基于法定诊断标准智能识别传染病的系统、设备及存储介质的制作方法
本发明涉及传染病防治技术领域,尤其涉及一种基于法定诊断标准智能识别传染病的系统、设备及存储介质。
背景技术:
传染病(infectiousdiseases)是由各种病原体引起的能在人与人、动物与动物或人与动物之间相互传播的一类疾病。目前国家法定管理的传染病已由原来的37种增为39种。其中:甲类2种、乙类26种、丙类11种。甲类传染病包括鼠疫、霍乱等;乙类传染病包括传染性非典型肺炎、艾滋病、病毒性肝炎等;丙类传染病包括肺结核、血吸虫病、丝虫病、包虫病、麻风病、流行性感冒、流行性腮腺炎、风疹、新生儿破伤风、急性出血性结膜炎、除霍乱、痢疾、伤寒和副伤寒以外的感染性腹泻病等。
法定传染病诊断标准主要参考《中华人民共和国传染病防治法》规定管理的传染病诊断标准(试行)目录。传统的法定传染病识别方法主要是发现或者采集到患者某些症状特征信息后,根据国家公布的诊断标准,如果发现符合或者基本符合法定诊断标准某一特征信息,进行人工进行比对、筛查,费时费力不说,有些模棱两可、似是而非的特征信息,有时让人无法判断或者做出正确的决定,往往会造成大量信息损失,从而导致漏报与错报。因此,需要一种基于法定诊断标准智能识别传染病的辅助诊断系统,来实现病例精准识别、智能认知和辅助诊断。
技术实现要素:
有鉴于此,本发明提出了一种基于法定诊断标准智能识别传染病的系统,用于解决传统人工进行传染病比对筛查可能导致漏报与错报的问题,帮助医护工作人员进行传染病辅助诊断。
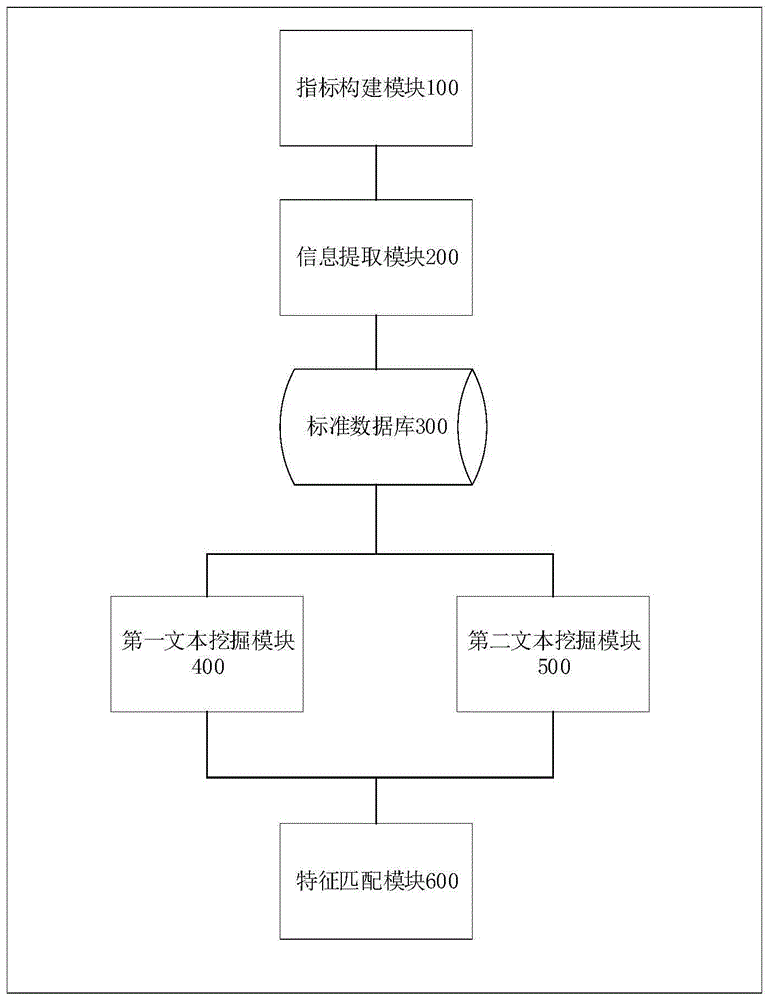
本发明第一方面,提出一种基于法定诊断标准智能识别传染病的系统,所述系统包括:
指标构建模块:用于根据法定传染病诊断标准绘制和构建法定传染病病例分类以及诊断标准的具体指标;
信息提取模块:用于根据法定传染病病例分类以及诊断标准的具体指标,提取每一个传染病病例分类所包含的主要特征信息;
标准数据库:用于建立各种传染病以及同一种传染病不同病例分类类型诊断标准与所对应的主要特征信息之间关联关系的标准数据库;
第一文本挖掘模块:用于对所述标准数据库的主要特征信息进行文本挖掘,进行权重计算及第一核心特征词提取,构建向量空间模型,得到各个传染病病例分类的主要特征信息对应的第一特征向量集合;
第二文本挖掘模块:用于构建基于条件互信息的特征选择模型,采用tf-idf函数对所述标准数据库的主要特征信息进行文本挖掘,根据主要特征信息的词条和病例分类之间的相关度进行权值计算,并选取第二核心特征词,构建向量空间模型,得到各个传染病病例分类的主要特征信息对应的第二特征向量集合;
特征匹配模块:用于分别计算待分类文本与所述第一特征向量集合中元素之间的余弦相似度;分别计算待分类文本与所述第二特征向量集合元素之间的互信息相关度;根据所述余弦相似度和互信息相关度对待分类文本进行病例分类。
优选的,所述第一文本挖掘模块中,采用tf-idf函数计算主要特征信息的词条权重:
设d为一个包含m个文档的档集合,di为第i个文档的特征向量,则有:d={d1,d2,…,dm},di=(di1,di2,…,din),i=1,2,…,m,其中dij为文档di中第j个词条tj的权值:
上式中i=1,2,…,m;j=1,2,…,n,n是文档数据库中文档总数,nj是文档数据库含有词条tj的文档数目。
优选的,所述特征匹配模块模块中,所述根据主要特征信息的词条和病例分类之间的相关度进行权值计算,并选取第二核心特征词具体为:
计算病例分类中包含的主要特征信息的各个词条和病例分类之间的互信息相关度,公式为:
