一种基于多中心模型的精神分裂症分类方法及系统
本发明涉及神经疾病诊断技术领域,尤其涉及一种基于多中心模型的精神分裂症分类方法及系统。
背景技术:
精神分裂症是一种严重的精神疾病,客观的辅助检查手段是精神分裂症早期诊断的基础,并且有助于精神分裂症的治疗和改善预后。大量的研究表明精神分裂症患者与正常人的大脑结构存在差异,因此目前普遍采用磁共振成像(mri)获得全面的大脑结构和功能信息,对精神分裂症进行诊断,但是这种诊断结果存在很大的异质性,容易导致诊断结果不准确。
目前虽然有很多结合通过机器学习的方法进行神经影像的分类分析,但是大多具有以下的局限性:1)针对单中心数据,样本量少,有限的样本量往往导致分类模型的泛化性能较差;2)针对所有中心的原始数据进行训练,无法避免原始数据量大的问题及伦理问题。然而,多中心研究可以明显增加样本量以及提升分类模型的泛化能力,在大数据分析中发挥重要作用。
综上所述,本发明提出一种基于多中心模型的分类方法,每个中心只需要利用自己的样本训练各自的单中心模型,通过每个单中心的分类概率值和权重进行加权求和得到基于多中心模型的分类结果,通过多中心模型实现数据共享。
技术实现要素:
针对现有技术的不足,本发明拟解决的技术问题是,提出了一种基于多中心模型的精神分裂症分类方法及系统。
本发明解决所述技术问题采用以下技术方案:
一种基于多中心模型的精神分裂症分类方法,其特征在于,该方法包括以下步骤:
步骤一、数据准备:采集样本的脑mri图像,对脑mri图像进行处理,提取多个脑结构特征,这些脑结构特征构成特征矩阵;对特征矩阵进行协变量回归处理,然后再进行标准化处理;每个中心都按照此步骤准备各自的数据集;
步骤二、每个中心均利用机器学习分类器构建各自的单中心模型,利用各自的数据集训练各自的单中心模型;
步骤三、利用各个单中心模型对待分类的测试样本进行分类,得到待分类的测试样本对应每个中心的分类概率值;
根据式(1)计算各个单中心模型在所有单中心模型中的权重;
式(1)中,wi表示第i个中心的权重,ni表示第i个中心的样本数,n表示所有中心的样本总数;
利用式(2)将每个中心的分类概率值和权重进行加权求和,得到基于多中心模型的分类概率值p,以此将各个单中心模型集成为多中心模型;
其中,pi表示第i个中心对应的单中心模型的分类概率值;m表示中心总数;
用多中心模型对待分类的测试样本进行精神分裂症的分类。
当基于多中心模型的分类概率值大于或等于0.5则认为是精神分裂症患者,基于多中心模型的分类概率值小于0.5则认为是正常人。
所述机器学习分类器为xgboost分类器。
步骤一中,对脑mri图像进行处理包括脑组织分割、配准和指标解算,一共提取484个脑结构特征,包括每个皮层感兴趣区域的皮层厚度、表面积和体积,左、右脑共得到444个特征;皮层下感兴趣区域的体积,共33个特征;全脑总体积、全脑皮层灰质体积、全脑皮层下灰质体积、全脑白质体积、全脑白质表面积及全脑平均皮层厚度这7个特征。
本发明还提供一种基于多中心模型的精神分裂症分类系统,其特征在于,该系统权利要求上述方法进行精神分裂症分类,系统的处理单元中存储有所有的单中心模型;使用时,采集患者的脑mri图像,将脑mri图像输入到该系统中,经过处理后输出分类结果,实现精神分裂症的在线诊断。
