基于机器学习算法对废气处理率进行预测的方法及系统与流程
1.本发明涉及废气处理技术领域,尤其是指一种基于机器学习算法对废气处理率进行预测的方法及系统。
背景技术:
2.废气处理主要是指针对工业场所产生的工业废气诸如粉尘颗粒物、烟气烟尘、异味气体、有毒有害气体进行治理的工作。常见的废气处理有工厂烟尘废气净化、车间粉尘废气净化、有机废气净化、废气异味净化、酸碱废气净化、化工废气净化等。常用的方法有水吸收法、曝气式活性污泥脱臭法、多介质催化氧化工艺,由于废气对空气的污染非常严重,因此,环保部门制定了严格的要求,要求废气处理达标后才能进行排放。但是目前缺少对废气处理率进行预测的方法,导致企业在废气处理前无法对废气处理率进行预测,容易发生废气排放不达标的问题,如此空气污染问题依然困扰着很多企业。
3.因此,迫切需要寻求一种基于机器学习算法对废气处理率进行预测的方法,以便企业在废气处理前能够对废气处理率进行预测,有效避免废气排放不达标的问题。
技术实现要素:
4.为此,本发明所要解决的技术问题在于克服现有技术中因在废气处理前无法对废气处理率进行预测而导致的废气排放不达标的问题。
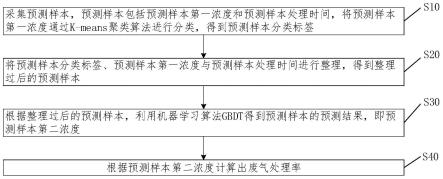
5.为解决上述技术问题,本发明的一个目的提供了一种基于机器学习算法对废气处理率进行预测的方法,包括:
6.采集预测样本,预测样本包括预测样本第一浓度和预测样本处理时间,将所述预测样本第一浓度通过k-means聚类算法进行分类,得到预测样本分类标签;
7.将所述预测样本分类标签、预测样本第一浓度与预测样本处理时间进行整理,得到整理过后的预测样本;
8.根据所述整理过后的预测样本,利用机器学习算法gbdt得到预测样本的预测结果,即预测样本第二浓度;
9.根据所述预测样本第二浓度计算出废气处理率。
10.在本发明的一个实施例中,将所述预测样本第一浓度通过k-means聚类算法进行分类包括:
11.在预测样本第一浓度的数据集中随机选取k个预测样本数据作为起始的聚类中心μi,其中k=3,聚类中心分别为μ1、μ2和μ3,μ1、μ2和μ3分别表示高浓度、中浓度和低浓度;
12.分别计算数据集中每个预测样本数据xi到3个聚类中心的距离,计算公式为:式中,μi为聚类中心,xj为预测样本数据,j为预测样本数据索引;
13.根据计算得到的距离将预测样本数据xj划分至距离最近的聚类中心,使用欧拉公
式重新计算聚类中心,欧拉公式为:其中xi,xj为两条离散的预测样本数据,x
iu
、x
ju
分别为xi、xj在字段索引u上的取值;
14.重复所述聚类过程,直至算法收敛,得到聚类结果。
15.在本发明的一个实施例中,根据所述整理过后的预测样本,基于机器学习算法gbdt得到预测样本的预测结果,即预测样本第二浓度包括:
16.采集训练样本,训练样本包括训练样本分类标签、训练样本第一浓度、训练样本处理时间和训练样本第二浓度;
17.将所述训练样本整理为训练集样本,记为t={(x1,y1),(x2,y2),...,(xi,yi)},其中xi为训练数据的输入值,yi为训练数据的输出值,i为数据索引;
18.输入训练数据集t、损失函数l及最大迭代次数t,其中损失函数为l(y,f(x));
19.对弱学习器f0(x)进行初始化,式中c为常数,yi为训练数据的输出值,i为数据索引,n为数据的个数;
20.通过t次迭代计算更新强学习器fn(x),输出强学习器fn(x)的表达式,得到预测样本第二浓度。
21.在本发明的一个实施例中,通过t次迭代计算更新强学习器fn(x),输出强学习器fn(x)的表达式,得到预测样本第二浓度包括:
22.对样本i=1,2,...,n,计算负梯度r
n,i
,式中i为数据索引,f(x)为学习器得到的预测值,l(y,f(x))为损失函数,m为分类回归树索引;
23.利用cart回归树拟合数据(xi,r
n,i
),得到第n棵回归树,其对应的叶子节点区域为r
n,j
,其中j=1,2,...,jn,jn为第n棵回归树叶子节点的个数;
24.对于jn个叶子节点区域j=1,2,...,jn,计算最佳拟合值c
n,j
,式中f(x)为学习器得到的预测值,l(y,f(x))为损失函数,c为常数,r
n,j
为叶子节点区域;
25.更新强学习器fn(x),式中c