其中,a为在病例分类类别c中词条t出现的文档数;b为在除了病例分类类别c的其他类别中词条t出现的文档数;c为在病例分类类别c中词条t未出现的文档数;n为所有类别中的文档数的总和;如果共有m个类别则每个词条将得到m个相关度值;
取所述m个值的平均值作为每个词条的权值,对词条按照词频从低到高排序,去除只在单个类别出现且词频低于预设词频阈值的词,对剩余词条按照权值从高到低排序,取权值高于预设权值阈值的词作为第二核心特征词。
优选的,所述特征匹配模块模块中,所述根据所述余弦相似度和互信息相关度对待分类文本进行病例分类具体为:
对于每一病例分类类别,取余弦相似度与互信息相关度中的最大值作为对应病例分类类别的输出概率值,设置第一概率阈值,取概率值大于所述第二概率阈值的类别作为识别推荐结果。
优选的,所述特征匹配模块模块中,所述根据所述余弦相似度和互信息相关度对待分类文本进行病例分类具体为:
对于每一病例分类类别,取余弦相似度与相关度的加权之和作为对应病例分类类别的输出概率值,设置第二概率阈值,取概率值大于所述第二概率阈值的类别作为识别推荐结果。
本发明第二方面,公开一种电子设备,包括:至少一个处理器、至少一个存储器、通信接口和总线;
其中,所述处理器、存储器、通信接口通过所述总线完成相互间的通信;
所述存储器存储有可被所述处理器执行的程序指令,所述处理器调用所述程序指令,以实现如本发明第一方面所述的系统。
本发明第三方面,公开一种计算机可读存储介质,所述计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机实现本发明第一方面所述的系统。
本发明的相对于现有技术具有以下有益效果:
1)本发明基于现行的传染病法定诊断标准,建立了不同传染病以及同一种传染病不同病例分类类型诊断标准与所对应的主要特征信息之间关联关系的标准数据库,所述标准数据库为各类传染病及同一种传染病不同病例分类类型提供了全面的标准特征信息库,为各类传染病辅助诊断与准确识别提供了依据;
2)基于所述标准数据库,本发明将向量空间模型应用到传染病诊断标准的特征提取之中,可以有效解决类型分类和特征信息提取这两个重要的问题,极大地减少特征信息损失,提高了智能识别与诊断的准确率;
3)本发明分别通过余弦相似度、互信息相似度及其结合结合来进行智能识别,通过多方面交叉对比的方式进一步提高诊断准确率,为医护人员提供了可靠的辅助诊断结果,减少漏报与错报。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的系统结构示意图。
具体实施方式
下面将结合本发明实施方式,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
请参阅图1,本发明提出一种基于法定诊断标准智能识别传染病的系统,所述系统包括:
指标构建模块:用于根据法定传染病诊断标准绘制和构建法定传染病病例分类以及诊断标准的具体指标;
信息提取模块:用于根据法定传染病病例分类以及诊断标准的具体指标,提取每一个传染病病例分类所包含的主要特征信息;
标准数据库:用于建立各种传染病以及同一种传染病不同病例分类类型诊断标准与所对应的主要特征信息之间关联关系的标准数据库;
第一文本挖掘模块:对所述标准数据库的主要特征信息进行文本挖掘,采用tf-idf进行权重计算及第一核心特征词提取,构建向量空间模型,得到各个传染病病例分类的主要特征信息对应的第一特征向量集合;
第二文本挖掘模块:构建基于条件互信息的特征选择模型,对所述标准数据库的主要特征信息进行文本挖掘,根据主要特征信息的词条和病例分类之间的相关度进行权值计算,并选取第二核心特征词,构建向量空间模型,得到各个传染病病例分类的主要特征信息对应的第二特征向量集合;
