指示NTRK致癌融合的候选标志的鉴定的制作方法
指示ntrk致癌融合的候选标志的鉴定
1.本发明涉及鉴定患者数据内指示ntrk致癌融合的一个或多个候选标志。本发明的主题是用于从与受试患者相关的患者数据确定概率值的计算机实施的方法、系统和非暂时性计算机可读存储介质,所述概率值指示受试患者患有由神经营养受体酪氨酸激酶(ntrk)基因突变引起的癌症的概率。
2.原肌球蛋白受体激酶(trk)受体家族包含三种被称为trk a、b和c(trka、trkb和trkc)受体的跨膜蛋白,分别由ntrk1、ntrk2和ntrk3基因编码。
3.这些受体酪氨酸激酶的野生型在人神经元组织中表达,并通过神经营养蛋白的激活在神经系统的生理发育和功能中发挥重要作用。
4.与其他基因相似,ntrk基因也会发生改变,包括融合。临床前研究表明,trk融合蛋白通过介导组成型细胞增殖和存活来促进肿瘤发生。
5.ntrk致癌融合产生于染色体内或染色体间重排,将ntrk含激酶结构域的3’区与ntrk基因配偶体(gene partner)的5’区并置。
6.ntrk致癌融合是在各种类型的先天性和获得性癌症中观察到的罕见但复发性事件(参见例如ed s.kheder,david s.hong:emerging targeted therapy for tumors with ntrk fusion proteins,clincancerres.aacrjournals.org,2018,doi:10.1158/1078
‑
0432.ccr
‑
18
‑
1156的表2)。
7.这些遗传异常最近已成为癌症治疗的靶点,因为已开发出新化合物,它们是组成型活性重排蛋白的选择性抑制剂。在过去的几年里,已经开发了各种靶向trk家族成员的抑制剂,并在临床试验中进行了测试(参见例如ed s.kheder,david s.hong:emerging targeted therapy for tumors with ntrk fusion proteins,clincancerres.aacrjournals.org,2018,doi:10.1158/1078
‑
0432.ccr
‑
18
‑
1156的表3)。具体而言,拉罗替尼(larotrectinib)和恩曲替尼(entrectinib)已成为强效、安全和有前景的trk抑制剂。
8.开发这些抑制剂及其作为治疗剂的用途中的主要挑战是每个单一肿瘤组织学中的低发生率。
9.下一代测序提供了检测ntrk基因融合的精确方法(m.l.metzker:sequencing technologies
‑
the next generation,nat rev genet.2010,11(1),第31
‑
46页)。然而,对每个患者进行基因分析比较昂贵,且由于ntrk致癌融合的发生率较低,效率低下。
10.免疫组织化学提供了检测ntrk基因蛋白表达的常规方法(例如j.f.hechtman等人:pan
‑
trk immunohistochemistry is an efficient and reliable screen for the detection of ntrk fusions,am j surg pathol.2017,41(11),第1547
–
1551页;https://www.prnewswire.com/news
‑
releases/roche
‑
launches
‑
first
‑
ivd
‑
pan
‑
trk
‑
immunohistochemistry
‑
assay
‑
300755647.html)。然而,进行免疫组织化学需要技能,并且蛋白表达和基因融合状态之间的相关性并非微不足道。解读ihc结果需要经过培训和认证的医学专业病理学家的技能。类似的实际挑战也适用于其他分子试验,如fish(荧光原位杂交)或pcr(聚合酶链式反应)。
11.本发明的主题解决了这个问题。
12.在第一方面,本发明提供了一种用于鉴定与受试患者相关的患者数据内指示ntrk致癌融合的一个或多个候选标志的计算机实施的方法,该方法包括:
13.‑
接收患有癌症的受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
14.‑
将所述患者数据输入到预测模型中,所述预测模型经由机器学习利用一组训练数据进行了训练,所述预测模型被配置为用于鉴定所述患者数据内ntrk致癌融合的一个或多个特征;
15.‑
从所述预测模型接收概率值作为输出,所述概率值指示所述受试患者患有由ntrk致癌融合所引起的癌症的概率。
16.在第二方面,本发明提供了一种系统,包括:
17.处理器;和
18.存储应用程序的存储器,所述应用程序被配置为当由所述处理器执行时,执行用于鉴定与受试患者相关的患者数据内指示ntrk致癌融合的一个或多个候选标志的操作,所述操作包括:
19.‑
接收患有癌症的受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
20.‑
将所述患者数据输入到预测模型中,所述预测模型经由机器学习利用一组训练数据进行了训练,所述预测模型被配置为用于鉴定所述患者数据内ntrk致癌融合的一个或多个特征;
21.‑
从所述预测模型接收概率值作为输出,所述概率值指示所述受试患者患有由ntrk致癌融合所引起的癌症的概率。
22.在第三方面,本发明提供了一种包括处理器可执行指令的非暂时性计算机可读存储介质,利用所述处理器可执行指令来执行用于鉴定与受试患者相关的患者数据内指示ntrk致癌融合的一个或多个候选标志的操作,所述操作包括:
23.‑
接收患有癌症的受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
24.‑
将所述患者数据输入到预测模型中,所述预测模型经由机器学习利用一组训练数据进行了训练,所述预测模型被配置为用于鉴定所述患者数据内ntrk致癌融合的一个或多个特征;
25.‑
从所述预测模型接收概率值作为输出,所述概率值指示所述受试患者患有由ntrk致癌融合所引起的癌症的概率。
26.下面将更具体地阐述本发明,而不区分本发明的主题。相反,以下说明旨在类似地应用于本发明的所有主题,而不管它们出现在哪个上下文中。