m,j
为最佳拟合值,r
m,j
为叶子节点区域,i为指示函数;
26.输出强学习器fn(x)的表达式:式中f0(x)为初始化的弱学习器,m为分类回归树索引,m为最大树索引,j=1,2,...,jm,jm为第m棵回归树叶子节点的个数,c
m,j
为最佳拟合值,i为指示函数;
27.得到预测样本第二浓度。
28.在本发明的一个实施例中,根据所述预测样本第二浓度计算出废气处理率的计算公式如下:
[0029][0030]
式中,s0为预测样本第二浓度,s为预测样本第一浓度,a为废气处理率。
[0031]
本发明的另一目的提供了一种基于机器学习算法对废气处理率进行预测的系统,包括:
[0032]
采集模块,所述采集模块用于采集预测样本,预测样本包括预测样本第一浓度和预测样本处理时间,将所述预测样本第一浓度通过k-means聚类算法进行分类,得到预测样本分类标签;
[0033]
整理模块,所述整理模块用于将所述预测样本分类标签、预测样本第一浓度与预测样本处理时间进行整理,得到整理过后的预测样本;
[0034]
预测模块,所述预测模块用于根据所述整理过后的预测样本,利用机器学习算法gbdt得到预测样本的预测结果,即预测样本第二浓度;
[0035]
计算模块,所述计算模块用于根据所述预测样本第二浓度计算出废气处理率。
[0036]
本发明的上述技术方案相比现有技术具有以下优点:
[0037]
本发明利用机器学习算法gbdt预测得到预测样本第二浓度,并计算出废气处理率,如此在废气处理前能够对废气处理率进行预测,有效避免废气排放不达标的问题,而且利用k-means聚类算法对预测样本进行分类,能够对不同的预测样本进行合理准确的预测,显著提高了预测的准确度。
附图说明
[0038]
为了使本发明的内容更容易被清楚的理解,下面根据本发明的具体实施例并结合附图,对本发明作进一步详细的说明,其中
[0039]
图1是本发明实施例中一种基于机器学习算法对废气处理率进行预测的方法的流程示意图。
[0040]
图2是本发明实施例中一种基于机器学习算法对废气处理率进行预测的系统的结构示意图。
[0041]
说明书附图标记说明:100、采集模块;200、整理模块;300、预测模块;400、计算模块。
具体实施方式
[0042]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0043]
请参阅图1所示,图1是本发明实施例公开的一种基于机器学习算法对废气处理率进行预测的方法的流程图。其样本数据中编号为1-2的样本数据为训练样本,编号为3的样本数据为预测样本,且预测样本中预测样本第二浓度为预测值。
[0044]
基于上述的样本数据,本发明实施例一种基于机器学习算法对废气处理率进行预测的方法包括如下步骤:
[0045]
步骤s10中:采集预测样本,预测样本包括预测样本第一浓度和预测样本处理时间,将预测样本第一浓度通过k-means聚类算法进行分类,得到预测样本分类标签。
[0046]
示例的,本发明首先将预测样本第一浓度通过k-means聚类算法进行分类,得到预测样本分类标签,例如高浓度样本、中浓度样本或低浓度样本,如此能够对不同的预测样本进行合理准确的预测,用于提高预测的准确度。具体聚类过程如下:
[0047]
步骤s11:在预测样本第一浓度的数据集中随机选取3个预测样本数据作为起始的聚类中心μ1、μ2和μ3,μ1、μ2和μ3分别表示高浓度、中浓度和低浓度;
[0048]
步骤s12:分别计算数据集中每个预测样本数据xi到3个聚类中心的距离,计算公式为:式中,μi为聚类中心,xj为预测样本数据,j为预测样本数据索引;
[0049]
步骤s13:根据计算得到的距离将预测样本数据xj划分至距离最近的聚类中心,使用欧拉公式重新计算聚类中心,欧拉公式为:其中xi,xj为两条离散的预测样本数据,x
iu
、x
ju
分别为xi、xj在字段索引u上的取值;
[0050]
步骤s14:重复所述聚类过程,直至算法收敛,得到聚类结果,即预测样本分类标签,
[0051]
步骤s20:将预测样本分类标签、预测样本第一浓度与预测样本处理时间进行整理,得到整理过后的预测样本。
[0052]