特征匹配模块:分别计算待分类文本与所述第一特征向量集合中元素之间的余弦相似度;分别计算待分类文本与所述第二特征向量集合元素之间的互信息相关度;根据所述余弦相似度和互信息相关度对待分类文本进行病例分类。
下面结合具体传染病类别对本发明的实施方案做进一步说明。
通过指标构建模块绘制和构建法定传染病病例分类以及诊断标准的具体指标。法定传染病诊断标准病例类型的准确分类决定了传染病识别系统能否快速、准确地检索各类传染病的特征,从而提升匹配速度。比如,以法定传染性非典型肺炎(试行)诊断标准为例:1、流行病学史。这里面要注意两点:1.1与发病者有密切接触史或属受传染的群体发病者之一或有明确传染他人的证据;1.2发病前:两周内曾到过或居住于报告有传染性非典型肺炎病人并出现继发感染疫情的区域;2、症状与体征:是不是起病急、以发热为首发症状、体温一般38℃、偶有畏寒,可伴有头痛、关节酸痛、肌肉酸痛、乏力、腹泻,常无上呼吸道卡他症状,可有咳嗽,多为干咳、少痰,偶有血丝痰,可有胸闷,严重者出现呼吸加速、气促或明显呼吸窘迫。肺部体征不明显,部分病人可闻少许湿罗音、或有肺实变体征。注意:有少数病人不以发热为首发症状,尤其是有近期手术史或有基础疾病的病人;3、实验室检查结果:外周血白细胞计数一般不升高、或降低、常有淋巴细胞计数减少;4、胸部x线检查结果:肺部有不同程度的片状、斑片状浸润性阴影或呈网状改变、部分病人进展迅速、呈大片状阴影、常为多叶或双侧改变、阴影吸收消散较慢、肺部阴影与症状体征可不一致。若检查结果阴性,1-2天后应予复查;5、抗菌药物治疗无明显效果。
根据上述法定诊断标准,可以确定法定传染性非典型肺炎(试行)诊断标准分类类型:1)、疑似诊断标准:符合上述1.1+2+3条或1.2+2+4条或2+3+4条;2)、临床诊断标准:符合上述1.1+2+4条及以上或1.2+2+4+5条或1.2+2+3+4条;3)、医学观察诊断标准:符合上述1.2+2+3条。4)、鉴别诊断:临床上要注意排除上感、流感、细菌性或真菌性肺炎、艾滋病合并肺部感染、军团病、肺结核、流行性出血热、肺部肿瘤、非感染性间质性疾病、肺水肿、肺不张、肺栓塞、肺嗜酸性粒细胞浸润症、肺血管炎等临床表现类似的呼吸系统疾患;5)、重症非典型肺炎诊断标准:符合下列标准中的1条即可诊断为重症“非典型肺炎”:a、呼吸困难、呼吸频率>30次/分;b、低氧血症、在吸氧3-5升/分条件下动脉血氧分压pao2<70mmhg或脉搏容积血氧饱和度spo2<93%或已可诊为急性肺损伤ali或急性呼吸窘迫综合征ards;c、多叶病变且病变范围超过1/3或x线胸片显示48小时内病灶进展>50%;d、休克或多器官功能障碍综合征mods;e、具有严重基础性疾病或合并其他感染或年龄>50岁。
确定法定传染病病例分类以及诊断标准的具体指标后,通过信息提取模块提取每一个传染病病例分类所包含的主要特征信息,作为识别认证或区分同一种传染病不同病例分类标准的最核心的特征信息。
每一个传染病病例分类的核心特征信息,作为认证或区分传染病的最核心的细节特征,在传染病识别系统中起着至关重要的作用。比如,根据流行病学史、临床表现及实验室检查结果,排除其他疾病后,可以作出人禽流感的诊断。那么,人感染高致病禽流感病例分类所包含的主要特征信息分别为:1、医学观察病例:有流行病学史,1周内出现临床表现者;与人禽流感患者有密切接触史,在1周内出现临床表现者;2、疑似病例:有流行病学史和临床表现,患者呼吸道分泌物标本采用甲型流感病毒和h亚型单克隆抗体抗原检测阳性者;3、确诊病例:有流行病学史和临床表现,从患者呼吸道分泌物标本中分离出特定病毒或采用rt-pcr法检测到禽流感h亚型病毒基因,且发病初期和恢复期双份血清抗禽流感病毒抗体滴度有4倍或以上升高者。
