基于深度学习的充血性心力衰竭自动诊断方法与流程
本发明涉及充血性心力衰竭检测技术领域,具体涉及一种基于深度学习的充血性心力衰竭自动诊断方法。
背景技术:
充血性心力衰竭是全球慢性心血管疾病的重要组成部分,主要是由于各种心脏疾病导致心脏结构或功能紊乱,进而使心脏无法向其他组织和器官输送足够的富氧血液而引起的一组临床综合征。心室泵送功能不足,还会导致血液和体液回流到患者的肺部和身体里,从而导致患者呼吸窘迫和全身肿胀。充血性心力衰竭是造成全球死亡率和发病率的主要因素,也是导致医疗支出增加的重要因素。其具有高发病率、高医疗诊治花费、高死亡率、预后差的特点,已成为全球范围内的重大公共卫生问题。充血性心力衰竭的诊断是一种临床诊断,需要综合患者的症状和体征来判断。心电图是一种非侵入性的检查,可以记录患者的心脏活动。通常情况下,都需要心脏病学方面的专家亲自查看患者的心电图信号,检测信号中是否存在异常,才能判断患者是否患有充血性心力衰竭。但是这种人工对心电图进行视觉检查评估是很浪费时间的,也会受到观察者的不同而产生一些差异。因此,利用机器学习技术自动学习获取知识来进行充血性心力衰竭诊断,以为医生进一步治疗提供参考依据是具有重要意义的。
目前,已经有很多学者提出了利用机器学习技术实现充血性心力衰竭诊断的方法。他们主要使用基于特征提取的机器学习方法,通过将提取的特征(例如形态特征、时域特征、频域特征等)输入到分类器中进行诊断。为了得到更好的分类结果,其通常需要结合多个特征参数对模型进行训练。例如支持向量机(svm)、决策树、随机森林等算法都已经成功应用于分析、检测和分类心力衰竭。这种基于特征提取的机器学习算法,严重依赖于人类经验,并且需要进行复杂的特征提取和特征选择工作。相较而言,深度学习算法更具有优势。现有的基于深度学习技术实现充血性心力衰竭诊断的研究相对较少,且大多都是基于卷积神经网络(cnn)实现的。cnn只能捕获心电信号的局部特征,而心电图本质上其实是一种时间序列数据,利用cnn并不能很好的捕获心电信号的全局特征和长短期依赖。目前的研究都未能解决这一问题,因此构建一种在捕获心电信号局部特征的同时,也能捕获心电信号的序列特征和全局特征的技术至关重要。
技术实现要素:
本发明要解决的技术问题是:克服现有技术的不足,提供一种提高充血性心力衰竭诊断的准确性,为医生进一步治疗提供了有效的参考依据的基于深度学习的充血性心力衰竭自动诊断方法。
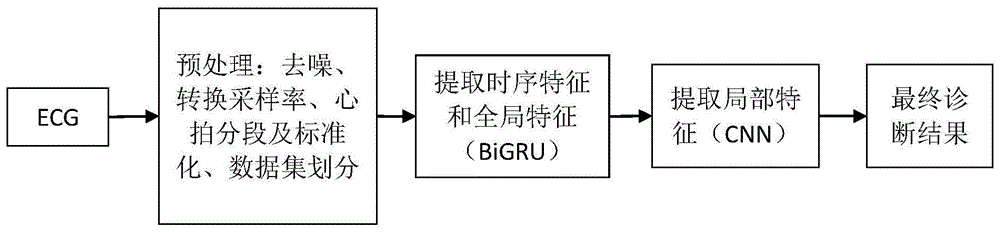
本发明为解决其技术问题所采用的技术方案为:基于深度学习的充血性心力衰竭自动诊断方法,包括以下步骤:
步骤一、获取两组心电图数据,其中一组数据为正常组,另一组为心衰组,对两组心电图数据进行处理;
步骤二:构建深度学习模型;
步骤三:对模型进行训练,进一步优化模型;
步骤四:评估模型的分类准确性。
所述步骤一中心电图数据存储在physiobank数据库中,从physiobank数据库中获取心电图数据,将心电图数据分为正常组和心衰组两类数据,然后进行数据预处理,预处理包括去噪、转换采样率、心拍分段及标准化、数据集划分。
步骤一种将数据划分为训练集、验证集及测试集。
步骤二中深度学习模型主要基于双向循环神经网络和卷积神经网络构建。
所述本发明所使用的双向循环神经网络为双向门控循环单元网络bigru,其主要是用来提取心电信号的时序特征和全局特征。步骤二包括以下子步骤:
2-1:时序特征和全局特征的提取:将bigru层的输出拼接成矩阵,作为卷积神经网络的输入;
2-2:局部特征的提取:使用两种不同大小的卷积核来提取心电信号不同位置的不同长度的局部特征,并同时使用最大池化和平均池化两种池化方式来减少特征信息的丢失,以获得更加全面、完整的心电信号特征;
2-3:进行充血性心力衰竭诊断:经过flatten层,将池化层的输出转化为一维特征向量,经过两个全连接层进行降维,利用输出层得到分类结果,即充血性心力衰竭的诊断结果。
利用训练集的数据对模型进行训练,学习模型的参数,利用验证集调节模型的超参数,进一步优化模型。
利用测试集进行模型性能评估,进一步评估模型的分类准确性。
与现有技术相比,本发明具有以下有益效果:
