77示出了根据本发明实施例的未填充橡胶和填充橡胶的测量的剪切损失模量。图78示出了根据本发明实施例的填充橡胶的测量的损耗角正切值。填充橡胶的峰值小于未填充橡胶的峰值。低频区域的损耗角正切值高于未填充橡胶的损耗角正切值。图79示出了根据本发明实施例隐藏的橡胶基质材料。图80示出了与根据本发明实施例的实验结果相比的预测的填充橡胶的tan(δ)。图81示出了根据本发明实施例的fft与实验结果之间的(分图a)剪切储能模量g’和(分图b)剪切损失模量g”的比较。图82示出了根据本发明实施例的填充橡胶的脱机阶段和联机阶段。图83示出了根据本发明实施例的在基质相和填充相中的填充橡胶的聚类。用64个聚类表示将两相填充橡胶域分解为降阶模型。左图示出了两相填充橡胶的原始体素网格。右图示出了压缩的两相填充橡胶模型,其中基质相中有32个聚类,填充相中有32个聚类。图84示出了根据本发明实施例的由sca计算的填充橡胶的tan(δ)。图85示出了根据本发明实施例的(分图a)剪切储能模量g’图和(分图b)剪切损失模量g”图。图86示出了根据本发明实施例的具有9.74nm的中间相的填充橡胶和处于基质相、填充相和中间相的填充橡胶的聚类。三相填充橡胶域分解为以96个聚类表示的降阶模型。左图为用于三相填充橡胶的原始体素网格;右图为压缩的三相填充橡胶模型,其中基质相中有32个聚类,中间相中有32个聚类,填充相中有32个聚类。图87示出了根据本发明实施例的通过fft和sca预测的填充橡胶的主曲线与实验结果。图88示出了根据本发明实施例的填充橡胶的(分图a)预测的g’和(分图b)预测的g”与实验结果。图89示出了根据本发明实施例的计算方案的总体图。必须指定几何形状、构建过程参数、材料和载荷条件。这些参数用于进行热分析和宏观尺度应力分析。针对这两个模型中的每个材料点x,构造逐单元子模型以表示该点处的可能状态。这样,利用局部热历史和应变历史来分别确定微观结构(空隙几何形状)和变形历史。这些参数用于预测状态变量(例如可塑性和损坏)的微观尺度演进,这些状态变量被均质化(例如,通过取域的l∞范数进行均质化),并用作部件级故障易感性的逐单元估计器。图90示出了根据本发明实施例的缺陷估计和数据库构建过程的示意图。在第一部分中,使用过程建模和x射线计算机断层扫描来确定凝固冷却速率(scr)和空隙体积分数(vf)之间的关系。其次,2(a)示出了基于vf来选择使用x射线断层扫描获取的图像的子集,这样就可以跨越任意部分(具有已知或预测的热历史)的vf的预期范围;2(b)示出了生成这些可能的微观结构的数据库;2(c)示出了该数据库包括预先计算的相互作用张量,其包括降阶力学模型的训练阶段。图91示出了根据本发明实施例的针对每个宏观尺度的材料点(在这种情况下为:单元),热历史和应变历史被传递给微观尺度求解器;基于热历史从数据库中选择微观结构,并且根据应变历史来施加变形边界条件。计算基于晶体可塑性的微观尺度解,并且将均质化的响应(例如,如果选择了疲劳问题,则其为疲劳指示参数的l∞范数)返回到宏观尺度。图92示出了根据本发明实施例的(分图a)示例部件几何规格(astme606疲劳试样)、(分图b)两个网格和(分图c)试样网格的细节,包括应力(左)网格和热(右)网格之间的差异。图93示出了根据本发明实施例的连续半径疲劳测试试样,其示出了在构建过程中途的热处理预测。图94示出了根据本发明实施例的在不同的施加应变幅度下,在模拟实验条件下运行的疲劳试件的多个实现方式的估计疲劳寿命。对两个不同的处理条件(表6-2中的条件1和2)进行了建模。图95示出了根据本发明实施例的编织复合材料的从微观尺度到宏观尺度的多尺度特征。图96示出了根据本发明实施例的编织复合材料结构在三个尺度下的多尺度计算挑战;复杂性,以及微观结构。图97示出了根据本发明实施例的编织复合材料的sca方案。图98示出了根据本发明实施例的并发多尺度仿真框架。图99示出了根据本发明实施例的平纹编织复合材料的微观结构。图100示出了根据本发明实施例的udrve模型。图101示出了根据本发明实施例的具有256个聚类的基质的聚类过程和结果。尺寸在图99中给出。图102示出了根据本发明实施例的具有64个聚类的纱线的聚类过程和结果。对于每个纱线,首先根据局部定向进行聚类。使用应变集中am张量进一步细化所得聚类。图103示出了根据本发明实施例的由fem和sca给出的预测结果(sca-64-128指示基质中的64个聚类和纱线中的128个聚类)。图104示出了根据本发明实施例的由fem和sca给出的预测结果。图105示出了根据本发明实施例的希尔屈服面计算工作流程。相对于三个法向应力分量和三个剪切应力分量来绘制3d屈服面。针对相对于法向应力分量而绘制的图,示出了sigma_zz=0的横截面。针对相对于剪切应力分量而绘制的图,绘制了sigma_xy=0的横截面。图106示出了根据本发明实施例的针对不同rve大小的收敛性研亢。图107a示出了根据本发明实施例的t形钩状结构的几何形状和网格:几何形状和边界条件。图107b示出了根据本发明实施例的t形钩状结构的几何形状和网格:网格模型和降阶模型。图108示出了t形钩状结构的仿真结果。图109示出了根据本发明实施例的(分图a):晶体方向随机分配并且根据图109的(b)中的反极图着色的八个立方晶粒的理想化mve,其中晶粒1至8的欧拉角为(15.2、65.0、184.0)、(313.5、28.5、35.7)、(102.1、171.5、245.7)、(198.3、54.7、340.8)、(288.2、1.1、53.1)、(300.1、126.2、248.0)、(325.7、133.5、39.6)和(47.2、127.1、196.3);(分图b):反极(ipf)彩色图,示出了mve中的方向,以z面法线为参考方向,并在六边形密堆积单位晶格中示出了三个米勒指数;(分图c):使用fem计算的弹性应力分量e11,在x方向的单轴张力下总应变为0.02时具有纯弹性;(分图d):使用k均值聚类法从(分图c)中获得的128个聚类,每个晶粒具有16个聚类。图110示出了根据本发明实施例的(分图a):使用cpfem(黑色)、cpfft(红色)在不同网格下计算的宏观尺度应力-应变曲线;(分图b):(分图a)中虚线矩形的放大图示;(分图c):使用cpsca(蓝色)计算的宏观尺度应力-应变曲线,每个晶粒的聚类数均越来越多,其中示出了高保真cpfem和cpfft结果作为参考;(分图d):(分图c)中虚线矩形的放大图示。绿色阴影表示面积在参考解的5%内,红色表示在参考解的1%内。图111示出了根据本发明实施例的(分图a):0.2%偏移应力和0.4%偏移应力的误差作为每个晶粒所用的聚类数的函数;(分图b):与使用cpfem和cpfft相比,cpsca的cpu时间与每个晶粒的聚类(或体素)的数量。请注意,所有仿真都在intelhaswelle5-2680v32.5ghz处理器上运行。图112示出了根据本发明实施例的重构-计算-评估循环生成微观结构属性数据库的多种实现。图113示出了根据本发明实施例的具有约90个晶粒的示例性mve和相应的晶粒尺寸直方图。对晶粒进行采样:(分图a)无织构;(分图b)优选(0,0,0);(分图c)优选(90,0,0);(分图d)优选(90,90,0);所有这些都由z方向的反极着色。图114示出了根据本发明实施例的50个mve的预测应力-应变曲线,对每个mve进行采样:(分图a)无织构;(分图b)优选(0,0,0);(分图c)优选(90,45,0);(分图d)优选(90,90,0)。图115示出了不同织构情况下的预测有效杨氏模量(分图a)和0.2%偏移有效屈服强度(分图b)的分布图。根据本发明实施例,红线示出了均值和一个标准差扩展。图116示出了根据本发明实施例的平均晶粒尺寸增加的示例性mve,其中示出了(分图a)esd=13.2μm,(分图b)esd=19.7μm,(分图c)esd=26.6μm,(分图d)esd=35.9μm。晶粒通过ipf着色。图117示出了根据本发明实施例的不同的平均晶粒尺寸条件下的预测有效杨氏模量(分图a)和0.2%偏移屈服强度(分图b)的分布图。图118示出了根据本发明实施例的(分图a)轧制过程和(分图b)其并发多尺度仿真方法的示意图。给定该部分中每个材料点的变形梯度f0,可以通过求解多晶mve问题来获得第一皮奥拉-基尔霍夫应力p0。图119示出了根据本发明实施例的在变形构造上绘制的、轧制时间为0.08秒时的剪切应力分量σ12(单位:mpa)的等值线图,其用3d单元(a和b)和平面应变单元(c)进行仿真。3d仿真预测了在轧制方向上变形较小而极限剪切应力较高。图120示出了根据本发明实施例的图119的(分图c)中指示的三个单元的每个积分点的σ12的历史。靠近接触区域的单元的剪切应力值往往会交替出现更多次,并且幅度更大。图121示出了根据本发明实施例的与三个单元相关联的宏观尺度剪切应力等值线图和微观尺度等效塑性应变和(0001)极图的快照。远离接触表面时,相关的mve经历的旋转和剪切力较小,而压缩和塑性应变更大。图122示出了根据本发明实施例的在不同温度下以5×108s-1的应变速率变形的epon825的单轴张力(分图a)和压缩(分图b)应力-应变曲线。图123示出了根据本发明实施例的针对不同温度而获得的屈服面,其中,点是仿真数据,线是使用方程(9-1)的理论预测。图124示出了根据本发明实施例的通过使用环氧树脂3501-6作为模型系统的交联度和分量比率对应力-应变行为的影响。图125示出了根据本发明实施例的中间相属性表征。(分图a)为包括中间相区域(黄色)的横截面示意图。(分图b)示出了在中间相区域内的杨氏模量或强度的变化。图126示出了根据本发明实施例的预浸料在预成型过程中的变形机理。图127示出了根据本发明实施例的用于单轴张力和斜拉伸测试的实验设置。图128示出了根据本发明实施例的来自单轴张力测试的工程应变-应力曲线。图129示出了根据本发明实施例的针对不同试样尺寸的斜拉伸测试结果:(分图a)为原始载荷-位移曲线;(分图b)为归一化的载荷-位移曲线。图130示出了根据本发明实施例的针对(分图a)不同的温度和(分图b)不同的拉伸速率的斜拉伸测试结果。图131示出了根据(分图a)从dic获得的格林应变场和(分图b)中部区域的平均格林应变比较对斜拉伸测试的运动学假设的验证。图132示出了根据本发明实施例的(分图a)弯曲测试设置的示意图和(分图b)在50℃下的预浸料的形状。图133示出了根据本发明实施例的用于预浸料-预浸料相互作用测试设备的实验设置。图134示出了根据本发明实施例的相互作用测量实验设备的示意图。图135示出了根据本发明实施例的在70℃、5mm/s和0/90/0/90纤维定向的条件下从该测试中得到的力和相互作用因子。图136示出了根据本发明实施例的在0/90/0/90纤维取向下,在50℃、15mm/s的测试条件下,周期性变化的稳态相互作用因子。图137示出了根据本发明实施例的在各种温度下经受不同的(分图a)相对运动速度和(分图b)纤维取向的的相互作用和粘滑强度。图138是根据本发明实施例的通过(分图a)真实产品照片和(分图b)由软件texgen生成的模型的预浸料结构的图示。图139示出了根据本发明实施例的两个仿真的2×2斜纹织物界面的对称性和力。图140示出了根据本发明实施例的(分图a)在各种温度和10mm/s下的实验和数值相互作用因子的比较;(分图b)60℃和70℃的放大图示,以清楚地示出。图141示出了根据本发明实施例的在各种速度和60℃的温度下的实验和数值相互作用因子的比较。人为地将这些点随输入速度移开,以更好地区分数据。图142示出了根据本发明实施例的数值和实验数据的快速傅立叶变换(fft)结果。图143示出了根据本发明实施例的非正交材料模型中的应力分析。图144示出了根据本发明实施例的ls-dynamat_293的计算流程图。图145示出了根据本发明实施例的预浸料的厚度为1.2mm时的texgen粗糙几何模型:(分图a)示出了结构;(分图b)示出了相应网格的横截面。图146示出了根据本发明实施例的在fe软件abaqus中的预浸料rve压缩:引入了两个刚性板以调节rve厚度。图147是根据本发明实施例的沿宽度方向压缩时的纱线横截面变形的图示:(分图a)示出了真实材料变形模式;(分图b)示出了具有横向各向同性材料模型的fe变形模式;(分图c)示出了在fe中具有解耦的材料模型的变形模式。图148示出了根据本发明实施例的一个斜拉伸rve仿真示例:(分图a)为rve上的冯·米塞斯应力等值线图的图示;(分图b)示出了仿真剪切应力和实验真实剪切应力的比较。图149示出了根据本发明实施例的模块化贝叶斯校准:该方法具有四个阶段,并且能够估计潜在的仿真器偏差以及校准参数的联合后验分布。图150示出了根据本发明实施例的在校准参数上的边缘后验分布:后验和先验分别用实心蓝色和虚线红色表示。图151示出了根据本发明实施例的响应的后验均值:(分图a)示出了针对两个不同的剪切角,法向应力为沿纱线的法向真实应变的函数;(分图b)示出了针对两个不同的织物剪切角,剪切应力为沿纱线的法向真实应变的函数;(分图c)示出了用于校准的单轴张力测试与我们的预测;(分图d)示出了未在校准中使用的斜拉伸测试与我们的预测。图152示出了根据本发明实施例的开发的多尺度预成型仿真方法的流程图:贝叶斯校准利用rve和实验来获得纱线属性和介观尺度应力仿真器。然后将应力仿真器实现到非正交材料模型中,以进行宏观尺度的预制成型仿真。图153示出了根据本发明实施例的cfrp中的不同尺度的示意图。图154示出了根据本发明实施例的单向ud横截面的显微镜图像。图155示出了根据本发明实施例的udrye等距视图,其中黑色为纤维,灰色为基质。图156示出了根据本发明实施例的编织rve几何形状。图157示出了根据本发明实施例的纱线中的纱线角、纱线纤维体积分数和纤维错位的图示。图158示出了根据本发明实施例的纱线角对编织物刚度基质的分量的影响。图159示出了根据本发明实施例的纤维相和基质相中的聚类的图示。图160示出了根据本发明实施例的ud并发多尺度建模的示意图。图161示出了根据本发明实施例的(分图a)ud试件建模几何形状和(分图b)边界条件。图162示出了根据本发明实施例的a)在裂纹形成之前和b)在裂纹形成之后的试件模型的冯·米塞斯应力等值线图和局部rve。图163示出了根据本发明实施例的(分图a)ud帽形型材碰撞模型的设置;(分图b)撞击力与时间。图164示出了根据本发明实施例的ud动态3-pt弯曲的并发仿真的示意图。图165示出了根据本发明实施例的三尺度并发多尺度建模设置。图166示出了根据本发明实施例的在并发多尺度建模中的编织物rve的几何形状。图167示出了根据本发明实施例的三尺度和两尺度单单元简单剪切的工程剪切应力与工程剪切应变。图168示出了根据本发明实施例的编织物斜拉伸测试装置。图169示出了根据本发明实施例的(分图a)编织物斜样本σ22的等值线图,其中在顶部接片上施加了0.4mm的位移;(分图b)并发双轴张力和三组测试数据的σ22与ε22曲线。图170示出了根据本发明实施例的具有聚合物基质的四尺度编织纤维复合材料的多尺度结构示意图。在此结构的计算建模中,任何尺度下的每个积分点都是下一个更精细尺度的结构的实现。图171示出了根据本发明实施例的我们用于两尺度结构的方法的演示:空间随机过程(srp)用于生成通过自上而下的采样过程连接的空间变化。图172示出了根据本发明实施例的在我们的工作中研亢的宏观固化的编织层压结构。(分图a)示出了变形的结构,其中浅蓝色线指示纤维取向,并且按比例缩放尺寸以更清楚地表示;(分图b)示出了通过仿真完美制造的复合材料而获得的纱线角的确定性空间变化;(分图c)示出了与实例9相对应的冯·米塞斯应力场;(分图d)示出了与实例1的实现之一相对应的纱线角的随机空间变化;(分图e)示出了与实例3的实现之一相对应的的随机空间变化。图173示出了根据本发明实施例的纤维错位角。天顶角和方位角表征了纤维相对于纱线横截面上的局部正交框架的错位角。图174示出了根据本发明实施例的不确定性源的跨尺度耦合:宏观尺度上的v和θ的空间变化被连接至更精细尺度上的空间变化。为简洁起见,仅示出了两个量的平均值的耦合(即,rf的平均值:图175示出了根据本发明实施例的平均值对编织rve的有效模量的影响:(分图a)示出了纤维体积分数的影响;(分图b)示出了错位的影响。这些图上的每个点都表示20次仿真的平均值。表9-17中定义了(分图b)中的实例id。参考解是指不存在错位的情况。图176示出了根据本发明实施例的作为训练样本数量的函数的预测误差:随着训练样本数量的增加,mrgp元模型在预测介观尺度的编织rve的刚度基质的单元时的准确性增加。图177示出了根据本发明实施例的图形用户界面的屏幕截图:(分图a)示出了最佳拉丁超立方体采样用户界面;(分图b)示出了高斯过程建模用户界面。图178示出了根据本发明实施例的宏观结构对空间变化的整体和局部响应:(分图a)示出了反作用力;(分图b)示出了中段的平均应力;(分图c)示出了中段的应力场的标准偏差。对于分图(b)和(c)中的实例1至实例8,曲线基于20个独立的仿真。图179示出了根据本发明实施例的(分图a)典型的纤维体积分数(vf)的等值线图,其中黄色表示高vf(约0.6),蓝色表示低vf(约0.4);(分图b)利用分割线的位置来表示非平稳性。图180示出了根据本发明实施例的(分图a)3个样本的线间距离的概率密度估计;(分图b)3批样本(每批包含10个样本)的概率密度估计。图181示出了根据本发明实施例的重构的两个示例。图182示出了根据本发明实施例的分段线性回归过程。图183示出了根据本发明实施例的通过所提出的方法发现的局部波度的图示。图184示出了根据本发明实施例的较大图像的纤维波度表征。图185示出了根据本发明实施例的一些重构及其对应的周期图。图186示出了根据本发明实施例的双圆顶冲头和粘合剂的几何形状。图187示出了根据本发明实施例的双圆顶预成型测试设置:(分图a)示出了用于预成型的压机;(分图b)示出了预浸料的温度历程图。该历程图表明,将预浸料放在压机下时,其温度从最初的70℃迅速下降至约23℃。图188示出了根据本发明实施例的双圆顶预成型仿真设置。图189示出了根据本发明实施例的±45°单层编织预浸料的双圆顶预成型部分的变形几何形状和纱线角分布的仿真和实验结果比较。图190示出了根据本发明实施例的预成型仿真:(分图a)示出了最终部分的形状和纱线角分布;(分图b)示出了冲压力比较。在分图(a)中,a-e点表示纱线角测量位置。图191示出了根据本发明实施例的具有不同的初始预浸料层取向的双圆顶比较:(分图a)0/90;(分图b)-45/+45;和(分图c)0/90/-45/+45。仿真结果显示在上半部分,而实验结果显示在下半部分。实验结果上的银线表示经纱和纬纱的方向。图192示出了根据本发明实施例的双圆顶经纬纱角度分布结果:(分图a)示出了0/90预浸料层上的采样点;(分图b)示出了-45/+45采样点上的采样点;(分图c)示出了针对单层0/90纤维取向预成型的角度比较;(分图d)示出了针对单层-45/+45纤维取向预成型的角度比较;(分图e)示出了针对0/90/-45/+45双层预成型中的0/90纤维取向层的角度比较;(分图f)示出了针对0/90/-45/+45双层预成型中的-45/+45纤维取向层的角度比较。图193示出了根据本发明实施例的在低温预成型之后尤其在边缘处的预浸料的折叠。具体实施方式现在将在下文中参考附图更全面地描述本发明,在附图中示出了本发明的示例性实施例。然而,本发明可以以许多不同的形式来实施,并且不应被解释为限于在此阐述的实施例。而是,提供这些实施例使得本公开将是彻底和完整的,并将向本领域技术人员充分传达本发明的范围。贯穿全文,相似的参考标号指代相似的单元。在本发明的上下文中,以及在使用每个术语的特定上下文中,本说明书中使用的术语通常具有它们在本领域中的普通含义。在下文或说明书的其他地方讨论了用于描述本发明的某些术语,从而为从业人员提供有关本发明描述的附加指导。为方便起见,某些术语可能会突出显示,例如使用斜体和/或引号。突出显示和/或大写字母的使用对术语的范围和含义没有影响;术语的范围和含义在相同的上下文中是相同的,无论是否突出显示和/或以大写字母表示。应当理解,可以以一种以上的方式阐述同一件事。因此,替代的语言和同义词可以用于本文讨论的任何一个或多个术语,关于是否在此阐述或讨论术语也没有任何特殊的意义。提供了某些术语的同义词。一个或多个同义词的陈述不排除使用其他同义词。在本说明书中任何地方使用的示例(包括本文讨论的任何术语的示例)仅是示例性的,绝不限制本发明或任何示例性术语的范围和含义。同样,本发明不限于本说明书中给出的各种实施例。将理解的是,尽管在本文中可以使用术语第一、第二、第三等来描述各种单元、组件、区域、层和/或部分,但是这些单元、组件、区域、层和/或部分不应受这些术语的限制。这些术语仅用于区分一个单元、组件、区域、层或部分与另一单元、组件、区域、层或部分。因此,在不脱离本发明的教导的情况下,下面讨论的第一单元、组件、区域、层或部分可以被称为第二单元、组件、区域、层或部分。将理解的是,如本文的说明书和所附的权利要求书中所使用的,除非上下文另外明确指出,否则“一个(a)”、“一种(an)”和“该(the)”的含义包括复数形式。同样,将理解的是,当一个单元被称为在另一单元“上”、与其“附接”、“连接”、“耦合”、“接触”等时,它可以直接在另一单元上、与其附接、连接、耦合或接触或者还可以存在中间单元。相反,当单元被称为例如“直接在”另一单元“上”、与其“直接附接”、“直接连接”、“直接耦合”或“直接接触”时,则不存在中间单元。本领域技术人员还将理解,提及与另一特征“相邻”设置的结构或特征可以具有与相邻特征重叠或位于相邻特征之下的部分。还将理解的是,当在本说明书中使用时,术语“包括(comprises)”和/或“包括(comprising)”或“包含(includes)”和/或“包括(including)”或“具有(has)”和/或“具有(having)”指定存在所述特征、区域、整数、步骤、操作、单元和/或组件,但不排除一个或多个其他特征、区域、整数、步骤,操作、单元、组件和/或其组的存在或添加。此外,相对术语(例如“下”或“底”和“上”或“顶”)在本文中可用于描述一个单元与另一单元的关系,如图中所示。将理解的是,除了附图中所示的定向之外,相对术语旨在涵盖装置的不同定向。例如,如果附图之一中的装置被翻转,则被描述为在其他单元的“下”侧的单元将被定向在其他单元的“上”侧。因此,根据附图的特定方向,示例性术语“下”可以包括下和上两个方向。类似地,如果将其中一个附图中的装置翻转,则描述为在其他单元“下方”或“之下”的单元将被定向为在其他单元“之上”。因此,示例性术语“下方”或“之下”可以涵盖上方和下方两个方位。除非另有定义,否则本文中使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域的普通技术人员通常所理解的相同含义。还将理解的是,诸如在常用词典中定义的那些术语应被解释为具有与它们在相关领域和本公开的上下文中的含义一致的含义,并且将不以理想化或过于正式的意义进行解释,除非在此明确定义。如本公开中所使用的,“约(around)”、“大约(about)”、“近似(approximately)”或“基本上(substantially)”应通常是指给定值或范围的百分之二十以内、优选地为百分之十以内并且更优选地为百分之五以内。这里给出的数值是近似的,意味着如果没有明确说明,则可以推断出术语“约(around)”、“大约(about)”、“近似(approximately)”或“基本上(substantially)”。如本公开中所使用的,短语“a、b和c中的至少一个”应被解释为表示使用非排他性逻辑or表示逻辑(a或b或c)。如本文所使用的,术语“和/或”包括一个或多个相关联的所列项目的任何和所有组合。将在以下详细描述中描述方法和系统,并通过各种框、组件、电路、过程、算法等(统称为“构件”)在附图中示出该方法和系统。这些构件可以使用电子硬件、计算机软件或其任意组合来实现。将这些单元实现为硬件还是软件取决于特定的应用和施加在整个系统上的设计约束条件。举例来说,构件或构件的任何部分或构件的任何组合可以被实现为包括一个或多个处理器的“处理系统”。处理器的示例包括微处理器、微控制器、图形处理单元(gpu)、中央处理器(cpu)、应用处理器、数字信号处理器(dsp)、精简指令集计算(risc)处理器、片上系统(soc)、基带处理器、现场可编程门阵列(fpga)、可编程逻辑器件(pld)、状态机、门控逻辑、分立硬件电路以及其他合适的硬件,这些硬件被构造为执行本公开中描述的各种功能。处理系统中的一个或多个处理器可以执行软件。软件应广义地解释为指指令、指令集、代码、代码段、程序代码、程序、子程序、软件组件、应用程序、软件应用程序、软件包、例程、子例程、对象、可执行文件、执行线程、过程、函数等等,无论是被称为软件、固件、中间件、微码、硬件描述语言还是其他形式。因此,在一个或多个示例性实施例中,可以以硬件、软件或其任何组合来实现所描述的功能。如果以软件实现,则功能可以被存储在计算机可读介质上或作为一个或多个指令或代码被编码在计算机可读介质上。计算机可读介质包括计算机存储介质。存储介质可以是计算机可以访问的任何可用介质。作为示例而非限制,这种计算机可读介质可以包括随机存取存储器(ram)、只读存储器、电可擦可编程只读存储器(eeprom)、光盘存储器、磁盘存储器、其他磁存储设备、上述类型的计算机可读介质的组合或任何其他可用于以可由计算机访问的指令或数据结构的形式存储计算机可执行代码的介质。以下描述本质上仅是说明性的,绝不旨在限制本发明、其应用或用途。本发明的广泛教导可以以多种形式实现。因此,尽管本发明包括特定的示例,但是本发明的真实范围不应受到如此限制,因为在研亢附图、说明书和所附权利要求书后,其他修改将变得显而易见。为了清楚起见,在附图中将使用相同的附图标记来标识相似的单元。应当理解,在不改变本发明的原理的情况下,可以以不同的顺序(或同时)执行方法中的一个或多个步骤。微观结构材料是各个分量的集合体。在多分量材料中,被视为材料构建块的分量会集合或自组装,以形成多个尺度的复杂结构或构象。多尺度建模方法试图忠实地捕获在若干长度和时间尺度上出现的复杂行为。本发明的目的之一是提供数据驱动的表示和聚类离散化方法和系统,这是一种数据驱动的域分解方法,适合于加速微观结构响应的数值仿真。这里的概念类似于图2所示的勒贝格积分,这取决于对附近响应(y轴)进行分组,而不是对用于黎曼积分的附近域(x轴)进行分组。这种分解方法显著降低了问题的整体计算复杂性,尤其是在多尺度分析中。在本发明的一方面,一种用于材料系统的设计优化和/或性能预测的方法包括:生成所述材料系统在多个尺度上的表示,其中,某一尺度上的所述表示包括在所述尺度上作为所述材料系统的构建块的微观结构体积单元(mve);收集根据预先定义的一组材料属性和边界条件由所述材料系统的材料模型计算出的所述mve的响应场数据;将机器学习应用于所收集的响应场数据,以生成聚类,所述聚类使每个聚类内的标称响应空间中的点之间的距离最小;计算每个聚类与每个其他聚类的相互作用的相互作用张量;以及使用所生成的聚类和所计算的相互作用对控制偏微分方程(pde)进行求解,以得出可用于所述材料系统的所述设计优化和/或性能预测的响应预测。在一个实施例中,所述方法还包括将所得到的响应预测传递到下一更粗尺度以作为所述构建块的总体响应,并且迭代所述过程直到达到最终尺度。在一个实施例中,所述构建块是通过材料属性和结构描述符来定义的,所述材料属性和结构描述符是通过建模或实验观察而获得的,并且被编码在结构的域分解中,以用于识别所述构建块中的每个相的位置和属性。在一个实施例中,所述结构描述符包括特征长度和几何形状。在一个实施例中,选择所述边界条件以满足希尔-曼德尔条件。在一个实施例中,所收集的响应场数据包括应变集中张量、变形集中张量、应力张量(例如,pk-i应力、柯西应力)、塑性应变张量、热梯度等。在一个实施例中,所述机器学习包括无监督机器学习和/或有监督机器学习。在一个实施例中,所述机器学习是利用自组织映射(som)法、k均值聚类法等来执行的。在一个实施例中,所述聚类是通过用唯一的id对所述材料系统的所述表示内具有相同响应场的所有材料点进行标记并对具有所述同一id的材料点进行分组来生成的。在一个实施例中,所生成的聚类是所述材料系统的简化表示,所述简化表示减少了表示所述材料系统所需的自由度的数量。在一个实施例中,所生成的聚类是所述材料系统的降阶mve。在一个实施例中,所计算的相互作用张量是针对所有所述成对聚类的。在一个实施例中,所述计算所述相互作用张量是利用快速傅立叶变换(fft)、数值积分或有限元法(fem)来执行的。在一个实施例中,所述pde是李普曼-施温格方程。在一个实施例中,所述求解所述pde是利用任意边界条件和/或材料属性来执行的。在一个实施例中,将所收集的响应场数据、所生成的聚类和/或所计算的相互作用张量保存在一个或多个材料系统数据库中。在一个实施例中,所述求解所述pde是通过访问用于所生成的聚类和所计算的相互作用张量的所述一个或多个材料系统数据库来实时地执行的。在本发明的另一方面,一种用于材料系统的设计优化和/或性能预测的方法包括:进行脱机数据压缩,其中,所述材料系统的构建块的原始微观结构体积单元(mve)被压缩为聚类,并计算每个聚类与每个其他聚类的相互作用的相互作用张量;以及使用所述聚类和所计算的相互作用对控制pde进行求解,以得出可用于所述材料系统的所述设计优化和/或性能预测的响应预测。在一个实施例中,所述方法还包括将所得到的响应预测传递到下一个更粗尺度以作为所述构建块的总体响应,并且迭代所述过程直到达到最终尺度。在一个实施例中,所述构建块是通过材料属性和结构描述符来定义的,所述材料属性和结构描述符是通过建模或实验观察而获得的,并且被编码在结构的域分解中,以用于识别所述构建块中每个相的位置和属性。在一个实施例中,所述结构描述符包括特征长度和几何形状。在一个实施例中,当降阶响应预测涉及一个以上尺度时,所述方法被称为多分辨率聚类分析(mca)。在一个实施例中,选择所述边界条件以满足希尔-曼德尔条件。在一个实施例中,所述执行所述脱机数据压缩包括:收集根据预先定义的一组材料属性和边界条件由所述材料系统的材料模型计算出的所述mve的响应场数据;将机器学习应用于所收集的响应场数据,以生成聚类,所述聚类使每个聚类内的标称响应空间中的点之间的距离最小;以及针对所有成对聚类来计算所述相互作用张量。在一个实施例中,所收集的响应场数据包括应变集中张量、变形集中张量、应力张量(例如,pk-i应力、柯西应力)、塑性应变张量、热梯度等。在一个实施例中,所述机器学习包括无监督机器学习和/或有监督机器学习。在一个实施例中,所述机器学习是利用som法、k均值聚类法等来执行的。在一个实施例中,所述聚类是通过用唯一的id对所述材料系统的所述表示内具有相同响应场的所有材料点进行标记并对具有所述同一id的材料点进行分组来生成的。在一个实施例中,所述聚类是所述材料系统的简化表示,所述简化表示减少了表示所述材料系统所需的自由度的数量。在一个实施例中,所述聚类为所述材料系统的降阶mve。在一个实施例中,所述计算所述相互作用张量是利用fft、数值积分或fem来执行的。在一个实施例中,所述pde是李普曼-施温格方程。在一个实施例中,所述求解所述pde是利用任意边界条件和材料属性来执行的。在一个实施例中,所收集的响应场数据、所生成的聚类和/或所计算的相互作用张量被保存在一个或多个材料系统数据库中。在一个实施例中,所述求解所述pde是通过联机访问用于所生成的聚类和所计算的相互作用的所述一个或多个材料系统数据库来执行的。另一方面,本发明涉及一种可用于对材料系统进行高效准确多尺度建模的材料系统数据库。在一个实施例中,所述材料系统数据库包括:用于多个材料系统的聚类,每个聚类将相应材料系统的mve内具有相同响应场的所有材料点用唯一的id进行分组;相互作用张量,每个相互作用张量表示所述相应材料系统的所有成对聚类的相互作用;以及基于所述聚类和所述相互作用张量计算的响应预测。在一个实施例中,所述聚类是通过将机器学习应用于根据预先定义的一组材料属性和边界条件由所述相应材料系统的材料模型计算出的所述mve的响应场数据来生成的。在一个实施例中,所述相互作用张量是利用fft、数值积分或fem来计算的。在一个实施例中,所述响应预测是通过使用所述聚类和所计算的相互作用求解控制pde来获得的。在一个实施例中,所述响应预测至少包括有效刚度、屈服强度、热导率、损坏开始和fip。在一个实施例中,所述材料系统数据库被构造为使得一些所述响应预测被分配为训练集,用于训练将过程/结构直接连接到所述材料系统的响应/属性的不同机器学习,而无需经历聚类和相互作用计算过程;剩余响应预测中的一些或全部被分配为验证集,用于验证所述材料系统的多尺度建模的效率和准确性。在一个实施例中,所述材料系统数据库是利用预测的降阶模型来生成的。在一个实施例中,所述预测的降阶模型包括自洽聚类分析(sca)模型、虚拟聚类分析(vca)模型和/或fem聚类分析(fca)模型。在一个实施例中,所述材料系统数据库是能够更新的、能够编辑的、能够访问的和能够搜索的。又一方面,本发明涉及一种将以上公开的材料系统数据库应用于材料系统的设计优化和/或性能预测的方法。在一个实施例中,所述方法包括:利用所述材料系统数据库的数据训练神经网络;以及在使用经过训练的神经网络执行的载荷过程中,预测实时响应,其中,所述实时响应用于材料系统的设计优化和/或性能预测。在一个实施例中,所述方法还包括执行拓扑优化,以设计具有微观结构信息的结构。在一个实施例中,所述神经网络包括前馈神经网络(ffnn)和/或卷积神经网络(cnn)。又一方面,本发明涉及一种存储指令的非暂时性有形计算机可读介质,所述指令在由一个或多个处理器执行时使系统执行以上公开的用于材料系统的设计优化和/或性能预测的方法。另一方面,本发明涉及一种用于材料系统的设计优化和/或性能预测的计算系统。在一个实施例中,该计算系统包括:一个或多个计算设备,其包括一个或多个处理器;以及存储指令的非暂时性有形计算机可读介质,所述指令在由所述一个或多个处理器执行时使所述一个或多个计算设备执行以上公开的用于材料系统的设计优化和/或性能预测的方法。下面简要介绍本发明的方法和系统的优点和特殊应用,而在本节后面的示例1-9中将详细讨论它们的细节。已经开发出一种用于构建微观结构材料数据库以进行源于快速微观结构的响应预测的方法。该方法获取材料数据并使用无监督机器学习对其进行压缩,以创建“聚类离散化”,实际上是一种特殊设计的数据库,该数据库适合于对任意材料系统进行高效且准确的多尺度建模。由于此处描述的方法依赖于捕获和组合材料的基本构建块及其响应,因此可以对任何复杂和/或分层的材料系统进行准确且高效的建模,因此该方法是与材料无关的。在此描述的方法也可以适用于对许多具有相似的基本数学描述的物理现象的预测。尽管提供的示例与承受机械载荷的固体的材料性能有关,但这不应被视为基本限制。该方法可以很好地用于预测一系列有效的物理学属性(包括但不限于电属性和磁属性)。实际上,该方法可用于解决任意计算均化问题或涉及偏微分方程解的问题。图1示意性地示出了通过根据本发明实施例的系统的数据的总体流程,其中,加粗的框(例如110、120、130、140、150)是操作,通常包括计算机代码;并且这些操作对包含在平行四边形(例如115、125、135、145、155)中并且通常根据这些操作的实现方式存储在磁盘或内存中的各种数据起作用。在更复杂的操作中,列出了通常用于产生所需操作的信息或步骤;这些信息或步骤由带编号的圆角框示出。该系统以有限数量的尺度上的材料系统表示开始。任何特定的尺度都由基本的构建块组成。构建块的大小由特征长度定义。构建块的组成是通过建模或实验观察来定义的。然后将它们编码为结构的详细空间分解(有时称为“网格”),用于描述构建块内每个相的位置和属性。这种高分辨率描述的生成被称为微观结构生成,并且可以与任何尺度有关。预定义的一组材料属性和边界条件(通常经过仔细选择和简化)被提供给直接数值求解器,以计算标称响应场。将无监督机器学习应用于这些场,以生成聚类,所述聚类使每个聚类内的标称响应空间中的点之间的距离最小。这就产生了材料构建块的简化表示。可以计算和存储每个聚类之间的相互作用(或施加到一个聚类的单位载荷对其他聚类的影响)。使用预先计算的聚类和相互作用,可以在响应预测阶段利用任意边界条件和材料属性(不一定是用于计算聚类的简化边界条件和材料属性)快速求解相关控制偏微分方程(pde)。响应预测的结果将传递到下一个更粗尺度,作为该构建块的总体响应,因此该过程将继续进行。设想多尺度分析包括模型,这些模型在每个相关的长度尺度上捕获材料行为,从而将信息传递给下一个更高的长度尺度,直到达到最终尺度。该过程在图1的最左边示出。图1所示的下一步涉及生成mve或材料表示。对于任何给定的问题,一个合理的mve或一组mve(取决于所涉及的尺度数)可能来自许多不同的来源。此方法可用于由过程仿真示例2中得出的mve(由统计示例2-3和11中纯概念地或综合地生成的mve),并且可用于以多种方式(例如,请参见示例5-6)直接从实验图像中获取的mve。在图8中给出了针对金属的mve构造和处理的示例,其中使用了统计重构和直接成像的组合来创建mve。以复合材料为例,最简单的形式是最终尺度为用单向碳纤维增强复合材料(尺度1)构建的分量(在尺度为0时,最大)。在尺度1下,需要微观结构模型来计算物理材料响应。计算完成后,此响应将被作为单元级别的行为提供给尺度0。这在图5中示出。为了捕获其响应,将微观结构建模为高保真mve。如图4所示,每个mve包含数百万个体素。如图7所示,例如,对于在每根纱线中包含单向纤维的编织复合材料,可能会设想如何将该相同的方案扩展到尺度2。对于任意材料系统,此尺度分解可能延续到尺度n。金属是显示功能和结构层次的材料的另一示例。在一种简单的情况下,在尺度0下,金属可能由均质化行为表示,而尺度1则描述了晶粒级别的行为。许多晶粒的集体行为起到产生在尺度0时观察到的均质化响应的作用,请参见例如示例2。另一种可能是在每个晶粒内产生缺陷(夹杂物、空隙),而再一种可能是沉淀和位错的尺度。根据本发明,该方法的核心由以下三个步骤组成,在图1的顶行中概述:(1)使用高保真mve进行数据收集。此操作使用具有特定边界条件和属性的高保真方法。针对每个mve,给出了mve的材料响应指标。为每个mve收集的数据称为“响应场”,这意味着不一定需要唯一的材料响应选择。为了简化起见,通常需要弹性响应,但是该方法可以使用任何适当的响应场(例如,塑性应变是另一种可能性)。此数据保存在数据库中。(2)对步骤(1)中获得的响应数据进行无监督学习。此过程用唯一的id(例如1、2、3等)来标记mve中的所有点。因此,对mve行为的描述可依赖于具有相同id的多个点组,而不是点本身。我们称每个组为“聚类”。这在图2中示出。聚类id和空间点之间的映射存储在名为“聚类”的数据库中。尽管每个聚类不必是连续的,但聚类必须是空间填充的。(3)计算所有成对聚类(而不是点)的相互作用张量。此过程计算所有聚类的成对相互作用张量。当在mve上应用某个强制项时,可以计算每个聚类的行为。在此步骤中,原始mve已完全被在数学上仅用聚类而非空间点/单元描述的“压缩”mve代替。在图6中进一步详细描述了上述三步法。完成此三步法后,通过预测运算符在图1所示的下部读入数据。该方法使得用于求解mve响应的计算成本大大降低(如表1所示),但是保持了准确性(如图9中的示例所示)。表1中提供了针对图9中给出的情况的计算时间比较。随着这种计算时间的大幅度减少,可以使用台式工作站级的计算资源来克服需要在多个尺度上描述材料的实际建模挑战。复杂度的降低在图73中示出。mve大小的选择可以通过统计分析过程来确定。可以使用各种公式来加速相互作用张量的计算。如表1所示,可以看到没有任何数据压缩的模型很大,并且执行仿真的成本很高。本发明的方法显著降低了整个系统的复杂性(例如,通过解中的自由度来衡量)和计算成本。表1:dns和降阶mve计算之间的计算时间和平均百分比差异的比较。通过使用降阶模型(rom),例如示例1,也可以以优异的效率来构建复杂的材料微观结构响应数据库。这种数据库的一种可能用途是训练基于物理学的神经网络。如图10中示意性所示,该网络在任意外部载荷条件下提供了几乎瞬时的微观结构响应。如示例1所示,基于物理学的神经网络可用于结构优化和设计。此外,如图11所示,所描述的方法适用于具有所需性能指标的材料和系统设计。图3示出了可以通过该方法和系统建模的具有两个或更多个相关长度尺度的示例材料系统。图4示出了包含3600万体素的单向碳纤维增强复合材料的一个示例性mve模型。左侧的蓝色圆柱体表示碳纤维,红色的圆柱体是多尺度环氧树脂基材料。在y方向上对施加的载荷的整体(均质化)响应在右上角绘制,局部应力等值线图在右下角绘制。使用80个计算机处理器来计算此单个载荷历史记录的dns过程约需要200个小时。图5是使用传统的有限元法的多尺度(两尺度)问题及其复杂性的图示。在宏观尺度上,示出了受某个边界条件影响的通用部分的网格。在这些单元内的每个材料点上,都将对与通用子尺度的行为相对应的微观尺度响应进行计算,在此示例中显示为球形夹杂物。底图是多尺度(两尺度)聚类法及其降阶能力的图示。在此图示中,每种颜色都表示1阶自由度,而不是顶部图示中的每个蓝色边界区域。图6示出了示例性的三步“训练”过程,作为计算宏观尺度几何形状(顶图)和微观尺度几何形状(底图)的聚类和相互作用张量的一种可能方式。图7示出了示例性的三尺度frp建模框架。宏观尺度模型是编织层压复合材料模型,构建为有限元网格。宏观尺度模型中的每个积分点都由编织mve表示。该mve可以具有不同的丝束尺寸、丝束间距和丝束角度(所示为90°丝束角度)。介观尺度模型中的每个积分点都由udmve表示。该udmve可以具有不同的纤维方向、纤维体积分数和基质-纤维界面强度。如果使用fe网格将所有三个尺度离散化,则该全场系统的总dof可能为3.3×1015。使用本发明的方法并用rom代替介观尺度和微观尺度,总rof减小到1.6×106,由此减小了9个数量级。图8示出了在某些实施例中,可以从多个来源生成mve;此金属材料示例示出了使用x射线衍射测量、根据统计描述重构并由处理模型预测的晶粒。在这种情况下,在测量或预测时,均会产生缺陷、空隙,这里以两种实验方法(x射线断层扫描和fib-sem连续切片)为例。这些输入数据被配对(在空间上),并用于mve,从而直接基于实验图像进行响应预测。在图9中,左图是udmve的原始dns描述;中图是基于聚类的描述(示出了纤维相中的2个聚类,基质中的8个聚类)并且在底层体素网格上可视化;右图是总应力/应变的数值均质化结果。dns参考解以红色显示,并具有5%的逐点误差条。参看具有8个聚类(蓝色)和16个聚类(绿色)的降阶解。参考图10,物理指导的nn可以在mverom之上“分层”:nn在大型的快速计算行为数据库中训练。一旦经过训练,该nn被认为包含类似于rom的微观结构信息,但是评估起来要快得多。这种替代选择使进行基于微观结构的结构优化和设计变得切实可行。图11示出了应用示例:复合材料设计。可以将复合材料结构设计成具有不同的微观尺度结构(例如,纤维形状)和介观尺度结构(例如,每个层中的纤维定向、每个层中的纤维定向和纤维形状以及编织复合材料的不同编织图案)。可以预测复合材料结构的关键性能指标(例如,外部载荷下的强度和最大变形)。如果那些指标不符合所需标准,则将调用优化例程以更新微观尺度和介观尺度结构,从而改善性能指标。根据本发明,该过程较快,请参见例如示例5-8,如表1所示。根据以下理由(示例5-8),该过程也是高效的。该高效来自以下事实:数据压缩后,问题的复杂性大大降低了。示例5中显示的结果说明了计算成本得到节省,如表5-4所示。与诸如fem和fft等传统方法相比,本方法大大减少了所需的计算机内存和所需的计算时间。此外,如表1所示和图9所示,该方法也是准确的。此外,如示例8和9中所提供的,该方法可以应用于具有一个或多个长度尺度的材料。另外,该方法可以为任意数量的尺度提供多尺度建模能力。在示例9中,该方法已经应用于由纱线(其微观结构类似于图7所示的ud复合材料)和基质材料制成的编织复合材料。编织微观结构与基质和纱线相中的聚类分布一起在图12中给出。利用传统的材料定律对基质进行建模,并由单向(ud)复合微观结构对纱线进行建模,以捕获实际的纱线材料微观结构。由于编织复合材料由聚类表示,因此可以将其应用于图7所示的更高尺度的编织层压编织物,并实现为三尺度复合模型。在一个实施例中,编织微观结构数据库用于执行编织剪切仿真,在图167中给出了载荷方向。仿真是三尺度模型,其中宏观尺度模型是有限元框架(fef)中的单单元模型。还测试了两尺度编织微观结构数据库。该数据库的纱线相被建模为均质化的各向异性弹性材料。如图167所示,由于纱线的弹塑性行为,三尺度编织物提供了高度非线性的编织响应。三尺度模型能够捕获由于纱线可塑性引起的这种非线性,而使用具有弹性纱线属性的简化的两尺度模型无法捕获这种非线性。图167通过单单元有限元模型进行编织rve剪切载荷仿真。绘制了三尺度编织模型和两尺度编织模型的结果。根据本发明,该方法还可以利用示例8和9所示的固定边界内的任意形状。如示例9所示,该方法可以应用于纤维增强复合材料和编织复合材料,其中纤维增强复合材料mve已经在图9中示出,并且编织复合材料mve在图12中示出。该方法可以应用于任意数量的相/组成(示例4-5)。在某些实施例中,如示例5和图83和86所示,该方法已经应用于两相和三相填充橡胶复合材料。参照图83,用64个聚类表示将两相填充橡胶域分解为降阶模型。左图是用于两相填充橡胶的原始体素网格。右图是压缩的两相填充橡胶模型,其中基质相中有32个聚类,填充相中有32个聚类。图13示出了具有35个晶粒的随机晶粒结构(分图(a)),其中每个晶粒被认为是不同的材料相并进行逐晶粒应力预测,其中每个晶粒的聚类逐渐增多(分图(b))(如示例4中所公开的)。该方法是预测性的(解在已知数据的边界外提供),请参见示例3和9。在某个实施例中,如示例4和11中所述,该方法用于对ud碳纤维增强聚合物(cfrp)进行并发建模。参见示例3和9,预测能力在图11、12、83、86和167中示出。此外,如示例3和8所示,该方法也具有描述性(提供了均质化的全场信息)。此外,请参见示例6,该方法可以在分层建模方案中实现。如示例3和8中所讨论的,该方法也可以针对并发建模方案实现,其中展示了用于并发捕获宏观尺度物理场演进和微观尺度物理场演进的若干实例研亢,并且该方法可以针对分层建模和并发建模方案的组合(示例7)实现(如图14所示)。图14是介观尺度和微观尺度之间的分层建模以及宏观尺度和介观尺度之间的并发建模的一种实现方式的图示。udmve的弹性属性被预先计算并传递给纱线,从而构成了分层建模过程。当编织mve在外部载荷下时,使用纱线(由udmve给出)和基质属性来计算其响应。当有限元(fe)模型处于外部载荷下时,使用编织mve来计算其局部响应。以并发方式计算fe模型和编织mve响应,从而建立并发建模方案。因此实现了分层建模和并发建模的组合。该方法的其他应用包括材料设计(材料相选择),如图4、9和14所示,其中每个相的材料属性都会改变mve行为。例如,如图4所示,不同的纤维和基质属性将导致不同的应力和应变曲线,并且可以在几秒钟内做出预测。这就可能生成大型材料响应数据库,因此可以选择每个相的最佳材料属性。示例3和8公开了用于微观结构设计的本发明的实施例。此外,参见示例2和5-6,该方法可用于任何基础数据表示形式:图像、颗粒、无网格、有限元网格等。参见示例5,图83所示的情况利用了直接从3dtem过程生成的体素网格。在一个实施例中,该方法可以与机器学习一起使用以提高效率(gpu和不同的nn),例如,示例1。该方法还可以用于创建包含许多对应力和应变状态的微观结构响应数据库。然后,该数据库可以用作监督学习算法(一种类型的机器学习方法)的输入,以训练可以进一步提高效率的前馈神经网络(ffnn)。ffnn可以预测微观结构响应数据库中任意应变状态下的应力状态。如表1-5所示,使用ffnn可以达到10000的加速。在某些实施例中,数据驱动的材料和结构设计是通过机器学习技术实现的。如示例1所示,制定了基于微观结构的优化。它允许执行拓扑优化,从而设计具有微观结构损坏信息的结构,如图12-15、58、83、86和167所示。可以在示例6中找到不同过程的过程-结构-属性-性能(增材制造(am)、复合材料、聚合物基复合材料(pmc)),从而实现包括预测实验的系统设计。另外,在图4和7中,通过两个示例(复合材料和合金)示出了多尺度结构属性的材料和结构设计。如图7所示,该方法可以用于三尺度材料系统,并且可以扩展到n尺度。对于复合材料,例如编织复合材料,该方法可用于快速预测整个材料屈服面,如示例7中所述。该方法可以为编织mve创建rom,从而提供编织复合材料的弹塑性材料响应的高效预测。