一种面向动态医疗数据的因果特征提取方法
1.本发明属于数据挖掘领域,涉及到因果发现、人工智能等技术,具体地说是一种面向动态医疗数据的因果特征提取方法。
背景技术:
2.伴随着大数据技术的快速发展,使用信息科技来处理健康医疗大数据来保障居民的健康已成为炽手可热的焦点之一。其中健康医疗大数据是指在人们疾病防治、健康管理等过程中产生的与健康医疗相关的数据。但是大多的医疗数据是动态产生的,庞大且杂乱,医护人员无法从众多的条目中及时而准确的得到关键信息。因此在捕获并汇总动态医疗数据的同时,如何实时地提取出当前医疗数据中的关键特征信息,以期更好地辅助医生的工作具有重大意义。
3.选择关键的特征需要使用特征选择技术。特征选择作为一种数据处理技术,可以降低特征数量、去除冗余特征和噪声数据,广泛地应用于机器学习和数据挖掘的各个领域。特征选择是从高维数据集中选择必要且尽可能小的一组特征子集,用于各类机器学习与数据挖掘任务,并与使用完整数据特征相比,拥有相近或更好的效果。
4.但是主要通过计算特征与类别变量之间的相关性进行特征子集的选择的传统特征选择方法存在一些缺点:
5.(1)缺乏可解释性。相关性旨在捕获特征与类别变量之间的共现性,因此通过相关性选择出来的特征并不能为预测模型提供令人信服的解释。
6.(2)缺乏鲁棒性。通过特征与类别变量之间相关性选择的特征子集所构建的预测模型,在应用到其它同分布的数据集时,其性能可能会明显下降,效果会比验证时的差很多,即该模型不可靠。
技术实现要素:
7.本发明是为了克服现有技术的不足之处以及应对动态医疗数据,提出了一种面向动态医疗数据的因果特征提取方法,以期能够更加准确地选择出关键特征来辅助医生的工作,同时持续跟进患者的情况,实时地选择关键因素,并提高选择的可解释性和鲁棒性。
8.本发明为解决技术问题采用如下技术方案:
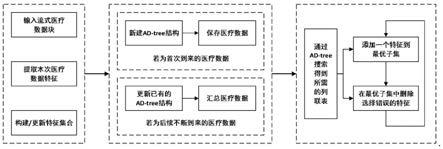
9.本发明一种面向动态医疗数据的因果特征提取方法的特点是按如下步骤进行:
10.步骤1、获取第i次的医疗数据记录,并记为其中,record
j,i
表示第i次的第j条医疗数据记录,1≤j≤ri;ri表示第i次的医疗数据记录的条数,且第i次的第j条医疗数据记录record
j,i
中包含mi种特征,记为其中,f
m,j,i
表示第i次的第j条医疗数据记录record
j,i
中的第m个特征;且第m个特征f
m,j,i
有nm个不同取值;m
j,i
表示第i次的第j条医疗数据记录record
j,i
中的特征数,令第j条记录record
j,i
的类别标签为l
j,i
;
11.步骤2、构建并更新全维树的结构,并在全维树中以统计信息的形式汇总全部数据
信息:
12.步骤2.0、初始化i=1;k=1;
13.步骤2.1、新建根节点root并作为第k层统计节点,并记录datai的记录条数;
14.步骤2.2、按datai中从第m个特征开始,分别在第k层统计节点下,向下新建统计节点的子节点,并作为第k层特征节点;
15.步骤2.3、按每个特征的取值个数,分别在第k层每个特征节点下,向下新建特征节点的子节点,并作为第k+1层统计节点,所述第k+1层统计节点内记录有数据集中与第k层特征节点取值相同的条数,并作为统计信息;
16.步骤2.4、将m+1赋值给m,将k+1赋值给k后,返回步骤2.2顺序执行,直到全维树构建完成,从而得到第i个全维树,记为adti,用于存储第i次的医疗数据记录;
17.步骤2.5、将i+1赋值给i;
18.步骤2.6、在第i-1个全维树adt
i-1
上,更新根节点root中所记录的条数为
19.步骤2.7、初始化k=1;
20.步骤2.8、更新第k层统计节点下的第k层特征节点:若datai中出现新的特征,则在第k层统计节点下新建相对应的特征节点;
21.步骤2.9、统计datai中与第k层特征节点取值相同的条数,并累加到第k层每个特征节点下的第k层每个统计节点的统计信息中,从而完成统计节点的更新,同时,若datai中的特征出现新的取值,则第k层特征节点下新建相对应的统计节点,用于记录datai中与新的取值相同的条数;
22.步骤2.10、将k+1赋值给k后,循环进行步骤2.8顺序执行,直到第i个全维树更新完成,并存储有前i次的医疗数据记录;
23.步骤2.11、返回步骤2.5执行,直到完成所有医疗数据记录的存储;
