从受试者声音诊断呼吸疾病的制作方法
从受试者声音诊断呼吸疾病
1.相关申请的交叉引用
2.本技术要求于2019年12月16日提交的澳大利亚临时专利申请第2019904754号的优先权,其公开内容通过引用并入本文。
技术领域
3.本发明涉及一种用于处理受试者声音以诊断呼吸疾病的设备和方法。
背景技术:
4.对现有技术的方法、设备或文件的任何引用都不应被视为构成任何证据或承认它们过去或现在形成公知常识的一部分。
5.众所周知,电子处理受试者声音以识别呼吸疾病。通常进行这种处理的一种方式是从与所讨论的疾病相关的声音片段中提取特征。例如,所讨论的疾病可能是肺炎,在这种情况下,相关的声音片段是包括受试者咳嗽声的片段。提取的咳嗽声的特征通常是量化声音片段的各种属性的值。例如,咳嗽声波形的一段的时域中的过零点的数量可以是一个特征。另一个特征可以是指示咳嗽声片段的高斯分布偏差的值。其他特征可以是咳嗽声片段的能量水平的对数。
6.一旦确定了特征值,它们就形成了一个特征向量。然后将来自已知患有或未患有特定疾病的受试者的咳嗽声的特征向量用作训练向量来训练模式分类器,诸如神经网络。然后,训练的分类器可以用于将测试特征向量分类为很可能预测受试者是否患有特定疾病。
7.因此,将会认识到,这种基于机器学习的自动诊断系统非常有帮助。事实上,可以通过应用程序配置智能手机的处理器,以实现具有预训练神经网络的预测系统,从而为临床医生提供高度便携的预测辅助。考虑到预测的结果,临床医生然后能够对受试者应用适当的治疗。这样的系统在以下文献中描述:“porter,p.,abeyratne,u.,swarnkar,v.et al.a prospective multicenter study testing the diagnostic accuracy of an automated cough sound centered analytic system for the identification of common respiratory disorders in children.respir res 20,81(2019)”(本文称为porter等人的论文)。
8.然而,我们将认识到,确定一些特征的值,诸如高斯分布的偏差、对数能量水平和其他计算密集型特征,需要复杂的编程,这在技术上是有要求的。此外,选择一组最佳特征来形成待诊断的目标疾病的特征向量绝非易事。通常需要测试、直觉和灵感的闪现来得到最佳或接近最佳的特征集。
9.如果存在一种用于从受试者声音自动诊断呼吸疾病的方法和设备,其是对已经讨论的现有技术的改进,或者至少是有用的替代方案,那么这将是非常有利的。
技术实现要素:
10.根据第一方面,提供了一种用于预测受试者中的呼吸系统的疾病存在的方法,包括:
11.操作至少一个电子处理器以将受试者的音频记录中与疾病相关的一个或多个声音片段转换成所述声音片段对应的一个或多个图像表示;
12.操作所述至少一个电子处理器以将所述一个或多个图像表示应用于至少一个模式分类器,所述模式分类器被训练用于从图像表示来预测疾病的存在;以及
13.操作所述至少一个电子处理器(“所述处理器”)以基于所述模式分类器的至少一个输出来生成对所述受试者中的所述疾病的存在的预测。
14.在一实施例中,所述方法包括操作所述处理器以将一个或多个声音片段转换成对应的一个或多个图像表示,其中所述图像表示将一个轴上的频率与另一个轴上的时间相关。
15.在一实施例中,所述图像表示包括声谱图。
16.在一实施例中,所述图像表示包括梅尔谱图。
17.在一实施例中,所述方法包括操作所述处理器以通过使用第一咳嗽声模式分类器和第二咳嗽声模式分类器来将潜在咳嗽声识别为音频记录的咳嗽音频片段,第一咳嗽声模式分类器和第二咳嗽声模式分类器被训练为分别检测咳嗽声的初始阶段和后续阶段。
18.在一实施例中,所述图像表示具有n
×
m个像素的尺寸,其中图像通过所述处理器处理每个片段的n个窗口而形成,其中每个窗口在m个频率区间中被分析。
19.在一实施例中,n个窗口中的每一个与n个窗口中的至少一个其他窗口重叠。
20.在一实施例中,所述窗口的长度与其相关的咳嗽音频片段的长度成比例。
