一种基于深度学习的人脸诊断系统
本发明涉及疾病辅助诊断领域,特别是一种基于深度学习的人脸诊断系统。
背景技术:
在过去的几十年中,用于处理各种疾病的计算机辅助诊断系统引起了许多研究者的兴趣。最近,这些计算机辅助诊断系统使用深度学习体系结构对医学图像进行分析和分类。
许多疾病如部分遗传疾病等具有可识别的面部特征,有些医生可根据一定的经验累积和学习,通过对患者面部特征的观察初步得到较为正确的诊断结果。但诊断结果易受到医生经验的丰富程度、技能水平的高低等影响,可重复性差,尤其对于一些罕见疾病诊断更是不易。但是当前缺乏针对面部图像分析识别的辅助诊断系统。
技术实现要素:
为了解决现有技术中缺乏针对面部图像分析识别的辅助诊断系统的技术问题,本发明提出一种基于深度学习的人脸诊断系统。
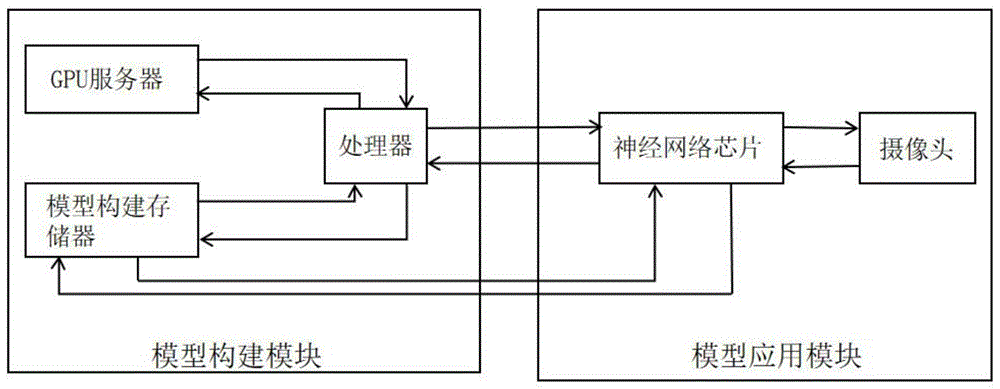
为此,本发明提出的基于深度学习的人脸诊断系统包括模型构建模块和模型应用模块;
所述模型构建模块包括中央处理器、gpu服务器和模型构建存储器,所述模型构建存储器中存储有可以被所述中央处理器运行的程序,并且可以存储相关疾病患者的面部图像;
所述模型应用模块包括神经网络芯片和摄像头,所述摄像头用于采集患者的面部照片,所述神经网络芯片可以搭载辅助诊断模型,所述辅助诊断模型基于深度卷积神经网络,通过训练、验证和优化得到,可基于人脸图像预测出特定疾病的患病概率。
进一步地,所述中央处理器通过运行程序可以实现模型构建,模型构建的具体步骤包括:
s1、采集数据集:获取相关疾病患者的面部图像;
s2、数据预处理:对所获图像数据进行数据清洗、标注和增强;
s3、模型训练:将预处理得到的数据集输入深度卷积神经网络中训练,获得辅助诊断模型;
s4、验证、优化模型性能,将经过训练的辅助诊断模型传输给模型应用模块。
进一步地,所述步骤s2具体包括:
s21、数据清洗:对采集到人脸图像数据进行筛选,剔除模糊、失焦的不合格图像,保留面部显像清晰的合格图像;
s22、数据标注:将图像根据对应病症对其进行规范的分类标注;
s23、数据增强:对图像进行旋转、平移、剪切、缩放等操作进行数据扩增,以增加数据集样本量;
s24、脸部分割和人脸对齐:对图像进行面部检测和对齐处理等并将图像裁剪到面部区域;
s25、数据格式规范化:将不同分辨率的图像数据resize后获得相同分辨率的图像,图像格式统一。
进一步地,所述步骤s24具体包括:
s241、根据人脸范围,找出两只眼睛的区域并计算中心坐标,分别记为(xleft,yleft),(xright,yright);
s242、计算两眼连线与水平线的夹角
s243、按照图像的中心作为坐标原点根据如下公式进行坐标变换
x′=x·cosa-y·sina
y′=y·cosa+x·sina。
进一步地,所述步骤s3中,将数据集按比例分为训练集和验证集,训练集部分的数据集输入深度卷积神经网络中,在所述gpu服务器上训练。
进一步地,所述步骤s3中,所述深度卷积神经网络的最后两层为全连接层和softmax层。
进一步地,所述softmax层的输出向量中每个元素的值均在0-1之间,数值大小表示该人脸图像对应每种疾病的患病概率。
进一步地,所述步骤s4中,根据网络在验证集和训练集上的表现,判断模型是否过拟合或者欠拟合,若出现过拟合或者欠拟合,则采取措施优化模型。
进一步地,所述步骤s4中,当训练集和验证集上排名前五的错误率均低于5%,则认定辅助诊断模型训练完成。
进一步地,所述模型应用模块的工作过程包括:
s5、通过摄像头获取待诊断者面部清晰图像;
s6、将人脸图像输入辅助诊断模型内;
s7、若检测到疑似疾病,则输出预测数据,否则,预测数据为空;
s8、输出诊断。
相比于现有技术,本发明具有如下有益效果:
采用基于深度学习的人脸诊断,可预测出某些疾病的患病概率,从而协助医生进行疾病的筛查工作,提高了诊断准确率和效率。
附图说明
图1是本发明实施例人脸诊断系统的结构图。
图2是本发明实施例模型构建流程图。
图3是本发明实施例模型应用流程图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图说明本发明的具体实施方式。
基于深度学习的人脸诊断系统主要针对具有较明显面部表型的遗传疾病等,如图1所示,具体包括模型构建模块和模型应用模块。
模型构建模块包括中央处理器、gpu服务器和模型构建存储器。模型构建存储器中存储有可以被中央处理器运行的程序,并且可以存储相关疾病患者的面部图像。中央处理器通过运行程序可以实现模型构建,如图2所示,模型构建的具体步骤包括:
