基于对比预测编码的ECG数据特征生成模型
基于对比预测编码的ecg数据特征生成模型
技术领域
1.本发明属于计算机软件技术领域,具体涉及一种基于对比预测编码的ecg数据特征生成模型。
背景技术:
2.对比预测编码是自监督学习的一种,自监督学习目前主要的方法分为三类,分别是基于上下文、基于时序、基于对比。基于对比的自监督学习通过学习对两个事物的相似或不相似进行编码来构建表征,这类方法的性能是非常强的。自监督学习算法不再依赖标注,而是通过揭示数据各部分之间的关系,从数据中生成标签。而且在当前的深度学习应用中,数据的问题无处不在,ecg作为医疗数据的一种,存在着样本分布不平衡,无标签等诸多问题,而采用人工标注的方式耗时耗力,人们迫切的需要通过自监督的方式,在没有数据标注的情况下,学习丰富的特征表示。
3.心电图(electrocardiogram,简称ecg)对各种心律失常和传导阻滞的诊断分析具有良好效果,有助诊断、对冠心病的诊断具有重大意义。心电图主要反映心脏激动的电学活动,心肌受损、供血不足、药物和电解质紊乱都可能引起一定的心电图变化,特征性的心电图改变时诊断心肌梗死的可靠方法。现如今各种针对ecg数据分类的模型都面临一个问题,ecg数据中样本分布极不均衡,正常样本与心率不齐样本比例严重失衡,监督学习网络得不到足够的数据进行训练,模型性能不能保证。通过对比预测编码可以生成与ecg数据原类别一致的高维特征,相当于扩展了样本的数量,同时通过打分函数使得相同样本之间得分更高,不同样本之间的得分更低,进一步区分样本类别,可用于下游任务,比如分类任务,可极大防止模型过拟合,提高下游训练模型的收敛速度以及提高模型的分类准确率。
技术实现要素:
4.本发明针对现有技术中的不足,提供一种基于对比预测编码的ecg数据特征生成模型,引入自监督学习模型对比预测编码来预测出与原ecg数据相同类别的高维特征,在增大样本集的同时,减少人工标注成本,同时配合下游分类任务进行分类,也便于其它分类模型减少过拟合提高分类准确率。
5.为实现上述目的,本发明采用以下技术方案:
6.基于对比预测编码的ecg数据特征生成模型,包括如下步骤:
7.s1、采用数据集并进行预处理;
8.s2、划分ecg训练数据,划分为正样本对与负样本对,正样本对是相同类别的数据,负样本对是不同类别的数据;正样本对与负样本对中又分别划分出训练数据与待训练数据;
9.s3、搭建对比预测编码cpc模型,输入为训练数据与待训练数据;
10.通过编码器将训练数据与待训练数据都进行编码,接着把训练数据经过编码得到的结果放入自回归模型得到上下文信息context,context进入预测模型后得到未来多步的
预测值;
11.s4、将预测值与待训练数据经过编码后的值一起计算点积得到损失值;
12.s5、训练对比预测编码cpc模型;
13.s6、将训练好的cpc模型运用到下游的分类任务中。
14.为优化上述技术方案,采取的具体措施还包括:
15.进一步地,s1中的对数据集预处理过程包括:
16.s11、采用数据集自身标注的r峰位置采集心拍;
17.s12、将心拍重采样;
18.s13、使用小波变换进行滤波;
19.s14、为数据集重新打上标签并打乱重排,将数据集分为训练集和验证集,训练集又分为两部分,分别是训练数据与待训练数据;同时构造正样本对与负样本对。
20.进一步地,s3中的自回归模型构造过程包括:
21.使用自回归模型gru来融合历史信息,输出维度为256,只返回最后一个单元的输出。
22.进一步地,搭建预测模型过程包括:
23.全连接层输出维度10,使用线性激活函数;由于四个全连接层是放在一个列表里的,使用lambda层将这四个全连接层横向拼接起来构成一个网络。
24.进一步地,s4中,点积得到损失值使用sigmoid函数使其在[0,1]范围内,作为对比预测编码cpc模型的输出。
[0025]
进一步地,训练cpc模型,步骤如下:
[0026]
s51、初始化模型参数;
[0027]
s52、将数据输入到模型中进行训练;
[0028]
s53、保存模型,并作图绘制训练集以及验证集的准确率。
[0029]
进一步地,s6包括如下步骤:
[0030]
s61、划分训练数据,为了与训练好的cpc模型保持一致,将数据集划分为5份。
[0031]
s62、构造分类模型,分类模型使用的三份相同的训练数据;每一份训练数据都经过cpc的编码器部分、一维卷积层、relu激活层、一维最大池化层、一维卷积层、relu激活层、一维最大池化层;将三份数据得到的结果进行拼接后接一个flatten层、两个全连接层,最后经过一个激活函数为softmax的全连接层得到分类结果;
[0032]
s63、训练分类模型,损失函数使用categorical_crossentropy,优化器使用rmsprop,批量大小设置为64,训练10个epoches。