21.在一实施例中,所述方法包括操作所述处理器以计算快速傅立叶变换(fft)和每个频率区间的功率值,以得到所述一个或多个图像表示中的对应图像表示的对应像素值。
22.在一实施例中,所述方法包括操作所述处理器以m个功率值的形式计算每个频率区间的功率值,所述m个功率值是所述m个频率区间中的每个频率区间的功率值。
23.在一实施例中,所述m个频率区间包括m个梅尔频率区间,所述方法包括操作所述处理器以将m个功率值连接和归一化,从而产生梅尔谱图图像形式的对应图像表示。
24.在一实施例中,所述图像表示是正方形的,并且m等于n。
25.在一实施例中,所述方法包括操作所述处理器以接收关于特定疾病的症状和/或临床体征的输入。
26.在一实施例中,所述方法包括操作所述处理器以:除了所述一个或多个图像表示之外,还将症状和/或临床体征应用到的所述至少一个模式分类器上。
27.在一实施例中,所述方法包括操作所述处理器以基于响应于所述至少一个图像表示和症状和/或临床体征的所述至少一个模式分类器的至少一个输出来预测受试者中疾病的存在。
28.在一实施例中,所述至少一个模式分类器包括:
29.响应于所述表示的表示模式分类器;以及
30.响应于所述症状和/或临床体征的症状分类器。
31.在一实施例中,所述表示模式分类器包括神经网络。
32.在一实施例中,所述神经网络优选地是卷积神经网络(cnn)。
33.在一实施例中,所述症状模式分类器包括逻辑回归模型(lrm)。
34.在一实施例中,所述方法包括操作所述处理器以基于来自所述症状模式分类器的一个或多个输出来确定基于症状的预测概率。
35.在一实施例中,所述方法包括操作所述处理器以基于来自所述表示模式分类器的一个或多个输出来确定基于表示的预测概率。
36.在一实施例中,所述方法包括基于响应于两种到七种表示的来自所述表示模式分类器的一个或多个输出确定基于表示的预测概率。
37.在一实施例中,所述方法包括基于响应于五种表示的来自所述表示模式分类器的一个或多个输出确定基于表示的预测概率。
38.在一实施例中,所述方法包括将所述基于表示的预测概率确定为针对每个表示的基于表示的预测概率的平均值。
39.在一实施例中,所述方法包括基于所述基于表示的预测概率和所述基于症状的预测概率来确定总体预测概率值。
40.在一实施例中,所述方法包括将所述总体概率值确定为基于表示的概率和基于症状的概率的加权平均。
41.在一实施例中,所述方法包括操作所述处理器以将基于表示的预测概率值与预定阈值进行比较。
42.在一实施例中,所述方法包括操作所述处理器以将总体概率值与预定阈值进行比较。
43.在一实施例中,所述方法包括操作所述处理器以响应于所述处理器在显示屏上呈现基于所述比较的所述疾病存在或不存在的指示。
44.根据另一方面,提供了一种用于预测受试者中呼吸疾病存在的设备,包括:
45.音频捕获装置,其被布置成将受试者的数字音频记录存储在电子存储器中;
46.声音片段-图像表示组件,其被布置成将与疾病相关的记录的声音片段转换成其图像表示;
47.与所述声音片段-图像表示组件通信的至少一个模式分类器,其被配置成处理图像表示以产生一信号,所述信号指示受试者声音片段预测具有呼吸疾病的概率。
48.在一实施例中,所述设备包括片段识别组件,所述片段识别组件与所述电子存储器通信并且被布置成处理所述数字音频记录,从而识别包括与寻求预测的疾病相关的声音的所述数字音频记录的片段。
49.在一实施例中,所述片段识别组件被布置成处理所述数字音频记录,从而识别包括与所述疾病相关的声音的所述数字音频记录的片段,其中所述疾病包括肺炎,并且所述片段包括所述受试者的咳嗽声。
50.在一实施例中,所述片段识别组件被布置成处理所述数字音频记录,从而识别包括与所述疾病相关的声音的所述数字音频记录的片段,其中所述疾病包括哮喘,并且所述片段包括所述受试者的喘息声。
51.根据本发明的另一方面,提供了一种用于训练模式分类器以从受试者的声音记录来预测受试者中呼吸疾病存在的方法,该方法包括:
52.将患有和未患有疾病的受试者的与疾病相关的声音转换成对应的图像表示;
53.训练模式分类器以响应于来自患有疾病的受试者的对应于与疾病相关的声音的图像表示的应用而产生预测疾病存在的输出,并且响应于来自未患有疾病的受试者的对应于所述声音的图像表示的应用而产生预测疾病不存在的输出。
