宫颈癌癌前早期病变阶段诊断模型及建立方法与流程
本发明涉及医学检测技术领域,特别是涉及一种宫颈癌癌前早期病变阶段诊断模型及建立方法。
背景技术:
宫颈癌是严重侵害女性健康的恶性疾病,发病率高,且呈持续增长趋势。现有的预防宫颈癌的策略为对适龄妇女进行细胞学和hpvdna水平的筛查。但是由于细胞学筛查对于检测设备及医生资源要求较高,很大程度上限制了资源不足地区的筛查推广。越来越多的研究希望探索单独通过dna的检测结果来推断疾病状态的方法。
然而,由于单纯hpvdna的检测结果的假阳性率较高,进而导致过高的阴道镜转诊率,因此,单纯依赖hpvdna阴阳性来判断宫颈癌早期病变需要结合其他指标来提高准确性。
有研究提出dna的甲基化水平或者hpv的整合状态也可以作为筛查的指标,但目前的研究结果还存在结果不一致及准确性不够高的问题。hpvdna检测方法非常多,有hc2,aptimae6e6,cobas4800等方法,其中一些方法的检测结果可以一定程度地反映hpv病毒在宿主体内的存在丰度,被称为病毒载量。病毒载量与宫颈癌癌前病变不同分期的相关性已被研究证实,也有研究试图利用hpv病毒载量进行辅助疾病诊断,但存在结果准确性不够高等问题。
技术实现要素:
基于此,有必要针对上述问题,提供一种宫颈癌癌前早期病变阶段诊断模型及建立方法,该诊断系统采用临床检验结果大数据,集中多项因子不同组合进行多种机器学习方法的模型构建,并对模型进行准确性评估,通过比较不同组合及不同方法的结果,得到最优的诊断模型用于临床诊断。
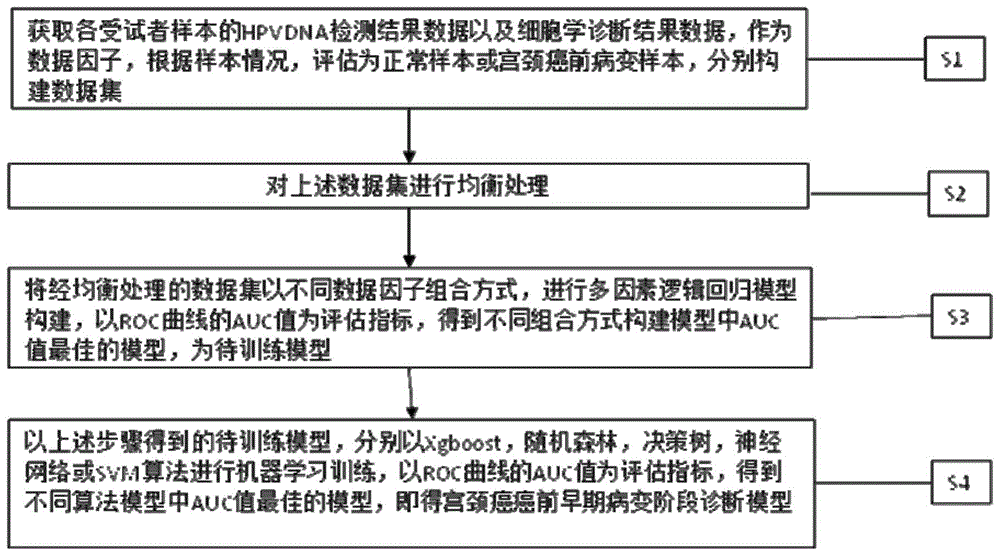
一种宫颈癌癌前早期病变阶段诊断模型的建立方法,包括以下步骤:
s1:获取各受试者样本的hpvdna检测结果数据以及细胞学诊断结果数据,作为数据因子,根据样本情况,评估为正常样本或宫颈癌前病变样本,分别构建数据集;
s2:对上述数据集进行均衡处理;
s3:将经均衡处理的数据集以不同数据因子组合方式,进行多因素逻辑回归模型构建,以roc曲线的auc值为评估指标,得到不同组合方式构建模型中auc值最佳的模型,为待训练模型;
s4:以上述步骤得到的待训练模型,分别以xgboost,随机森林,决策树,神经网络或svm算法进行机器学习训练,以roc曲线的auc值为评估指标,得到不同算法模型中auc值最佳的模型,即得宫颈癌癌前早期病变阶段诊断模型。
上述宫颈癌癌前早期病变阶段诊断模型的建立方法,首先收集患者的hpvdna检测和宫颈细胞学检测结果,构建数据集;针对数据集的不同数据因子组合分别采用不同模型构建方法(逻辑回归,svm,随机森林,决策树,神经网络,xgboost等),以不同癌前病变阶段进行建模训练,将训练好的模型通过验证集进行验证,获得针对各病变分期的多种不同检测模型;评估每种模型的诊断效果,并比较相同分期的诊断模型效果优劣,选择最优的模型;收集测试检测结果并构建测试数据集,通过选择出的最优诊断模型,预测每个患者的疾病状态及分期,从而对模型进一步验证。
经过以上所述模型构建方法及比较,本方法最终建立的宫颈癌癌前早期病变阶段诊断模型,对早期宫颈癌前病变有较高的诊断效率,阳性预测值和阴性预测值分别可以达到0.8706和0.946,能够应用于仅有hpv检测结果的早期疾病诊断。