若为精神分裂症患者,该系统则使用shap方法计算从脑mri图像提取的各个脑结构特征的权重,对所有脑结构特征的权重进行求和得到诊断权重分数,诊断权重分数反映了精神分裂症的严重程度。
与现有技术相比,本发明的有益效果是:
1.相较于现有的基于单中心模型的分类,本方法中每个中心只需要利用本中心的数据集训练各自的单中心模型,每个单中心模型都对待分类的测试样本进行分类预测,然后将每个单中心的分类概率值和权重进行加权求和得到基于多中心模型的分类概率值,每个中心模型都对最终分类结果贡献了自己的力量,有利于对待分类的测试样本进行更加全面诊断,避免了单中心由于样本数量有限,而导致该单中心模型的有效性和泛化能力较差的缺陷。
2.本方法适用于多中心的大数据分析,基于多中心模型实现数据共享,而每个中心无需共享原始数据,从而解决了由于原始数据量大,神经影像数据的存储要求较高,导致融合分析较困难的技术难题;同时避免了多中心数据进行统一分析涉及到的伦理问题及被试的隐私问题等。
3.多中心模型的可扩展性好,实验结果表明随着加入的中心的数量增加,多中心模型总的分类性能良好。
4.本发明的方法为疾病诊断提供了新的思路,能够推广到其他疾病的诊断中,利用大数据,为疾病的临床诊断带来新的视角和帮助。
5.本发明的分类系统可以更好的帮助临床对精神分裂症患者进行诊断,可以帮助提高对精神分裂症的理解,并有助于精神分裂症的早期诊断和预测。
附图说明
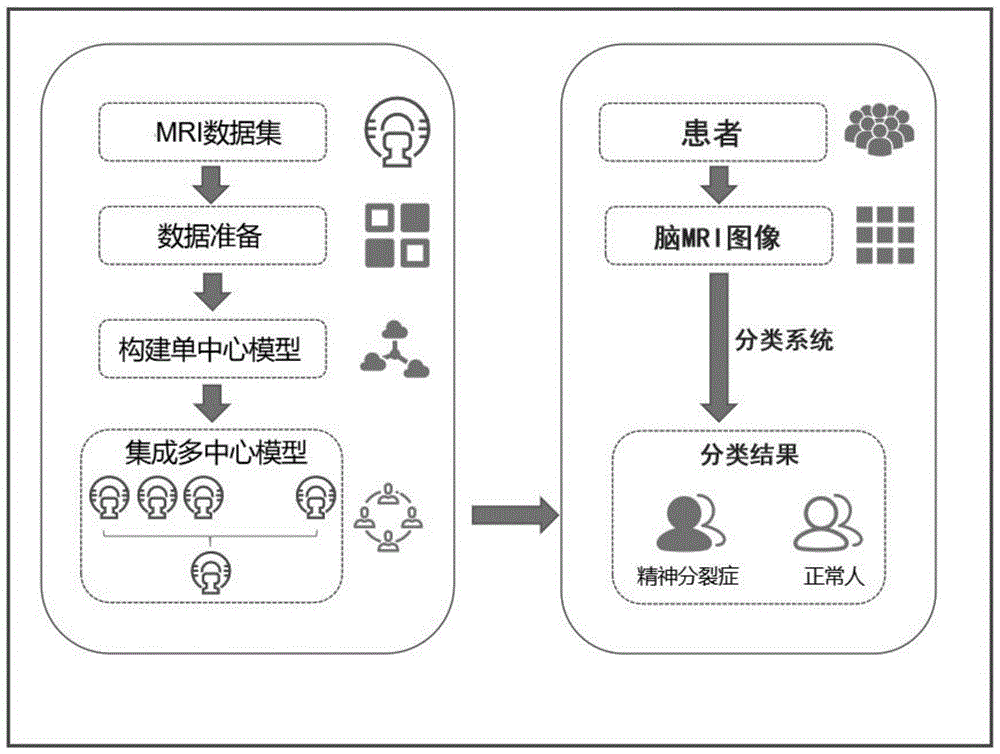
图1为本发明的整体流程示意图;
图2为本发明的多中心模型随着加入中心数量的增加,auc均值的变化趋势图。
具体实施方式
下面结合具体实施例和附图对本发明的技术方案进行详细说明,并不用于限定本申请的保护范围。
本发明为一种基于多中心模型的精神分裂症分类方法(简称方法,参见图1-2),包括以下步骤:
步骤一、数据准备:采集样本的脑mri图像,对脑mri图像进行处理,提取多个脑结构特征,这些脑结构特征构成特征矩阵;对特征矩阵进行协变量回归处理,然后再进行标准化处理;每个中心都按照此步骤准备各自的数据集;
步骤二、每个中心均利用机器学习分类器构建各自的单中心模型,利用各自的数据集训练各自的单中心模型;
步骤三、利用各个单中心模型对待分类的测试样本进行分类,得到待分类的测试样本对应每个中心的分类概率值;
根据式(1)计算各个单中心模型在所有单中心模型中的权重;
式(1)中,wi表示第i个中心的权重,ni表示第i个中心的样本数,n表示所有中心的样本总数;
利用式(2)将每个中心的分类概率值和权重进行加权求和,得到基于多中心模型的分类概率值p,以此将各个单中心模型集成为多中心模型;
其中,pi表示第i个中心对应的单中心模型的分类概率值;m表示中心总数;
用多中心模型对待分类的测试样本进行精神分裂症的分类。
进一步的,当基于多中心模型的分类概率值大于或等于0.5则认为是精神分裂症患者,基于多中心模型的分类概率值小于0.5则认为是正常人。
进一步的,机器学习分类器为xgboost分类器。