示例地,整理过后的预测样本为编号3的样本数据,数据为预测样本分类标签、预测样本第一浓度、预测样本处理时间和预测样本第二浓度,其中预测样本第一浓度和预测样本处理时间为设定值,预测样本分类标签为通过k-means聚类算法进行分类得到的分类结果,预测样本第二浓度为预测值。
[0053]
步骤s30:根据整理过后的预测样本,利用机器学习算法gbdt得到预测样本的预测结果,即预测样本第二浓度。
[0054]
示例地,利用机器学习算法gbdt得到预测样本的预测结果具体包括:
[0055]
步骤s31:采集训练样本,训练样本包括训练样本分类标签、训练样本第一浓度、训练样本处理时间和训练样本第二浓度,将所述训练样本整理为图2所示的编号为1-2的样本数据;
[0056]
步骤s32:设置学习率为1、最大迭代次数t为3,树的深度为2,损失函数l,其中损失函数为l(y,f(x));
[0057]
步骤s33:对弱学习器f0(x)进行初始化:式中c为常数,yi为训练数据的输出值,i为数据索引,n为数据的个数;其中损失函数为平方函数,直接求导,倒数等于零,得到c,
[0058]
步骤s34:对迭代轮数n=1,2,3,计算负梯度r
n,i
,式中i为数据索引,f(x)为学习器得到的预测值,l(y,f(x))为损失函数,m为分类回归树索引。这里损失函数为平方损失,即负梯度就是残差,然后将残差作为样本的真实值来训练弱学
习器f1(x),接着,寻找回归树的最佳划分节点,遍历每个样本数据的每个可能取值,从编号为1的训练样本分类标签开始,到编号为2的训练样本处理时间,计算分裂后一组数据的平方损失,找到使平方损失最小的那个划分节点,即得到第一课树的样子,由于我们设置的树的深度为1,此时树的深度满足了设置,然后计算最佳拟合值c
n,j
,式中f(x)为学习器得到的预测值,l(y,f(x))为损失函数,c为常数,r
n,j
为叶子节点区域;这里其实和上面初始化学习器是一个道理,求导,令导数等于零,化简之后得到每个叶子节点的参数,其实就是样本第二浓度的均值,需要说明的是,这里的样本第二浓度不是原始值y,而是本轮要拟合的残差。这时候更新强学习器fn(x),需要用到学习率为1,式中c
m,j
为最佳拟合值,r
m,j
为叶子节点区域,i为指示函数;重复此步骤,直至最后生成3颗树。
[0059]
步骤s35:输出强学习器fn(x)的表达式:式中f0(x)为初始化的弱学习器,m为分类回归树索引,m为最大树索引,j=1,2,...,jm,jm为第m棵回归树叶子节点的个数,c
m,j
为最佳拟合值,i为指示函数。
[0060]
步骤s36:得到预测样本第二浓度。
[0061]
步骤s40:根据预测样本第二浓度计算出废气处理率。
[0062]
示例地,根据预测样本第二浓度计算出废气处理率的计算公式如下:
[0063][0064]
式中,s0为预测样本第二浓度,s为预测样本第一浓度,a为废气处理率。
[0065]
综上,本发明利用机器学习算法gbdt预测得到预测样本第二浓度,并计算出废气处理率,如此在废气处理前能够对废气处理率进行预测,有效避免废气排放不达标的问题,而且利用k-means聚类算法对预测样本进行分类,能够对不同的预测样本进行合理准确的预测,显著提高了预测的准确度。
[0066]
参阅图2所示,本发明的另一实施例提供了一种基于机器学习算法对废气处理率进行预测的系统,包括:
[0067]
采集模块100,采集模块100用于采集预测样本,预测样本包括预测样本第一浓度和预测样本处理时间,将预测样本第一浓度通过k-means聚类算法进行分类,得到预测样本分类标签;
[0068]
整理模块200,整理模块200用于将预测样本分类标签、预测样本第一浓度与预测样本处理时间进行整理,得到整理过后的预测样本;
[0069]
预测模块300,预测模块300用于根据整理过后的预测样本,利用机器学习算法gbdt得到预测样本的预测结果,即预测样本第二浓度;
[0070]
计算模块400,计算模块400用于根据预测样本第二浓度计算出废气处理率。
[0071]
显然,上述实施例仅仅是为清楚地说明所作的举例,并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变
动仍处于本发明创造的保护范围之中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1