s1、采集数据集:获取相关疾病患者的面部图像;
步骤s1数据集采集中,采集的数据集包含多种疾病,这些疾病的患者的面部均具有较明显的特征,其中大部分疾病为具有面部表型的遗传疾病,具体的,从权威机构如正规医院或相关研究机构等收集具有较明显面部特征的疾病的相关资料及患者面部图像,其中每种病症图像数量在500张以上,将收集的相关资料及患者面部图像存储在模型构建存储器中。
s2、数据预处理:对所获图像数据进行数据清洗、标注、增强等操作,步骤s2数据预处理具体步骤包括:
s21、数据清洗:对采集到人脸图像数据进行筛选,剔除模糊、失焦的不合格图像,保留面部显像清晰的合格图像,具体的,筛选采集到的图像数据,排除不合格图像,即无法被神经网络正确分析提取的图像,除模糊、失焦的图像外,还包括照片中虽有患者面部但为拍摄到特征部位的无效图像。
s22、数据标注:将图像根据对应病症对其进行规范的分类标注。
s23、数据增强:对图像进行旋转、平移、剪切、缩放等操作进行数据扩增,以增加数据集样本量,具体的,使用开源的图像处理库opencv对图像进行旋转、平移、剪切、缩放等操作。
s24、脸部分割和人脸对齐:对图像进行面部检测和对齐处理等并将图像裁剪到面部区域。脸部分割部分使用矩形框分割人脸的方式。人脸对齐方法步骤如下:
s241、根据人脸范围,找出两只眼睛的区域并计算中心坐标,分别记为(xleft,yleft),(xright,yright);
s242、计算两眼连线与水平线的夹角
s243、按照图像的中心作为坐标原点根据如下公式进行坐标变换
x′=x·cosa-y·sina
y′=y·cosa+x·sina
具体的,也是使用opencv代码实现。
s25、数据格式规范化:将不同分辨率的图像数据resize后获得相同分辨率的图像,图像格式统一。
s3、模型训练:将预处理得到的数据集输入深度卷积神经网络中训练,获得诊断模型,将数据集按比例分为训练集和验证集,训练集部分的数据集输入深度卷积神经网络中,在gpu服务器上训练。模型训练所用的卷积神经网络为具有多个卷积层、池化层的深度卷积神经网络,除最后一层外,其余各层后均批归一化(batchnorm)和relu,最后两层为全连接层和softmax层。softmax层的输出向量中每个元素的值均在0-1之间,数值大小表示该人脸图像对应每种疾病的患病概率。具体的,深度卷积神经网络可以利用resnet或inceptionv4等网络。
s4、验证、优化模型性能,根据网络在验证集和训练集上的表现,判断模型是否过拟合或者欠拟合,若出现以上情况,则采取调整网络参数或加入正则化等措施优化模型。当训练集和验证集上的top5errorrate均低于5%,则认定辅助诊断模型训练完成,将经过训练的辅助诊断模型传输给模型应用模块。
模型应用模块包括神经网络芯片和摄像头,摄像头用于采集患者的面部照片,神经网络芯片可以搭载经过训练的辅助诊断模型。如图3所示,模型应用模块的工作过程包括:
s5、通过摄像头获取待诊断者面部清晰图像,具体的,尽量在光线充足,拍摄设备性能合格情况下。
s6、将人脸图像输入辅助诊断模型内。
s7、若检测到疑似疾病,则输出预测数据,否则,预测数据为空。
s8、输出诊断。
辅助诊断模型具体应用场景为当前来看诊的病人面部具有较异常的特征,通过摄像头拍摄该患者面部照片并输入辅助诊断模型得到模型的输出。当该患者面部图像输入模型后计算得到的softmax层输出向量,当向量中得到的每个病症的概率都小于0.5时,判定输出为空,或因为训练模型时未采集该患者所属病症数据集,辅助诊断系统无法预测患者所患病症;当向量中含概率大于0.5的元素时,输出数值大小排前三且大于0.5的概率对应的病症及其预测概率。医生可参考系统的预测对患者进行进一步的检查、诊断。(相关建议:申请人的举例较为上位抽象,能否给出一个具体的实测例子,给出预测准确率,证明本系统的可实施性以及有益效果)。
虽然在本发明实施例中将辅助诊断模型搭载于模型应用模块的神经网络芯片上,但根据实际应用需求,经过训练的辅助诊断模型部署的载体可以是手机软件,也可以附在某种医疗硬件设备中,即经过训练的辅助诊断模型可以单独部署在其他设备上。
本发明采用上述基于深度学习的人脸诊断系统,可协助医生对面部具有疑似疾病特征的患者进行诊断,通过拍摄患者面部照片并输入模型,找出可能的对应疾病类型供医生参考,从而初步筛查疾病,方便患者之后做针对性的检查,提高了诊断效率和准确率。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!