27.本发明用于通过预测模型从与受试患者相关的患者数据确定概率值,所述概率值指示受试患者患有由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的癌症的概率。
28.术语“突变”本文中是指导致具有改变的氨基酸序列的原肌球蛋白受体激酶(trk)受体表达的任何基因改变,包括dna重排、核苷酸取代、添加和/或缺失。具体而言,该术语指将ntrk(ntrk1,ntrk2,ntrk3)的包含激酶结构域的3’区与ntrk的基因配偶体的5’区并置的
fibrosarcoma by comprehensive genomic profiling reveals an lmna
‑
ntrk1 gene fusion responsive to crizotinib.j natl cancer inst.2016;108(1))。
64.对于ntrk2基因,描述了以下与头颈部鳞状细胞癌相关的基因融合配偶体:
65.‑
pan3(聚腺苷酸(poly(a))特异性核糖核酸酶亚基)(stransky n等人,landscape of kinase fusions in cancer.nat commun.2014;5:4846.)。
66.对于ntrk3基因,描述了以下与中胚层肾瘤癌相关的基因融合配偶体:
67.‑
etv6(ets变体6)(anderson j等人,expression of etv6
‑
ntrk in classical,cellular and mixed subtypes of congenital mesoblastic nephroma.histopathology.2006;48(6):748
‑
53)。
68.对于ntrk3基因,描述了以下与胃肠道间质瘤癌相关的基因融合配偶体:
69.‑
etv6(ets变体6)(brenca m等人,transcriptome sequencing identifies etv6
‑
ntrk3 as a gene fusion involved in gist.j pathol.2016;238(4):543
‑
9.,shi e等人,fgfr1 and ntrk3 actionable alterations in"wild
‑
type"gastrointestinal stromal tumors.j transl med.2016;14(1):339)。
70.根据患者数据确定指示癌症由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的概率的概率值。患者数据包括受试患者的肿瘤组织的至少一个组织病理学图像。
71.可通过活组织检查从受试患者获得至少一个组织病理学图像。
72.在本发明的一个优选实施方案中,所述至少一个组织病理学图像是受试患者的肿瘤组织的显微图像。放大因子优选在10至60的范围内,更优选在20至40的范围内,而例如“20”的放大因子意味着肿瘤组织中0.05mm的距离对应于图像中1mm的距离(0.05mm
×
20=1mm)。
73.在本发明的一个优选实施方案中,所述至少一个组织病理学图像是全玻片图像。
74.在本发明的一个优选实施方案中,所述至少一个组织病理学图像是染色的肿瘤组织样本的图像。一种或多种染料可用于创建染色图像。优选的染料是苏木精和曙红。
75.在本发明的一个优选实施方案中,所述至少一个组织病理学图像是来自染色的肿瘤组织样本的组织病理学组织玻片的全玻片图像。
76.科学文献和教科书中广泛描述了创建组织病理学图像,特别是染色的全玻片显微镜图像的方法(参见例如s.k.suvarna等人:bancroft'stheory and practice of histological techniques,8
th ed.,elsevier 2019,isbn 978
‑0‑
7020
‑
6864
‑
5;a.f.frangi等人:medical image computing and computer assisted intervention
‑
miccai 2018,21
st international conference granada,spain,2018proceedings,part ii,isbn978
‑
030
‑
00933
‑
5;l.c.junqueira等人:histologie,springer 2001,isbn:978
‑
354
‑
041858
‑
0;n.coudray等人:classification and mutation prediction from non
‑
small cell lung cancer histopathology images using deep learning,nature medicine,vol.24,2018,第1559
‑
1567页),其内容通过引用完全并入本说明书。
77.所述至少一个组织病理学图像是数字图像。数字图像是二维图像的数字表示,通常为二进制。根据图像分辨率是否是固定的,它可以是矢量或光栅类型。在本发明的一个优选实施方案中,至少一个组织病理学图像是在3个图像通道中保持rgb颜色值的光栅图像。rgb颜色模型是一种加色模型,其中红色(r)、绿色(g)和蓝色(b)以各种方式相加,以再现各
种颜色。或者,至少一个组织病理学图像采用具有明度、亮度和颜色色度值的色彩空间像素(yuv)格式。其他形式也是可以想到的。
78.优选地,至少一个组织病理学图像的记录像素数(像素分辨率)在1,000
×
1,000像素至500,000
×
500,000像素的范围内,更优选地在10,000
×
10,000像素至100,000至100,000像素的范围内。图像可以是正方形、矩形或任何其他形状。
79.在一个优选的实施方案中,患者数据包括多于一个的组织病理学图像。可以获得例如不同放大率的组织病理学图像(参见例如wo2018/156133,其内容通过引用完全并入本文)。
80.在一个优选的实施方案中,将至少一个组织病理学图像分割成肿瘤区域和健康区域。肿瘤区域显示肿瘤组织。健康区域显示健康组织。优选地,使用经训练的卷积神经网络来自动完成分割(参见例如n.coudray:classification and mutation prediction from non
‑
