一种基于多组学和影像数据融合的癌症患者分类系统
1.本发明涉及癌症患者分类的技术领域,尤其是指一种基于多组学和影像数据融合的癌症患者分类系统。
背景技术:
2.癌症是一种具有复杂的潜在分子机制和因素的疾病,需要通过大量的数据来更准确地描述、诊断和治疗患者。组学一直是研究者们用来研究癌症机理的主要数据,近几年,由于基因测序技术的进步,使得测序时间极大缩短、测序成本大幅度降低、人力消耗降低,从而促进了包括基因组学、蛋白组学等多种组学的快速发展。同时由于现代计算机、医学影像的发展,影像被当作研究癌症的有效手段,其中更有病理学图片被称为诊断的“金标准”。多组学和影像从不同层面提供了患者的疾病信息,其中,基因组学、转录组学、蛋白组学分别从基因、转录、蛋白表达层面为癌症患者提供分子级的分析,而影像数据直观地呈现了患者目前的身体状况。越来越多的研究致力于将组学数据和影像数据融合,从而更全面地为癌症患者进行诊断和治疗,但组学数据和影像数据的融合面临着维度灾难、数据异构、数据不平衡等多种挑战;
3.多年来,人们提出了许多针对各种问题进行多组学数据和影像数据融合的方法。然而,大多数现有的工作集中在无监督的多组学数据和影像数据融合,或者是单一地从特征或样本中获取额外的信息。随着公共数据集和个性化医疗的发展,越来越多的组织和机构提供了癌症的相关文献信息和数据集,吸引了人们对有监督的多组学数据和影像数据融合的方法进行研究,该类方法可以识别与疾病相关的生物标志物,并对新样本进行预测。该类方法的早期尝试包括基于特征拼接的方法和基于集成的方法。一方面,基于拼接的方法通过直接拼接输入数据的特征来融合多组学数据和影像数据,完成分类模型的学习。另一方面,基于集成的方法集成了来自不同分类器的预测,每个分类器分别在一种类型的输入数据上进行训练。然而,这些方法没有考虑到不同输入数据类型之间的相关性,可能偏向于某些输入数据类型;
4.综上所述,考虑同时从特征和样本中获取额外的信息,利用一种新的多模态数据融合方法,实现不同输入数据之间的信息交互,完成多组学数据和影像数据的融合。
技术实现要素:
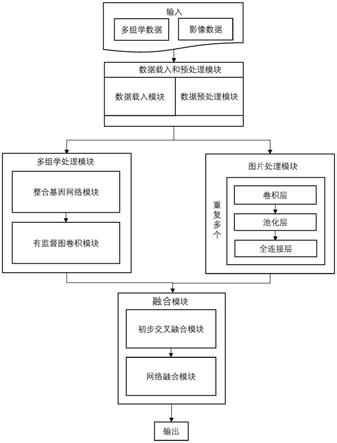
5.本发明的目的在于克服现有技术的缺点与不足,提出了一种基于多组学和影像数据融合的癌症患者分类系统,能够实现多组学数据和影像数据之间的信息融合,并利用融合后的多组学和影像数据对癌症患者进行准确分类。
6.为实现上述目的,本发明所提供的技术方案为:一种基于多组学和影像数据融合的癌症患者分类系统,该系统能完成端到端的多组学数据、影像数据的载入和预处理,利用外部知识数据库引入额外的特征信息对特定组学数据进行特征降维和信息聚集,通过计算癌症患者,即样本之间的相似度来补充额外的样本信息,最终通过一种多模态交叉融合方
法实现多组学数据和影像数据分类结果的融合,其具体包括以下功能模块:
7.数据载入和预处理模块,用于导入多组学数据和影像数据,并针对导入的数据进行预处理;
8.多组学处理模块,包括整合基因网络模块和有监督图卷积模块,其中,所述整合基因网络模块利用外部数据库hint所提供的基因之间相互作用信息构建基因之间的邻接矩阵,利用图卷积神经网络(gcn,graph convolutional network)和基因之间的邻接矩阵进行基因的表征,所述有监督图卷积模块利用余弦相似性构建样本之间的邻接矩阵,利用图卷积神经网络(gcn,graph convolutional network)和样本之间的邻接矩阵进行样本的表征,并获得以组学数据为输入的初步预测分类结果;
9.图片处理模块,利用卷积神经网络对影像数据进行表示学习,获得以影像数据为输入的初步预测分类结果;
10.融合模块,包括初步交叉融合模块和网络融合模块,其中,所述初步交叉融合模块构建多模态数据交叉融合向量,并将该向量的重构向量输入到网络融合模块,实现多个组学和影像数据的分类结果融合,获得最终的分类结果。
