医疗数据分类分级方法、计算机设备及存储介质与流程
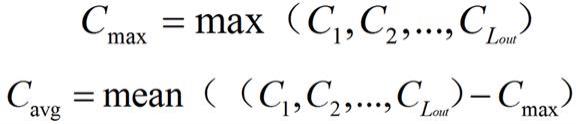
1.本发明涉及电数字数据技术领域,尤其涉及一种医疗数据分类分级方法、计算机设备及存储介质。
背景技术:
2.传统的医疗数据分类方法主要分为两类。一是基于词典的数据分类,将数据与建立的词典库进行比对从而进行分类。二是基于机器学习的数据分类,该方法通过文本预处理、特征提取、文本表示等特征工程,如通过词袋模型计算词的出现频率,通过tf
‑
idf模型计算文本中词的权重。在特征工程的基础上,使用svm、朴素贝叶斯、k最近邻分类等分类模型进行分类。
3.但是,上述方案存在如下缺陷:基于词典的数据分类该方法简单,但需要建立繁琐的规则且需要人工维护规则库,无法解决医疗数据文本复杂多样,语法结构不规范的问题。基于机器学习的数据分类方法中使用的词袋模型、tf
‑
idf模型将每个词汇看成是独立的特征,无法根据文本的语句序列来进行建模,无法获得文本的上下文关系,不仅丢失了词序信息,而且存在数据稀疏和维度灾难等问题。此外,svm、朴素贝叶斯等算法属于有监督的机器学习方法,需要人工标注训练数据,人工标注数据的数量及质量将影响文本分类任务的性能,当数据训练不足时会影响分类效果。
4.因此,针对传统的医疗数据分类方法造成分类准确性不高的问题,需要提供一种新的医疗数据分类算法与模型。
技术实现要素:
5.为了解决上述问题,本发明提出一种医疗数据分类分级方法、计算机设备及存储介质,用于解决数据稀疏、维度庞大进而导致的医疗数据分类结果准确率较低的问题。
6.本发明采用的技术方案如下:一种医疗数据分类分级方法,包括以下步骤:s1. 医疗数据预处理:利用分词工具,根据医疗类数据集中的医疗数据进行分词;根据需要过滤掉的字词和标点符号建立停用词语料库,在分词之后,根据所述停用词语料库将分词结果中的停用词过滤掉;将过滤后的医疗数据词袋化,统计词频并建立词典;s2. 提取词向量:对预处理后的医疗数据进行词向量化,即将预处理后的医疗数据映射为词向量,再根据生成的词向量构建词向量语料库;s3. 构建分类模型:将所述词向量语料库中的词向量输入至textcnn模型进行训练,所述textcnn模型包括输入层、卷积层、池化层、全连接层;所述输入层的输入为n*m的矩阵v,其中n为预处理后的医疗数据的词语数,m为每个词语对应的词向量维度;所述卷积层采用多个高度不同、宽度固定为词向量维度m的卷积核,以在不同长度的语句中提取不同视野尺寸的特征,所述卷积核与所述输入层进行卷积运算后获得特征序列;所述池化层对所
述特征序列进行降维操作,生成所述特征序列的池化结果;所述全连接层通过softmax函数将所述池化层的输出映射到(0,1)的范围内,即映射为概率;s4. 分类分级预测:调用已训练的textcnn模型来计算待分类医疗数据的分类分级概率,并输出分类分级结果。
7.进一步地,步骤s2中,基于word2vec模型,通过skip
‑
gram算法将预处理后的医疗数据映射为词向量;读取预处理后的医疗数据作为输入,训练一个m维的word2vec模型,将每个词映射到n维的向量空间并存储结果作为字典。
8.进一步地,在所述输入层中,对词向量进行padding即填充操作,使得每个句子的长度都一样。
9.进一步地,在所述卷积层中,不同高度的所述卷积核提取特征的方法包括以下步骤:s301. 采用1维卷积,公式如下:其中,l
in
为输入序列长度,l
out
为输出序列长度,padding为填充,dilation为卷积的扩张率,kernel_size为所述卷积核大小,stride为步长;s302. 所述卷积核沿着预处理后的医疗数据的文本方向进行移动,所述卷积核与所述输入层进行卷积运算后获得的特征序列为:其中,c
i
的计算公式为:其中,f为非线性函数,w为所述卷积核的权重矩阵,x