在其中一个实施例中,s1步骤中,所述hpvdna检测结果数据包括:hpv感染状态、hpv病毒载量;所述细胞学诊断结果数据包括:细胞学诊断的分期、阴道炎情况、真菌感染情况。
在其中一个实施例中,s1步骤中,所述宫颈癌前病变样本评估为ascus、asc-h、hsil或lsil。上述ascus指意义不明的非典型鳞状上皮细胞(atypicalsquamouscellsofundeterminedsignificance),asc-h指不能排除高级别鳞状上皮内病变的非典型鳞状上皮细胞(atypicalsquamouscells:cannotexcludehigh-gradesquamousintraepitheliallesion),hsil指高度鳞状上皮内病变(high-gradesquamousintraepitheliallesion),lsil指低度鳞状上皮内病变(low-gradesquamousintraepitheliallesion)。
在其中一个实施例中,s2步骤中,采用smote-regular方法对正常和宫颈癌前病变样本的数据集进行均衡处理,使正常样本和宫颈癌前病变样本的数目具有一致性。可以理解的,所述一致性指符合统计学要求,正常样本和宫颈癌前病变样本的数目接近相同。
在其中一个实施例中,s2步骤中,采用smote-regular方法进行均衡处理的具体步骤为,以dmwr软件,先统计不同endpoint下的01频数,从而得到少数类样本和多数类样本的比例,再根据该比例,相应地模拟合成少数类样本,进行数据平衡。
在其中一个实施例中,s3步骤中,多因素逻辑回归模型构建以rattle软件的逻辑回归分析方法进行,该模型构建以不同癌前病变早期分期为因变量(y),以不同相关因子组合为自变量(x)组合,假设因变量(y)服从伯努利分布,采用sigmod函数作为判别函数,最后给出相应的概率值,通过采用预定阈值(一般为0.5)进行二分类判别。可以理解的,所述阈值可以采用不同的阈值进行判别,一般为0.5。
上述癌前病变早期分期包括:ascus、asc-h、lsil和hsil。
在其中一个实施例中,s3步骤中,以hpv病毒载量和阴道炎情况作为数据因子组合构建得到的模型为待训练模型。
在其中一个实施例中,s4步骤中,以xgboost算法进行机器学习训练,设置树的最大深度为6,迭代次数为50,学习速率为0.3,然后根据训练集数据进行建模,得到宫颈癌癌前早期病变阶段诊断模型。
本发明还公开了上述的宫颈癌癌前早期病变阶段诊断模型的建立方法建立得到的宫颈癌癌前早期病变阶段诊断模型。
在其中一个实施例中,所述宫颈癌癌前早期病变阶段包括:ascus、asc-h、hsil和lsil。
与现有技术相比,本发明具有以下有益效果:
本发明的一种宫颈癌癌前早期病变阶段诊断模型的建立方法,通过对3万多例临床检测数据,为构建准确性高的诊断模型提供保障;并通过对数据集进行了均衡处理,避免由于数据不平衡导致的模型无用;再通过比较不同建模因子组合,选择出最优因子组合(vl+bv);并通过比较六种不同的机器学习建模方法,从中选择最准确的诊断模型并确定最合适的建模方法(xgboost),最终得到的宫颈癌癌前早期病变阶段诊断模型,对以癌前病变各阶段为重点的患者阳性预测值可达0.8706,阴性预测值可达0.946。