54.根据本发明的另一方面,提供了一种基于来自受试者的一段声音的图像表示来预测受试者中呼吸疾病存在的方法。
55.根据本发明的另一方面,提供了一种用于预测受试者中呼吸疾病存在的设备,该设备被配置成将来自受试者的一段声音转换成对应的图像表示。
56.根据本发明的另一个方面,提供了承载有形的、非暂时性的机器可读指令的计算机可读介质,所述指令用于一个或多个处理器实现基于来自受试者的一段声音的图像表示来预测受试者中呼吸疾病存在的方法。
附图说明
57.本发明的优选特征、实施例和变化可以从下面的详细描述中看出,该详细描述为本领域技术人员实施本发明提供了足够的信息。该详细描述不应被视为以任何方式限制本发明的前述概述的范围。详细描述将参考如下多个附图:
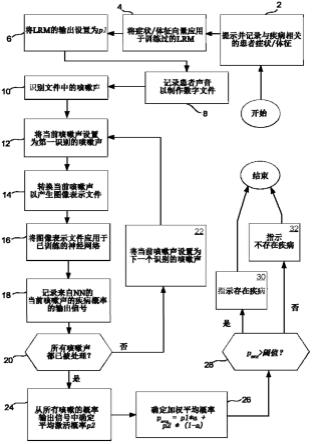
58.图1是根据本发明实施例的疾病预测方法的流程图。
59.图2是呼吸疾病预测机器的框图。
60.图2a是描绘一系列咳嗽声以及第一和第二训练模式分类器的相应输出的图表。
61.图3是机器的界面屏幕显示,用于引出关于疾病的受试者症状的输入。
62.图4是在记录受试者声音期间机器的界面屏幕显示。
63.图5是示出该方法中的步骤的图,该方法由机器执行以产生与疾病相关的受试者声音的图像表示。
64.图6是与疾病相关的受试者声音的梅尔谱图图像表示。
65.图7是与疾病相关的受试者声音的德尔塔梅尔谱图图像表示。
66.图8是机器的界面屏幕显示,用于呈现对受试者中存在疾病状况的预测。
67.图9是根据本发明实施例的卷积神经网络(cnn)训练机器的框图。
68.图10是编码为由图9的训练机器执行的软件产品中的指令的方法的流程图。
具体实施方式
69.图1示出了根据本发明优选实施例的方法的流程图,该方法用于预测受试者中诸如呼吸疾病的疾病存在。如将要讨论的,图1的流程图将基于表示的预测概率与基于症状的预测概率相结合,其中基于表示的预测概率是基于部分受试者声音的图像表示的。基于症状的预测概率是基于对疾病的自我评估的受试者症状。如将进一步讨论的,在其他实施例中,不使用自我评估的症状,并且预测仅基于部分受试者声音的图像表示。
70.被配置为实施该方法的硬件平台包括呼吸疾病预测机器。该机器可以是台式计算机或便携式计算设备,诸如智能手机,其包含与电子存储器通信的至少一个处理器,该电子存储器存储指令,该指令专门配置操作中的处理器以执行将要描述的方法的步骤。应当理解,如果没有专用硬件,即专用机器或由专门编程的一个或多个处理器组成的机器,就不可
能实现该方法。可选地,该机器可以被实现为专用组件,该专用组件包括执行将要讨论的每个步骤的特定电路。该电路可以主要使用根据硬件描述符语言(hdl)或verilog规范配置的现场可编程门阵列(fpga)来实现。
71.图2是包括呼吸疾病预测机器51的设备的框图,在当前描述的实施例中,该呼吸疾病预测机器51使用智能电话的一个或多个处理器和存储器来实现。呼吸疾病预测机器51包括至少一个处理器53,其可以简称为“处理器”,其访问电子存储器55。电子存储器55包括例如由处理器53执行的操作系统58,诸如android操作系统或苹果ios操作系统。根据本发明的优选实施例,电子存储器55还包括呼吸疾病预测软件产品或“app”56。呼吸疾病预测app56包括可由处理器53执行的指令,以便呼吸疾病预测机器51处理来自受试者52的声音,并通过lcd触摸屏界面61向临床医生54呈现受试者52中呼吸疾病存在的预测。app 56包括用于处理器实现模式分类器的指令,诸如训练预测器或决策机器,在本发明的当前描述的优选实施例中,其包括特定训练的卷积神经网络(cnn)63和特定训练的逻辑回归模型(lrm)60。
