一种健康医疗数据的预处理方法及系统
本发明属于数据治理
技术领域:
,具体涉及一种健康医疗数据的预处理方法及系统。
背景技术:
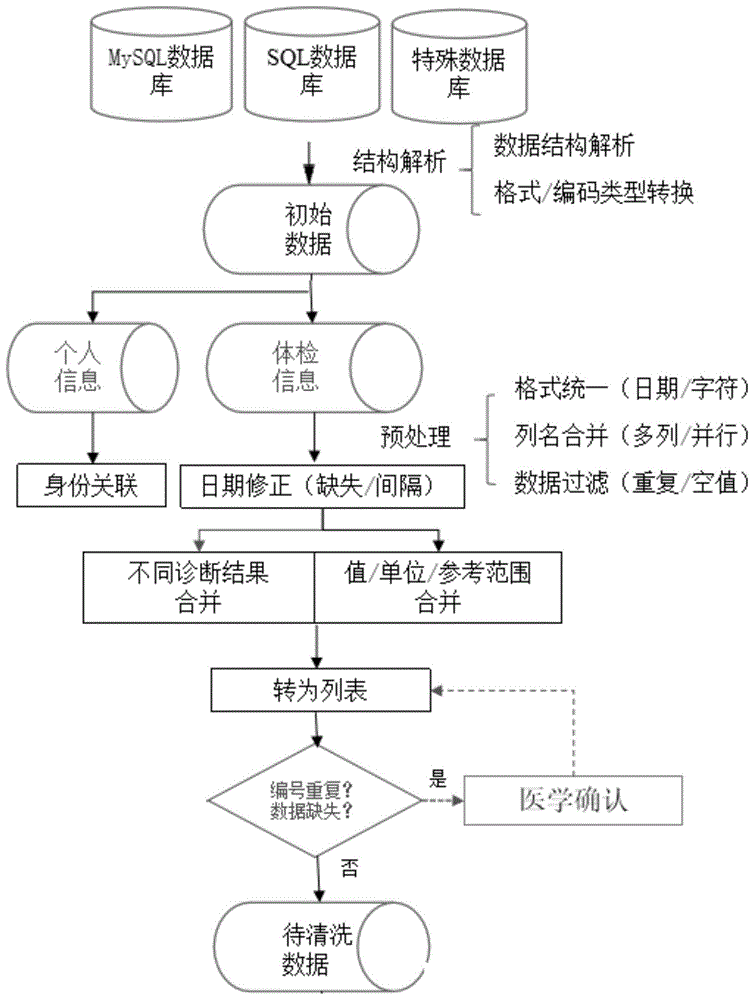
:随着医疗信息化的不断推进,医疗健康产业在大数据技术的支持下,对医疗资源高效整合和调整,具备巨大潜力。然而在真实世界中,数据常常出现不完整,结构复杂,信息冗余等问题。这些低质量的数据将导致数据治理的难度加大,因此需要一套完善的用于规范原始医疗数据的方法流程。这将大大提高数据的质量,数据治理的效率及医疗数据信息化的进展。目前健康大数据产业快速发展,而医疗数据的预处理尚无流程规范。不规范的原始数据无疑将降低包括人工及机器算法对数据治理的效率。数据预处理就是解决上面所提到的数据问题的可靠方法。技术实现要素:本发明的目的在于,提供一种健康医疗数据的预处理方法及系统,将不规范的原始数据规范化,提高数据的质量和数据治理的效率。本发明提供一种健康医疗数据的预处理方法,包括以下步骤:将原始体检数据保存为数据框形式,体检信息保存为字符串格式,生成体检行表,每行包括体检编号、体检时间、体检项目和体检结果;删除行表中重复的体检数据;为每个体检人员设定身份唯一码;若体检编号缺失,则根据身份唯一码和体检日期生成唯一体检编号;若体检时间缺失,则将同一次体检下的最早体检时间补齐到缺失体检时间处;同一体检编号下一定时间阈值内的体检数据视为一次体检;将体检数据中代表体检项目名称的列名用第一连字符合并在一起;将每项体检的结果、参考范围、量纲用第二连字符合并在一起;将行表形式的体检数据转化为列表。进一步地,行表转化为列表时,体检结果、参考范围、量纲分离存储。进一步地,根据身份证号、性别、电话号码、职业、居住地、身高信息进行逻辑判断身份唯一性,生成身份唯一码。进一步地,行表转化为列表后,列名按照医疗信息规律进行排序,然后人工审核并矫正数据。进一步地,第一连字符为“|”。进一步地,体检结果、参考范围、量纲合并在一起表示形式为:体检结果||||[参考范围]量纲。进一步地,若体检结果为空,则体检结果、参考范围、量纲合并在一起表示为“na”。进一步地,将原始体检数据读取入r软件保存为数据框形式。进一步地,生成体检行表之前,删除体检医生、检验仪器、体检地点。本发明还提供一种用于实现上述健康医疗数据的预处理方法的健康医疗数据的预处理系统,包括:行表生成模块,用于将原始体检数据保存为数据框形式,体检信息保存为字符串格式,生成体检行表,每行包括体检编号、体检时间、体检项目和体检结果;数据去重模块,用于删除行表中重复的体检数据;身份唯一码模块,用于为每个体检人员设定身份唯一码;编号补齐模块,用于若体检编号缺失,则根据身份唯一码和体检日期生成唯一体检编号;时间补齐模块,用于若体检时间缺失,则将同一次体检下的最早体检时间补齐到缺失体检时间处;同一体检编号下一定时间阈值内的体检数据视为一次体检;项目合并模块,用于将体检数据中代表体检项目名称的列名用第一连字符合并在一起;结果合并模块,用于将每项体检的结果、参考范围、量纲用第二连字符合并在一起;列表转化模块,用于将行表形式的体检数据转化为列表。