i:i+h
‑1为预处理后的医疗数据中的第i个词到第i+h
‑
1个词对应的词向量,h为所述卷积核的高度,b为偏置项。
10.进一步地,所述非线性函数设置为relu函数,即修正线性单元函数,其计算公式如下:当输入小于0时,输出都是0;当输入大于0时,输出与输入相等。
11.进一步地,所述卷积核设置为3个,分别是2*m、3*m和4*m,其中m为词向量的维度。
12.进一步地,所述池化层对所述特征序列进行的降维操作包括:首先提取所述特征序列中的最大值c
max
,然后对所述特征序列中除最大值以外的剩余数据求平均值c
avg
,再将最大值c
max
和平均值c
avg
拼接在一起作为所述特征序列的池化结果,其中:其中,表示所述特征序列中除最大值以外的剩余数
据。
13.进一步地,在所述全连接层中,所述softmax函数的计算公式如下:其中,z
j
为第j个节点的输出值,k为输出节点的个数即分类分级的类别个数。
14.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述医疗数据分类分级方法的步骤。
15.一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现上述医疗数据分类分级方法的步骤。
16.本发明的有益效果在于:(1)本发明提出的医疗数据分类分级方法可很好地解决数据稀疏、维度庞大进而导致的医疗数据分类结果准确率较低的问题。
17.(2)本发明在提取词向量的过程中,基于word2vec模型,通过skip
‑
gram算法将预处理后的医疗数据映射为词向量。具体读取预处理后的医疗数据作为输入,训练一个n维的word2vec模型,将每个词映射到n维的向量空间并存储结果作为字典。这样做能有效降低运算量,使高纬的稀疏表示,映射到低维的向量表示,保存了更多的语义信息。
18.(3)本发明在池化层进行降维操作的过程中,提出了一种新的融合剩余信息的最大值池化方法,首先提取特征序列中的最大值,然后对特征序列中除最大值以外的剩余数据求平均值,再将最大值和剩余数据平均值拼接在一起,作为特征序列的池化结果,可避免信息丢失的问题,兼顾性能与效率。
19.(4)本发明在进行卷积运算时,采用的非线性函数为relu函数,可减少参数间相互依赖的关系,缓解梯度消失的问题,收敛速度与sigmoid和tanh函数相比较快。
20.(5)本发明与传统基于机器学习算法的分类相比,传统机器学习算法准确率为61%左右,本发明的医疗数据分类分级方法的准确率为72.1%,准确率提升了18.2%左右。
附图说明
21.图1是本发明实施例1的医疗数据分类分级方法流程图。
22.图2是本发明实施例1的textcnn分类流程图。
具体实施方式
23.为了对本发明的技术特征、目的和效果有更加清楚的理解,现说明本发明的具体实施方式。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
24.实施例1如图1所示,本实施例提供了一种医疗数据分类分级方法,包括以下步骤:
s1. 医疗数据预处理,包括以下子步骤:s101. 利用分词工具,根据医疗类数据集中的医疗数据进行分词;s102. 根据需要过滤掉的字词和标点符号建立停用词语料库,在分词之后,根据停用词语料库将分词结果中的停用词过滤掉;s103. 将过滤后的医疗数据词袋化,统计词频并建立词典,例如:{unkown:0,不适:1,术后:2,复查:3,疼痛:4,复诊:5,咳嗽:6,......}s2. 提取词向量:分类模型的输入是词向量,需要构建词向量语料库。对预处理后的医疗数据进行词向量化,即将预处理后的医疗数据映射为词向量,再根据生成的词向量构建词向量语料库。优选地,基于word2vec模型,通过skip
‑