本发明提供一种基于深度学习的充血性心力衰竭自动诊断方法,提出了一种基于深度学习的充血性心力衰竭自动诊断方法,以期能在不做复杂的特征提取和特征选择工作的前提下,实现更加有效的充血性心力衰竭自动诊断;
基于深度学习完成了心电信号的时序特征、局部特征以及全局特征的自动提取,可以学习到更加全面、完整的心电信号特征,提高充血性心力衰竭诊断的准确性,为医生进一步治疗提供了有效的参考依据;
本发明提出的方法不需要经过复杂的特征提取和特征选择工作,利用深度学习技术就可以实现特征的自动提取,节省了大量的人力资源和时间,具有较高的效率;
本发明将双向循环神经网络和卷积神经网络进行了有效的融合。利用双向循环神经网络可以在考虑心电信号时间序列的同时有效地学习到心电信号的全局特征;利用具有不同大小的卷积核的卷积神经网络,则可以提取到心电信号不同位置的不同长度的局部特征。特别地,为了减少特征信息的丢失,本发明同时采用了最大池化和平均池化。最终,本发明可以提取出更加全面的心电信号特征,为充血性心力衰竭的诊断提供了有力的支撑,从而使诊断的准确性大大提升。
附图说明
图1是本发明流程图。
图2是本发明基于深度学习的模型图。
具体实施方式
下面结合附图对本发明实施例做进一步描述:
实施例
如图1至图2所示,包括以下步骤:
步骤一、获取两组心电图数据,其中一组数据为正常组,另一组为心衰组,对两组心电图数据进行处理;
步骤二:构建深度学习模型;
步骤三:对模型进行训练,进一步优化模型;
步骤四:评估模型的分类准确性。
所述步骤一中心电图数据存储在physiobank数据库中,从physiobank数据库中获取心电图数据,将心电图数据分为正常组和心衰组两类数据,然后进行数据预处理,预处理包括去噪、转换采样率、心拍分段及标准化、数据集划分。
步骤一种将数据划分为训练集、验证集及测试集。
步骤二中深度学习模型主要基于双向循环神经网络和卷积神经网络构建。
所述本发明所使用的双向循环神经网络为双向门控循环单元网络bigru,其主要是用来提取心电信号的时序特征和全局特征。步骤二包括以下子步骤:
2-1:时序特征和全局特征的提取:将bigru层的输出拼接成矩阵,作为卷积神经网络的输入;
2-2:局部特征的提取:使用两种不同大小的卷积核来提取心电信号不同位置的不同长度的局部特征,并同时使用最大池化和平均池化两种池化方式来减少特征信息的丢失,以获得更加全面、完整的心电信号特征;
2-3:进行充血性心力衰竭诊断:经过flatten层,将池化层的输出转化为一维特征向量,经过两个全连接层进行降维,利用输出层得到分类结果,即充血性心力衰竭的诊断结果。
利用训练集的数据对模型进行训练,学习模型的参数,利用验证集调节模型的超参数,进一步优化模型。
利用测试集进行模型性能评估,进一步评估模型的分类准确性。
该方法主要基于两种网络,包括双向循环神经网络和卷积神经网络。其中,双向循环神经网络主要是用来提取心电信号的时序特征和全局性特征,而卷积神经网络则是用来提取局部特征。本发明会利用不同大小的卷积核对心电信号进行处理,来提取心电信号不同位置的不同长度的局部特征;还会将最大池化和平均池化相结合,来减少特征信息的丢失。这样可以更好的提取心电信号的特征,实现有效的充血性心力衰竭检测。
实施例2
如图1至2所示,在实施例1的基础上,步骤一包括以下子步骤:
步骤1-1:从mit-bih心电数据库中的normalsinusrhythmdatabase(nsrdb)数据库和fantasia数据库中获取正常组数据。其中nsrdb数据库包含了18名健康人员的心电图记录,采样频率为128hz;fantasia数据库包含了40名健康人员的心电图记录,采样频率为250hz。再从bethisraeldeaconessmedicalcenter(bidmc)的congestiveheartfailuredatabase(chfdb)数据库中获取心衰组数据。该数据库共包含15名心衰分级为nyha3级到4级的心衰病人的心电图信号记录,其采样频率为250hz,数据记录时长为20小时。
步骤1-2:对数据进行去噪处理:心电信号在采集的过程中会不可避免的受到各种因素影响产生噪声,故本发明利用小波变换对心电数据进行了去噪处理。