24.步骤3、构建最优特征子集,即关键特征集合f
′
:
25.步骤3.1、初始化i=1;
26.步骤3.2、定义第i次的医疗数据记录datai所对应的第i次选取的关键特征集合为f
′i={f
′
1,i
,f
′
2,i
,
…
,f
′m′
,i
,
…
,f
′m′
,i
},其中,f
′m′
,i
表示第i次选取的关键特征集合f
′i中第m
′
个关键特征,m
′
表示第i次选取的关键特征集合f
′i中的关键特征的个数;
27.步骤3.3、初始化
28.步骤3.4、使用因果关系推断方法,从第i次的医疗数据记录datai中的mi个特征中选择出可能的特征作为关键特征添加到最优特征子集f
′i中;
29.步骤3.4.1、定义候选特征集合ci={c
i,k
|c
i,k
∈fi\f
′i,1≤k≤mi},其中,fi表示第i次的医疗数据记录datai中包含的mi种特征的集合,且f
m,i
表示第i次的医疗数据记录datai中第m种特征,c
i,k
表示第i次的医疗数据记录datai中包含mi种特征的集合fi中除第i次选取的关键特征集合f
′i以外的第k个特征;
30.步骤3.4.2、将第i次的医疗数据记录datai的类别标签li={l
j,i
|j=1,2,
…
,ri}和候选特征集合ci中的每个特征均作为特征节点,并从全维树的根节点root开始,对所有特征节点及其取值进行遍历,得到所有特征节点之间的第一列联表,用于表征各个特征节点
之间不同取值相互组合的出现次数;
31.步骤3.4.3、以第i次选取的关键特征集合f
′i为条件集,利用式(1)分别计算候选特征集合ci中的每个特征与类别标签li之间的条件相关性:
[0032][0033]
式(1)中,g2表示统计值,表示在第i次的医疗数据记录datai中,满足第m
′
个关键特征f
′m′
,i
=a和标签l
j,i
=b的记录的条数,表示在第i次的医疗数据记录datai中,满足第m
′
个关键特征f
′m′
,i
=a,标签l
j,i
=b和条件集f
′i取值为集合β的记录的条数;表示在第i次的医疗数据记录datai中,满足条件集f
′i取值为集合β的记录的条数,表示在第i次的医疗数据记录datai中,满足标签l
j,i
=b和条件集f
′i取值为集合β的记录的条数,表示在第i次的医疗数据记录datai中,满足第m
′
个关键特征f
′m′
,i
=a和条件集f
′i取值为集合β的记录的条数;
[0034]
步骤3.4.4、利用式(2)计算第i次选取的关键特征集合f
′i中第m
′
个关键特征f
′m′
,i
和类别标签li之间的自由度dfm′
,i
:
[0035][0036]
式(2)中,表示第i次的医疗数据记录datai中第m
′
个关键特征f
′m′
,i
的不同取值的个数,表示第i次的医疗数据记录datai中类别标签的不同取值的个数;
[0037]
步骤3.4.5、将第m
′
个关键特征f
′m′
,i
和类别标签li之间的统计值g2在自由度dfm′
,i
下渐进为卡方分布,并在卡方分布上进行卡方检验,得到概率值pm′
,i
,所述概率值pm′
,i
表示在零假设为真时,错误拒绝零假设的概率,其中,所述零假设为第m
′
个关键特征f
′m′
,i
和类别标签li之间条件独立;
[0038]
步骤3.4.6、计算m
′
个关键特征分别和类别标签li={l
j,i
|j=1,2,
…
,ri}的概率值集合p,并对概率值集合中的概率值进行降序排列;
[0039]
步骤3.4.7、选择降序排序后的第一个概率值p
max,i
所对应的关键特征f
′
max,i
,如果第一个概率值p
max,i
小于显著性水平α,则拒绝零假设,即f
′
max,i
和标签li之间条件依赖,并将f
′
max,i
添加到第i次选取的关键致病因素集合f
′i中;
[0040]
步骤3.5、使用因果发现理论,移除第i次选取的关键致病因素集合f
′i中错误的关键特征;
[0041]
步骤3.5.1、对类别标签li={l
j,i
|j=1,2,
…
,ri}和关键致病因素集合f
′i中的每个特征作为特征节点,并从全维树的根节点root开始,对所有特征节点及其取值进行遍历,得到所有特征节点之间的第二列联表;
[0042]
步骤3.5.2、在关键致病因素集合f