11.进一步,所述数据载入和预处理模块包括数据载入模块和数据预处理模块;所述数据载入模块实现多组学数据和影像数据的加载,所述多组学数据包括基因组学数据、转录组学数据和表观组学数据,所述多组学数据每行表示在相应特征上每个样本的表达值,每列表示一个样本在对应特征中的表达值,所述影像数据为癌症患者病理图数据;所述数据预处理模块的预处理包括样本对齐,特征对齐,对多组学数据空值比例超过全部样本的a%的特征进行删除,而空值比例低于全部样本的b%的值用软件impute2进行填充,去除方差低于阈值的特征,利用软件tcga-assembler对特定组学数据进行特征对齐,利用软件histomicstk对病理图进行分析,利用openslide工具对病理图进行裁剪,每个样本得到z块感兴趣区域(roi,region of interest),z大于或等于1,每个感兴趣区域(roi,region of interest)的像素大小是r1×
r2,其中r1和r2分别对应每个感兴趣区域(roi,region of interest)的长、宽像素值,最后将组学和影像数据按照指定比例进行划分,得到训练集和测试集;经过数据预处理模块后输出的数据由多个样本构成,每个样本包含多种组学数据和多块病理学图片。
12.进一步,所述多组学处理模块包括整合基因网络模块和有监督图卷积模块;
13.所述整合基因网络模块利用外部数据库hint引入基因之间相互作用信息,通过图卷积神经网络(gcn,graph convolutional network)实现多个组学数据特征层面的信息聚集和特征筛选,包括以下步骤:
14.a1)利用外部数据库hint提供的智人二元物理相互作用数据集构建基因之间的邻接矩阵a
(g)
∈r
(p
×
p)
,r为实数集,p为特征数目;
15.a2)利用步骤a1)得到的邻接矩阵a
(g)
构建图卷积神经网络(gcn,graph convolutional network)获得特征空间的邻居信息:
[0016][0017]
其中,组学u={1,2,...,u},u为多组学数目,分别为经过预处理的组学u的训练集和测试集,分别在训练阶段和测试阶段输入步骤a2)的公式中,为组学u的
隐含层表征,σ(
·
)为激活函数relu(
·
)=max(0,
·
),max(0,
·
)表示取0和
·
中较大的数,
⊙
为阿达玛乘积,为组学u在图卷积神经网络(gcn,graph convolutional network)训练过程中需要学习的参数,整合基因网络模块只在训练阶段学习图卷积神经网络(gcn,graph convolutional network)的参数;
[0018]
所述有监督图卷积模块依据样本之间的余弦相似性构建样本邻接矩阵a
(s)
,通过图卷积神经网络(gcn,graph convolutional network)获得每个组学的初步预测分类结果,包括以下步骤:
[0019]
b1)依据样本之间的相似性构建邻接矩阵a
(s)
;
[0020]
b1.1)在训练阶段,计算训练集中的样本之间的余弦相似度,得到训练样本的邻接矩阵
[0021][0022]
其中,表示样本i和样本j的邻接矩阵,表示样本i和样本j之间的余弦相似度,xi和xi分别为样本i和样本j在组学中的表达值,||
·
||2表示对
·
进行2-范数操作,是邻接矩阵的度矩阵,i表示单位矩阵,ε通过给定的参数k确定,k表示每个节点保留的平均边数,包括自连接,其公式如下:
[0023][0024]
其中,i(
·
)为指示函数,当sim(xi,xj)≥ε时,i(
·
)=1,否则,i(
·
)=0,n为样本数,即节点数,在同一数据集上的所有实验中都采用相同的k值,当k=1时,表示每个节点只连接自己,此时的图卷积神经网络(gcn,graph convolutional network)等同于一层全连接层;
[0025]
b1.2)在测试阶段,计算训练样本和测试样本、测试样本和测试样本之间的余弦相似度,依据步骤b1.1)的公式更换训练集成测试集,得到测试样本的邻接矩阵
[0026]