本发明的有益效果是:本发明的健康医疗数据的预处理方法及系统,针对医疗机构或数据中心数据存储的特点及医疗信息产生的自身特点,结合数据预处理技术,对预处理过程中的重复数据清洗、异常数据检测、身份唯一以及身份关联进行流程的制定,将不规范的原始数据规范化,有助于医疗大数据规范治理工作的进行。附图说明图1是本发明的健康医疗数据的预处理方法的流程图。具体实施方式下面将结合附图对本发明作进一步的说明:本发明实施例的健康医疗数据的预处理方法,如图1所示,包括以下步骤:s1、根据医疗机构存储数据生成初始化数据,对初始数据进行结构解析,及格式/编码类型转换,删除无意义或无关数据内容。将原始数据读取入r软件保存为数据框形式,日期保留为日期格式,其余信息保存为字符串格式,生成行表,如表1所示。在生成行表之前,将无意义的数据,例如检验医生,检查地点、检验仪器等无关信息删除。其中,r软件,一种自由软件编程语言与操作环境,主要用于统计分析、绘图、数据挖掘。表1行表体检编号体检时间体检大类名称体检项目id检测项目名称结果099900072011/7/270:00普检106普检正常099900072011/7/270:00腹部b超106腹部b超正常099900072011/7/270:00心电图106心电图正常099900072011/7/270:00心电图106心电图正常099900072011/7/270:00颈椎侧位片106颈椎侧位片正常s2、将数据中重复出现的数据删除,主要利用duplicated函数。对数据进行数据过滤,去重复,去掉空值。其中,表1的心电图体检数据重复出现,故需将心电图的一行数据删除。表2数据去重后的行表体检编号体检时间体检大类名称体检项目id检测项目名称结果099900072011/7/270:00普检106普检正常099900072011/7/270:00腹部b超106腹部b超正常099900072011/7/270:00心电图106心电图正常099900072011/7/270:00颈椎侧位片106颈椎侧位片正常s3、设定身份唯一码。根据身份证号、性别、电话号码、职业、居住地、身高等基本信息属性进行逻辑判断身份唯一性,生成身份唯一码。将属于同一人的不同体检数据关联起来,便于对个人数据再不同来源下依旧可以进行整合判断。s4、体检编号缺失的补充。若某一项数据的体检编号缺失,则基于身份唯一码及体检日期生成唯一体检编号。体检编号为一位体检人员一次体检记录的识别编码。目的为确定每人次每次的医疗信息独立性,进一步避免数据冗余,便于追踪个人健康状况s5、体检日期缺失的补充。判断同一次体检(同一个体检编号下一定时间阈值内医疗信息判断为一次体检信息,合并不同诊断结果)的体检数据中体检日期是否有缺失,若是体检日期存在缺失,则将同一次体检下的最早体检日期补齐到缺失体检日期处。