′i中选择一个特征作为当前特征,以关键致病因素集合f
′i中除当前特征以外的所有特征为条件集;利用式(1)计算关键致病因素集合f
′i中当前特征分别与类别标签li之间的条件相关性;
[0043]
步骤3.5.3、利用式(2)计算当前特征和类别标签li之间的自由度,将当前特征和类别标签li之间的统计值g2值在相应自由度下渐进为卡方分布,并在卡方分布上进行卡方检验,得到对应的概率值;如果对应的概率值大于显著性水平α,则接受零假设,即当前特征和类别标签li之间条件独立,表明当前特征不是真正的关键特征,并将当前特征从关键特征集合f
′i中移除;
[0044]
步骤3.6、重复循环步骤3.4和步骤3.5,直到无特征被添加到关键致病因素集合f
′i中,从而得到前i次的医疗数据记录的关键特征;
[0045]
步骤4、当新的医疗数据到来时,则将i+1赋值给i后,返回步骤2顺序执行。
[0046]
与已有技术相比,本发明的有益效果体现在:
[0047]
1、本发明提出的关键特征的因果特征选择方法,用来减小特征空间的维度,使特征空间更有利于进一步的特征学习;本发明使用基于因果学习的特征选择方法,使得从医疗数据中选择的关键特征更具解释性和鲁棒性。
[0048]
2、本发明采用的全维树结构可以利用相对较小的空间以统计信息的形式保存完整的医疗数据,并将树结构与列联表相连接,可从从树结构中获取所需的列联表,使得在选择关键特征时的g2计算更加便捷与高效。同时,通过更新已有的全维树结构将患者不断产生的医疗数据汇总起来,并且每条数据仅在到来时扫描一次,也避免了因计算带来的重复冗余的数据读取。
[0049]
3、本发明采用了通过已有的关键特诊为当前的选择进行初始化的策略,做到了对居民健康的持续跟进,具有延续性;并且在新一轮的关键特征的选择中,通过添加新的关键特征和移除已失效的特征,做到了关键特征提取的实时性和实用性。此外,通过初始化关键特征集合,避免了从零开始选择,加快了添加和移除操作,使选择更加快捷。
[0050]
4、本发明所提出的方法可以用于各类数据分析任务中,例如销售数据分析、决策信息处理、用户社交媒体兴趣挖掘等,有助于商家和研究人员等挖掘与目标任务密切相关的特征信息,从而更好的进行数据分析和信息挖掘。
附图说明
[0051]
图1为本发明方法的示意图;
[0052]
图2为记录第一次的医疗数据记录的年数数据集data1的示意图;
[0053]
图3为由数据集data1构建的全维树结构adt1的示意图;
[0054]
图4为记录第二次的医疗数据记录的年数数据集data2的示意图;
[0055]
图5为根据新的数据集data2,在adt1上更新得到的部分adt2示意图。
具体实施方式
[0056]
本实施例中,一种面向动态医疗数据的因果特征提取方法,是首先对医疗数据集提取多种特征,构建或更新医疗数据的特征集合;之后根据提取的特征和当前的医疗数据,通过构建或更新全维树结构,将医疗数据信息以统计信息的形式进行汇总;然后使用已有的关键特征集合赋值给本次因果特征提取的初始特征子集,即进行初始化;利用因果推断理论与算法,计算特征间的因果关系,通过添加与删除操作的迭代,选择最优的特征子集,即得到当前最优的关键特征;而当新的医疗数据到来后,重复上述的操作,即可在动态医疗
数据中选择出实时的关键特征。具体的说,如图1所示,包括如下步骤:
[0057]
步骤1、获取第i次的医疗数据记录,并记为datai={record
1,i
,record
2,i
,
…
,record
j,i
,
…
,record
ri,i
},其中,record
j,i
表示第i次的第j条医疗数据记录,1≤j≤ri;ri表示第i次的医疗数据记录的条数,且第i次的第j条医疗数据记录record
j,i
中包含mi种特征,记为其中,f
m,j,i
表示第i次的第j条医疗数据记录record
j,i
中的第m个特征;且第m个特征f
m,j,i
有nm个不同取值;m
j,i
表示第i次的第j条医疗数据记录record
j,i
中的特征数,令第j条记录record
j,i
的类别标签为l
j,i
;
[0058]
如图2所示,表示第一次的医疗数据记录,data1={record
1,1
,record
2,1
,record
3,1
,record
4,1
},其中r1=4,特征f={f1},特征f1共有2个不同的取值,即n1=2,类别标签为l。