small cell lung cancer histopathology images using deep learning,nature medicine vol 24,1560,2018,第1559
–
1567页)。
81.一方面根据用于训练和验证预测模型以及用于预测目的的组织病理学图像的大小,另一方面根据可用的计算机能力,可以将图像划分为较小的优选非重叠的图块。然后优选地使用图块而非整个图像来执行预测模型的训练和验证以及概率值的预测。优选地,仅使用显示肿瘤区域的那些图块。
82.可用于预测概率值的额外的患者数据是患者的解剖或生理数据,例如关于患者的身高和体重、性别、年龄、生命参数(例如血压、呼吸频率和心率)、肿瘤分级、icd
‑
9分类、肿瘤的氧合、肿瘤的转移程度、血细胞计数值肿瘤指示值(如pa值)的信息、关于创建组织病理学图像的组织的信息(例如组织类型、器官)、其他的症状、病史等。此外,可以使用文本挖掘方法将组织病理学图像的病理报告用于预测概率值。此外,不涵盖trk基因序列的下一代测序原始数据集可用于预测概率值。
83.患者数据可以例如从一个或多个数据库收集,或者由用户手动输入到根据本发明的系统中。
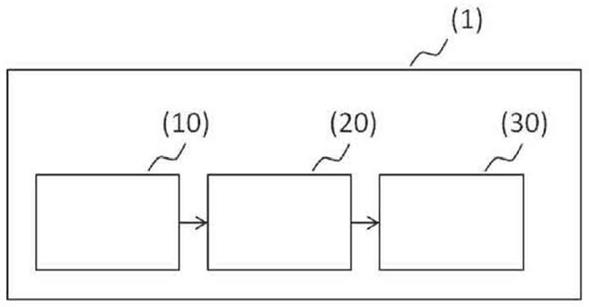
84.将患者数据输入预测模型。预测模型使用一种或多种机器学习算法。机器学习算法是一种可以基于一组训练数据进行学习的算法。可将机器学习算法的实施方案设计成对数据集内的高级抽象进行建模。例如,图像识别算法可用于确定给定输入属于几个类别中的哪一个;回归算法可以输出给定输入的数值。
85.预测模型可以是或包括人工神经网络。本发明优选地使用包括至少三层处理元件的人工神经网络:具有输入神经元(节点)的第一层、具有至少一个输出神经元(节点)的第n层和n
‑
2个内层,其中n是大于2的自然数。
86.在这样的网络中,输出神经元用于预测至少一个概率值,该概率值指示受试患者患有由ntrk致癌融合所引起的癌症的概率。输入神经元用于接收患者数据作为输入值。通常,至少一个组织病理学图像的每个像素都有一个输入神经元。对于以上所列的额外患者数据可以有额外的输入神经元。
87.这些层的处理元件以预定模式互连,其间具有预定的连接权重。该网络之前已经过训练,以鉴定患者数据内指示ntrk癌基因融合的一个或多个候选标志。可以利用包括患者数据的一组训练数据来进行训练,对于所述患者数据,已经通过其他医学研究例如肿瘤
组织的遗传分析来验证或排除了指示ntrk致癌融合的候选标志。
88.当训练时,处理元件之间的连接权重包含关于患者数据(输入)和概率值(输出)之间的关系的信息,其可用于基于他/她的患者数据来预测新的受试患者的概率值。
89.每个网络节点都表示来自先前节点的输入的加权和的简单计算以及非线性输出函数。网络节点的组合计算将输入与输出相关联。
90.可以为每个属性测量开发单独的网络,或者可以将属性组包含在单个网络中。优选地,在算法结束时组合患者数据的不同维度。
91.训练估计网络权重,允许网络计算接近测量输出值的输出值。可以使用监督训练方法,其中输出数据用于指导网络权重的训练。用小的随机值或用先前部分训练的网络的权重对网络权重进行初始化。将训练数据输入应用于网络,并为每个训练样本计算输出值。将网络输出值与测量的输出值进行比较。应用反向传播算法,在减少测量输出与计算输出之间误差的方向上校正权重值。重复该过程,直到不能进一步减小误差或直到达到预定的预测精度。
92.可以采用交叉验证方法将数据分为训练数据集和验证数据集。训练数据集用于网络权重的反向传播训练。验证数据集用于验证经训练的网络是否泛化,以做出良好的预测。可以将最佳网络权重集作为最能预测测试数据集输出的网络权重集。类似地,改变网络隐藏节点的数目并确定该数据集表现最佳的网络可以优化隐藏节点的数目。
93.前向预测使用经训练的网络来计算概率值,所述概率值指示患者患有由ntrk致癌融合所引起的癌症的概率。将患者数据输入经训练的网络。通过网络进行前馈计算以预测输出属性值。可以将预测的测量值与属性目标值或容差进行比较。由于本发明的方法基于属性值的历史数据,所以使用这种方法对属性值的预测通常具有接近经验数据的误差的误差,使得预测通常与验证实验一样准确。
94.在本发明的一个优选实施方案中,预测模型是或包括卷积神经网络(cnn)。
95.cnn是一类深度神经网络,最常用于分析视觉图像。cnn包括具有输入神经元的输入层、具有至少一个输出神经元的输出层以及输入层与输出层之间的多个隐藏层。
96.cnn的隐藏层通常由卷积层、relu(修正线性单元)层(即,激活函数)、池化层、全连接层与归一化层组成。
97.将cnn输入层中的节点组织成一组“过滤器”(特征检测器),每组过滤器的输出被传播到网络的连续层中的节点。cnn的计算包括对每个过滤器应用卷积数学运算来产生该过滤器的输出。卷积是一种特殊的数学运算,由两个函数执行,产生第三个函数,该第三个函数是两个原始函数之一的经修改型式。在卷积网络术语中,卷积的第一个函数可以称为输入,而第二个函数可以称为卷积核。输出可称为特征图。例如,卷积层的输入可以是限定输入图像的各种颜色分量的多维数据阵列。卷积核可以是多维参数阵列,其中参数通过神经网络的训练过程来适配。
98.通过对cnn的分析,人们可以在分析训练数据时揭示数据中不明显且被cnn优选使用(即,更强加权)的模式。这种可解释的ai方法有助于产生对预测模型性能的信任。
99.本发明可用于
100.a)检测除了正在接受训练的那些适应症之外的其他适应症中的ntrk融合事件(即,在甲状腺数据集上训练的算法可用于肺癌数据集)
101.b)检测涉及其他trk家族成员的ntrk融合事件(即,在ntrk1、ntrk3融合上训练的算法也可用于预测ntrk2融合)
102.c)检测涉及其他融合配偶体的ntrk融合事件(即,在lmna融合数据集上训练的算法也可用于tpm3融合数据集)
103.d)发现新的融合配偶体(即,在已知融合事件上训练的算法可以预测新数据集中的融合,该新数据集中的融合随后通过分子试验证实涉及ntrk家族成员的尚未描述的融合配偶体)。
104.预测模型产生指示患者患有由ntrk致癌融合所引起的癌症的概率的概率值。概率值可以输出给用户和/或存储在数据库中。概率值可以是0至1范围内的实数,而概率值0表示癌症不可能是由ntrk致癌融合引起的,概率值1表示癌症无疑是由ntrk致癌融合引起的。概率值也可以用百分比表示。