并且本方法基于宫颈癌筛查数据集构建模型,对患者无额外负担,数据易采集,具有实操性强的优点。
本发明的一种宫颈癌癌前早期病变阶段诊断模型,可以基于筛查数据或自采样数据进行宫颈癌早期筛查或诊断的预测,精确度高,可进一步应用于医学诊断数据的处理及疾病的早期诊断领域。
附图说明
图1为本发明模型建立方法流程示意图;
图2为实施例1中模型建立方法流程示意图;
图3为实施例2中测试数据集分析方法流程示意图;
图4为实施例2中模型验证的roc曲线图。
具体实施方式
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的较佳实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
一种宫颈癌癌前早期病变阶段诊断模型的建立方法,如图1所示流程,包括以下步骤:
s1:获取各受试者样本的hpvdna检测结果数据以及细胞学诊断结果数据,作为数据因子,根据样本情况,评估为正常样本或宫颈癌前病变样本,分别构建数据集;
s2:对上述数据集进行均衡处理;
s3:将经均衡处理的数据集以不同数据因子组合方式,进行多因素逻辑回归模型构建,以roc曲线的auc值为评估指标,得到不同组合方式构建模型中auc值最佳的模型,为待训练模型;
s4:以上述步骤得到的待训练模型,分别以xgboost,随机森林,决策树,神经网络或svm算法进行机器学习训练,以roc曲线的auc值为评估指标,得到不同算法模型中auc值最佳的模型,即得宫颈癌癌前早期病变阶段诊断模型。
以下针对具体样本数据,对建立宫颈癌癌前早期病变阶段诊断模型的方法进行举例说明。
实施例1
一种宫颈癌癌前早期病变阶段诊断模型,其流程如图2所示,通过以下方法建立:
s1:获取各受试者样本的hpvdna检测结果数据以及细胞学诊断结果数据,作为数据因子,根据样本情况,评估为正常样本或宫颈癌前病变样本,分别构建数据集。具体方法如下:
s11:数据收集。
宫颈涂片细胞hpvdna和tct细胞学临床检测数据31954例。提取hpv感染状态(即阴性或阳性),hpv病毒载量(vl),细胞学诊断的分期(tct宫颈癌前病变分期,即tct分期),年龄(age),阴道炎(bv),真菌感染(fungus)等诊断结果。
s12:构建数据集。
构建数据集,由上述病毒载量(vl)、细胞病理结果(tct分期)、阴道炎(bv)、真菌感染(fungus)等因子构成。该数据集信息汇总见表1。
表1.临床检测数据
s2:对上述数据集进行均衡处理。
具体方法如下:
通过smote-rregular方法对正常和非正常宫颈癌前病变阶段(以不同病变分期及以上分期为终点,包括ascus、asc-h、lsil或hsil)的数据集进行过采样处理,以dmwr软件,先统计不同endpoint下的01频数,从而得到少数类样本和多数类样本的比例,再根据该比例,相应地模拟合成少数类样本,进行数据平衡。以达到正常和宫颈癌前病变样本的数目一致性,即接近相同。各个不同诊断终点的过采样比例从3到51倍不等,具体见表2。