进一步的,对脑mri图像进行处理包括脑组织分割、配准和指标解算,一共提取484个脑结构特征,包括每个皮层感兴趣区域的皮层厚度、表面积和体积,左、右脑共得到444个特征;皮层下感兴趣区域的体积,共33个特征;全脑总体积、全脑皮层灰质体积、全脑皮层下灰质体积、全脑白质体积、全脑白质表面积及全脑平均皮层厚度这7个特征。
一种精神分裂症分类系统,该系统使用上述方法进行精神分裂症分类,系统的处理单元中存储有所有的单中心模型;使用时,采集患者的脑mri图像,将脑mri图像输入到该系统中,经过处理后输出分类结果,实现精神分裂症的在线诊断。
若为精神分裂症患者,该系统使用shap方法计算从脑mri图像提取的各个脑结构特征的权重,对所有脑结构特征的权重进行求和得到诊断权重分数,诊断权重分数越大表明精神分裂症越严重,诊断权重分数越小表明精神分裂症程度越轻微。
实施例
本实施例的基于多中心模型的精神分裂症分类方法,该方法包括以下步骤:
步骤一、数据准备:本实施例使用了来自9个mri数据集的1167个样本(被试)的脑核磁共振图像(mri),这些数据集包括精神分裂症患者(schizophrenia,scz)和正常对照组(normalcontrol,nc)的脑mri图像,所有患者均符合《精神疾病诊断与统计手册第四版》的scz诊断标准;
利用freesurfer平台对每个样本的脑mri图像进行脑组织分割、配准和指标解算,基于freesurfer平台提供的aparc.a2009s模板,得到每个皮层感兴趣区域的皮层厚度、表面积和体积,左、右脑共得到444个特征;利用基于freesurfer平台提供的aseg模板,得到皮层下感兴趣区域的体积,共33个特征;除此之外,还将全脑总体积、全脑皮层灰质体积、全脑皮层下灰质体积、全脑白质体积、全脑白质表面积及全脑平均皮层厚度这7个全脑指标也作为特征,因此每个样本一共得到484个脑结构特征,这些脑结构特征构成特征矩阵;
利用matlab软件的regress函数对前述得到的特征矩阵进行协变量回归处理,将性别、年龄、年龄的平方和去除总颅内体积(totalintracranialvolume,tiv)作为协变量进行回归处理,得到协变量回归后的特征矩阵;最后采用高斯替代的方法对协变量回归后的特征矩阵进行标准化处理,以保证数据符合正态分布,至此完成单中心的数据准备;每个中心都通过此步骤制作各自的数据集;
步骤二、每个中心均利用xgboost分类器构建各自的单中心模型,设定xgboost分类器各个超参数的搜索范围:梯度计算的次数为100-1001,步长为100;在训练过程中样本数据比例为0.5-1;每棵决策树的最大深度为1-10;每棵决策树叶子上的最小样本数范围为1-8;每棵决策树随机采样的列数的占比范围为0.3-1;决策树的每一级每一次分裂对列数的采样的占比范围为0.3-1;节点分裂所需的最小损失函数下降值(gamma)取值范围为:0-0.5,权重的l1正则化项(alpha)的取值范围为:[5,2,1,0.1,0.01,0.001,0];权重的l2正则化项(lambda)的取值范围为:[5,2,1,0.1,0.01,0.001,0];
利用步骤一得到的数据集,在训练过程中进行5折交叉验证,即通过5次循环进行最优参数的选择;每个中心都利用各自的数据集训练自己的单中心模型,一共得到9个单中心模型;