如图15的分图(a)、表4和示例7所示,在一分钟内即可计算出屈服应力,与实验方法相比,可节省大量成本。3d屈服面在图15的分图(b)中示出,屈服面可用于确定施加的应力状态是否导致材料屈服。此外,该方法可用于根据纱线和基质的不同微观结构和材料属性生成广阔的编织复合材料屈服面,从而在减小计算成本的同时提供了更大的材料设计空间。表4:如示例7所示的用于校准屈服面的六个屈服点在不意图限制本发明的范围的情况下,下面给出了根据本发明实施例的示例。注意,为了方便读者,可以在示例中使用标题或副标题,这绝不应该意图限制本发明的范围。此外,本文提出并公开了某些理论。但是,无论它们是对还是错,只要它们是根据本发明实施的,而无须考虑任何特定的理论或作用方案,它们就决不应该意图限制本发明的范围。示例1机器学习与设计优化中用于生成材料性能数据库的聚类离散化方法机械科学与工程可以使用机器学习。但是,数据集仍然相对稀缺。幸运的是,已知的控制方程能够补充这些数据。本示例性研亢总结并归纳了三种降阶方法:自洽聚类分析、虚拟聚类分析和fem聚类分析。这些方法具有两阶段结构:无监督学习有助于简化模型的复杂性,而机械方程则可以提供预测。这些预测定义了适合于训练神经网络的数据库。前馈神经网络解决了正问题,例如,替换了本构定律或均质化例程。卷积神经网络则解决了反问题或作为分类器,例如提取边界条件或确定是否发生损坏。在此示例中,我们解释了如何应用这些网络,然后提供了实践练习:(a)具有非线弹性材料行为和(b)在微观结构损坏约束条件下的结构的拓扑优化。这产生了对微观结构敏感的设计,其计算量仅比传统的线性弹性分析大得多。材料力学中的计算方法随着计算工具的发展而演变。计算机科学的最新进展是所谓的“大数据”时代的发展,在此期间,伴随着计算资源和方法的传感器和数据点的数量激增,从而能够跟踪和使用大型数据库来加深对世界的了解,通常会替代可能导致得出的结果普遍性较差或缺乏关键见识的针对性较小的研亢。以计算力学为背景,我们能够开发出依赖大量背景数据的数据驱动的计算工具,以促进例如快速多阶段材料系统设计的实时多尺度仿真、控件的在环力学(例如在制造时)。为了开发这种数据驱动的计算工具,出现了两个主要的研亢领域:(1)针对材料力学生成材料系统数据库,通常使用数据压缩来降低计算复杂性;(2)利用数据库进行实时响应预测和多阶段设计。之所以出现第一个领域,是因为数据科学严重依赖于可用数据库的大小和可靠性。与数据科学中的传统应用(例如图像检测/识别或自动控制)不同,计算力学中通常无法获得或仅无法访问极其庞大且定义明确的数据集。无论是由实验还是由计算模型来构建数据库,到目前为止,以例如图像识别中使用的尺度生成数据的成本在很大程度上是难以克服的问题。解决这一挑战的一种方法是使用材料系统的多尺度仿真,通过对任意远场变形载荷的代表性体积单元(rve)的总应力进行快速计算来进行。已经开发出许多方法,目的是针对这种问题在成本和准确性之间找到适当的平衡。这些方法通常被称为降阶方法(rom),并且其中许多方法已被开发出来。在某些实施例中,rye是mve的特定情况,它将产生由其代表的微观结构的收敛解。该方法可以应用于rve,但也可以应用于mve,从而涵盖各种材料系统。第二个领域通常利用机器学习和神经网络的方法来解决,以提供实时预测和多阶段设计。数据驱动的方法也已用于增强计算力学,例如,优化数值求积并用实验数据代替经验本构定律。最近,提出了一种深层材料网络方法。该方法在拓扑上模仿神经网络以将微观材料刚度与宏观材料刚度联系起来。一旦在预先仿真的微观-宏观刚度数据库上进行训练,就可以用来显著加快计算任意远场变形载荷下rve的总应力。在本示例性研亢中,首先探索并概括了三种基于数据挖掘的微观结构建模技术。这类快速方法解决了第一个问题:它们可用于生成纯机器学习或机械增强的机器学习所需的非常大的数据库类型。然后得出两种不同类别的神经网络的工作原理。接下来,将通过详细示例来探讨这些网络的工程应用,即考虑到微观结构的拓扑优化。然后,概述了数据驱动的计算方法的一些可能的未来方向,以激发对计算力学这一新兴领域的进一步研亢。两阶段聚类分析法自洽聚类分析(sca)及其近亲虚拟聚类分析(vca)和fem聚类分析(fca)是两阶段降阶建模方法,包括脱机数据压缩过程和联机预测过程。这在图16中简明地示出。在脱机阶段,以体素或单元表示的原始高保真rve被压缩为聚类。在联机阶段,宏观载荷被施加于降阶(聚类)rve。然后,将描述机械响应的方程组仅以简化表示形式作为边界值问题进行求解。表1-1中总结了本节中使用的符号。表1-1:用于两阶段聚类分析法的符号为了定义边界值问题,考虑到一种材料,该材料占据均质化的目的是找到以下两者之间的宏观本构关系:宏观应力和宏观应变其中|ω|是该区域的总体积。我们在数学上将rve问题定义为其中σ=σ(ε;x)是一般的微观尺度本构定律。针对均质化问题,必须选择边界条件以满足希尔-曼德尔条件。在本示例性研亢中,使用了周期性边界条件:上的ε周期性边界条件和σ·n反周期性边界条件。连续与离散李普曼-施温格方程通过引入弹性刚度为的参考材料,已证明具有周期性边界条件的rve问题等效于积分方程其中是在施加与原始rve问题相同的载荷和边界条件时参考材料中的应变;是施加于参考材料的特征应力;是与参考材料关联的格林运算符。如果在材料点x′上施加单位特征应力skl,则的物理含义为材料点x处的应变分量εij,其中分量skl由定义,其中δkm和δln为克罗内克三角函数。方程(1-4)中给出的积分方程被称为李普曼-施温格方程,通常被认为描述了量子力学中的颗粒散射。除非参考材料是均质化的,否则通常没有明确的形式。该域可以分解为几个子区域,称为聚类,通过特征函数χ在数学上进行区分,如方程(1-5)所示。其中i=1,2,3,nc表示每个聚类,ωi是聚类i内的体积的子集。这些聚类是在脱机阶段定义的。这样就可以使李普曼-施温格方程离散化,如下所示:其中表示第i个聚类中的任意变量■的体积平均值;是第i个聚类的体积分数,其中第i个聚类的体积由|ωi|给出。dij是由以下方程给出的相互作用张量:如果将均匀单位特征应力分量kl施加于第j个聚类,则的物理含义是第i个聚类中的平均应变分量ij。备注1:如果使用均质化的参考材料,如sca和vca中,则备注2:与fca的理念类似,方程(1-6)的对应项可以表示为:其中是参考材料的柔性基质;是在施加与原始rve问题相同的载荷和边界条件时参考材料中的应力。是第j个聚类中的体积平均特征应变。如果在第j个聚类中应用均匀单位特征应变分量kl,则的物理含义是第i个聚类中的平均应力分量ij。请注意,fca的参考材料是原始rve的弹性状态,而不是此处其他两种方法使用的均质化的参考材料。备注3:bij和dij之间的关系由以下方程给出:可以通过注意到在参考材料的某个聚类j中施加任意单位特征应变kl的效果等同于在同一聚类中施加特征应力的效果来证明这一点。在联机阶段,sca利用任意外部载荷条件来求解增量离散李普曼-施温格方程,即方程(1-6)。这些条件可以是固定应变增量εm型条件,也可以是固定应力增量σm型条件。脱机:聚类和相互作用张量脱机阶段包括三个主要步骤:(1)数据收集;(2)无监督学习(例如,聚类);以及(3)预先计算聚类相互作用。针对以下三个两阶段方法中的每一个方法,均按照完全相同的方式来执行线弹性响应的计算(数据收集)以及基于该响应的后续聚类:在所有三个方法的示例中均使用相同的体素网格和聚类。方法之间的差异在于相互作用张量的计算。(1)数据收集数据收集提供了用于构造系统的简化表示的信息。它通常涉及在有限的一组载荷情况下,用简化的材料模型对完全分解的系统的响应进行某一计算。可以收集的机械响应的一种度量是微力学a中使用的应变集中张量,由ε(x)=a(x):εm定义,并在远场应变或施加应变εm与域内的x点处测得的应变ε(x)之间映射。上面给出的应变集中张量的选择通常是合适的,但这取决于问题的相关细节。例如,在有限变形下,可以考虑使用变形集中张量:其中f(x)是域内任意给定点x的变形梯度,而f0是对应于边界条件的宏观变形。可替代地,如果弹性和塑性材料响应基本不同,例如,如果一个是各向同性的而另一是各向异性的,则可能需要包括有关变形的塑性部分的信息。(2)聚类聚类的目的是减少表示系统所需的自由度数量,同时最大程度地减少有关机械响应的信息损失。一种方法是将相关域内的材料点分组。如果可以假设每个组内的材料响应是相同的,则可以通过求解每个组而不是每个材料点的响应来确定域的演进。通过利用收集阶段生成的数据,可以应用许多聚类(或无监督学习)技术中的一种来优化域分解。在以下示例中,采用了自组织映射(som),如图16所示,其中构造了八个聚类(每相四个聚类)。聚类过程为每个材料点分配聚类id,以便将聚类标记为1、2、……、nc。k均值聚类法也已被使用。也可以考虑更复杂的聚类方案。正在进行的工作包括:模仿适应性fe方法随着变形的发展而演进的能力的“自适应聚类”方案;以及“丰富的”机器学习,从而将从力学中获得关于在步骤(1)中收集的数据边界之外的变形场的先验信息用于指导或限制无监督学习。另一未开发的未来方向可能是使用“基于特征”的机器学习,该机器学习除了力学信息外还包括微观结构信息。(3)相互作用张量相互作用张量描述了每个聚类对每个其他聚类的影响。一旦完成聚类过程,就可以显式地计算相互作用张量。重要的是,在脱机阶段仅需计算一次积分部分。然后,仅将该计算的结果用于联机阶段。三种计算相互作用张量的方式如下:这里突出显示每种方法都使用的一种方式(尽管这些方式并不限于每种方法):a.sca:dij的傅立叶变换由于周期性边界条件和均质化的参考材料,格林运算符在傅立叶空间中具有简单的表达式,为:其中是周期性格林运算符γ0的傅立叶变换;λ0和μ0是均质化刚度张量的拉梅常数;ξ是傅立叶点。然后,可以使用快速傅立叶变换(fft)技术通过以下方程计算相互作用张量。计算复杂度为o((nc)2(nf)log(nf)),其中nf是fft计算中使用的傅立叶点数。b.vca:dij的数值积分使用无限均质化的参考材料,可以在真实空间中表示格林运算符。数值积分是计算方程(1-7)中给出的积分方程的最直接方法。计算复杂度为o((ni)2),其中ni是使用的积分点数。c.fca:bij的有限元法基于对相互作用张量的物理解释,也可以使用有限元法。通过在第j个聚类中施加均匀单位特征应变分量kl,可以计算所有聚类的平均应力,从而得出所有i=1,...,nc的因此,计算复杂度为o(6(nc)(ne)),其中ne是所用有限元的数量。张量bij与相互作用张量dij类似,尽管bij是通过施加应变而不是应力确定的。联机:降阶响应预测准备好相互作用张量数据库后,即可在联机阶段求解在方程(1-6)中定义的离散的李普曼-施温格方程。方程(1-6)的增量形式由以下方程给出:其中是所施加的增量参考应变。根据局部材料的本构定律,增量应力σ1是增量应变εi的函数。因此,方程(1-12)的未知数是每个聚类中的应变对于非线性微观尺度本构定律,方程(1-12)是非线性的,并且必须迭代地求解。sca和vca使用牛顿迭代法,而fca使用另一种迭代法,方程(1-12)的残差形式由以下方程给出:然后,牛顿法的雅可比矩阵由以下方程给出:其中i4是四阶等同张量。第j个聚类中材料的切线刚度是求解局部机械响应的另一种方法是最小化基于聚类的系统的互补能。方法比较为了比较每种方法的准确性和效率,构建了用于两相材料的2d平面应变模型,并在图17中示出。2d网格包含600×600正方形像素。夹杂物面积分数为51%。表1-2给出了基质和夹杂物的材料常数。屈服面是冯·米塞斯(vonmises)表面,如方程(1-15)所示。基质材料的硬化定律在方程(1-16)中给出。注意,在以后的部分中,这将通过单调载荷的非线弹性行为来近似。表1-2:基质和夹杂物的材料常数ematrix(mpa)vmatrixeinclusion(mpa)vinclusion夹杂物的面积分数100.00.30500.00.190.51冯·米塞斯等效应力为屈服应力σy,基质由方程(1-16)中的硬化定律给出,具有等效塑性应变x方向上中规定了从0到005的应变,并且在y和xy方向施加了零应变。使用fem对这些载荷条件下的微观结构进行直接数值仿真(dns),并记录有效的冯·米塞斯应力,以便以后与降阶模型结果进行比较。使用应变集中张量执行一次微观结构数据压缩。所得的微观结构的聚类显示在图18中。使用前述算法计算每种方法的相互作用张量。用于计算相互作用张量的不同方法各自导致张量的形式略有不同。尽管细节有所不同,但它们之间还是有很强的相似性-毕竟,使用相同的微观结构和聚类。图19示出了了三种方法中每种方法的幅值图,其中幅值表示第j个聚类中每个应力分量对第i个聚类中相应应变分量的影响。图19分别在分图(a)-(c)中示出了的逐分量幅值图。对于所有三个相互作用张量表面图,沿对角线方向的尖峰表明,在逐聚类应力增量中,自相互作用比其余聚类具有更大的贡献。由于均质化参考材料假设,和沿它们的对角线方向具有相似的大小。沿对角线方向对于基质和夹杂物相具有不同的大小,隐式地表示非均质化参考材料。图20是的等值线图。请注意,对于fca,这两个区域对应于不同的物理域(基质和夹杂物)。图19和图20所示的幅度的趋势表明,尽管差异相对较小,但聚类间的相互作用对于vca并不如对于sca和fca那样强。最强的相互作用是聚类内相互作用,如沿对角线的峰值所示。fca具有两个不同的峰值区域,分别对应于夹杂物和基质中的聚类集。张量是按有序方式构造的,这将导致这两个不同的聚类集。因此不太可能改变整体解的准确性。一旦创建了微观结构数据库并计算了相互作用张量,就可以进行联机预测。如图21所示,在所有三种情况下,x方向上的应力rom结果均在dns结果的5%以内,三个rom之间的差异很小。图21的分图(b)突出显示了这三种方法之间的细微差别:sca遵循与dns相同的趋势,但略柔和一些;由于恒定的参考材料假设,vca预测的响应仍然更柔和;fca展现的趋势与dns总体上略有不同,但其值仍然相当接近。图22中,绘制的图示出了sca最符合dns解,并且是在参考解的5%之内的唯一预测。请注意,vca具有与dns解不同的边界条件,即,它使用了虚构的周围域。因此,在周期性边界条件下,dns结果可能会出现一些偏差。基于预测性rom生成的数据库上的机器学习神经网络是一类特定的机器学习算法,在最基本的形式上看起来类似于回归分析。实际上,这些方法涉及通过一系列函数修改输入数据以获得输出数据。确切的函数系列及其权重和形式取决于应用。一旦对算法进行了适当的训练,这些方法就可以较之于许多常规方法使速度提高。为了获得基于机器学习的高效建模方法,需要丰富的力学响应信息数据库来执行该训练。用实验开发这样的数据库是很难的,对于设计不存在材料性能信息的新材料或材料系统尤其如此。因此,上文概述的快速预测模型(sca、vca、fca)对于快速填充相对较大的材料数据库来说是理想的。这使得能够在多尺度设计中使用机器学习算法,在多尺度设计中,需要同时应用和满足控制材料微观结构和组件级宏观结构的准则和约束条件。前馈神经网络(ffnn)是最早开发的神经网络。ffnn旨在学习复杂的输入-输出关系。因此,ffnn可以用来代替常规的本构定律;当对材料的均质行为的描述复杂和/或难以获得时,这尤其有吸引力。ffnn的基本结构包括输入层、隐藏层和输出层。相邻层中的每对神经元具有加权连接。隐藏层和输出层中的每个神经元具有偏差。在ffnn中,同一层中的神经元未连接。在学习过程中,连接权重会按照一组预先定义的规则(例如反向传播)而改变。funahashi和hornik等人证明,ffnn中的三个隐藏层足以学习任何非线性连续函数。将机器学习应用于力学的早期努力使用了计算和知识表示范式,所述范式实际上是一种前馈神经网络,通过从分析和实验数据进行训练来直接“学习”材料行为。一项早期的工作应用了反向传播神经网络来对混凝土在单调双轴荷载和压缩单轴循环荷载下的平面应力行为进行建模。举例来说,一旦建立了rve模型,就可以在该数据上训练ffnn,并且可以实现将微观结构直接连接到宏观材料响应的并发多尺度方案,其中ffnn代替了rve或本构定律来描述每个材料点的响应。为了与多尺度方法集成,已经研亢了神经网络。在这些情况下,将数值仿真的某些部分替换为神经网络,以更好地利用它们的优势。随着数值方法的发展和对多尺度仿真的兴趣日益增加,多尺度仿真与神经网络的集成正在持续发展。在设计优化中,人们可能希望对材料子例程进行多次调用(例如,对于每次设计迭代的每个载荷的每个单元调用一次)。因此,与在几毫秒内给出应变状态的情况下预测rve应力响应的模型或在几毫秒内给出微观结构应力等值线图的情况下提供应变状态的模型相比,运行rve的rom可能仍然很耗时。为了解决这个问题,我们建议用对sca计算的rve响应进行训练的神经网络替换rom,以应对微观应力和宏观应力。这些网络保留微观结构信息,并且旨在:a.对于一个rve使用ffnn预测给定宏观应变的情况下的宏观(均质化)应力或微观(局部)应力。在这种情况下,ffnn发挥了传统材料本构方程和均质化(以计算宏观应力)的作用。我们将其分别表示为和b.使用卷积神经网络(cnn)预测给定任何微观应力分布的情况下的宏观应变。这是ffnn的反函数。输入是rve域内的应力分布。输出是施加到此rve的宏观应变载荷(边界条件)。我们将其称为c.通过将局部冯·米塞斯应力与应力阈值进行比较来计算rve损坏。cnn经过训练以识别rve中损坏的发生。在这种情况下,cnn充当分类器,其识别所施加的宏观应变是否会引起微观结构损坏。我们将其称为使用sca生成用于机器学习的数据库本示例中呈现的rom可用于生成用于机器学习的数据库。在这种情况下,我们将sca与8个聚类一起使用。通常,此类数据库含有nt个训练样本和nv个验证样本。对于rve模型,通过随机取样各自具有四个子加载步骤的200个终端状态,为非线弹性材料计算出nt=1000个应变-应力对的数据库,如图23所示。类似地,生成nv=150个应变-应力对(30个最终状态,外加四个中间步骤)以进行验证。假定载荷单调增加,并且所有最终点都被限制在半径为0.05的球形空间中。表1-3示出了通过使用本示例情况的sca,相对于fem或fft,建立数据库所需的时间减少。在没有降阶模型的情况下,使用fem或fft生成微观结构数据库需要几天的时间。所述数据库含有nt=1000对宏观应变和应力εm,s、σm,s,以及局部(微观)应力σs(x),其中s=1,2,...,nt。在这种情况下,我们只考虑平面应变问题,而不考虑z方向的应力。与fft相比,sca的总计算时间减少了两个数量级,而与fem相比,则减少了四个数量级。图23示出了应变状态的随机样本;选择了两百个最终状态,并且记录了四个均匀间隔的中间步骤以达到最终状态,共计nt=1,000个样本。所有应变状态都将应用于rve以生成对应应力状态。表1-3:生成nt=1,000个应变状态样本的非线弹性rve响应的微观结构数据库所需的时间的比较。sca只需要单个工作站来生成数据库。方法总时间(秒)较之于fem的加速fem2.04×107-fft3.01×10568sca(4+4个聚类)脱机:13.0+联机:2.16×1039400前馈神经网络为了说明前馈神经网络(ffnn)的结构,提出了一个简化的一维示例。联机性弹性中,应力与材料刚性造成的应变有关;通常可以将其界定为映射。神经网络的总体结构也可以描述为映射,即:其中是使用应变状态ε作为输入并且生成应力状态σ作为输出的ffnn。简单的ffnn的结构在图24的图(a)中示出。如图24所示,图(a)是对于线弹性示例的具有一个隐藏层的ffnn网络的图示;连接输入层(绿色)、隐藏层(蓝色)和输出层(红色)的权重和偏差的集体函数是杨氏模量e的集合函数。图(b)是应力-应变图,示出了ffnn如何使用线性激活函数和零偏差来解释线弹性情况的输入应变。该图及本节中使用的符号在表1-4中进行限定。对于该图示情况,仅考虑一个样本,因此s=1,并且所有变量都写为不带上标s。通用ffnn含有神经元(圆圈)和权重(黑线)。通常,ffnn具有一个输入层、一个输出层和多个隐藏层。每一层可能具有多个神经元;对于输入层和输出层,这些神经元是简单的输入和输出值。在最简单的情况下,ffnn将具有一个输入神经元、一个隐藏神经元和一个输出神经元。在此情况下,对于1d线弹性应力分析而言,输入神经元将为应变,而隐藏神经元将作为刚度的乘性函数分解,从而恢复将应变映射到输出神经元中的应力所需的总刚度。稍微概括一下,我们可以考虑具有三个隐藏神经元的ffnn,如图24所示。每个神经元只有一个值。第一神经元就是应变:隐藏层中的三个神经元采用该值,并且每个神经元采用以下给出的值:其中是激活函数。在训练部分,该示例使用sigmoid函数:并且每个神经元使用不同的权重和偏差进行计算,其中i是前一层(在这种情况下,输入层)的神经元,而j是当前层(在这种情况下,隐藏层)的神经元。最后,总体响应(应力)由下式给出:所有w和b项以及激活函数的组合在回归分析中用作拟合因子。激活函数对于所有神经元都是固定的,并且用于调节加权因子。对于上述本构模型,权重、偏差和激活函数的总体结果将与弹性模量完全匹配。如果我们只考虑权重,并且激活函数仅仅是线性映射,那么隐藏层中的每个神经元的功能在图24的分图(b)中明确给出,其中所有神经元的偏差取为零。尽管整体思想是相同的,但对于非线性响应,个别神经元的物理解释更为复杂。在此公式中,应变路径相依性(即可塑性)是无法捕获的,且净结果是响应图,人们可能会认为神经元集合(权重、偏差和激活函数)为“瞬时弹性模量”或使应变与当前应变点处的应力相关的直线的斜率。图25是具有多个隐藏层的ffnn的图示:nl表示层索引;nn(l)表示层l中的神经元数量。ffnn的公式在等式(9-21)中给出,具有ffnn结构的相关联解释。索引i和j表示上一层与当前层的神经元id,例如是层l=1中的神经元1与层l=2中的神经元2之间的权重。图25中所示的示例扩展了前面的示例,以考虑二维应力分析,其中每层含有许多神经元,并且具有若干层。输入是平面应变问题中的三个宏观应变分量输出是三个宏观应力分量不考虑应力分量上文概述的数据库的样本(应力-应变对)用于训练神经网络。在训练之后,当给定应变输入时,ffnn可以预测应力。在通用ffnn的每一层中,每个神经元将前一层中每个神经元的输出值作为输入,并给出单个输出。对于每一层都重复此步骤。泛化等式(1-18)、(1-19)和(1-20)到任意数量的层和每层的神经元会导致等式(1-21),其中第s个样本(不管是训练样本还是预测样本)的层l中的第j个神经元的值可以表达为:其中,最后一层给出估计应力:表1-4:前馈神经网络中使用的变量的符号表每一层的输出具有与1d情况类似的物理含义。对于第s个样本,输入应变分量由表示,而表示对微观结构的非线性应力响应的估计。层l=2,...,nl-1的激活函数和权重与固体力学中切线模量的经典界定起到大致类似的作用。隐藏层吸收了应变分量,并且产生了非线性应力响应的估计值。在训练过程期间,那些隐藏层逐渐“学习”了应力与应变之间的非线性关系。在最后一层中,l=nl,表示预测应力分量。预测应力分量是通过输出层中的回归操作产生的,如等式(1-21)所示。输出层的权重和偏差会校正从隐藏层生成的预测,并且产生准确的非线性应力响应。为了使概念清晰,可以将隐藏层认为是对中间应变值操作的无单位值,而输出层中的w和b的单位是应力的单位(例如,在示例问题中为mpa)。由于以下两个关键因素,ffnn可以学习非线弹性材料的行为:1)隐藏层类似于传统的本构模型那样近似于材料非线弹性响应,如等式(1-17)中所述;2)输出层校正预测非线性响应以改善预测精度。具有由sca生成的数据库的前馈神经网络在该实例研亢中,用使用sca生成的数据来训练ffnn。使用与图18中给出的相同的微观结构,当应用单调递增的应变时,sca计算rve(或任何任意rve)的应力响应。由于sca提供了有效的应力状态评估,因此在用sca得出的数据上训练ffnn很方便。然后,ffnn可以通过“学习”应力状态作为应变状态的函数来代替sca。这将在应变和应力之间建立直截了当的关系,以几乎立即评估rve应力响应。请注意,尽管在由sca分析的rve中将塑料材料描述为基质材料,但此处描述的ffnn仅限于非线弹性(即与路径无关)的材料行为:我们用非线弹性材料来近似得出塑性响应,并且集中在单调载荷上。此外,在以下设计情况中,训练ffnn以不仅预测总体rve应力响应(如图25所示),而且还预测逐聚类局部应力响应。这基本上是相同的过程,但输出层的大小为nc×nn(l=1),其中每个聚类的每个应力分量都有一个点。该第二种形式复制了sca的非均质化结果。训练ffnn的训练过程可以重新公式化为优化问题。我们将损失函数(或成本函数)定义为估计应力和由rve使用sca计算的应力的均方误差(mse)。假设存在一个隐藏层,则优化公式由下式给出:通过找到的最佳值,mse减小。请注意,在此过程中仅使用训练数据,因此s=1,2,...,nt。通常,mse随每个训练步骤而逐渐减小。为了确保训练后的神经网络对于所有可能的输入状态足够通用,称为验证数据的一些数据点用于监视误差的趋势。最小化迭代在验证数据的误差开始增加之前终止。这确保了神经网络能够为不在训练集中的数据点提供一定的外推能力。上文描述的ffnn在数据库上进行了训练。在这种情况下,选择了具有一个隐藏层和50个神经元的ffnn。在训练过程中,使用1,000个样本来训练神经网络。使用莱文贝格-马夸特(levenberg-marquardt)优化算法来减小mse。预测在训练过程之后,对单调加载过程期间的应力状态执行快速评估。用于此的ffnn可根据等式(1-24)预测给定宏观尺度应变张量情况下的宏观尺度应力张量;类似地,使用等式(1-25)来预测给定宏观尺度应变张量情况下的局部(逐聚类)应力张量。为了证明宏观尺度ffnn的有效性,使用了l2范数来测量由等式(1-24)预测的总体应力以及验证数据集中每个样本的均质化sca结果之间的差,计算方法如下:为了验证训练后的ffnn,选择了另外30个最终应变状态(在训练期间未知),其中每个状态(包括最终状态)选择五个加载步骤。图26示出了对于验证数据集中的这些新的nv=150个应变-应力对,用l2范数、等式(1-26)测得的差的直方图。大多数测试样本的l2范数都很低,这表明ffnn受过良好训练。图27示出了对照每个ffnn预测绘制的每个应力分量的sca应力数据;完美匹配的斜率是1。相关联的交叉相关统计数据是1:ffnn解与sca解完美匹配。在每个加载步骤,ffnn和sca的应力预测相匹配,如图28所示。此实例研亢说明了使用降阶建模方法生成用于训练ffnn的丰富的微观结构响应数据库的便捷工作流程,所述ffnn然后用于生成rve响应的快速预测。请注意,尽管此处详细给出了均质化应力-应变关系的ffnn验证,但宏观尺度加载和微观尺度(逐聚类,或局部)应力之间的关系已使用了类似的过程,如等式(1-25)中给出。我们建议,此处示出的ffnn可以用于设计优化过程中,例如拓扑优化或微观结构设计,其中需要快速而准确的材料响应预测。然而,请注意,材料是非线弹性的和/或处于单调加载下。如果考虑可塑性和加载/卸载,则可能需要不同的ffnn设置或不同的神经网络。使用sca和ffnn运行150个样本的速度比较在表1-5中给出,其中ffnn较之于sca的σm联机预测的加速为10000。将使用ffnn预测(等式(1-24)和等式(1-25))和卷积神经网络进一步探讨该思想。表1-5:使用sca和ffnn运行150个样品所需的时间比较。卷积神经网络卷积网络或卷积神经网络(cnn)广泛用于图像识别和特征识别等领域。术语“卷积”是指线性数学运算,并且指示在网络的至少一个层而不是常规基质乘法中实施卷积运算。这是生物学启发的模型,用于处理已知的网格状拓扑数据,例如时间序列(连续时间间隔下的1d样本栅格)或图像数据(2d像素栅格)。卷积神经网络已在材料科学和多尺度建模中实施,以在输入数据为微观结构图像的情况下分析微观结构特性。经由微观结构图像提取材料信息(材料科学中一种普遍存在的数据类型)已被证明是cnn的有前途的应用。举例来说,lubbers等人基于织构图像的分布实施了cnn,用于无监督地检测低维结构。扫描电子显微镜(sem)图像在材料科学中经常使用以区分材料的类别。可以使用cnn来用单个特征或多个特征对此类图像数据集进行分类。一些研亢已经实施了cnn,以使sem图像在单个数据集上特征化。然而,应使用可扩展和通用的特征来促进cnn的广泛应用。ling等人分析了基于cnn的sem图像特征化方法的可推广性和可解释性,并且发现在这种情况下,平均织构特征化通常很有用,但有时无特征cnn程序也很有吸引力。cnn的应用不限于图像。cang等人建立了cnn方法来预测异质材料的物理特性,从而取代了标准的统计或微力学建模技术。生成的方案适用于具有基于高维微观结构的高度非线性映射的系统。他们已经实施了卷积网络以量化材料的形态,随后实施另一卷积网络以预测给定微观结构的材料特性。对于复杂的材料和响应,这也可以3d方式完成。cnn模型包括若干基本单元操作:填充(padding)、卷积(convolution)、合并(pooling)和前馈神经网络(ffnn)。示例1dcnn的结构在图29中示出。输入是一系列应力值,即1d问题。1dcnn包括填充、卷积和合并的多个循环。对于特定的循环迭代η,填充过程会在边界周围添加零,以确保卷积后维度与输入维度相同。在填充后,将使用若干内核函数来如下近似得出离散卷积运算符:其中对于第η个卷积过程且η=1,2,...,nconv,是输入,是第κ个内核函数,且bκ,η是偏差。内核函数的大小为lconv。表1-6中给出了本节中使用的所有符号的概述。卷积运算可以认为是特征识别运算。在填充之后,合并层将减小输入的维度,并且从卷积后数据中提取最重要的特征。一维最大合并等式由下式给出:其中是输出值,是输入值,且lpooling是合并窗的长度。最大合并从所述窗中提取最大值,但也可以使用其它合并运算。在这种情况下,我们推测,为了预测远程应变,最大应力值可能为显著大的。填充、卷积和合并可能会重复nconv次。该值将传送到完全连接的ffnn,如上一节中所示的ffnn。图30表示典型的二维cnn的结构的概观。继续上文给出的二维示例问题,对于cnn,输入为应力在由σ(α,β)给出的600×600栅格内的应力,其中α和β分别对应于应力图的x和y分量。在每个栅格点(α,β)处,存储了三个应力分量xx、yy和xy。填充将在输入数据周围添加零边界,以确保在卷积之后,图的大小将保持不变。与1d卷积类似,卷积运算将内核函数应用于应力轮廓,并且生成具有与初始应力轮廓相同分辨率的新特征图。等式(1-29)示出了用于第η个卷积过程的卷积运算到二维的扩展。其中k是卷积层的内核id,且从1到nkernel。维度1和2中卷积内核的大小由xconv和yconv给出,并且都是奇数。维度1和2中内核中的计数索引分别界定为ξ和ψ。应力分量的数量为nfeature;对于此2d示例,nfeature=3。通过将内核应用于每个输入应力阵列中的每个单元,将生成完整的特征图。为使用cnn界定输入和输出之间的非线性关系,经常使用激活函数。在某些情况下,这是整流线性单元(relu)层,其应用于从卷积运算生成的所有特征图。为了简化说明,该步骤未在等式和图中示出。在relu层之后,将合并层应用于所有特征图,以压缩x和y方向上的数据分辨率。可能使用不同的合并运算;在此示例中,我们选择了最大合并。最大合并运算符将特征图划分为许多子集区,并从每个区中选择最大值,以用作压缩特征图中的值;从等式(1-28)概括,对于第η个卷积过程,这可以写为:在最后的合并运算之后,所有压缩的特征图通过展平运算转换为单个向量。然后,将展平的阵列用作ffnn的输入,以进行回归以计算对应的应变。cnn方法和实施方案的更多详细信息可以在本节开头引用的文献中找到。表1-6:用于描述上文示出的cnn的符号。用sca生成的数据库识别边界条件的卷积神经网络使用图30所示的cnn,已经建立了微观结构上的局部应力分布与所施加的外部应变之间的映射。训练该cnn在与ffnn相同的具有1000个sca结果的数据库上进行了训练。对于cnn,输入为rve的每个点(体素)处的微观尺度应力,由sca的逐聚类结果σ(α,β)给出。rve中的每个点含有三个2d应力分量,如同用于图像的rgb通道。cnn的输出是宏观尺度应变εm,其用作载荷条件并且引起了观察到的应力。训练可以写为优化问题,如等式(1-31)中给出。重复nconv次用填充、卷积和合并层训练cnn的等式由下式给出:所述项用于通过组合图30所示的嵌套运算来简化表示法。其界定为:其包括用于填充、卷积和合并的项。训练问题中的其余项界定如下。ffnn中的权重和偏差是和bκ,η是卷积运算中的权重和偏差。基本实况是ε*m,s,且估计值是εm,s。训练样本的数量界定为nt,且nn(l=nl)是输出层中神经元的数量。在这种情况下,nn(l=nl)为3。取样由s编索引。cnn的输入是与由σs(α,β)给出的应力分量相对应的三个应力阵列。输出是三个应变值正如ffnn,使用若干优化方法之一逐步降低均方误差(mse)预测正如ffnn,我们可以界定函数该函数描述了训练后的cnn所执行的操作,在这种情况下:在图31中,使用等式(1-33)计算预测的εm和验证数据集(同样,上文生成的nt=150个样本)之间的误差的直方图。cnn做出的大多数预测的l2范数都小于1×10,这表明cnn产生了应变状态的准确预测。l2范数说明了cnn网络能够正确预测验证数据。在图32中,使用与前文提到的相同的验证数据集提供了所施加应变的cnn预测与三个应变分量的参考解之间的相关性。黑色实线是基本实况:所有完美的预测都应落于这些线上。所有三种情况的相关系数都高于0.99,这表明训练后的cnn可以在预测施加应变时提供良好的准确性。这些表明cnn可以有效地将应力轮廓映射到所施加的外部应变。这样的图在将微观结构信息与宏观尺度信息联系起来,例如在将微观结构损坏强度与宏观尺度应变状态联系起来方面可以起重要作用。这将有助于逆设计问题,在该问题中,可以使用局部信息来推断最佳加载状态。由sca生成的数据库进行分类的卷积神经网络cnn在材料微观结构预测中的应用不限于上文示出的样本问题。cnn的另一示例用途是作为微观结构分类器;这类似于其在图像分类中的常见应用。通过使用微观结构网格和在微观结构上作为输入的所施加应变,可以训练cnn来预测微观结构是否将损坏。训练分类cnn的训练程序由下式给出:分类cnn的输出ds是二元指示符:0表示未损坏,1表示损坏。由于输出是二元值,因此现在根据真实值d*s和预测值ds之间的交叉熵界定目标函数。交叉熵或对数损失广泛用于测量分类模型的性能。本节中的cnn在从用于先前nn的数据库中提取的数据上进行训练。用于训练分类器的数据库包括成对的微观应力分布和损坏指示符。在这种情况下,将使用基于临界应力的损坏准则来确定rve是否受到损坏:如果任何冯·米塞斯应力σ(x)超过了临界冯·米塞斯应力σ*,则rve视为已损坏。预测一旦经过训练,cnn就可以预测所施加的载荷是否会导致微观结构损坏,而无需执行完整的rve仿真:这种cnn将在基于微观结构的拓扑优化示例中使用,以说明微观结构损坏约束条件对优化结构的影响。使用神经网络的基于微观结构的多尺度拓扑优化在本节中,我们将说明如何在拓扑优化中使用ffnn和cnn来实现基于微观结构的设计。这将当前方法与通常使用简单本构关系的经典拓扑优化区分开来。如上所述,我们建议将rve响应数据库压缩到ffnn中,以对rve应力响应进行正向预测,其作用类似于传统的均质本构模型。然而,由于使用了rve响应数据库,因此不需要均质化的函数形式。rve微观结构损坏响应以训练后的ffnn+cnn表示;这会引入与所施加的rve应变状态相联系的微观结构损坏。通过使用训练有素的ffnn和cnn,界定了两个不同的优化问题,如下:1.用从在给定微观结构的应力-应变关系上训练的ffnn中提取的材料本构定律进行拓扑优化。在这种情况下,拓扑优化期间的非线性材料行为可用于实现在材料响应进入非线性区的极端载荷条件下持久的设计。2.用由ffnn+cnn框架界定以识别微观结构损坏的约束条件以及由此用cnn设计耐用(可感知损坏)结构进行拓扑优化。在这种情况下,微观结构损坏对拓扑优化公式化构成了额外的约束条件,以实现减轻或避免可能的局部微观结构损坏的设计。在这两个示例问题中,用矩形线性单元的60×30网格描述了设计区。每个单元是1cm×1cm的正方形。弹性材料的特性来自均质化的sca结果:e=200mpa,且ν=0.27。近似非线弹性材料响应从第3节获得的rve仿真中提取,如以下各节所述。请注意,虽然使用了可塑性,但我们的ffnn仅对材料响应的非线弹性近似有效。右下角施加了75n的点载荷。优化部分的所需体积分数设置为原始设计区的0.35。对于第二种损坏情况,临界应力界定为0.7mpa利用ffnn的拓扑优化等式(1-36)中示出ffnn对微观结构敏感的拓扑优化的公式化。目标函数界定为结构的总应变能φ,其将被最小化。在本示例中,这项工作中的一个细微但重要的区别是,ffnn用于用非线性响应替换通常的线弹性材料响应。通过使用上文描绘的非线性材料响应数据库,说明了数据驱动材料和结构设计的新途径。这在图33中以图形方式描绘,图33示出了使用ffnn在拓扑设计框架内产生基于微观结构的应力-应变响应。其中f是主体力,t是在设计区边界上施加的牵引力,而u是设计区中的局部位移。u*是允许的位移场,且sm界定宏观结构(设计区)的边界。σ(xm)和σ(xm)是宏观应力和应变。每个宏观网格的密度为ρ(xm)。设计区中剩余的材料的所需体积为v*,并且界定为0.35,且v(ρ(xm))是设计区中的优化体积。在设计区中,位置xm的密度为ρ(xm),且均质化应力为σ(xm),界定为ρ(xm)与的乘积。此处,表示训练后的ffnn,其将基于如等式(1-17)中界定的给定应变输入ε(xm)生成应力预测。在这种情况下,ffnn用于近似得出rve响应。因此,σm由ffnn直接近似得出。实际上,用于优化的软件的约束条件需要对行为进行功能描述(该限制将在以后的工作中解决),因此使用指数函数近似得出有效的冯·米塞斯rve应力与有效应变曲线。这种超弹性材料的界定符合ffnn的结果。这种特用方法通过使用基于条件的优化使总应变能最小化而确保了优化过程的稳定性。图33是使用ffnn的拓扑优化设置。ffnn用于计算非线性材料响应以驱动新设计。这用宏观尺度中每个点的微观结构的均质化响应代替了通常用于宏观尺度的本构定律。从数学上讲,如等式(1-36)中所界定。在图34的分别针对线弹性材料和非线弹性材料的分图(a)-(b)中示出了优化的梁式结构。表1-7提供了必要的结果。两个结构在结构的最终形状上表现出实质性差异。这意味着材料的非线性在拓扑优化中起着重要作用,其中为了确保最小的应变能,实现了新的桁架结构。结果表明相当大的基于微观结构的材料非线性对于结构优化的重要性。也可能将微观结构变化(例如不同的颗粒体积分数)包括到该结构中。简而言之,ffnn为基于微观结构的数据驱动拓扑优化提供了一种替代方法,其中可以将微观结构效果并入该过程中并实现满足设计准则的不同设计。表1-7:基于ffnn的非线弹性优化问题的结果。请注意,在保持并发方法的准确性和微观结构基础的同时,实现了显著的加速。这将在3d中提供进一步的速度优势。*估算,假定迭代次数与ffnn相同具有由ffnn+cnn界定的约束条件的拓扑优化拓扑优化结果可能具有高应力集中区。如果处理不当,集中区可能会造成意想不到的损坏,并且影响结构的功能。解决此问题的传统方式是在优化中添加应力或应变约束条件。先前的研亢者专注于应力集中和奇点的优化。在这些以前的研亢中,大多数损坏准则仅与宏观材料模型有关,而没有考虑微观结构的力学行为。在本项工作中,利用由sca生成的数据库训练的ffnn+cnn框架提供了对于损坏的基于微观结构的损坏预测准则。为了做到这一点,使用在等式(1-25)中界定的ffnn,其执行运算如上所述,这预测了rve中的局部应力,而不是均质化应力。这些局部应力分布用作cnn的输入,这指示是否已发生损坏。优化公式因此为:其中是整体结构的柔量,n是单元的数量,p是惩罚能力(通常p=3),ue是每个单元的位移,且k0是单元刚度。rve的平均应变响应为εm。rve内的局部应力界定为σ,并且使用训练后的ffnn计算。其它变量与上文针对仅ffnn的优化所界定的变量相同。对于rve中的任何xωm(x),的输出值应为0,其表示未损坏状态。由于ffnn+cnn数据库仅给出准则,因此敏感性分析在这种情况下并非优选的。此处的算法遵循改进的最佳准则(oc)方法。优化程序的结构基于99行拓扑优化代码(因此问题是类似的,但实施方式与上述基于ffnn的优化不同)。在密度更新期间,对于每个单元,三个应变分量将被传递到ffnn+cnn。ffnn+cnn将通过评估局部微观结构响应来确定当前应变状态是否可以接受。这在图35中示意性地示出。对于设计区内的每个材料点,考虑到微观结构的影响,ffnn用于计算材料响应(不管是线性还是非线性)。cnn用于并入微观结构损坏,与仅使用线性材料的拓扑优化相比,其将驱动新设计的优化算法。从数学上讲,其为:如等式(1-37)中所界定。如果任何d(x)在微观结构中标记为已损坏,则设计区中含有该微观结构的点xm将标记为已损坏。如果单元已损坏,则将通过应用惩罚因子来增加此单元的密度,同时将降低其余单元的密度以满足体积约束条件。类似于ffnn示例,图36的分图(a)示出了参考情况:在没有损坏约束条件下的线弹性优化。最终柔量为30n·cm。图36的分图(b)示出了基于微观结构的损坏约束条件下的优化设计。最终柔量为31n·cm。请注意,尽管柔量非常类似,但在微观结构损坏约束条件下的设计类似于更传统的桁架结构;优化过程避免了锐角,并减少了梁,从而导致应力集中,从而可能导致微观结构驱动的损坏。表1-8提供了与优化有关的设计变量和重要参数的概述。上文的简单示例示出了通过聚类降阶方法生成的ffnn+cnn数据库的潜在应用。然而,优化只是基于人为界定的最佳性准则。该算法可能不适用于所有类型的问题。将来,我们应该基于ffnn+cnn数据库来研亢约束条件的敏感性和奇异性。表1-8:ffnn+cnn约束条件优化问题的结果。请注意,在保持并发方法的准确性和微观结构基础的同时,实现了显著的加速。这将在3d中提供进一步的速度优势。*估算,假设迭代次数与cnn相同概述当前力学材料科学中机器学习方法的两个挑战是:(1)数据库生成时间长和工作量大;以及(2)机器学习的应用尚未得到团队的充分开发或理解。这项研亢涵盖了与这些挑战相关的几个不同主题:·我们已经概述、关联和比较了三种不同的基于无监督学习的聚类离散化方法(sca、vca和fca),用于降阶和求解用于预测的力学控制等式。·这些方法之一,即sca,用于开发适用于训练神经网络的示例性材料行为数据库。这种数据库开发方法极大地减少了获取可训练神经网络的信息所需的工作量。·概述了基本操作以及这些操作如何在ffnn中组合在一起以预测力学响应。这包括权重、偏差和激活函数的作用,以及使用力学科学中常见的符号将神经网络的训练阶段描述为最小化问题。·对卷积神经网络的类似描述针对两种不同的可能应用进行了开发:(1)求解需要从已知应力分布中识别边界条件的逆向问题;以及(2)作为分类器以识别在给定已知应力分布下是否会在微观结构内发生损坏。·演示了两种微观结构敏感的拓扑优化。在第一种情况下,从ffnn结果导出微观尺度的材料响应,并将其用于对照导致材料以非线弹性方式表现的载荷执行设计。在第二种情况下,在优化中添加材料损坏约束条件,其中cnn用于识别微观尺度上是否发生了损坏,并相应地对设计进行惩罚。简言之,我们提供了一些方法来更快地生成训练神经网络所需的数据,从力学科学的角度进一步深入了解了神经网络的工作原理,并强调了这些方法在增强实际设计任务方面的潜力。开发了使用sca做出响应的数据库、用于用神经网络进行训练和预测的代码以及拓扑优化代码。这将鼓励将数据科学和机器学习用作力学分析的工具,而不是像未知的黑箱运算符那样简单。已经指出了可能需要进一步研亢的若干领域:·聚类方法的进一步发展可能是有前途的,以表示大的变形、更好地捕获各向异性行为或由于载荷条件而变化的行为,甚至在预测阶段细化聚类。适用于聚类离散化方法的接触式或自接触式公式的开发将有助于实现普遍性。·目前正在开发适用于组件尺度(而不是仅rve尺度)的聚类离散化解决方案的公式,以及在多个尺度上使用聚类离散化的并发多尺度解决方案的扩展。·对于神经网络,包括历史相依性(例如,可塑性)的方法当前是活跃的领域。将物理学直接包括在神经网络中是另一个发展领域,例如具有物理学知识的神经网络(pinn)。·为了进行优化,应进一步开发使用ffnn和cnn进行拓扑优化的灵敏度分析。也希望有更灵活的软件来支持这一点。·利用各种材料微观结构数据库进行多尺度拓扑优化仍然是一个发展中的领域。此处概述的方法可能是在给定足够约束条件的情况下同时优化拓扑结构和微观结构的有前途的方法。·这些方法(基于聚类的离散化和神经网络)的“数据驱动”组件不限于使用计算数据。如果可能,可以包括来自其它来源的信息,例如实验传感器数据和图像。如果使用混合数据流,则在数据表示方面需要格外小心。·持续的校验和验证研亢将有助于使这些方法稳定可靠。示例2延展性材料的有限应变力学科学的数据科学在此示例中,公式化了基于数据科学的材料力学科学,以预测工艺-结构-特性-性能关系。取样技术用于构建训练数据库,然后使用无监督学习方法对其进行压缩,最后通过力学等式生成预测。本示例中提出的方法依赖于解空间的先验确定性取样、k均值聚类方法以及使用自洽方案求解的力学李普曼-施温格方程。该方法是在有限应变设置中公式化的,以便对在金属成型过程中产生的大塑性应变进行建模。引入了包括碎片模型的有效实施,以便在聚类离散化中对这种微观机制进行建模。通过添加同样基于数据科学的疲劳强度预测方法,可以在冷拔niti管的情况下预测工艺-结构-特性-性能关系。近几十年来,在精细尺度实验和数值建模方面越来越多的研亢工作逐渐导致了力学和材料科学中建模方法的改变。以前用来对结构和材料的非线性力学响应进行建模的经验和现象学材料定律已被基于微观结构的力学材料定律所取代。在任意载荷条件下,要建模的微观结构观察和条件的数量使得这种努力所需的精力在实际应用中站不住脚。数据科学,尤其是机器学习的吸引力在于,大大减少了生成预测性材料定律所需的微观结构观察和仿真的数量。因此,对于材料力学科学的数据科学理论产生了极大感兴趣,其可以从预界定的实验和数值结果数据库中生成预测性材料定律。文献中提出了多种方法来实现这一目标,一般可以通过三个步骤来概括:(1)使用高保真实验和仿真来收集数据,以建立训练数据库;(2)使用无监督学习方法压缩训练数据库以减少维度;以及(3)使用监督学习方法或压缩训练数据库上的力学等式来生成预测,并且视情况使用带有新的高保真实验和仿真的测试数据库对这些预测进行交叉验证。可以使用例如随机取样、高斯(gaussian)过程或sobol序列来生成训练数据库。由于那些取样方法可能需要大量数据点才能充分覆盖求解空间以进行准确的预测,因此一些研亢者已考虑确定性取样方法。举例来说,在不考虑训练数据库的大量任意、随机载荷条件的情况下,已证明仅6个小幅度的正交载荷条件就足以进行小应变弹塑性分析。可以使用各种无监督的降维方法来实现训练数据库的压缩,例如本征正交分解(pod)、k均值聚类和自组织图。压缩方法的选择非常重要,因为其界定了将在预测阶段求解的力学等式的离散化。pod导致了全局支持的形状功能,而聚类方法则确保了逐聚类离散化。由于数据压缩,用于构建训练数据库的高保真实验和仿真的复杂性限制于几个自由度中。为了解决这些自由度并且预测任意载荷条件下的力学响应,必须根据减小的自由度来重新公式化力学等式。这种力学等式的新公式化通常称为降阶模型,但该名称涵盖例如恰当广义分解等不依赖数据科学的方法。此外,一些方法将数据压缩和力学预测步骤结合在一起以在仿真期间改善降阶模型。一些监督学习方法已直接应用于具有内置压缩阶段的训练数据库。举例来说,人工神经网络就是这种情况,人工神经网络在文献中已应用于依据材料的微观结构特征预测其力学性能。在此示例性研亢中,我们公开了通过自洽聚类分析(sca)用于延展性材料的数据科学力学方法,自洽聚类分析是针对较小应变弹塑性材料开发的数据驱动的力学材料建模理论。sca依靠通过聚类进行数据压缩以及通过微力学和均质化理论进行力学预测。在这项研亢中,sca进行预测所依赖的力学等式被重新公式化以用于有限应变弹塑性材料。已验证了这种新方法的数值收敛。sca的这种新公式化使得能够通过图37所示的夹杂物在微观结构尺度上的脱粘和碎裂来预测延展性材料中空隙的成核,其中使用体素网格离散化延展性材料的微观结构,其中基质示出为蓝色,夹杂物示出为红色:分图(a)为二维微观结构,且分图(b)为三维微观结构的内部视图,其中碎裂的夹杂物由以浅灰色示出的脱粘空隙包围。这种预测得以实现,且复杂性降低了若干数量级。利用这一优势来预测冷拔镍钛(niti)管的工艺-结构-特性关系。