105.在本发明的一个优选实施方案中,将概率值与一个预定阈值进行比较。在概率值低于阈值的情况下,患者患有由ntrk致癌融合所引起的癌症的概率低;不指示用trk抑制剂治疗患者;为了确定癌症的原因,还需要进一步的研究。在概率值等于阈值或大于阈值的情况下,可以合理地假设癌症是由ntrk致癌融合引起的;可以指示用trk抑制剂治疗患者;可以开始进一步研究以验证该假设(例如,进行肿瘤组织的遗传分析)。
106.阈值可以是介于0.5和0.99999999999之间的值,例如0.8(80%)或0.81(81%)或0.82(82%)或0.83(83%)或0.84(84%)或0.85(85%)或0.86(86%)或0.87(87%)或0.88(88%)或0.89(89%)或0.9(90%)或0.91(91%)或0.92(92%)或0.93(93%)或0.94(94%)或0.95(95%)或0.96(96%)或0.97(97%)或0.98(98%)或0.99(99%)或任何其他值(百分数)。
107.预测模型还可以执行分类。基于输入数据,将至少一个组织病理学图像分配给至少两个类别(第一类别和第二类别)中的一个。第一类别包括显示肿瘤组织的图像,其中肿瘤是由ntrk致癌融合引起的。第二类别包括未显示由ntrk致癌融合所引起的肿瘤组织的图像。在这种情况下,概率值表示各个组织病理学图像被分配到的类别。
108.在另一个方面,本发明涉及trk抑制剂在制备用于治疗受试患者的癌症的药物中的用途,其中应被治疗的受试患者是概率值被确定为等于或大于一个预定阈值的患者,所述概率值指示患者患有由ntrk致癌融合所引起的癌症的概率,所述概率值通过基于患者数据的预测模型来确定。
109.在另一个方面,本发明涉及用于治疗受试患者的癌症的trk抑制剂,其中应被治疗的受试患者是概率值被确定为等于或大于一个预定阈值的患者,所述概率值指示患者患有由ntrk致癌融合所引起的癌症的概率,所述概率值通过基于患者数据的预测模型来确定。
110.在另一个方面,本发明涉及用于治疗受试患者的癌症的方法中的trk抑制剂,其中应被治疗的受试患者是概率值被确定为等于或大于一个预定阈值的患者,所述概率值指示患者患有由ntrk致癌融合所引起的癌症的概率,所述概率值通过基于患者数据的预测模型来确定。
111.在另一个方面,本发明涉及trk抑制剂在治疗受试患者的癌症中的用途,其中应被治疗的受试患者是概率值被确定为等于或大于一个预定阈值的患者,所述概率值指示患者患有由ntrk致癌融合所引起的癌症的概率,所述概率值通过基于患者数据的预测模型来确
定。
112.在另一个方面,本发明涉及用于鉴定倾向于对用于治疗癌症的trk抑制剂有良好反应的受试患者的方法,其中所述方法包括以下步骤:
113.‑
接收所述受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
114.‑
将所述患者数据输入到预测模型中,所述预测模型经由机器学习利用一组训练数据进行了训练,所述预测模型被配置为用于鉴定所述患者数据内ntrk致癌融合的一个或多个特征;
115.‑
从所述预测模型接收概率值作为输出,所述概率值指示所述受试患者患有由ntrk致癌融合所引起的癌症的概率;
116.‑
将所述概率值与一个预定阈值进行比较;
117.而概率值等于或大于所述预定阈值。
118.在另一个方面,本发明涉及治疗受试患者的癌症的方法,所述方法包括以下步骤:
119.‑
接收所述受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
120.‑
将所述患者数据输入到预测模型中,所述预测模型经由机器学习利用一组训练数据进行了训练,所述预测模型被配置为用于鉴定所述患者数据内ntrk致癌融合的一个或多个特征;
121.‑
从所述预测模型接收概率值作为输出,所述概率值指示所述受试患者患有由ntrk致癌融合所引起的癌症的概率;
122.‑
将所述概率值与一个预定阈值进行比较,而所述概率值等于或大于所述预定阈值;
123.‑
给予治疗有效量的trk抑制剂。
124.在另一个方面,本发明涉及一种套件,其包括:
125.‑
包含trk抑制剂的药物,和
126.‑
一种计算机程序产品,所述计算机程序产品包括非暂时性计算机可读存储介质,所述非暂时性计算机可读存储介质包括处理器可执行指令,利用所述处理器可执行指令执行用于鉴定与受试患者相关的患者数据内指示ntrk致癌融合的一个或多个候选标志的操作,所述操作包括:
127.·
接收患有癌症的受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
128.·
将所述患者数据输入到预测模型中,所述预测模型经由机器学习利用一组训练数据进行了训练,所述预测模型被配置为用于鉴定所述患者数据内ntrk致癌融合的一个或多个特征;
129.·
从所述预测模型接收概率值作为输出,所述概率值指示所述受试患者患有由ntrk致癌融合所引起的癌症的概率;
130.·
将所述概率值与一个预定阈值进行比较,而所述概率值等于或大于所述预定阈值。
131.在一个优选的实施方案中,trk抑制剂是sitravatinib、belizatinib、恩曲替尼或
拉罗替尼。
132.sitravatinib(mgcd
‑
516)是一种小分子多激酶抑制剂,靶向met、axl、mer以及血管内皮生长因子受体(vegfr)、血小板衍生生长因子受体(pdgfr)、盘状结构域受体酪氨酸激酶2(ddr2)和trk家族。
133.belizatinib(tsr
‑
011)是一种口服双重alk和泛trk(pan
‑
trk)抑制剂。
134.恩曲替尼(n
‑
[5
‑
(3,5
‑
二氟苄基)
‑
1h
‑
吲唑
‑3‑
基]
‑4‑
(4
‑
甲基
‑1‑
哌嗪基)
‑2‑
(四氢
‑
2h
‑
吡喃
‑4‑
基氨基)苯甲酰胺)是一种口服atp竞争性泛trk、ros1和alk trk抑制剂。
[0135]
拉罗替尼((3s)
‑
n
‑
{5
‑
[(2r)
‑2‑
(2,5
‑
二氟苯基)吡咯烷
‑1‑
基]吡唑并[1,5
‑
a]嘧啶
‑3‑
基}
‑3‑
羟基吡咯烷
‑1‑