再比如,法定霍乱诊断标准最核心的特征信息包括:1、疑似霍乱诊断标准特征信息:a、凡有典型临床症状,如剧烈腹泻、水样便(黄水样、清水样、米泔样或血水样)、伴有呕吐、迅速出现严重脱水、循环衰竭及肌肉痉挛(特别是腓肠肌)的首发病例,在病原学检查尚未肯定前;b、霍乱流行期间有明确接触史(如同餐、同住或护理者等),并发生泻吐症状而无其他原因可查者。具有上述项目之一者诊断为疑似霍乱;2、确定诊断标准特征信息:a、凡有腹泻症状粪便培养01群或0139群霍乱弧菌阳性;b、霍乱流行期间的疫区内凡有霍乱典型症状(见1a),粪便培养01群和0139群霍乱弧菌阴性,但无其他原因可查者;c、在流行期间的疫区内有腹泻症状,作双份血清抗体效价测定,如血清凝集试验呈4倍以上或杀弧菌抗体测定呈8倍以上增长者;d、在疫源检查中,首次粪便培养检出01群或0139群霍乱弧菌前后各5天内有腹泻症状者;临床诊断:具备b;确诊病例:具备a或c或d;
根据各种传染病以及同一种传染病不同病例分类类型诊断标准与所对应的主要特征信息之间关联关系建立标准数据库,所述标准数据库具有全面化、标准化的特点,将作为传染病辅助诊断与识别的标准特征信息库。
本发明分别通过第一文本挖掘模块和第二文本挖掘模块对对上述标准数据库的特征信息进行文本挖掘,构建向量空间模型。
现有的特征信息提取算法通常需要一系列有先验知识作为支撑的预处理步骤,这些预处理步骤往往会造成大量信息损失,从而导致细节点(特征信息)的漏提取与错提取,进而影响整个系统识别的准确率。为克服传统算法的上述缺陷,本发明将向量空间模型应用到传染病诊断标准的特征提取之中,可以有效解决类型分类和特征信息提取这两个重要的问题,极大地减少特征信息损失,提高了智能识别诊断的准确率。具体方式为:用特征词条(t1,t2,…tn)及其权值ωi代表数据库中一个病例分类类型诊断标准所对应的主要特征信息,组成空间向量,在进行信息匹配时,使用这些特征项评价未知文本与数据库中空间向量的相关程度。
所述第一文本挖掘模块采用tf-idf进行权重计算及第一核心特征词提取,构建向量空间模型,得到各个传染病病例分类的主要特征信息对应的第一特征向量集合;该第一特征向量集合中,每一个特征向量代表一个传染病病例分类的诊断标准和对应的主要特征信息。
设d为一个包含m个文档的档集合,di为第i个文档的特征向量,则有:d={d1,d2,…,dm},di=(di1,di2,…,din),i=1,2,…,m,其中dij为文档di中第j个词条tj的权值:
上式中i=1,2,…,m;j=1,2,…,n,n是文档数据库中文档总数,nj是文档数据库含有词条tj的文档数目。
计算得到词条权重后,根据权重大小筛选出第一核心特征词,将第一核心特征词和对应的权重组成构建向量空间模型。通过上述的向量空间模型,文本数据就转换成了计算机可以处理的结构化数据,两个文档之间的相似性问题转变成了两个向量之间的相似性问题。
假设标准数据库的第一特征向量集合中某一类别对应的特征向量为vk,待分类文本的特征向量为v0,则两者的相似程度可用两向量的夹角余弦
所述第二文本挖掘模块构建基于条件互信息的特征选择模型,对所述标准数据库的主要特征信息进行文本挖掘;根据主要特征信息的词条和病例分类之间的相关度进行权值计算,并选取第二核心特征词,构建向量空间模型,得到各个传染病病例分类的主要特征信息对应的第二特征向量集合;
以某一传染病病例分类为例:选取疑似诊断标准、临床诊断标准、确定诊断标准、医学观察诊断标准、重症诊断标准以及诊断鉴别标准等病例分类的主要特征信息语料,通过互信息来选取词来建立空间向量模型。