数据科学公式化基于微观结构的材料建模需要界定理想化或统计上具有代表性的微观结构实现,称为rve。均质材料定律可以通过分析或数值求解该rve的响应的边界值问题来计算。对于任意的微观结构几何形状和微观结构成分的复杂行为(塑性、断裂),需要使用例如基于有限元(fe)方法的数值方法或基于快速傅立叶变换(fft)。本文将要研亢的微观结构与延展性材料相对应,且特征在于嵌入在基质中的一个或多个夹杂物和空隙,如图37所示。微观结构成分行为的复杂性是由于基质的超弹塑性响应、夹杂物的超弹性-脆性行为以及基质/夹杂物界面处的脱粘微机制而引起的。fe方法可以与未变形rve域(上标m意味着微观)的任何结构化或非结构化fe网格一起使用,而基于fft的方法需要结构化体素网格,例如图37中所示。在fe方法中,针对位移场um编写了离散等式,该位移场在网格节点处近似为:其中nnodes是fe网格中节点的数量,um,n是节点n处的位移向量,并且nn是节点n处的fe形状函数。在基于fft的数值方法中,针对变形梯度张量场编写了离散等式其在体素方向近似为:其中nvoxels是体素的数量,fm,n是体素n中的变形梯度张量,且χn(x)是特征函数,如果x在体素n内,则其等于1,否则为零。对于给定的微观结构,位移场um和变形梯度场fm取决于应用于rve的边界条件。在目前的工作中,um将在rve域上分解为线性部分和周期性部分。结果,fm将分解为常数部分fm(上标m意味着宏观)和在上具有零平均值的周期性部分。这些假设与一阶均质化理论相对应。数据科学用于材料的力学科学中,以依据fm预测um或fm。如引言中所述,第一步骤是通过仿真生成数据。训练数据库中的仿真结果将具有较大的维度,这是由于等式(2-1)和(2-2)中的近似对节点数或体素数的依赖性所致。为了获得维度减小的新近似值,必须进行数据压缩。数据压缩使用各种方法可以实现降维,其中在下文提出了pod与聚类并对其进行比较。仅当要在预测阶段进行的仿真的复杂度至少优于训练和数据压缩阶段所需的仿真的复杂性达一阶时,本文提出的数据科学方法的一般公式化才有意义。数据科学方法的相关性还取决于可以从预测阶段转移的工作量。以下将在基于pod和基于聚类的材料力学科学的数据科学方法中证明这一点。pod情况下的数据压缩在于用k<<nnodes个全局函数(称为主成分或模式)替换大量的局部fe形状函数(nn)n=1nnodes。可以使用各种分解技术(例如主成分析或奇异值分解)来计算后者。所得的近似值代替等式(2-1)为:其中在网格节点处将模式离散化为:然后可以使用标准的fe弱形式进行预测阶段的仿真,但可以用(2-3)代替等式(2-1)的近似值。有趣的是,一旦在数据压缩阶段计算了模式,就可以在fe网格的积分点处预先计算等式(2-4),计算方式与通常在fe代码中预先计算fe形状函数相同。然而,如果材料是异质的,或者如果其具有导致异质变形的非线性行为,则仍必须在每个积分点处求解材料积分。因此,在pod方法中,材料积分的复杂性没有降低。另外,由于等式(2-4)的形式,与fe弱形式相关联的刚度基质是致密的,且因此使用直接或迭代求解器的解决方案具有三次最坏情况复杂度,而非二次。然而,此复杂度取决于k而不是nnodes,其中k<<nnodes,且因此可以通过pod大大降低。在sca的情况下,数据压缩遵循另一种方法,其中初始数值方法是基于fft的。大量的体素将被k<<nvoxels个互相排出的体素群组(称为聚类)代替,且跨越整个rve域。可以使用各种聚类技术(例如k均值聚类或自组织图)构建聚类。下面给出了可用于聚类的数据的示例。所得的近似值替代等式(2-2)为:其中fm,k是聚类k中的逐聚类恒定变形梯度张量,且χk(x)是特征函数,如果x在聚类k的任意体素内部,则其等于1,否则为零。因为在基于fft的数值方法中,自由度直接是逐体素的恒定变形梯度,所以在同一点进行内插和积分。因此,聚类自由度直接导致自由度数量的减少和材料积分复杂性的降低。实际上,在sca中,在预测阶段进行的所有操作的复杂度仅取决于聚类k的数量,其中类似于pod,最昂贵的操作是密集线性系统的求解。后者是由将柯西(cauchy)等式重新公式化和离散化为离散的李普曼-施温格方程而产生的。下文在有限应变情况下描述这些步骤,随后为关于基于有限应变fft的数值方法的最新研亢,然后将其集成到sca中。连续李普曼-施温格方程如前所述,一阶均质化在于将rvefm中的变形梯度张量场界定为宏观(均质)变形梯度fm和微观(非均质)波动的相加。希尔引理可用于将宏观的第一皮奥拉-基尔霍夫应力张量pm界定为微观的一个的平均值。希尔引理需要(fm-fm)来验证兼容性,即从周期位移场中导出,且需要fm来验证平衡,即成为cauchy等式的解:可以证明,等式(2-6)等效于李普曼-施温格方程:四秩张量是与各向同性线弹性参考材料相关联的刚度张量。远场变形梯度张量f0和周期性格林(green)运算符在下文确定。后者将任意张量字段τm映射到兼容的张量字段:u在上为周期性的,其中是平方可积分函数的索伯列夫(sobolev)空间,其弱导数也为平方可积分的。等式(2-7)和(2-8)的组合产生验证兼容性的微观变形梯度张量fm和验证平衡的第一皮奥拉-基尔霍夫应力张量pm。离散李普曼-施温格方程sca包括逐聚类而非逐体素地求解等式(2-7)。这种选择的灵感来自微力学,尤其是变换场分析。图38示出了对图37中的微观结构执行的聚类的示例。在图38中,分图(a)示出了使用8个聚类离散化的二维微观结构;分图(c)示出了使用65个聚类离散化的相同二维微观结构;且分图(c)示出了使用217个聚类离散化的三维微观结构,其示出了在基质相中的两个聚类(两个蓝色阴影),夹杂物相中一个聚类(红色),空隙相中一个聚类(浅灰色)。作为训练阶段的结果,rve域离散为k个子集基于fft的数值方法中的自由度与微观变形梯度fm相关。在sca中,fm通过逐聚类恒定近似(fm,k)k=1k来离散化。因此,微观的第一皮奥拉-基尔霍夫应力张量也逐聚类地近似为(pm,k)k=1k,并且等式(2-7)可离散化为:其中是由下式界定的相互作用张量:特征函数χk和χk′在聚类k和k′中分别等于1,在其它地方等于0。在基于fft的数值方法中,周期性格林运算符取决于并且在傅立叶空间中为封闭形式。由于与各向同性线弹性参考材料有关,因此可以在傅立叶空间中表达为参考拉梅(lamé)参数λ0和μ0的函数。然后,其通过使用逆fft而在真实空间中获得。特别是,等式(2-10)可以写为以下形式:尤其可以找到f1、f2、和的详细表达式。sca大大降低了计算成本,这是因为通过聚类减少了自由度的数目,并且可以在训练阶段预先计算和因此,fft或逆fft可在预测阶段计算,即使参考材料发生变化。在目前的工作中,混合边界条件耦合到等式(2-9)。微观变形梯度的平均值的一些分量设置为等于它们的宏观对应项且微观第一皮奥拉-基尔霍夫应力张量的平均值的其它一些分量设置为零。可以通过将以下条件添加到等式(2-9)中来完成此操作:其中是施加运动学条件的一组分量。如上所述,等式(2-9)的解取决于参考材料的选择。可以通过使参考材料与均质化材料一致来在预测阶段计算出最佳选择。这意味着远场变形梯度张量f0是sca中必须求解的另一未知数,这与f0≡fm的基于fft的数值方法不同。自洽方法包括使用定点迭代方法,其中在每个步骤中,改变参考拉梅参数λ0和μ0,使得得以最小化。在附录中以算法形式给出此情况。综上所述,sca是基于rve域的逐体素离散化,其是从基于fft的数值方法继承而来的。sca的独创性来自训练阶段使用k均值聚类算法来基于使用加载空间的简单取样计算出的先验聚类准则对体素进行聚类。此训练阶段还包括计算所有在体素方面和计算方面昂贵的运算,例如fft和逆fft。在预测阶段,使用自洽迭代算法来搜索参考拉梅参数的最佳选择。在此自洽循环的每次迭代中,由于在训练阶段已对所有体素方面的操作进行了预先计算,并且已经减少为聚类方面的贡献,因此可以加快基质装配操作的速度。牛顿-拉夫森(newton-raphson)迭代算法必须在考虑非线性材料时嵌入于每个自洽迭代中,因此离散李普曼-施温格方程得以线性化。sca的输出是微观变量的逐聚类近似,包括微观的第一皮奥拉-基尔霍夫应力张量。后者可以用于通过基于应力的断裂准则来预测空隙成核的微观机制,如第4节所述。sca相对于pod技术的主要优势在于,在预测阶段,所有操作都是在sca中逐聚类的而非逐体素地进行,包括材料积分甚至碎片化建模。数值验证在考虑特定应用之前,本节同时使用基于有限应变fft的数值方法和有限应变sca对通用延性材料的微观结构进行建模。目的是验证sca相对于参考结果的数值收敛性,以及其以较小的复杂度来计算准确预测的能力,如针对小应变情况所示。但在当前的大应变情况下,在基质和夹杂物中都对超弹性行为进行建模。添加了具有线性各向同性硬化的乘性冯·米塞斯塑性模型,以对基质的非线性响应进行建模。夹杂物被认为是脆性的,这是延性材料中对硬质相的常见假设。延性材料模型的微观结构在图39的分图(a)中示出。表2-1给出了基质和夹杂物的材料性能。使用100×100×100体素对微观结构进行离散化,这足以根据我们的初步计算(此处未报告)使用fft数值方法来准确预测响应。表2-1:延性材料模型的材料参数范围基质夹杂物空隙单位杨氏模量70.0400.00.07e-3gpa泊松比0.330.20-屈服强度400--mpa硬化模量1333--mpa在单向张力高达所施加的应变增量大小为0.001的对数应变25%的情况下,使用基于有限应变fft的数值方法在体素网格上计算参考结果。用于k均值聚类的训练数据库仅包含从该参考仿真的第一个增量中提取的体素级变形梯度张量,这与线弹性分析相对应。换句话说,除了载荷条件以外,用于训练的仿真在所有方面(网格、几何形状、材料属性)都与在预测阶段进行的仿真相同,因为在训练期间仅施加了一个应变增量。因此,可以以可忽略的计算成本来构建该数据库。k-均值算法需要预定义数量的聚类,该预定数量的变化范围从基质相的k1=1,4,16,64,256到夹杂物相的k2=1,1,4,13,26。参考宏观应力/应变曲线与由有限应变sca预测的宏观应力/应变曲线之间的比较在图39的分图(b)-(c)中示出。对于基质中的16个或更多个聚类,使用有限应变sca可以获得非常准确的预测。这使得验证可以扩展应用于较大应变。为了示出聚类对计算复杂度的影响,图39的分图(c)中示出了计算时间的比较。与基于fft的数值方法相比,使用sca可以将计算时间减少4个数量级。这表明基于体素的机械聚类,sca极大地降低了微观结构计算的复杂度。sca的这一有趣优势在第二组仿真中得到了证明,其中图39的分图(a)中的夹杂物被空隙代替。该多孔延性材料的材料属性与表1中相同,除了将空隙的刚度假定为基质刚度的1%。将载荷设置为单轴张力,以确保在分析期间应力状态保持恒定。参考宏观应力/应变曲线与由有限应变sca预测的宏观应力/应变曲线之间的比较在图40的分图(a)-(b)中示出。可以看出,对于带有空隙的示例,收敛速度要慢得多,与夹杂物情况相比,其具有更大的塑性应变。但是,预测非常接近参考结果。如图40的分图(b)所示,保留了sca在计算时间方面的主要优点。由于所有sca预测都非常接近,因此可以使用很少的聚类并获得参考结果的良好近似值,从而再次大大降低了计算复杂度。由于大大降低了计算复杂度,并且预测结果与参考结果非常接近,这些首次采用所提出的有限应变sca公式进行的仿真很有前景。但是,这种比较完全是全局性的:仅对平均结果进行了评估。在较大的塑性应变或更复杂的载荷条件下,可能会出现非常不均匀且局部的应变场,这将需要对该方法进行改进。例如,当rve内发生塑性定位现象时,可以考虑采用自适应聚类技术来更新聚类。冷拔niti管的疲劳强度预测本节的目的是演示基于数据科学的材料机械学在预测过程-结构-属性-性能之间的关系的实用性。选择的应用是冷拉伸niti管的疲劳强度的预测,该疲劳强度是拉伸比和初始夹杂物纵横比(ar)的函数。niti管是使用一系列与热处理相结合的热金属和冷金属成型工艺制成的。它们用于制造例如由于心跳而承受大量循环载荷的动脉支架和心脏瓣膜框架。因此,管的性能的关键指标是其材料的疲劳强度,它本身就是材料在不同施加的周期性应变幅度下的疲劳寿命的函数。这种疲劳寿命可以使用微机械仿真来预测,该仿真取决于niti管的微观构成。微观构成是成形过程的结果,尤其是冷拔步骤的结果,这是后续研亢的重点。我们公开了通过将双轴压缩应用于嵌入niti基质中的初始脱粘夹杂物来在微观尺度上对冷拔进行仿真。为了预测冷拔过程中该微观结构的演变,上文介绍的有限应变sca理论利用碎裂模型完成。在此拉伸模型的不同阶段提取了微观结构,并将其用作在先前研亢中开发并简要描述的数据驱动的疲劳寿命预测模型的输入。将微观结构形态从拉伸模型转移到疲劳寿命预测模型需要进行位移重建和微观结构插值步骤。给出了使用这种数据科学方法所得到的过程-结构-属性-性能预测。冷拔模型使用上文介绍的自洽方案,可以使用混合边界条件(2-12)和适用于微观结构成分的本构模型来求解离散李普曼-施温格方程(2-9)。本构模型和材料参数保持与表2-1中使用和报告的相同,但它们由夹杂物碎裂模型完成。此外,与冷挤压工艺类似,由于在冷拔过程中在夹杂物/基质界面处早期产生了高剪切应力,因此夹杂物被认为最初是脱粘的。遵循先前工作中使用的、与尺寸效应标准耦合的正则化技术,使用逐夹杂物平均的tresca屈服准则对夹杂物碎裂进行建模。tresca准则将剪切应力σtresca定义为:其中σ1,σ2,σ3为夹杂物相的每个聚类内计算的逐聚类恒定主应力。然后,对逐个夹杂物或在夹杂物已经破裂的情况下的逐个夹杂物碎片的剪切应力σtresca求取平均值,并将该平均值与夹杂物剪切强度σtresca。还将该夹杂物或夹杂物碎片的等效半径r与临界尺寸参数rc进行比较。如果达到剪切强度且r≥rc,则包含该夹杂物或夹杂物碎片的经σtresca加权的质心的夹杂物聚类会变成空隙,如图41所示。在实践中,这包括在多个载荷增量下将其杨氏模量降低至其初始值的千分之一。一旦为方程式(2-9)和(2-12)已使用自洽方案求解,那么在有限应变sca仿真的每个载荷增量结束时执行此过程。如图41所示,碎裂裂纹的朝向是预定义的,并且最初垂直于拉伸方向。断裂准则参数在表2-2中给出。表2-2:冷拔模型的断裂准则参数参数值单位剪切强度3000mpa临界夹杂物尺寸0.171/rve)大小疲劳寿命预测模型可以基于在循环载荷下预测的局部塑性变形来估算高周疲劳寿命,其中,使用上文概述的sca计算这些变形。由于循环应变幅度较低,通常低于反向应变的1%,因此可以使用小应变方法。逐聚类地求解适当的微观尺度材料定律-晶体可塑性(cp),以获得基质材料中塑性剪切应变(δγp)和该应变的法向应力(σn)的循环变化。这些变量的峰值通常在3或4个加载周期内迅速达到循环稳态。通过这些变量,可以定义一个称为疲劳指示参数(fip)的标量值,该标量值可以量化任何位置的疲劳驱动力。在这里,我们采用fatemi-sociefip,定义如下:该fip是一种基于通过材料屈服应力(σy)和控制法向应力影响的材料相关参数k(此处k取0.55)二者进行归一化的最大法向应力σn平面的临界平面方法。当与sca和cp定律一起使用时,可以通过简单的搜索根据跨时间增量的塑性应变和应力逐聚类地计算每个聚类中的fip,以使塑性应变最大化,从而确定临界平面。可以利用科芬-曼森(coffin-manson)参数化将最大饱和的fip(nfipmax)与微观结构可以承受的疲劳孵化周期(ninc)的数量进行关联。通过针对多个不同的应变幅度来计算ninc以生成应变-寿命曲线,可以通过内插或拟合来计算疲劳强度(可以达到给定数量的循环的应变幅度)。使用经校准以捕获niti的b2相的硬化反应的cp材料定律。屈服后硬化是使用导致直接和动态强化的背应力项来计算的。在与材料相的最坏情况近似或几乎最坏情况相似以及冷拔模型缺乏晶体学信息的情况下,假定基质由单个晶粒组成,该晶粒经定向以使其schmid因子最大化。硬质夹杂物相(以氧化物或碳化物为代表)被认为具有线弹性,其弹性模量是基质材料的十倍。该过程遵循cpsca方法,该方法整合了sca中的cp材料定律,以及针对合成微观结构所示的疲劳预测方法。实际上,如图所示,对于cp、fip和科芬-曼森使用相同的模型参数。微观结构从冷拔模型到疲劳寿命预测模型的转变疲劳寿命预测模型依赖于cpsca,因此依赖于下层的体素网格。为了使用该模型,需要将拉伸仿真结果中显示的变形和碎裂的微观结构转移到新的体素网格中。第一步是重建微观位移矢量场,因为基于fft的数值方法和sca都只能求解出微观变形梯度张量。这个步骤是使用简单的泰勒展开或正向有限差分公式完成的,该公式可根据体素内部的微观变形梯度来计算体素网格所有节点处的位移。该计算从rve域的任意一个位移固定为零的拐角处开始,这与基于fe的线性均质化实现方式一致。一旦重建了位移矢量场,就可以通过将这些位移添加到节点坐标上来使网格变形,如图42的分图(a)-(b)所示。最后,使用简单的逐体素常数插值将相位接片(基质、夹杂物、空隙)从该变形网格转移到变形rve域的新体素网格。如此一来,新体素网格与基于fft的数值方法和sca兼容,但嵌入了对应于冷拔微观结构的相位接片。可以使用cpsca方法在这个新体素网格上计算疲劳寿命预测,如图42的分图(c)所示。疲劳强度预测考虑了拉伸模型的三个不同初始条件,这些条件代表了冷拉伸原料中加工质量和加工程度可能的变化性。每个条件都包括一个以基质为中心、椭圆形、脱粘的夹杂物,在载荷方向上具有不同的ar。初始构造的横截面面积(即椭圆形的短轴)保持恒定,并且长度(沿拉伸方向)发生变化。通过这样做,我们研亢了ar(平均曲率)对拉伸、碎裂和随后疲劳寿命的影响。通过使用无应力的第三轴进行双轴压缩,可以将这三种不同的情况变形为最多减少60%的截面高度。对于每种情况,每减小5%的高度,都会执行流程大纲并计算疲劳强度。为了计算疲劳强度,对在0.36%到0.54%之间的范围内以0.06%的增量递增的应变幅度所对应的疲劳寿命进行计算,并使用与该数据拟合的幂次定律来估算达到107个循环所需的应变幅度。始终使用加载速率为0.1/s的三角波形来施加完全反向的拉伸压缩(应变比,r=-1)疲劳载荷。该参数研亢的结果如图43中所示。在图的中心,绘制了疲劳强度(可获得指定次数的循环的最大应变幅度)与拉伸所导致的截面减小的关系图。在截面减小的每个点上,对于每个ar,使用上文概述的流程计算107个循环的疲劳强度。在六个不同的点处给出体积的横截面,以便对疲劳强度随减小量变化的过程进行可视化和分析。拉伸模型捕获了疲劳寿命(特别是对于最高ar)随着高度的不断减小而增加的总体趋势。当ar3颗粒碎裂减少了40%至45%时,可以见到疲劳寿命大大增加。在图2至图7的右上子集中示出了碎裂前构造,在图42的分图(c)中示出了碎裂后构造。fip的分布在这两种状态之间发生显著变化,场在碎裂之前更集中在界面处,而在碎裂之后则更分散在整个体积中。高度减小达60%时,ar1和2都不发生碎裂,而且寿命未见显著降低。这与实验经验是一致的,在实验经验中,通常需要较大幅度的减小以获得较大的疲劳性能增益。需要更大的减小量或不同的材料性能以实现碎裂。根据该实施例,提出了用于材料力学的数据科学方法的通用组合。该通用组合包括在高保真仿真的训练数据库上使用无监督学习方法来降低过程-结构-属性-性能预测方法的复杂度。这一点在由使用fe方法或基于fft的数值方法计算出的rve仿真结果构成的训练数据库的情况下得到了证实。降维导致rve模型的压缩,其中根据用于数据压缩的监督学习方法将节点和体素替换为模式或聚类。在预测阶段,使用压缩后的rve来求解监督学习方法或机械方程式。例如,pod可用于使用压缩的fe离散化来求解柯西方程,其中复杂度取决于模式数而不是节点数。类似地,可以使用k-均值聚类来求解李普曼-施温格方程,其复杂度取决于聚类数而不是体素数。后一种方法相对于前一种方法的有趣优势在于,它既降低了机械方程式求解的复杂度,又减少了材料集成。使用聚类离散化求解李普曼-施温格方程需要一个在此示例中已扩展到有限应变弹塑性材料并耦合到微机械空隙成核模型的自洽方案。如此一来,在niti管的冷拔过程中已捕获到由较大的塑性应变引起的微观结构演变。使用先前工作中开发的第二种基于数据科学的方法将这些微观结构演变与niti管的疲劳寿命以及疲劳强度进行关联。因此,已经证实,针对材料力学所提出的数据科学方法能够预测过程-结构-属性-性能,并且复杂度有所降低。示例3单向碳纤维增强聚合物的预测性多尺度建模这项示例性研亢提出了单向(ud)碳纤维增强聚合物(cfrp)的预测性多尺度建模方案。讨论了一种自下向上的建模过程,用于预测ud结构的性能。ud材料响应是根据高保真代表性体积单元(rve)计算的。数据驱动的降阶建模(rom)方法将rve压缩为降阶模型,因此可以同时进行材料响应和结构级仿真。本示例中提出的方法已针对实验数据进行了验证,并被认为可为未来的纤维增强聚合物开发过程提供设计指导。在现代工程应用中,复合材料因其非凡的轻质和强度而受到越来越多的关注。为了了解各种cfrp设计的机械性能,必须进行物理测试。随着计算能力的不断提高,现在可以使用集成计算材料工程(icme)方法来虚拟评估复合材料设计的性能并为复合材料提供设计指导。icme方法将微观结构信息直接集成到属性和性能预测中。在icme过程中,可以通过将微观结构与宏观尺度性能联系起来的多尺度模型来捕获材料微观结构与机械性能之间的内在联系。在此示例性研亢中,介绍了用于udcfrp的自下向上icme建模框架。该框架采用了可在udcfrp结构仿真过程中快速计算ud微观结构非线性响应的两阶段rom技术。udcfrp的自下而上的多尺度建模工作流程在图44中进行了解释,其示出了建模过程中的长度比例跨度。通过udrve表征的微米级的udcfrp微观结构提供毫米级的ud薄片和ud试件的微观结构信息。使用物理rve预测出准确的ud结构响应。从微观尺度(ud微观结构)到宏观尺度(ud试件fe网格),ud试件是以自下而上的方式建模的。该框架可以扩展到三尺度复合材料,包括ud、编织和编织层压结构。过去几十年里,在将微观结构信息并入到宏观模型中以进行性能预测方面已经做出了巨大的努力。例如,可以将所有微观结构细节建模为一个模型,但是由于需要精细的网格,此种计算方式成本很高。通过部署多尺度建模技术,可以使用物理微观尺度信息来预测宏观尺度的响应。多分辨率连续体理论(multiresolutioncentinuumtheory)证明的一种分层多尺度建模方法就是其中之一。在多分辨率连续体理论中,将微观结构信息实施到宏观尺度本构定律中,以构建分层多尺度模型,该模型捕获微观结构效应,例如夹杂物尺寸的效应。尽管这种分层多尺度建模方法保留了某些微观结构信息,但它没有提供明确的微观结构演变。为了捕获微观结构响应,可以部署并行均质化。并行均质化方案其中之一是有限元平方(fe2)方法。在fe2方法中,用有限元(fe)网格对宏观尺度几何形状进行离散化。通过求解由fe网格离散化的rve,计算出所有积分点处的材料响应。fe2方法同时对两组fe网格进行求解,由此导致较高的计算成本。为了提高计算效率,开发了各种rom方法,例如转换场分析,非均匀转换场分析和本征正交分解。一种新提出的数据驱动的两阶段rom方法,即自洽聚类分析(sca),利用高保真体素网格rve来创建rom,并利用有效的rve破坏和失效仿真来rve的弹塑性行为。在脱机阶段,引入了一种三步法,其包括:1)数据收集,例如为rve中的每个体素收集应变集中张量;2)无监督学习,将所有体素单元分类为不同的聚类;3)生成逐聚类的相互作用张量。在联机预测阶段,通过求解离散化的李普曼-施温格方程来识别逐聚类的应变响应。先前的出版物显示了sca大大减少了计算费用,并且验证了高保真直接数值仿真(dns)的准确性。因此,该三步两阶段数据驱动的sca方法是icme过程中用于建模udcfrp复合材料的有价值的工具。图66中示出了用于求解一个实施例中的李普曼-施温格方程的sca流程图。在该示例性示例中,提出了用于udcfrp结构性能预测的icme建模框架。在该框架下,使用fe网格对宏观ud模型进行离散化。ud微观结构由rve表征。rve被压缩到ud降阶模型(rom)中,并为所有积分点提供动态的机械响应。每种成分(例如纤维和基质)的本构响应是从物理测试中获得的。udrom通过计算rve响应来捕获udcfrp的弹性和弹塑性响应。此外,由于基质可塑性而引起的ud非线性使本项工作与cfrpicme建模中的先前工作有所不同。这些先前工作都是基于线弹性材料响应的假设进行结构分析的。udrom足够高效地计算rve响应,以取代现象学各向异性的材料模型,同时毫不费力地实现材料常数的校准工作。一般而言,开发的方法可广泛用于预测纤维增强聚合物的性能。基本材料信息、udcfrp试件偏轴拉伸试验和udcfrp三点弯曲试验的实验程序、udcfrp的icme建模过程的详细信息以及结果和实验验证将在下文进行讨论。材料信息在本节中,提供了针对购自dowaksa的a42碳纤维和购自dowchemical的热固性环氧树脂所得到的材料特性。在本示例性研亢中,本节提供的材料特性将在整个建模工作中使用。纤维的弹性常数在下表3-1中给出。假定纤维具有弹性。假设纤维方向的压缩强度为拉伸强度的四分之一,其中假设拉伸强度(ts)和压缩强度(cs)分别为4200mpa和1050mpa。假设碳纤维的延展性破坏模型,如方程式(3-1)所示,其中dfiber=0表示没有损坏,而dfiber=1表示纤维被损坏。表3-1:碳纤维弹性材料常数e11e22=e33g12=g13gpa19.8gpa29.2gpag23v12=v13v2392gpa0.280.32环氧树脂的弹性常数以及拉伸强度和压缩强度在表3-2中给出。拉伸和压缩屈服曲线分别在图45的分图(a)-(b)中给出。不同的拉伸和压缩行为表明可以实施抛物面屈服准则来捕获这种行为。表3-2:环氧树脂基质的材料常数evσtσc3803mpa0.3968mpa330mpa针对udcfrp的实验通过材料表征可以很好地了解相关材料。各种测试方法都可以提供cfrp属性,并为icme框架所做的预测提供验证数据。在本项工作中,确定了两种类型的实验来检测所提出的udcfrpicme框架的可预测性:(1)ud试件10°偏轴拉伸试验和(2)ud三点弯曲试验。udcfrp试件的10°偏轴拉伸测试:通过以下步骤制备udcfrp试件。ud平台的边缘(标称纤维体积分数为50%)用作确定切削10°偏轴方向的角度的参考。在应用市售丙烯酸粘合剂之前,先用磨纸制备试件的头部区域和接片(环氧树脂中编织玻璃纤维)表面(长度为50mm)。直径约为220m的金属线被用作试件和接片表面之间的间隔物。通过研磨形成大约16°的接片角。用水射流系统将样品切成标称宽度(w)为12.7mm、长度为210mm,在长度1=120mm的量规部分中得到的长宽比为9,如图46所示(样品001-005)。基于对水射流切割参数(即喷嘴直径、压力、速度、磨料粒度等)优化的初步研亢,选择了220m的磨料粒度和最低的平移速度,以最大程度地减少制造损失。在伺服液压试验机上以0.0167mm/s(1mm/min)的准静态加载速率进行了位移受控的拉伸试验。载荷是由位于测试框架底部的致动器引起的。在每次测试之前,已使用精密钢块对致动器进行旋转对准,以减少平面外的取向不良。用安装在金刚石夹爪表面上的防旋转套环以4mpa的压力将样品牢固地通过液压夹持。每侧的夹持长度在30mm至40mm之间。样品已与夹具中的样品挡块对齐。使用市售的哑光白色喷涂涂料处理所有样品以进行数字图像相关性(dic)测量,然后通过过度喷涂方法喷涂哑光黑色喷涂涂料以产生随机图案,如图47的分图(a)所示,其中示出了在l=120mm、w=12.7mm的样本上具有斑点图案的视场。用于应变测量的相关区域(彩色区域)在图47的分图(b)中示出。对于立体dic测量,使用了两个4.1兆像素(2048像素×2048像素)相机和35mm定焦镜头。图像采集速率为2赫兹。通过线相交法测量,分辨率为每个像素60m至70m,暗斑的大小约为232m(3.4像素)。样品的暗/亮比接近于1(54∶46)。对于数据分析,选择的子集大小为15像素,步长为6像素。参考图像是样品仅被顶部夹具夹住时在f=0kn的力下拍摄的。为了进行分析,已经使用市售dic软件包计算了工程应变。udcfrp帽形型材动态3点弯曲测试:本项工作中研亢的udcfrp帽形型材由dowaksa提供的a42纤维和纤维体积分数为50%的热固性环氧树脂模制而成。动态三点弯曲测试件品的几何形状显示在图48的分图(a)中。帽形型材的标称厚度为2.4mm,每层厚度约为0.2mm。帽形型材样品在热压机中变形并保持约5分钟以固化。用[0/60/-60/0/60/-60]s叠层(标记为0-60)制作该帽形型材。为了成功地进行测试,用betamate4601胶(dow)将具有相同叠层和厚度的背板胶合到帽形型材的底部,如图48的分图(b)所示。动态三点弯曲测试的设置在图48的分图(c)中示出。用胶带将样品稍微固定在下辊(直径25mm)上,以便在底部旋转。重量为25公斤、外径为100mm的撞击器以4.66m/s的初始撞击速度撞击该帽形型材。记录峰值撞击器加速度和撞击器力,以便与数值预测进行比较。udcfrpicme建模过程在icme框架中,以自下而上的方式对cfrp结构进行建模,如图44所示。在微观尺度上,udcfrp的微观结构被建模为rve。rve被压缩到微观结构数据库中,该数据库包含所有rve的rom。可以将rom放入由3d应力状态单元(例如砖形单元或厚壳单元)组成的任意宏观有限元模型。rom与宏模型相互作用,并实现能够在微观尺度和宏观尺度之间交换信息的多尺度模型。在本节中,将逐步提供用于icme过程的多尺度建模工作流程。icme多尺度建模工作流程为了说明icme多尺度模型的设置,使用了上述udcfrp试件的几何形状。udcfrp试件fe模型反映了真实的udcfrp试件。它复制了作为一对一复制品进行的偏轴拉伸实验。fe模型包含所有12个udcfrp薄片。这些薄片中的每一个被建模为在厚度方向(z方向)上具有2个积分点的单独一层厚壳单元,如图49所示。为清楚起见,有限元模型在厚度方向上放大了2倍。有限元模型包含49,420个单元和99,480个积分点。图49中的放大区域显示了四个选定的厚壳单元以及每个单元中的积分点。将由udcfrprve建模的udcfrp微观结构分配给每个积分点,以便计算外部载荷下的材料响应。为了说明微观结构数据库的多样性,将图49中用红色框标记的两个选定的积分点进一步放大以显示下面的微观结构。图50描绘了如何使用微观结构数据库来建模来自两个相邻积分点(如红色虚线框所示)的两个udrve。该数据库包含四种可能用于多尺度建模过程的rve设置。在图的右侧。在图50的右侧部分,每个rve周围的椭圆被用来指示由于周期性边界条件(pbc)的假设在rve的每一侧上都存在隐藏的相邻rve。第一种设置假定纤维和基质以及所有薄片之间都具有完美的结合。第二种设置假设薄片之间较弱的结合可以建模为内聚层。第三种设置假设纤维和基质之间的界面区域,其被建模为非零厚度的中间相。第四种设置假设纤维和基质之间存在界面区域,并且薄片之间存在较弱的结合。在本项工作中,由于完美结合的假设,仅并入了第一种设置。通过三步脱机数据压缩阶段将图50中所示的rve压缩到udcfrprom中。脱机阶段的详细信息将在后面的小节中提供。udrve建模固化的udcfrp层状平台由陶氏化学(dowchemical)制造,并且图51显示了显微镜下udcfrp的横截面。纤维用浅色显示,环氧树脂用深色显示。纤维随机地分散在环氧树脂基质中,总体积度量分数为50%。纤维不是正圆形,而是豆形,如图51所示。假设豆形符合椭圆域,则该椭圆的主轴由长度为7μm的白色线段测量,如图51的放大图所示。为了方便对纤维进行建模,假设直径为7μm的圆形。使用rve表征udcfrp的微观结构。一般来说,当rve足够大,通常是纤维直径的十倍时,纤维的随机分布不会显著影响rve响应。为了生成udrve,将纤维横截面简化为直径为7μm的圆形,并且假定纤维是完全笔直的。可以对udrve的横截面以2d方式进行建模,其中使用蒙特卡洛方法在2d域中随机填充圆,直到满足目标纤维分数。如果任何纤维的一部分位于rve的四个边缘之外,则该部分将以相反的方向重新出现以确保所有纤维的周期性分布,从而使rve符合pbc假设。然后将生成的2d网格通过正方形像素离散化。在图52中给出了用于生成udrve的2d网格的算法流程图。上面讨论的rve算法适用于纤维体积分数约为50%的udrve。对于更高的体积分数,需要专门的算法。这超出了本项工作的范围,因此不会进行详细讨论。最后,通过为所有像素分配厚度来拉伸2d网格,以生成3d体素网格。所产生的udrve在图53中给出。rve的分辨率为600×600×100立方像素,体素边缘长度为0.14μm。rve中产生了93根纤维。假定纤维是完全笔直的并且呈圆形的。为了利用udrve动态计算宏观fe模型中的应力响应,使用rom技术将rve压缩到微观结构数据库中。rom过程在以下各节中给出。还执行了rve横向拉伸载荷的dns。dns用于验证rom的效用,其与dns解相比,可以产生准确的结果。纤维和基质属性如上文所述。udrve的降阶建模由于具有良好的网格分辨率,上述udrve包含用于单个rve运行的大量dof。要使用udrve对udcfrp结构进行建模,由于昂贵的rve计算,计算成本无法承受。取而代之的是,将rom技术应用于udrve,以生成其rom。从理论上讲,与rve计算相比,rom将显著降低计算成本。使用sca方法为udrve生成rom。附录a中提供了sca的所有必要派生。在本小节中,我们将重点说明三步脱机阶段计算和联机预测阶段。脱机:脱机阶段始于通过体素网格进行离散化的高保真rve。应变集中张量a(x)通过以下关系将施加在rve上的宏观应变链接到每个体素:εm(x)=a(x):εm(3-2)其中,em是rve中任何体素的微观应变,εm是rve的施加宏观应变。a(x)是众所周知的应变集中张量。在voigt表示法下,εm和εm均为1×6向量。这意味着a(x)是一个6×6的矩阵。a(x)可以通过应用六个正交载荷条件(εm每次仅具有一个非零分量)来计算。这将允许a(x)一次被计算一列,并且六个载荷条件可以提供a(x)的全部36个分量。一旦计算了每个体素的a(x),就可以将无监督学习应用于rve中的所有a(x)以执行聚类。此过程会将由许多体素单元组成的原始rve压缩为几个聚类。对于具有纤维和基质相的udrve,纤维和基质相分别分解。纤维和基质相中的聚类数分别表示为kf和km。定义kf+km=k很方便。图50所描绘的针对udrve设置1和2的聚类处理在图54中示出。数据压缩过程是使用无监督学习方法(例如k-均值聚类)执行的。必须在所有聚类对之间计算相互作用张量dij。一旦计算了相互作用张量,就有可能通过求解离散化的李普曼-施温格方程来求解逐聚类的应变增量。联机:联机阶段涉及在方程式(3-3)中求解以下残差形式。sca联机阶段的详细信息在附录a中给出。其中,ri是每个聚类上应变增量的残差。可以通过先针对δεi对方程式(3-3)进行线性化并求解使ri最小化的δεi来使残差最小化。请注意,在本多尺度建模方案中,rom部署在复合层状结构的fe网格中的所有积分点上。在每个积分点,由fe求解器提供宏观应变增量δεm,并用方程式(3-3)求解逐聚类的应力和应变响应。均匀化的rve应力增量(表示为δσm)返回到fe求解器。dns与降序模型的比较用不同数量的聚类生成udrve的两组rom:1)纤维相中的2个聚类(kf=2)和基质相中的8个聚类(km=8);2)纤维相中的16个聚类(kf=16)和基质相中的16个聚类(km=16)。为了验证rom产生令人满意的结果,执行了最大0.02应变幅度的横向拉伸测试。同样的加载也应用于两个rom。图55中绘制了所有三种情况的应力和应变曲线。以95%的置信区间绘制dns结果。前面提到的第一rom和第二rom的结果分别表示为“sca,8聚类”和“sca,16聚类”。从图55所示的结果可以明显看出,两个rom都收敛于dns解决方案。为了节省udcfrp的并行多尺度建模的计算成本,在以下结构级别的模型中使用具有8个聚类的rom来达到平衡的准确性和效率。如上所述,实施抛物面屈服函数以便考虑环氧基质的不同拉伸和压缩行为。使用抛物线型环氧损伤模型对基质损伤进行建模。udrom利用纤维和基质来高效地计算udcfrp的材料响应。在ud结构建模中,将等效的损坏模型应用于所有rom,以仿真rve的损坏。rve在每个积分点的损坏将降低宏模型中每个单元的承载能力。当损坏超过0.5时,积分点将失去承载能力。当宏单元中的所有积分点都失去了承载能力时,宏单元将失效。udcfrp试件的轴向拉伸仿真模型设置利用上述所有可用信息,udcfrp试件多尺度模型如图56所示。在图56中示出了所应用的边界条件。在实验中,两个接片部分均用4mpa的压力紧紧夹持。相同的夹持压力应用于fe模型的两个接片部分。此外,上接片部的两个表面在y方向上固定,但是下接片部的两个表面被允许在y方向上移动。朝着负y方向的位移被施加到底部接片部分,使试件伸长,从而允许重复进行拉伸测试。可以看到fe试件模型保留了大多数实验条件。这与icme建模的目的一致,在icme建模中,对真实世界的零件进行建模并对其尽可能多的细节进行分析。udcfrp动态三点弯曲模型设置三点弯曲模型是用于验证所提出的udcfrp框架有效性的第二个测试案例。采用与udcfrp试件模型类似的方法。udcfrp帽形型材的模型如图57所示,其中使用了[0/60/-60/0/60/-60]s布局。如图57所示,ud层压结构的12层使用厚壳单元进行显式建模。这样的设置允许在撞击器的作用下捕获单个薄片的失败。至此,udcfrp结构的所有必要建模步骤均已完成。并行多尺度建模框架可用于测试上述问题。所有测试问题均以实际的几何形状建模,因此fe模型利用了两个测试中给出的相同边界条件。实验测试数据用于验证提出的udcfrp并行多尺度建模框架。该框架的预测能力是通过精心进行的实验来检验的。下一节将给出测试问题和相关讨论的结果。结果和讨论本节讨论了偏轴试件拉伸试验和三点弯曲试验的并行仿真结果。由于纤维体积分数相同,在两种情况下都使用上文所示的相同的udrve。udcfrp试件的轴向拉伸仿真在本节中,给出了并行多尺度10°ud偏轴试件拉伸仿真结果,并将其与实验结果进行比较。0.0167mm/s的加载速率使试件逐渐向下延伸。如图58所示,在变形过程中,形成了10°应力带。udcfrp试件偏轴拉伸仿真用于验证所提出的针对udcfrp材料的多尺度建模框架可以准确地预测系统行为。多尺度试件仿真和测试数据之间的比较针对的是:1)法向应力与法向应变;2)y方向位移;3)y方向应变。基于比较,解决了两个目的:1)验证针对udcfrp材料的多尺度建模框架;2)证明本udcfrp多尺度模型具有相当好的预测能力。对于fe模型,法向应力是使用在标称横截面面积除以原始试件横截面面积的反作用力来计算的。在仿真过程中记录了试件的顶部接片区域附近的横截面的反作用力。然后将反作用力用于计算多尺度模型的法向应力。量规长度的变化用于计算法向应变。多尺度模型的法向应力与应变在图58中以蓝点形式绘制。将多尺度模型的应力和应变曲线与实验数据进行比较,可以观察到二者匹配的很好。预测趋势与实验数据相同,如表3-3所示。预测的最大应力为404.81mpa,接近实验数据报告的395.64mpa。此外,模型预测的最大应变为0.011,再次与实验测量值0.012匹配的很好。两种预测的有关物理量均与实验测量值相差10%以内,这意味着udcfrp并行多尺度模型已得到实验数据的验证。表3-3:偏轴ud试件样本的预测最大法向应力和应变最大法向应力(mpa)最大法向应变实验395.640.012预测404.810.011差值2.32%8.33%图59:a)y位移和b)y应变场的等值线图。在预测和dic上应用的位移为0.9031mm。在位移图a)中,两个黑色箭头衡量条纹之间的垂直距离,范围在-0.250mm和-0.700mm之间,差值为3.95%。在灰度应变等值线图b)中,预测的应变场与dic相当。预测和dic图像之间的差异是由真实udcfrp材料中的微观结构变化引起的,这可能导致真实样品中的应变集中。y方向的位移和应变场由实验结果验证,如图59的分图(a)-(b)所示。图59的分图(a)中的黑色箭头表示条纹之间的垂直距离为-0.250mm至-0.700mm。多尺度模型所做的预测为80.26mm,与dic的测量值83.57mm相差3.95%。如图59的分图(b)所示,预测的y方向应变屈服等值线图与dic测量非常相似。两种应变场等值线图在试件中间都显示出一条清晰的带。由于制造过程中不可避免的微观结构变化,dic应变场高度不均匀。但是,由于预测的位移和应变场与实验结果一致,因此结果令人鼓舞。此外,在图60的分图(a)-(b)中分别描绘了预测的裂纹形成和实际的试件裂纹形成。在图60的两个分图(a)-(b)中,裂纹一直延伸跨过试件量规部分。如图51所示,因为数值模型尚未考虑局部微观结构变化,所以预测裂纹的图案不是实验结果的精确复制。在将来的工作中,将在建模过程中考虑局部微观结构变化,以解决对宏观性能的不确定性影响。尽管如此,如表3-3所示,icme模型能够提供关于试件最大应力和应变的准确预测,以及失效型态的预测。icme模型所做的预测与实验观察结果一致,这为针对icme工艺提出的多尺度建模方案的预测性提供了信心。icme多尺度建模方案已通过上面讨论的实验数据得到验证。然而,所提出的多尺度建模方案的能力超出了对宏观物理量的准确预测这一范围。它还提供了udcfrp结构的详细微观结构演变,用于研亢ud试件失效的根本原因。图61利用三个快照示出了本地udcfrp损坏过程。在图61的分图(a)-(c)中示出了标记成红色的区域的放大图,其中y轴位移为1.40mm、1.41mm和1.42mm。在图61的分图(d)-(f)中示出了代表用黑色标记的单元的udrve。在图61的分图(e)中,所有三个rve都遭受了基质损坏,表明试件失效的潜在原因。在图61的分图(b)中,底部元件的应力等值线从绿色变为蓝绿色,表明承载能力降低。这是由于中部和底部rve的基质破坏加剧,如图61的分图(e)所示。在图61的分图(c)中,由于失去了承载能力,中间和下部单元已标记为失效,而顶部单元仍然能够承载载荷。然而,如图61的分图(f)所示,顶部的rve也遭受了严重的基质损坏,这意味着该rve将很快失效。图61中的udrve微观结构演变为了解微观损伤过程提供了宝贵的信息。此外,udrve应力和损伤演变是和宏观ud试件仿真同时捕获的。将来,可以将现场监测技术与现有的建模功能结合起来,以进一步验证ud的微观结构失效过程使用图61中所示的详细的微观结构演变信息,发现了通往udcfrp设计的路径。例如,可以设计基质强度以避免在较小的加载量下损坏基质。或者,可以设计中间相属性并将中间相区域合并到模型中,以检查udcfrp的中间相效应和分层行为。ud三点弯曲模型为了进一步说明并行方案的有效性,还执行了ud三点弯曲模型并行仿真。仿真和实验的破裂的帽形型材在图64中示出。ud三点弯曲仿真用于检查所提出的方案对任意udcfrp结构的适用性。选择两个物理量进行比较:撞击器上的峰值载荷和峰值撞击器加速度。由于三点弯曲仿真中帽形型材的剧烈振动,基质已简化为具有脆性失效的弹性材料,其中失效强度设置为压缩强度,如表3-2所定义。撞击之后,将来自数值预测和实验结果的帽形型材分别绘制在图62的分图(a)-(b)中。黄色椭圆形标出了帽形型材的损坏区域。可以看出,撞击力将材料向内推动,导致两个侧壁上的帽形型材脱层。在数值模型和实验结果中观察到的相似趋势进一步表明,多尺度模型可以为ud结构上的失效型态提供良好的预测。icme过程可用于预测复杂载荷条件下ud结构的响应。除了ud结构变形和失效的良好匹配之外,表3-4中还报告了对撞击器上的峰值载荷和峰值撞击器加速度的定量比较,与实验数据进行对比。可以看到预测数据与实验数据之间的合理匹配。具体来说,峰值载荷和峰值撞击器加速度的相对差分别为8.21%和2.82%。两种预测均与实验数据相差10%以内,这为使用icme框架预测宏观性能指标提供了信心。表3-4:撞击器的峰值载荷和加速度峰值载荷(n)撞击器峰值加速度(m/s2)实验103280.39预测94800.379差值8.21%2.82%在图62的分图(a)中,以宏观尺度描绘了帽形型材的失效。在复杂的宏观结构演化之下,以并行方式捕获局部rve响应,其为帽形型材的微观演化提供了额外的信息。为了说明ud微观结构中的冯·米塞斯应力演化,对图63中示出的代表三列单元的rve进行可视化。这三列单元显示在图62右侧的放大视图中。每列包含12层ud薄片,其中每个薄片用1个udrve进行可视化。如图63所示,每个ud薄片上的纤维取向均按颜色编码。遵循薄片取向,将所有udrve与按照颜色代码所指明的纤维方向对齐。所有ud层从上到下依次记为第1层到第12层。撞击器下的帽形型材变形和冯·米塞斯应力等值线图在图64的上半部分示出。在以下位置拍摄隐藏了撞击器和支撑物的三个不同快照:撞击器位移4.85mm;撞击器位移6.85mm。在图64的分图(a)的上半部分中,撞击器接触帽形型材并在接触区域立即引起应力集中。在图64的分图(b)-(c)中,可以看出,在帽形型材接触撞击器之后,帽形型材的顶部和两个侧壁向内弯曲。撞击器向内推动udcfrp帽形部分的中间,以仿真复合结构在外部载荷条件下的场景。相应的rve冯·米塞斯应力等值线图显示在图64的分图(a)-(c)的下半部分。可以看出,udrve可用于研亢ud微观结构的层间应力分布。由于帽形型材层压结构中的纤维取向不同,冯·米塞斯应力的大小在整个厚度方向上随层的不同而变化,这可能导致那些应力较大的层更早失效。图64的分图(b)中所示的rve图表明位置1中的第二层和第三层与其他层相比具有更大的应力。在图64的分图(c)中,由于应力大小为零,所以这两层都已失效。这表明,多尺度建模在预测复杂的udcfrp层压结构的微观结构演变方面具有巨大的潜力。此类信息可用于使用能够检查宏观和微观材料性能的虚拟验证功能来检查各种udcfrp层压设计。这可以通过消除某些性能指标表现不佳的设计或具有不良微观结构演变型态的设计来辅助cfrp设计过程。对于udcfrp材料,了解微观结构失效机理可为改进cfrp设计提供有价值的信息。类似于udcfrp试件模型,在图65的快照视图中捕获并显示了不同的撞击器位移下帽形型材的微观结构演变。在图65中,对表示两个标记区域的两个udcfrprve进行可视化。可以看出,当dy=5.91mm时,上层中的rve开始受到损坏,而下层中的rve则保持完整,如图65的分图(a)所示。当上层失效时,相邻区域将朝新形成的空区域塌陷,并且相邻单元将压缩下层。不久,当dy=6.13mm时,下层也会失效,如图65的分图(b)所示。最终,两层都失效,如图65的分图(c)所示。这三个快照说明了为结构级仿真引入udcfrp的详细微观结构演变的能力。这些信息可以为cfrp结构设计提供指导,以防止局部损坏以改善结构性能。在本小节中,使用所提出的多尺度建模框架解决了udcfrp试件10°偏轴拉伸测试多尺度仿真和udcfrp帽形型材三点弯曲测试的一对一复制。两种模型都对照实验数据加以验证,以进行框架验证。数值方法所做的预测与实验数据相比相差在10%以内。该样的一致性表明本项工作可以用于预测其他udcfrp层压结构。此外,同时捕获微观结构演变为ud层压板的fe模型中的任何位置提供了微观结构演变历史。这使研亢人员能够查看很难通过实验捕获的详细的微观结构演变,找出结构层面上的失效原因。然后可以设计新的微观结构以承受载荷并改善整体结构性能。简而言之,该示例性研亢为udcfrp材料引入了一种可预测且高效的icme多尺度建模框架。详细说明该框架的主要工作流程,并提供实验验证。可预测框架将udcfrp微观结构链接到结构级模型,以准确预测结构性能。使用所提出的icme建模框架,提出了两个样本案例研亢,即ud偏轴拉伸测试和ud帽形型材动态三点弯曲测试。根据实验数据验证预测的性能指标,从而确认了良好的一致性。由udcfrprve捕获ud结构中的微观结构演变,揭示了微观结构演变,包括应力轮廓和基质损伤。icme框架是通用的,可以应用于其他纤维增强聚合物(frp)系统,例如玻璃纤维增强聚合物,以预测结构性能。除微观结构信息外,本示例中介绍的工作还应为现有的基于实验的复合材料设计工作流程提供指导,以加快设计过程。本udcfrp多尺度建模框架的未来工作包括:1)将中间相并入udrve中以进行纤维基质剥离。2)考虑微观结构的不确定性,例如纤维错位和纤维体积分数,以定量测量微观结构的影响。3)扩展到其他复合材料系统。示例4数据驱动的具有晶体可塑性的非均质材料的自治聚类分析要分析复杂的异质材料,需要一种快速且准确的方法。这意味着要超越传统的有限元方法,以寻求使用适度的计算资源来计算以前即使在大型聚类计算机中也不可行的解决方案的能力。