一种对医疗数据中等级资料进行标准化的方法
本发明涉及医疗大数据技术领域,尤其涉及一种对医疗数据中等级资料进行标准化的方法。
背景技术:
近年来,我国在大数据科学领域取得了飞速的发展。但是,在医疗健康大数据领域仍存在着很多技术瓶颈。其中一个亟待解决的难题是如何对海量的健康数据进行有效的治理,以便挖掘出有用的信息造福人类健康。体检数据是医疗健康数据的一个非常重要的来源,其所涵盖的人群面十分广泛。对健康体检数据进行有效的治理和挖掘,将会对我国的慢性病防控等领域提供非常重要的科学参考。
健康体检数据主要包含了文本型数据、计量型数据和等级型数据这三种数据资料类型。等级资料指有一定级别的数据,如临床疗效分为治愈、显效、好转、无效,临床检验结果分为-、+、++、+++,疼痛等症状的严重程度分为0(无疼痛)、1(轻度)、2(中度)、3(重度)等。等级型数据由于不同单位的标准与描述方式不同,显得非常混乱。比如相同的等级型指标可能被记录为“-、±、+、++、+++、++++;阴性、弱阳性、阳性、强阳性;0.00(-)、10(弱阳)、500(+)、>10000”等形态各异的内容,导致数据难以通过分析转化为有价值的信息。而本发明能够很好地解决上面的问题。
技术实现要素:
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种对医疗数据中等级资料进行标准化的方法。
本发明解决其技术问题所采用的技术方案是:
本发明提供一种对医疗数据中等级资料进行标准化的方法,该方法包括以下步骤:
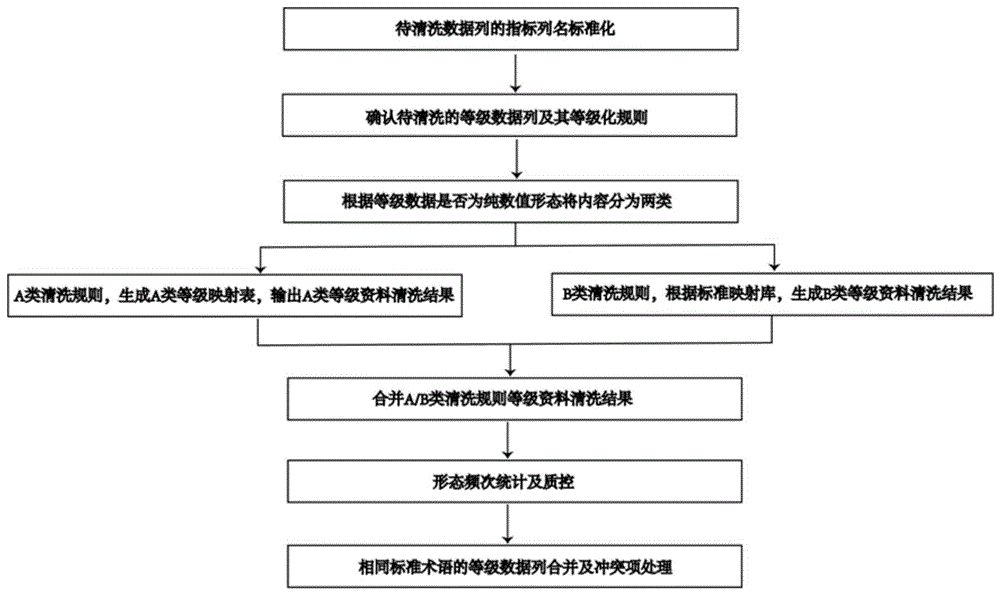
步骤1:获取来源于不同数据源单位的原始体检数据列,通过标准术语表进行列名标准化处理,得到标准化后的等级数据列;
步骤2:确定待清洗的等级数据列及其等级化规则;
步骤3:根据等级数据列中的数据是否为纯数值型数据分为两类,纯数值数据按照a类映射规则进行清洗,非纯数值数据按照b类映射规则进行清洗;
步骤4:a类映射规则:将数据列中属于纯数值形态的数据内容依据指标参考范围自动转化为相应的等级化形态;
步骤5:b类映射规则:将数据列中属于非纯数值形态的数据内容通过标准数据库替换为相应的等级化形态;
步骤6、通过a、b类映射规则清洗后,合并清洗结果并进行等级形态的频次统计,对清洗结果进行质控;
步骤7、合并等级化替换结果,进行合并结果后的冲突项校正,输出校正后的标准化数据。
进一步地,本发明的所述步骤1中列名标准化处理的具体方法为:
列名标准化给每一数据列匹配一个对应的标准术语,标准术语所属的资料类型包含了文本资料标准术语、计量资料标准术语和等级资料标准术语。
进一步地,本发明的所述步骤2的具体方法为:
标准化为等级资料术语的数据列将进入等级资料清洗流程,标准术语表制定了每一个等级资料术语对应的等级化标准,标准术语的等级化标准将等级资料的内容通过数字进行表述,从而能够将各种形态的等级化资料用一套统一的数字化标准进行标准化治理。
进一步地,本发明的所述步骤4的具体方法为:
a类映射规则即将该数据源单位给出的该指标的正常参考范围[a,b]通过算法自动转化为统一的区间形式:等级化形态1:(-∞,a)||||等级化形态2:[a,b]||||等级化形态3:(b,+∞);基于a类映射规则,等级数据列中的纯数值形态内容通过a类映射规则算法进行等级替换。
进一步地,本发明的所述步骤5的具体方法为:
b类映射规则是按照国家临床检验指南制定的一个专业数据库,其基本结构为标准术语名称-等级化规则-原始形态-对应的等级替换形态;基于b类映射规则,非纯数值形内容通过b类映射规则算法进行等级替换。
进一步地,本发明的所述步骤6的具体方法为:
通过算法对各标准术语下各数据列的等级形态频次进行统计,生成等级形态频次统计表,其形式为:标准术语名称-数据源单位/数据列-等级形态-等级形态频次-等级形态百分比。通过观察同一标准术语下的各数据列的等级形态分布比例是否异常实现对等级清洗结果的质控。
进一步地,本发明的所述步骤7的具体方法为:
将所有同一标准术语下的数据列进行合并,将同一患者对应有两个或两个以上相同标准术语下的不同等级形态标记为合并冲突,最后从合并冲突中选择唯一的、正确的等级形态。
本发明产生的有益效果是:本发明的对医疗数据中等级资料进行标准化的方法,通过对等级型体检数据进行标准化治理,最后得到整齐统一的数字化检验结果,大大提高了等级资料体检数据的有序性和可挖掘性。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例的等级资料数据清洗流程图;