72.如图2所示,处理器53经由数据总线57与多个外围组件59至73进行数据通信,该数据总线57由金属导体组成,数字信号200沿着金属导体在处理器和各种外围组件之间传送。因此,如果需要,呼吸疾病预测机器51能够经由wan/wlan组件73和射频天线79与语音和/或数据通信网络81建立语音和数据通信。该机器还包括其他外围组件,诸如透镜和ccd组件59,其实现数码相机,使得如果需要,可以捕获受试者52的图像。提供lcd触摸屏界面61作为人机界面,并允许临床医生54读取结果并将命令和数据输入到机器51中。提供usb端口65用于实现与外部存储装置(诸如usb棒)的串行数据连接,或者用于与数据网络或外部屏幕和键盘等进行电缆连接。除了由存储器55提供的内部数据存储空间之外,如果需要,还提供辅助存储卡64用于附加的辅助存储。音频接口71将麦克风75耦合到数据总线57,并且包括抗混叠滤波电路和模数采样器,以将来自麦克风75的模拟电波形(对应于受试者声波39)转换成可以存储在存储器55中并由处理器53处理的数字音频信号50(如图5所示)。音频接口71还耦合到扬声器77。音频接口71包括用于将数字音频转换成模拟信号的数模转换器和连接到扬声器71的音频放大器,使得记录在存储器55或辅助存储器64中的音频可以被回放以供临床医生54收听。将会认识到,麦克风75和音频接口71连同用app 56编程的处理器53包括音频捕获装置,该音频捕获装置被配置用于将受试者52的数字音频记录存储在诸如存储器55或辅助存储器64的电子存储器中。
73.呼吸疾病预测机器51编程有app 56,使得其被配置为作为用于分类受试者声音的机器,可能与受试者症状相结合,以预测受试者体内特定呼吸疾病的存在。
74.如前所述,虽然图2中所示的呼吸疾病预测机器51是由app 56唯一配置的智能手机硬件的形式提供的,但是它同样可以利用一些其他类型的计算设备,诸如台式计算机、膝上型计算机或平板计算设备,或者甚至在云计算环境中实现,其中硬件包括用app 56专门编程的虚拟机。此外,还可以构建不使用通用处理器的专用呼吸疾病预测机器。例如,这种专用机器可以具有音频捕获装置,该音频捕获装置包括麦克风和模数转换电路,该模数转换电路被配置为将受试者的数字音频记录存储在电子存储器中。该机器还包括与存储器通信的片段识别组件,其被布置为处理数字录音,从而识别包括与寻求预测的疾病相关的声音的数字录音片段。例如,疾病可以包括肺炎,并且片段可以包括受试者的咳嗽声。作为另
一个例子,疾病可以包括哮喘,并且片段可以包括受试者的喘息声。可以提供声音片段到图像表示的组件,其将识别的声音片段转换成图像表示。专用机器还包括与特征提取处理器通信的硬件实现的模式分类器,该模式分类器被配置成产生指示受试者声音片段指示呼吸疾病的信号。
75.呼吸疾病预测机器51用来预测受试者52中呼吸疾病的存在的过程的实施例,其包括构成app 56的指令,在图1的流程图中示出并且现在将被详细描述。
76.在框2,临床医生54或另一个护理者或甚至受试者39选择app 56,app 56包含使处理器53操作lcd触摸屏界面61以显示屏幕80的指令,如图2所示。受试者的年龄和症状的存在和/或严重程度,诸如发烧、喘息和咳嗽,然后被输入并存储在存储器55中作为症状测试特征向量。还可以输入临床体征,诸如受试者的溶解氧水平(单位为%)、呼吸频率、心率等。控制然后进行到图1的框4,其中处理器53将症状测试特征向量应用于以预训练l2的正则化逻辑回归模型60的形式的症状模式分类器,app 56被编程来实现该模型。
77.来自lrm 60的输出是一个信号,例如数字电信号,其指示症状测试特征向量与受试者52患有的特定疾病相关的概率。例如,如果lrm已经用对应于患有/未患有特定疾病(例如肺炎)的人的训练向量进行了预训练,则lrm的输出将指示受试者患有该疾病的概率p1。在框6,处理器53基于来自lrm 60的输出设置基于症状的预测概率p1值。
78.在框8,处理器53显示诸如图3的屏幕82的屏幕,以提示临床医生54操作机器51开始通过麦克风75和音频接口71记录来自受试者52的声音39。音频接口71将声音转换成数字信号200,数字信号200沿着总线57传送,并由处理器53作为数字文件记录在存储器55和/或辅助存储sd卡64中。在当前描述的优选实施例中,记录应该进行足够长的持续时间,以包括与要出现在声音记录中的所讨论的疾病相关的许多声音。
79.在框10,处理器53识别表征特定疾病的声音片段。例如,在疾病是肺炎的情况下,app56包含处理器53处理数字声音文件以识别咳嗽声片段的指令。