详言之,这种进步是由复合材料设计推动的。在这里,我们将相似的原理应用于另一种复杂的异构系统:增材制造的金属。金属增材制造(am)的复杂度和潜在收益为机械材料模型的开发提供了丰富的基础。这些模型通常基于金属塑性的有限元建模。粉末床am使用大功率激光或电子束来逐层熔化粉末,以生成3d模型文件指定的任意几何形状。这种方法消除了对特殊工具的需求,从而达成了定制零件和产品的快速实现。它为拓扑和材料优化引入了新的可能性,但是这些任务需要高度的知识和应用该知识(即,充分控制构建条件)的能力。该过程涉及大量且重复的局部能量输入,导致具有复杂微观结构的不均匀、各向异性、位置相关的材料属性。多尺度建模的永恒挑战是以高效和准确的方式根据微观结构构象和属性预测宏观行为。诸如混合法则和其他微力学方法之类的分析方法非常高效,但会失去准确性,尤其在处理不规则形态和非线性属性时更是如此。相反,直接数值仿真(dns)可以提供很高的精度,但代价是计算成本过高,以至于它们不适用于材料设计的并行仿真。最近,数据挖掘已被引入机械界,以解决dns和分析方法的局限性。通常,数据挖掘是发现大型数据集中的模式的计算过程。一旦提取出来,这些模式就可以用来预测未来的事件。机器学习方法是数据挖掘的技术基础,例如聚类和回归方法。最近,数据挖掘也已应用于异构材料的建模。首先,通常从先验的数值仿真中生成或通过实验来获得用于学习的原始数据集。根据原始数据集的类型,当前数据驱动的建模方法主要可以分为宏观和微观两种。在宏观方法中,输入数据通常是每种成分的材料属性、载荷条件和代表微观结构几何形状的统计描述符,而输出数据是直接数值仿真(dns)得到的宏观机械属性。但是,宏观方法的预测的准确性和顺畅性由于缺乏微观信息而受到限制。例如,对于塑性和损伤预测理论至关重要的局部塑性应变场不能用它们的场均值很好地表示。为了解决这个问题,微观方法收集了dns中每个离散点的数据。值得强调两种基于所收集本地数据进行预测的方法:(1)非均匀变换场分析(ntfa)和(2)适当正交分解(pod)方法的变体。对于这两种方法,载荷条件下的预测都是通过对从先前在各种载荷条件下完成的仿真所获得的有限数量的rve模式进行线性组合得到的。很好地建立了本征模态的线性组合,但是对于非线性材料的插值需要付出额外的努力。对于ntfa,必须为非弹性场的每种模态假设内部变量的特定演化规律。对于基于pod的方法,需要进行大量的先验仿真,以保证在任意载荷条件下插值的稳定性。但是,这仍然总体上降低了计算成本。该示例性研亢的目的之一是提出一种晶粒级晶体可塑性模型,以捕获局部微观结构,例如在am中出现的局部微观结构,如空隙和圆柱状晶粒。在一个实施例中,基于数据挖掘的理论并且最初为复合材料开发的最近引入的材料建模方法被用来极大地提高这些仿真的速度。这允许更高的细节度或更大的关注区域,这两者都有利于预测零件内的损伤和疲劳起始。该示例性研亢基于两阶段方法,该方法使用聚类和后续的变形分析,并且能够以高精度和高速度解释异质材料行为,称为sca。它是一种数据驱动的方法,旨在减少预测异质材料的宏观行为所需的计算自由度(dof),而部分地基于聚类在引起较大应力梯度的特征附近保留局部信息。基本思想是通过假设感兴趣的局部变量(例如,弹性应变、塑性应变和应力)在每个变量中都是均匀的,而在具有相似机械响应的材料点聚类上(并非在每个材料点处)求解平衡方程。该方法的两个阶段是:脱机(训练或聚类)和联机(预测)。在脱机阶段,使用基于机械相似性的数据挖掘技术(例如k-均值聚类)将材料点分组为聚类。为了进行联机计算,使用格林函数(称为李普曼-施温格方程)以积分形式编写了平衡方程。使用自洽方案为每个聚类求解该方程,以确保精度,其中迭代更新参考刚度以使其与宏观有效刚度保持一致。sca的主要优点是与dns相比,dof大大减少了,同时保留了本地和全局响应信息。在这里,我们将这种方法扩展到适用于晶体可塑性(cp),这是一类计算方面的可塑性问题,它是根据材料的微观结构专门制定来捕获结晶固体的变形力学信息的。已经针对宏观问题(例如预测深拉时的耳形)和微观问题(例如纳米线的变形)推导出了各向异性材料模型(例如cp)。sca框架脱机阶段:机械材料表征通过使用聚类方法对材料点进行域分解,可以将具有相似机械行为的材料点分组到单个聚类中。首先,两个材料点之间的相似性是通过应变集中张量a(x)来测量的,其定义为:εmicro(x)=a(x):εmacroinω1(4-1)其中,εmacro是宏观弹性应变,对应于代表体积单元(rve)的边界条件;εmicro(x)是微观尺度rve域ω中点x处的弹性局部应变。对于二维(2d)模型,a(x)具有九个独立分量,需要在三种个正交载荷条件下进行一组弹性直接数值仿真(dns)来唯一界定。对于3维(3d)模型,a(x)具有36个独立分量,这些分量由dns在六种正交载荷条件下确定。一旦计算出应变集中张量,它就与线弹性材料的载荷条件无关,并且其弗罗宾尼斯(frobenius)范数在坐标变换下是不变的。对于非线性塑性材料的整体响应,我们证明了弹性应变集中张量是一个很好的脱机数据库。但是,如果对局部响应更感兴趣,则弹性应变集中张量通常不会在高应变集中区域附近提供足够高的聚类密度。在具有晶体可塑性的多晶材料中,所有晶体均在弹性状态下均匀变形,因此无法提供有效的数据来计算应变集中张量。在这些情况下,可以选择其他类型的材料响应来构建脱机数据,从而在感兴趣的区域获得足够的分辨率。例如,在需要局部可塑性信息(例如用于预测疲劳起始)时,我们从dns计算中选择塑性应变张量进行聚类,。我们展示了不同材料响应的选择是如何影响整体响应预测的。k均值聚类方法用于基于分组度量对数据点进行分组。目前,让我们将其视为应变集中张量a(x)。由于假定聚类中的所有材料点都具有相同的机械响应,因此自由度的数量从例如fem仿真中的单元数减少到聚类数。注意,聚类是基于应变集中张量形成的,因此不需要在空间上彼此相邻。与域分解相关的主要假设是,每个局部变量β(x)在各个聚类内都是均一的。在全局上,这相当于rve中的变量具有逐片(piece-wise)均一的等值线:其中,βi是第i个聚类中的均质变量,k是rve中的总聚类数。第i个聚类的域ωi通过其特征函数χi(x)来区分,定义为:方程式(4-2)中的逐片均匀逼近使我们能够减少李普曼-施温格方程的自由度数,该李普曼-施温格方程在下面的联机阶段中求解。在基于先前的dns进行域分解之后,脱机阶段的剩余任务是预先计算所有聚类之间的相互作用张量。在离散化/简化的李普曼-施温格方程中,我们可以利用逐片均匀假设来提取相互作用张量dij,该张量表示第j个聚类中的应力对第i个聚类中的应变的影响。在具有周期性边界条件的rve域ω中,可以将相互作用张量写为格林函数和方程式(4-3)中所定义特征函数的卷积:其中,ci是第i个聚类的体积分数,|ω|是rve域的体积。φ0(x,x′)是与各向同性且具有线弹性的参考材料相关联的四阶周期格林函数,其刚度张量为c0。具体而言,该参考材料在联机阶段作为均质介质被引入,以表述李普曼-施温格积分方程。随着rve的周期性,φ0(x,x′)在傅立叶空间中呈现以下形式:且其中,ξ是与实空间中的x对应的傅里叶空间中的坐标,δij是克罗内克函数。λ0和μ0是参考材料的拉梅常数。在频率点ξ=0时,的表达式定义不明确。通过施加用于推导格林函数的边界条件,均匀分布的极化应力场不会在rve内部引起任何应变场。结果,我们得到:基于方程式(4-5),可以使用傅立叶变换将方程式(4-4)中空间域中的卷积项转换为频域中每个点ξ的直接乘法,从方程式(4-6)可以看出,和与材料属性无关,因此可以在脱机阶段对其进行一次计算。如果联机阶段在自洽方案中参考材料发生变化,则仅需要更新与方程式(4-5)中的参考拉梅常数有关的系数。对于微观结构尺寸接近rve大小的rve或者甚至具有相连的微观结构网络(例如编织复合材料)的rve,需要进行修正dij以满足rve上的边界条件。当前,我们已将sca脱机阶段应用于具有均匀(规则六面体或“体素”)网格的2d和3d材料,以便可以使用快速傅里叶变换(fft)方法高效地计算方程式(4-9)。尽管域分解基于脱机阶段中每个材料相的特定属性选择,但相同的数据库可用于预测联机阶段中材料成分新组合的响应。联机阶段:自洽李普曼-施温格方程通过引入均质的参考材料,rve中的平衡条件可以表示为连续的李普曼-施温格积分方程,δε(x)+∫ωφ0(x,x′):[δσ(x′)-c0:δε(x′)]dx′-δε0=0(4-10)其中,δε0是控制局部应变演化的远场应变增量。它在rve中是均一的。参考材料是各向同性且具有线弹性。其刚度张量c0可以由两个独立的拉梅参数λ0和μ0确定:其中,i是二秩等同张量,ii是四秩等同张量的对称部分。应变和应力增量为δε(x)和δσ(x)。通过对rve域q中的增量积分方程式(4-10)进行平均,我们得到:通过施加用于推导格林函数的边界条件,可以将方程式(4-8)等效地写为:∫ωφ0(x,x′)dx=0(4-13)通过将方程式(4-13)代入(4-12)得到:这表明远场应变增量始终等于rve中的整体平均应变增量。为了在积分方程,即方程式(4-10)中求解δε(x),需要宏观边界条件的约束。宏观应变约束可以写成:其中,是应用于rve上的宏观应变增量。类似地,宏观应力约束可以与宏观应力相关,对于更一般的情况,还可以制定混合约束(例如,方向11的应变约束和其余方向的应力约束)。由于连续李普曼-施温格方程的全场计算(例如基于fft的方法)可能需要过多的计算资源,因此我们将在脱机阶段基于域分解执行积分方程的离散化。通过方程式(4-2)中的逐片均匀假设,可以减少新系统中的自由度数量和内部变量数量。分解后,第i个聚类的离散积分方程为:其中,δεj和δσj分别是第j个聚类中的应变和应力增量。相互作用张量dij在方程式(4-4)中定义,与参考材料的格林函数有关。离散化后,远场应变仍等于rve中的平均应变,宏观边界条件也需要离散化。例如,宏观应变约束的离散形式可以写成:在新的简化系统中,未知变量是每个聚类δεi中的应变增量。聚类比fe节点少得多,这意味着rom求解更快。在一般情况下,例如塑性情况下,应力增量δσj是其应变增量δεi的非线性函数,使用牛顿法来迭代求解每个增量的非线性系统。连续李普曼-施温格方程(4-10)的解与参考材料c0的选择无关。这是因为物理问题完全由平衡条件和规定的宏观边界条件描述。但是,由于逐片均匀假设,对于离散化的方程,rve中并非每个点均严格满足平衡条件,并且简化系统的解取决于c0的选择。可以通过增加使用的聚类数来减少这种差异,其代价是因自由度增多而导致的计算成本上升。为了同时达到效率和准确性,我们在联机阶段提出了一种自洽方案,该方案通过较少的聚类保持准确性。在该自洽方案中,参考材料的刚度张量c0与均质刚度张量c大致相同,c0→c(4-20)材料的非线性通常导致无法确定精确匹配的各向同性c0。在这里,我们提出两种类型的自洽方案来近似方程式(4-20):1)平均应变增量和应力增量的线性回归(或基于回归的方案);2)有效刚度张量c的各向同性投影(或基于投影的方案)。基于回归的自洽方案在基于回归的方案中,自洽方案被公式化为一个优化问题:目标是找到使预测的平均应力增量之间的误差达到最小的各向同性c0。回归算法的输入是平均应变增量和应力增量它们的计算公式如下:基于回归的方案的目的是通过计算来求出参考材料的λ0和μ0其中,对于任意二秩张量z来说,||z||2=z:z。函数f(λ′,μ′)可以表示为其中,i是二秩等同张量,ii是四秩等同张量的对称部分。等效地,优化问题的成本函数g(λ′,μ′)可以写成:通过成本函数的各个偏导数找出最佳点:其根据拉梅常数形成了由两个线性方程组成的系统。除了在纯剪切载荷条件下(其中λ0欠定)之外,该系统始终具有唯一解。在这种情况下,λ0的值不会更新。另外,当有效的宏观均质材料也是各向同性且具有线弹性时,g(λ0,μ0)消失。尽管此方案不需要显式计算c,但它有两个主要缺点。第一,对于静水压力和纯剪力载荷条件,优化问题是欠定的,因此必须假定两个独立的弹性常数之一。第二,更重要的是,对于并行仿真中的复杂载荷历史,最佳参考材料的模量可能为负,这对定点方法的收敛是不利的。基于投影的自洽方案为了避免基于回归的方案的难点,我们提出了另一种基于有效刚度张量c的各向同性投影的自洽方案。通过均质化,rve的有效刚度张量c可以表示为其中,是第i个聚类中材料的算法刚度张量,并且是聚类中当前应变增量的局部本构定律的输出,第i个聚类ai的应变集中张量将第i个聚类中的局部应变增量δεi与远场应变增量δε0相关联,δεi=ai:δε0(4-28)其可以通过首先使用对离散积分方程(4-17)进行线性化、然后反转雅可比矩阵来确定。由于该自洽方案只需要c,因此在牛顿迭代收敛后,可以进行一次计算g,以节省计算成本。对于3d问题,各向同性参考材料的刚度张量c0可以分解为:c0=(3λ0+2μ0)j+2μ0k(4-29)其中,第四张量j和k被定义为:由于两个张量仍然正交,我们得到:j::k=0,j::j=1,k::k=5(4-31)基于方程式(4-31),从均质刚度张量c到c0的投影可以表示为:同时,也可以根据各向同性投影确定参考材料的拉梅参数λ0和μ0。由于c0直接基于c取近似值,所以确保在条件c下其是正值。总的来说,可以将基于投影的方案视为基于回归的方案的简化版。联机阶段总结在这两种方案中,必须迭代确定最佳参考材料,因为方程式(4-26)中c的值是通过用先前c0求解简化系统而获得的。在此采用定点方法。对于这种方法,根据我们的经验,参考材料参数的收敛只通过几次迭代就可以实现(即,少于五次迭代可达到0.001的公差)。求解自洽李普曼-施温格方程的通用算法如下:1.初始条件和初始化:设(λ0,μ0);{ε}0=0;n=0;{δε}new=0;2.对于载荷增量n+1,更新参考材料c0的相互作用张量dij和刚度张量中的系数;3.开始牛顿迭代:(a)根据局部本构定律计算应力差{δσ}new;(b)使用应力差计算离散积分方程(4-17)的残差:{r}=f({δε}new,{δσ}new);(c)计算系统雅可比{m};(d)求解线性方程{dε}=-{m}-1{r};(e){δε}new←{δε}new+{dε};以及(f)检查错误标准;如果不符合,则转到3(a);4.使用基于回归的方案(4-22)或基于投影的方案(4-32)计算(λ0,μ0);5.检查错误标准;如果不符合,则执行步骤2;6.更新增量应变和应力:{δε}n+1={δε}new,{δσ}n+1={δσ}new;更新载荷增量索引n←n+1;以及7.如果仿真未完成,请转到步骤2。使用相对于残差的l2范数的相对迭代误差准则。如果材料的所有相都具有线弹性,则牛顿迭代将一步收敛。注意,如果在计算中未使用自洽方案,则将使用恒定刚度张量c0,可以选择该常数张量与基质材料相同。在这种情况下,c0不更新,意味着相互作用张量dij不需要更新,并且算法中的步骤4-5也可以跳过。尽管具有常数c0的算法可以在求最佳值c0方面节省时间,但是使用少量聚类无法保证预测非线性材料行为的准确性。晶体塑性模型在本项工作中,我们提出了一种结晶材料的机械响应的弹塑性、各向异性、非均质可塑性模型,应用于上述sca框架中。力学模型是所谓的晶体可塑性(cp)本构定律的一种实现方式。其中用于解决平衡方程的变分形式的有限元方案由sca方案及其fft基础取代。因此,在某些方面,这开始类似于最近的cp-fft公式,并增加了上面概述的脱机/联机分解功能。简要概述遵循经典可塑性和有限元方法的早期组合,已将结合有限元方法的晶体可塑性(称为cpfem)应用于解决微观和宏观问题。它具有两个主要变体:多晶和单晶可塑性。在多晶公式中,假定每个实质点代表一组晶体,以使该点的总体响应是均匀的。对于单晶可塑性,假设每个材料点代表一个单晶或单晶中的一个点,其变形由单晶变形机制(例如,活动滑移系统和/或位错运动)的特殊性决定。。前一种方法更常用于需要较大溶液体积的宏观问题。后一种方法是本研亢的重点。两种形式的晶体可塑性定律都有很多版本。这里讨论基本的动力学和本构定律。动力学变形梯度f可以相乘性分解为:f=fefp(4-33)其中,塑性部件fp将参考构型中的点映射到中间构型,然后通过弹性部件fe将其映射到当前构型。注意,物理上fp与位错运动有关,并且fe是弹性拉伸和刚体旋转的组合。通过将中间构型(通常用表示)中的塑性速度梯度与简单的剪切变形γ(α)相关联来对位错运动的影响进行建模:其中,是二元乘积;nslip是滑动系统的数量;是剪切速率;是滑动方向;是滑动平面法线,所有这些都是针对中间构型中的晶体滑动系统(α)而言的。和fp之间的关系由下式给出:本构定律构建晶体可塑性框架的最后任务是定义弹塑性的本构定律。我们从许多可用的共轭对中选择格林拉格朗日应变ee和第二皮奥拉-克希荷夫(piola-kirchhoff)应力se作为基础,用下式关联起来:其中,弹性刚度张量在中间构型中定义。使用由下式给出的每个滑移系统的塑性剪切速率的现象学幂次定律:其中,τ(α)是解析剪切应力;a(α)是描述随动硬化的背应力;是参考剪切速率,是导致各向同性硬化的参考剪切应力,m是材料应变速率敏感性。剪切应力通过以下方式分解为滑移方向:其中,σ、s(α)、n(α)分别是柯西应力、滑移方向和滑移平面法线,所有这些都处于当前构型中。柯西应力由下式给出:其中,je决定了fe。s(α)和之间的关系由下式给出:并且n(α)和之间的关系由下式给出:这样一来确保了在当前构型中,滑移平面法向矢量保持与滑移方向正交。参考剪切应力根据以下表达式演变:其中,h是直接硬化系数;r是动态恢复系数;qαβ是由下式给出的潜在硬化率:qαβ=χ+(1-χ)δαβ(4-43)其中,χ是潜在的强化参数。背应力a(α)根据以下表达式演变:其中,h和r分别是直接硬化因子和动态硬化因子。计算晶体可塑性算法需要求解方程式(4-33)到方程式(4-44)的一组非线性方程。可以使用不同的数值方法来求解这些方程。mcginty和mcdowell给出了使用有限元方法的材料定律的隐式时间积分算法。然而,sca方法使用了快速傅立叶变换方法,cp算法在该框架中也很有效。在这里,我们只是在sca和fem计算中实现了相同的晶体可塑性模型,尽管在计算变形梯度f的方式上略有不同。示例在本节中,将通过描述的cp例程来实现探亢sca功能的三个示例性实例。首先,对具有j2可塑性的多夹杂物系统验证了sca方法。其次,显示了单晶基质中球形夹杂物的简单实例。最后,通过仿真具有等轴、随机取向的晶粒的多晶立方体增加系统的复杂度。具有j2可塑性的多夹杂物系统首先使用更为简单的材料定律(j2可塑性)针对多夹杂物系统验证sca方法的有效性。夹杂物相具有弹性,杨氏模量ei=500mpa,泊松比vi=0.19。基质相具有弹塑性,弹性状态下em=100mpa且vm=0.3,根据有效塑性应变εp,其具有冯·米塞斯屈服面(j2可塑性)和逐片硬化定律:夹杂物彼此相同,并且夹杂物相的体积分数等于20%。高保真有限元模型的网格大小为80x80x80。基于应变集中张量a(x)的聚类结果如图67所示。基质和夹杂物中的聚类数分别用km和ki表示。请注意,a(x)有36个独立的分量,,这些分量需要在6种正交载荷下通过弹性仿真确定。由于夹杂物相的体积分数为20%,因此我们选择其中表示大于或等于口的最接近整数。针对单轴拉力和纯剪力载荷条件,图68示出由基于回归和基于投影的自洽方案预测的应力-应变曲线,其中实线表示供比较的dns结果。dns结果以实线绘制以便比较。对于这两种方案,通过增加系统中的聚类数,预测结果都收敛到dns结果,但是与基于有效刚度张量的各向同性投影的方案相比,基于回归的方案具有更好的准确性。通过加权投影可以大大提高基于投影的方案的准确性。对于这种80×80×80的网格,基于fem的dns通常在24核上花费25小时(最先进的高性能计算聚类,其中每个计算节点具有两个12核/处理器intelhaswelle5-2680v32.5ghz处理器)。在相同的载荷增量数下,sca降阶方法(在matlab中)在km的值分别为1、16和256时仅在一台inteli7-3632处理器花费0.1秒,2秒和50秒。具有晶体可塑性的球形夹杂物此处针对最简单的几何情况引入了晶体可塑性定律,该定律近似于3deshelby问题:嵌入无限(周期性边界)单晶基质中的球形夹杂物/空隙。几何形状的示意图在图69中示出。在导言中提供的am的背景下,可以将其视为零件内部出现的球形空隙。直径在1-2微米和50微米之间的此类空隙通常是由于在制造过程中沸腾和材料蒸发所致。为了对此建模,在球体内应用了几乎无限可压缩、非常低模量的材料定律,而对于基质材料使用cp模型。表4-3列出了一组晶体可塑性参数。软质夹杂物的杨氏模量和泊松比分别为500mpa和0.19。这些参数与fcc金属相当吻合,尽管尚未专门针对am材料进行校准。表4-1:fcc金属的晶体可塑性参数为了解决此几何形状的整体和局部响应,必须为域分解阶段做出适当的数据选择。使用应变集中张量和弹性响应可以在载荷历史记录中与dns解决方案进行合理的总体匹配,但是局部解决方案(靠近夹杂物)则不太匹配。如上所述,可以使用不同的变量来进行聚类。图70的分图(a)示出了弹性dns解决方案,图70的分图(b)示出了由应变集中张量构建的聚类。在可塑性开始时选择应变张量的可塑性部分,即图70的分图(c)中绘制的轮廓,导致图4d所示的分解。这将使夹杂物附近的聚类密度更高,并且我们将在未来的工作中表明,这将带来更加准确的局部解决方案。使用充分开发的塑性解决方案,图70的分图(e)给出了图70的分图(d)中所示的聚类。沿z方向施加单轴张力,直到整个系统完全屈服为止。相对于与全局轴对齐的坐标系,晶体以欧拉角ψ=0°、θ=45°、φ=0°(使用roe约定)取向。确定聚类之后,可以在联机阶段使用结合晶体可塑性的sca降阶方法(称为cpsca)来计算应力和应变的整体和局部解决方案。图71示出了图70中的聚类对应的整体解决方案。第一组解决方案在弹性区域非常匹配,并且在可塑性开始时开始出现细微的差异。与cpfem结果相比,基于弹性聚类和初始可塑性聚类的cpsca响应更硬,而基于充分开发的可塑性的方案响应更柔和。对于这种40×40×40的网格,在abaqus中作为用户材料实现的dnscpfem通常在24个核上花费4600秒。在相同的载荷增量数下,cpsca(在fortran中)在使用基质中的16个聚类的一台inteli7-3632处理器上仅需5秒。多晶rve在该实施例中,使用cpsca来预测rve的整体响应,该rve包括等轴的、随机取向的晶粒,其具有充分开发的塑性应变张量,该塑性张量被先验地计算为脱机数据库。这种rve的一个例子在图72中示出。图73示出了分别由cpfem和cpsca预测的总应力应变曲线的比较。图72分别在分图(a)和(b)中示出了20×20×20和40×40×40的体素网格中包括35个等轴、随机取向的晶粒(如反极图颜色图所示)的rve。图73示出了分别使用cpfem和cpsca的与示出了与网格尺寸和聚类数量的收敛。我们看到,当添加单元或聚类时,较粗粒度案例的总体响应收敛到非常相似的解决方案。当使用粒度非常粗的聚类(例如1个聚类/每晶粒)时,cpsca的响应比cpfem解决方案更硬。这不是一个例外的结果,因为sca使用基于李普曼-施温格方程的fft解决方案。平均应变为5%的s33的完整3d解决方案状态显示在图74所示的不透明度和颜色轮廓图中,其中分图(a)是cpfem的203网格,分图(b)是cpfem的303网格,分图(c)是cpfem聚类的403网格,分图(d)是35个聚类的403网格,分图(e)是70个聚类的403网格,分图(f)是140个聚类的403网格。在35个聚类的情况下,每个晶粒一个聚类,而140个聚类的情况下,每个晶粒四个聚类。不透明度与压力水平成正比。通过这种可视化,可以观察到内部的一些差异:在cpsca方法中,与总体应力更分散但是水平更高的cpfem解决方案相比,应力总体上更加集中,而集中区域之外的应力更低。在这两种求解方法中,对于所有网格尺寸和聚类数,应力都集中在具有高schmid因子的晶粒中。fem和sca解决方案的峰值通常在10%以内,而最小值相差更大。同样,在abaqus中作为用户材料实现的dnscpfem通常在24个内核上对于20×20×20、30×30×30和40×40×40网格分别需要587秒、5177秒和31446秒。在相同的载荷增量数下,在一个inteli7-3632处理器上分别使用1个聚类/每晶粒、2个聚类/每晶粒和4个聚类/每晶粒,cpsca(在fortran中)仅花费18秒、96秒和793秒。总而言之,我们提出了一种方法,可以大大降低与进行微观晶体可塑性仿真相关的计算成本,这种方法可用于校准均质模型或研亢与金属内的损伤或定位有关的过程的力学。这是由希望预测增材制造过程所引起材料的机械响应(一项最近广受关注的挑战)驱动的。在这些材料中,令人关注的是微观尺度和介观尺度因子(例如,不同尺寸的空隙,取决于物理位置的晶粒尺寸),因此需要一种快速预测相对较大体积的微机械解的方法。通过三个实例展示该方法:多夹杂物系统中的j2可塑性,嵌入单晶基质中的简单空隙状夹杂物,以及等轴晶粒的多晶rve。示例5预测成品橡胶性能的逆建模方法在此示例中,提出了一种将实验数据与中间相逆建模相结合的计算程序,以预测填充胶料化合物的属性。将基于fft的数值均化方案应用于高质量的填充橡胶3d透射电子显微镜(tem)图像,以计算其复数剪切模量。然后使用一种新颖的降阶建模(rom)技术将3dtem填充橡胶图像压缩到材料微观结构数据库中,该技术即自洽聚类分析(从训练和学习开始、然后通过无人监督学习进行数据压缩的两阶段脱机数据库创建,以及联机预测方法)),以提高效率和准确性。为了理解中间相行为,制定了一种逆建模方法来定量计算中间相复数剪切模量。两阶段sca和逆建模方法构成了一个三步预测方案,用于研亢填充橡胶,其损失切线曲线可以依照测试数据进行计算。与它们的基本成分相比,复合材料通常表现出改善的机械性能。这样的特征为创建特定的材料提供了一个窗口,以满足没有经过特殊处理的材料很难满足的要求。众所周知,聚合物纳米复合材料(pnc)的属性与纯聚合物组分不同,部分原因是聚合物和填料之间存在一个中间相区域。因此,可以通过将填料添加到聚合物组分(例如橡胶化合物)中来设计出特定的属性,从而实现与没有填料的纯聚合物不同的粘弹性行为。在该示例性研亢中,公开了一种用于高效评估填充橡胶属性和用于改善填充橡胶属性预测的中间相性能逆建模的计算框架。在橡胶和轮胎工业中,损耗角正切(或tan(δ))的减小会降低滚动阻力,而损耗角正切的增大会在轮胎与地面之间产生更大的摩擦。实验研亢表明,高分子化合物中的填料确实会导致pnc与纯高分子化合物具有不同的粘弹性行为。对于丁苯橡胶,炭黑填料的添加可降低低温区的tan(δ),但提高高温区的tan(δ)。此外,布林森等人使用不同填料对丁苯橡胶进行研亢,得出的结论是,填料增强了pnc的整体刚度,但降低了tan(δ)。因此,可以通过定制设计的聚合物纳米复合材料(pnc)或填充橡胶来实现各种轮胎属性。已经广泛研亢了pnc和纯聚合物之间粘弹性行为改变的原因。由于过去数十年来计算能力呈指数级增长,研亢人员能够利用分子动力学(md)仿真通过观察聚合物链与填料之间的相互作用,来捕获填料在高分子化合物中的作用。创建不同的聚合物层。聚合物链聚集在添加的填充材料周围,从而形成更致密的聚合物层。这样的结果归因于聚合物和填料之间的范德华相互作用。从md获得的结果与实验观察结果非常吻合,其中,与聚合物基质相比,中间相显示出更强的响应。为了表征聚合物结构的这种变化,可以使用中间相来区分pnc和纯聚合物化合物的不同粘弹性行为。在本项工作中,当前的工作中考虑了使用三相模型的填充聚合物系统:这些相是填料、中间相和聚合物。该三相模型应用于本项工作中研亢的填充橡胶样品。该模型应能够捕获填充和未填充橡胶之间的粘弹性能差异。橡胶属性可以通过动态力学分析(dma)进行实验测量。实验程序提供了橡胶混合物的粘弹性,即储存和损失模量。因而,dma提供了橡胶的整体均质属性。在数值上,可以通过各种均质化方法确定宏观属性。前述3dtem过程已应用于不同的填充橡胶几何形状,该几何形状已通过有限元(fe)方法进行了研亢,以获得局部应力响应。但是,在过去的这项工作中,由3dtem作为3d数字图像提供的填充橡胶几何形状仅转换为精细的fe网格,只能在超级计算机上使用。大尺寸的体素网格(例如3dtem提供的3d数字图像)更适合使用基于fft的数值方法进行计算均质化。数字图像可直接用于基于fft的算法中,以解决指定宏观边界条件下的局部和整体响应。因此,可以使用填充橡胶的3d图像通过fft算法直接获得填充橡胶的属性。现有的实验技术允许通过dma测量填充和未填充橡胶的tan(δ)曲线(也称为主曲线)。因此,如果假设填充橡胶是具有橡胶和填料相的两相模型,则可以使用未填充橡胶和填料的测量属性对其在不同频率下的响应进行数值仿真。在目前的工作中,中间相属性是未知的,这使得很难通过基本成分(未填充的橡胶和填充剂)来预测填充的橡胶的主曲线。在此示例实例中,我们将通过所谓逆建模技术的中间相建模与基于fft的高效均质方案相结合,以使用从3dtem重建的精细网格来计算填充橡胶的主曲线。通过实验结果验证主曲线,以说明我们提出的方案的有效性。对fft方法和sca进行比较,以检查这种基于降阶建模的方法的改进的计算效率。以下各节着重于填充橡胶的实验研亢和填充橡胶样品的3dtem重建,所用fft算法、sca方法、用于中间相属性计算的逆建模方案、以及结果和讨论的详细信息。我们展示了一种高效的集成实验和建模方法,该方法结合了fft均化算法,数据驱动sca和逆建模技术的优点。通过填充橡胶样品的3dtem重建和实验dma数据,我们可以了解填充橡胶组件的中间相属性。填充橡胶的实验研究未填充和填充橡胶样品的制备本研亢中使用的未填充橡胶样品由聚异戊二烯(ir2200)和一些化学试剂(例如硫、硬脂酸、微晶蜡、氧化锌等)制成。在混合的第一阶段,将聚异戊二烯和除固化剂以外的其他试剂进行混合。然后加入固化剂,例如硫。将聚合物和试剂的混合物在高温下固化以获得硫化的未填充橡胶样品。填充橡胶样品由聚异戊二烯、二氧化硅颗粒(zeosil1165mp)和一些化学试剂制成。其以相同方式制得,区别在于在混合的第一阶段中添加二氧化硅颗粒。这些橡胶样品的配方总结于表5-1中。表6-1橡胶样品配方(基于橡胶总重的重量比)未填充的橡胶样品填充的橡胶样品异戊二烯(ir2200)100100硫(交联剂)1.51.5其他试剂9.39.3二氧化硅(zeosil1165mp)无40填充和未填充橡胶样品的主曲线测量的实验结果通过动态力学分析(dma)(热分析仪,橡胶流变仪ares-g2)测量填充和未填充的橡胶样品的储能模量和损耗模量。使用直径为8mm、高度为6mm的圆柱形样品。在0.1%的振荡剪切应变下进行测量,其中材料响应在线性粘弹性区域内。为了在较宽的频率范围内获得粘弹性响应,在-60℃至40℃的温度范围内操作从0.5hz到50hz的扫频。通过将时间-温度与参考温度25℃叠加而获得主曲线,其中仅执行水平移动。从图75可以清楚看出,水平移动因子at的温度依赖性已由威廉姆斯-兰德尔-费里(wlf)方程很好地描述。图76、图77、图78分别示出了这些样品的储能剪切模量、损耗剪切模量和损耗角正切。填充橡胶样品的3d-tem重建使用聚焦离子束(日本电子株式会社,jem-9310fib)在-150℃的低温下将填充橡胶制成厚度约为100nm的薄片。将超薄部分转移到带有聚乙烯醇缩甲醛支撑膜的cu网格上。在电子显微镜实验之前,将直径为5nm的金颗粒置于胶体水溶液的超薄切片上。我们使用在200kv下运行的jem-2200fs显微镜(日本电子株式会社)通过tem和3d-tem进行了3d观察。该电子显微镜配备有慢速扫描usc4000ccd相机(美国加坦公司)。弹性散射的电子(电子能量损失:0±40ev)通过安装在显微镜中的能量过滤器(日本电子株式会社的ω过滤器)进行选择。在-66°到73°范围内的倾斜角度下,以1°的角度间隔获取一系列tem图像。随后,使用金纳米颗粒作为基准标记,通过基准标记法对齐这一系列倾斜的tem图像。对准后这一系列倾斜的tem图像通过滤波反投影(fbp)重建。在fbp重建之前,我们分别花费了大约2个小时和几天的时间在tem上拍摄140张tem倾斜图像并对齐这些投影。另外,已经完成了在将这些堆叠起来生成3d图像之前,将每个数字切片的图像中的填料与橡胶基质分开,这一过程通常需要1-2周。这里使用的基本方案与我们证明小于1nm分辨率,即0.5至0.8nm的方案基本相同。重建的填充橡胶示于图79中,其中以俯视图和正视图显示了测得的填料结构的3d图像,并且隐藏了橡胶基质材料。快速傅里叶变换均质化方案快速傅立叶变换方案的制定3dtem生成填充橡胶样品的高保真3d重建,作为具有亚纳米分辨率的3d数字图像,如前一节所述。3dtem的性质导致结构化体素网格非常大,由于分辨率高,因此很难进行fe计算。直接根据高分辨率3dtem数据生成fe网格,作为具有较大自由度总数的体素网格。为了使重建适合于fe分析,必须将3d数字图像转换为合适的网格。但是,这样的过程在实际模拟之前的预处理阶段需要额外的时间和资源。fft均匀化方案的最新发展为使用结构化网格解决边界值问题提供了另一种解决方案。fft均匀化方案避免了此转换过程,并可以使用来自3dtem过程的3d数字图像直接进行计算。尽管fft方案针对任意相位对比度的收敛性及其效率仍然可以提高,其是3d图像的强大均质方案。例如,fft方案无需进行fe方法所需的网格生成,并减小了问题的大小,因此可以在个人计算机上求解。尽管由于自由度总数的增加,较大的输入图像可能需要更大的计算机内存,但是当提供了高分辨率3d数字图像时,fft方案使方法变得更加容易。在该示例性实例中,我们首先基于方程式(5-1)所示的方程组,采用假设应变较小的fft方案。其中应用的位移场u*在计算域ω0上是周期性的。遵循线性动量守恒,任何输入网格的平衡条件如下所示:在fft方案中,输入图像中的每个体素代表一个材料点。体素的位置由x表示。通过fft方案计算所有材料点上的应力和应变张量。可以使用任何给定的本构定律来计算局部应力σ(x),但是现在我们以线弹性举例。为了求解方程式(5-2),fe方法将用有周期性边界条件公式化柯西动量方程。在这里,局部应变如方程式(5-1)所示。它由周期位移场u*梯度的对称部分和规定的宏观应变张量εmacro组成。通过引入极化应力τ和格林算子γ0,可以将局部应变表示为李普曼-施温格方程:在方程式(5-4)中定义了极化应力τ和傅立叶空间中格林算子的显式形式。其中,是各向同性参考材料的标准刚度张量,用参考拉梅参数λ0和μ0按照索引表示法写作其中,的索引与的索引一致。由于格林算子的显式形式仅在傅立叶空间中已知,因此借助方程式(5-6)中的傅立叶逆变换来计算方程式(5-4)中的卷积项。其中,和分别表示fft和逆fft。为了求解上述fft公式,可以使用各种迭代方法,例如定点迭代和共轭梯度。求解技术在文献中可大量获得。出于演示目的,附录a中使用定点迭代介绍fft算法。fft算法的迭代过程从给定的初始局部应变开始,并检查局部ε(x)的收敛性。在迭代过程中,格林函数实施方程式(5-1)中给出的兼容性条件。为了从网格中获得宏观应力和应变张量,按照方程式(5-7)进行遵循希尔引理的体积平均:为了获得有效的弹性材料属性μmacro和λmacro,如方程式(5-8)所示,将σmacro和εmacro插入胡克定律:通过求解(5-8)式可以方便地计算μmacro和λmacro。可以用矩阵格式重写方程式(5-8)并求解μmacro和λmacro。fft方案在频域计算中的应用通常,对于橡胶材料或粘弹性材料,在各种载荷频率下的响应都大不相同。dma是评估这一变化的常用实验方法。dma在不同的频率点ωk提供粘弹性材料属性,例如复数杨氏模量e*=e′+ie″,以及复数剪切模量。复数杨氏模量的实部e″与复数杨氏模量的虚部e’之间的比值给出了tan(δ)曲线。复数杨氏模量可以与复数剪切模量g*=g′+ig″互换。对于dma,将给定频率ωk的正弦应变应用于橡胶,并测量稳态应力以计算粘弹性材料的属性。在一维情况下,给定峰值应变下的应力可以写为:其中,对于任何复数z,都是z的实部。只需取即可求出σmacro(t)的稳态解。然后可以将稳态应力视为复数,记为由实部和虚部组成。对于一维情况,取σmacro,*和的商即为复数杨氏模量。相应地,可以通过输入复数杨氏模量基于fft方案计算复数应力。以上操作将在给定的频率点ωk上执行。要计算橡胶的tan(δ)曲线,需要不同的ωk的个别tan(δ)点,其中tan(δ)针对拉伸dma定义为针对剪切dma定义为因此,通过计算橡胶在不同频率点的响应,可以得到复数杨氏模量或剪切模量,然后可以计算出tan(δ)。当取足够数量的ωk时,可以重建填充橡胶的平滑tan(δ)曲线。在该示例性实例中,进行未填充橡胶和已填充橡胶的剪切dma以重建主曲线。但是,由于实验条件的限制,只能使用不同频率的复数剪切模量。一个假设是,对于复数剪切模量,向拉梅常数的转换仍然有效。通过输入基本成分(未填充橡胶和填料)的属性,可以使用fft方案在填充橡胶的各个频率点上计算tan(δ)。使用上文介绍的网格,可以在不同的频率点上使用未填充橡胶复合剪切模量和填料属性进行计算。为了使计算更可行,将填充橡胶区域在所有三个方向上缩小1/2到513×513×75体素,其中每个体素边缘的长度为1.62nm。未填充橡胶的泊松比取0.499,允许橡胶材料有限的可压缩性。请注意,在给定足够的来自材料表征的实验数据的情况下,可以通过选择频率相关的泊松比来达成玻璃态有限的可压缩性,从而改善上述假设。这将在以后的工作中解决。填充材料的杨氏模量e=300mpa,泊松比v=0.19。使用fft方案的均质复数剪切模量计算tan(δ)曲线。计算出的tan(δ)曲线和实验结果示于图80中。图80中的结果表明tan(δ)的预测和实验测量之间的不一致。从图中可以得出,在tan(δ)峰值之前,两相模型遵循的趋势与实验结果不同。在低频区域(小于1e5hz),tan(δ)低于实验测量值。在1e5hz和5e7hz之间,tan(δ)被高估。填充橡胶模型预测的g’和g″示出在图81的分图(a)-(b)中。在图81的分图(a)中,在低频区域(即1e1hz与1e5hz之间)的g’预测值比实验值小50%。在相同区域中,如图81的分图(b)所示,预测的损耗模量g″可以低至100%处于实验值以下。模拟和预测结果之间的这种差异导致较低的tan(δ),如图80所示。在1e5hz到1e7hz之间的高频区域,预测的储能模量相对于实验数据具有相同的50%差值,但预测的g″与实验数据之间的差值减小,从而导致g增大的趋势。这解释了为什么图80中所示的预测的tan(δ)在1e5hz和1e7hz之间为什么会高于实验数据。在高于1e7hz的频率区域中,预测的g’和g″均接近实验结果,从而给出了相对较好的tan(δ)预测。在图80中观察到的这种不一致是能够预见到的,因为输入网格仅考虑橡胶和填充相。如导言中所述,现有文献支持这样的假设,即在填料和纯橡胶之间存在应被视为第三种材料的中间相区域。具体而言,中间相在1e1hz和1e5hz之间的低频区域中,与未填充橡胶相比,应具有更大的g’。其在1e5hz和1e7hz之间的频率区域中,与未填充橡胶相比,也应具有更大的g’。原始的两相模型是不完善的,无法完全揭示填充橡胶的属性,但是基于重建的填充橡胶3d图像对中间相进行建模却需要这样的属性。在对原始填充橡胶网格中的中间相进行建模后出现的一个问题是,中间相的属性仍然未知。由于实验技术的限制,无法将中间相的粘弹性或复数杨氏模量或剪切模量作为已知输入给出。因此,我们提出了一种逆建模技术,以定量计算中间相属性,这将在下一节中进行介绍,目的是更好地预测填充橡胶的tan(δ)。但是,逆建模过程需要多次迭代,并且在所有迭代中都执行fft过程。这将带来相当高的计算成本。为了解决计算效率问题,还引入了降阶建模方法,以减少评估每个频率点的填充橡胶响应的计算成本。然后将降阶建模方法与逆建模过程相结合,以计算中间相属性和填充橡胶属性。关于填料模量的影响,附录c给出了具有300mpa(3e+8pa)到3gpa(3e+9pa)填料杨氏模量的相同填充橡胶结构的预测g’和g″。填充橡胶g’和g’的变化很小。这意味着预测的填充橡胶对填充模量不敏感。但是,由于fft算法对填料和基质材料之间的对比度很敏感,因此在本项工作中使用300mpa的填料杨氏模量。填充橡胶复合材料的高效降阶建模前面提到的fft公式能够计算填充橡胶的有效属性,但是它需要计算个别体素上的所有局部响应,因此需要很高的计算成本,尽管与fem相比已经要低得多。最近提出的sca方法为以合理的计算成本计算任意微观结构(例如填充橡胶复合材料)的有效属性提供了一种替代方法。在本节中,将讨论sca公式,以深入了解基于物理的降阶模型。sca是一种两阶段的降阶建模方法。在脱机阶段,执行两个步骤:1)根据对机械响应相似性的任意度量(例如应变集中张量)对网格中的所有体素单元进行聚类;2)然后,针对每对聚类计算相互作用张量。脱机阶段将生成一个材料微观结构数据库,其中包含聚类对之间的所有相互作用张量以及每个聚类的体积分数。脱机状态后,将原始的高保真rve压缩至少量聚类。在联机阶段,离散的李普曼-施温格方程将在任何给定的外部载荷条件下通过求解边界值问题来计算每个聚类中的应变和复应力,以及rve级平均复应力和应变。一旦确定了rve复应力,就会相应地计算出tan(δ)。该过程在图82中简明地示出。请注意,在上一节中,每个频率点的rve复应力是通过fft计算的。在这里,体素被假定为“一旦响应相同,就始终响应相同”。因此,脱机数据库可以一次构建。此后,该数据库可用于所有频点,以高效评估不同频点处的tan(δ)。方程式(5-3)中给出的李普曼-施温格方程可以在方程式(5-10)中用以下形式重新表示:其中,x是网格中体素单元的位置,x’是参考域中的位置。为了对填充橡胶复合材料执行降阶建模,可以通过将具有相似机械响应的体素分组在一起来减少网格中的整体自由度。这个过程也称为聚类。此处选择的一个方便的标准是众所周知的应变集中张量该张量将宏观的规定应变与每个体素上的局部应变响应相关联,如下面方程式(5-11)所示:其中,是沃伊特表示法表示的6x6矩阵。在原始rve上需要六种无牵引载荷,以确定的所有36个项。聚类算法(例如k均值聚类)可用于聚类所有体素,并将19,737,675个体素的原始域分解为k个聚类,其中k等于64。这是脱机阶段的第一步。可能会认为这是将总积分点减少到k,其中与原始网格中的积分点总数相比,k是一个较小的数字。请注意,不是聚类过程的唯一解决方案。对于不同的问题,可能希望使用其他有意义的物理量来标识具有类似机械响应(例如晶格方向)的体素。为了分解方程式(5-10)以合并新分解的域,可以方便地定义如方程式(5-12)所示的特征函数。其中i=1,2,3,...k。对于每个聚类,离散的李普曼-施温格方程在方程式(13)中给出。其中,ci是聚类i的体积分数,|ω|是网格的总体积。注意,σ(x′)和ε(x′)可以写为:则方程式(13)变为:其中,为:在脱机阶段过程(即聚类过程)的第一步之后,可以计算计算完成后,便完成了聚类过程的第二步,将原始rve压缩到由聚类和相互作用张量组成的微观结构数据库中。将插入方程式(5-13)将得到方程式(5-17)中离散的李普曼-施温格方程的最终形式:其中,增量形式为:联机阶段涉及方程式(5-18)的评估过程。附录b中给出了方程式(5-18)的求解过程,以供读者参考。由于积分点和自由度数量的减少,上述sca公式与方程式(5-9)相结合,以降低的计算成本来计算填充橡胶的有效复数模量。具有聚类的原始填充橡胶域的rom在图83中示出,其中每一相32个聚类。还生成了第二个rom,其中每一相64个聚类(共计128个聚类),但是为了节省空间并未示出。相应的主曲线在图84中给出,其中示出了与fft结果的比较。rom计算的主曲线显示了整体有效填充橡胶性能的趋势,该趋势与fft算法计算的结果一致。尽管sca高估了tan(δ)曲线,但对于64个聚类(填充相32个聚类,未填充橡胶相32个聚类)在计算时间大幅减少的情况下得到了结果,加快了924倍。下表2中示出了使用sca和fft的计算时间之间的比较。在图85中,由sca计算的填充橡胶g’和g″处于相同趋势。但是,sca可以节省大量的计算时间。fft和sca预测之间的差异在一个数量级之内,这意味着rom在聚类过程之后不会牺牲所有微观结构信息。fft和sca都预测出填充橡胶g’和g″的趋势相同,这意味着需要捕获中间相引起的偏差,如上一节所述。为了使用我们提出的降阶模型方法进一步研亢中间相属性,将上述过程集成到逆建模过程中,以更好地预测填充橡胶的属性。表5-217个频率点上的计算时间比较中间相的逆建模方案利用图84中所示的主曲线,明显可见,两相填充橡胶模型不足以表示真实的填充橡胶行为。计算出的tan(δ)曲线与实验测量值不一致的原因可归因于填充材料和未填充橡胶之间的中间相区域。因此,在下面的讨论中,考虑到填料和基质材料之间存在中间相。这应该会减小图84中绘制的tan(δ)曲线之间的差异。假定中间相在半径βip为9.74nm的球形区域中围绕填料。请注意此处假定中间相是均匀的,这意味着其厚度在整个区域内都是恒定的。对填充橡胶3d图像进行逐体素搜索,以将βip内的单元从基质转换为中间相。逆建模公式可以按照上述逐体素搜索过程创建具有中间相的填充橡胶模型,但是中间相的粘弹性行为仍是未知的。使用中间相抑制fft均化方案得到的主曲线与实验数据之间的不一致,因此必须计算其在不同ωk时的复数杨氏模量或剪切模量。为了用有限的实验数据预测未知的中间相属性,基于优化技术引入了所谓的逆建模方案。逆建模过程的目标函数可以写为:对于每个给定的ωk的目标函数状态,当预测的复数剪切模量g*,pmc(g*,ip,ωk)和g*,exp(ωk)之差最小时,求出中间相复数剪切模量g*,ip(ωk)的解。ωk为固定值时,可以为寻根过程定义一个函数如下:f(g*,ip)=g*,pmc(g*,ip)-g*,exp(5-20)其中,与方程式(5-10)相比,这里省略了ωk,因为求出了每个相关ωk的解。为了求解方程式(5-20),使用迭代方法来求出g*,ip(ωk)的解。为了应用牛顿迭代方法,可以按照方程式(5-21)来公式化(5-20)的导数:使用方程式(5-20)和方程式(5-21),可以将迭代过程写为方程式(5-22):其中,上标n表示当前迭代次数,n+1表示下一次迭代。中间相属性的初始猜测值设置为与未填充橡胶相同。具有中间相的填充橡胶模型的逆建模将所提出的逆建模方法应用于上述填充橡胶区域,以重新计算填充橡胶主曲线。网格是上面使用的网格,但是增加了中间相。将厚度βip=9.74nm的中间相(相当于6个体素)添加到域中,以创建具有中间相的填充橡胶模型。具有中间相的更新的填充橡胶网格示出在图86的左侧。上述三相模型的相应rom也已被构造并示出在图167的右侧。图86示出了rom在每一相具有32个聚类,这意味着整个填充橡胶网格被压缩为96个聚类。对于逆建模过程,在填充橡胶的整个主曲线的跨度中选取17个频率点。可以将更多点用于逆建模过程,但会增加计算成本。上文已经报告了测量填充的和未填充橡胶主曲线的实验程序。上文还介绍了未填充橡胶和填充材料的材料属性。将逆建模过程与sca联机预测相结合,是本方案的第三步。如此,提出了针对填充橡胶的三步预测方案。逆向建模的结果将在下一节中介绍和讨论。结果和对逆建模结果的讨论通过逆建模,在图87中示出了填充橡胶主曲线的更准确的预测。通过fft和sca方法预测的tan(δ)曲线与实测实验数据非常吻合。sca结果与fft结果一致,这意味着当前的rom在预测填充橡胶的整体行为方面提供了足够的准确性。填充橡胶的预测g’和g″与实验结果之间的比较分别示出在图88的a)和b)中,可以得出结论:考虑到中间相,tan(δ)的预测与实验数据非常吻合。还通过逆建模计算中间相的g’和g″,如图88的分图(a)-(b)所示。如上所述,与未填充橡胶相比,中间相应具有更大的g’和更大的g″。橡胶性能。只有这样,填充橡胶g’和g″才能得到改进并与实验结果相匹配。逆建模的中间相属性确保了填充橡胶行为的预测遵循实验数据。值得注意的是由rom通过sca预测的中间相g’和g″要高于从fft获得的结果,但是sca和fft都预测出了填充橡胶g’和g″作为频率的函数的相同趋势。由于使用两相填充橡胶通过sca预测的g’和g″要比fft的预测值要小,这种偏差是可以预期的。较高的中间相g’和g″将抵消这种差异,以符合方程式(5-19)中定义的目标函数。图87中示出的填充橡胶和未填充橡胶tan(δ)之间观察到的差异表明,由于在较低频率范围(1e4hz和1e6hz)下测得的tan(δ)较小,填充橡胶的滚动阻力较小。可以将这样的特征与计算出的中间相属性联系起来,其中观察到较高的储能和损耗模量,如图88所示。