甲酰胺)是一种口服给药的选择性原肌球蛋白受体激酶(trk)抑制剂,可用于治疗携带ntrk基因融合的基因组定义的癌症,包括实体瘤、非霍奇金淋巴瘤、组织细胞疾病和原发性cns癌。美国正在进行前体细胞淋巴母细胞白血病
‑
淋巴瘤(急性淋巴母细胞白血病)的临床前开发。
[0136]
在一个更优选的实施方案中,trk抑制剂是拉罗替尼。
[0137]
在本发明的一个优选实施方案中,癌症选自:肺癌、结肠直肠癌、乳头状甲状腺癌、多形性成胶质细胞瘤、肉瘤、分泌性乳腺癌、乳腺类似物分泌性癌、非霍奇金淋巴瘤、组织细胞疾病和原发性cns(中枢神经系统)癌。
[0138]
在另一个方面,本发明涉及一种系统,其包括
[0139]
‑
输入单元,
[0140]
‑
处理单元,和
[0141]
‑
输出单元,
[0142]
其中所述输入单元被配置为接受受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
[0143]
其中所述处理单元被配置为基于所述患者数据来确定概率值,所述概率值指示所述受试患者患有由ntrk致癌融合所引起的癌症的概率;
[0144]
其中所述处理单元可选地被配置为将所述概率值与一个预定阈值进行比较,从而确定比较结果;
[0145]
其中所述输出单元被配置为显示所述概率值和/或显示所述比较结果。
[0146]
根据本文教导的操作可以由为期望目的而专门构建的至少一个计算机或为期望目的而专门配置的通用计算机通过存储在典型的非暂时性计算机可读存储介质中的至少一个计算机程序来执行。
[0147]
术语“非暂时性”在本文中用于排除暂时性的、传播的信号或波,但另外包括适用于该应用的任何易失性或非易失性计算机存储器技术。
[0148]
术语“计算机”应被广义地解释为涵盖具有数据处理能力的任何种类的电子设备,包括,但作为非限制性实例,个人计算机、服务器、嵌入式核、计算系统、通信设备、处理器(例如,数字信号处理器(dsp))、微控制器、现场可编程门阵列(fpga)、专用集成电路(asic)等)以及其他电子计算设备。
[0149]
上文所使用的术语“处理”旨在包括数据的任何类型的计算或操控或转换,这些数据表示为可发生或驻留在例如至少一个计算机或处理器的寄存器和/或存储器内的物理(例如,电子)现象。术语处理器包括单个处理单元或多个分布式或远程处理单元。
[0150]
可使用任何合适的处理器、显示和输入装置来处理、显示(例如,在计算机屏幕或其他计算机输出设备上)、存储和接受信息,例如由本文示出和描述的任何方法和系统所使用或所生成的信息;根据本发明的一些或全部实施方案,上述处理器、显示和输入装置包括计算机程序。本文示出和描述的本发明的任何或所有功能,例如但不限于流程图内的操作,可以由以下的任何一个或多个来执行:用于处理的通用的或专门构建的至少一个传统的个人计算机处理器、工作站或其他可编程设备或计算机或电子计算设备或处理器;用于显示的计算机显示屏和/或打印机和/或扬声器;机器可读的存储器,例如光盘、cdrom、dvd、bluray、磁光盘或其他光盘;用于存储的ram、rom、eprom、eeprom、磁卡或光卡或其他卡,以及用于接受的键盘或鼠标。本文示出和描述的模块可以包括以下的任何一个或组合或多个:服务器、数据处理器、存储器/计算机存储器、通信接口、存储在存储器/计算机存储器中的计算机程序。
[0151]
任何合适的输入设备,例如但不限于相机传感器,可以用于生成或以其他方式提供由本文示出和描述的系统和方法所接收的信息。可使用任何合适的输出设备或显示器来显示或输出由本文示出和描述的系统和方法所生成的信息。可以采用任何合适的处理器来计算或生成本文所述的信息和/或执行本文所述的功能和/或实施本文所述的任何引擎、接口或其他系统。任何合适的计算机化数据存储器,例如计算机存储器,可以用于存储由本文示出和描述的系统所接收或所生成的信息。本文示出和描述的功能可以在服务器计算机与多个客户端计算机之间划分。本文示出和描述的这些或任何其他计算机化组件可以通过合适的计算机网络在它们之间通信。
[0152]
wo2018/184194a中公开了一种特别适于执行本发明的操作/步骤/方法的系统,其内容通过引用并入本文。
[0153]
现在将在下文中参考附图更全面地描述本公开内容的一些实施方式,其中示出了本公开的一些但不是全部实施方式。实际上,本公开内容的各种实施方式可以以许多不同的形式体现,并且不应当被解释为限于本文阐述的实施方式;相反,提供这些示例性实施方式是为了使本公开内容透彻和完整,并将本公开内容的范围充分传达给本领域技术人员。如本文所使用的,例如,单数形式“一个(a)”、“一个(an)”、“该(the)”等包括复数指代物,除非上下文另有明确说明。根据本发明的一些示例性实施方式,术语“数据”、“信息”、“内容”和类似术语可以互换使用,以指代能够被传输、接收、操作和/或存储的数据。此外,例如,本文可以参考定量测量、值、关系等。除非另有说明,这些中的任何一项或多项(如果不是全部)都可以是绝对的或近似的,以考虑可能发生的可接受变化,如因工程公差等引起的变化。相同的附图标记自始至终表示相同的元件。
[0154]
图1示意性地示出了根据本发明的系统(1)的一个实施方案。它包括输入单元(10)、处理单元(20)和输出单元(30)。输入单元(10)接受患者数据并将其转发到处理单元(20)(由输入单元和处理单元之间的箭头描绘)。处理单元(20)基于患者数据确定概率值。处理单元可选地被配置为将该概率值与一个预定阈值进行比较,从而确定比较结果。概率值和/或比较结果从处理单元(20)传输到输出单元(30)(由处理单元和输出单元之间的箭头描绘)。输出单元(30)显示概率值和/或比较结果。输入单元(10)、处理单元(20)和输出单元(30)可以是一个或多个计算机系统的部件。
[0155]
图2更详细地示出了根据本公开内容的一些示例性实施方式的计算机系统(1)。一
般而言,本公开内容的示例性实施方式的计算机系统可以被称为计算机,并且可以包含、包括或体现在一个或多个固定或便携式电子设备中。计算机可以包括多个部件中的每一个的一个或多个,例如连接到存储器(50)(例如,存储设备)的处理单元(20)。
[0156]
处理单元(20)可以单独由一个或多个处理器组成,或者与一个或多个存储器相结合。处理单元通常是能够处理信息如数据、计算机程序和/或其他合适的电子信息的任何计算机硬件。处理单元由一组电子电路组成,其中一些电子电路可以被封装为集成电路或多个互连的集成电路(集成电路有时更通常地被称为“芯片”)。处理单元可以被配置为执行计算机程序,该计算机程序可以存储在处理单元上或者以其他方式存储在同一或另一计算机的存储器(50)中。