s3:将经均衡处理的数据集以不同数据因子组合方式,进行多因素逻辑回归模型构建,以rattle软件的逻辑回归分析方法进行,该模型构建以不同癌前病变早期分期为因变量,以不同相关因子组合为自变量组合,假设因变量服从伯努利分布,采用sigmod函数作为判别函数,最后给出相应的概率值,通过采用0.5的阈值进行二分类判别。
最终以roc曲线的auc值为评估指标,得到不同组合方式构建模型中auc值最佳的模型,为待训练模型。
具体方法如下:
s31:将数据集分为训练集(80%)和验证集(20%),对训练集通过不同因子组合进行模型构建。具体如下表2所示。
表2.各数据集(训练集)情况及模型构建结果
s32:将构建的模型通过验证集进行验证,比较不同组合构建的模型的准确性(以roc曲线auc值为评估指标)。
s33:选择同一数据集不同因子组合构建模型中auc值最好的组合(vl+bv),以该最优因子组合的逻辑回归模型为待训练模型,进行下一步机器学习算法模型构建。
s4:以上述步骤得到的待训练模型,以xgboost,随机森林,决策树,神经网络或svm算法进行机器学习训练,以roc曲线的auc值为评估指标,得到不同算法模型中auc值最佳的模型,即得宫颈癌癌前早期病变阶段诊断模型。
具体方法如下:
s41:以上述步骤得到的待训练模型,将均衡处理后的数据集按80%,20%比例拆分为训练集和验证集,分别通过xgboost,随机森林,决策树,神经网络或svm算法进行机器学习训练。使用rattler包进行分析,采用上述获得的最优因子组合(vl+bv)进行建模。
s42:通过训练集得到模型后,采用验证集进行效果评估,以roc曲线auc值,阳性预测值,阴性预测值为评估指标,选择auc值最高的模型构建方法(xgboost)的结果作为最终构建模型,结果见表3。
表3.模型训练结果
s43:以上述roc曲线的auc值为评估指标,得到不同算法模型中auc值最佳的模型,即得宫颈癌癌前早期病变阶段诊断模型。具体为采用xgboost算法进行机器学习训练所得模型。在以xgboost算法进行机器学习训练时,设置树的最大深度为6,迭代次数为50,学习速率为0.3,然后根据训练集数据进行建模。
本实施例建立得到的宫颈癌癌前早期病变阶段诊断模型,通过大样本量进行训练和验证,以smote-regular方法对数据进行均衡处理,再以pv病毒载量和阴道炎情况为因子组合方式,进行多因素逻辑回归模型构建,以xgboost算法进行机器学习训练得到。
该模型可用于宫颈癌癌前早期病变阶段的诊断,以hpv病毒载量(vl)和阴道炎(bv)情况为因子,输入模型中,以算法xgboost进行结果预测,预测结果为正常、ascus、asc-h、lsil或hsil。
实施例2
一种宫颈癌癌前早期病变阶段诊断模型验证。
收集新数据集,具体内容同实施例1中s11步骤,作为测试集,其流程如图3所示。
将新收集的数据以实施例1得到的宫颈癌癌前早期病变阶段诊断模型进行结果预测,比较不同癌前病变分期的预测概率值,选择预测概率值最高的为疾病分期诊断结果,结果见表4。针对不同疾病分期的模型的roc曲线见图4。
表4.
从上述结果可以看出,本发明的宫颈癌癌前早期病变阶段诊断模型,用于宫颈癌癌前早期病变阶段进行预测评估,具有结果准确性高,对患者无额外负担,数据易采集的优势。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!