这导致中间相的tan(δ)降低,通过减少填充橡胶tan(δ),导致填充橡胶的总滞变降低。因此,与纯橡胶相比,填充橡胶将具有较小的滚动阻力。另一方面,图87示出了在高频范围内填充和未填充橡胶tan(δ)之间的差异很小。这表明在高频范围内,两种材料的行为类似。如上所示,计算出的中间相储能和损耗模量与未填充橡胶性能相差不大。因此,计算出的中间相属性与填充橡胶混合物的实测tan(δ)一致。另外,填充橡胶的峰值tan(δ)低于未填充橡胶的峰值。为了增加低温下的轮胎牵引力,应提高低温下的tan(δ)。基于计算出的填充橡胶属性,这可以通过识别能够在高频范围内形成具有高损耗模量的中间相的填充材料来实现。这样的材料组合将提供增加的阻尼,因此可以改善冬季牵引力。本工作流程适合于对必要的中间相储能和损耗模量进行逆建模,从而缩小了材料选择的范围。根据从sca获得的逆建模结果,图87示出了通过sca预测得到的较高的中间相g’和g″大小。这是由于如图85所示sca预测的填充橡胶g’和g″较低以及中间相在补偿两相填充橡胶结构和三相填充橡胶结构之间观察到的差异方面的作用。因此,更大的中间相g’和g″意味着填充橡胶的机械响应更硬,这解释了在图78中观察到的更低的tan(δ)。就粘弹性而言,sca和fft均可捕获玻璃化转变区域,如图87中tan(δ)的峰值所描述。此外,对于sca预测,观察到了计算效率的显著提高。下表5-3中示出了在单个频率点进行逆建模的计算时间的比较,其中,通过将提出的rom与fft进行比较,可以实现1778倍的加速。表5-4总结了通过不同方法评估填充橡胶属性时所耗费计算时间的比较。尽管sca需要进行脱机阶段计算来生成填充橡胶复合材料的rom,这在计算上仍然很昂贵。但是,一旦计算出数据库,就可以将其用于以后的所有评估过程。这样可以在联机阶段预测填充橡胶的有效属性以及逆建模过程的计算时间上节省大量时间。sca方法与逆建模相结合,为材料设计开辟了一条新途径。此外,同一套rom可用于各种材料属性,以合理的成本计算填充橡胶的机械属性。有可能探索设计空间并获得填充橡胶的良好趋势和定量描述。更重要的是,即使计算资源有限,所提出的方案仍可为研亢填充橡胶材料的中间相属性提供有效的解决方案,以满足未来的设计需求。表5-3单频点cpu逆建模时间比较表5-4使用不同方法对尺寸为513×513×75的模型进行填充橡胶属性评估的速度比较尽管使用逆建模方案观察到令人鼓舞的结果,但为使此过程成为可能仍进行了必要的假设。例如,假定中间相厚度βip在填充材料周围的圆形区域中。但是,中间相厚度可能是填料曲率或填料尺寸的函数,因为聚合物链聚集的程度会受到这些参数的影响。该方案将扩展到包括填料周围的变化的中间相厚度以考虑几何效应。在此示例性研亢中,引入并说明了逆建模方案,以作为使用填充橡胶样品的高保真重建来定量分析填充橡胶化合物的中间相属性的工作。当将精细的3d数字图像用作输入时,fft方案可实现高效的计算。未填充和填充橡胶的测试数据提供了足够的输入,以解决每个频率点的中间相属性的逆建模过程。此外,将sca(降阶建模方案)与逆建模过程结合起来,以首次计算中间相属性。脱机阶段数据库一旦构建,就可以方便地在所有频点使用该数据库来计算整个填充橡胶主曲线。这种新颖的降阶建模方法大大节省了计算成本。sca和逆建模方案的合并是一种高效且有价值的填充橡胶设计工具。本方法足够通用,并且可以结合微观结构的其他细节,例如中间相厚度的变化。所获得的中间相属性允许在时域分析(例如拉伸测试)中对三相填充橡胶模型进行正向计算。据信,在不同的载荷条件下,中间相的作用可以更好地预测填充橡胶的响应,这将在以后的工作中得到解决。fft方案算法流程图下面简要地给出了具有定点迭代的fft方案的算法流程图。使用收敛测试确定局部应变εi+1是否达到稳定值。该实现方式可以用任何编程语言轻松实现,只要可以容易地使用fft和逆fft包即可。初始化:用已知的εi和σi迭代i+1;b)收敛测试;上面的算法流程图是针对单个载荷步骤的。读者可以通过为多个载荷步骤定义多个εmacro来轻松地将其修改为多个载荷步骤。自洽聚类联机分析解决方案流程sca要求根据外部载荷条件(固定的应变增量δεmacro或固定的应力增量δσmacro)求解离散的李普曼-施温格方程。离散的李普曼-施温格方程如下所示:方程式(5-23)的解将是每个聚类的应变张量εi。为了使用牛顿-拉夫森方法求出方程式(5-23)的解,残差形式如下面的方程式(5-24)所示对于宏观应变边界条件,宏观应变的残差写为:对于宏观应力边界条件,残差变为:通过最小化ri来求解δεi。将ri相对于δε进行线性化得到其中,雅可比矩阵为对于宏观应变边界条件,具有:对于宏观应力边界条件,具有:求解方程式(5-27)可得到更新所有局部应变增量δεi的δεi。应该重复此过程,直到将所有聚类中的残差最小化为止。示例6基于图像的金属增材制造机械性能的多尺度建模系统材料的多尺度或微观结构敏感建模所使用的通用假设和方法通常不适用于捕获增材制造(am)金属的性能。目前的方法通常依赖于rve或其他某种形式的代表性结构(例如:具有代表性的单位晶格或简单的周期性结构);对这些结构的响应预测也可能基于简化的假设,例如:微观结构(例如:椭球体)、周期性或统计(空间)一致性的理想化。预测最低性能或捕获最坏情况的模型通常难以作出过程设计定量有用的预测,这是结构-性能-性能建模的主要目标之一。这些困难与增材制造的潜在挑战有关:局部化过程产生了依赖于过程的微观结构和随机微观结构的混合物,这些微观结构既不遵循(在更坏的情况下分析时可能有用的)大致确定的模式,也不遵循(统计一致性情况下将会适用的)完全随机的模式。由金属增材制造形成的材料是异质、不均匀且高度可变的。在本示例中,在与微观结构相关失效的机械建模中引入了新的范例,其中,将快速降阶方法直接用于组成宏观组件的实验成像微观结构;这些微观结构的行为用于预测宏观尺度性能。(来自建模或实验中的)过程历史可以用于选择在组件级模型中每个材料点处发生的微观结构。因此,可以捕获空间的、构建到构建的以及部分到部分的变化。具体来说,使用空隙的x射线计算机断层扫描图像来证明该概念,所述空隙构成了包含成千上万可能的微观结构的数据库。在组件的每个材料点,根据增材制造的过程模型的结果来选择特定的微观结构。最后,预测组件的预期使用寿命期间的载荷历史,并将其用于估算疲劳寿命(或其他性能指标)。通过使用微观结构的数据库并进行抽样研亢(即:蒙特卡洛分析),尽管存在一定的计算量,但减轻了界定代表性的体积单元的需求。通过引入随机选择每个微观结构,我们也能够对性能的可变性和分布进行预测。根据加工历史,选择组件中每个材料点处的微观结构,这样可以捕获诸如不同的刀具路径之间的差异或选择加工参数。实际上,这看起来有点像数字孪生,其中,可能跟踪给定的构建,直至跟踪到失效概要文件。人们也可以将其视为“虚拟实验”,因为每个通过计算测试的“试样”都提供了一个有关性能(如:疲劳寿命)的数据点,这很像物理实验。所得的框架具有几个独特的特征:与位置和历史相关的性能和性能预测、(基于所使用的宏观尺度求解方法的)组件甚至系统的可量测性以及预测整个域中行为的可变性(包括平均值/最小值/最大值)的能力。当然,这是需要代价的。应该使用足够丰富的微观结构图像数据库,但是“足够丰富”是模棱两可的,且取决于许多因素。某种将加工历史与适当的微观结构测量联系起来的方式也是最佳的,该方式既与位置/加工相关又是可预测且可靠的,并且与机械性能相关。可能发生疲劳载荷的结构应用中所使用的金属增材制造为证明该方法带来了极大的挑战。在增材制造中,出现了相对独特的、分散的、异质的微观结构特征,这取决于与零件制造条件相关的诸多因素。真正的预测模型能够为设计的稳定性和可量化的安全性评估带来信心,同时减少所需的实验次数。但是,只有在使用具有足够描述能力的模型时,才有可能实现这一点。在过去的几年中,对增材制造金属的机械性能的了解进展迅速。其中,许多进展是实验性的,并且已经报道了对增材制造材料(如:ti-6a1-4v、ss316l和镍基高温合金)的性能预测。这些材料之间的一个共同点是:具有不同参数的构建之间以及具有相同条件和参数的同一机器上的不同构建之间,在单个组件内,它们可能存在很大的点对点变化。以前的计算学家已经注意到与这些可变性的各种来源相关的挑战。实验工作中也注意到这种可变性。例如,gong等人和sheridan等人指出具有不同参数的构建之间以及具有相同参数的构建之间具有显着差异,强调了加工参数的重要性,还强调了过程导致的随机性。这种可变性和随机性,尤其是在涉及缺陷的情况下,将导致标准的预测方法可能不适用于异质材料。多尺度建模是一种能够捕捉异质、非均质材料响应的方法。例如,基于所开发的多级疲劳模型,horstmeyer提供了在利用分层多尺度方法的异质材料中疲劳建模的实例。近期的工作专注于在增材制造的整个加工过程和随后的使用寿命中应用模型,以便将加工过程、结构和性能联系起来。这些框架结构是有价值的,虽然不是多尺度的,但其为当前的工作提供了起点。两者都是相对确定性的,关键在于两者都使用过程建模来对微观结构和缺陷进行直接预测。这意味着完全依赖过程模型的准确性和真实性来获取所有重要的物理信息,对于诸如空隙之类的缺陷,准确的预测仍然是增材制造建模文献中的挑战,尤其是组件尺度上更是如此。当疲劳响应取决于每个孔的精确形状和位置时,依赖模型可能是不明智的。在下文中,绘制了用于构建我们的多尺度模型的方法的草图,包括:增材制造过程的热模型、基于图像和建模的空隙统计描述以及用于预测性能的机械多尺度模型。接着是计算示例,其中,使用几种不同的工艺参数,对inconel718构建的试样样本的应变寿命行为进行了预测。方法从概念上讲,这种多物理参数、多尺度的方法由三个主要部分组成。前两个部分用于生成描述材料内异质性所需的信息;最后的部分使用该信息对机械性能进行预测。因此,前两个部分将该方法与增材制造金属联系起来;第三部分具有重要意义,且不一定限于任何特定的材料系统。第一部分涉及构建过程的热建模,以便捕捉加工参数的影响。根据第一部分中的加工信息,第二部分使用先前增材制造构建中的空隙的同步加速器x射线计算机断层摄影图像,将可能的微观结构映射到所述组件。蒙特卡洛(montecarlo)方法用于生成许多可能的例示,以说明(以加工-结构关系中的散度衡量的)相同加工条件内的随机波动。第三部分是并行多尺度应力分析,该分析利用第二部分的例示和计算晶体塑性来估计整个厘米尺度组件中微米尺度的空隙的疲劳功效。尽管该方法是广泛适用的,但始终将标准试样用作示例。图89示出了计算方案的整体图。必须指定几何图形、构建工艺参数、材料和荷载条件。这些参数用于进行热分析和宏观尺度应力分析。对于这两个模型中的每个材料点x,构造逐单元子模型来表示该点可能的状态。这就利用了局部热历史和应变历史来确定微观结构(空隙几何形状)和变形历史。将这些参数用于预测状态变量(如:塑性和损坏)的微观尺度演化,这些状态变量被均质化(例如,通过取域的l∞范数),并用作部件级别对失效的敏感性的逐单元评估指标。模型设置此处所述的系统适用于相同的几何形状、也适用于加工条件、机械载荷期间的边界条件以及可以在标准有限元分析中表示的材料的选择。如下文所述,相关材料需要足够的实验数据,尤其是有缺陷的3d图像。宏观尺度增材制造构建过程的热建模我们首先进行热分析,以使用定向能量沉积(ded)方法对相关组件进行建模。使用瞬态热有限元求解器进行该项分析。待求解的控制传热能量平衡是:其中,p是材料密度;cp是比热;t是时间;xi是空间坐标;k是材料的电导率;t是温度;q表示热源。该热源由高斯分布(gaussiandistribution)描述的移动激光表示:其中,p是激光的功率;η是用于限制材料从激光器吸收的能量的量的吸收因子,取值为30%;rb是激光的半径。变量x、y和z是激光的局部坐标。通过结合对流和辐射来仿真模型的动态自由表面上的热损失。将对流热损失定义为:qconv=hc(t-t∞)(6-3)其中,hc为对流系数;t是表面温度;t∞是远场(环境)温度。辐射热损失是根据斯蒂芬-波兹曼(stefan-boltzmann)定律定义的,由下式给出:其中,σ是斯蒂芬-波兹曼常数;ε是材料的表面发射率。选择特定的构建参数,包括:激光速度、功率以及刀具路径。还必须指定材料。根据给定的信息,该模型可以预测该部件内各点的时间与温度历史。根据热模型的温度历史计算凝固冷却速率(scr),并在每个节点处输出该凝固冷却速率。根据方程(6-5),这近似为由下标i表示的材料点从液相线温度达到固相线温度所需的时间。为了捕获这种凝固行为,用约为9.0×10-4秒的近似时间步长明确地求解方程(6-1)。如果选择的时间步长过大,就可能跳过某些材料点的凝固行为。此外,在重新熔化的情况下,只考虑最终的冷却阶段。其中,scr(xm)是凝固冷却速率,作为宏观尺度域ωm内宏观尺度空间坐标xm的函数;为固相线温度;为液相线温度;是达到液相线温度的时间;是达到固相线温度的时间。但是,在构建组件的机械模型之前,需要更多的信息。具体而言,需要估算在构建过程中产生的微观结构(包括诸如空隙之类的缺陷)的各向异性分布。微观尺度将热条件和缺陷相关联为了进行热预测,我们需要将热模型输出连接到缺陷统计数据和几何形状中。我们选择在两个阶段生成这种关系:首先,通过热描述符(例如,如上所述的scr)和微观结构描述符统计量之间的关系;然后,通过对应于每个微观结构描述符(例如,空隙尺寸)统计量的微观结构几何形状的数据库。然后,该数据库中的微观结构被用于填充该部件的每个实现。图90中示出了该缺陷估算和数据库构建过程。在第一部分中,使用过程建模和x射线计算机断层扫描成像来确定凝固冷却速率和空隙体积分数(vf)之间的关系。图90的图(a)是基于vf选择的通过x射线断层扫描成像获取的图像的子集,涵盖(具有已知或预测的热历史)任意部分的预期的vf范围。图90的图(b)产生这些可能的微观结构的数据库,包括计算机械模型的训练阶段。为了识别scr与空隙的关系并建立数据库,我们使用了两个inconelded单轨薄壁部件,其加工参数与表6-2中的参数组1相对应。两个壁都具有垂直的锯齿形刀具路径图案,但是当一个壁的刀具路径连续时,另一个壁则在各层之间增加一分钟的停留时间。在阿贡国家实验室的先进光子源的beamline2-bm上,对从两个薄壁上的22个位置(共44个数据点)提取的试样进行了x射线断层扫描成像实验。每个图像的材料约为1mm3,其体素边缘长度为0.65μm。通过一系列处理步骤(包括过滤、阈值处理和伪影去除),使用与x射线吸收率的对比来区分空隙和材料。从这些图像中提取了11种不同的描述统计量,例如,空隙位置、大小、形状、方向和n最近邻信息。为了简单起见,在此我们将重点关注空隙的大小,即:以单点相关统计量表示的空隙体积分数vf。总的vf是根据整个图像中每个位置上空隙大小的总和来计算的。使用上述热分析方法对这两个薄壁的构建过程进行建模。在整个构建过程中,将零件的热历史总结为逐点scr。scr是有用的、与物理相关的单点统计,其总结了因选择构建参数而产生的热状况。使用该过程模型来计算每个x射线图像位置处的平均scr。请注意,例如,可以使用红外(ir)摄像头对冷却速率进行实验测量,以提供等效数据。图90的第一部分示出了如何收集和绘制平均scr与每个图像的vf的图示。指数关系由下式给出:vfrac=ae-(b)(scr)(6-6)该指数关系与数据拟合。拟合参数为a=0.0047,且b=0.0011。构建图像数据库接下来,利用这种关系来确定该构建中可能出现的一系列可能的微观结构。找出在第一部分中使用的图像的子集,使得该子集的vf范围对应于预计在如图90所示的关系所给出的部分出现的范围。这些图像子集构成了可能的微观结构的数据库。在这种情况下,每个子集的大小为97.5μm×97.5μm×97.5μm,且大致介于vf=0.0001和vf=0.03之间。为了完成数据库,对每个条目进行了第2.4.1节中所述的三个培训步骤。因此,用于多尺度机械响应预测的最终数据库包含原始数据,所述原始数据用于生成任意载荷的响应预测,该原始数据取决于微观结构信息。机械响应预测在前两节中,我们使用了实验数据的数据库,利用真实、异质分布的空隙来填充部件,所述空隙与用于构建该部件加工条件相对应。下一步是使用该信息来预测该部件的机械性能。但是,在计算方面,直接预测缺陷结构是不可行的,由于同样的原因,直接对我们生成的微观结构的机械响应进行直接建模也是不可行的。采用多尺度方法来获取用于预测增材制造材料的机械性能所需的微观结构信息。在宏观尺度上,使用简单的约翰逊-库克(johnson-cook)材料模型,为微观尺度使用的数据驱动的降阶模型提供应变边界条件(更具体地说,使用变形梯度)。在微观尺度上,使用晶体塑性来预测材料行为。由于缺乏更加完整的数据,我们简单地假设vf在方程(6-6)指定的±10%以内的微观结构具有相同的发生概率。这样,基本上通过蒙特卡洛过程就能够描述该部件,其中,随机变量的可能状态受过程模型控制。该过程的示意图如图91所示,其中,局部温度历史和应变历史作为报告均质响应的微观力学模型的输入。对于每个宏观尺度材料点(在这种情况下为元件),将热历史和应变历史传递到微观尺度求解器;从基于热历史开发的数据库中选择微观结构,并根据应变历史施加变形边界条件。计算基于晶体塑性的微观尺度解,并且将均质响应(例如,如果选择了疲劳问题,则为疲劳指示参数的l∞范数)返回至宏观尺度。具有晶体塑性的微观尺度降阶模型在微观上尺度,该建模方法将数据驱动的微观力学与计算晶体塑性相结合,称为晶体塑性自洽聚类分析(cpsca)。该方法源自一阶均质化、希尔-曼德尔条件和局部平衡。在有限变形中,将该问题简明地定义为:其中,p是第一皮奥拉-基尔霍夫(piola-kirchhoff)应力;u是域ω中点x的位移;f是位移梯度,f0是移除(施加的)变形。为了满足希尔-曼德尔条件,我们假设在微观尺度域内存在周期性位移场和反周期边界牵引。在此假设下,已经显示方程(6-7)中给出的边界值问题等效于李普曼-施温格(ls)方程,并被逐个聚类近似为:其中,该域已被离散为固定的有限数量的聚类nc;c0为参考刚度;*表示卷积,且张量dij描述了聚类i和j之间的相互作用,由下式给出:其中,ωi是聚类i中的域;γ0是周期性四阶格林运算符;χ是特征函数。为了进行详细推导,cpsca分两个阶段求解该方程。第一个“训练”阶段包括三个部分:数据收集、数据压缩(或聚类)和相互作用张量的计算。所得的相互作用张量可以存储起来以备将来使用。第二个“预测”阶段利用相互作用张量并求解方程(6-8)中给出的积分方程,该方程受到施加的应变状态和材料定律的约束。对每个子集体积执行该第一阶段:将聚类和相互作用张量数据添加到图像子集的数据库中。因此,在将部件实例化并将子集用于填充微观尺度之后,仅需通过第二阶段来计算机械响应。然后,可以在独立的应力-应变历史和边界条件下任意次运行第二阶段。在第二阶段,施加循环载荷,并根据晶体塑性(cp)材料定律来计算应力。将施加的变形梯度分解为弹性和塑性部分;塑性梯度的塑性部分是由塑性速度梯度计算得出的,其本身是通过对中间构造中滑移系统的塑性剪切速度求和来确定的,如下式所示:其中,是二元乘积;α是滑移系统;nslip是滑移系统的数量;是微观尺度剪切速率;s(α)是滑移方向;n(α)是滑移平面法线。方程(6-11)中所示的具有背应力的现象学幂次定律可用于更新剪切滑移速率。其中,τ(α)是(用计算得到的)滑移系统α上的分解切应力;是参考剪切速率;是参考剪切应力;a(α)为背应力项,且m是“速率硬化”系数。示例性能测量:疲劳寿命失效预测包括一系列损坏机制,这取决于对性能的预测。一种更具挑战性的失效是试图预测由循环载荷引起的疲劳。因此,我们将本方法用于测量疲劳性能。具体来说,为了预测疲劳裂纹潜伏寿命,采用临界平面法推导的疲劳指示参数(fip)来估算给定塑性应变历史条件下的微观结构的疲劳潜伏寿命。fip由下式定义:其中,是最大循环塑性剪切应变;是垂直于发生的平面的峰值应力;σy是屈服应力;k是假设为0.55的正常应力因子。fip与使用下式的潜伏周期数有关:其中,和c是类似科芬-曼森(coffin-manson)的乘积型和指数型校准因子。数值演示具有标准疲劳试样的校准/验证实例为了证明该方法,对符合astme606/e606m/e466标准几何形状的疲劳试样进行了数值测试。试样的几何形状采用两个不同的六面体网格划分,进行一次热分析和应力分析,如图92所示。除了用于应力分析的网格在厚度(z-)方向上变粗糙之外,这两个网格基本相同。这就是构建方向,因此在热模型中每个构建层至少需要一个单元,但是在应力分析过程中,应力和应变在该方向上大致恒定。但是,这样可以消除工艺参数之间的某些可变性,因为在网格粗糙化过程中scr得到平均。按照图89所示的示意图,将该网格加载到热求解器和应力求解器中。热模型使用内部热有限元分析(fea)代码,abaqus中的c3d8r单元用于在宏观尺度上计算应力和应变。在若干个不同的应变幅度下,在五个完全反向的载荷循环中,下部手柄固定,上部手柄以恒定的应变速率位移。将对应于inconel718(in718)的宏观尺度均质材料性能应用于热应力分析和宏观尺度应力分析。表6-1中总结了in718的这些热性能。使用了约翰逊-库克(johnson-cook)参数,尽管在指定的疲劳载荷下,该选择基本上是任意的,同时宏观尺度响应完全是弹性的。表6-1:in718的热物理性质针对热分析,选择了具有90度逐层偏移的锯齿形刀具路径,表6-2中指定了四个不同的工艺参数。对部件进行网格划分和仿真,使量规横截面垂直于构建方向对齐。使用具有539216个六面体单元的相对较细的网格(图92中图(b),未显示基板);图92中图(b)示出了量规截面的最窄部分的网格的细节。图92中分图(c)显示了试样网格的细节,包括应力网格(左)和热网格(右)之间的差异。表6-2用于in718热分析的工艺参数组参数组激光功率(w)扫描速度(mm/s)光束半径(mm)层厚(mm)1800151.50.751800101.50.751500151.50.751500101.50.75在微观尺度上使用cp模型。通过将包含64个立方晶粒的立方域的多次运行结果与amin718的一组基线拉伸和循环载荷数据之间的差异最小化来校准参数,初始条件取m和作为弹性模量。得到的模型参数如表6-3所示。将fip与疲劳寿命相关联的参数拟合至从文献中收集的in718的实验性高周疲劳数据。我们承认,这通常代表相对无缺陷的材料,并且对于增材制造材料可能不是完美的。但是amin718的疲劳数据相对较少,生成此类数据超出了本项工作的范围。假设通过上述方法识别出的图像空隙被嵌入到单晶中,所述单晶被取向为使得最快的生长方向与构建方向对齐。这与实验经验相吻合,实验经验表明in718中的晶粒比空隙大得多,并且优先地取向。在将来的工作中,能够使用诸如元胞自动机方法之类的方法来预测整个构建过程中的晶粒。另一种可能性是由给定的实验证据使用合成方法生成晶粒结构,这为合成性生成提供了统计基础。尚未公布的初步结果表明,当与基于图像的空隙几何形状一起使用时,通过这种方式产生的晶粒可能会显着影响预期疲劳寿命。作为热预测的示例,图93中以温度等高线的形式示出了根据加工参数组而构建的部件的热响应快照。该热预测将贯穿此试样的整个构建过程。表6-3:初级晶体可塑性模型参数我们仿真了三十个不同的虚拟试样,每个试样都有不同的、随机分布的缺陷以及预估的疲劳寿命。如图6所示,在两种不同的处理条件下,仿真了在三种不同荷载幅值下试样的五种实现方式。每个试样在宏观上包含19360个单元,每个单元在微观尺度上都用150×150×150的体素网格表示。因此,通过约650亿个体素有效地表示每个试样。换句话说,这30个试样测试套件需要评估580800个这些微观体积,或为每个体素进行超过130个时间步的总共1.9602×1012次晶体塑性例程的调用。如果没有在微观尺度上使用cpsca方法,这将是一笔巨大的计算开支。但是,使用cpsca方法,在2.3ghz时钟频率的intelxeonskylake6140上使用36个内核并行测试每个虚拟试样,大约需要花费9个小时。图94示出了在不同的应用应变幅度下,仿真实验条件下运行的疲劳试件的多个实现方式的估计疲劳寿命。对两种不同的处理条件(表6-2中的条件1和条件2)进行了建模。图94中的结果直接展示了该方法的关键特征。量规截面的等高线图报告了在疲劳试样中每个宏观尺度点处疲劳裂纹开始形成所需的估计循环数;在任何给定的宏观尺度点上,不同例示(图94中的试样a与试样b)之间的微观结构不同,这形成了不同的等高线图。比较试样a和试样b的微观结构,可得出造成这种差异的原因:具有较高疲劳强度的特征可能随机出现在一个例示中的应变集中度最高的点上,而不出现在另一个例示中。这与物理测试中的行为相似。尽管我们假设总是出现空隙,但这并不是该方法的必要假设:如果给定足够的加工材料表征数据,则可以使用该方法获得多种微观结构。此处使用的这种微观结构并未明确地捕获微观结构疲劳行为的表面效应。例如,整个部件靠近表面的微观尺度的空隙可能会影响疲劳性能。尽管很自然地涵盖了边界的宏观尺度效应,但是这种小尺度的相互作用正在进行。一些作者建议,对于完工的机械加工的成品试样,整体疲劳寿命的变化非常有限,直至达到高周限值(跳动);这可能表明此处所做的假设是合理的。进行演示时,也使用了晶粒结构的简化假设;但是,我们可以增加一个步骤,要么如证明的那样根据热历史预测晶粒结构,要么在数据可用的情况下根据实验得出晶粒结构。目前,我们还无法获得需要包括基于图像的晶粒的那种3d晶粒结构,尽管人们可能会考虑使用基于当前可用图像的统计学上类似的、以合成方式生成的晶粒结构,这是单纯基于图像的微观结构中的下一个逻辑步骤。此处使用的图像的隐含假设是,轨道间距应当适当,以避免轨道之间出现未融合的缺陷。这是因为用于建立数据库的图像源于单轨薄壁构建,因此不可能出现轨间孔隙。通过将多轨构建中空隙图像加入数据库中,能够很容易地放宽此假设的限制。制定用于增材制造中疲劳预测的基准将支持建模工作。目前,与传统工艺相比,增材制造对金属疲劳性能的影响存在相互矛盾的报道。这可以部分归因于材料的广泛性、构建过程的范围和机器操作员做出的选择。如果缺少更好的、针对增材制造的标准测试程序,此类冲突将很可能持续存在,从而对缺乏校准和验证数据的建模团队造成不利影响。本示例展示了一种利用计算效率高的微观力学技术来执行蒙特卡洛(montecarlo)类型的数值实验。具体的微观尺度解是由李普曼-施温格(lippmann-schwinger)方程的基于聚类的解推导出来的,这涉及利用晶体塑性和疲劳指示参数来预测疲劳寿命。通过3d成像实验开发了可能的微观尺度几何形状的数据库。这些几何形状通过凝固冷却速率与增材制造工艺条件相关联,并且通过合理的计算开销,可以随机预测与工艺和微观结构有关的疲劳寿命。示例7基于自洽聚类分析的编织复合材料的高效多尺度建模在该示例性实施例中,使用sca来抵消编织rve问题的计算成本,与标准fem相比,sca保持了相当高的稳定性。使用编织sca可以有效地预测希尔各向异性屈服面,这能够加快编织复合材料的微观结构优化和设计。此外,针对编织复合材料结构,提出了两尺度fem×sca建模框架。基于该框架,能够使用微观尺度性能来预测复合材料结构在宏观尺度上的复杂行为。另外,同时捕获宏观尺度和介观尺度的物理场,这些物理场很难(但并非不可能)使用实验方法来观测。这将加快对复合材料的变形机理的研亢。在循环荷载作用下,对t形钩状结构进行了数值研亢以阐述这些优点。与单向层压复合材料相比,编织复合材料由于具有出色的机械性能而被广泛用于航空航天和汽车等行业。但是,由于介观尺度和微观尺度的异质性(见图95),对编织复合材料进行结构分析是具有挑战性的。在这些不同的尺度上能够观察到不同的特征,并且仅使复合材料结构均质化并应用仅表征材料平均行为的现象学本构关系,并不能解决较精细尺度上的局部行为问题。因此,没有考虑局部非线性变形和损坏效应。另外,无法基于微观结构成分预测宏观尺度性质,并且需要通过实验来设计新的复合材料,这是费钱又费时的。多尺度仿真为分析材料的微观结构和宏观结构提供了一种有效的方法。使用该方法,可以根据编织复合材料成分的性质预测编织复合材料的宏观性能。一旦微观结构得到表征,则不必每次都在微观结构变化时进行宏观结构实验。这就使得多尺度方法能够加速编织复合材料的材料设计、降低成本并提高编织复合材料结构的分析精确度。此外,还能够捕获不同尺度的物理场,这些物理场很难(或在有些情况下,不可能)使用实验方法来观测。但是,实现对编织复合材料的有效多尺度仿真依然面临一些挑战。第一个挑战是找到编织rve的有效解。有效的宏观尺度性能是指复合材料的均质性能,这些均质性能始终用于编织复合材料的材料选择和结构设计。为了预测这些有效性能,必须开发编织复合材料的rve,这将在微观结构特征和有效的宏观结构性能之间建立联系。在周期性编织架构下,使用针对rve的单位晶格。针对微观结构设计,能够将编织的rve解集成到优化算法中,使用该算法时,必须反复求解rve以找到优化解并满足客观的有效特性的要求。因此,有效地解决编织rve问题可以加快整个优化过程。从而,将促进编织复合材料的微观结构设计。目前,已经提出了几种解决rve问题的方法。诸如混合定律和理论微观力学方法之类的分析方法是有效的,但是,在复杂的微观结构和与历史相关的非线性材料定律的情况下,这些分析方法不是很准确。直接数值仿真(dns)方法(例如,fem)非常耗时。基于fft的方法比fem更加有效,但是基于fet的方法由于在非线性问题中具有高相位对比而遇到收敛问题。转换场分析(tfa)、非均匀转换场分析(ntfa)和适当的正交分解(pod)是其他的求解方法,但是,尤其对于非线性相行为而言,需要对这些求解方法进行广泛的先验仿真以获得变形模式。第二个挑战是编织结构的并发多尺度仿真。通过并发多尺度仿真,利用rve的行为来预测编织复合材料结构的行为。此外,能够同时捕获不同参与尺度的物理场,这将加快编织复合材料结构的变形机制的研亢。如图96所示,并发仿真需要大量的rve解,使用fe2框架求解的计算成本非常昂贵。在本示例中,仅在宏观尺度级别使用了5000个单元,在编织rve介观尺度级别使用了1843200个单元,在udrve微观结构尺度级别使用了576000个单元。对于并发多尺度仿真而言,每个高尺度的材料点都将与低尺度的rve相连接。在本示例中,假设每个单元具有单个积分点,则整个多尺度计算需要2511.4万亿个单元。这种计算是非常昂贵的,并且需要使用高性能计算聚类(hpcc)。解决这些挑战需要提高解决rve问题的效率。sca是解决rve问题的有效且快捷的方法,该方法能够用于正在经历不可逆的过程(例如:非弹性变形)的复杂的编织架构。这使得其非常适合集成到多尺度仿真中。该sca方法涉及两个阶段的流程:脱机阶段和联机阶段。在脱机阶段,使用聚类算法来降低rve的总体自由度(dof),从而形成降阶rve。在联机阶段,利用降阶rve求解离散增量李普曼-施温格(lippmann-schwinger)积分方程,以获得降阶rve中的应力场和应变场。在考虑到非线性弹塑性损坏软化作用和多晶材料的计算的情况下,已将这种有效的方法用于二维(2d)两相复合材料和三维(3d)硬夹杂物材料的仿真。已经证明这些仿真具有良好的效率和准确性。在该示例性示例中,讨论了通过sca对编织复合材料进行降阶建模的过程,并将结果与fem进行了比较。此外,针对编织复合材料提出了编织复合材料的多尺度框架。基于该框架,仅使用纤维材料和基质材料定律就能够有效地预测线性或非线性的部件尺度机械响应。方法和框架介观尺度级别的编织rve的sca方法通过在两个方向上交织纱线,然后用环氧基质材料填充编织物来构造编织复合材料。根据纤维和基质材料的成分性能,使用udrve预测单根纱线的有效弹性性能(参见图97)。然后,将编织rve与高保真体素单元啮合,并进行弹性分析以获得每个单元中的应变集中张量。根据每个单元的应变集中度和方向对这些体素单元进行聚类,降低编织rve域中的自由度。通过利用编织rve聚类的结果,使用以下方法生成材料数据库:该方法包括相互作用张量dij、每个聚类ai的应变集中张量、体积分数ci和各种成分的材料参数。在联机阶段,特别是对于非线性材料行为,采用牛顿-拉夫森(newton-raphson)迭代算法求解离散增量李普曼-施温格积分方程组,从而能够提高精度和收敛性。该方程解是介观尺度应变场和应力场。fem×sca并发多尺度框架在本研亢中(图98),在并发多尺度框架中使用了宏观尺度和介观尺度两种尺度。由fem离散化结构尺度(宏观尺度),这样能够适应复杂的几何形状。使用sca对编织rve尺度(介观尺度)进行建模。进行涉及宏观尺度和介观尺度级别的多尺度仿真,在该多尺度仿真期间,同时交换信息。将载荷施加到结构尺度模型上。在宏观尺度单元的每个积分点处,应变增量将从sca模型中的fem模型传递过来。将该应变增量应用于相应的编织rve中,并且使用sca方法来解决编织rve问题,并将应力增量返回至fem求解器。将编织复合材料结构进行并发多尺度仿真的算法总结如下:1.使用fem对宏观尺度复合材料部件进行网格划分;2.开始求解增量;3.根据节点值计算积分点字段变量;4.对于i=1,n_ip(对积分点进行循环);a.将宏观尺度应变增量δe作为输入数据传递到用户定义的子例程中;b.运行sca的联机部分,以使用脱机编织数据库来求解受δe约束的编织rve;c.计算编织rve域中每个聚类中的介观尺度应变增量δe;对于j=1,n_clu(对该相应编织rve中的所有聚类进行循环)d.使用相应的材料模型计算介观尺度应力增量δσ;e.结束(获得所有聚类的响应);d.检查降阶离散增量李普曼-施温格积分方程的收敛性,如果不收敛,则使用牛顿-拉夫森方法更新δe并转到c,如果收敛,则转到e;e.通过求取编织rve域中δσ的平均值来计算宏观尺度应力增量δ∑,并将宏观尺度应力传递回fem求解器;5.结束(获得所有积分点的响应);以及6.检查frm部分的收敛性,如果不收敛,更新节点值,并转到步骤3。从流程图中可以看出,可以通过用户定义的子例程来实现sca联机算法,该子例程能够与大多数商业fem软件包集成。通过这种方式,fem×sca多尺度框架可以适应任意的结构几何形状和任意的编织构架。请注意,并不要求聚类具有规则的几何形状,这使得其对于复杂的微观结构也是有效的。编织rve的sca验证几何模型在编织复合材料家族中,平纹编织复合材料因容易制造而得到广泛应用。选择平纹复合材料作为示例,以在rve级别中演示和验证sca方法。图99示出了在本项工作中使用的平纹编织rve的微观结构。假设纱线的横截面为椭圆形,并且将纱线的中心线建模为正弦函数。建立两个坐标系(x1o1y1和x2o2y2)来分别描述横截面和纱线中心线的特征。其数学描述如方程(7-1)所示。局部坐标系1-2用于表示纱线的局部方向,这也是纱线中材料模型的局部系统。方向1是中心线的切线,并且方向2垂直于方向1。该局部坐标系随着纱线的长度而变化。本示例中使用的编织rve在宽度和长度尺寸上有120个体素单元,在高度尺寸上有32个体素单元。将横截面形状和纵向形状分别建模如下:其中,a、b分别是椭圆横截面的长轴、短轴;a是方程(7-1)中正弦函数的振幅。编织rve的三维几何模型是由如图99所示的五个参数定义的。这些参数的值是假设的,仅用于数值验证。通过适当的实验表征,可以使用这些参数生成真实的编织rve。材料性能和本构模型采用非线性环氧塑料材料模型对聚合物基质进行建模,将屈服函数写成:f(σ,σc,σt)=6j2+2i1(σc-σt)-2σcσt(7-2)其中,σ是柯西应力张量;i1=tr(σ)柯西应力张量的第一不变量;是偏应力的第二不变量;σt和σc是拉伸屈服强度和压缩屈服强度。使用非关联流动法则,将塑性势函数写成:g(σ,σc,σt)=6j2+2αi1(σc-σt)-2σcσt(7-3)其中,vplas称为塑性泊松比。因此,流动规则由下式给出:其中,表示塑性增长乘子的时间导数。拉伸屈服强度和压缩屈服强度的演变写成:其中,和是拉伸和压缩时的初始屈服强度,ht和hc分别是拉伸和压缩时的硬化参数。表7-1中给出了这些材料参数。α0和α1是内部运动学变量,这些变量是由环氧实验数据确定的。表7-1基质的材料参数考虑到了纤维的横向各向同性弹性材料模型。另外,表7-2中列出了弹性性能。假设纤维体积分数为60%。下标1、2和3表示局部材料方向(见图99)。本示例中使用的udrve(图100)在宽度和长度上具有240个体素单元,在高度上具有10个体素单元。表7-2纤维的材料参数e1(gpa)e2=e3(gpa)g13(gpa)v12v23纤维23112.9711.280.30.45使用udrve(图100)模型和弹性性能(表7-1和表7-2)并通过施加六个具有周期性边界条件(pbc)的正交载荷来预测纱线的有效材料性能。因此,纱线的弹性材料性能如表7-3所示。表7-3预测的纱线有效弹性材料性能编织介观尺度rve的聚类过程基质材料是各向同性的,这就要求仅基于张量am进行一次聚类。该过程后,将与张量am最相似的材料点分组到相同的聚类中。图101示出了使用k均值聚类算法得到的256个聚类的基质的聚类结果。纱线材料的聚类过程会更加复杂,如图102所示,图中示出了具有64个聚类的纱线的聚类过程和结果。对于每根纱线,首先根据局部方向进行聚类。进一步使用应变集中张量am将得到的聚类细化。由于一个聚类对应于一个与方向相关的材料定律,所以局部坐标系与纱线中心线上的点对齐(见图99)。方向1与纱线中心线相切,并且代表每个材料点的纱线材料方向。进行两次该聚类过程。首先,使用k均值算法根据材料方向对单根纱线进行聚类。将距离材料方向最近的点分组到同一聚类中。根据第一步的结果,将根据应变集中张量am对同一聚类中的材料点进行第二次聚类。在本示例性示例中,第二次使用两个聚类。经过两个步骤的聚类后,将距离方向最近且最接近应变集中张量的材料点分组到同一聚类中。对rve中的所有纱线实施上述两个步骤。结果和讨论采用sca方法计算单轴拉伸响应和纯剪切响应。图103和图104分别是在这两种不同载荷情况下编织复合材料的应力-应变曲线。当纱线中聚类的数量固定为128个时,基质中聚类的数量为64至256个。当纱线中聚类的数量为32至128个时,基质中聚类的数量固定为256个。作为与基线的解的比较,还提供了fem的结果。可以得出以下结论:在线性区域和非线性区域,纯剪切条件下的sca结果与fem结果非常吻合。在单轴拉伸条件下,随着基质中聚类数量的增加,sca结果与fem结果收敛。由于非线性本构模型仅用于基质材料,因此需要更多的聚类来捕获局部材料的非线性效应。与fem的计算成本相比,sca能够在具有明显较少的自由度情况下准确地捕获编织复合材料的非线性行为(与fem相比,sca结果相差不到4%)。表7-4和表7-5列出了fem和sca方法之间的效率对比。fem需要求解约145万个自由度,求解时间为6523秒,而sca仅需求解2304个自由度,求解时间为30秒。因此,在时间要求和内存需求方面,使用sca方法显著提高了计算效率。图103示出了由fem和sca方法得出的预测结果(sca-64-128表示基质中的64个聚类和纱线中的128个聚类)。表7-4fem和sca的计算效率对比表7-5fem和sca的计算效率对比性能预测和并发多尺度仿真宏观尺度各向异性屈服面预测针对基质考虑到了非线性环氧弹塑性材料定律,这导致了编织rve的整体弹塑性行为。弹塑性材料的屈服应力这一性能对于复合材料结构的材料选择与设计非常重要。形成屈服面以评估不同载荷条件下的材料的屈服性能。在本示例中,考虑编织复合材料的各向异性希尔屈服准则。使用基于基质的环氧弹塑性材料定律和纱线的弹性材料定律的sca能够有效地预测均质化材料定律。二次希尔屈服准则的形式如下:其中,f、g、h、l、m和n是屈服面的常量特征,这些参数通常是通过繁琐的实验确定的。此外,有些实验(例如,平面外拉伸测试)难以进行。在本示例性示例中,使用sca方法预测这些参数,显著降低了计算成本并提高了效率。若yxx、yyy、yzz是主要的各向异性方向上的拉伸屈服应力,则如下所示:若yyz、yzx、yxy是相对于各向异性的主轴的剪切中的屈服应力,则:利用编织rve的对称特征,仅向rve施加四个正交荷载条件;使用sca方法来计算响应。根据应力-应变响应在每个点计算切线刚度,并通过评估切线刚度的变化来确定屈服点。从而,得到六个方向上屈服应力的值。此外,使用屈服应力的值,利用方程(7-7)和方程(7-8)来计算方程(7-6)中的希尔常数。可能难以设想由方程(7-6)描述的六维屈服面,但是,通过一次选择三个分量(并将其他三个分量设置为零),可以在三维空间中将该六维屈服面绘制出来,参见图105,其示出了希尔屈服面计算的工作流程。针对三个法向应力分量和三个剪切应力分量绘制了3d屈服面。针对法向应力分量的图示,示出了sigma_zz=0的横截面。针对剪切应力分量的图示,示出了sigma_xy=0的横截面。对于编织复合材料结构的非线性计算,能够将各向异性的希尔屈服面用作瞬时判断在各种载荷条件下开始塑性变形的依据。图105所示的工作流程使得人们能够毫不费力地(使用个人计算机大约用时一分钟)构建用于各种微观结构的屈服面并产生材料本构信息。能够构建大型的编织复合材料响应数据库,以帮助设计防止发生屈服的编织复合材料。如果给定有关最大服务荷载的先验信息,则该数据库将提供所有防止发生屈服的可能的编织微观结构(例如,纱线几何形状和纱线角度)和材料成分(例如,基质性能和纱线性能)。因此,通过缩小各种设计参数的设计空间,该工作流程能够潜在地加速编织复合材料的设计过程。多尺度仿真收敛研究首先进行rve收敛研亢,以量化rve尺寸对应力-应变响应的影响(图106)。rve-1是平纹编织复合材料的单位晶格,并且rve-2的尺寸是rve-1的尺寸的九倍。这两种不同的rve尺寸的结果如图106所示。请注意,结果彼此相差很小,rve-1将提供计算效率更高的收敛结果。t型钩状结构分析编织复合材料通常由用于工业领域的多层材料制成。t形钩状结构为常见的几何形状,用于连接不同的复合材料部件。在该示例中,在t形钩状结构的周期性弯曲过程中,使用多尺度仿真来捕获不同层中的宏观尺度场和介观尺度场。该结构和荷载条件如图107a所示。根据厚度考虑多层结构。如实验所示,图107b中的红色突出显示的区域表示达到失效应力时的关键区域,在该区域中使用更细的网格。结构级别模型的单元总数为34720。对于编织介观尺度rve,考虑将基质中的64个聚类和纱线中的32个聚类用于sca计算,同时使用降阶积分的八节点连续体实体单元(abaqus单元c3d8r)用于fem计算。宏观尺度行为由每个聚类的微观结构形态和介观尺度本构方程确定。在脱机阶段,首先生成sca材料数据库,这使得多尺度仿真更加有效。使用abaqusvumat用户子例程实施该数值研亢,离散增量李普曼-施温格方程是使用英特尔数学内核库(mkl)fortran代码求解的。该数值示例在具有48核和128gb内存的处理器上运行。计算结果如图108所示,选择拐角的不同层中的四个单元来表示介观尺度场。在弯曲载荷条件下,沿着整个厚度方向存在应力梯度,并且在不同的rve中应力场是不同的。由于纱线具有更高的模量,它们比基质承担更多的荷载。最大应力处的均质化应力应变曲线如图108所示,其示出了加载和卸载后的残余塑性应变。将峰值点处的应力状态绘制在2d屈服面上,这表明应力已经超过了初始屈服面。此外,表7-6中列出了计算时间,这表明fem×sca框架的效率得到显著提升。表7-6计算时间对比并发多尺度框架计算时间fe25.2×105天(预计)fem×sca2.4天加速2.16×105上述数值研亢表明使用所述多尺度仿真框架的优点。能够在宏观尺度和介观尺度上捕获应力场和应变场,包括非线性效应,这是利用实验技术难以观察到的。因此,该框架建立了复合材料结构的微观结构和宏观尺度响应之间的联系。当修改编织微观结构且纱线和基质材料保持不变时,无需进行其他实验来校准本构方程;只需更新sca脱机数据库即可。通过这种方式,可以降低成本、提高效率,为特定的结构找到最优的微观结构。在给出sca联机的效率的情况下,能够使用该框架分析更大尺寸的复合材料结构。在该示例性示例中,建立了基于自洽聚类分析(sca)的编织复合材料的多尺度建模框架。开发了针对编织复合材料的两阶段降阶建模(称为rve):在脱机数据压缩阶段,由于具有相似机械响应的材料点被分组到聚类中,因此利用聚类技术来降低rve域中的总体自由度。然后,计算连接不同聚类的相互作用张量,生成编织rve的微观结构数据库;在联机阶段,使用牛顿-拉夫森迭代来求解降阶离散的李普曼-施温格积分方程。对于线性和非线性材料定律,均显示出快速收敛性。编织多尺度建模方法提供了两个具有吸引力的特征:1)在给定编织微观结构的情况下,能够在联机阶段使用针对基质相和纱线相的不同材料定律来计算编织微观结构响应。例如,对于依赖于温度的材料特性,可以有效地计算出不同操作温度下的编织行为。2)在给定相同的成分性能的情况下,只需要更新脱机数据库来合并不同的编织结构,例如:平纹、斜纹或缎纹。编织多尺度建模框架具有各种潜在的应用,在本研亢中说明了两个重要的应用:针对防屈服的编织设计快速产生屈服面。能够使用屈服面生成工作流程来研亢在可能的荷载条件下编织复合材料是否未发生塑性变形。请注意,塑性变形很容易延伸到失效面,用于进行防失效的编织设计。fem×sca编织层压板建模框架可在分析过程中同时捕获宏观尺度(fem网格)和介观尺度力学行为。随着荷载的增加,可以跟踪介观尺度场的演变,建立起微观结构与宏观响应之间的桥梁。能够基于fem×sca框架在介观尺度上建立损坏和失效模型,并考虑更多机制,甚至进行复合材料结构级别的失效分析。与传统的现象学本构关系相比,这些基于介观尺度机制的本构关系不需要复杂的数学公式和大量的参数。此外,能够将该框架扩展到具有复杂荷载条件的更大尺度结构级别的分析。最后,这项工作提供了解决编织复合材料多尺度问题的有效方法和框架。示例8有限应变下多尺度建模的自洽聚类分析为了预测材料的宏观行为,对微观结构相互作用和演化进行准确和高效的建模对于材料设计和制造过程控制是非常重要的。本研亢采用降阶方法sca来应对这一挑战。对于变形大的普通弹黏塑性材料,重新对其进行阐述。通过与传统的全场求解方法(例如,有限元分析和快速傅里叶变换)对比,证明了预测多晶材料的整体机械响应的准确性和效率。结果表明,使用降阶方法能够快速预测具有定量变化的微观结构与性能之间的关系。在保持合理的计算费用的同时,通过对具有亚晶粒空间分辨度的大变形制造过程进行并发多尺度仿真,证明了该方法的实用性。该方法能够用于对微观结构敏感的性能设计以及过程参数的优化。过程-微观结构-性能链的关系在新材料的开发中起着重要作用,特别是在计算材料设计或集成计算材料工程(icme)的实践中更是如此,后者主要依赖于基于微观结构的模型。经过校准,这些模型能够用于探索比传统试错法更大的材料设计空间。经典微观力学包括解析模型,例如,自洽方法和mori-tonaka方法。这些模型是有效的,但是需要对微观结构形态和/或相互作用进行严格的理想化假设。在过去的几十年里,在计算力学和强大的计算机的发展支持下,制造过程、微观结构演变以及由此产生的力学性能的详细建模蓬勃发展。然而,icme部署的速度仍然受到所涉及模型的计算复杂性的限制。因此,人们对数据驱动的降阶模型非常感兴趣,这些模型有望提供高的精度,并且不需要任何与至今使用的详细模型相关的计算费用。这些降阶模型具有两个重要特征:(1)自由度(dof)显著降低;(2)在脱机阶段预先计算一些数据,以便在联机阶段将其重复用于迭代。其中的一个示例是转换场分析方法(tfa)。它将局部变形分解为弹性变形和转换变形(或非弹性变形)。弹性变形由预先计算的弹性应变集中张量确定。假设转换变形在每个材料相中是均匀的。这样,将自由度减少至涉及特定问题的相数的数量级。因此,该方法比传统的全场方法更快,但是无法准确地捕获相内异质的机械响应。非均匀转换场分析(ntfa)通过在某些预先定义的荷载路径下内插预先计算的转换场数据(或模式)来缓解这一问题;与具有自由度的tfa相比,其在所使用的模式的数量的数量级方面,达到了更高的精确度。其他数据驱动的方法采用类似的思路来减少自由度,例如,适当的正交分解(pod)内插位移场并通过单值分解更加有效地对模式进行计算。然而,这些方法都有相同的局限性:需要进行许多价格高昂的脱机计算来获得高度非线性材料行为(如:塑性和有限应变)的代表性模式。最近,已经证明:即使在这些更具有挑战性的荷载条件下,由liu等人提出的sca也能保持高精度和高效率。为此,sca使用基于聚类的数据压缩技术进行降阶,并使用自洽迭代方案来精确地求解李普曼-施温格方程。该方法的一些最新进展包括:sca收敛性的理论分析、颗粒增强复合材料的韧性设计的应用、弹塑性应变软化材料的破坏过程以及镍钛(niti)合金的疲劳寿命预测。然而,这些研亢大多仅限于小的应变问题,并且仅考虑将微观结构与相对较少的特征(例如,均质基质、夹杂物和/或空隙)相互作用。利用有限应变sca对拉拔过程中夹杂物的断裂进行建模。实际上,如果基质相中的成分的特征长度与夹杂物和空隙相当,则也应考虑基质相中的成分。