高风险用药路径的计算方法与流程
1.本发明涉及一种多个药物之间的使用路径的搜寻方法,尤其涉及一种高风险用药路径的计算方法。
背景技术:
2.近年来,因人口老化及慢性病普遍,同时服用两种以上药品或合并成药、中草药或保健食品,都让用药变得更复杂。当一种药品作用被其他药品所改变,造成疗效减少或增加时,即称为药物交互作用。药物交互作用较轻微者可能只是影响药物的吸收,而影响到疗效的发挥,严重时则可能会致命。而药物交互作用的连锁效应可能经过很多药物,且病患可能不只看过一位医师,使其追溯原因变得困难。因此,若能从病患的病历数据,找出高风险的用药路径,可以提醒医生注意病患的用药史,避免不良的连锁效应。然而,由于药物种类繁多,当病患的用药的路径愈长,其排列组合将呈现非线性成长,导致数据量庞大。故,需要一个有效率的方式来找出高风险的路径。
技术实现要素:
3.本发明是针对一种高风险用药路径的计算方法,可以节省时间,避免搜寻庞大的用药路径。
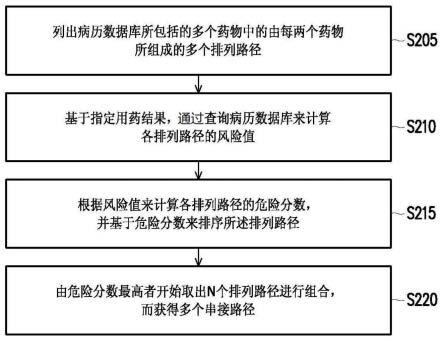
4.本发明的高风险用药路径的计算方法,包括:列出病历数据库所包括的多个药物中的由每两个药物所组成的多个排列路径;基于指定用药结果,通过查询病历数据库来计算各排列路径的风险值;根据风险值来计算各排列路径的危险分数,并基于危险分数来排序排列路径;以及由危险分数最高者开始取出n个排列路径进行组合,而获得多个串接路径,其中每一个串接路径所包括的药品数量符合指定用药数量。
5.在本发明的一实施例中,所述在由危险分数最高者开始取出n个排列路径进行组合,而获得串接路径的步骤之后,还包括:设定预设人数;判断符合所获得的串接路径且导致指定用药结果的病患人数是否符合预设人数;以及倘若病患人数不符合预设人数,更新n为n+m,并重新执行由危险分数最高者开始取出n个排列路径进行组合,而获得串接路径的步骤,直到病患人数符合预设人数。
6.在本发明的一实施例中,所述风险值为胜算比(odds ratio),通过下列公式来计算第i个排列路径的胜算比:
[0007][0008]
其中,o代表第i个排列路径的胜算比,de为其药物使用纪录中符合第i个排列路径且导致指定用药结果的病患人数,he为其药物使用纪录中符合第i个排列路径且未导致指定用药结果的病患人数,dn为其药物使用纪录中不具有第i个排列路径且导致指定用药结果的病患人数,hn为其药物使用纪录中不具有第i个排列路径且未导致指定用药结果的病
患人数。
[0009]
在本发明的一实施例中,所述根据风险值来计算各排列路径的危险分数的步骤包括:基于各排列路径的胜算比来设定各排列路径的风险排名,并以风险排名来作为危险分数;计算各排列路径的机率值,并基于机率值来设定各排列路径的机率排名;以及将风险排名加上机率排名来获得危险分数。
[0010]
在本发明的一实施例中,所述高风险用药路径的计算方法还包括:基于下述设定来查询病历数据库中符合第i个排列路径的病患人数,其中第i个排列路径依序包括第一药物与第二药物。所述设定为:在多个病患的药物使用纪录中查询在指定时间范围内依序使用了第一药物与第二药物的病患人数。
[0011]
在本发明的一实施例中,所述高风险用药路径的计算方法还包括:通过查询病历数据库,在串接路径中取出病历数据库所记载的多个用药路径,并获得具有指定用药结果的多个病患所对应的多个疾病的数据集,其中一个病患对应至一个疾病且具有一组路径集合,路径集合包括至少一个用药路径;基于下述公式计算各用药路径的逆向文件频率值,
[0012][0013]
其中,idf(i)代表第i个用药路径的逆向文件频率值,d为疾病的总数,t(i)为数据集所包括的第i个用药路径的数量;
[0014]
基于下述公式计算各用药路径在各病患所对应的路径集合的出现频率,
[0015][0016]
其中,tf
i,j
代表第i个用药路径在第j个病患所对应的路径集合的出现频率,n
i,j