[0033]
本发明的有益效果是:
[0034]
(1)本发明适用于数据不平衡条件下ecg数据;
[0035]
本发明适用于收集到的ecg数据较少的,不太常见的心律失常数据。针对收集到的数据较少的情况,cpc可以通过最大化自身的互信息,就可以解决因为数据量不足所带来的问题,由此可以扩展样本数量不足的数据,提高下游任务的泛化能力。
[0036]
(2)本发明提高了产生相同类别ecg数据特征的准确率;
[0037]
通过编码器提取有效特征,去除了不必要的噪声,使特征更加明显,便于后续处理。对比预测编码利用自身的互信息,提高自身预测能力的同时,强化了编码器的特征提取
能力,特征提取效果相当不错。模型在mit
‑
bit心律不齐数据库上取得了相当好的效果。
[0038]
(3)本发明加快了下游ecg分类模型的训练速度;
[0039]
通过对比预测编码将ecg数据经过编码器编码后已经对不同类别的数据做了一个区分,这样在训练分类模型时可以提高模型的收敛速度,加快模型训练。
附图说明
[0040]
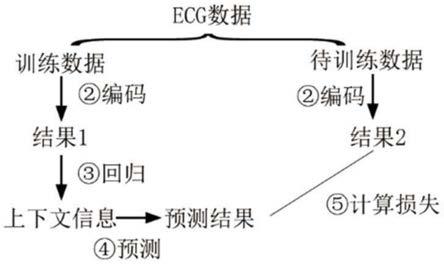
图1为本发明的对比预测编码应用在ecg上的工作流程图。
[0041]
图2为本发明的编码器的模型结构示意图。
[0042]
图3为本发明的预测模型的结构示意图。
[0043]
图4为本发明的训练数据与待训练数据,正样本对与负样本对的关系示意图。
[0044]
图5为本发明的训练集和验证集的准确率记录图。
[0045]
图6为本发明实施例的分类模型的结构示意图。
[0046]
图7为本发明实施例的分类模型训练过程的模型准确率示意图。
具体实施方式
[0047]
现在结合附图对本发明作进一步详细的说明。
[0048]
需要注意的是,发明中所引用的如“上”、“下”、“左”、“右”、“前”、“后”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
[0049]
本发明提供了一种基于对比预测编码的ecg数据特征生成模型,引入自监督学习模型对比预测编码来预测出与原ecg数据相同类别的特征,在增大样本集的同时,减少人工标注成本,同时也便于其它分类模型减少过拟合提高分类准确率。本发明旨在解决以下问题:
[0050]
1)ecg数据数量不平衡。数据作为模型训练的材料,其大小往往决定了模型的性能。如今已存在各种各样针对ecg进行分类的模型,然而由于ecg数据本身的特点,一些心率类型所对应的数据非常少,计算机得不到足够的数据进行训练,从而导致分类模型出现各种各样的问题。
[0051]
2)标注成本居高不下。全监督学习训练过程中需要用到大量人工标注标签的数据集,然而标注数据类型将消耗大量的人力、物力等资源。针对ecg这种特定的数据,标注则需要一定的专业知识,提高了人工标注的门槛,使得大规模、更复杂的数据集标注愈加艰难。
[0052]
3)预测准确度不高。使用深度学习模型预测ecg数据特征的最终目标就是快速精准的实现预测。现有模型多是基于相同的概率分布进行预测,并没有挖掘不同类别数据之间特征的不同,往往预测准确率不高。
[0053]
4)提高下游任务训练速度。通过对比预测编码可以使得编码后相同样本之间的差距越来越小,不同样本之间的差距越来越大,从而在正式的下游任务训练之前对不同类别的数据做了区分,可以加快下游任务的收敛速度。
[0054]
本发明主要有以下步骤:
[0055]
如图1所示,图1展示了对比预测编码应用在ecg数据上的工作步骤,首先将划分ecg训练数据,横向看是正样本对与负样本对,正样本对是相同类别的数据,负样本对是不
instrumentation,简称aami)提出的标准,所有的心拍可以被分为这五大类:正常心拍(normal beat,简称n)、室上异位心拍(supraventricular ectopic beat,简称sveb)、心室异位心拍(ventricular beat,简称veb)、融合心拍(fusion beat,简称f)以及未知分类心拍(unknown beat,简称q)。截取心拍的时候同时对心拍进行归类,得到的n、sveb、veb、f、q这五种类型的心拍所对应的个数分别为:90081、2781、7008、802、15。由于q为未分类心跳,所以最终数据集只包含n、sveb、veb、f这四大类,标签编码为0、1、2、3。
[0078]
1.2将所有的数据与对应的标签按照互相对应的关系进行打乱重排。取前90%个数据作为训练集,后10%个数据作为验证集。
[0079]
1.3对信号进行小波变换滤波。小波基使用db6,滤波将小于5hz和大于90hz的小波系数替换为0,只保留第3和第6细节子带之间的系数进行重构。
[0080]