例如,金属合金由具有各种形态、尺寸、晶格取向以及可能出现的缺陷(例如,沉淀物或空隙)的晶粒组成。尽管已使用基于自洽和本征变形的方法对相互作用的多晶体进行建模,但如上所述,它们的局限性仍然存在。最近,我们将小应变sca公式与晶体可塑性模型结合在一起,但是它忽略了变形的旋转分量,因此不适合于有限应变。通过将sca归纳到有限应变的实例中,本示例性研亢解决了上述局限性问题并证明了其预测非均质弹黏塑性材料(例如,多晶材料)的宏观机械响应的准确性和效率。通过这种方法,针对钛合金给出了两个涉及不切实际地需要大量的计算时间的实例研亢:第一实例是对具有不确定性的微观结构与性能的关系进行量化;第二实例是通过并行多尺度仿真来预测轧制过程中厚板的织构演变。以下各节讨论了有限应变mve问题的数据驱动的机械学sca方法以及有限应变情况下sca的准确性和效率,并与使用有限元方法(fem)和fft方法的参考解进行了比较。也给出了用于生成我们的结果的算法、实施方式和程序。有限应变自洽聚类分析微观结构体积单元问题可以通过在未变形构造中用公式表示的一组方程来描述mve在远场宏观载荷下的平衡力学响应:在这些方程中,p是第一皮奥拉-基尔霍夫应力(pk1应力);f是变形梯度;u是位移;x是材料点;ω是mve域。为简单起见,假设此处为纯变形型远场载荷f0。基于聚类的李普曼-施温格方程在周期性边界条件假设下,方程(8-1)给出的mve问题等效于李普曼-施温格方程其中,γ0是与任意参考刚度张量c0相关的四阶格林运算符;*表示由下式定义的卷积运算:γ0*(p-c0:f)=∫ωγ0(x-x′):(p(x′)-c0:f(x′))dω(x′)(8-3)为了在数值上求解方程(8-2),需要进行mve域分解。与通过界定精细(相对于最小特征尺寸的)网格做到这一点的传统的数值方法(例如,fem和fft)不同,sca采用了即将介绍的基于聚类的域分解方法。在此假设mve被分解为nc个非重叠子域,以下称为聚类。针对第j个聚类ωj,j=1,......,nc,将特征函数χj定义为:使用特征函数,将变形梯度和应力近似为:其中,fj是平均变形梯度;pj是第j个聚类中的平均应力。因此,可将方程(8-6)近似为:将方程(6)两边同时乘以χi,i=1,...,nc,并且对ω积分得到下式:简化上述方程,得到基于聚类的李普曼-施温格方程:其中,dij是由下式给出的第i个聚类和第j个聚类之间的相互作用张量:在此,|ωi|是第i个聚类的体积。sca分两个阶段求解基于聚类的李普曼-施温格方程。在脱机阶段,准备变形集中张量(称为小应变近似下的应变集中张量),并将其用来确定界定区域ωj,j=1,...,nc(域分解)的聚类,然后,计算这些聚类之间的相互作用张量。在联机阶段,使用这些数据和局部材料定律一起求解方程(8-8)。在方程(8-5)中做出的逐聚类近似的应用导致变形相容性的损失。这意味着,尽管连续的李普曼-施温格方程(即:方程(8-2))与参考刚度张量c0的选择无关,但是方程(8-8)中的基于聚类的近似却与此有关。为了获得更高的精度,提出了一种自洽迭代方案,以更新在每个荷载增量处的参考刚度张量c0,使得其近似于mve的有效切线刚度ceff。但是,这就需要在自洽迭代方案中更新相互作用张量,这会增加联机阶段的计算时间。幸运的是,通过强制使得c0具有各向同性,能够在脱机阶段完成大多数相互作用张量的计算工作。ceff及其各向同性近似的公式如下所示。脱机阶段:微机械数据库、聚类和相互作用张量计算sca利用mve中材料点的机械响应相似性来降低待求解的自由度。通过对某些机械响应的场数据进行聚类来发现这种相似性。通常可以使用变形集中张量。其定义如下式所示:其中f0是与mve的边界条件相对应的宏观变形;f(x)是mve域ω中的点x处的局部变形。在二维中,a(x)具有(2×2)2=16个独立分量,需要在四个正交荷载条件下进行直接数值仿真(dns)才能唯一界定。在三维中,a(x)具有(3×3)2=81个独立分量,要求在九个正交载荷条件下进行dns才能唯一界定。但是,对于先验已知的荷载条件的特定问题,可以将相同荷载条件的变形梯度(或应变)场用于聚类。准备好聚类数据以后,就可以使用聚类方法(例如,k均值聚类或自组织映射)来查找预定义数量的聚类。在自洽方案中,每次更新c0时,都必须重新计算相互作用张量。但是,如果c0是各向同性的,则大部分计算工作都可以在脱机阶段完成。各向同性参考刚度张量可以表示为:其中,μ0和λ0是参考拉梅常数。对应的格林运算符γ0可以分解为两部分:γ0=c1(μ0,λ0)γ1+c2(μ0,λ0)γ2(8-12)在此,c1和c2取决于λ0和μ0:项γ1和项γ2在傅里叶频率空间中具有简单的形式:其中,ξ是傅里叶频率点,且因此,相互作用张量可以表示为:其中:请注意,在方程(8-14)和方程(8-16)中,不取决于两个参数λ0和μ0,因此,仅需在脱机阶段计算一次。如果能够由规则栅格(即:体素)表示mve,那么利用fft算法就可以通过较少的计算量得到方程(8-16)中的卷积。其中,是fft运算,且是其倒数。多晶微观结构-性能数据库生成的过程在某些实施例中,用于生成多晶微观结构-性能数据库的实施过程包括以下步骤。1.如果不使用图像,则设置微观结构描述符;否则(a)加载3d图像;(b)测量微观结构描述符;2.运行dream.3d管线以生成m个mve;3.初始化m=1;4.针对mve的m设置每个晶粒k的聚类数量;5.针对mve的m,运行cpsca脱机计算:(a)若k=1,转到(d);否则继续;(b)使用fft计算弹性应变集中;(c)使用k均值聚类进行域分解;(d)使用fft进行相互作用张量计算;6.设置荷载条件;7.运行cpsca联机子例程;8.评估并将有效性能添加到数据库,并且m←m+;以及9.重复步骤4-8,直到m=m。联机阶段:自洽方案对于大的变形,递增地施加远场变形梯度。当前荷载步骤的增量远场变形梯度δδf0由定义。然后,方程(8)的增量形式给定为:其中,δfj和δpj是局部增量变形梯度和pk1应力。由于可以通过第j个聚类中的局部本构定律将δpi确定为δfj的函数,因此方程(8-18)的未知数为然后,能够使用牛顿的迭代方法在联机阶段求解方程(8-19)中给出的方程(8-18)的残差形式。逐个分量将系统雅可比行列式(jacobian){m}定义为:其中,是第j个聚类中材料的切线刚度张量,也是当前荷载增量时聚类中局部本构定律的输出。i4是由i4,klmn=δkmδln定义的第4秩等同张量,δij是指数i和j的克罗内克符号。牛顿法对增量变形梯度的更新可以表示为:{δf}=-{m}-1{r}(8-21)如前所述,还需要采用自洽迭代方案来更新每次荷载增量时的各向同性c0,使其近似于该荷载步骤中mve的有效切线刚度ceff。通常ceff可以通过下式得到:其中,δp0是由给出的当前荷载步骤的增量远场pk1应力;vi是聚类i的体积分数。是当前载荷增量的第i个聚类的变形梯度集中张量。注意:方程(18)的微分形式是d{δf0}={m}d{δf},计算得出每个增量,给出d{δf}={m}-1d{δf0},其中,{δf0}={δf0;...;δf0}有nc块δf0。将bij表示为与雅可比行列式(jacobian)系统成倒数的ij分量:{b}={m}-1,则,将||δp0-c0:δf0||2最小化,得到各项同性c0,其中,对于任意二阶张量z,||z||2=z:z。该方法的缺点是,在纯剪切或静水载荷条件下,优化问题是欠定的。在该示例性示例中,通过将“mve”的ceff投影到第4秩各向同性张量来完成近似。首先,将各向同性c0表示为:c0=(3λ0+2μ0)j+2μ0k(8-23)其中,4秩张量j和k定义如下:然后,注意:j::k=0,j::j=1,并且k::k=8(8-25)得到以下两个拉梅常数:其中,定义了双重收紧操作。sca的联机阶段算法在某些实施例中,sca的联机阶段的算法包括以下步骤。1.初始条件和初始化:(a)设置n=0、{f}n=(i2)、{p}n=0、{δf}n=0以及{δf}new={δf}n;(b)调用umat子例程得到cj,j=1,...,nc,并设置参考刚度2.针对荷载增量n+1,更新相互作用张量部分{d1}和{d2};3.牛顿迭代法(a)调用umat子例程得到{δp}new和{c};(b)计算残差{r};(c)计算系统雅可比行列式(jacobian)(d)求解线性方程{m}{δf}=-{r}for{δf};(e){δf}new←{δf}new+{δf};(f)如果不满足则转到3(a);4.计算有效切线刚度ceff并将其投影至4秩各向同性张量,得到5.如果不满足则转到步骤2;6.{f}n+1←{f}n+{δf}new,{p}n←{p}n+{δp}new,n←n+1并更新umat子例程的状态变量;7.重复步骤2-6,直到完成仿真。数值验证通过在有限应变时阐述mve问题,我们现在能够正确地考虑那种依赖于变形梯度乘法分解的一般弹黏塑性本构定律。本文给出了这种定律(通常称为晶体可塑性)的一种常见应用,描述了单晶的机械行为。通过与两种全场方法进行比较,验证了使用这种材料定律来预测多晶聚类的宏观响应。结果表明:sca显著降低了自由度和计算费用,从而获得了类似结果。弹粘塑性材料模型在一般的弹粘塑性材料模型中,局部变形梯度f被乘法分解为弹性分量fe和非弹性分量fin:f=fe·fin(8-27)fe是弹性拉伸和刚体旋转的组合,fin与不可恢复的变形机制(例如,位错滑移或相变塑性)相关,弹性本构定律由下式给出:其中,ee是弹性的格林-拉格朗日应变;se是第二皮奥拉-基尔霍夫应力;cse是第4阶弹性刚度张量;i2是第二阶等同张量。仅将非弹性项作为塑性变形(fin=fp),可以使用塑性本构定律确定非弹性变形梯度fin,以通过下式将弹性速度梯度与滑移系统α中的塑性剪切速率相关联在此,和是单位矢量,其定义了未变形构造中的滑移系统α的滑移方向和滑移面法线;nslip是主动滑移系统的数量;是二元乘积。通常,滑移系统α中的塑性剪切速率是该滑移系统中的分解剪切应力τα、变形阻力以及背应力aα的函数。分解剪切应力由下式给出:其中,σ是柯西应力;s(α)是滑移方向;n(α)是滑移面法线,所有这些都是在变形构造中定义的。它们是利用下式根据未变形构造中的对应项计算得出的。对于可以使用任何合适的演化定律。在该项工作中,我们选择使用由下式给出的的幂次定律:其中,是参考剪切速率;是与材料应变敏感性有关的指数。给出了变形阻力(各向同性硬化项)和背应力αα(运动硬化项)的演化定律:其中,h和h是直接硬化系数;r和r是动态恢复系数。请注意:在方程(8-33)中,我们假设潜在硬化和自硬化效果是相同的。为了说明晶粒尺寸对表观性能的影响,引入了霍尔-佩奇(hall-petch)型方程,通过下式,该方程将晶粒中的初始滑移系统变形阻力与该晶粒的等效球体直径(esd)d关联起来。其中,是固有初始滑移阻力;kα是晶粒尺寸强化系数。该方程近似计算晶粒边界对位错滑移的阻碍效应。在给定变形梯度增量δf的情况下,根据所给出的数值算法,能够算出相应的pk1应力的增量。还给出了用于将该材料定律与sca结合的切线刚度晶粒骨料的拉伸行为在该项工作中考虑使用的材料是完全转变的α-相钛合金,其包含24个活性六方密堆积(hcp)滑移系统:3个基部、3个棱柱、6个一阶椎体和12个阶椎体。假设弹性刚度基质是横向各向同性的,其分量如表8-1所示,其中,cij是沃伊特符号表示的刚度分量。在此使用的塑性定律的材料参数如表8-2所示;前四项使用校准后的值,其余项为假设值。表8-1:hcp钛合金的横向各向同性弹性刚度分量分量值(mpa)分量值(mpa)c11=c221.70×105c332.04×105c44=c551.02×105c660.36×105c12=c210.98×105c13=c310.86×105c23=c320.86×105其他cij0表8-2:hcp钛合金的晶体塑性参数[*]jthomas,mgroeber和sghosh,用于ti-6a1-4v合金的微观结构相关性能的基于图像的晶体可塑性有限元框架,《材料科学与工程》:a,553:164-175,2012。所考虑的微观结构是八个大小相等的40μm×40μm×40μm的立方体晶粒的理想的mve,如图109中分图(a)所示,根据图109中图(b)给出的反极图8进行着色,并以z面法线作为参考方向定义。这样使得fem和fft能够使用相同的网格和网格细化。mve在x方向上以10-4/秒的应变速率经历单轴拉伸变形,直到最大应变达到0.02。利用sca、fem和fft三种方法以200的增量施加该变形。在下文中将这些方法称为cpsca、cpfem和cpfft,其中cp是晶体可塑性的缩写。对于cpfem而言,abaqus/standard与c3d8r单元以及作为umat实施的用户资料一起使用,用于隐式分析。对于cpfft而言,采用牛顿-克雷洛夫求解器来实施。对于cpsca而言,脱机聚类数据是使用建模为各向异性弹性且具有相同总体荷载历史的材料来准备的。将峰值远程应变处的弹性应变场用作脱机数据,以使用k均值聚类方法获得聚类。图109中图(c)示出了使用具有10×10×10个体素网格的fem而获得的脱机数据的弹性应变分量e11的分布。图109中分图(d)示出了使用k均值聚类方法获得的128个聚类(16个聚类/晶粒)的分布。为了表明cpsca的准确性,将采用全场方法得到的收敛宏观尺度应力-应变曲线用作参考解。将网格细化为60×60×60,可以得到收敛解,对于cpfem而言,将产生648000个自由度,对于cpfft而言,将产生1944000个自由度。图110中图(a)-(b)示出:弹性响应对网格细化不敏感,而具有粗糙网格的cpfem和cpfft结果之间的塑性变形状态存在显着差异,并且通过细化网格可以达到非常相似的结果。在下面的比较中,参考解是具有60×60×60个栅格或27000个栅格点/晶粒的cpfft结果。每个晶粒的四个不同聚类数(从1到64)(自由度总数从72到4608)用来表示cpsca的收敛性。图110中图(c)-(d)示出:即使在弹性变形状态下只有1个聚类/晶粒,cpsca的解也是无法区分的(相差1%以内)。在塑性变形状态方面,随着使用的聚类的数量越来越多,cpsca的解逼近cpfft的解。仅对几个自由度进行求解,cpsca具有高效率,而不需要牺牲太多的精度。为了证明这一点,针对不同数量的聚类,将0.2%的塑性应变偏移(σ0.2,接近屈服点)和0.4%的偏移应力(σ0.4,远离屈服点)与参考解进行了比较。在图111的分图(a)中示出了这种差异。σ0.2之间的差异随着聚类数量的变化而变化,但总是低于0.4%。相反,σ0.4之间的差异可高达1.4%,但其随着聚类数量的增加而单调减少。图111中图(b)示出在脱机和联机阶段中cpsca所需的cpu时间随着所使用的聚类/晶粒的数量的变化而增加。对数轴上的斜率在脱机阶段约为2,在联机阶段约为3。这是因为在脱机阶段聚类之间需要计算的相互作用张量的数量为。在联机阶段,基质反转的复杂度为。使用64个聚类/晶粒所需的时间与使用40×40×40栅格的cpfft所需的时间相当,但与使用相同网格的cpfem相比快两个数量级。如果使用大量群集,则随着群集数量的增加,计算时间主要在联机阶段增加。实例研究1:预期有效性能的不确定性微观结构建模的一种应用是评估块状材料的有效特性。例如,在单调拉伸载荷情况下,虚拟拉伸测试直接通过均质化来预测总体应力-应变曲线。由此,可以提取诸如有效弹性刚度和屈服强度之类的常见标量材料性能。在循环荷载情况下,能够使用局部应力和应变信息来评估疲劳寿命。由于计算费用和微观结构随机性限制了mve的大小,因此需要对预测的有效性能进行不确定性量化。为此,使用上面介绍的sca方法来计算mve均质化的多个实现形式。在图112中示出了用于生成mve性能数据库的流程图,该流程是用该算法实施的。在本节中,此流程用于量化在不同织构和晶粒尺寸效应情况下屈服强度的不确定性。合成的微观结构体积单元如引言中所述,尽管能够通过从3d实验图像或晶粒生长仿真中提取体积信息来获得mve,但是这种方法的成本可能非常高昂,因为需要许多mve来生成微观结构性能数据库。更实际的做法是,通过常规的2d实验表征能够测量微观结构特征参数的统计分布,并将其用于合成构建mve。为了构建多晶mve,我们使用软件包dream.3d,该软件包包括生成微观结构的工具,所述微观结构尽可能地遵守预先确定的描述符的统计信息。该项工作重点在于改变多晶材料的两个微观结构描述符:晶粒取向分布函数和晶粒尺寸分布函数。晶体取向分布函数(odf)(又称织构)定义了微晶在取向q附近落入无穷小邻域的概率密度f(q),通常用欧拉角将其参数化。在这项工作中,我们使用欧拉角(φ1,φ,φ2)的邦吉约定(bungeconversion),这些欧拉角定义了绕z轴旋转,然后绕新的x轴旋转,然后又绕新的z轴旋转。在dream.3d中,将取向空间离散为分箱(bins),并且能够通过指定一些取向来生成具有较强织构的晶体取向分布函数(odf),相应的权重被定义为随机分布(mrd)的倍数,mrd值减小到零所使用的分箱的数量从输入取向的分箱呈二次方减小。假定晶粒分布函数为对数正态分布,概率密度函数为:其中,d是晶粒的等效球形直径(esd);σ是比例参数;μ是形状参数。为了真实地合成完整的微观结构,还需要其他描述符,例如,取向错误分布函数、长宽比和邻单元数。织构对有效性能的影响为了显示织构对屈服强度的影响,考虑了四种织构:无织构、优选的(0,0,0)、优选的(90,45,0)和优选的(90,90,0)。使用dream.3d合成了五十个立方体mve,对于四个织构实例中的每一种,晶粒尺寸分布参数μ=19.7μm,并且,σ=2.7μm。每个mve有大约90个等轴晶粒,以81×81×81个体素网格为代表,每个体素的分辨率为1μm×1μm×1μm。图113示出了这些织构实例的示例mve。所有mve在x方向上以10-4/秒的应变速率经受单调的单轴拉伸,直到最大应变达到0.02。图114示出了使用具有一个聚类/晶粒的cpsca预测的应力-应变曲线。根据这些预测中的每一个来测量有效杨氏模量和0.2%偏移屈服强度,并在图115中进行比较。具有优选的(90,90,0)织构的mve通常具有最高的屈服强度。具有优选的(90,0,0)织构和(90,45,0)织构的mve通常具有大致相同的屈服强度,并且屈服强度是最低的。没有织构的mve介于两者之间。另外,还示出了每种情况下屈服强度的变化。晶粒尺寸对有效性能的影响通过设置方程(8-35)中的σ来研亢晶粒尺寸对屈服强度的影响,以便产生介于10μm和40μm之间的四种不同的平均晶粒尺寸。针对每个σ值,使用dream.3d生成没有织构的等轴晶粒的五十个mve,同时使所有其他参数保持相同。每个mve用81×81×81的体素网格表示。图116中示出了具有不同晶粒尺寸的样品mve。所有mve都在x方向上以应变速率10-4/秒经受单调的单轴拉伸,直到最大应变达到0.02。图117示出了预测的有效杨氏模量和0.2%偏移屈服强度与平均esd的分布图。平均杨氏模量对平均esd不敏感。正如预期的那样,还观察了平均屈服强度和平均esd之间的霍尔-佩奇(hall-petch)型关系。但是,随着mve中晶粒数量的减少,不确定性随平均esd的增加而增加。这是因为晶粒越少,mve越不具有代表性。实例研究2:轧制过程的并发多尺度仿真基于微观结构的高效建模的另一种应用是有限变形过程的仿真,其中,微观结构广泛发展并产生复杂的宏观行为。对于此类应用,通常很难在宏观尺度上找到形式简单的现象学本构模型。此外,对于微观结构不同的新材料,必须重新校准现象学本构模型。在本实例研亢中,可以看出,基于cpsca的微观结构建模的速度使得并发多尺度模型能够用于微观尺度上有限应变非常重要的应用中。我们以金属轧制过程为例。在微观尺度上,织构的演变是非常重要的,它取决于整个部件的宏观尺度载荷和应力分布。为了满足这一要求,需要使用多尺度方法。厚板的轧制过程的示意图如图118中图(a)所示。初始厚板的高度(h)为40mm,厚度(t)为40mm,长度(l)为92mm。辊子的半径为170mm,旋转速度为2π/秒,因此轧制速度(辊子表面速度)为1.07m/秒。假设轧制板的高度为30mm。在初始厚板中,假设微观结构是具有随机的晶格取向(无织构)的等轴hcp晶粒,平均晶粒尺寸为26μm。仿真目标是预测轧制过程中的部件变形以及微观结构演变。通过对所有晶粒进行显式建模(此处研亢的厚板具有超过200亿个晶粒),该系统的直接数值仿真已超过了现代的计算能力。另一种方法是使用如图118中图(b)中示意性示出的两尺度并发多尺度仿真方法。该板(宏观尺度下)与mve(微观尺度下)完全结合,使得宏观尺度积分点的变形梯度作为远场载荷被传递到与其关联的mve,然后,解决mve问题,并且将均质应力传递回宏观尺度积分点。在计算方面,使用这种方法和全场方法(例如,针对微观尺度mve问题的fe2)的大多数文献研亢仅限于2d问题。在本实例研亢中,我们将展示cpsca能够在合理的计算时间内实现微观结构演化的逼真3d仿真。对于宏观尺度问题,采用了隐式时间积分方法,以便能够使用更大的时间增量。假定辊子和板之间具有库仑摩擦,则将板拉过轧机机架的摩擦系数为0.3。厚板的初始速度为1.07m/秒,以减少板和辊子之间可能造成数值困难的冲击。利用对称性,仅对1/4的板和单个辊子建模。1/4的板与2994个均匀的六面体单元形成网格,并且使用优良的刚性单元对辊子建模。降阶积分与基于刚度的沙漏控制一起使用。对于微观尺度问题,选择mve包括90个随机取向的等轴晶粒(图118中图(b)所示),并且每个晶粒用一个聚类表示。使用商业软件abaqus/standard实现宏观尺度动态分析,而且将微观尺度cpsca方法实施为用户材料子例程,或者umat.8提供了在umat中时间步结束时计算应力的步骤。使用方程(8-22)计算abaqus/standard要求的切线刚度张量。轧制时间为0.1秒时停止仿真。图119中图(a)-(b)示出了轧制0.08秒后的剪切应力σ12的轮廓线,这是使用多尺度3d仿真预测的。为了进行比较,在图119的分图(c)中示出了2d平面应变仿真结果。这表明在对称平面上3d仿真和2d仿真具有相似的剪切应力分布模式:在板和辊子之间的接触区域附近的交替的正、负剪切应力值。然而,3d仿真显示在厚度方向(z方向)上的剪切应力不均匀。3d仿真预测在轧制方向上的变形较小而极限剪切应力较高。图120示出了由图119的分图(a)中的红色箭头表示的3个单元的σ12随着轧制进度而发生的变化。对于所有3个单元,σ12交替出现并最终达到一个稳定的非零值。更加靠近接触区域的单元的剪切应力值具有交替次数多、振幅大的趋势。并发多尺度仿真的另一个优点是:在整个制造过程中求解微观结构的演变。图121示出了在图120中红色垂直虚线所示的时间点上,三个单元的每个积分点在轧制过程中mve变形和(001)(用mtex生成的)极像图的照片。这表明:相对于轧制面,宏观部分位置不同的mve的变形和旋转是不同的:在远离接触表面的地方(将单元a与单元c比较),晶体旋转和剪切较少,压缩较多。从极像图中能够看到每个晶粒的旋转,其中,每个点表示使用立体投影技术在平面上绘制的晶粒的晶格取向。在轧制过程中,这些点集中在圆的横向两端附近,这意味着晶粒取向朝y方向(最大压缩方向)旋转。这与冷轧、纯α相钛的织构的实验结果相吻合。据认为,这种织构是由当前模型捕获的位错滑移引起的。请注意,由于双晶形成导致织构不同。为了更准确地预测钛系统的演化,可以将我们的模型扩展为捕获双晶形成。使用具有72核(三个节点,每个节点具有两个intelhaswelle5-2680v32.5ghz12核处理器)的abaqusmpi并行化,并发仿真大约需要112小时。总之,开发有限应变自洽聚类分析方法,并将其应用于一般弹塑性粘塑性材料的相互作用并演化微观结构模型。在初始拉格朗日构造中重新阐述该方法,从而解决大变形的问题。通过与有限元分析和基于快速傅里叶变换的方法进行比较,证明了预测多晶材料整体机械响应的准确性和效率。结果表明:cpsca具有很高的精度,并且大大降低了自由度。在我们的实例研亢中,晶粒是在由预定义的微观结构描述符重建的基于体素的mve中被明确解析的。这些mve用于定量地不确定预测织构对屈服强度的影响以及晶粒尺寸对屈服强度的影响。最后,对轧制过程进行并发多尺度仿真,示出了整个轧制部分的异质微观结构演化。这种方法的效率可能实现这一点。潜在的应用包括仿真驱动的微观结构设计和制造过程控制。示例9集成计算材料工程(icme)复合材料的建模和表征1.基于原子信息的树脂注入模型在这项工作中,建立了环氧树脂的预测原子模型,并对其热机械性能及其对树脂基质的分子化学的依赖性进行了表征,所述热机械性能包括树脂功能性、交联度和组分比,证明了利用原子仿真预测关键材料性能和趋势的可行性。此外,我们还提出了一种分层多尺度模型,在该模型中,将md仿真结果均质化为热塑定律,以描述环氧树脂的本构行为。已经将该热塑性定律用于rve建模,以预测cfrp复合材料的刚度和强度。此外,我们对碳纤维与树脂基质之间的纳米级中间相的性质进行了表征,并将中间相集成到cfrp的机械连续体模型中,并阐明了中间相区域对复合材料失效行为的显著影响,这样可以形成一些见解,用于将来指导防失效复合材料的设计策略。环氧树脂具有优异的热机械性能,使其得到广泛的应用,尤其是用作纤维增强型复合材料中的基质材料。树脂可以形成高度交联的分子结构,使其具有优异的热机械性能。环氧树脂的纳米尺度仿真提供了一种很好的方法来表征其性能以及对分子级别因素(如:树脂类型和交联密度)的依赖性。此外,深入了解热机械性能对分子级别结构的依赖关系,对于将来针对具有优化的机械性能的环氧树脂指导基于计算的设计是至关重要的。已经成功将环氧树脂上的原子分子动力学(md)仿真应用于预测各种材料性能。为了研亢交联结构的物理性能,已经开发了几种计算方法来生成合理的交联结构。已经进行md仿真来预测玻璃转变温度(tg),并为应变速率、温度和交联度对杨氏模量和屈服行为的影响提供了有价值的见解。尽管在了解环氧热机械响应方面取得了重大进展,但是能够在长度尺度和时间尺度之间建立桥梁(尤其是将原子尺度和连续体尺度结合)的多尺度模型仍然是一项特殊的挑战。为了克服这一挑战,我们首先通过捕获特定的交联结构来开发具有代表性的环氧树脂的纳米尺度模型。然后,我们根据md仿真来表征弹性行为、屈服行为和屈服后行为。此后,根据md仿真结果生成了屈服面,可以用抛物面屈服准则很好地描述这些屈服面。此外,通过添加塑性势和硬化定律,提出了热塑定律来描述环氧树脂的本构行为。在此过程中,我们还说明了环氧树脂的热机械性能(例如,环氧树脂的类型、组分比和交联密度)对分子化学的依赖性。另外,处于纤维和树脂基质之间的中间相区域具有异质的化学和物理特征,并且具有亚微米尺度的厚度。虽然中间相区域比纤维直径小得多,但是已经表明:中间相区域在cfrp复合材料的性能中起着至关重要的作用。对中间相区域准确建模或对其进行表征依然是一项巨大的挑战。为了克服在纳米实验中遇到的障碍,已经报道人们使用分析模型或md分析来表征中间相区域。但是,几乎没有哪项研亢将纳米尺度中间相区域与rve建模接合起来并且研亢中间相区域对宏观复合材料响应的影响。为了解决这个问题,我们首先根据md仿真结果和通用的解析梯度模型得到中间相区域的性能。然后,将中间相区域的一般性能并入改进的rve模型,该模型中包括三相,即:纤维相、基质相和中间相。改进的rve模型在预测复合材料的模量和失效强度方面有显著提高。生成环氧树脂的实际交联结构和屈服面计算我们选择了两种具有代表性的环氧体系作为模型系统:(1)一种商业名称为epon825的环氧树脂,其包括双酚a的二缩水甘油醚(dgeba)和固化剂3,3-二氨基二苯砜(33dds);(2)一种商业名称为3501-6的环氧树脂,其主要由四缩水甘油基亚甲基二苯胺(tgmda)与固化剂4,4-二氨基二苯砜(44dds)组成。我们将polymatic算法与lammps软件包集成在一起,对交联过程进行仿真。基本上,根据成对的分隔距离,在合适的原子之间添加了共价交联键。另外,对于形成的每几个交联键,使用md进行能量最小化和平衡仿真,以减轻产生的应力。该工作流程能够根据不同的初始化学成分和组分比率生成具有不同交联度的环氧树脂的原子结构。为了获得典型环氧树脂的屈服面,首先根据md仿真在不同温度和5×108s-1的应变速率下计算epon825模型系统的应力-应变响应。我们注意到:因为所用的时间步长很短,在md仿真中固有高的应变率。在这些仿真过程中,应用适当的温度调节以将系统维持在指定的温度。图122中示出了单轴拉伸和压缩载荷情况的结果。从图中可以看出,两个载荷的整个应力-应变响应均取决于温度,且影响屈服应力和弹性模量。在玻璃状聚合物的md仿真中,这种行为是众所周知的。随后获得的模型系统在不同温度下的屈服面如图123所示。我们采用了常用的惯例,即:屈服应力对应于应力-应变曲线中的最大点或明显的“拐点”。我们发现:md结果与抛物面屈服面之间具有良好的一致性。该屈服准则由压缩屈服应力和拉伸屈服应力这两个材料参数唯一确定。其中,j2是偏应力张量的第二个不变量;i1是应力张量的第一个不变量。σt和σc分别表示拉伸屈服应力和压缩屈服应力。由于在进行md仿真时的应变速率高,因此得到的屈服应力高于实验中得到的值。然而,我们进一步发现:可以用方程(9-1)所示的同一标准来很好地描述屈服应力的实验结果。图123示出了在不同温度下得到的屈服面,其中,点是仿真数据,线是使用方程(9-1)进行的理论预测。与其他可塑性公式相似,此处公开的热塑性定律是由下文所述的屈服面、塑性势和硬化定律定义的。首先,为了防止在静水压力下出现正的体积塑性应力,具有非关联流动规则的塑性势定义如下:其中,是冯·米赛斯等效应力;p=1/3i1是静水压力;α是用于校正塑性流体积分量的材料参数,该参数等于:其中,υp是塑性泊松比。树脂基质的这种热塑性定律已被整合到cfrp的机械连续体模型中,由实验结果确定其基本参数。使用该定律,环氧树脂的特征屈服面与实验结果非常吻合,误差小于5%,从而实现了该项目的目标。该框架用于开发交联环氧树脂结构以及屈服表面表征,通常适用于具有不同化学性质的其他环氧树脂体系。热机械性质对分子化学的依赖我们还研亢了环氧树脂的大变形行为,并在原子级别上对其失效响应进行了表征。在大变形过程中,环氧树脂的网状结构中不可避免地会出现断键现象。为了捕获真实的键断裂现象,我们采用了反应力场,并已经对其进行验证,以保留在此研亢的环氧树脂的弹性和塑性响应。图124绘出了具有不同的交联度和组分比的3501-6环氧体系的应力-应变曲线。在所有情况下,均观察到一致的“弹性-屈服-硬化-失效”行为。随着交联度的增加,屈服应力和最大应力均会增加,这与失效应变或可变形性的降低有关。改变组分比在应力-应变曲线中导致微小的变化,但是改变化学计量比会导致最大的屈服应力和最大应力,同时导致最低的可变形性。因此,根据原子级别的拉伸仿真,我们发现:树脂的分子化学成分显著影响其机械性能和失效响应。建立在拉伸仿真的应力-应变曲线和量化结构变化(例如,链的重新定向和空隙的形成)的参数基础上,我们根据连续体断裂力学模型,将树脂的原子级别失效响应与其宏观断裂特性联系起来。这项工作为控制环氧树脂断裂特性的分子机理提供了物理见解,并且证明了成功地使用了原子仿真来预测宏观断裂能。我们要注意的是,计划中研亢环氧树脂的大变形和失效行为的方法是开发环氧树脂的粗粒度模型,这样能够提高计算效率。将所捕获特定的化学细节用于原子仿真则不适于该计划的方法。虽然原子仿真的计算成本更加昂贵,但是原子仿真让我们能够直接预测热机械性能,而且不必校准粗粒度模型的力场。此外,反作用力场为纳米尺度树脂的应力导致的断键事件和失效响应提供了更加准确的预测。更加重要的是,与粗粒度模型相比,告知屈服面准则和热塑性本构定律的多尺度方法在连接长度尺度和时间尺度方面更加有效。中间相性能表征由于碳纤维的表面粗糙度、纤维制造过程中的表面处理以及基质受影响的区域,碳纤维周围存在亚微米级厚的中间相区域。通过透射电子显微镜(tem)的分析,估计中间相区域的厚度约为200nm。在此,将中间相区域进一步简化为与纤维相邻的柱状壳体,其内半径rf与纤维半径相同,外半径ri=rf+200nm,如图125所示。在下文中,下标f、i和m分别表示纤维、中间相和基质。尽管目前尚未对中间相区域进行定量表征,但是我们了解了中间相区域内部的性能变化的一些基本信息。第一,在内边界和外边界,中间相的物理性质和化学性质均与相邻的相一致。第二,在中间相区域,从纤维性能到基质性能之间存在明显的梯度。第三,由于纤维表面和树脂基质的胶料之间不相容,我们预期中间相区域的部分区域将达到较低的交联度。实验观察表明:失效最先发生在中间相区域的内部,进一步证明了存在弱的区域。在上一节以及图124中,我们表征了交联度对典型环氧树脂的弹性模量和强度的影响。结果表明:未充分交联的环氧树脂(约70%交联度)和完全交联的环氧树脂(95%交联度)之间的杨氏模量差约为20%,而两者之间的强度差则高达50%。我们用ems和σms表示中间相区域内的杨氏模量和强度的下限值。为了表征中间相区域的平均性能,我们采用了解析梯度模型来描述中间相内部的模量和强度分布。此外,我们整合了在交联不足的树脂上进行的md仿真的结果,以得到ems和σms。在此提出的梯度模型包括两个部分。在第一部分中,杨氏模量和强度从纤维值降低至最低值,即:ems和σms。在第二部分中,上述值逐渐从最低值增加至块状基质的值。第一部分出现的降低趋势是由于纤维约束效应减弱,而第二部分出现的增加趋势是由于充分交联导致固有的环氧树脂硬化。我们利用纤维和基质的性能来制定中间相区域的边界条件。假设最低值(ris)的位置位于中间相与纤维表面之间的距离的四分之三(0.75)处。选择该位置为靠近基质侧,这是由于胶料与块状基质树脂之间的不相容性是导致交联不足的主要原因。还进行了灵敏度分析,验证交联不足的区域的假设位置对中间相的平均性能的影响较小。假设中间相区域的性能变化遵循以下指数函数:其中,k可以是e(杨氏模量)或σ(强度),构建函数r(r)和q(r)与边界条件匹配:可以得到中间相的平均杨氏模量和强度:将杨氏模量和强度的数值代入上式,我们最终得到了中间相的平均杨氏模量和强度。与基质模量和拉伸强度相比,中间相区域的平均杨氏模量和强度分别增加了约5倍和9倍。虽然部分中间相区域由于交联不足而变弱,但是与块状基质相比,中间相区域表现出明显的硬化反应。假设中间体的本构行为和破坏模型与块状基质的本构行为和破坏模型相似。将这种硬化的中间相区域并入ud复合材料的rve模型中,与不具有中间相区域的传统两相模型相比,大大提高了rve的精度。因此,明显体现了该中间相区域的重要性。我们在环氧树脂原子建模方面的工作将为未来基于计算的环氧树脂设计提供指导。原子分子动力学仿真作为集成计算材料工程(icme)的重要组成部分,将通过该技术的商业实施进一步优化材料设计的流程。第一,高度交联的环氧树脂的纳米尺度仿真为开发新的连续体理论和模型提供了颇具前景的方法。完全原子模型特别具有吸引力,因为它们基于基本输入信息(力场和化学结构),不必校准现象学定律。第二,分层多尺度方法是一种基于从较小尺度到较大尺度按照顺序进行均质化的方法,能够将信息从原子级别或纳米尺度级别有效地转移至宏观连续体级别。在这项工作中,已经从原子仿真中获知了屈服面准则,并将其集成至宏观模型中。第三,本文揭示了热机械性能对分子化学的依赖性,表明:通过整合分子模型中的数据,可以加快热固性材料的材料设计过程。接下来可能利用分子仿真来指导环氧化合物或组分比例的设计,以优化热固性树脂的强度和韧度。最后,我们已经证明:利用分子仿真和解析模型,我们能够展示纤维和基质之间的独特的中间相区域性能。随后,我们阐明了该中间相区域对复合材料的失效行为的显性影响。在此基础上,未来的潜在工作可能涉及用于防失效复合材料的基于计算的设计策略,例如,中间相区域内的特定的纳米工程结构和化学成分。2.预制品成型预制品研亢使用实验与计算方法来帮助理解预成型工艺过程中的材料机械行为。然后,基于对材料行为的观察,开发出了高保真度的预成型仿真模型。这些模型从宏观的零件级别开始,发展到介观复合材料级别,最后形成多尺度仿真策略。多尺度策略使用户能够全面了解工艺参数优化和较低级别的复合材料设计。为了验证仿真模型,开发并且执行采用剪切角和成型力测量技术的预成型基准试验。这些基准试验利用工艺参数的各种组合,为预成型工艺设计提供了深刻的指导。开发一种碳纤维复合材料制造工艺的传统试错法在很大程度上依赖于实验,需要大量的原材料消耗和较长的开发周期。为了解决这一成本问题,针对预成型工艺所开发的实验与计算方法形成一个完整的系统,其利用计算能力和虚拟制造工具来协助设计和优化碳纤维复合材料预成型工艺。实验研亢揭示了复合材料预浸料在制造工艺中的行为,特别是与常规金属成型工艺的区别,例如温度控制、纤维重新取向、表面相互作用等。这些行为说明了根据先进复合材料的需求调整制造技术的重要性。另一方面,计算建模研亢完成了整个软件包,所述整个软件包使学术领域或工业领域的研亢人员能够虚拟地设计和优化碳纤维预浸料预成型,这有助于降低碳纤维复合材料制造开发的成本并扩宽这种先进复合材料的应用。为了批量自动化地制造用于运输设备的cfrp零件,热成型是适当的选择,因为它可以提供较高的生产速率,并且实现相对复杂的表面几何形状、良好的产品质量和较低的设备成本。在热成型工艺中,第一步是以优化的纤维取向组合来堆叠数层由未固化的热固性树脂浸渍的热固性碳织物(预浸料)。然后,加热这些叠层以软化树脂,随后在预成型步骤过程中在压力机上将其成型为所需的3d形状。最后,将零件固化以获得所设计的零件形状。在热成型中,大多数纤维重新取向是在预成型步骤中进行的,所述预成型步骤代替了传统的高成本且低速率的手工铺设工作。由于复合材料的机械刚度和强度主要受纤维方向的影响,因此选择预成型参数(例如工艺温度和初始纤维取向)对最终零件性能(包括各种载荷条件下编织物中剪切带和扭结带的形成)至关重要。为了优化预成型参数并生产出无缺陷的零件,通常会进行大量具有不同参数组合的试验。但是,原材料的消耗和较长的开发周期增加了生产的成本和时间,由此妨碍了热成型的实用性。为了解决这个问题,开发出了几种计算模型来仿真预成型工艺,以预测纤维取向、几何形状、零件上的起皱行为,以及成型力。第一种广泛使用的预测预成型工艺过程中的编织cfrp行为的计算方法是基于纯运动学的枢接网(pjn)假设。然而,对织物和树脂的机械特性的了解不足会导致预测不准确,尤其是对于起皱预测。作为替代,有限元方法(fem)引起了越来越多的关注。许多文献中记录了对预成型工艺过程中的纤维取向、拉缩量和起皱行为预测进行仿真。jauffre等人结合1d梁单元和2d壳单元分别对材料的拉伸行为和剪切行为进行仿真。但是,这种混合单元的网格化过程费事且耗时。hamila等人开发了一种半离散三角形壳单元,并且基于内部虚拟工作对该问题进行处理。缺点是该半离散三角形壳单元适用于内部开发的fem软件,从而限制了其在工业领域中的使用。在ls-软件中,存在内置的编织织物材料模型,例如mat_234和mat_235。但是,这两个模型都是基于介观尺度力学的,因此需要输入介观尺度材料参数,例如纱线模量和纱线间相互作用系数。在实践中发现,对于这些参数,难以进行直接的实验表征,并且进行反向计算非常耗时。为了实现商业化和用户友好操作,西北大学开发了一种用于cfrp预成型仿真的非正交材料模型,并且该非正交材料模型被实现在商业fem代码中作为用户自定义材料子例程。尽管在新的本构定律中将拉伸行为和剪切行为结合的想法因其最通用的形式而值得称赞,但是尤其当编织cfrp经受较大的剪切变形时可能不准确。作为进步,本发明中发明了一种改进的用于编织cfrp预成型工艺的非正交模型。该非正交模型已通过基准试验进行验证并且通过该学术和工业团队的共同努力已将其并入ls-软件中作为mat_comprf(mat_293)。为了进行可靠的预测,需要在计算模型中表征并采用真实且准确的材料特性。在预成型过程中,预浸料将经受拉伸、剪切和弯曲变形,如图126所示。图126还示出了当不同的预浸料层具有不同的初始纤维取向时,在预浸料表面之间将发生较大的相对滑动。综上所述,预浸料的实验表征的指标是:拉伸、剪切、弯曲和表面相互作用。用于表征一个预浸料层内的特性的最广泛采用的方法是:1)确定复合材料的拉伸模量的单轴拉伸试验;以及2)测量编织复合材料的剪切模量的偏向延伸试验。这两个试验的可靠性和可重复性已经通过使用不同的设备来研亢一组相似的材料进行了验证。为了正确仿真成型工艺过程中的材料行为,还需要材料的弯曲刚度。然而,预浸料在预成型温度下的柔软性使得难以通过标准的三点弯曲试验来测量弯曲刚度。开发出了一种利用自重使试样弯曲的可替代的悬臂梁方法,并将其用于测量预浸料的弯曲刚度。但是,对于预浸料表面相互作用的表征,尽管该相互作用确实影响预成型后的纤维取向,并且在最终产品性能方面起着重要作用,但在该集成计算材料工程(icme)项目之前,仍缺乏系统性研亢。为了填补这一空白,我们在本发明中设计并构建了一种创新的试验设备。基于我们对这种表面相互作用机制的观察,还构造了一种流体润滑的相互作用模型来分析和预测预浸料层之间的相互作用。这个数值模型和实验一起揭示了纤维相互作用的细节,例如其强度和周期性图案。实验预浸料的表征可以提供可靠的结果,但是它也有一些缺点。主要缺点是只能达到有限的载荷状态。例如,单轴拉伸试验只能引入纯拉伸变形,而偏向延伸试验只能引入纯剪切变形。因此,拉伸与剪切之间的接合不能被物理地表征并且随后被实现在数值模型中。尽管在大多数情况下,由于未固化的预浸料的剪切模量始终比其拉伸模量小几个数量级,所以这种忽略不会显著影响几何形状和纤维取向的预测,但会在预成型应力和冲压力的预测中引入误差,因此会降低缺陷(例如纤维纱线的断裂、拉出和分离)的分析精度。为了解决上述问题,设计出了几种新的试验装置,例如双轴拉伸设备和具有拉伸调节功能的相框设备。然而,实际上,由于三维几何形状的复杂性和所得到的非线性载荷路径,这些复杂的装置仍无法涵盖预浸料在预成型过程中将经历的所有应变状态。另外,这些实验表征方法是在宏观尺度上进行的,因此无法提供关于介观尺度复合材料结构和成分如何影响材料的机械特性的有见地的信息。在计划的实验中还需要考虑原材料成本和试验时间。为了解决这个问题,在本发明中,我们基于介观尺度的代表性体积单元(rve)对预浸料进行表征,开发了一种新的多尺度预成型仿真方法以对拉伸-剪切的结合做出说明,并将所述多尺度预成型仿真方法应用于2×2斜纹热固性预浸料的预成型仿真。构建一种紧密填充的编织rve模型的挑战包括结构生成和介观尺度纱线特性表征。为了构造具有准确编织图案和纱线几何特征的rve,开发出了几种不同的方法。一种方法是直接使用cad软件来设计和输出rve结构。对于特定的复合材料结构,这种方法虽然简单且适用,但很耗时,这是因为对于每种特定的复合材料,都需要分别绘制结构,并且当纱线表面的几何形状变得复杂时,纱线的横截面形状需要手动识别。为了使设计工艺普遍化并适应更多的复合材料结构,开发了几何建模软件包,例如texgen和wisetex。这些软件包存储用于不同复合材料图案的大型文库,并在给定几何特征(例如rve长度、纱线宽度、纱线高度等)的情况下生成相应的rve结构。然而,自动生成的结构通常具有固定的纱线横截面形状和纱线中心线形状。对于松散的编织材料,这些简化适用,但会导致紧密填充的复合材料中出现纱线间渗透。在这种情况下,必须通过修改位置、尺寸或利用局部纱线横截面的非对称形状来对几何形状进行微调。但是,这些程序涉及复杂的几何形状处理并且耗时。为了捕获rve中更准确和详细的结构,研亢人员最近采用了x射线显微断层扫描技术来直接获得复合材料的几何形状。这是一种有前途的技术,但价格相当昂贵,并且需要仔细的图像处理。作为替代,为了在生成rve结构时实现速度与精度之间的良好平衡,我们在本发明中开发了一种新颖的两步几何建模方法,其中一次性后处理步骤用以修改由texgen生成的局部纱线几何形状。关于在介观尺度上获得未知纱线特性的挑战,开发了一种贝叶斯模型校准和验证方法,用于将校准后的介观尺度应力仿真器与宏观尺度零件性能仿真集成在一起。这是利用贝叶斯校准和分层多尺度技术仿真未固化的预浸料预成型的第一种情况。本发明的预成型建模部分的主要技术目标是开发一种计算仿真方法,该计算仿真方法能够捕获碳纤维复合材料预浸料的变形,包括预成型过程中的零件几何形状、纤维取向和成型力,精度高且误差小于5%。与很大程度上依赖于试错实验的传统的制造工艺设计方法相比,利用这种仿真方法可以显著降低碳纤维复合材料预浸料预成型的设计和优化所需的材料成本和开发周期。碳纤维复合材料制造工艺开发的这种成本和时间削减将拓宽这些先进轻质复合材料在运输行业中的应用,为控制化石燃料消耗和排放污染做出了巨大贡献。为了成功开发,将系统地设计和执行实验材料表征技术,首先要为仿真模型提供正确的输入。然后,将建立并验证介观尺度和宏观尺度的模型。介观尺度建模的目的是进行虚拟材料表征,以代替不尽如人意的直接实验表征。另一方面,宏观建模的目的在于:当输入所测量的材料特性时,形成用于零件尺度预成型仿真的平台。最后,这些建模工具将与适当的校准技术相结合,以形成用于预浸料预成型工艺的高精度和高保真度的分层多尺度建模方法。未固化的预浸料表征实验方法为了获得明确定义的本构模型和用于数值计算的仿真方案,需要对未固化的预浸料进行表征。在本发明中开发出了几种对材料进行表征的实验方法:单轴拉伸试验用于表征沿纤维纱线的拉伸模量;偏向延伸试验用于表征预浸料的剪切模量;弯曲试验用于表征沿纱线的弯曲刚度;以及表面相互作用试验用于表征预成型工艺过程中预浸料与预浸料间的相互作用以及预浸料与工具间的相互作用。单轴拉伸试验:单轴拉伸试验用于获得预成型工艺过程中沿纤维纱线的拉伸模量。图127中示出了实验设置,其中使用了拉力机。预浸料中的未固化的环氧树脂的机械特性对温度敏感,因此这里使用温控室。另外,利用数字图像相关(dic)系统来测量样本中的应变分布。在预浸料的单轴拉伸试验中,根据织物拉伸试验而不是纱线试验来确定拉伸模量,因此拉伸试样可以包括尽可能多的单位晶格。在预成型过程中会遇到的各种温度下进行试验。为了避免由粘性环氧树脂引起的试样与夹具之间的滑动,在试验之前将试样的两端加以固化以使材料硬化并确保试验过程中的夹紧力。工程应力和应变用于归一化载荷数据和位移数据。作为示例,图128中示出了各种温度下的曲线。可以看出,随着温度的升高,材料的波动阶段变得更长,沉降区域的拉伸模量略有降低。考虑到环氧树脂在高温下会软化,这是合理的。由于这种现象,选择波动阶段结束时的应变和应力以及波动阶段之后的刚度来适当地描述温度对预浸料的单轴行为的影响。偏向延伸试验:偏向延伸试验确定了编织的碳纤维预浸料的面内剪切刚度特性。实验设置与图127所示的单轴拉伸试验的实验设置相同。为了产生一个纯剪切中心区域,将纤维纱线偏离载荷方向±45°对齐,并且试样的长度应大于宽度的两倍,以便释放沿纱线方向的约束。将实验的温度设置为预成型时会遇到的各种温度,涵盖在我们的实验室执行的单圆顶预成型工艺过程中由红外线(ir)摄像机测量的一般预成型工艺温度的范围。所述试验中包括各种温度和拉伸速率,以研亢温度和剪切速率对剪切应力的影响。需要一些归一化方法,以便利用偏向延伸试验的载荷-位移数据并补偿试样的尺寸差异。使用工程应力来归一化载荷。关于位移,因为整个试样中变形是不均匀的,所以基于纱线不可伸展且在偏向延伸试验过程中样本中不会发生滑动的假设推导出归一化方法。为了验证这种位移归一化方法,进行两个具有不同试样尺寸的偏向延伸试验。表9-1中列出了所述试验的参数。选择拉伸速率,使得两个试验的归一化拉伸速率相同。根据图129中的结果可以看出,当在中心区域发生较大的纯剪切变形时,这种位移归一化方法可以适当地补偿剪切锁定之前的试样尺寸差异。表9-1偏向延伸试验中的位移归一化方法的参数试验尺寸(宽度*厚度*长度)拉伸速率温度短试样50mm*1.1mm*104.31mm12.00mm/min60℃长试样51mm*1.1mm*136.00mm18.87mm/min60℃作为示例,图130中绘制出了在各种温度和剪切速率下的归一化的载荷-位移曲线。可以看出,温度对剪切应力-应变关系起着重要作用,尤其是在接近50℃的温度下,这是所使用的环氧树脂开始从固态转变为流态的温度。温度越高,所测得的应力越低。其可能的原因是,在较高的温度下,环氧树脂变得更软,减小了纤维经纱和纤维纬纱相对转动的阻力。关于变形-速率的影响,较高的变形速率将导致较高的最终应力,这是合理的,因为在较高的变形速率的情况下,由环氧树脂的粘度引起的变形阻力会更大。但是,应该注意的是,当变形较小时,在较小变形下载荷会更早地增加。这种现象不能简单地通过材料的弹性行为或粘性行为来解释。可能需要将来进一步研亢这种现象。为了进一步验证纱线不可伸展且在偏向延伸试验过程中样本中不会发生滑动的运动学假设,应用dic技术检查真实试样中的格林(green)应变场,并将结果与如图131所示的基于相同假设推导出的理论结果进行比较。可以看出,在dic可以正常工作的范围内,这一假设成立。