代表第i个用药路径出现在第j个病患所对应的路径集合的数量,aj代表第j个病患所对应的路径集合中所包括的用药路径的数量;
[0017]
基于各用药路径的逆向文件频率值以及出现频率,计算各病患对应于第i个用药路径的估计值;以及
[0018]
基于估计值,针对各疾病来选出独特路径。
[0019]
在本发明的一实施例中,所述针对各疾病来选出独特路径的步骤包括:基于每一用药路径所对应的所有病患的估计值,计算平均值,并以具有最大的平均值的用药路径作为独特路径。
[0020]
在本发明的一实施例中,所述针对各疾病来选出独特路径的步骤包括:基于每一用药路径所对应的所有病患的估计值,计算平均值,并以手肘法决定一阈值后,选择平均值大于阈值的用药路径作为独特路径。
[0021]
基于上述,本公开提出了一个有效率寻找高风险路径的方法,可以节省时间,避免搜寻庞大的用药路径。
附图说明
[0022]
图1是依照本发明一实施例的电子装置的框图;
[0023]
图2是依照本发明一实施例的高风险用药路径的计算方法流程图;
[0024]
图3是依照本发明一实施例的找出不同疾病的独特路径的方法流程图;
[0025]
图4是依照本发明一实施例的用药路径的估计值平均值的曲线图。
[0026]
附图标记说明
[0027]
100:电子装置
[0028]
110:处理器
[0029]
120:存储装置
[0030]
121:病历数据库
[0031]
130:输出装置
[0032]
t:阈值
[0033]
s205~s220:高风险用药路径的计算方法各步骤
[0034]
s305~s320:找出不同疾病的独特路径的方法各步骤
具体实施方式
[0035]
图1是依照本发明一实施例的电子装置的框图。请参照图1,电子装置100包括处理器110、存储装置120以及输出装置130。处理器110耦接至存储装置120以及输出装置130。处理器110例如为中央处理单元(central processing unit,cpu)、物理处理单元(physics processing unit,ppu)、可程序化的微处理器(microprocessor)、嵌入式控制芯片、数字信号处理器(digital signal processor,dsp)、特殊应用集成电路(application specific integrated circuits,asic)或其他类似装置。
[0036]
存储装置120例如是任意型式的固定式或可移动式随机存取内存(random access memory,ram)、只读存储器(read-only memory,rom)、闪存(flash memory)、硬盘或其他类似装置或这些装置的组合。病历数据库121中记载多个病患的药物使用纪录。在其他实施例中,病历数据库121亦可以设置在云端服务器,而事先由云端服务器将病历数据库121下载至电子装置100或者由电子装置100实时联机至云端服务器来查询病历数据库121。另外,存储装置120还存储有多个代码段,上述代码段在被安装后,会由处理器110来执行,以实现下述高风险用药路径的计算方法。
[0037]
则本公开的高风险用药路径的计算方法是为了在多个药物中找出可能会造成指定用药结果的用药路径。在底下实施例中,以指定用药数量为3而言,用药路径的表示方法为a
→b→
c,其代表病患服药顺序为先服用药物a,在服用药物a之后的指定时间范围(例如30天)内服用了药物b,并且在服用药物b之后的指定时间范围(例如30天)内服用了药物c。而在服用药物a之后与服用药物b之前还可服用其他药物,且在服用药物b之后与服用药物c之前还可服用其他药物。
[0038]
图2是依照本发明一实施例的高风险用药路径的计算方法流程图。请参照图2,在步骤s205中,列出病历数据库121所包括的多个药物中的由每两个药物所组成的多个排列路径。处理器110会执行相关的代码段来找出病历数据库121中所记载的每一种被使用的药物,并且,以两个为一组来组成多个排列路径。
[0039]