[0157]
根据特定的实施方式,处理单元(20)可以是多个处理器、多核处理器或一些其他类型的处理器。此外,处理单元可以使用许多异构处理器系统来实施,其中主处理器与单个芯片上的一个或多个辅助处理器一起存在。作为另一说明性实施例,处理单元可以是包含多个相同类型的处理器的对称多处理器系统。在又另一实施例中,处理单元可以体现为或以其他方式包括一个或多个asic、fpga等。因此,尽管处理单元能够执行计算机程序以执行一个或多个功能,但是各种实施例的处理单元能够在没有计算机程序帮助的情况下执行一个或多个功能。在任一情况下,处理单元可以被适当地编程以执行根据本公开内容的示例性实施方式的功能或操作。
[0158]
存储器(50)通常是能够在临时和/或永久的基础上存储信息例如数据、计算机程序(例如,计算机可读程序代码(60))和/或其他合适的信息的任何计算机硬件。存储器可以包括易失性和/或非易失性存储器,并且可以是固定的或可移动的。合适的存储器的实施例包括随机存取存储器(ram)、只读存储器(rom)、硬盘驱动器、闪存、拇指驱动器、可移动计算机磁盘、光盘、磁带或上述的某种组合。光盘可以包括光盘只读存储器(cd
‑
rom)、高密度读写磁盘(compact disk
–
read/write)(cd
‑
r/w)、dvd、blu
‑
ray光盘等。在各种情况下,存储器可以被称为计算机可读存储介质。计算机可读存储介质是能够存储信息的非暂时性设备,并且与计算机可读传输介质例如能够将信息从一个位置传送到另一位置的电子暂时性信号是不同的。本文描述的计算机可读介质通常指计算机可读存储介质或计算机可读传输介质。
[0159]
除了存储器(50),处理单元(20)还可以连接到用于显示、传输和/或接收信息的一个或多个接口。接口可以包括一个或多个通信接口和/或一个或多个用户接口。通信接口可以被配置为例如向和/或从其他计算机、网络、数据库等传输和/或接收信息。通信接口可以被配置为通过物理(有线)和/或无线通信链路传输和/或接收信息。通信接口可以包括连接到网络的接口(41),例如使用技术例如蜂窝电话、无线网络、卫星、电缆、数字用户线路(dsl)、光纤等。在一些实施例中,通信接口可以包括一个或多个短程通信接口(42),其被配置为使用短程通信技术例如nfc、rfid、蓝牙、蓝牙le、zigbee、红外(例如irda)等连接设备。
[0160]
用户接口可以包括显示器(30)。显示器可以被配置为向用户呈现或以其他方式显示信息,其合适的实施例包括液晶显示器(lcd)、发光二极管显示器(led)、等离子体显示面板(pdp)等。用户输入接口(11)可以是有线或无线的,并且可以被配置为将来自用户的信息接收到计算机系统(1)中,例如用于处理、存储和/或显示。用户输入接口的合适实施例包括麦克风、图像或视频捕获设备、键盘或小键盘、操纵杆、触敏表面(与触摸屏分离或集成到触
摸屏中)等。在一些实施例中,用户接口可以包括用于机器可读信息的自动识别和数据捕获(aidc)技术(12)。这可以包括条形码、射频识别(rfid)、磁条、光学字符识别(ocr)、集成电路卡(icc)等。用户接口还可以包括一个或多个用于与外围设备如打印机等通信的接口。
[0161]
如上所述,程序代码指令可以存储在存储器中,并通过由此被编程的处理单元执行,以实施本文所描述的系统、子系统、工具及其各自元件的功能。如将理解的,任何合适的程序代码指令可以从计算机可读存储介质加载到计算机或其他可编程装置上,以产生特定机器,使得该特定机器成为用于实施本文指定的功能的装置。这些程序代码指令还可以存储在计算机可读存储介质中,其可以指示计算机、处理单元或其他可编程装置以特定方式运行,从而生成特定的机器或特定的制品。存储在计算机可读存储介质中的指令可以产生制品,其中该制品成为用于实施本文描述的功能的装置。程序代码指令可以从计算机可读存储介质中获取并加载到计算机、处理单元或其他可编程装置中,以配置计算机、处理单元或其他可编程装置来执行将在计算机、处理单元或其他可编程装置上或由计算机、处理单元或其他可编程装置执行的操作。
[0162]
程序代码指令的获取、加载和执行可以顺序执行,使得一次获取、加载和执行一个指令。在一些示例性实施方式中,获取、加载和/或执行可以并行执行,使得多个指令被一起获取、加载和/或执行。程序代码指令的执行可以产生计算机实施的过程,使得由计算机、处理电路或其他可编程装置执行的指令提供用于实施本文描述的功能的操作。
[0163]
由处理单元执行指令,或者将指令存储在计算机可读存储介质中,支持用于执行指定功能的操作组合。以这种方式,计算机系统(1)可以包括处理单元(20)以及耦合到处理电路的计算机可读存储介质或存储器(50),其中处理电路被配置为执行存储在存储器中的计算机可读程序代码(60)。还应当理解,一个或多个功能以及功能的组合可以由执行指定功能的基于专用硬件的计算机系统来实施和/或处理电路或者由专用硬件和程序代码指令的组合来实施。
[0164]
图3以流程图的形式示意性地示出了根据本发明的一些实施方案所执行的步骤。
[0165]
步骤是:
[0166]
(a1)接收患有癌症的受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
[0167]
(b1)将所述患者数据输入到预测模型中,所述预测模型经由机器学习利用一组训练数据进行了训练;
[0168]
(c1)从所述预测模型获得概率值,所述概率值指示所述受试患者患有由ntrk致癌融合所引起的癌症的概率;
[0169]
(d1)输出和/或存储概率值。
[0170]
图4以流程图的形式示意性地示出了根据本发明的一些实施方案所执行的步骤。
[0171]
步骤是:
[0172]
(a2)接收患有癌症的受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
[0173]
(b2)将所述患者数据输入到预测模型中,所述预测模型经由机器学习利用一组训练数据进行了训练;
[0174]
(c2)从所述预测模型获得概率值,所述概率值指示所述受试患者患有由ntrk致癌