s6、将体检数据,用dplyr包中的unite函数将代表体检项目名称的列名用连字符“|”合并到一起,去重复后将所有指标列名保存。例如,表1中代表项目名称的列名可以表示为:体检项目id|体检大类名称|体检项目名称,又如表3的结果一列。s7、将体检结果,参考范围,量纲三列合并。将参考范围格式调整为[参考范围],将量纲放在参考范围后面([参考范围]量纲),若是合并后的结果为“”,则赋值为“na”。再把体检结果和[参考范围]量纲用“||||”连接起来(体检结果||||[参考范围]量纲),例如葡萄糖检测结果表示为:5.03||||[3.6-6.11]mol/l,若是合并后的结果为“”,则赋值为“na”。将检查项目与检查指标合并,便于列表转置和数据查询。s8、将行表形式的体检数据,如表3所示,用reshape2函数包里的dcast函数转化为列表,以“publishid”和“physicaldate”为id,转化所有的指标列名为列表。此时体检数据中的数值/单位/参考值可以分离存储,便于后续数据清洗。表3行表形式publishedphysicaldatecolname提示11070101422011/7/3040001|妇检|外阴正常11070101422011/7/3040002|妇检|阴道正常11070101422011/7/3040003|妇检|分泌物量正常11070101422011/7/3040005|妇检|宫颈正常11070101422011/7/3040005|妇检|宫体正常表4列表形式s9、输出指标列名由人工按照医疗信息规律进行指标排序,再转置为列表输出。此步骤输出结果符合医疗信息记录产生特点,减少数据储存容量,便于后续数据治理和数据挖掘。最后人工审核并矫正编号重复,数据缺失等异常情况。本发明还提供一种用于实现上述健康医疗数据的预处理方法的健康医疗数据的预处理系统,包括:行表生成模块,用于将原始体检数据保存为数据框形式,体检信息保存为字符串格式,生成体检行表,每行包括体检编号、体检时间、体检项目和体检结果;数据去重模块,用于删除行表中重复的体检数据;身份唯一码模块,用于为每个体检人员设定身份唯一码;编号补齐模块,用于若体检编号缺失,则根据身份唯一码和体检日期生成唯一体检编号;时间补齐模块,用于若体检时间缺失,则将同一次体检下的最早体检时间补齐到缺失体检时间处;同一体检编号下一定时间阈值内的体检数据视为一次体检;项目合并模块,用于将体检数据中代表体检项目名称的列名用第一连字符合并在一起;结果合并模块,用于将每项体检的结果、参考范围、量纲用第二连字符合并在一起;列表转化模块,用于将行表形式的体检数据转化为列表。本发明的健康医疗数据的预处理方法及系统适应于不规范存储的医疗原始数据的初步处理,包括数据的格式和内容调整,以及身份唯一检验及身份关联,便于医疗信息的去冗余,去复杂,最终有助于医疗信息化,为医疗信息化及健康大数据治理提供有力保障。本领域的技术人员容易理解,以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1