例如,假设病历数据库121中所记载的多个病患的药物使用纪录总共包括k种药物,则可获得k
×
(k-1)的排列路径。其中,每个排列路径所包括的两个药物之间具有使用顺
序的区别。以药物a10ba、药物c10aa、药物d01ac而言,其可组合获得6个排列路径,即,a10ba
→
c10aa、a10ba
→
d01ac、c10aa
→
a10ba、c10aa
→
d01ac、d01ac
→
a10ba、d01ac
→
c10aa。
[0040]
接着,在步骤s210中,基于指定用药结果,通过查询病历数据库121来计算各排列路径的风险值。在此,可利用胜算比(odds ratio)或逻辑回归(logistic regression)来计算风险值。在本实施例中,以胜算比来作为风险值,即,通过下列公式来计算第i个排列路径的胜算比o:
[0041][0042]
其中,de为药物使用纪录中符合第i个排列路径且导致指定用药结果的病患人数,he为其药物使用纪录中符合第i个排列路径且未导致指定用药结果的病患人数,dn为其药物使用纪录中不具有第i个排列路径且导致指定用药结果的病患人数,hn为其药物使用纪录中不具有第i个排列路径且未导致指定用药结果的病患人数。
[0043]
以排列路径a10ba
→
c10aa(先服用药物a10ba再服用药物c10aa)而言,查询病历数据库121中各病患的药物使用纪录,以找出具有排列路径a10ba
→
c10aa的病患以及不具有排列路径a10ba
→
c10aa的病患。在具有排列路径a10ba
→
c10aa的病患中,找出发生住院的病患人数de以及未发生住院的病患人数he。并且,在不具有排列路径a10ba
→
c10aa的病患中,找出发生住院的病患人数dn以及未发生住院的病患人数hn。进而,通过上述公式来获得排列路径a10ba
→
c10aa的风险值(胜算比o
a10ba
→
c10aa
)。以此类推,计算各排列路径对应的风险值。
[0044]
在此,基于下述设定来查询病历数据库121中符合第i个排列路径(依序包括第一药物与第二药物)的病患人数。所述设定为:在多个病患的药物使用纪录中查询在指定时间范围(例如30天)内依序使用了第一药物与第二药物的病患人数。
[0045]
接着,在步骤s215中,根据风险值来计算各排列路径的危险分数,并基于危险分数来排序所述排列路径。进一步地说,基于各排列路径的胜算比来设定各排列路径的风险排名,并且计算各排列路径的机率值(probability value,p值),并基于p值来设定各排列路径的机率排名。之后,将风险排名加上机率排名来获得危险分数。举例来说,表1为一实施例的排列路径对应的风险排名、机率排名以及危险分数(风险排名+机率排名)。
[0046]
表1
[0047]
排列路径风险排名机率排名危险分数a10ba
→
c10aa11718
…ꢀꢀꢀ
d01ac
→
h03ba201434
…………
n07aa
→
s01la15823
[0048]
在获得危险分数之后,在步骤s220中,由危险分数最高者开始取出n个排列路径进行组合,而获得多个串接路径。在此,每一个串接路径所包括的药品数量符合指定用药数量。例如,假设指定用药数量为3,表示串接路径是由两个排列路径来组成。例如,排列路径a
→
b以及排列路径b
→
c可组成串接路径a
→b→
c。
[0049]
在本实施例中,危险分数越高代表此排列路径所代表的药物服用顺序导致指定用药结果(例如:住院)的机率越高。由危险分数高的排列路径所得到的串接路径的住院风险通常也较大。据此,从危险分数高的排列路径开始来找出高风险用药路径,可节省搜寻所有路径的时间。
[0050]