1.4生成正样本与负样本。其中正样本对的类别相同,负样本对的类别不相同,将样本数据划分为训练数据与待训练数据。训练数据与待训练数据都为(32,4,151)。
[0081]
步骤2:搭建cpc模型。
[0082]
2.1搭建编码器模型。编码模型整体架构如图2所示,前半部分由四个由全连接层、批归一化层、leakyrelu激活层组成的块组成,全连接层的输出维度为64,经过一个flatten层后,再接一个块,此块的全连接层的输出维度为256,最后一个全连接层的输出维度为10,所有的全连接层都使用线性激活函数。编码器的作用是提取训练数据的特征。
[0083]
2.2构造自回归网络模型。自回归网络模型使用gru(gated recurrent unit),输出维度为256,只返回最后一个单元的输出。这一部分得到的是融合了历史信息的特征融合向量c。
[0084]
2.3搭建预测模型。预测模型如图3所示,其中全连接层输出维度10,使用线性激活函数。由于四个全连接层是放在一个列表里的,使用lambda层将这四个全连接层横向拼接起来构成一个网络。自回归模型输出的特征融合向量输入预测模型后输出预测的结果。
[0085]
2.4搭建输出模型。输出模型计算待训练数据经过编码器编码得到的结果与预测模型生成的待预测结果之间的点积,求平均值后通过sigmoid函数将其值映射到[0,1]范围内。
[0086]
2.5构建整体cpc模型,输入为训练数据与待训练数据,训练数据经过编码器、自回归模型、预测模型后得到结果1,待训练数据经过编码器得到结果2,计算结果1与结果2的点积值,输出为点积值经过sigmoid后的结果。
[0087]
步骤3初始化模型参数,将ecg数据输入模型进行训练。
[0088]
3.1初始化模型参数。设置模型学习率为0.001,样本批次大小为32,迭代次数10。使用adam优化学习率,损失函数使用binary_crossentropy。其中对学习率做了特殊处理以便模型更快的收敛,当2个epoch过去而模型性能不在提升时,学习率将减少为原来的1/3。
[0089]
3.2生成训练数据与待训练数据。其中训练数据与待训练数据,正样本对与负样本对的关系如图4所示。正样本对的个数与负样本对的个数相同,根据训练集不同类别个数的不同,使产生n、sveb、veb、f类别的概率分别为0.1,0.3,0.2,0.4,使得样本个数较少的类别能得到充分的训练。训练数据经过编码器、自回归模型、预测模型后生成的数据为预测数据,待训练数据经过编码器后生成的数据成为待预测数据。将训练数据与待训练数据输入模型进行训练。
[0090]
3.3保存模型。将训练好的模型保存起来,同时绘制训练过程中训练集以及验证集的准确率,如图5所示,从图中可以看出模型取得了非常好的效果。
[0091]
步骤四:将训练好的cpc模型运用到下游的分类任务中
[0092]
4.1划分训练数据。为了与训练好的cpc模型保持一致,训练集数据还是使用mit
‑
bit心律不齐数据库,将数据集划分为5份。
[0093]
4.2构造分类模型。分类模型使用的三份相同的训练数据。每一份训练数据都经过cpc的编码器部分、一维卷积层、relu激活层、一维最大池化层、一维卷积层、relu激活层、一维最大池化层。将三份数据得到的结果进行拼接后接一个flatten层、两个全连接层,最后经过一个激活函数为softmax的全连接层得到分类结果。具体模型结构如图6所示。
[0094]
4.3训练分类模型。损失函数使用categorical_crossentropy,优化器使用rmsprop,批量大小设置为64,训练10个epoches。训练过程的模型准确率如图7所示。
[0095]
本发明适用于数据不平衡条件下ecg数据。
[0096]
本发明适用于收集到的ecg数据较少的,不太常见的心律失常数据。针对收集到的数据较少的情况,cpc可以通过最大化自身的互信息,就可以解决因为数据量不足所带来的问题,由此可以扩展样本数量不足的数据,提高下游任务的泛化能力。
[0097]
本发明提高了产生相同类别ecg数据特征的准确率。
[0098]
通过编码器提取有效特征,去除了不必要的噪声,使特征更加明显,便于后续处理。对比预测编码利用自身的互信息,提高自身预测能力的同时,强化了编码器的特征提取能力,特征提取效果相当不错。模型在mit
‑
bit心律不齐数据库上取得了相当好的效果。
[0099]
本发明加快了下游ecg分类模型的训练速度。
[0100]
通过对比预测编码将ecg数据经过编码器编码后已经对不同类别的数据做了一个区分,这样在训练分类模型时可以提高模型的收敛速度,加快模型训练。
[0101]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1