80.在国际专利申请公开wo 2018/141013中描述了一种用于识别咳嗽声的优选方法(本文有时称为“lw2”方法),其公开内容通过引用整体并入本文。在lw2方法中,来自受试者声音的特征向量被应用于两个预训练的神经网络,这两个神经网络分别被训练用于检测咳嗽声的初始阶段和咳嗽声的后续阶段。根据正向训练对第一神经网络进行加权,以检测咳嗽声的初始爆发阶段,并且对第二神经网络进行正向加权,以检测咳嗽声的一个或多个后爆发阶段。在lw2方法的优选实施例中,根据关于爆发阶段的正向训练和关于后爆炸阶段的负向训练,进一步加权第一神经网络。lw2特别擅长在一系列相连的咳嗽中识别咳嗽声。
81.在框10,处理器53识别音频声音文件50中的潜在咳嗽声(pcss)。在本发明的优选实施例中,app 56包括配置处理器53以实现第一咳嗽声模式分类器(cspc1)62a和第二咳嗽声模式分类器(cspc2)62b的指令,每个分类器优选地包括被训练以分别检测咳嗽声的初始和后续阶段的神经网络。因此,在优选实施例中,处理器53使用之前已经讨论过的lw2方法来识别pcss。
82.也可以使用现有技术中其他已知的咳嗽声检测方法。例如,在abeyratne等人的wo2013/142908中,描述了一种用于咳嗽检测的方法,该方法包括确定受试者声音的多个片段中的每一个的多个特征,从这些特征形成特征向量,并且将它们应用于单个预训练的分类器。然后处理分类器的输出以将这些片段视为“咳嗽”或“非咳嗽”。
83.图2a是显示来自受试者52的声波40的音频记录的一部分的曲线图。音频记录作为数字声音文件50存储在存储器55中。
84.现在将解释wo 2018/141013中描述的lw2方法的应用示例,其优选地由处理器53在框10处实现。lw2方法包括将声波的特征应用于两个经过训练的神经网络cspc1 62a和cspc262b,这两个神经网络分别被训练来识别咳嗽声的第一相位和第二相位。第一神经网络cspc162a的输出在图4中表示为线54,并且包括表示声波的相应部分是咳嗽声的第一相位的可能性的信号。第二神经网络cspc2 62b的输出在图4中表示为线52,并且包括表示声波的相应部分是咳嗽声的后续阶段的可能性的信号。基于第一和第二训练神经网络cspc1 62a和cspc262b的输出54和52,处理器53识别位于片段68a和68b中的两个咳嗽声66a和66b。
85.在框12,处理器将可变的当前咳嗽声设置为声音文件中已经识别的第一咳嗽声。
86.在框14,处理器变换当前咳嗽声以产生相应的图像表示,其例如作为文件存储在存储器55或辅助存储器64中。
87.该图像表示可以包括或者基于数字音频文件的当前咳嗽声部分的声谱图。可能的图像表示包括梅尔频谱图(或“梅尔谱图”)、连续小波变换以及这些表示沿时间维度的导数,也称为德尔塔(delta)特征。
88.图5中描绘了框14的一个特定实现的例子。最初,处理器53在数字声音文件50中识别两个咳嗽声66a、66b。
89.处理器53将检测到的咳嗽66a和66b识别为单独的咳嗽音频片段68a和68b。然后,每个单独的咳嗽音频片段68a和68b被分成n个(在本例中n=5)等长的重叠窗口72a1,
……
,72a5和72b1,
……
,72b5。对于较短的咳嗽片段,例如比咳嗽片段68a稍短的咳嗽片段68b,用于片段68b的重叠窗口72b成比例地比用于片段68a的重叠窗口72a短。
90.处理器53然后计算快速傅立叶变换(fft)和每个梅尔频谱的功率,以得到相应的像素值。用于操作处理器对声波执行这些操作的机器可读指令包含在app 56中。此类指令可公开获取,例如:https://librosa.github.io/librosa/_modules/librosa/core/spectrum.html(2019年12月11日检索)处获取。
91.在图5所示的例子中,处理器53从n=5个重叠窗口72a1、
……
、72a5和72b1、
……
、72b5中的每一个中提取n=5个梅尔谱图74a、74b,每个具有n=5个梅尔频率区间。
92.处理器53连接并归一化存储在频谱图74a和74b中的值,以产生相应的正方形梅尔谱图图像76a和76b,它们分别是表示咳嗽声66a和66b的图像表示。图像76a和76b中的每一个都是8位灰度n
×
n图像。