具体而言,先行设定n的起始值以及搜寻的停止条件。在此,搜寻的停止条件为符合所获得的串接路径且导致指定用药结果的病患人数符合预设人数。例如,预设人数为住院总人数的50%。之后,处理器110查询病历数据库121中每一个病患的药物使用纪录,以找出曾经住院的病患的总人数。并且,判断符合所获得的串接路径且导致指定用药结果的病患人数是否符合预设人数。倘若符合所获得的串接路径且导致指定用药结果的病患人数不符合预设人数,重新设定n=n+m,并重新执行由危险分数最高者开始取出n个排列路径进行组合,而获得符合指定用药数量的串接路径的步骤,直到符合所获得的串接路径且导致指定用药结果的病患人数符合预设人数。而倘若n+m大于所获得的排列路径,则取全部的排列路径来进行组合,以获得符合指定用药数量的多个串接路径。
[0051]
表2示出在排列路径中进行搜寻的搜寻结果。在进行串接的两个排列路径中,第一个排列路径中的第二个药物必需与第二个排列路径中的第一个药物相同才可串接。以表2的排列路径r05fa
→
n02be、n02be
→
a02ba、n02be
→
m01ab进行说明,其可组合的串接路径为r05fa
→
n02be
→
a02ba以及r05fa
→
n02be
→
m01ab。
[0052]
表2
[0053][0054]
以表2而言,预设人数为住院总人数的50%,n的初始值为100,m=100。在n为100的情况下,搜寻结果即符合所获得的串接路径且导致指定用药结果的病患人数仅7%,故重新设定n为200,直到n为1500时,搜寻结果(53%)大于预设人数50%,故,至此满足停止条件,停止进行搜寻。
[0055]
在获得最终串接路径之后,还可进一步针对不同的疾病来找出独特的用药路径(下述称为独特路径)。在底下实施例中,采用词频(term frequency)与逆向文件频率(inverse document frequency)的技术来找出不同疾病的独特路径。
[0056]
图3是依照本发明一实施例的找出不同疾病的独特路径的方法流程图。请参照图3,在步骤s305中,计算各用药路径的idf值。具体来说,处理器110通过查询病历数据库121,在所述串接路径中取出病历数据库121所记载的多个用药路径,并获得具有指定用药结果
的多个病患所对应的多个疾病的数据集。
[0057]
例如,假设串接路径包括a1~a10,处理器110通过查询病历数据库121来判断串接路径a1~a10是否存在于病历数据库121中,以找出与串接路径a1~a10相符者作为用药路径。在此,假设病历数据库121中存在符合串接路径a1~a5的用药路径p1~p5,并且假设指定用药结果为住院。接着,取出具有这些用药路径p1~p5且具有住院记录的病患,以及这些用药路径所造成的疾病(住院原因),进而获得所述数据集。
[0058]
举例来说,表3例示出一实施例的数据集。如表3所示,每一个病患对应至一种疾病(住院原因)且具有对应的路径集合,所述路径集合包括至少一个用药路径。在表3所示的数据集中,以病患编号来区别不同的病患,而在此所列出的疾病包括肺炎、消化性溃疡及中风,然,并不以此为限。以病患编号u01而言,病患编号u01的病患其对应至肺炎,且其路径集合包括用药路径p1、p2、p4。
[0059]
表3
[0060]
病患编号疾病(住院原因)路径集合u01肺炎{p1;p2;p4}u02肺炎{p3}u03消化性溃疡{p1;p4}u04中风{p2;p4;p5}u05中风{p3;p4}
[0061]
在获得所述数据集后,处理器110基于下述公式(1)计算各用药路径的idf值。
[0062]
公式(1):
[0063]
其中,idf(i)代表第i个用药路径的idf值,d为疾病的总数,t(i)为数据集所包括的第i个用药路径的数量。以表3为例,用药路径包括p1~p5,d=3。以用药路径p1而言,用药路径p1在数据集中的数量t(p1)为2,故,其idf(p1)=log(3/2)=0.41。以此类推,可分别获得用药路径p2~p5的idf值,如表4所示。
[0064]
在此,idf值愈大,表示对应的用药路径在越少住院原因(疾病)出现,表示其越独特。
[0065]
表4
[0066]