融合所引起的癌症的概率;
[0175]
(d2)将所述概率值与一个预定阈值进行比较,从而确定比较结果;
[0176]
(e2)输出和/或存储所述概率值和/或所述比较结果。
[0177]
图5以流程图的形式示意性地示出了根据本发明的一些实施方案所执行的步骤。
[0178]
步骤是:
[0179]
(a3)接收患有癌症的受试患者的患者数据,所述患者数据包括所述受试患者的肿瘤组织的至少一个组织病理学图像;
[0180]
(b3)将所述患者数据输入到预测模型中,所述预测模型经由机器学习利用一组训练数据进行了训练;
[0181]
(c3)从所述预测模型获得概率值,所述概率值指示所述受试患者患有由ntrk致癌融合所引起的癌症的概率;
[0182]
(d3)将所述概率值与一个预定阈值进行比较;
[0183]
(e3)在所述概率值等于或大于所述阈值的情况下:开始进一步的研究以验证所述受试患者患有由ntrk致癌融合所引起的癌症的指示,或给予治疗有效量的trk抑制剂。
[0184]
图6和图7示意性地示出了根据本发明的可用于确定概率值的示例性卷积神经网络。图6示出了cnn内的各个层。如图6所示,用于鉴定患者数据内的ntrk致癌融合的一个或多个特征的示例性cnn可以接收描述输入组织病理学图像的红色、绿色和蓝色(rgb)分量的输入(102)。输入(102)可以由多个卷积层(例如,卷积层(104)、卷积层(106))处理。来自多个卷积层的输出可以可选地由一组全连接层(108,110)处理。全连接层中的神经元与前一层中的所有激活都有全连接。来自全连接层(108)的输出可用于从网络产生输出结果(110)。输出结果可以是指示患者患有由ntrk致癌融合所引起的癌症的概率的概率值。
[0185]
可以使用矩阵乘法而不是卷积来计算全连接层(108)内的激活。并非所有的cnn实施方式都使用全连接层。例如,在一些实施方式中,卷积层(106)可以为cnn生成输出。
[0186]
卷积层是稀疏连接的,这不同于在全连接层(108)中发现的传统神经网络配置。传统的神经网络层是全连接的,使得每个输出单元都与每个输入单元交互。然而,卷积层是稀疏连接的,因为场的卷积的输出被输入(而不是场中的每个节点各自的状态值)到后续层的节点,如所例示的。与卷积层相关的内核执行卷积运算,其输出被发送到下一层。在卷积层内所执行的降维是使cnn能够处理大图像的一个方面。
[0187]
图7示出了cnn的卷积层内的示例性计算阶段。cnn的卷积层(114)的输入(112)可以在卷积层(114)的三个阶段中处理。这三个阶段可以包括卷积阶段(116)、检测器阶段(118)和池化阶段(120)。然后,卷积层(114)可以将数据输出到连续的卷积层。网络的最终卷积层可以生成输出特征图数据或向全连接层提供输入,例如,以生成分类或回归值。
[0188]
在卷积阶段(116),卷积层(114)可以并行执行几个卷积以产生一组线性激活。卷积阶段(116)可以包括仿射转换,其是可以被指定为线性转换加平移的任何转换。仿射转换包括旋转、平移、缩放以及这些转换的组合。卷积阶段计算连接到输入中的特定区域的函数(例如,神经元)的输出,所述特定区域可被确定为与神经元相关的局部区域。神经元计算神经元的权重与神经元所连接的局部输入中的区域之间的点积。卷积阶段(116)的输出定义了一组线性激活,该组线性激活由卷积层(114)的连续阶段处理。
[0189]
线性激活可以由检测器阶段(118)处理。在检测器阶段(118)中,每个线性激活由
非线性激活函数处理。非线性激活函数增加了整个网络的非线性属性,而不影响卷积层的接受域。可以使用几种类型的非线性激活函数。一种特殊类型是修正线性单元(relu),它使用定义为f(x)=max(0,x)的激活函数,使得激活阈值为零。
[0190]
池化阶段(120)使用池化函数,该池化函数用附近输出的汇总统计量代替卷积层(106)的输出。池化函数可用于将平移不变性引入神经网络,使得对输入的小平移不会改变池化输出。在输入数据中特征的存在比特征的精确位置更重要的情况下,局部平移不变性非常有用。在池化阶段(120)可以使用各种类型的池化函数,包括最大池化、平均池化和12范数池化。此外,一些cnn实施方式不包括池化阶段。相反,这种实施方式替代了相对于先前的卷积阶段具有增加的步幅的额外卷积阶段。
[0191]
然后可以由下一层(122)处理来自卷积层(114)的输出。下一层(122)可以是额外的卷积层或全连接层(108)之一。例如,图6的第一卷积层(104)可以输出到第二卷积层(106),而第二卷积层可以输出到全连接层(108)的第一层。
[0192]
图8示出了神经网络的示例性训练和部署。一旦已经为任务构造了给定网络,就使用训练数据集(1102)来训练神经网络。
[0193]
为了开始训练过程,可以随机选择初始权重,或者通过使用深度信念网络进行预训练来选择初始权重。然后以监督或无监督的方式执行训练周期。监督学习是一种学习方法,其中训练作为中介操作来执行,例如当训练数据集(1102)包括与输入的期望输出成对的输入时,或者其中训练数据集包括具有已知输出的输入并且神经网络的输出被手动分级时。网络处理输入,并将所得到的输出与一组预期或期望输出进行比较。然后,误差会通过系统反向传播。训练框架(1104)可以调整控制未训练的神经网络(1106)的权重。训练框架(1104)可以提供工具来监控未训练的神经网络(1106)向适于基于已知输入数据生成正确答案的模型收敛的程度。当调整网络的权重以优化由神经网络所生成的输出时,训练过程会重复发生。训练过程可以继续,直到神经网络达到与经训练的神经网络(1108)相关的统计上期望的准确度。然后经训练的神经网络(1108)可被部署以实施任何数目的机器学习操作。可将一组新的患者数据(1112)输入到经训练的神经网络(1108)中以确定概率值,该概率值指示患者患有由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的癌症的概率。
[0194]
图9是癌症患者的肿瘤组织的组织病理学图像(hi)的实施例。
[0195]
图10是示出预测模型的性能以及表示其输出的方式的实施例的示意图。
[0196]