但是,当剪切变形变大时,经纱与纬纱之间的相对运动会刮擦掉用于检测dic系统中的应变的涂料,并且结果将不再可靠。为了进一步验证所述假设并获得剪切变形与应力之间的更准确的关系,在将来的工作中可能需要先进的光学方法,这可有助于检查偏向延伸试验过程中预浸料在较大剪切变形下的应变场。弯曲试验:为了正确地仿真成型工艺过程中的材料行为,还需要材料的弯曲刚度。然而,预浸料在预成型温度下的柔软性使得难以通过标准的三点弯曲试验来测量弯曲刚度。作为替代,本发明中的弯曲试验利用试样的自重。在试验中,矩形预浸料样本的一端被水平地夹紧在作为悬臂梁的支架上,如图132中分图(a)所示。由于在高温下预浸料的刚度较低,所以预浸料将在重力下变形。测量样本尖端的挠度,并通过数字图像分析对变形的形状进行分析。将整个系统置于温控室内,并记录温度。作为示范,图132的分图(b)中给出了在50℃温控室温度下试验过程中的预浸料变形。在该预浸料弯曲试验中,由于较强的几何非线性度,无法直接根据典型的梁理论计算出弯曲刚度。作为解决方案,利用仿真模型反向计算弯曲刚度。该仿真模型利用了均质材料特性。修改材料的压缩模量,直到达到与实验结果相同的末端位移。然后,可以获得有效的压缩刚度,以适当地描述预浸料的弯曲行为。表面相互作用试验:在本发明之前,缺乏系统的研亢来表征两个不同的复合材料预浸料表面之间的相互作用,但是这种相互作用肯定会影响预成型后的预浸料变形和纤维取向。为了解决这个问题,开发了一种新的实验方法来表征预成型工艺过程中未固化的预浸料层之间的相互作用。该方法的重点是表征温度、滑动速度和纤维取向对切向相互作用的影响。这种新的摩擦试验方法的设备、试验程序和结果将在本节的以下部分中具体说明。图133中示出了本发明中开发的试验设备。图134中示出了该设备的示意图。在试验过程中,顶部预浸料层被夹紧在运动台上,这类似于相对的“拉出”滑动。底部预浸料被夹紧在固定的加热台上,该加热台升高两个预浸料表面之间的温度。顶部预浸料层的边缘固定在运动台的侧面而不是底部,以避免任何可能的边缘效应,并确保整个试验过程中表面与表面间的相互作用。运动台上安装有力-扭矩传感器,以记录由滑动引起的法向力和切向力。在该试验中,通过位移-控制运动台在两层之间引入了压缩。因此,如果整个试验阶段中预浸料的厚度改变,则在试验过程中接触力也发生变化。有趣的是,如以下分析所示,这种变化将不会影响相互作用因子,通过用接触力对面内切向力进行归一化计算得到所述相互作用因子。所述系统中还包括红外线(ir)摄像机,以测量表面温度分布并提供所选区域的平均值。在每次试验过程中,通过小心地改变加热台的功率对温度加以调节,直到将其保持在与所需值相差±1℃的范围内。对于这种表面相互作用试验,最重要的参数是表面温度,因为它会影响复合材料中树脂的粘度。在实际的预成型工艺过程中,将预浸料材料在加热室中加热到50℃至80℃,然后放入室温下的压力机中。因此,为试验选择的温度范围为室温(24℃)至80℃。第二个考虑的参数是相对运动速度,因为在预成型过程中,2d片材会变形为3d零件。然后,材料层之间的相对运动速度在不同位置发生变化,由于界面处树脂粘度引起的剪切速率效应,导致了预浸料之间的相互作用强度不同。最后,需要研亢纤维取向的影响。在工业应用中,将具有不同纤维取向的预浸料层堆叠在一起,以优化各个方向上的产品性能。由于复合材料的表面织构是各向异性的,这会影响织物与树脂之间的流体动力学相互作用,因此对经受不同纤维取向组合的材料相互作用进行试验也很重要。当完成所有参数组合的试验时,对摩擦试验结果进行分析。因为树脂在预成型温度下粘度较高,所以未固化的预浸料在预成型时非常发粘。作为结果,两个未固化的预浸料层之间的库仑摩擦系数可以大于1。为了避免混淆,定义了类似于库仑摩擦系数的相互作用因子,以指示两个预浸料层之间的纱线-树脂-纱线间的相互作用的强度。图135中的结果表明在试验开始时,观察到力分量和相互作用因子值的较大变化。其原因包括:(1)滑动的起始点在底部预浸料的边缘,这不在均匀的温度区域内,因为加热阶段仅在中心提供了均匀的场,(2)在试验的前30秒过程中,两个预浸料层相互接触进行热传导,而没有相对运动。因此,预浸料非常发粘,导致较高的初始相互作用因子。基于用ir摄像机图像测量的稳定的温度场以及相互作用因子曲线的趋势,只利用了稳定阶段内的实验数据,即如图135紫色标记所示的范围为30mm到70mm的滑动距离。根据所得的曲线图观察到相互作用因子的周期性改变,特别是当树脂具有非常高的粘度时。以图136中所示的稳态阶段的相互作用因子为例。除了由粘滑引起的小振荡外,所有三个试验的曲线图还显示出具有相似振幅和相位的一致且明显的峰值和谷值。下一节中将通过流体润滑的相互作用模型进一步研亢这种现象。图137中绘制出了关于稳定阶段平均温度、相对运动速度和纤维取向组合的最终结果。相互作用强度和粘滑强度都在50℃时达到峰值,这是树脂从固态完全转变为流态并显示出最高粘度时的临界温度。低于50℃,树脂处于固态。随着温度的升高,树脂逐渐变得更软和更粘,这导致:(1)更大的相互作用因子,因为在相对滑动运动下需要更大的外力来剪切不同层中的树脂,以及(2)更大的振幅和频率更高的粘滑,因为分子链更频繁地混合和相互扩散,导致切向相互作用力发生波动。温度对预浸料表面相互作用的影响是在于:当温度高于50℃时,树脂完全转变为粘性流态,并在两个预浸料层之间起“润滑剂”的作用。在此阶段,进一步的温度升高会降低树脂粘度并增强其在滑动过程中的润滑性,从而导致较低的相互作用因子和较小振幅的较低频率的粘滑。关于相对运动速度的影响,我们发现在低于50℃或高于60℃的温度下影响较小。但是,当树脂的粘度达到峰值时,相互作用因子在约50℃下与运动速度正相关。关于纤维取向的影响,当温度高于50℃时,在0/90/0/90纤维取向的情况下的相互作用因子比在0/90/-45/+45取向的情况下的相互作用因子更大,因为不同层中的横向纤维纱线在0/90/0/90取向的情况下更可能互锁,从而使各层更难以滑动。这也就解释了以下事实:如果顶层和底层中的纤维彼此对齐,则粘滑强度通常会更大,尤其是在树脂粘度达到峰值时在50℃的情况下。然而,当温度低于50℃并且树脂处于固态时,两种取向组合之间的差异变得不那么显著。这主要是由于以下事实:片材仍处于固态,并且树脂填充了由纤维纱线产生的表面“谷”以使预浸料变平。作为结果,与更高温度下的取向组合相比,所述取向组合没有太大的影响。流体润滑的未固化的预浸料表面相互作用模型本发明中的编织纤维形成一定织构的表面形貌。它具有2×2斜纹结构,如图138中的实际材料照片和texgen软件模型所示。表9-2中列出的编织结构的特征尺寸,即纱线宽度、纱线间隙和纱线厚度,这些特征尺寸是根据材料的横截面通过显微镜测量的。通过卡尺获得预浸料的平均厚度。表9-2.偏向延伸试验中位移归一化方法的参数纱线宽度纱线间隙纱线厚度预浸料厚度2.430±0.112mm0.004±0.004mm0.503±0.012mm0.85±0.15织构会影响织构化表面的相互作用。开发了一种流体动力学模型,并应用它来仿真和研亢本发明中的预浸料表面相互作用。在此模型中,将顶部和底部编织织物对齐到同一方向,纤维取向为0/90/0/90,以便进行2d简化。这些织物被视为刚性的,因为:1)它们在纤维基体中强力地拉伸,因此竖向变形最小;并且2)正常载荷较低。可以通过图139所示的一般润滑系统来考虑界面的相对运动。该系统由被连续的流体薄膜分开的两种固体形成。在仿真中,基于2×2斜纹预浸料的横截面确定固体几何形状,如图135的分图(b)所示。将单根经纱的横截面理想化为椭圆形状,而将两根经纱顶部的纬纱的横截面建模为与两个半椭圆形状相切的平面。假设在仿真中,上层会相对于下层移动。为了描述粘性树脂的动力学,利用不可压缩牛顿流体流动的一维瞬态雷诺方程。利用这种流体润滑的模型,可以在10mm/s的相对运动速度设置下仿真各种温度下的表面相互作用。图140中示出了数值结果和实验结果的比较,其中绘制出了相互作用因子的平均值、最大值和最小值。在50℃时,因为连续性假设无效,因此数值计算的相互作用因子显著大于实验计算的相互作用因子。在仿真中,树脂层就像具有高粘度的连续流体,而在实验中,树脂可能仅部分熔化,因此在顶部预浸料与底部预浸料之间仍然存在发生摩擦的界面。应该注意,在该打破了仿真中的连续性假设的界面,摩擦应该较低。此外,在数值计算中,为简化起见,假设预浸料纤维是刚性的。另一方面,在实验中,高粘性树脂在此温度下会导致较大的流体剪切应力,使预浸料纤维变形,改变表面轮廓,从而减少相互作用。在60℃时,数值结果与实验结果非常吻合,因为粘度处于合理的范围内,并且由于树脂完全熔化,因此连续性假设是有效的。在70℃的条件下,数值预测值略小于实验结果。实验中的相互作用较大因子是由于两个编织织物之间的直接接触导致的。我们发现,在此条件下,因为树脂的粘度变得非常小,所以在计算过程中最小薄膜厚度将达到0.06mm。最小薄膜厚度为与0.012mm半纱线厚度变化相同的数量级;因此,在实际试验中,两个编织织物表面可能在某些位置相互接触,从而导致边界混合的流体动力学润滑循环。然后,对于60℃下的相互作用,进行各种相对运动速度的数值计算。图141中绘制出了平均相互作用因子、最大相互作用因子和最小相互作用因子的实验结果和数值结果。相互作用模型结果总体上与实验结果吻合良好。但是,由于模型中刚性表面之间的流体动力学假设(对滑动速度敏感),因此速度的影响比实验中发现的影响略微更显著一些。但是,在实际实验中,其他因素也会带来速度的影响。在低速下,树脂有足够的时间进行混合和相互扩散,以使树脂更加发粘并易于将两个表面粘在一起,从而增加运动流体阻力。在高速下,由于粘性摩擦,相互作用力增加,因此纤维的弹性变形相应增加,进而使表面变平并减少实际材料中的相互作用。最后,利用这种流体润滑的模型来研亢图136中示出的周期性相互作用因子变化。对于实验结果和数值结果应用快速傅立叶变换(fft)。图142中绘制出了在60℃和10mm/秒下的结果,表明所有的实验曲线和数值曲线具有大约0.1/mm的一阶长度频率,这意味着相互作用因子在大约10mm的周期内改变。这种现象由预浸料单位晶格的尺寸控制,所述预浸料单位晶格具有边长为9.74mm的2×2斜纹单元。但是,对于更高阶频率,数值结果与实验结果不能很好地吻合,尤其是在振幅方面。这可以通过以下事实来解释:实际材料的粘弹性可以吸收滑动过程中的高频振动能量。实验验证表明,在某些预成型条件下,即所提供的编织预浸料在60℃的温度和5-15mm/s的滑动速度下,两个预浸料表面之间的相互作用可以通过流体润滑机制来解释,并且可以通过本发明中开发的数值方法进行预测。在未来的工作中,应该考虑织物的弹性变形以及树脂在各种变形速率和温度下的相互扩散混合,以便更准确地对预浸料与预浸料间的相互作用进行建模,并预测在更广泛条件下的相互作用行为。未固化的预浸料的宏观非正交材料模型在本发明中,开发了一种用于cfrp预成型仿真的非正交材料模型,旨在准确地预测未固化的预浸料在预成型过程中的变形,特别是在较大的剪切下的变形。该材料模型以明确的用户自定义材料子程序(abaqusvumat)和ls-用户自定义材料子程序(ls-dynaumat)的形式开发。由于其容易使用并且对零件形状和纤维取向具有高预测精度,所以将这种模型并入ls-中作为mat_293(matcomprf)。这种模型的理论基础可以在本节之后找到。编织cfrp具有高度各向异性的机械特性,由于刚性碳纤维增强,沿经纱和纬纱的拉伸模量(10gpa级)较大,而且层内剪切模量(0.1mpa级)较小。在预成型过程中,最主要的变形模式是层内剪切。为了捕获这种以纤维取向为主的各向异性,即使在较大的剪切下,材料模型也需要分别仿真剪切和沿纱线的拉伸。图143中示出了利用本发明中开发的非正交模型对编织的未固化的预浸料进行应力分析。σf1和σf2是由纱线拉伸引起的应力分量,它们分别沿经纱方向和纬纱方向。σm1和σm2是由纱线旋转引起的应力分量。这些应力分量将被转换为局部共旋坐标,加起来为σxx、σxy和σyy,然后将从材料模型输出到fem软件。在该模型中,利用变形梯度张量f通过g=f·g来跟踪预成型过程中的纱线方向和拉伸比,其中g和g分别是局部纤维的最终取向和初始取向。它可以用于计算α和纱线角度β,α表示局部共旋坐标中的局部经线方向与x方向之间的相对旋转,纱线角度β表示材料中剪切变形的量。该非正交材料模型被实现在和ls-中。该模型使得用户能够直接输入实验数据来定义应力-应变曲线以及剪切自锁角度,所述剪切自锁角度指示剪切变形是否达到与材料的拉伸模量相比经纱与纬纱之间的旋转阻力不再小的程度。图144示出了在fem软件中该模型的计算流程图。从该流程图可以看出,根据变形梯度张量计算得出每个单元的经纱方向和纬纱方向。如果经纱与纬纱之间的角度小于剪切自锁角度,则将保持较小的剪切模量条件,并且将通过非正交模型更新单元中的总应力。如果经纱与纬纱之间的角度达到剪切自锁角度,则因为接触的纤维纱线使编织结构变硬,进一步剪切变形的阻力将大大增加。在这种情况下,仍将通过非正交模型计算“纱线拉伸引起的应力”,而“纱线旋转引起的应力”的剪切分量将根据固化的单向(ud)碳纤维复合材料的剪切模量进行更新。材料表征对于fem模型在预成型工艺过程中准确地预测编织cfrp的行为至关重要。从图143可以看出,针对感兴趣的任何特定编织材料,需要校准由纱线拉伸和纱线旋转引起的面内应力。它们的校准可以直接通过单轴拉伸实验和偏向延伸实验进行。通过单层弯曲试验和双层相互作用试验表征未固化的预浸料的面外行为。当准备好材料模型和实验输入之后,进行双圆顶基准试验并进行仿真,以验证材料模型用于3d形状成型的能力,并考虑不同的纱线取向和堆叠顺序。这些验证结果表明,这种非正交模型在纤维取向预测方面一定程度上可以达到5%的误差目标。未固化的预浸料的介观尺度rve模型用rve进行介观尺度rve建模和虚拟材料表征需要构建一个rve有限元模型、校准介观尺度纱线特性,以及生成作为应变函数的预浸料本构定律。为了构建速度与精度之间良好平衡的预浸料rve的网格,在本发明中开发了一种新颖的两步几何建模方法。在这种方法中,首先由texgen在步骤1中生成具有指定编织图案和关键特征尺寸(例如编织图案、纱线宽度、纱线间隙和纱线厚度)而没有纱线与纱线间的渗透的粗糙复合材料结构。然后,在步骤2中,将与结构相对应的网格和局部纱线取向导入到商用有限元软件中,以在厚度方向上压缩结构并满足预浸料厚度要求,同时保持已分配的特征。最后,导出变形的网格和局部材料取向以构建用于虚拟材料表征的rve。利用该方法构建所提供的2×2斜纹预浸料。图138中示出了实际的2×2斜纹预浸料的织构结构。表9-2中列出了纱线的特征尺寸和平均厚度数据。首先在texgen中输入纱线宽度、纱线间隙、纱线厚度和2×2斜纹图案的平均值。表9-2表明,与纱线的厚度和宽度相比,纱线间隙很小。为了使纱线与纱线间的渗透最小,将纱线横截面的形状设置为透镜状。texgen预浸料结构的厚度也被人为地从0.85mm扩大到1.2mm,以避免完全渗透。图145中示出了结果,并且可以观察到,不同纱线之间不再有任何渗透。然而,这种厚度扩大的缺点在于,如图145的分图(b)所示,结构中引入了许多间隙。这些人为的间隙显著地削弱了rve模型的预测能力;在施加载荷时,内部间隙将极大地软化rve,减小响应模量,并拉长波动区域。作为闭合这些间隙的解决方案,在步骤2中引入了压缩方法。为此,采用两个刚性板在厚度方向上压缩预浸料rve,以将厚度减小到0.85mm,这是实际材料的平均值,如图146所示。这一步骤的合理性得到以下事实的支持:对纱线的横截面形状和纵向路径没有严格的限制。在此阶段,预浸料纱线的机械特性尚未表征,因为它们需要通过rve进行校准,而rve的结构还尚未获得。作为结果,在压缩仿真中,选择纱线的弹性模量使其与已有的用于固化的单向复合材料的弹性模量相同。泊松比在所有方向上都设置为零,以避免由于纱线在厚度方向上的变形而改变纱线宽度。应该注意,这些纱线特性仅用于生成rve结构。它们与根据贝叶斯校准获得的预浸料的纱线特性不同。除了rve结构外,还应正确建立纱线材料模型。因为预成型是一步加载工艺,其中变形后的材料恢复不容忽视,因此假设rve模型内的纱线是纯弹性的。包括准单向纤维和未固化树脂的预浸料纱线表现出横向各向同性。但是,直接执行这种材料行为会导致数值误差。当沿宽度方向将压缩载荷施加到单根纱线上时,会出现一种误差。该载荷条件对于剪切变形中的预浸料是常见的,其中,如图147的分图(a)所示,当树脂在实际纱线中流动时,纤维会重新排列。因此,在保持基本椭圆形状的同时,纱线发生变形(即,其尺寸改变)。在有限元仿真中,将纱线视为具有相对平坦横截面几何形状的连续体。如果利用横向各向同性的材料模型,则数值误差(例如,人工弯曲和过度单元畸变)将特别出现在边缘上,如图147的分图(b)所示。为了解决这个问题,将纱线材料模型中的横向剪切行为和正常行为解耦,以控制纱线的弯曲和畸变,同时保持其压缩特性。利用这种方法,可以实现与实际材料类似的变形,如图147的分图(c)所示。基于所述解耦方法,使用在不同方向上具有不同的杨氏模量和剪切模量的各向异性弹性本构定律对纱线进行建模。该本构定律定义在共旋框架中,利用变形梯度张量更新所述共旋框架,以准确地跟踪在rve变形下较大纱线变形和旋转时的局部纤维取向。在预浸料纱线中,非常坚硬的碳纤维沿纵向方向对齐,所施加的载荷主要沿所述纵向方向存在。同时,较软的未固化的树脂控制横向变形。因此,很容易使纱线变形在纵向方向和横向方向上解耦。在给定沿纱线的法向真实应变、剪切角和纱线特性的情况下,一旦生成rve的结构和材料模型,就将它们输入到有限元仿真中。经过仿真后,提取每个单元的应力并求平均值,以获得rve的应力响应。介观尺度纱线的机械特性(包括弹性模量、泊松比和摩擦系数)由于小尺寸、单纱线试样制备和较软树脂而难以直接表征。作为结果,在此阶段手动调整未知的材料特性,并将rve的应力预测与实验数据进行比较。图148中示出了最佳示例比较之一。当剪切角小于0.6弧度时,rve结果与实验结果非常吻合,由此验证了所开发的两步法。当剪切角进一步增大时,仿真与实验之间的差异会变大,这表明需要进行校准。在本发明中,首次使用贝叶斯校准来获得预浸料纱线特性。采用单轴拉伸数据和偏向延伸数据来进行下列操作:(1)估计rve模型的校准参数;(2)确定rve仿真器是否偏置;以及(3)构建一个评估廉价的仿真器,以替代宏观尺度分析中昂贵的rve仿真。为此,采用了kennedy和o’hagan(koh)的贝叶斯校准框架的模块化版本。贝叶斯校准的目的是结合三个数据源(实验、仿真和来自现场经验的先验知识)来估计未知情况。如图149所示,其中x代表应变,θ代表纱线特性,此工艺首先用模块1中的gp仿真器(元模型)η(x,θ)代替昂贵的介观尺度rve仿真。然后,使用单轴拉伸实验数据和介观尺度纱线特性的先验知识p(θ)将gp仿真器δ(x)拟合到模块2中的偏差函数。引入δ(x)的原因是,即使知道真实的校准参数(虽然它们并不真实)并在仿真中使用,rve模型的应力预测可能也与实验不匹配。在模块3中,在给定d的情况下获得介观尺度纱线特性的联合后验分布p(θ|d),即收集实验结果和仿真结果。最后,在模块4中,将更新后的仿真器与偏向延伸实验数据进行比较以进行验证。验证后,利用更新后的仿真器(作为真实表征的本构定律)预测rve在任何应变状态下的应力响应。实际上,对于本发明中所提供的预浸料,针对θ选择均匀先验分布(根据我们的经验),其涵盖η(x,θ)适合的整个范围。优选均匀先验分布(超过例如正态分布),因为θ可取的值的范围(而不是例如其最可能的值)是已知信息。这些范围的选择足够广泛,以确保涵盖真实(但未知)的校准参数。另外,此选择确保了使用较大的方差来避免削弱实验数据对θ的联合后验分布的影响。表9-5.校准参数的先验分布和后验分布:关于θ=[e1,e2,μ]的先验分布是均匀的,并用uni(下限,上限)表示。与先验分布不同,校准参数的后验分布既不均匀也不独立。图150中示出了校准的纱线特性结果,这些结果表明边际方差相对较大,这是意料之中的,这是因为(1)存在多种不确定性来源,例如实验误差和仿真误差以及仿真器偏差,以及(2)贝叶斯分析中使用的数据有限:校准数据只是单轴拉伸试验的20个点,并且rve虚拟测试则进入了复杂的载荷条件。图151示出了更新后的仿真器对各种变形状态下的正交应力分量的预测。图151的分图(a)中绘制出了两个不同的γ’12值下法向应力σ11相对于沿着经纱的法向真实应变ε’11和沿着纬纱的法向真实应变ε’22的曲线图。类似地,图151的分图(b)中绘制出了剪切应力σ12,其中其关于ε’11和ε’22的对称性很明显。与σ12相比,σ11对γ’12并不那么敏感。还可以观察到,σ12随着任何应变分量的增加而单调地增加。在图151的分图(a)中也观察到了这种单调行为,但在没有剪切应变时(即在红色表面上)会稍有折中。这种小的不一致可能是由于(1)动态的显式数值问题,例如人为的高应变速率以减少rve仿真中的运行时间,以及(2)缺少非常小的γ’12的仿真数据,导致在贝叶斯校准过程中外插。在图151的分图(c)中,绘制出了单轴拉伸实验结果和预测结果。由于此试验用于校准,因此预计所述预测结果将与实验结果匹配。在图151的分图(d)中,绘制出了偏向延伸实验结果和预测结果。由于校准中没有使用该数据,因此图151示出了校准在了解应力-应变行为方面是有效的。现在,可以将所得的gp模型的后验分布用作宏观预成型仿真中积分点的本构定律。利用贝叶斯校准的多尺度未固化预浸料预成型模型由于具有未固化热固性树脂的2×2斜纹预浸料的本构定律,从虚拟材料表征获得的介观尺度应力仿真器被实现在非正交材料模型中,以形成多尺度仿真方法。图152中示出了所开发的方法的流程图。该仿真器是在介观尺度上获得的,它通过替换宏观尺度预成型分析中每个积分点上昂贵的介观尺度rve有限元仿真来充当非正交材料本构定律。对于这种多尺度方法中的宏观本构定律,变形输入包括沿着经纱方向的法向真实应变ε’11和沿着纬纱方向的法向真实应变ε’22以及剪切角γ’12。这些输入都是使用非正交坐标算法计算的。所预测的应力分量直接在正交材料坐标中获得。因此,本构定律不需要应力的坐标变换。应该注意,预浸料应力仿真器是在ε’11∈[-2,2]%,ε’22∈[-2,2]%和γ’12∈[0,1]弧度的范围内获得的。对于超出这些范围的变形状态,预浸料将转变为剪切自锁状态,并且有限元仿真在非正交模型中采用剪切自锁状态算法。在建立多尺度预成型仿真方法时,进行双圆顶基准试验并对其进行建模,以验证多尺度方法在考虑到不同的纱线取向和堆放顺序的3d形状成型时的能力。该验证结果表明,这种多尺度方法在零件几何形状和纤维角度分布的预测方面略有改进,纤维取向预测的平均误差为4.0%,达到了所提出的目标。此外,与基于实验的非正交模型相比,该多尺度方法的成型力预测精度显著提高了26%以上,并且与实验结果非常吻合。图152示出了所开发的多尺度预成型仿真方法的流程图:贝叶斯校准利用rve和实验来获得纱线特性和介观尺度应力仿真器。然后将应力仿真器实现在非正交材料模型中,以进行宏观预成型仿真。本发明所开发的表征碳纤维复合材料预浸料的机械特性的实验方法、用于预成型仿真的非正交材料模型、利用贝叶斯校准进行虚拟材料表征的介观尺度预浸料rve有限元模型,以及用于预成型的多尺度仿真方法给出了一种开发cfrp零件预成型工艺的准确的计算设计和优化方法。在材料结构级别上的高保真度rve仿真也为复合材料中的编织图案和成分设计提供了深入的指导。与很大程度上依赖实际实验的传统试错法相比,这种方法能够减少预成型开发的时间周期和材料成本。作为结果,这种方法使学术界或工业界的研亢人员和工程师能够以更快的速度、更低的价格和更大的数量发明和生产cfrp零件以及相应的制造工艺,从而拓宽了这些先进复合材料的应用,且有利于环境排放和化石燃料控制。两步介观尺度rve建模技术和多尺度仿真工具也可以商业化并被实现在成熟的有限元软件中作为插入特征件。对于rve技术的商业化,下一个必要步骤是将用于生成织物几何形状/网格的开放式texgen软件与有限元软件集成在一起,以形成一个完整的软件包。关于多尺度工具的商业化,未来需要采取的步骤包括:(1)将贝叶斯校准算法从当前的matlab代码转变为可以由有限元软件直接利用的python或fortran语言;以及(2)将rve虚拟测试模型、贝叶斯校准以及零件尺度预成型仿真模型集成到一个完整的软件包中。在本发明的预成型部分中,我们发明了一组实验和仿真方法,它们可以以低成本加速cfrp零件制造的开发。这不仅使大公司,还使小的研亢团队能够设计他们自己的复合材料和相应的制造工艺,这有可能提高这些先进轻质材料的应用和市场需求,减少运输行业的排放污染,并推动碳纤维复合材料生产行业。碳纤维复合材料预浸料价格昂贵,并且在存储(冻结)和制造(高温以熔化树脂,但不将其固化)方面均需要进行特殊处理。系统地安排进行适当变形和温度检查的物理实验对于避免浪费原材料至关重要;并且(2)当需要运行数百个计算模型进行校准、虚拟材料表征和设计优化时,所述计算模型可能会很耗时。在网格密度、局部材料坐标、材料模型等方面验证单个仿真实例对于确保大规模计算仿真的高效率至关重要。作为总结,为了节省时间、削减成本并获得整齐和令人满意的结果,无论是实验还是仿真研亢工作都需要充分的准备和计划,而不是简单地执行它们和依靠试错法。3.cfrp的机械连续体模型碳纤维增强聚合物(cfrp),包括单向cfrp(udcfrp)和斜纹编织cfrp(编织cfrp),具有取向相关的材料特性。简而言之,udcfrp和编织cfrp的拉伸响应将根据载荷条件而有所不同。这是由于碳纤维的各向异性的性质,碳纤维在纤维方向和面内方向上具有不同的弹性模量。因此,为了研亢cfrp材料的机械行为,需要对cfrp的实际微观结构进行建模,以分析固化的cfrp(包括udcfrp和编织cfrp)的性能。在本发明中建立的多尺度方法提供了通过rve方法对cfrp微观结构进行建模的工具。rve的数值测试预测udcfrp和编织cfrp的有效弹性材料特性。基于rve的降阶建模方法,建立了并行多尺度建模方法以执行有效的零件级性能预测。在ud建模和编织建模方面的主要成果总结如下:·用户友好的udrve建模软件包;·用户友好的编织cfrp建模软件包;·ud弹性常数预测与试验数据的差异小于10%;·编织弹性常数预测与试验数据的差异小于10%;·编织rye的不确定性量化(uq);·与udcfrp建模并行的新型多尺度建模;·ud零件性能预测与试验数据的差异小于10%;·编织并行建模。cfrp复合材料的特性是各向异性的,并且与微观结构相关。因此,准确捕获cfrp的机械特性(例如刚度张量),需要1)重建微观结构;2)准确的数值建模。对于udcfrp,其刚度张量可以通过混合规则简化为体积平均值。可以通过使用voigt平均值或reuss平均值来估计ud刚度张量,但由于voigt平均值给出了上限,而reuss平均值给出了下限,因此精度可能是有问题的。另外,还提出了通过假设纤维具有良好结构且周期性填充图案(例如六边形填充)对udcfrp进行建模,并且提出了通过代表性胞元(ruc)对udcfrp进行建模。ruc使得对udcfrp进行建模更简单,因为它仅对udcfrp中的最小重复单元进行建模,并且允许不同的填充图案和纤维体积分数。与分析均质化方法相比,可以很容易地在有限元网格中对ruc进行建模,并且可以在不处理代数的情况下计算出有效的ud弹性特性。不幸的是,在实际的udcfrp产品中,碳纤维是随机分布的。因此,ruc模型可能无法提供有关ud特性的准确信息。对于编织cfrp,可以使用ruc对编织复合材料的机械特性进行建模。然而,由于上述假设,当希望捕获某些微观结构变化时,ruc并不是对编织cfrp进行建模的理想方式。为了包括真实的微观结构,需要识别和实现更好的建模技术,以便可以预测udcfrp和编织cfrp的特性。在本发明中,采用代表性体积单元(rve)方法来如实地对ud的微观结构进行建模。ud的rve模型捕获基体材料中的纤维的随机分布,并且可用于有限元分析。构建udrve使得可以考虑任意纤维分布和纤维形状。与试验数据相比,预计udrve可以很好地预测ud的机械特性。对于编织复合材料,rve模型使得可以捕获经线方向和纬线方向上具有多个纤维束的较大区域,从而可以准确预测编织机械性能。另外,编织rve使得能够对编织cfrp进行不确定性量化,其中可以定量分析纤维束中纤维体积分数和纤维错位的影响。因此,rve方法为ud复合材料与编织复合材料之间的特性图及它们的机械特性提供了清晰的结构。当前的范围是使用rve来准确预测ud复合材料和编织复合材料的弹性刚度张量。此外,udrve可以应用于最近提出的降阶建模(rom)方法,即自洽聚类分析(sca)。sca使得可以将来自许多体素单元的udrve压缩到由多个聚类组成的rom数据库中。ud的rom可以使用sca方法(以下称为“udsca”)求解,从而以有效的方式计算ud的弹塑性响应。udsca不仅提供了一种有效的方法来计算ud的机械响应(弹性和塑性),而且还将ud微观结构与ud零件性能联系起来。首次为ud材料建立并行多尺度建模框架,并且使用所述并行多尺度建模框架进行结构特性预测。当前ud建模和编织建模的目标是开发一个完整的建模工作流程,使用户可以生成ud微观结构和编织微观结构并提取弹性材料特性,尤其是刚度张量。它使得可以在有限元网格中将ud微观结构或编织微观结构构建为rve。用户可以分配微观结构信息,例如编织复合材料中的ud纤维体积分数和纱线取向。可以使用有限元网格在三个法向方向和三个剪切方向上执行无牵引加载。在6×6矩阵中,将使用来自所有六个加载的rve有效应力和应变结果来计算刚度张量。本过程提供了对cfrp材料特性的直接数值均质化。可以计算杨氏模量和剪切模量,并将其与实验结果进行比较。rve模型和试验数据的ud弹性常数和编织弹性常数之间的预期差异小于10%。此外,首次为编织cfrp建立不确定性量化工作流程。在此工作流程中,可以对编织cfrp中的编织微观结构的变化进行建模。考虑几种微观结构变化,例如纱线角度、纤维错位和纤维体积分数。可以定量地测量这些变化对有效编织弹性材料特性的影响。对于udcfrp和编织cfrp,应用一种有效的降阶建模方法(即自洽聚类分析(sca))来减少rve计算的计算成本。这使得可以即时计算响应rve,并启用并行多尺度建模框架。多尺度建模框架建立了一种可以对宏观尺度结构性能进行预测的并行多尺度建模框架。将利用实验验证提出udcfrp结构的试验实例。它在通过数值模型评估cfrp结构性能方面具有广阔的潜力,并且可用于将来的cfrp结构设计。udrve建模在icme过程中,针对cfrp采用了自下而上的多尺度建模方法。如图153所示,使用三尺度模型来描述固化的cfrp零件非常方便:微观尺度的ud、介观尺度的编织和宏观尺度的零件。构建udrve模型和编织rve模型是为了评估其机械特性,例如刚度张量。然后,可以在较大尺度上使用较小尺度上获得的信息。例如,编织rve中的纤维束可被视为具有与udrve相同的特性。因此,udrve还可以用于计算纤维束特性,所述纤维束特性用于评估编织rve的机械特性。因此,应首先介绍ud建模。图154中给出了本发明中使用的固化的ud微观结构的图像,其中观察到随机纤维分布。该项目中所有ud的纤维体积分数为51%。因此,ud建模需要构建一个数值模型,所述数值模型捕获具有给定纤维体积分数的随机纤维分布。为此,使用udrve对图155中观察到的微观结构进行建模。如下给出udrve建模的主要假设:1)总纤维体积分数为51%;2)纤维具有直径为7μm的圆形形状;3)纤维完全笔直;4)rve的横截面为正方形,长度大于70μm。构建udrve的过程类似于将多根纤维填充到一个正方形域中。由于假设所有纤维均完全笔直,因此将3d域降低为2d域(将多个圆填充成一个正方形)是很方便的。可以在纤维方向上挤压此2d域,以形成最终的3dudrve。这里,udrve几何形状为84μm×84μm×2.8μm,如图136所示。在图156中,按照右手法则,将纤维方向定义为方向1,将两个横向方向定义为2和3。为此特定目的形成udrve软件包,因此用户可以在给定的纤维直径和任意rve尺寸的情况下构建新的rve。图136所示的udrve通过在2和3方向上具有600个单元且在方向1上具有20个单元的立方体素单元而被离散化。当使用udrve进行有限元分析时,每个体素单元仅包含一个积分点。udrve可用于预测ud的弹性刚度张量。表9-6中给出了纤维和基体的材料特性。由于主要重点是计算ud的弹性材料特性,因此仅需要纤维和基体的弹性材料特性。表9-6.固化的编织复合材料的纤维和基体特性为了计算ud刚度矩阵,需要回顾一下一般单斜晶材料的定义。单斜晶材料的一般应变和应力关系如下所示,其中使用了沃伊特(voigt)符号。对于udrve,由于其各向异性的性质,我们得出:s12=s21,s13=s31,s23=s32,s22=s33,s44=s55,s14=s41=0,s24=s42=0,s34=s43=0,以及s56=s65=0。为了计算s柔度矩阵的各个项,需要在udrve上执行加载,使得仅加载方向上的应力为非零。这种所谓的正交载荷条件使得可以逐列计算s。因此,需要执行11、22、33、12、13和23方向的加载。一旦构造了完整的柔度矩阵,刚度张量就是柔度矩阵的逆。一旦生成udrve,即可在fe软件(例如abaqus)中使用网格,以在上述六个加载方向上执行加载。由于纤维和基体都假设是弹性材料,因此udrve响应将严格地是弹性的。ud有效应力和应变使用如下所示的方程(9-9)计算,其中σmicro和εmicro是udrve中每个体素单元的应力张量和应变张量。一旦计算出和就可以根据特定的加载方向计算出柔度矩阵的一列。例如,在11加载方向上,除σ11以外,所有应力分量都将为零。通过执行基本矩阵代数,可以逐项计算出柔度矩阵的第一列。udrve相关的量是杨氏模量和剪切模量,以及不同方向上的泊松比。可以使用以下方程发现ud柔度矩阵与弹性模量之间的转换:表9-7中总结了udrve的弹性材料常数以及实验结果。大多数差异都在实验数据的5%以内,超出了这项工作最初提出的目标。应该注意,对于剪切模量g12和g13,实验与预测之间有相对较大的差异,但仍在10%差异的目标之内。表9-7.udrve计算的ud弹性模量与实验数据的比较。当前的软件包假设纤维几何形状为圆形,但是它可以为任意形状。而且,目前的圆形填充方法正在考虑完全随机的纤维分布,但是这将最大纤维体积分数限制为60%。为了获得更高的纤维体积分数,该算法需要一个额外的功能,这个额外的功能可以重新排列纤维位置,从而超过60%的限制。生成的udrve网格通常具有相当多的体素单元,比le6多。因此,当使用有限元方法时,udrve计算最适合于高性能计算聚类。由于udrve被体素单元离散化,因此该体素网格实质上是3d图像。基于快速傅里叶变换(fft)的均质化方案是首选算法,以输入体素网格并计算总体应力和应变响应。如果采用基于fft的均质化方法,则可以使用单个工作站来计算rve弹性响应。简而言之,udrve模型已经建立了一种方便的工作流程,该工作流程使得可以利用所需的纤维体积分数构建udrve。所有预测的ud弹性特性均达到或超过10%差异的项目要求。编织rve编织rve的生成利用了texgen,这是一种开源软件,该软件使得可以以任何给定的图案和纤维束(或纱线)几何形状构建织物结构。在本发明中,编织cfrp由斜纹编织物制成。斜纹编织物的最小重复单元包括四根经向纤维纱线和四根纬向纤维纱线。图156中示出了所生成的编织rve,其中编织rve被分辨率为210×210×20的体素单元离散化。经纱沿方向2,纬纱沿方向1。一旦生成编织rve的网格,就可以在fe软件中使用它来执行数值均质化,从而获得其弹性材料常数。这里,基体材料具有相同的材料特性。假设纤维纱线特性与udcfrp相同,纤维体积分数为65%。由于上述限制,使用分析方法来计算纤维纱线的特性。为了分析编织rve的弹性响应,需要使用六个正交载荷条件(与udrve相同)来计算矩阵形成刚度张量(由于使用voigt符号)。一旦计算出柔度矩阵,就可以方便地计算出刚度矩阵。唯一的区别是,对于编织rve,方程(9-8)中列出的柔度矩阵的所有分量都需要计算。下表9-8中列出了所计算出的编织rve的有效弹性特性。与实验数据相比,所有预测均满足所提出的10%差异。表9-8.根据编织rve和实验数据的编织物弹性模量。e11g12g23编织rve59.96gpa5.68gpa3.6gpa实验数据65.95gpa5.18gpa3.49gpa差异,%9.089.653.15使用编织rve数值模型的优点在于可以在rve模型中解决各种微观结构不确定性,并且可以进行定量分析以了解这些不确定性的影响。在这项工作中,首次引入了编织cfrp的不确定性量化。不确定性量化使得可以解决由各种制造工艺(例如预成型和固化)导致的不确定性。通过对不确定性影响进行定量测量,可以将制造工艺与最终的cfrp性能联系起来,这是icme工艺的重要部分。这里,编织rve也可用于检查如图157所示的三种编织微观结构的影响:1)纱线角度;2)纱线纤维体积分数;3)纱线局部纤维错位。通过构造如图157所示的具有各种纱线角度α的编织rve来研亢纱线角度的影响。过去的编织cfrp研亢中的一般假设是,编织物在预成型和固化工艺后将保持90°的纱线角度或正交构型。但是,这表明在固化工艺之后,整个编织cfrp零件的纱线角度将发生变化。因此,需要研亢纱线角度小于90°的非正交编织rve。这里,计算每个编织rve实现的刚度矩阵,并且图156中绘制出了所有分量。应该注意,局部材料取向是图156中所示的取向。根据图158,纱线角度对c11、c22、c44和c24的影响最显著。随着纱线角度的减小,经纱将逐渐向方向1倾斜,而方向c2则显著减小。但是,c11保持恒定,直到纱线角度小于60°。这意味着当纱线角度大于60°时,经纱与纬纱之间的相互作用不显著。c44趋向于随着纱线角度的减小而增加,这意味着在较小纱线角度下的编织面内刚度将比在较大纱线角度下的编织面内刚度更强。c24的凹形形状表现出剪切-拉伸耦合效应,其中当纱线角度不为90°时,面内剪切应变将导致方向22上的应力。所有这些观察都再次肯定了编织纱线角度对于准确捕获编织rve的机械特性的重要性。除纱线角度外,还研亢了纱线纤维体积分数(表示为vf)和纱线纤维错位的影响。表9-8中获得的结果均未考虑不确定性,这意味着纱线材料是均质的,但是由于制造工艺的变化,对于制造的实际材料而言通常不是这种情况。如图156所示,编织rve中的每根纱线都由多个体素单元制成,其中每个体素单元包含一个积分点,代表一个udrve。因此,通过改变每个体素单元处的纤维体积分数,可以将不均匀性添加到纱线中。通过假设每根纱线上的纤维体积分数遵循高斯分布,可以在不同体素单元中分配不同的ud特性,以仿真纱线中的不同的vf。表9-9中总结了vf的影响,其中vf遵循高斯分布,平均方差可以得出结论,不会显著影响编织物特性,主要取决于其平均值。表9-9.纱线纤维体积分数对均质材料特性的影响。此外,每个体素单元都包含局部材料取向,该局部材料取向与均质材料的纱线中心线对齐。纤维错位被认为是与完美对齐方向偏离。如图157所示,向量表示完美纤维方向的方向,实质上是纱线中心线的切线。平面是纱线横截面,与所述平面正交。角度θ(0°≤θ≤90°)和φ(-180°≤φ≤180°)用于建立错位的纤维方向代表考虑纤维错位的横向各向同性材料框架。如下给出了计算的方程:对于纤维错位,通过让均值方差均值和方差(确保纱线内的所有单元,其φ按照三西格玛准则将落在-180°与180°之间),使θ和φ遵循高斯分布。总而言之,编织rve建模提供了一种用于研亢编织cfrp的机械特性的简单的数值分析工具,与试验数据相比,所有预测在10%差异以内。此外,编织不确定性参数的试验实例说明了编织cfrp中的微观结构效应。编织uq提供了一种评估由不同制造工艺引起的可能的不确定性的方便的数值解决方案。udcfrp的降阶建模上述ud软件包能够在体素网格中生成udrve,并允许用户分析udcfrp的机械响应。然而,与微小的体素网格相关的高计算成本需要某些降阶模型(rom)技术来实现:1)更快的rve响应计算;2)将udrve与大尺度零件级模型联系起来,以利用实验验证来进行零件性能预测(在10%差异以内)。表9-10.纤维错位对均质材料特性的影响。最近提出的降阶建模方法,即自洽聚类分析(sca),是一种为包括udrve的任意体素网格构建rom的一种有前途的方法。它基于fft均质化方案。在fft均质化方案中,每个体素处的应变张量被视为总施加应变εmacro和极化应变的组合,如方程(9-14)所示:以上方程,也称为李普曼-施温格方程,当εmacro固定时,使得可以求解出局部应变响应ε(x)。这是fft均质化方法的基础,由于要对所有体素单元进行评估,因此非常耗时。方程(9-3)也可以写成如下方程(9-15)。εmacro-ε(x)-∫ωγ0(x,x′):[σ(x′)-c0:ε(x′)]dx′=0,x∈ω(9-15)刘等人提出了通过将体素网格重新离散化为几个聚类的降阶建模方法。假设原始体素网格包含n个单元,则可以将网格压缩为k个聚类,其中n>>k。方程(15)重新以公式表示为如下所示的方程(9-16)。可以使用牛顿方法轻松求解方程(9-16)。由于n>>k,方程(9-5)是一个比方程(9-15)小得多的线性系统。为了将sca应用于udrve,第一步是构建udrve数据库。这涉及两个步骤:1.将来自体素网格的原始rve压缩为聚类。2.计算所有聚类对之间的相互作用张量dij。一旦rve被压缩,每个体素用一个聚类标记。这在图159中示出,其中rve分解为10个聚类:在纤维相中有2个聚类,在基体相中有8个聚类。一旦ud数据库构建,求解方程(9-16)以计算在给定外部加载时每个聚类中的应力和应变响应。这种rom(以下称为udsca)可用于及时计算udrve的弹塑性响应。如图55所示,进行udsca的数值验证,其中考虑了横向拉伸加载。在这种验证情况下,使用两种不同的rom分辨率:一种在基体相中有16个聚类,而另一种在基体相中有8个聚类。纤维相中的聚类的数量保持为两个。结果表明,与dns解决方案相比,使用在基体相中有8个聚类且在纤维相中有2个聚类可提供良好的精度。因此,这种rom用于所有ud并行建模实例。对于ud两尺度并行建模,它遵循图160所示的示意图。宏观尺度零件被离散化为有限元网格。udrve的rom采取积分点处的应变,然后将应力响应传回积分点。ud离轴试件拉伸并行建模接下来,将udsca应用于试件离轴试验模型以执行并行多尺度建模。为了真实地表示环氧树脂基体,施加抛物面屈服表面,其中从图45中提取拉伸曲线和压缩曲线。通过试件试验实例,解决了两个重要问题:(1)通过真实的rve实时计算材料微观结构演变;(2)使用多尺度方法预测cfrp零件性能。对于试件模型,使用来自nist的精确几何形状,如图161所示。试件模型被构建在商业有限元软件ls-dyna中。应该注意,蓝绿色区域是由12个ud薄片制成的ud叠层。由于需要对至少409,422根碳纤维进行建模,因此无法显式地对试件中的每根纤维进行建模。如果在试件模式下将前面所示的有限元网格与每个有限元的各个积分点耦合,则计算成本仍然很大,并且所估计的求解时间超出了现有hpc的能力。但是,使用udsca,可以有效地计算出每个积分点的udrve响应。仿真耗时2560cpu小时完成。如图1253所示,计算y方向上的应力-应变曲线,并将其与实验结果进行比较。表9-11中给出了试件试验的总结,其中并行模型能够很好地预测极限应力和应变。图9-15.ud离轴试件试验的法向应力和应变曲线。表9-11.极限法向应力和法向应变的比较。预测实验差异极限法向应力404.809mpa395.639mpa2.3%极限法向应变0.0110.01186.7%另外,图162示出了裂纹萌生之前和裂纹形成之后局部rve和试件的冯·米塞斯(vonmises)应力。在图162中,代表四个不同积分点的rve被可视化。在代表裂纹上的积分点的rve中,随着积分点从试件模型中删除,应力变为零。在代表未删除的积分点的rve中,由于应力波传播,应力仍然为非零。通过并行多尺度建模方案,可以同时捕获宏观尺度和微观尺度的应力演变。ud碰撞试验并行建模图163的分图(a)中示出了ud碰撞试验设置,其中所述模型是基于福特提供的模型的四分之一模型。使用与ud试件试验中所示相同的并行方案。图163的分图(b)中示出了冲击力与时间的关系,时间高达4秒。可以得出结论,由并行模型预测的第一峰值力与第二峰值力之间的时间间隔与试验数据的时间间隔相似。表9-12中给出了所记录的峰值力,相差13.2%。表9-12.峰值力的比较峰值力预测11×1e4kn试验12.68×1e4knud动态3点弯曲并行建模udsca还应用于ud帽形型材的3点弯曲模型。图164中示出了该模型,以及该模型与较低级别udrve之间信息交换的示意图。在总位移s之后,观察到ud薄片发生故障。表9-13中记录了峰值载荷和峰值冲击加速度,其中与试验数据相比,差异在10%以内。表9-13.峰值载荷和峰值冲击加速度的比较编织cfrp的降阶建模建立了编织rve的三尺度并行建模。以下图166中示出了该方案。在图165中,使用sca方法通过编织rve的rom计算宏观尺度积分点处的应力响应。对于编织rve的每个纱线聚类,分配一个udrve的rom,并通过sca求解。考虑到跨越三个不同尺度的信息,该方案也称为三尺度并行建模。应该注意,在本发明中没有用于三尺度并行建模的验证计划。示出了数值样本来说明这一概念。图166中示出了编织rve的几何形状细节,其中所有参数均由cao组提供。在编织rve中,纱线的体积分数为77%,而每根纱线中纤维的体积分数为60%。比较两尺度与三尺度单个单元简单剪切试验。图167中示出了应力和应变结果。可以合理地得出结论,由于纱线相被认为是弹性材料,所以两尺度模型预测的编织rve的剪切响应更大。由于考虑udrve,三尺度模型将需要更多的计算成本,并且在编织物由于塑性而表现出高度非线性响应时可以使用所述三尺度模型。如果不关心纱线的非线性(例如塑性行为),也可以用纤维体积分数为60%的一组ud弹性常数替换udrve。这会将编织物的三尺度并行模型降为两尺度并行模型,其中,唯一的基体被建模为弹塑性材料。正交编织物双轴拉伸试验显示几乎线性的应力曲线和应变曲线。因此,进行编织物偏向拉伸仿真的两尺度并行建模。图168中示出了试验设置。在对编织物偏向样本进行并行建模时使用相同的几何形状。这里应该注意,编织物样本由图166所示的单层编织物微观结构制成。图169的分图(a)-(b)中分别给出了最终的σ22轮廓和σ22与ε22的曲线图。在图169的分图(b)中,σ22与ε22是根据图168所示的测量区域中的那些单元获得的平均值。预测的τ12略低于试验数据,但显示出相同的趋势。差异可能是由于各种因素造成的,例如不准确的编织物几何形状和纱线特性。需要进一步研亢。效益评估ud和编织cfrprve建模软件包提供了研亢cfrp机械特性的替代解决方案。它可以应用于不同的成分,并预测ud复合材料和编织复合材料的弹性刚度张量。编织rve的uq功能使得可以将制造工艺参数与最终产品性能联系起来。此外,ud和编织并行多尺度建模提供了对零件级产品性能的准确且有效的预测。它可以应用于评估概念设计的虚拟验证平台。它可以优化新设计,并可以显著减少昂贵的实验次数。只要需要开发新的复合材料应用程序,该技术的潜在客户就很广泛。在多尺度建模工作中,可以理解的是,微观结构在cfrp材料建模中起着重要作用。引入了一种有效的降阶建模方法sca来将cfrp微观结构(ud和编织)集成到零件级模型中以预测结构性能。下一步将涉及对ud动态问题(例如ud帽形型材碰撞和动态3点弯曲)建模的研亢。当前模型由于较高的加载速率而出现数值不稳定。期望使用不同的稳定化方法来改进并行方案,以实现更好的精度。4.随机多尺度表征我们的研亢可以研亢零件特性和行为的变化与多个长度尺度上的不确定性来源的关系,随后,识别制造过程中应该监控的最重要的不确定性来源。所开发的方法和工具使得可以利用不同的不确定性来源在时间和空间上进行建模,另外,还可以跨不同的长度尺度耦合结构的不确定性和材料相关的不确定性。我们通过引入自上而下采样方法来实现这些,所述自上而下采样方法构建嵌套的多响应高斯过程,以简约地量化随机字段,从而量化潜在的物理不确定性来源。我们的方法可以轻松用于进行灵敏度分析以降低维度,即也可以识别最重要的不确定性来源。与现有的基于模型的uq研亢相比,本发明中对ud复合材料的uq研亢是基于图像和面向微观结构的。考虑两个不确定性来源:纤维波纹度和纤维空间分布,这两者都可以通过福特公司提供的显微图像来表征。利用机器学习和应用统计方法来开发图像分析工具,以提取有关不确定性来源变化的信息,并构造生成统计模型以生成真实的随机样本,其变化模仿了我们从图像数据中观察到的变化。对于纤维空间分布,使用树回归来进行图像表征,并开发一种分层的非参数采样方法来对来自非平稳且非均质rf的实现进行采样。