被试的工作特征(roc)曲线下面积(auc)是一种常用的模型性能衡量指标,auc越大,那么模型就越理想,auc的取值范围在0.5和1之间,auc越接近1.0,模型预测的结果越准确。运用auc指标对利用xgboost分类器构建的单中心模型的分类性能进行评估,与常见的分类器相比,得到表1的结果;目前主流的分类器包括:朴素贝叶斯分类器(naivesbayes)、支持向量机分类器(supportvectormachine,svm)、线性判别分析分类器(lineardiscriminativeanalysis)、随机森林分类器(randomforest)、决策树分类器(decisiontree)以及逻辑回归分类器(logisticregression)这5种。
从表1中可知,xgboost分类器的auc均值为0.77,朴素贝叶斯分类器的auc均值为0.69,支持向量机分类器的auc均值为0.67,线性判别分析分类器的auc均值为0.66,随机森林分类器的auc均值为0.65,逻辑回归分类器的auc均值为0.61,xgboost分类器的auc均值最高,因此表现出良好的分类性能。
表1常见机器学习分类器的auc对比
步骤三、集成多中心模型:利用各个单中心模型对待分类的测试样本进行分类预测,得到待分类的测试样本利用各个单中心模型进行分类的分类概率值,即每个中心的分类概率值;
结合各个中心的样本数,根据式(1)计算得到各个单中心模型在所有单中心模型中的权重;
式(1)中,wi表示第i个中心的权重,ni表示第i个中心的样本数,n表示所有中心的样本总数;
利用式(2)将每个中心的分类概率值和权重进行加权求和,得到基于多中心模型的分类概率值p,以此将各个单中心模型集成为多中心模型;
其中,pi表示第i个中心对应的单中心模型的分类概率值;m表示中心总数,本实施例中m=9;
设定患有精神分裂症的分类概率值为1,精神正常的分类概率值为0,以0.5为分界,若基于多中心模型的分类概率值大于或等于0.5则认为是精神分裂症患者,基于多中心模型的分类概率值小于0.5则认为是正常人,得到分类结果。
表2为分别利用三种模型进行分类的auc比较结果,其中单中心模型是指每个中心利用各自的单中心模型得到的auc;原始数据融合模型是指将各个中心的原始数据收集在一起,只形成一个数据集,利用这个数据集训练一个原始数据融合模型,每个中心的待分类的测试样本利用原始数据融合模型得到的auc;多中心模型是指利用本发明提出的方法进行分类,得到的auc;
表2三种模型的auc比较
从表2可知,单中心模型的auc均值为0.77,多中心模型的auc均值与原始数据融合模型的auc值相差不大,但是本发明的方法可以解决集中处理大量原始数据的问题。
图2为本发明中多中心模型包含的单中心模型数量不同,auc均值的变化图;随着多中心模型中加入的单中心模型的数量增加,平均auc升高为0.82,表明基于多中心模型的分类效能得到了进一步提升,从而形成了样本量-分类效能的正向循环;同时表明了多中心模型具有良好的可拓展性;每个中心只需要提供该中心训练得到的单中心模型,而无需提供原始数据,克服了现有方法中将各中心的原始数据进行集中处理,导致原始数据量大的缺陷。
本发明未述及之处适用于现有技术。
- 还没有人留言评论。精彩留言会获得点赞!