图10(a)示出了he染色、福尔马林固定、石蜡包埋(ffpe)的肿瘤组织切片的数字图像。组织(200)包含孔(210)。这样的图像用作预测模型的输入。注意,为清楚起见,省略了he染色显示的组织细节(这导致组织切片中出现不同的颜色和强度)。然而,这些只向受过训练的人揭示了细胞的位置、形状和类型,而不是它们的分子组成。
[0197]
图10(b)示出了预测工具的输出实施例。生成与图10(a)中的组织扫描的布局相对应的数字图像。组织扫描通常被伪彩色图像覆盖,其中颜色或颜色强度对应于组织区域显示由ntrk致癌融合所引起的肿瘤癌的概率(这里仅显示黑色/白色图像)。在一个优选的实施方案中,选择颜色以代表免疫组织化学染料的典型颜色(如,褐色或红色),从而产生“伪ihc图像”。图中颜色由点虚线(表示预测的弱染色强度)、交叉阴影线(中度染色)或粗阴影线(强染色)区域表示。
[0198]
图10(c)示出了用抗体染色的相邻ffpe肿瘤组织切片的数字图像,用于使用免疫
组织化学来指示trk蛋白的存在。注意,数字图像非常好地对应于由预测模型做出的预测,如图10(b)所示,即使分子试验是在相邻组织切片上进行的。
[0199]
注意,当从组织放大到形态/细胞水平时,这种性能在更高的放大率下也成立。在一个优选实施方案中,当放大到一个区域或在组织上移动时,例如图10(b)中所示的预测图像(几乎)实时地从he颜色转变为伪ihc颜色。这通过边缘分析来实现,并且使得根据本发明的系统能够本地处理信息并且更快速地响应情况。此特征还允许我们的工具在远程病理学设置中工作,甚至在移动计算设备如智能手机中工作。在一个优选实施方案中,预测模型被嵌入到网站中,以便于在常规计算机设备上安装。
[0200]
例如,可以仅使用泛trk单克隆抗体epr17341(abcam,cambridge,ma)的研究进行ihc,参见hechtman等人,the american journal of surgical pathology(2017),41(11),1547
–
1551,pmid 28719467,使用例如ventana autostainer discovery ultra设备。
[0201]
图11示意性地示出了用于在实践中使用本发明的方法的实施方案。该方法的起点是患者。患者患了癌症。该方法的一个目的是查明癌症是否由神经营养受体酪氨酸激酶(ntrk)基因突变引起。在第一步骤中,收集/获取患者数据(1112)。患者数据(1112)包括患者的肿瘤组织的至少一个组织病理学图像(hi)。在接下来的步骤中,将患者数据输入到通过监督学习训练的预测模型(1108)中。对于有监督的训练,可使用大量患者的患者数据,已确定了这些患者是否患有由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的癌症或是否患有并非由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的癌症。
[0202]
经训练的预测模型(1108)被配置为从输入的患者数据(1112)确定概率值p。概率值表示患者患有由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的癌症的概率。
[0203]
在进一步的步骤中,将概率值p与一个预定阈值t进行比较。
[0204]
如果概率值p小于预定阈值t(p≥t:“否”),则患者不太可能患有由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的癌症;必须鉴定癌症的其他原因;方法结束。
[0205]
如果概率值p等于或大于预定阈值t(p≥t:“是”),则患者很可能患有由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的癌症。开始随后的步骤(1120)。在本发明的一个实施方案中,开始进一步的研究以证实癌症是由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的。这可以例如通过肿瘤组织的遗传分析来完成。进一步研究的结果可用于优化(进一步监督学习)预测模型(1108)。如果进一步的研究证实癌症是由神经营养受体酪氨酸激酶(ntrk)基因突变所引起的,则可使用trk抑制剂对患者进行治疗。在另一实施方案中,认为由神经营养受体酪氨酸激酶(ntrk)基因突变引起癌症的可能性如此之高,以致于直接用trk抑制剂治疗患者(无需对肿瘤组织进行任何进一步的遗传分析)。
[0206]
图12至图14示出了本发明的实施例,其中建立了用于预测概率值的人工神经网络,每个概率值指示受试患者患有由ntrk致癌融合所引起的甲状腺癌的概率。
[0207]
图12示出了人工神经网络的层结构。该网络由ibm提供,名称为inception resnet v2(https://developer.ibm.com/exchanges/models/all/max
‑
inception
‑
resnet
‑
v2/)。在imagenet上预训练的网络与转换学习一起使用(在keras+tensorflow中)。
[0208]
用于训练和验证的数据集取自癌症基因组图谱(the cancer genome atlas)(tcga:https://portal.gdc.cancer.gov/)。其他数据来自芬兰图尔库大学医院的生物库auria。
[0209]
将he染色组织切片(冷冻和或ffpe福尔马林固定石蜡包埋)的.svs格式的数字图像用作组织病理学图像。诊断时患者的年龄也用作预测的输入参数。使用从tcga获得的关于关键致癌基因突变状态的全外显子组测序数据中所提取的信息以及ngs小组关于auria样本的结果(illumina tst 170)。
[0210]
图13以接收机工作特性曲线(roc曲线)的形式示出了结果。train指训练数据集,val指验证数据集,test指测试数据集。训练数据集用于训练预测模型,验证数据集用于验证预测模型,测试数据集用于预测目的。auc表示曲线下方的面积。
[0211]
图14以精度召回曲线的形式示出了结果。train指训练数据集,val指验证数据集,test指测试数据集。训练数据集用于训练预测模型,验证数据集用于验证预测模型,测试数据集用于预测目的。auc表示曲线下方的面积。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1