[0059]
步骤2、构建并更新全维树的结构,并在全维树中以统计信息的形式汇总全部数据信息:
[0060]
如图3所示,表示在data1上构建的全维树结构adt1。
[0061]
步骤2.0、初始化i=1;k=1;
[0062]
步骤2.1、新建根节点root并作为第k层统计节点,并记录datai的记录条数,此时data1共有4条记录,即第1层的统计节点保存统计数值4;
[0063]
步骤2.2、按datai中从第m个特征开始,分别在第k层统计节点下,向下新建统计节点的子节点,并作为第k层特征节点,即在第一层统计节点下新建第一层特征节点f
1,1
和l1;
[0064]
步骤2.3、按每个特征的取值个数,分别在第k层每个特征节点下,向下新建特征节点的子节点,并作为第k+1层统计节点,第k+1层统计节点内记录有数据集中与第k层特征节点取值相同的条数,并作为统计信息。如特征f
1,1
共有两个取值状态0和1,且在data1中f1=0的记录条数为1,f1=1的记录条数为3,则在第一层特征节点下新建两个统计节点f1=0和f1=1,且统计值分别为1和3;
[0065]
步骤2.4、将m+1赋值给m,将k+1赋值给k后,返回步骤2.2顺序执行,直到全维树构建完成,从而得到第i个全维树,记为adti,用于存储第i次的医疗数据记录,。如在统计节点f1=0和f1=1下,从特征l开始新建下一层的特征节点;
[0066]
步骤2.5、将i+1赋值给i;
[0067]
如图4所示,到来新的数据集data2,并根据data2中的数据记录通过更新adt1得到上adt2,如图5所示。
[0068]
步骤2.6、在第i-1个全维树adt
i-1
上,更新根节点root中所记录的条数为此时data2中共有4条记录,因此root统计节点的统计值更新为4+4=8;
[0069]
步骤2.7、初始化k=1;
[0070]
步骤2.8、更新第k层统计节点下的第k层特征节点:若datai中出现新的特征,则在第k层统计节点下新建相对应的特征节点,此时data2中出现了新的特征f2,则在第一层统计节点下新建对应的统计节点f2;
[0071]
步骤2.9、统计datai中与第k层特征节点取值相同的条数,并累加到第k层每个特征节点下的第k层每个统计节点的统计信息中,从而完成统计节点的更新,同时,若datai中
的特征出现新的取值,则第k层特征节点下新建相对应的统计节点,用于记录datai中与新的取值相同的条数,如在data2中特征f1=0和f1=1的统计值分别为1和2,则将对应的统计节点的统计值更新为1+1=2和3+2=5,同时f1出现了新的取值状态f1=2,则新建对应的统计节点f1=2;
[0072]
步骤2.10、将k+1赋值给k后,循环进行步骤2.8顺序执行,直到第i个全维树更新完成,并存储有前i次的医疗数据记录;
[0073]
步骤2.11、返回步骤2.5执行,直到完成所有医疗数据记录的存储;
[0074]
步骤3、构建最优特征子集,即关键特征集合f
′
:
[0075]
步骤3.1、初始化i=1;
[0076]
步骤3.2、定义第i次的医疗数据记录datai所对应的第i次选取的关键特征集合为f
′i={f
′
1,i
,f
′
2,i
,
…
,f
′m′
,i
,
…
,f
′m′
,i
},其中,f
′m′
,i
表示第i次选取的关键特征集合f
′i中第m
′
个关键特征,m
′
表示第i次选取的关键特征集合f
′i中的关键特征的个数;
[0077]
步骤3.3、初始化即关键特征集合初始化为空集;
[0078]
步骤3.4、使用因果关系推断方法,从第i次的医疗数据记录datai中的mi个特征中选择出可能的特征作为关键特征添加到最优特征子集f
′i中;
[0079]
步骤3.4.1、定义候选特征集合ci={c
i,k
|c
i,k
∈fi\f
′i,1≤k≤mi},其中,fi表示第i次的医疗数据记录datai中包含的mi种特征的集合,且f
m,i
表示第i次的医疗数据记录datai中第m种特征,c
i,k
表示第i次的医疗数据记录datai中包含mi种特征的集合fi中除第i次选取的关键特征集合f
′i以外的第k个特征;
[0080]
步骤3.4.2、将第i次的医疗数据记录datai的类别标签li={l
j,i
|j=1,2,
…