图2是本发明实施例的具体实施例流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,将等级数据列中属于纯数值形态的数据内容通过指标参考范围自动转化为相应的等级化形态(a类映射规则替换),将数据列中属于非纯数值形态的数据内容通过标准映射库替换为相应的等级化形态(b类映射规则替换),合并等级化替换结果,进行质控及合并结果后的冲突项校正。
如图2所示的实施例,对标准术语为大便分析-红细胞的一列等级化数据,其原始形态包括了:-、±、+、++、+++、++++、阴性、弱阳性、阳性、强阳性、强强阳性、强强强阳性、0、2、4、12、18。通过等级清洗流程,可将原始形态最终替换为数字化的标准等级形态。
该方法包括以下步骤:
步骤1:对原始数据列通过标准术语表进行列名标准化处理。列名标准化会给每一数据列匹配一个最合适的标准术语。标准术语所属的资料类型包含了文本资料标准术语、计量资料标准术语和等级资料标准术语。
步骤2:标准术语表还制定了每一个等级资料术语对应的等级化标准。标准术语的等级化标准将等级资料的内容通过数字进行表述,从而能够将各种形态的等级化资料用一套统一的数字化标准进行标准化治理。本数据列的标准术语为:大便分析-红细胞,为等级资料术语,其等级化标准为:1:阴性(-)、2:弱阳性(±)、3:阳性(+)、4:强阳性(++)、5:强强阳性(+++)、6:强强强阳性(++++)。
步骤3:根据等级资料数据列中的形态是否为纯数值型,将数据列中的形态分为两类,即(1)纯数值型:0、2、4、12、18,这部分内容走a类规则进行等级替换;(2)非纯数值型:-、±、+、++、+++、++++、阴性、弱阳性、阳性、强阳性、强强阳性、强强强阳性,这部分内容走b类规则进行等级替换。纯数值形态内容和非纯数值形态的内容有各自的特点,宜按照不同的清洗规则进行清洗以提升清洗的效率及准确性。
步骤4:计算机程序根据该数据源单位(通常为医院体检中心)给出的相应指标参考值范围生成a类映射规则。a类映射规则即将该数据源单位给出的该指标的正常参考范围转化统一的区间形式,进而通过计算机可识别的语言,将等级资料数据列中的纯数值形态内容通过a类映射规则进行等级替换。若数据源单位对该数据列给出的参考范围为:-:0-3;±:3-5;+:5-10;++:10-15;++:15-20;+++:20-无穷大,则那么在计算机自动生成的a类映射表中,其a类映射规则就会记录为1:[0,3);2:[3,5);3:[5,10);4:[10,15);5:[15,20);6:[20,+∞)。通过a类映射规则,可将0、2等级替换为1,4等级替换为2,12等级替换为4,18等级替换为5。
步骤5:对于等级资料数据列中非纯数值形态的内容,通过进行b类映射规则替换。b类映射规则是按照国家临床检验指南制定的一个专业数据库,其基本结构为标准术语名称-等级化规则-原始形态-等级替换形态。比如对于大便分析-红细胞这一标准术语,b类映射规则中会注明其等级化标准以及原始形态和相应的等级替换形态的对应规则,如“-”、“阴性”“(-)”等形态对应为等级化形态“1”;“±”、“弱阳性”“(±)”等形态对于为等级化形态“2”等,以此类推。根据b类映射表,程序即可识别待清洗数据中的原始形态并将其转化为相应的等级化形态。本例中,通过b类映射规则表,可将-、阴性等级替换为1,±、弱阳性等级替换为2,+、阳性等级替换为3,++、强阳性等级替换为4,+++、强强阳性等级替换为5,++++、强强强阳性等级替换为6。
表1b类映射表
步骤6:完成a、b类映射替换后,程序将合并a、b类清洗规则等级替换后的资料,进行各标准术语下各数据列的等级形态频次统计,生成等级形态频次统计表。通过等级形态频次统计表可以观察同一标准术语下的各数据列的等级形态分布比例是否异常从而对等级替换结果的质控。
表2等级形态的频次统计表
步骤7:同一标准术语下(大便分析-红细胞)可能存在多个数据列,对标化为相同标准术语的数据列进行合并。若合并后同一患者id的同一标准术语下存在等级形态不一致的情况,则会被标记为合并冲突,最后从合并冲突中选择唯一的、正确的等级形态。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!