步骤1-3:转换采样频率:本发明所使用的数据采样频率并不一致,其中fantasia数据库和chfdb数据库的采样频率均为250hz,而nsrdb数据库的采样频率为128hz,所以需对nsrdb数据库中的心电信号进行采样频率的转换,以使频率统一为250hz。
步骤1-4:心拍分段及标准化:本发明没有进行r峰检测,直接将心电图记录以2s进行分割,获取心拍数据。这样一个心拍的心电数据就是500个采样点组成的一段波形片段。再对数据进行标准化。本发明使用z-score标准化,将心电数据转化为符合标准差为1、均值为0的标准正态分布。
步骤1-5:划分数据集。本发明将数据集划分为训练集、验证集以及测试集。
步骤二中所构建的深度学习模型主要是基于双向循环神经网络和卷积神经网络。具体地,本发明使用的双向循环神经网络是双向门控循环单元网络(bigru),其主要是用来提取心电信号的时序特征和全局特征。然后,本发明将bigru层的输出拼接成矩阵,作为卷积神经网络的输入。特别地,本发明使用了两种不同大小的卷积核来提取心电信号不同位置的不同长度的局部特征,并同时使用最大池化和平均池化两种池化方式来减少特征信息的丢失,以获得更加全面、完整的心电信号特征。然后,经过flatten层,将池化层的输出转化为一维特征向量。再经过两个全连接层进行降维,最后利用输出层得到分类结果,即充血性心力衰竭的诊断结果。结合图2,模型构建的详细过程如下
时序特征和全局特征的提取:
本发明利用双向门控循环单元网络来提取心电信号的时序特征和全局特征。bigru因其双向计算的特点,可以获取目标序列的“左序列”和“右序列”的特征信息。它的基本思想是将每一个目标序列向左和向右输入到两个门控循环单元网络(gru),且这两个网络连接着同一个输出层。具体地说,bigru是在gru网络上添加了反向运算,即将输入序列进行反转,重新按照gru方式进行计算,最终的输出结果是正向gru和反向gru的输出的拼接。gru是长短期记忆网络(lstm)的一种变体,比lstm的结构要简单。gru中有两个门:更新门和重置门。更新门是用来决定更新多少信息,其值越大,则用候选值
ut=σ(wu·[ht-1,xt]+bu)
rt=σ(wr·[ht-1,xt]+br)
ht=ct
其中wu、wr、wc是权重矩阵,bu、br、bc是偏置向量;ut、rt分别代表更新门和重置门;
通过将每个时刻正向gru的隐藏状态和反向gru的隐藏状态拼接,可以得到bigru网络的输出。t时刻bigru网络的输出
其中
然后,再将bigru网络所有时刻的输出拼接成一个矩阵,作为卷积神经网络的输入。局部特征的提取:
局部特征的提取主要依赖于卷积神经网络。首先,本发明使用的卷积核的宽度与bigru输出的特征向量的维度一样。本发明使用不同大小的多个卷积核提取丰富的局部特征。令
c/k=f(wk·xi:i+s-1+bk),5=1,2,…,k,i=1,2,…,n-s+1
其中w0为卷积核,b0为偏置项;xi:i+s-1为输入矩阵中第i列到第i+s-1列组成的矩阵;n为输入矩阵的长度;f为激活函数,本发明中使用的是relu函数;cik为卷积运算的结果。
在经过卷积神经网络后,需要利用池化层来进一步对输出特征进行降维。为了减少特征信息的丢失,本发明同时采用了最大池化操作和平均池化操作。最大池化层是对窗口内的数据取最大值,而平均池化层是对窗口内数据取平均。对于不同的卷积层所得到的特征,池化窗口尺寸分别为1×10、1×8。
进行充血性心力衰竭诊断:
本发明将充血性心力衰竭诊断问题视为二分类问题。为了得到诊断结果,首先需要经过flatten层将池化层的输出结果转化为一维向量,再经过两个全连接层进行进一步的降维,最后经过输出层得出分类结果。输出层的公式表达如下:
其中wo为权重矩阵,bo为其偏置项,v为前一个全连接层的输出,σ为sigmoid函数,
步骤三、利用训练集的数据对模型进行训练,学习模型的参数,并利用验证集数据调节模型的超参数,进一步优化模型。在训练时,使用的损失函数如下:
其中m为批尺寸,y表示患者是否患有充血性心力衰竭的真实情况,
步骤四、利用测试集数据进行模型性能评估,进一步评估模型的分类准确性。测试集中的心电信号所属类别在预测时应当做未知,等到预测出结果后,用于检测预测结果的正确性。
- 还没有人留言评论。精彩留言会获得点赞!