gram算法将预处理后的医疗数据映射为词向量。具体读取预处理后的医疗数据作为输入,训练一个n维的word2vec模型,将每个词映射到n维的向量空间并存储结果作为字典。这样做能有效降低运算量,使高纬的稀疏表示,映射到低维的向量表示,保存了更多的语义信息。
25.s3. 构建分类模型:将词向量语料库中的词向量输入至textcnn模型进行训练,textcnn是一种用于文本分类任务的卷积神经网络,其优势在于可以捕捉医疗文本中的局部相关性,对于短文本分类任务较友好。
26.如图2所示,textcnn模型包括输入层、卷积层、池化层、全连接层。
27.(1)textcnn模型的第一层为输入层,输入层的输入为n*m的矩阵v,其中n为预处理后的医疗数据的词语数,m为每个词语对应的词向量维度。优选地,对词向量进行padding即填充操作,使得每个句子的长度都一样。
28.(2)textcnn的第二层为卷积层,例如在电子病历的文本中,相邻词语的关联度总是很高的,可以通过一维卷积来提取语句汇总的特征。本实施例的卷积层采用多个高度不同、宽度固定为词向量维度m的卷积核,以在不同长度的语句中提取不同视野尺寸的特征。以卫生综合信息为例,电子病历、电子健康档案中包括患者对于病情的描述、现病史、既往病史、家族史、新生儿情况描述、分娩记录等描述性的文本,且文本的长度不一致,值域为an10~an100。优选地,本实施例的卷积核设置为3个,分别是2*m、3*m和4*m,其中m为词向量的维度。
29.优选地,不同高度的卷积核提取特征的方法包括以下步骤:s301. 采用1维卷积,公式如下:其中,l
in
为输入序列长度,l
out
为输出序列长度,padding为填充,dilation为卷积的扩张率,kernel_size为卷积核大小,stride为步长。具体地,如图2所示,输入文本“患者张三反复咳嗽偶尔心悸气促”,分别经过2*m、3*m、4*m的卷积核处理,在该场景中,l
in
为10,padding为0,dilation和stride为1, kernel_size为2、3、4,则一维卷积后得到的输出序列长度l
out
分别为9、8、7。
30.s302. 所述卷积核沿着预处理后的医疗数据的文本方向进行移动,所述卷积核与
所述输入层进行卷积运算后获得的特征序列为:其中,c
i
的计算公式为:其中,f为非线性函数,w为卷积核的权重矩阵,x
i:i+h
‑1为预处理后的医疗数据中的第i个词到第i+h
‑
1个词对应的词向量,h为卷积核的高度,b为偏置项。更为优选地,非线性函数f设置为relu函数,即修正线性单元函数,其计算公式如下:当输入小于0时,输出都是0;当输入大于0时,输出与输入相等。relu函数具有神经网络的稀疏性,减少了参数间相互依赖的关系,缓解了梯度消失的问题,收敛速度与sigmoid和tanh函数相比较快。
31.具体地,如“患者/张三/反复/咳嗽/偶尔/心悸/气促”所对应的10*m矩阵与卷积核2*m、3*m、4*m分别做乘法再求和,然后将窗口向下滑动做如上动作,这便是卷积操作,操作之后将10*m矩阵分别映射输出为一个9*1、8*1、7*1的矩阵。
32.(3)textcnn的第三层为池化层,池化层是对卷积层得到的特征序列进行降维操作,传统使用的池化操作是最大池化操作(maxpooling),从卷积操作后产生的特征向量中筛选出最大值,其他数据全部舍弃。该方法存在的问题是信息丢失。为了解决这个问题,有学者提出使用k
‑
max pooling来进行池化操作,即选取特征系列中前k个最大值来代表这个序列,但仍然存在部分数据的丢失。为了使特征数据不丢失,还有学者将池化层遗弃,通过增加卷积层来提取更深层次的特征。该方法随着卷积层的增加网络复杂度也增加,在训练网络时花费的时间会更长。
33.为了避免信息丢失的问题,兼顾性能与效率,本实施例提出了一种新的融合剩余信息的最大值池化方法:首先提取所述特征序列中的最大值c
max