,ri}和候选特征集合ci中的每个特征均作为特征节点,并从全维树的根节点root开始,对所有特征节点及其取值进行遍历,得到所有特征节点之间的第一列联表,用于表征各个特征节点之间不同取值相互组合的出现次数;
[0081]
步骤3.4.3、以第i次选取的关键特征集合f
′i为条件集,利用式(1)分别计算候选特征集合ci中的每个特征与类别标签li之间的条件相关性:
[0082][0083]
式(1)中,g2表示统计值,表示在第i次的医疗数据记录datai中,满足第m
′
个关键特征f
′m′
,i
=a和标签l
j,i
=b的记录的条数,表示在第i次的医疗数据记录datai中,满足第m
′
个关键特征f
′m′
,i
=a,标签l
j,i
=b和条件集f
′i取值为集合β的记录的条数;表示在第i次的医疗数据记录datai中,满足条件集f
′i取值为集合β的记录的条数,表示在第i次的医疗数据记录datai中,满足标签l
j,i
=b和条件集f
′i取值为集合β的记录的条数,表示在第i次的医疗数据记录datai中,满足第m
′
个关键特征f
′m′
,i
=a和条件集f
′i取值为集合β的记录的条数;
[0084]
此时,计算所需要的列联表可以从已构建好的全维树中直接得到,使得在选择关
键特征时的g2计算更加便捷与高效。
[0085]
步骤3.4.4、利用式(2)计算第i次选取的关键特征集合f
′i中第m
′
个关键特征f
′m′
,i
和类别标签li之间的自由度dfm′
,i
:
[0086][0087]
式(2)中,表示第i次的医疗数据记录datai中第m
′
个关键特征f
′m′
,i
的不同取值的个数,表示第i次的医疗数据记录datai中类别标签的不同取值的个数;
[0088]
步骤3.4.5、将第m
′
个关键特征f
′m′
,i
和类别标签li之间的统计值g2在自由度dfm′
,i
下渐进为卡方分布,并在卡方分布上进行卡方检验,得到概率值pm′
,i
,概率值pm′
,i
表示在零假设为真时,错误拒绝零假设的概率,其中,零假设为第m
′
个关键特征f
′m′
,i
和类别标签li之间条件独立;
[0089]
步骤3.4.6、计算m
′
个关键特征分别和类别标签li={l
j,i
|j=1,2,
…
,ri}的概率值集合p,并对概率值集合中的概率值进行降序排列;
[0090]
步骤3.4.7、选择降序排序后的第一个概率值p
max,i
所对应的关键特征f
′
max,i
,即选择具有最大概率值的特征,如果第一个概率值p
max,i
小于显著性水平α,则拒绝零假设,即f
′
max,i
和标签li之间条件依赖,并将f
′
max,i
添加到第i次选取的关键致病因素集合f
′i中;
[0091]
在本实施例中,显著性水平α取值为0.05,可根据具体任务调整显著性水平的取值;
[0092]
步骤3.5、使用因果发现理论,移除第i次选取的关键致病因素集合f
′i中错误的关键特征;
[0093]
步骤3.5.1、对类别标签li={l
j,i
|j=1,2,
…
,ri}和关键致病因素集合f
′i中的每个特征作为特征节点,并从全维树的根节点root开始,对所有特征节点及其取值进行遍历,得到所有特征节点之间的第二列联表;
[0094]
步骤3.5.2、在关键致病因素集合f
′i中选择一个特征作为当前特征,以关键致病因素集合f
′i中除当前特征以外的所有特征为条件集;利用式(1)计算关键致病因素集合f
′i中当前特征分别与类别标签li之间的条件相关性;
[0095]
步骤3.5.3、利用式(2)计算当前特征和类别标签li之间的自由度,将当前特征和类别标签li之间的统计值g2值在相应自由度下渐进为卡方分布,并在卡方分布上进行卡方检验,得到对应的概率值;如果对应的概率值大于显著性水平α,则接受零假设,即当前特征和类别标签li之间条件独立,表明当前特征不是真正的关键特征,并将当前特征从关键特征集合f
′i中移除;
[0096]
步骤3.6、重复循环步骤3.4和步骤3.5,直到无特征被添加到关键致病因素集合f
′i中,从而得到前i次的医疗数据记录的关键特征;
[0097]
步骤4、当新的医疗数据到来时,则将i+1赋值给i后,返回步骤2顺序执行。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1