首先计算病例分类中包含的主要特征信息的各个词条和病例分类之间的互信息相关度,公式为:
其中,a为在病例分类类别c中词条t出现的文档数;b为在除了病例分类类别c的其他类别中词条t出现的文档数;c为在病例分类类别c中词条t未出现的文档数;n为所有类别中的文档数的总和;如果共有m个类别则每个词条将得到m个相关度值;
取所述m个值的平均值作为每个词条的权值,对词条按照词频从低到高排序,去除只在单个类别出现且词频低于预设词频阈值的词,对剩余词条按照权值从高到低排序,取权值高于预设权值阈值的词作为第二核心特征词。根据第二核心特征词和对应的权值构建特征向量。
所述特征匹配模块根据第一文本挖掘模块和第二文本挖掘模块的结果进行特征匹配,分别计算待分类文本与所述第一特征向量集合中元素之间的余弦相似度;分别计算待分类文本与所述第二特征向量集合元素之间的互信息相关度;用互信息来衡量某个特征信息和特定类别的相关性,如果互信息越大,那么特征信息和这个类别的相关性越大,属于该类别的概率就大。反之也成立。然后根据所述余弦相似度和互信息相关度对待分类文本进行病例分类。
所述根据所述余弦相似度和互信息相关度对待分类文本进行病例分类的具体方式有多种选择:
1.对于每一病例分类类别,取余弦相似度与相关度的加权之和作为对应病例分类类别的第一输出概率值,对各输出概率值降序排列,设置第二概率阈值,取概率值大于所述第二概率阈值的类别作为识别推荐结果。
2.对于每一病例分类类别,取余弦相似度与互信息相关度中的最大值作为对应病例分类类别的第二输出概率值,对各输出概率值降序排列,设置第一概率阈值,取概率值大于所述第二概率阈值的类别作为识别推荐结果。
所述识别推荐结果有一种或多种,按照降序排列,通过多种方式识别,交叉对比选取相似度较高的类别或者两种方式结合的方式作为推荐诊断结果,为医护人员提供多方位的辅助诊断参考,对一些模棱两可、似是而非的特征信息,有时让人无法判断或者做出正确的决定的信息,通过高效的特征信息匹配做出精准的辅助诊断,帮助医护人员做出正确判断,减少漏报与错报。
本发明还公开一种电子设备,包括:至少一个处理器、至少一个存储器、通信接口和总线;
其中,所述处理器、存储器、通信接口通过所述总线完成相互间的通信;
所述存储器存储有可被所述处理器执行的程序指令,所述处理器调用所述程序指令,以实现本发明前述的基于法定诊断标准智能识别传染病的系统,包括指标构建模块、信息提取模块、标准数据库、第一文本挖掘模块、第二文本挖掘模块、特征匹配模块。
本发明还公开一种计算机可读存储介质,所述计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机实现本发明实施例所述的全部系统或部分系统。例如包括指标构建模块、信息提取模块、标准数据库、第一文本挖掘模块、第二文本挖掘模块、特征匹配模块。所述存储介质包括:u盘、移动硬盘、只议存储器(rom,read—onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所描述的系统实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位千一个地方,或者也可以分布到多个网络单元上。可以根据实际的衙要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
以上所述仅为本发明的较佳实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!