,然后对所述特征序列中除最大值以外的剩余数据求平均值c
avg
,再将最大值c
max
和平均值c
avg
拼接在一起作为所述特征序列的池化结果,其中:其中,表示所述特征序列中除最大值以外的剩余数据。
34.(4)textcnn的第四层为全连接层,全连接层通过softmax函数将池化层的输出映射到(0,1)的范围内,即映射为概率,softmax函数的计算公式如下:
其中,z
j
为第j个节点的输出值,k为输出节点的个数即分类分级的类别个数。
35.s4. 分类分级预测:调用已训练的textcnn模型来计算待分类医疗数据的分类分级概率,并输出分类分级结果。其中,分类分级概率的概率越高,则待分类医疗数据属于该分类分级的概率越高。
36.优选地,为了评估本实施例的分类模型的性能,采用的评价指标是正确率与f1值,其中:正确率=分类正确的样本数/所有样本数.f1值是对分类器的整体评价,受到精确率和召回率的影响。精确率是指正确分类到某类别的样本数占所有被分类到某类别样本的比率。召回率是指正确分类到某类别的样本数占所有属于某类别的比率。例如,对于“疾病描述”类别,分类结果一般是4种情况:(1)属于“疾病描述”类的样本被正确分类到“疾病描述”类,记这一类样本数为tp;(2)不属于“疾病描述”类的样本被错误分类到“疾病描述”类,这一类样本数为fp;(3)属于“疾病描述”类的样本被错误分类到除“疾病描述”类的其他类,这一类样本数为fn;(4)不属于“疾病描述”类的样本被正确分类到除“疾病描述”类的其他类,这一类样本数为tn。
37.那么,对于“疾病描述”类的精确率与召回率为:精确率=tp/tp+fp;召回率=tp/tp+fn。
38.f1值是综合衡量准确率与召回率的指标,f1=(2*准确率*召回率)/(准确率+召回率)。
39.关于本实施例对医疗数据的分类,类别标签多达110个,计算所有类别的f1值,求算术平均值,即可得到整个分类器的综合f1值。
40.实验参数如下:参数名称说明取值embedding_dim词向量维度128batch_size批训练样本数64filter_size卷积核大小2,3,4num_filters卷积核数量128dropout丢弃率0.5与传统基于机器学习算法的分类相比,传统机器学习算法准确率为61%左右,本发明的医疗数据分类分级方法的准确率为72.1%,准确率提升了18.2%左右。
41.需要说明的是,对于本实施例,为了简便描述,故将其表述为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的动作顺序的限制,因为依据本技术,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本技术所必须的。
42.实施例2本实施例在实施例1的基础上:本实施例提供了一种计算机设备,包括存储器和处理器,该存储器存储有计算机
程序,该处理器执行该计算机程序时实现实施例1的医疗数据分类分级方法的步骤。其中,计算机程序可以为源代码形式、对象代码形式、可执行文件或者某些中间形式等。
43.实施例3本实施例在实施例1的基础上:本实施例提供了一种计算机可读存储介质,存储有计算机程序,该计算机程序被处理器执行时实现实施例1的医疗数据分类分级方法的步骤。其中,计算机程序可以为源代码形式、对象代码形式、可执行文件或者某些中间形式等。存储介质包括:能够携带计算机程序代码的任何实体或装置、记录介质、计算机存储器、只读存储器(rom)、随机存取存储器(ram)、电载波信号、电信信号以及软件分发介质等。需要说明的是,存储介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,存储介质不包括电载波信号和电信信号。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1