93.n可以是任何正整数值,记住在某个n处,取决于音频接口71的采样率,咳嗽图像将包含原始音频中存在的所有信息,这是所希望的。可能需要增加fft区间的数量以适应更高的n。
94.图6是使用图5中描述的过程获得的正方形梅尔谱图图像,其中n=224。在该图像中,水平轴上的时间从左到右增加,垂直轴上的频率从下到上增加。较暗的区域表示梅尔频率区间的振幅增加。
95.图7是在n=224的情况下使用类似于图5中描述的过程获得的正方形梅尔谱图图像。在此图像中,较暗的区域表示正德尔塔,较亮的区域表示负德尔塔。
96.出于本专利说明书的官方公开的目的,图6和图7都经过了阈值处理,以使得它们
成为黑白图像。
97.尽管使用正方形表示是方便的,该正方形表示是从n
×
m个片段中导出的n
×
m个像素,每个片段被分析用于m个梅尔频率区间,其中n=m。在其他实施例中,n可以不等于m,使得产生的图像将是正方形的,这是非常令人满意的,前提是cnn是使用相似尺寸的训练图像来训练的。
98.从框14的讨论中可以理解,由app 56配置来执行框14的过程的处理器53包括声音片段-图像表示组件,该组件被设置成将记录中与疾病相关的被识别的声音片段,转换成相应的图像表示。
99.现在回到图1,在框16,处理器53将图像表示,例如图像76a应用于训练的卷积神经网络(cnn)63形式的模式分类器。cnn 63被训练成从图像76a预测受试者52中特定呼吸疾病的存在。cnn 63包括模式分类器,其以输出概率信号的形式生成疾病存在的预测。输出概率信号的范围在0和1之间,其中1指示确定受试者中存在疾病,而0指示不存在疾病的可能性。处理器53记录当前咳嗽声的图像表示的基于表示的预测概率。在框20,执行检查,如果有更多的咳嗽要处理,则控制转移回框12,并重复该过程。可替代地,如果在框20所有咳嗽声都已被处理,则控制进行到框24。
100.将认识到,cnn 63包括模式分类器,该模式分类器被配置成生成指示受试者声音片段预测具有呼吸疾病的概率的输出。
101.在框24,处理器53从所有咳嗽的概率输出信号确定平均激活概率p2。在框26,处理器53将基于受试者症状的存在呼吸疾病的概率p1与平均激活概率p2相结合,该平均激活概率p2是从cnn响应于图像的输出而确定的基于表示的概率预测。在框26确定的p
avg
概率是p1和p2的加权平均值,由因子“a”加权。系数“a”通常为0.5。
102.在框28,处理器53将p
avg
值与预定阈值进行比较。如何确定阈值将在后面描述。如果p
avg
大于阈值,则处理器53指示所讨论的呼吸疾病是否被指示存在。在当前描述的实施例中,处理器53操作lcd触摸屏界面61来显示图8所示的屏幕78。屏幕78显示已经检测到的疾病的名称(例如“肺炎”)以及是否已经确定其存在。
103.在本发明的其他实施例中,处理器53不收集受试者症状和/或临床体征,因此不执行框2、4、6和26。相反,在框28,将p2与阈值进行比较,并且在框30和32做出的是否存在疾病的指示仅基于p2。
104.表现
105.将之前引用的porter等人的论文中描述的诊断方法的表现与本发明的各种实施例进行比较。
106.一项研究招募了来自西澳大利亚珀斯的joondalup health campus的1021名受试者。受试者是从急症综合医院的急诊室、病房和门诊招募的。诊断方法的表现使用灵敏度和特异性进行评估,并与专家临床医生通过全面检查和调查结果得出的临床诊断进行比较。
107.该组的人口统计数据如下。这组有628个女性和393个男性。女性的平均年龄为67岁,最小年龄为16岁,最大年龄为99岁。男性平均年龄为68岁,最小16岁,最大93岁。
108.使用25折交叉验证方法(25-fold cross-validation method)将结果汇集在整个数据集上。旧方法和本文描述的实施例的方法的结果都是在相同数据集上的25折交叉验证。仅使用训练组中的受试者进行模型构建。使用每个记录中的所有咳嗽来完成训练。然
而,在验证中,发明人仅使用了前五次咳嗽,因为这是在已经参照图1讨论的过程中使用的优选咳嗽次数,即,在五次咳嗽已经在框12至18中被处理之后,框20转移到框24。