用药路径p1p2p3p4p5idf(i)log(3/2)=0.41log(3/2)=0.41log(3/2)=0.41log(3/3)=0log(3/1)=1.1
[0067]
之后,在步骤s310中,处理器110计算各用药路径在各病患所对应的路径集合的出现频率。在此,采用词频计算方式来计算出现频率。即,基于下述公式(2)计算各用药路径在每一个病患所对应的路径集合的出现频率。
[0068]
公式(2):
[0069]
其中,tf
i,j
代表第i个用药路径在第j个病患所对应的路径集合的出现频率,n
i,j
代表第i个用药路径出现在第j个病患所对应的路径集合的数量,aj代表第j个病患所对应的
路径集合中所包括的用药路径的数量。
[0070]
以表3而言,病患编号u01的路径集合{p1;p2;p4}中包括3用药路径,即a
u01
为3。用药路径p1在病患编号u01的路径集合的数量n
p1,u01
为1,据此,计算tf
p1,u01
为1/3。用药路径p2在病患编号u01的路径集合的数量n
p2,u01
为1,据此,计算tf
p2,u01
为1/3。用药路径p3在病患编号u01的路径集合的数量n
p3,u01
为0,据此,计算tf
p3,u01
为0/3。用药路径p4在病患编号u01的路径集合的数量n
p4,u01
为1,据此,计算tf
p4,u01
为1/3。用药路径p5在病患编号u01的路径集合的数量n
p5,u01
为0,据此,计算tf
p5,u01
为0/3。以此类推进行计算,可获得如表5所示的各路径集合的出现频率tf
i,j
。
[0071]
之后,在步骤s315中,处理器110计算各病患对应于各用药路径的估计值。即,基于各用药路径的idf值以及出现频率,计算各病患对应于第i个用药路径的估计值。在此,估计值=tf
i,j
×
idf(i)。如表4的idf(i)、表5的tf
i,j
而言,可获得如表6所示的估计值。
[0072]
表5
[0073][0074]
表6(tf
i,j
×
idf(i))
[0075][0076]
在步骤s320中,处理器110选出独特路径。即,基于估计值,针对各疾病来选出独特路径。在此,处理器110基于每一个用药路径所对应的所有病患的估计值,计算平均值,并且以具有最大的平均值的用药路径作为独特路径。
[0077]
参照表3及表6,针对肺炎可整理如表7,针对中风可整理如表8。由表7可以选出肺炎的独特路径为p3,其表示因肺炎而住院的情况下,用药路径p3具有高风险且导致其他住院原因的机率低。由表8可以选出中风的独特路径为p5,其表示因中风而住院的情况下,用药路径p5具有高风险且导致其他住院原因的机率低。另外,基于表3的例示,消化性溃疡仅对应至病患编号u03,故,参照表6在病患编号u03对应的估计值中取最大值对应的用药路径p1来作为独特路径。
[0078]
表7
[0079][0080]
表8
[0081][0082]
另一个做法中,基于每一个用药路径所对应的所有病患的估计值,计算平均值,并在使用手肘法选出一个阈值之后,选取平均值大于所述阈值的所有用药路径作为独特路径。底下再举一例来说明。在表9所示的实施例中,假设住院原因为肺炎,病患包括ua、ub、uc,用药路径包括p11~p16。
[0083]
表9
[0084][0085]
基于表9所示的用药路径p11~p16对应于全部病患的估计值来计算平均值,并且基于这些平均值可获得一曲线图,如图4所示。图4是依照本发明一实施例的用药路径的估计值平均值的曲线图。在图4中,以手肘法在曲线图中取手肘位置(对应于用药路径p13)来作为阈值t,将平均值大于所述阈值t的用药路径作为独特路径。即,判定用药路径p11、p12、p15为独特路径。
[0086]
综上所述,本发明通过上述高风险用药路径的计算方法来找出导致指定用药结果的高风险的用药路径,并且还能找出针对不同原因而导致指定用药结果的独特路径。
[0087]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1