通过特殊设计的分段回归算法从图像中获得局部纤维波纹度,并通过频域时间序列分析方法生成新的随机样本。最后,讨论存在空间约束的两个量的联合采样,并实现相应的代码。所开发的计算方法和工具适用于许多材料系统和相应的多尺度材料仿真器。我们已经证明了它们在对单向和固化编织复合材料中的不确定性来源进行建模方面的有效性。一旦我们的计算方法和工具可用,就可以根据实验结果对它们进行验证。在固化的编织复合材料的情况下,我们证明了在介观尺度和微观尺度分别引入的各种不确定性来源(例如纱线角度和纤维错位)可以如何影响零件在运行条件下的性能。我们的结果表明,即使在线性分析中,这类不确定性来源也可能对结果产生显著影响。利用uduq工具,可以生成代表实际ud材料变化的随机样本,以进行进一步的计算研亢,包括它们对材料特性和零件性能的影响。我们的贡献是第一个研亢多尺度材料仿真中的不确定性,这使得可以系统地研亢不确定性的影响,以便(i)设计更可靠的材料,并且(ii)仅通过监控主要不确定性来源来降低制造成本。考虑到不确定性的影响,可以优化复合材料汽车部件,从而产生更安全且更轻便的设计。在项目期间开发的高斯过程建模工具已被一般化为用户友好的图形用户界面。该工具的优点是双重的:(i)简单且免费的用户界面使公司范围内的工程团队都可以从该功能强大的工具中受益,并且(ii)高斯过程模型可以将有效的仿真运转时间从几天缩短至几秒钟,从而可以使用这些模型来进行不确定性量化和传播目的以及优化设计。不确定性来源通常分为偶然性的和认知性两类。尽管偶然性的不确定性来源是系统固有的(因此是不可减少的),但认知性的不确定性来源通常是由于缺乏知识或数据而导致的,并且可以通过进行更多的仿真、实验或深入研亢来减少。在材料的情况下,两种不确定性来源都存在,并且可能在设计和成分选择阶段、制造工艺或操作中引入。这些不确定性表现为例如机械变化(例如,杨氏模量、泊松比、屈服应力、损伤演化参数等)或几何变化(例如,增强材料分布、复合材料中的纤维错位)。为了更详细阐述材料的不确定性,我们以编织纤维复合材料为例。这些材料由于其优越的特性(例如较高的强度重量比、无腐蚀行为、增强的尺寸稳定性和较高的抗冲击性)而越来越多地用于航空航天行业、建筑行业和运输行业。如图171所示,编织纤维复合材料具有一种从纳米尺度到宏观尺度跨多个长度尺度的分层结构。在这些长度尺度的每个内,都会引入许多相关的且在空间上变化的不确定性来源。高压和树脂的流动或立体裁剪改变了预成型工艺过程中纤维的局部架构。另外,工艺变化和材料缺陷导致整个样本中纤维体积分数在空间上发生变化。这些变化沿紧密接触的纱线路径尤为明显。这些宏观的不确定性是更微小尺度上存在的许多不确定性来源的体现,其中由于材料的精密,不确定性来源的数量和维度增加。图170示出了多尺度结构:具有聚合物基体的四尺度编织纤维复合材料的示意图。在此结构的计算建模中,任何尺度上的每个积分点都是下一个更微小尺度上的结构的实现。先前已经对纤维复合材料进行了研亢,以确定它们的特性和性能对不确定性有多敏感。但是,这些工作的重点并没有放在对不确定性来源进行严格建模以及在多尺度上统计地传播其影响。例如,经常忽略通过rf对空间变化进行建模、将跨不同的空间尺度的这些空间变化进行连接,以及研亢随机仿真。savvas等人研亢了必要的rve尺寸与纤维体积分数和纱线架构的空间变化的关系。他们的研亢表明,在较高的纤维体积分数下,rve尺寸应增加。他们还得出结论,介观尺度rve尺寸受纤维取向的影响比受波纹度的影响更大。他们的进一步研亢表明,几何特征(即纤维的形状和排列)和材料特性(成分的杨氏模量)对ud复合材料中的均质响应的影响相当显著(前者更为重要)。随着纤维数量和rve尺寸的增加,所述变化显示出减小。在这些研亢中,平均轴向刚度和剪切刚度构成了响应。vanaerschot等人研亢了复合材料特性的变化性,得出的结论是,介观尺度rve的刚度受载荷取向的影响,另外,随着纤维错位的增加,所述刚度显著降低。hsiao和daniel在实验上和理论上研亢了纤维波纹度对ud复合材料的影响,并证明了在单轴压缩加载下纤维波纹度会降低复合材料的刚度和强度。komeili和milani想出了介观尺度上的两级析因设计,以研亢正交编织织物对材料特性和纱线几何形状的敏感性。他们表明,基于施加的载荷,这些参数会对整体响应(即反作用力)产生显著影响。进行了基于sobol指数的类似敏感性研亢,以证明摩擦系数和纱线高度显著影响干燥编织织物中感兴趣的宏观尺度机械响应。纱线特性在空间上是均质的,没有纤维错位。为了解决关于编织复合材料中uq先前工作的缺点,我们采用rf,rf是在时间或空间中索引的随机变量的集合。我们介绍了一种自上而下采样方法,该自上而下采样方法通过将一个rf的超参数视为另一个rf的响应来构建嵌套的rf。这种嵌套的结构使得我们可以对微小长度尺度(即介观尺度和微观尺度)下非平稳和c0(即连续但不可微分)的rf以及宏观尺度上静态且可微分的rf进行建模。我们鼓励使用多响应高斯过程(mrgp)来简约地量化rf,并进行敏感性分析以降低维度。所得到的方法是非侵入式的(因为无需调整计算模型即可解决不确定性问题),并且可以利用统计技术(例如元建模和降低维度)来解决多尺度仿真的巨大计算成本。对于ud复合材料的uq,我们专注于可以通过成像技术捕获的两个微观结构不确定性来源:纤维分布和纤维波纹度。ud板的微观结构图像是在福特公司拍摄的,根据所述微观结构图像我们测量这两个感兴趣的量(qoi),然后利用统计方法对它们的变化进行建模。通过引入分层的非参数统计模型,我们解决了仿真用于纤维分布建模的非平稳和非均质rf的挑战。对于纤维波纹度,其图像数据极为有限,需要进行诸如平稳性之类的假设,并应用时间序列方法根据基础分布生成真实样本。这两种方法被集成到数据驱动的采样算法中,该数据驱动的采样算法可以同时仿真两个qoi的空间分布,以进行进一步的计算力学分析。将所开发的方法和工具应用于纤维复合材料,由于其优越的性能,这些纤维复合材料已越来越多地用于航空航天行业、建筑行业和运输行业。因此,我们的贡献对经济的各种部门产生了深远的影响。多尺度uq和up及其在固化编织复合材料中的应用对于多尺度uq和up,我们的方法有两个主要阶段:尺度内uq和尺度间up。我们首先识别出每个尺度上的不确定性来源,然后通过rf对它们进行建模,其中一个rf与每个结构实现相关联。我们采用具有合理的(在物理上可以解释的)参数的rf有以下三个主要原因:(i)耦合整个长度尺度上的不确定性来源并使它们从较低尺度传播到较高尺度,(ii)将rf的最重要的参数与材料系统的特征连接,从而以有物理意义的方式识别出主要的不确定性来源,以及(iii)通过在多尺度fe仿真中直接使用rf的输出(而不是调整uq和up的fe公式)来实现非侵入式uq程序。由于这些原因,我们使用多响应高斯过程的最佳线性无偏预测量(blup)表示。mrgp可以对不确定性来源进行合理的表征,具有灵活性和计算效率,并且可以通过可用数据轻松加以训练。此时,uq和up任务中的维度已从多尺度仿真中的自由度数量减少到最粗尺度的mrgp的少数超参数。但是,根据材料系统和感兴趣的量,通常在up过程中不需要考虑所有超参数。因此,通过例如通过灵敏度分析来识别主要的不确定性来源以及等效地识别相应的rf参数,可以实现进一步的降维。我们方法的第二阶段首先通过廉价但准确的元模型(又称替代品或仿真器)替代微小尺度上嵌套的仿真,从而将单个多尺度仿真的计算成本从几小时(甚至几天)降低到几分钟。元模型、其输入和其输出的选择取决于fe仿真的性质。最后,通过在up过程中传播来自所有较微小尺度的不确定性来量化最高尺度上的不确定性。在up期间,进行各种多尺度仿真,其中对于每次仿真,在多尺度材料中使用空间变化量的一种实现。为了生成这些实现中的每一个,我们引入自上向下采样方法,其中将实现分配给材料系统中从最粗尺度到最微小尺度的空间变化参数。这种采样策略使得能够(i)对微小尺度上非平稳和c0(即连续但不可微分)的空间变化进行建模,以及(ii)对所有尺度内和尺度间的各种不确定性来源之间的局部相关性进行建模。尽管自上而下采样方法可以与任何分析rf集成,但是我们选择了mrgp,因为它们足够灵活并且具有一些在物理上全部可以解释的超参数。另外,有时可以通过适当的转换将其他rf转换为gp。在图172中针对具有两个长度尺度的复合材料示出了我们的方法。图171示出了针对两个尺度结构对我们的方法的示范。采用空间随机过程(srp)生成空间变量,这些空间变量通过自上而下采样程序进行连接。不确定性量化的多响应高斯过程mrgp在rf和代理建模中广泛流行,并已在包括uq、机器学习、复杂计算机模型的敏感性分析、贝叶斯优化和简单的贝叶斯校准的广泛应用中使用。对于具有q个输出的rf,y=[y1,,yq]t,并且场(例如空间或时间)输入x=[x1,,xa]t,具有恒定先验均值的mrgp的blup表示为:其中,代表q维高斯过程,β=[β1,,βq]t是响应均值的向量,而c(x,x′)是一种参数函数,用于测量x和x’处的响应之间的协方差。c(x,x′)的一个常见选择是:其中∑是捕获输出之间的边际方差和协方差的q×q对称正定矩阵,d是场的维度,ω=[ω1,,ωd]t是控制rf的平滑度的所谓粗糙度参数或尺度参数,而是克罗内克积。应该注意,β和∑的维度取决于q,而ω的维度取决于d。参数β,∑和ω称为mrgp模型的超参数,并共同使得能够对多种随机过程进行建模:·整个输入空间上响应的平均值由β决定。·输入空间上的响应(即yi和yj,i≠j)之间的一般相关性由∑的非对角单元捕获。·每个响应的均值周围的变化由∑的对角单元控制。·整个输入空间上的响应的平滑变化/快速变化由ω控制。在可获得一些实验数据的情况下,可以通过例如最大似然法来估计mrgp模型的所有超参数。否则,如在这项工作中,可以使用专家知识或先验知识来调整这些参数并对空间变化量进行建模。一旦确定了这些超参数,就可以通过闭式公式根据mrgp模型生成实现。用于不确定性传播的自上而下采样为了执行一个多尺度仿真,必须将材料特性分配给所有尺度的所有ip,其中任何尺度的ip特性取决于下一个更微小尺度的rve(该rve本身具有多个ip)。由于这些特性取决于不确定性来源(或等效地取决于rf),因此不确定性来源必须在所有尺度上耦合。回想一下,由于结构的多尺度性质,因为我们将rf与每个结构实现相关联,所以rf的数量在微小尺度上显著增加。使用了参数在物理上敏感并且可以直接与不确定性来源联系起来的rf,这种跨尺度耦合非常简单,可以利用自上而下采样来实现,在该自上而下采样中,特定尺度的每个ip处的mrgp的输出用作与该ip相关联的rve的mrgp的超参数。该过程构成嵌套的rf。为了在整个多尺度结构中为ip参数分配值,这种方法从最粗尺度或最高尺度开始,因此称为自上而下采样。尽管自上而下采样方法适用于任何参数rf表示(例如pce或kl扩展),但我们强烈建议采用包括一些超参数的紧凑表示。这主要是因为随着微小尺度上空间变化量的数量的增加,粗尺度上的超参数的数量也会迅速增加。例如,假设在3d微观结构中三(二)个量在空间上改变,则需要具有12(8)个超参数的mrgp。为了在介观尺度上对这12(8)个超参数的空间变化进行建模,需要具有93(47)个超参数的mrgp。关于固化编织纤维复合材料的实例研究现在,我们按照我们方法的步骤来量化固化编织复合材料的弹性响应中的宏观尺度不确定性与七个不确定性来源中的空间变化的关系:纤维体积分数和错位、基体和纤维模量,以及纱线的几何形状参数(即纱线角度、高度和间距)。如图170的分图(a)所示,所述结构由四个相同的编织板层构成,这四个相同的编织板层以相同的取向堆叠并且构成总厚度为2.4mm(纤维取向用浅蓝色线表示)。图172示出了宏观固化的编织叠层结构。分图(a)示出了变形的结构。浅蓝色线表示纤维取向。尺寸被缩放以更清楚地表示。分图(b)示出了通过仿真完美制造的复合材料获得的纱线角度的确定性空间变化。分图(c)示出了与实例9相应的冯·米塞斯应力场。分图(d)示出了与实例1的一种实现相应的纱线角度的随机空间变化。分图(e)示出了与实例3的一种实现相应的的随机空间变化。通过使用非正交本构预成型模型对编织预浸料进行偏向延伸仿真获得这些编织板层的几何形状。在夹紧样本的底部的同时,拉动另一端1mm以产生偏向拉伸变形。在宏观尺度仿真中,采用3d实体连续体单元以离散化所述结构。由于我们将重点放在uq和up上,因此在这一点上,我们假设仅发生弹性变形。不确定性来源纵向纤维模量ef和纵向基体模量em是头两个不确定性来源。在给定模量的情况下,纱线材料特性主要取决于两个参数:纤维体积分数(以纱线计)v和纤维错位。尽管在大部分先前的工作中v都假定在空间上是恒定的,但实际上,它会沿着纱线路径发生变化,特别是在纱线紧密接触的地方。因此,我们的下一个不确定性来源来自v的空间变化,所述v的空间变化从微观尺度开始并传播到介观尺度和宏观尺度。在这项工作中,基于我们的材料系统,我们假设45%≤v≤65%。在制造工艺中,纱线中的纤维会偏离理想取向,并使纱线的横截面不均匀且各向异性。这些偏差导致纤维错位,这与纤维波纹度的概念不同,因为纤维可以完美地波动而不会错位。如图173所示,这种错位由两个角度φ和θ表征,这两个角度测量纤维方向f1相对于纱线横截面gk上的局部正交框架的偏差。基于文献中可用的实验数据,在这项工作中,我们假设-π≤φ≤π和0°≤θ≤90°。在对介观尺度编织复合材料进行建模时,通常假定纱线架构是完美的,其中纱线角度α设置为90°,并且纱线高度h和间距s固定为其标称值。由于预成型工艺过程中较大的面内剪切变形以及制造缺陷,因此这些假设实际上不成立。因此,我们还研亢了编织rve架构(α、h和s)的空间变化对宏观特性的影响。图173示出了纤维错位角度。天顶角和方位角表征了纤维相对于纱线横截面上的局部正交框架的错位角度。最后,我们应该注意,在我们的实例中,与其他参数(即[ν,φ,θ,h,s])不同,完美制造的复合材料中α的确定性空间变化可根据预成型工艺仿真获得。该确定性变化用作α的空间分布的先验平均值(方程(9-17)中的β),而对于其他六个参数,将标称值用作(空间恒定的)先验平均值。在所有七个参数中,后验空间变化都是随机的。我们采用计算均质化技术对多尺度编织样本进行建模,其中,任何长度尺度上的材料特性都是通过较低尺度上的rve的均质化来计算的。在微观尺度上,rve包括300×300×60体素(42μm×42μm×8.4μm),纤维直径为7μm。在采用周期性边界条件(pbc)的情况下,所述仿真是弹性的。假设纤维和基体良好粘结,没有空隙。为了获得udrve的刚度矩阵c,应用六个无应力加载状态(即在每种情况下仅应用εxx、εyy、εzz、εxy、εxz和εyz应变分量之一)。由于仿真是弹性的,因此c主要取决于体积分数ν。在介观尺度上,使用开源软件texgen创建具有8根纱线的2×2斜纹编织rve的几何形状和网格。纱线之间的空间填充有基体,并且使用体素网格来离散化rve,其中将每个体素指定给纱线或基体。为了平衡成本和精度,我们使用了具有625000个单元的体素网格。为了降低计算成本,在整个过程中都采用了pbc。碳纤维和环氧树脂的标称特性取自制造商的数据(参见表9-14)。树脂是各向同性的,其材料特性取自纯环氧树脂。具有良好排列的纤维的纱线被视为是横向各向同性的。然而,由于纤维错位,纱线不是横向各向同性的,因为在纱线横截面上所有ip的材料框架是不均匀分布的。在这种情况下,可以采用微平面三联体模型,通过为纱线的每个ip定义正交各向异性的微-三联体来解决纤维错位问题。该三联体通过错位角度与局部框架(参见图174)相关联:其中|·|和^分别表示向量的范数和向量积。关于局部框架一旦编织rve被离散化,texgen会为每个ip(介观尺度上的每个体素)自动生成局部框架我们注意到,通过ud-rve均质化获得了每个纱线材料点处的刚度矩阵。为了将介观尺度和宏观尺度联系起来,需要编织rve的有效弹性材料特性的应力-应变关系。该关系可以用对称介观尺度刚度矩阵写为:表9-14.纤维和基体特性:模量(即e和g)均以gpa为单位。还提供了沿不同方向的泊松比。ezzexx=eyyvzx=vzyvxygxz=gyzgxy碳纤维27519.80.280.3229.25.92环氧树脂3.253.790.390.391.361.36不确定性来源的自上而下采样、耦合和随机场建模为了使所述描述清晰,我们首先介绍一些符号。我们用数字表示三个尺度:1→宏观尺度,2→介观尺度,3→微观尺度。上标和下标分别表示尺度和ip。带条形的变量表示特定尺度上所有ip的平均量。例如,表示在宏观尺度上分配给第i个ip的纤维体积分数。表示编织rve在介观尺度上的平均错位角(天顶角)。表9-15中总结了我们的复合材料中的不确定性来源。虽然某些来源仅在不同结构中定义(在实现之间的空间变化下),但其他来源则具有额外的变化程度,因为它们也在结构内改变。表9-15.一种宏观结构实现的不确定性来源:来源是纤维错位角度(θ和φ)、纱线间距和高度(s和h)、纤维和基体模量(ef和em)、纤维体积分数(v)和纱线角度(α)。假设编织rve中的八个纤维束是统计独立的,并且它们中的空间变化源自相同的基础随机过程,则总共需要12个超参数才能由mrgp完全表征的空间变化(参见方程(9-17)):三个平均值六个的方差/协方差值,以及三个粗糙度参数(ω=[ωx,ωy,ωz]t,其中xyz表示介观尺度上的笛卡尔坐标系)。一旦指定了这些参数,就可以使用编织rve中ip的空间坐标为它们分配ν、φ和θ的实现。但是,对于宏观尺度上的每个ip,这12个超参数都是宏观尺度mrgp的响应的一部分,所述宏观尺度mrgp的其它响应对应于因此,宏观尺度mrgp总共具有173个超参数(对于β有17个平均值,对于∑有153个唯一协方差/方差值,对于ω=[ωη,ωξ,ωζ]有3个值,其中ηξζ表示在宏观尺度上的笛卡尔坐标系。在自上而下采样方法中,首先规定了宏观mrgp的173个超参数。然后对该mrgp进行采样,以为每个宏观ip分配17个值,其中12个值用作介观尺度mrgp的超参数,其中3个值用于构造编织rve,其中2个值用于确定纤维和基体模量。图174中示出了该过程,为清楚起见,其中仅显示了介观尺度上的(17个中的)两个超参数。图174示出了所有尺度上的不确定性来源的耦合。宏观尺度上v和θ的空间变化与更微小尺度上的v和θ的空间变化相关。为简洁起见,仅针对两个量的平均值(即,rf的均值:)示出所述耦合。通过敏感性分析在介观尺度上降维通过经由rf对空间变化进行建模,将uq和up问题的维度降低到rf超参数的数量。尽管这是一个显著的降低,但是多尺度仿真(甚至在线性分析中)的巨大成本使得uq和up过程在计算上有很高的要求。为了解决这个问题,我们注意到,根据感兴趣的特性,不确定性来源的子集通常是物理系统中主要的不确定性来源。由于我们的复合材料会发生弹性变形,因此我们预计不确定性来源的一小子集(即rf超参数)非常重要。我们进行了多尺度敏感性分析,以确定mrgp模型的12个超参数中的哪些是最重要的(并且必须在up中加以考虑),这取决于它们对介观尺度材料响应的影响。我们的研亢包括更改其中一个超参数(同时保持其余超参数固定不变)并进行20次仿真以解决随机性。然后,如果均质化响应中的变化(有效模量)可忽略不计,则将超参数视为无关紧要的,然后将其设置为常数。本节中的所有仿真都是在α=90°的编织rve上进行的。表9-16.确定纤维错位及其空间变化的影响的实例研亢:描述字段中的三联体对应于我们发现,均质化模量既不受六个协方差/方差值(即,)的影响,也不受三个粗糙度参数ω=[ωx,ωy,ωz]t的影响。在平均值(即β)的情况下,发现平均纤维体积分数和天顶角(与方位角相反)对介观尺度上的编织rve的均质化响应有很大影响。图175中总结了平均值对有效模量的影响。如图175的分图(a)所示,模量作为平均纤维体积分数的函数线性增加。将图175的分图(b)中的前九种情况与后九种情况进行比较,可以得出结论对模量和泊松比的影响不大。图175的分图(b)还表明与参考解决方案的偏差随的增加而增加(两次跳跃之间的增加,参见表9-16)。图175示出了平均值对编织rve的有效模量的影响:分图(a)为纤维体积分数的影响,分图(b)为错位的影响。这些图上的每个点都表示20次仿真的平均值。表9-15中定义了分图(b)中的实例id。参考解决方案是指不存在错位的情况。应该注意,由于我们对图173中的多尺度复合材料的弹性响应感兴趣,因此,仅在我们的敏感性研亢中考虑了有效模量的变化。与有效行为相反,编织rve的局部行为(即应力场)对ν和θ(而不是φ)的空间变化非常敏感,因此必须在非线性分析中加以考虑。通过元模型代替介观尺度仿真和微观尺度仿真为了进一步降低多尺度uq和up成本,我们采用元模型来代替与每个宏观尺度ip相对应的微观尺度和介观尺度fe仿真。特别地,该元模型捕获与宏观尺度ip关联的编织rve的刚度矩阵的宏观尺度空间变化,该宏观尺度空间变化是纱线角度(α2)、平均体积分数、纱线高度(h)和间距(s)、平均错位角度以及纤维和基体模量(ef和em)的函数。在机器学习用语中,元模型的输入和输出分别是和编织rve的刚度矩阵c。为了拟合元模型,我们生成了6个具有sobol序列的大小分别为60、70、110的训练数据集,其中α2∈[45°,90°],s2∈[2.2,2.5]mm,h2∈[0.3,0.34]mm,以及之后,我们为每个数据集拟合了mrgp元模型。然后,通过以下方程针对具有30个样本的验证数据集评估每个模型的精度:其中分别从元模型和fe仿真中获得图176中示出了每个模型的预测误差,其中可以明显看出,利用大约100个样本,可以预测出c的所有单元的误差小于6%。图176示出了预测误差与训练样本的数量的关系:随着训练样本的数量的增加,mrgp元模型在预测介观尺度编织rve的刚度矩阵的单元方面的精度增加。用于最佳采样和元建模的图形用户界面(gui)由于元建模是一种广泛适用的工具(也用在随机多尺度建模领域之外),因此开发了两个用户友好的图形界面:最佳拉丁超立方采样(olhs)和高斯过程建模。这些工具背后的思想是功能性和完整性,同时对于新手用户也足够直观。此外,图形界面是使用《matlabguide》开发的,可以在windows操作环境下的任何64位计算机上运行。如图178的分图(a)所示,olhs生成和可视化软件包允许自动生成训练数据输入,这些训练数据输入尽可能最佳且统一地跨越所需的元模型空间。可以指定任意数量的输入变量和样本数量。如图178的分图(b)所示,我们的grp软件包适用于多维和多响应数据集,一旦提供了足够的训练数据,便可以自动处理杂乱的观察结果。另外,所述界面包括一些特征,这些特征使得用户可以评估元模型的精度、对未观察到的输入进行预测,以及可视化,可视化使得用户可以方便地研亢输入输出关系,而不必考虑问题维度。关于宏观尺度不确定性的结果进行多次宏观仿真,其中在整个宏观尺度ip上在空间上发生变化。为了量化这些变量的空间变化对宏观行为的重要性,考虑了8种情况。用mrgp在宏观尺度上以受控方式从一种情况到另一种情况改变空间变化。除了最后一种情况外,针对每种情况都进行20次独立的宏观尺度仿真,以解决随机性。总而言之,进行了共161次宏观尺度仿真。最后一种实例研亢作为参考,其中没有错位,通过对图172的分图(b)所示的结构进行处理仿真确定并将所有其他参数设置为它们的标称值,即在实例1至7中,对于一个参数考虑了空间变化的影响,这时相对于先验平均值的变化量由宏观mrgp的方差控制。在这些情况中,我们将与空间变化参数相关的方差分别设置为9、25、1、0.052、0.012、402和1。这些方差足够大,以捕获真实的空间变化,同时又要足够小,以确保实现的值不会超出拟合介观尺度mrgp元模型的范围。图172的分图(b)-(e)中示出了实例1和3的样本空间变化。由于实际上不确定性来源共存,因此在实例8中,我们考虑了所有不确定性来源及其相关性的影响。这里,个体方差(宏观尺度mrgp的对角线,∑)与实例1至7相同,而协方差被选择为反映纤维体积分数与纱线和纤维错位之间的负相关性。为此,我们选择[σαv,σαθ,σvθ]=[-9,3,-3],并将∑的其余非对角值设置为零。我们注意到,当纱线在预成型后变得更接近时,σαv是负的以对纤维体积分数的增加进行建模。σvθ也是负的,以考虑富纤维区域中错位角度的减小。表9-17.仿真设置的说明:考虑了九种仿真实例,以量化宏观尺度的不确定性和空间变化的相对重要性。在所有情况下,均采用mrgp生成随机实现。除实例9(参考仿真)外,所有实例都包括20次仿真,以解决仅存在一个不确定性来源的情况下的随机性。图178的分图(a)比较了九种情况的样本横截面上的作用力,其中对于实例1至8,力-位移线是20个多尺度仿真的平均值。结果表明,在存在纤维错位的情况下,结构减弱,因此反作用力降低。在存在其他不确定性来源的情况下,这种减弱作用会加剧。特别是,在参考情况中,最大反作用力(大小)为15.4n,在实例3和8中,分别为14kn和13.5kn。这些结果表明:(i)复合材料的仿真必须考虑到纤维错位,即使主要对线性分析中的整体响应感兴趣;(ii)应考虑各种不确定性来源之间的相互作用:一旦考虑了所有不确定性来源,在反作用力减小12.3%的情况下,结构会更加明显地减弱;(iii)对某些参数的空间变化不敏感可以用以下事实解释:在线性分析中,整体响应主要受平均特性的影响。由于我们仅引入空间变化(除了纤维错位之外,我们不改变结构上的参数平均值),因此直观地得出结果是有意义的。为了说明空间变化对局部行为的影响,在图178的分图(b)-(c)中我们分别比较了结构中间部分的冯·米塞斯应力场的平均偏差和标准偏差。由于在我们的多尺度fe仿真中采用了显式求解器,因此在结构的边界可能会出现人工应力集中,因此我们选择整个结构的中间部分来分析应变场。通过分析与每种情况相对应的20个仿真,获得这两个图中的曲线。类似于图179的分图(a),图178的分图(b)表明,在存在纤维错位的情况下,结构减弱,这是因为中间部分的平均应力低于参考结构的平均应力(实例9)。显然,存在所有不确定性来源的最真实的情况会导致结构最弱。更有趣的是,这种减弱在整个中间部分是不均匀的,并且在中部最大,其下降幅度约为12.3%。在实例8中观察到了特定情况的仿真中最高的变化,其中所有参数在空间上都相对改变,参见图178的分图(c)。接下来是实例2、3和7,与实例2和7一样,在ip之间的波动更多(应该注意,沿x轴的每个点对应于中间部分的ip)。最后,实例4和5与纱线间距和高度改变的仿真相对应,具有最小的变化量。这是可以预期的,因为编织rve的刚度矩阵(通过介观尺度mrgp元模型获得)对这些参数也相当不敏感。但是,我们强调指出,我们已经考虑了这两个参数的相对较小的变化范围。如果这些范围增加,它们的效果将更加突出。ud复合材料的基于图像的微观结构uqud复合材料的uq工作旨在对材料的微观结构特征进行统计建模和重建,材料的微观结构特征包括(1)不均匀的纤维空间分布和(2)纤维波纹度。我们基于在福特汽车公司拍摄的ud板的微观结构图像构建我们的模型。针对图像表征、信息检索和生成的模型构建,开发了几种基于机器学习和应用统计的方法。对于同时表现出非平稳性和非均匀性的空间纤维分布,我们首先通过树回归算法对数据(图像)进行建模,然后开发出一种分层的非参数采样方法。该方法完全由数据驱动,在某种意义上,假设没有概率模型并且通过从数据中重新采样来生成新样本的一部分。纤维波纹度是纤维束相对于纤维整体方向的局部取向。完全笔直的纤维的波纹度到处为零,但是,从单向纤维复合材料样本(图182)获取的横向图像显示出确实存在波纹度。另一方面,由于图像质量的限制,就断开的碎片而言,仅观察到部分纤维,因此用于边缘或目标检测的传统计算机视觉算法不适用于本发明。为了克服这一挑战,我们开发了一种分段回归算法,该分段回归算法可以通过类似于线性回归、基于优化的方法来估计局部波纹角。然后,利用时间序列统计模型对沿纤维纵向方向的角度分布进行建模,从中我们可以对实现进行采样。纤维分布建模通过目视检查由纤维的局部体积分数的分布(图179的分图(a))表示的纤维的分布,局部纤维体积分数之间的空间相关性表现出两个特征。第一个特征是非均匀性,它是由分层结构沿垂直方向反映的。第二个特征是非平稳性,它是指体积分数图案沿水平方向的局部曲率。利用传统的参数统计模型对这两个特征进行建模将涉及估计代表这些特征的许多参数。因此,我们使用一种可选方法:沿着垂直方向,通过(利用替换)从图像数据集中重新采样,从其经验分布中采样非均匀性(即某些波状函数的形状);沿着水平方向,通过寻找该特征的代表性统计量并尝试找到统计量的分布来对非平稳性进行建模。找到这种统计量的第一步是将每个样本图像的尺寸从大约450,000像素减小到可管理的大小。为了压缩样本中的数据,我们使用了回归树算法,即样本由树形结构字段表示。通过使积分相对误差(ire)最小化,可以找到分割线(树的节点)的位置,并且在分割线之间对数据进行线性插值。通过将回归目标设置为ire<5%,我们通常获得200-300个节点。由于分割线将最不同的区域分开,所以它们的位置包含非平稳性的信息:这些线越密集,该区域包括的局部曲率就越多(图179的分图(b))。应该注意,密集的线集合意味着线间距离更小。因此,我们可以使用线间距离的分布来表征非平稳性。就概率密度估计而言,线间距离的分布是与所有样本一起生成的。图180的前三个曲线图显示了其中三个。可以观察到,每个样本的非平稳性水平不同,这可能是由于材料性能的差异。通过将10个随机选择的样本的线间距离数据分组在一起,估计出最后三个曲线图中的分布。概率密度的形状的相似性表明分布的收敛,即所有样本后面的共同分布。该观察提供了一种生成具有相似的非平稳性水平的随机样本的方式,该方式是根据图180的分图(b)中的共同分布对分割线的位置进行采样。根据通过数据估计的经验分布直接对沿垂直分割线的体积分数进行采样。因此,可以通过以下方式构造用于纤维分布/体积分数的采样算法:(a)根据线间距离的共同分布生成随机的分割位置,然后(b)根据数据集对沿分割线的体积分数进行重新采样,并且(c)通过对相邻线进行插值来填充线之间的区域。下面展示了两个示例性重建(图181),与原始样本相比(例如,在图180的分图(a)中),它显示出了随机性和高度相似性。纤维波纹度表征根据横向图像表征纤维波纹度并不像表征处理分布一样简单,因为就局部斜率或角度而言,不能根据像素信息(例如,二进制或灰度值)直接计算图像中的局部曲率。通常,表征过程将涉及检测图像上的每根纤维并相应地计算角度。但是,这种方法在本发明中失败了,因为未完全显示图像中的纤维,即仅观察到部分纤维,并且这部分纤维中的一些仅以点或小块的形式出现,因此其取向无法单独测量(参见例如,图182中的二进制图像段)。可以设计过滤器以将其作为噪声去除,但它们仍然具有总体趋势,这一事实表明统计表征有助于保存信息。还应注意,线性回归是估计斜率的理想工具,因此我们开发了一种分段线性回归方法(图182)来表征图像中的局部曲率。该方法背后的思想是:局部角度与局部斜率之间的关系由β=tan(α)给出,其中β是斜率,α是角度,局部斜率由回归线的斜率估计,在原始图像的局部二值化片段上具有多个点。最具挑战性的部分是为回归构建有效的线性模型:经典的简单线性模型假设误差为正态分布,并基于这个假设推导出众所周知的最小二乘法,在我们的问题中这是无效的。我们针对这种情况提出了我们自己的回归算法:在假设纤维像素点和纤维位置均匀分布的情况下,假设坐标原点位于图像段的中心,并且通过函数y=βx给出从原点回归的均值预测,斜率β的估计由下式给出:其中e是带有回归线的残差集y=βx(假设总共有n个点),是残差与残差的概率密度估计中的模数之间的映射。通过该估计,正确地捕获纤维在横向方向上的趋势(参见图183和184进行说明)纤维波纹度建模与该任务相关的挑战是图像数量非常有限:实际上总共只有一个图像(图184)。因此,进行了一些假设以验证我们构建统计模型和采样算法的方法:(1)此图像中包含的波纹度代表波纹分布;(2)波纹度分布是平稳的;(3)沿厚度/垂直方向的波纹度变化的影响很小,因此仅对沿水平方向的纤维角度分布进行建模。基于(9-3),我们可以对沿厚度方向的波状角进行平均并获得1d信号(图185)。所得到的信号具有幅度和频率变化的波形。这一信号的自然特征是周期图。周期图是信号频谱密度的估计,可以通过时间或空间序列的离散傅里叶变换获得。在假设(2)下,可以证明,随着序列长度的增加,序列的周期图在分布上收敛到一系列独立且呈指数分布的随机变量。然后,通过以下方式构造采样算法:(a)获取信号的周期图,(b)通过利用(a)给出的参数从独立的指数分布中采样来生成随机周期图,以及(c)使用傅立叶逆变换从(b)获得新的波纹度样本。图185示出了原始样本与在空间域和频域上的重建之间的比较。两种不确定性来源的联合采样上面的两种算法,一种用于纤维波纹度,一种用于纤维分布,能够分别对各个qoi进行建模和采样。但是,当将它们集成到联合采样程序中时,必须考虑空间限制。例如,如果我们要同时生成用于试件仿真模型的两个qoi的空间分布,则在不同横截面(即,沿纤维纵向方向在不同位置截取的横截面)的纤维分布的图案应相似但不同,因为纤维沿纵向方向弯曲。因此,将两个采样代码的独立实现结合起来将无法代表实际情况。为了观察这种现象,我们开发了一种用于试件模型的联合采样算法,并且可以根据该方法生成真实的实现。与依赖于随机变量的先前工作相反,我们采用随机场来对多尺度材料(例如固化编织复合材料)中的空间变化的不确定性来源进行建模。我们引入了自上而下采样方法,该自上而下采样方法构建嵌套的随机字段,进而使我们可以在微小的长度尺度(即介观尺度和微观尺度)上对非平稳性变化进行建模。我们鼓励使用多响应高斯过程来简约地量化随机字段,并进行敏感性分析以降低维度。所得到的方法是非侵入式的,并且可以利用统计技术来解决多尺度仿真的巨大计算成本。通过使用空间填充设计中训练的高斯随机过程,避免了多尺度材料的计算需求。由于工程问题中普遍存在对计算要求很高的仿真,因此开发出的用户友好的gui使得更多从事各种挑战的工程师可以从这些强大的工具中受益。嵌入在其源代码中的gui和工具能够将有效的仿真运转时间从几天缩短到几秒钟,其中包括多达50个输入变量的高维问题。开发了图像表征技术以量化ud不确定性来源(纤维波纹度和空间分布)的变化,并引入了相应的统计模型以研亢来自基础分布的随机场或随机过程的可变性和样本实现。与通常预先假设一些参数模型来表示不确定性的现有工作相比,我们的方法充分利用了可用的微观结构图像数据,并能够在现实环境中对ud复合材料的不确定性进行系统研亢。不确定性量化涉及使用多种计算和统计工具,选择适当的工具取决于可用的信息和资源。例如,对于编织复合材料的uq,在没有数据的情况下,选择高斯rf等参数rf模型,并开发用于多尺度分析的相关的自上而下采样方法,以研亢不确定性的影响;而对于ud复合材料的ud,由于给出了图像,因此设计了采样算法来仿真图像数据中包含的信息,从而使随机重建的样本更为真实。uq中的域大小也非常重要。例如,所选择的编织复合材料的uq中的微观尺度和介观尺度rve足够大,因此,如果我们选择较小的rve,则在响应中会观察到更多的不确定性。最后,我们注意到可以通过实验数据验证任何方法(包括我们的方法)的基本假设。例如,我们为编织复合材料中的uq选择mrgp暗示了正态性假设,这在分布严重偏斜或不易获得适当转换的其他应用中可能不成立。在这类情况下,其他随机场表示可以与自上而下采样方法集成,但是将以更多的计算为代价。将来,我们计划在不同空间尺度上从各种结构收集实验图像,以进一步证明我们的方法的应用。另外,实验数据将使我们能够验证对边际变化做出的正态性假设。最后,由于不确定性在材料和结构的非线性分析中更为重要,因此我们计划将我们的方法应用于诸如塑性之类的非线性问题中。对于ud复合材料的uq,在不确定性来源的变化被量化并开发相应的采样算法之后,下一步是基于生成的样本进行fea仿真,并研亢不确定性来源的影响。如果证明不确定性来源对ud复合材料的特性有影响,则应修改利用ud特性的其他多尺度模型,以反映ud尺度上存在不确定性。如果为ud的uq开发一些非基于图像的参数模型,这也将是有益的,从而可以通过一些参数来控制不确定性的水平,使诸如敏感性分析和元建模的研亢成为可能。5.零件级建模和模型验证本节中的零件尺度预成型实验验证测量了非正交预浸料材料模型的预测精度和多尺度预成型仿真方法。它还提供了有关当前仿真方法以及将来可能的解决方案的局限性的指导。最后,在预成型验证实验中选择各种工艺参数会导致不同的零件质量。观察和总结工艺参数与零件质量之间的关系可以作为生产高质量零件以进行研亢或进行实际生产应用的经验法则。随着双曲率特征的引入,在此cime项目中应用的双圆顶验证实验给出了一种定量测量3d几何形状零件的预成型模型的预测精度的可信赖的方法。这种双圆顶预成型实验验证不仅可以用于本发明中开发的模型,而且还可以用于未来的用于碳纤维预浸料预成型仿真的模型,以确定其精度和应用潜力。使用双圆顶基准几何形状来在零件尺度上验证本发明中开发的非正交材料模型和多尺度预成型仿真方法。在本发明中应用的双圆顶几何形状在普通汽车零件的尺寸上具有3d形状和复杂的双曲率特征。它是定量测量用于实际零件生产的预成型模型的预测精度的理想基准。在验证中,不仅要比较最终零件形状,还要比较不同位置的纱线角度,以及成型力。这是因为纱线角度(它是纤维取向的指标)显著影响了cfrp零件的机械刚度和强度,而成型力则是控制纤维束分离和断裂的薄膜应力的指示。在此基准验证中试验了不同的工艺参数组合,以确保模型可以在各种生产条件下工作。还比较了非正交模型与常规正交各向异性材料模型,以显示我们为实现本发明中的预成型仿真所做的改进。该零件尺度的双圆顶预成型实验的主要技术目标是验证我们在本发明中开发的非正交材料模型和多尺度预成型仿真方法的预测能力,并检查通过这两种仿真方法进行纤维取向预测是否达到所提出的5%误差。通过成功建立此基准试验以及相应的定量测量和验证标准,我们还旨在为学术研亢人员和工业研亢人员提供一种被广泛接受的预成型仿真验证方法。预成型是一个温度变化的过程,因为在此过程中利用了热的预浸料片材和冷/热工具。在本发明进行的双圆顶基准预成型验证实验中,首先将所提供的预浸料在炉中加热至70℃左右,然后将其置于压力机中进行预成型。图186中示出了双圆顶冲头和捆缚装置的几何形状,图188中示出了实验设置。为了加快生产速率,通过压力机内的冷却剂将压力机保持在23℃,因此预浸料的温度在预成型过程中从初始值下降。在单层预成型设置中,通过热电偶测量一个预浸料的顶表面中心、底表面中心和顶表面的一侧点处的温度历史记录,并在图186的分图(b)中绘制出来。该曲线图表明预浸料在炉中达到70℃左右的温度。然后,在从炉运输到压力机的过程中,通过空气将其逐渐冷却至45℃左右。当置于压力机中时,由于热的预浸料与冷的金属之间的热传导,冷却速率大大提高。具体而言,温度在前2秒内下降了20℃。同时,压力机花了10秒钟与冲头和预浸料接触,又花了6秒钟完成了预成型。因此,在该预成型工艺过程中预浸料的实际温度非常接近23℃,即压制温度。作为结果,尽管预成型模型能够考虑温度相关性,但在当前的验证实验设置中,表征预浸料的机械特性并在23℃的固定温度下仿真预成型工艺是合理的。使用动态显式积分方法在ls-中建立预成型仿真模型,所述预成型仿真模型利用了基于实验的非正交材料模型或多尺度方法。图188中示出了仿真设置:在该工艺中对多层预浸料进行预成型,冲头位移为90mm,并且根据实验测量值,捆缚力从4000n线性增加到8200n。预浸料的厚度与其长度和宽度相比要小几个数量级,因此,预浸料通过减少积分的壳体单元s4r被离散化,从而降低了计算成本。每个单元为大约4mm×4mm,具有五个贯穿厚度的积分点。与具有未固化树脂的软预浸料相比,工具由于具有较高的刚度而被仿真为刚体,因此,它们的单元类型不会影响仿真结果。选择s3单元来离散化工具,因为s3单元具有针对复杂几何形状的出色的自动网格功能。根据实验测量值将工具与预浸料之间的摩擦系数设置为0.3。摩擦系数在ls-中是恒定的动态摩擦系数,而静摩擦则被忽略,因为预成型工艺会导致大的预浸料变形,进而导致工具与预浸料之间的较大滑动。对于第一组验证,仅对一层具有±45°初始纤维取向的预浸料进行验证。比较了利用基于实验的非正交材料模型进行的仿真以及利用常规正交各向异性材料模型进行的仿真进行实验的结果。在仿真模型中,在23℃下使用单轴拉伸试验、偏向延伸试验和弯曲试验对材料特性进行校准,同时将纱线方向与全局坐标之间的初始角度定义为材料输入特性,以识别纤维合层。在图125的右上四分之一中的仿真结果表明所建立的非正交材料模型能够准确预测有关纱线角度分布和坯料拉缩的物理实验。例如,最大拉缩距离的偏差约为9mm,如表9-1所列出的。为了比较,在另一个仿真中使用了正交各向异性材料模型(mat_002),其结果显示在图189的左上四分之一中。由于正交各向异性模型无法跟踪纱线旋转过程中的材料特性改变,因此相应的仿真具有24mm的最大拉缩偏差,如表9-1所列出的,因此无法捕获总体工艺行为。在非正交模型中,纱线角度被定义为输出变量,而mat_002不具有直接可视化的能力。为清楚起见,表9-18比较了从实验和仿真获得的各个位置处的所得到的剪切角。再次表明,当前模型提高了预测精度。仅一半位置的纤维取向(纱线角度)预测误差达到所提出的5%,这令人不满意。表9-18.仿真与实验之间的拉缩距离和纱线角度比较:仿真结果来自基于实验的非正交材料模型和常规的正交各向异性材料模型(mat_002)。比较拉缩abcdef非正交40.22mm89°89°71°40°45°65°正交各向异性25.00mm70°85°86°47°59°77°实验49.02mm80°88°71°49°56°66°纤维取向预测精度令人不满意的原因在于,这种非正交材料模型仅利用了单轴拉伸(纯拉伸)和偏向延伸(纯剪切)试验的实验数据。忽略了拉伸与剪切之间的耦合。对于真正的预浸料,沿纱线的拉伸增加将使经纱与纬纱之间的接触力和摩擦力增加,从而导致剪切强度增加。基于实验的非正交模型无法仿真这种机制。但是,可以通过多尺度预成型仿真方法捕获这种机制,其中虚拟材料表征通过实验校准的介观尺度rve模型进行,该介观尺度rve模型可以变形至任意应变。为了证明多尺度建模的改进,将其仿真结果与从先前的非正交材料模型获得的仿真结果进行比较。图190的分图(a)中示出了最终的预浸料几何形状和纱线角度分布结果以及真实的预成型零件。表9-19中列出了通过仿真和实验在采样位置处的拉缩距离和纱线角度。比较表明,这种利用拉伸-剪切耦合的多尺度方法在6个采样点中的5个采样点处实现了所提出的5%误差的纤维取向(纱线角度),并且所有采样点处的预测误差均小于8%。表9-19.仿真与实验之间的拉缩距离和纱线角度比较:仿真结果来自新的多尺度材料模型和拉伸-剪切解耦材料模型。比较拉缩abcdef多尺度42.25mm86°88°73°54°57°67°非正交40.22mm89°89°71°40°45°65°实验49.02mm80°88°71°49°56°66°图190的分图(b)中比较了来自两种仿真情况和实验的冲压力-位移曲线。这些曲线图表明,与使用基于实验的非正交材料模型进行的仿真相比,多尺度预成型仿真方法预测的冲压力几乎与实验预测的冲压力相同,所述基于实验的非正交材料模型将实验冲压力低估了约26%。当冲头位移达到70mm以上时,新的仿真方法与实验产生的力之间的微小差异可能是由于忽略了仿真中壳体单元引起的预浸料厚度变化导致的。但是,当冲头位移范围为20mm至50mm时,微小的力差异可能是由于以下事实导致的:预浸料的某些位置处的温度在预成型的初始阶段尚未完全达到23℃,从而导致与仿真得到的材料行为相比具有更软的材料行为。作为总结,这种具有拉伸-剪力耦合的多尺度预成型仿真方法可以预测预成型的预浸料的拉缩距离和纱线角度变化。更重要的是,它还可以以高精度预测冲压力的历史记录。因此,这种多尺度方法比基于实验的非正交模式具有更强的预测能力,并且可以用作对将来的预成型工作进行零件性能预测、工艺参数优化、材料设计和缺陷分析的强大工具。在以±45°的初始纤维取向和6个纱线角度测量位置进行单层预成型验证之后,以不同的测量位置、不同的初始纤维取向和不同数量的预浸料层(0°/90°一层、±45°一层,以及0°/90°/±45°两层)进行进一步验证。由于项目时间的限制,仅将基于实验的非正交模型的仿真结果与实验的结果进行比较。多尺度仿真方法不适用于这些构造。图191中示出了具有不同的初始纤维取向的仿真结果和实验结果。表9-20中列出了拉缩距离比较。可以看出,通过仿真预测的大多数拉缩距离都在实验结果的范围内。但是,在单层和双层情况下,对于-45/+45初始纤维取向,在x方向拉缩中发生了两个最大偏差。还值得注意的是,对于单层-45/+45设置,在实验中,预成型后x方向上的试样尺寸实际上变大了(负的拉缩距离),这不仅与仿真不同,而且与常规成型工艺不同。表9-20.双圆顶拉缩距离比较。对于经纱角度分布和纬纱角度分布,图192中示出了结果。可以看出,对于单层情况,仿真与实验良好吻合。在几乎所有测量位置处,仿真结果均在实验偏差内,并且与平均实验结果相比可实现所提出的5%预测误差。但是,对于双层而言,差异更大。这种差异的最可能的原因是预浸料温度的迅速下降(如图190的分图(b)所示)导致树脂熔化并且在两个预浸料层之间重新凝固,这使得预浸料界面非常粘甚至消失,从而导致更大的相互作用强度,并且与仿真相比,使预浸料之间的相对滑动要困难得多。实际上,从实验的角度看,当树脂熔化但未固化时,本发明中所提供的预浸料在50℃至80℃下具有最佳的预成型温度。当温度下降到23℃左右时,树脂将变得坚硬且非常粘,导致不希望的特征(例如边缘断裂、不连续变形、面外变形或者甚至折叠),如图193所示。将来,不仅在预成型仿真中应考虑与温度有关的预浸料表面相互作用,而且可能需要通过将冷却剂加热至所需温度来调节工具的温度。该操作的目的不仅仅是减少仿真和实验差异,而且更重要的是,它可以提高最终零件的质量。所建立的双圆顶预成型基准试验可以在普通汽车零件的尺寸上引入复杂的双曲率特征。结合同样在本发明中开发的局部预浸料温度历史、拉缩距离、局部纱线角度和成型力的相应的定量测量,所建立的双圆顶预成型基准试验用作验证本发明中开发的预成型仿真方法的有效的实验方法。验证结果表明,所开发的模型在大多数情况下可以达到所提出的小于5%的纤维取向预测误差,从而保证模型的应用潜力。除了用于校准本发明中的模型外,由于该双圆顶基准试验考虑了大多数工艺参数并提供了最终零件的性能的最重要的标准,因此它还可用于对将来开发的或来自其他研亢人员的预成型仿真模型进行验证。作为结果,这种方法使学术界和工业界的研亢人员能够以可靠的方式对其预成型模型进行试验,从而激发准确的预成型仿真模型的发明,所述预成型仿真模型可以帮助提高产量并扩宽先进cfrp的应用,同时有利于环境排放和化石燃料控制。此外,在本发明中执行的双圆顶预成型试验提供了有关高质量零件生产的重要信息。不仅要在加热炉中进行温度控制,而且要用成型工具进行温度控制,这对于树脂完全熔化并引起较小的预浸料变形阻力和较小的预浸料表面相互作用都至关重要,这是生产出光滑且无缺陷的最终零件的关键。尽管事实上难以直接将双圆顶预成型验证实验的这种精确设置商业化,但它促进了本发明中开发的用于验证这些模型的预测精度的预成型模型的商业化。可以以开源的形式将局部温度、拉缩距离、局部纱线角度和成型力的定量测量方法转给其他研亢团队,以建立广为接受的预成型仿真验证标准,这样可以加快其他高精度预成型模型的开发。从该预成型实验中获得的温度控制和监控经验可以被实现在预成型压力机中,以便以加热的冷却剂和嵌入式热电偶的形式进行实际生产,从而生产出光滑且无缺陷的cfrp零件。在根据本发明的零件级预成型模型验证中,我们建立了双圆顶基准试验以及相应的定量测量方法和标准。基准试验验证了我们开发的预成型模型的预测能力。此外,提供了一种对其他研亢人员的模型进行试验的值得信赖的方法,并为预成型设备的设计提供了有见地的指导。对于需要考虑多个参数的实验(例如这个预成型基准试验)来说,必须适当地执行实验设计,以清楚地研亢来自参数的影响,同时使材料消耗和时间消耗较低。对于使用预浸料进行预成型,重要的是不仅要控制初始预浸料温度,而且还要控制工具温度以确保树脂在整个预成型工艺过程中保持熔化,从而实现光滑且无缺陷的零件的生产。本发明的示例性实施例的前述描述仅是出于说明和描述的目的提出,而并不意在穷举或将本发明限制为所公开的确切形式。鉴于以上教导,可能有许多修改和变化。选择和描述实施例以解释本发明的原理及其实际应用,从而使得本领域的其他技术人员能够最好地利用本发明和各种实施例,并在适合预期的特定使用时做出各种修改。在不脱离本发明的精神和范围的情况下,替代实施例对于本发明所属领域的技术人员将变得显而易见。因此,本发明的范围由所附权利要求书而不是前面的描述和其中描述的示例性实施例来定义。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1