109.表1比较了现有技术过程(即,作为porter等人公开的主题)与本发明的前述实施例,其中处理器53不收集受试者症状,因此不执行图1的框2、4、6和26。相反,在框28将p2与阈值进行比较,并且在框30和32中做出的是否存在疾病的指示仅基于p2。
[0110][0111][0112]
表1:两种咳嗽诊断算法在成人呼吸疾病群中的表现
[0113]
表2比较了porter等人描述的诊断过程(包括使用受试者体征的补充)与参考图1描述的本发明实施例的表现。
[0114]
咳嗽声和临床症状集合
[0115][0116]
表2:两种咳嗽和体征诊断算法在成人呼吸疾病群中的表现
[0117]
从表1和表2可以观察到,根据本发明实施例的过程使得诊断表现得到改善。然而更重要的是,根据本发明的实施例避免了手工制作音频特征和手动构建复杂的分类系统的需要。
[0118]
图9是使用根据cnn训练软件140配置的台式计算机的一个或多个处理器和存储器实现的cnn训练机器133的框图。cnn训练机器133包括主板134,主板134包括用于供电和连
接一个或多个板载微处理器135的电路。
[0119]
主板134充当微处理器135和辅助存储器147之间的接口。辅助存储器147可以包括一个或多个光或磁或固态驱动器。辅助存储器147存储操作系统139的指令。主板134还与随机存取存储器(ram)150和只读存储器(rom)143通信。rom 143通常存储用于启动例程的指令,诸如基本输入输出系统(bios)或统一可扩展固件接口(uefi),微处理器135在启动时访问这些指令,并使微处理器135准备好加载操作系统139。
[0120]
主板134还包括用于驱动显示器147的集成图形适配器。主板133通常包括通信适配器153,例如lan适配器或调制解调器或串行或并行端口,其使服务器133与数据网络进行数据通信。
[0121]
cnn训练机器133的操作员167通过键盘149、鼠标121和显示器147与它交互。
[0122]
操作员167可以操作操作系统139来加载软件产品140。软件产品140可以被提供为承载在诸如光盘157的计算机可读介质上的有形的、非暂时性的机器可读指令159。可替代地,它也可以通过端口153下载。
[0123]
辅助存储器147通常由磁性或固态数据驱动器实现,并存储操作系统,例如microsoft windows和ubuntu linux桌面是这种操作系统的两个例子。
[0124]
辅助存储器147还包括软件产品140,是根据本发明实施例的cnn训练软件产品140。cnn训练软件产品140包括用于cpus 135(或者可替代地,统称为“处理器135”)的指令,以实现图10所示的方法。
[0125]
最初,在图10的框192,处理器135经由通信端口153从数据存储源检索训练受试者音频数据集,该数据集通常由包含主题音频和元数据的多个文件组成。元数据包括训练标签,即关于受试者的信息,例如年龄、性别等,以及受试者是否患有多种呼吸疾病中的每一种。
[0126]
在框194,识别与特定疾病相关的音频片段,诸如关于肺炎的咳嗽,或其他声音,例如关于哮喘的喘息声。识别每个受试者的数据中的咳嗽事件,例如以与之前在图1的框10中讨论的相同的方式。
[0127]
在框196,处理器135以与之前在图1的框14中讨论的相同方式将咳嗽事件表示为图像,其中创建梅尔谱图图像来表示每次咳嗽。
[0128]
在框198,处理器135变换每个梅尔谱图以创建附加的训练示例,用于后续训练卷积神经网络(cnn)。该数据扩充步骤是优选的,因为cnn是非常强大的学习器,并且利用有限数量的训练图像,它可以记住训练示例,从而过拟合模型。发明人已经认识到,这种模型不能很好地概括以前未见过的数据。所应用的图像变换包括但不限于小的随机缩放、裁剪和对比度变化。
[0129]
在框200,处理器135根据在框198产生的增强咳嗽图像和原始训练标签来训练cnn 142。通过使用正则化技术,诸如丢弃(dropout)、权重衰减和批量归一化,进一步减少了cnn的过拟合。
[0130]
用于产生cnn的过程的一个例子是采用预训练的resnet模型,该模型是包含快捷连接的残差网络,诸如resnet-18,并且使用该模型的卷积层作为主干,并且用适合该问题域的层替换最终的非卷积层。这些包括完全连接的隐藏层、丢弃层和批量标准化层。关于resnet-18的信息可在https://www.mathworks.com/help/deeplearning/ref/
resnet18.html(2019年12月2日检索)处获得,其公开内容通过引用并入本文。resnet-18是一个卷积神经网络,它对来自imagenet数据库(http://www.image-net.org)的超过一百万个图像进行训练。该网络有18层深,可以将图像分为1000个对象类别,诸如键盘、鼠标、铅笔和许多动物。因此,该网络已经学习了各种图像的丰富特征表示。网络的图像输入大小为224
×
224。
[0131]
发明人已经发现,固定resnet-18层并且仅训练新的非卷积层就足够了,然而,也可以重新训练resnet-18层和新的非卷积层以实现工作模型。优选使用0.5的固定丢弃率。自适应矩估计(adam)优选地用作自适应优化器,尽管也可以使用其他优化器技术。
[0132]
在框202,来自框196的原始(未增强的)咳嗽图像被应用到cnn 142,该cnn 142现在被训练以从训练的cnn 142得出指示特定疾病的每个咳嗽的概率。
[0133]
在框204,处理器135计算每个记录的咳嗽的平均概率,并认为它是每记录激活(per-recording activation)。
[0134]
在框206,每记录激活被用于计算阈值,该阈值提供了期望的表现特征,并且在图1的框28处被使用。
[0135]
被训练的cnn然后作为cnn 63被分发,作为疾病预测app 56的一部分。
[0136]
概括地说,在一个方面,提供了一种用于预测受试者52呼吸系统疾病存在的方法,所述疾病例如但不限于肺炎或哮喘。该方法包括操作至少一个电子处理器53,以将受试者的音频记录(诸如数字声音文件50)中与疾病相关的声音40的一个或多个片段(例如片段68a、68b)转换成相应的一个或多个图像表示,诸如表示74a、74b和76a、76b。该方法还包括操作至少一个电子处理器53,以将一个或多个图像表示(例如表示76a、76b)应用于至少一个模式分类器63,该模式分类器63已经被训练成根据图像表示来预测疾病的存在。该方法还包括操作至少一个电子处理器53,以基于模式分类器63的至少一个输出(图1的框18)生成受试者中疾病存在的预测(图1的框30和32)。例如,预测可以呈现在诸如屏幕78(图8)的屏幕上。
[0137]
在另一方面,提供了一种用于预测受试者中呼吸疾病存在的设备,所述呼吸疾病例如但不限于肺炎或哮喘。该设备包括音频捕获装置,例如麦克风75和音频接口71,以及由app 56的指令配置的处理器53,以将受试者52的数字音频记录存储在诸如存储器55或辅助存储器64的电子存储器中。例如由处理器53提供由app 56配置的声音片段-图像表示组件,以执行框14(图1)的过程,从而将识别的声音片段,例如与疾病相关的记录(诸如数字声音文件50)的片段68a、68b,转换成对应的图像表示,诸如图像表示76a、76b。
[0138]
该设备还包括至少一个模式分类器,例如图像模式分类器63,其与声音片段-图像表示组件通信,并且例如通过预训练被配置为处理图像表示以产生指示受试者声音片段预测具有呼吸疾病的概率的信号。
[0139]
根据法规,已经用或多或少特定于结构或方法特征的语言描述了本发明。术语“包括(comprises)”及其变体,例如“包括(comprising)”和“由
……
组成(comprised of)”在全文中以包含的意义使用,并且不排除任何附加特征。
[0140]
应当理解,本发明不限于所示出或描述的具体特征,因为这里描述的手段包括实施本发明的优选形式。因此,在本领域技术人员适当解释的所附权利要求的适当范围内,本发明以其任何形式或修改被要求保护。
[0141]
在整个说明书和权利要求书中(如果存在),除非上下文另有要求,术语“基本上”或“大约”将被理解为不限于该术语限定的范围值。
[0142]
本发明的任何实施例仅仅是示例性的,而不限制本发明。因此,应该理解,在不脱离本发明的范围的情况下,可以对所描述的任何实施例进行各种其他改变和修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1