b2)构建有监督图卷积模块的图卷积神经网络(gcn,graph convolutional network):
[0027]
b2.1)在训练阶段,有监督图卷积模块的图卷积神经网络(gcn,graph convolutional network)的构建公式如下:
[0028][0029][0030]
其中,为组学u经过整合基因网络模块后的表征,为经过步骤b1.1)得到的样本之间的邻接矩阵,和为组学u在有监督图卷积模块的图卷积神经网络(gcn,
graph convolutional network)训练过程中所需学习的参数,和为有监督图卷积模块组学u的隐含表征;
[0031]
b2.2)在测试阶段,将步骤b1.2)获得的测试样本的邻接矩阵和经过整合基因网络模块后的测试集输入已经构建好的图卷积神经网络(gcn,graph convolutional network)中进行样本信息聚集,获得测试集的组学表征;
[0032]
b3)获得每个组学数据的初步预测分类结果:
[0033][0034]
其中,表示经过有监督图卷积模块后的训练集或者测试集的预测标签,n
tr
、n
te
分别是训练集和测试集中的样本数,c是分类任务中的类别数目,为构建softmax分类器过程中需要学习的参数,softmax分类器的公式如下:
[0035][0036]
其中,分类任务中的类别t={1,2,...,c}和m={1,2,...,c},h=[h1,h2,...,hc]
t
为输入softmax分类器的向量,h
t
和hm表示输入向量h中的第t个和第m个元素;
[0037]
构建有监督图卷积模块的损失函数如下:
[0038][0039]
其中,l
ce
(
·
)是交叉熵损失函数,表示组学i样本j的独热编码预测标签,表示中的第m个元素,yj是数据集中的真实标签。
[0040]
进一步,所述图片处理模块利用卷积神经网络(cnn,convolution neural network)提取病理图片的深度特征,所述卷积神经网络(cnn,convolution neural network)由l个卷积层、池化层和全连接层构成,l大于或等于1,其中卷积层的核大小为s1×
s2,每个卷积层有q个特征图,池化层大小是s3×
s4,最后一层采用全连接层,输出样本的影像数据初步分类结果,包括以下步骤:
[0041]
c1)在训练阶段,将预处理好的大小为r1×
r2的训练集中的病理图片his
tr
输入卷积神经网络(cnn,convolution neural network)中,卷积神经网络(cnn,convolution neural network)通过卷积层提取病理图片his
tr
的深层特征,通过池化层对数据进行降维,通过全连接层输出结果再通过反向传播调整网络结构参数,通过不断训练得到最优网络参数,训练过程为避免过拟合采用dropout机制;
[0042]
c2)在测试阶段,将预处理好的大小为r1×
r2的测试集中的病理图片his
te
输入已经训练好的卷积神经网络(cnn,convolution neural network)中,输出图片处理模块的初步预测分类结果
[0043]
进一步,所述融合模块包括初步交叉融合模块和网络融合模块,所述初步交叉融合模块先构建多模态数据交叉融合向量,再将多模态数据交叉融合向量重构得到重构向
量,最后网络融合模块输出融合后的分类结果;
[0044]
所述初步交叉融合模块具体执行以下操作:
[0045]
d1)构建多模态数据交叉融合向量:
[0046][0047]
其中,是训练集或测试集的多模态数据交叉融合向量,r为实数集,n
tr
、n
te
分别是训练集和测试集中的样本数,c是分类任务中的类别数目,u为组学数目,为以组学u为输入经过有监督图卷积模块后训练集或测试集的初步预测分类结果,为以病理图为输入经过图片处理模块后训练集或测试集的初步预测分类结果;
[0048]
d2)将步骤d1)得到的多模态数据交叉融合向量进行重构,得到训练集或测试集的重构向量
[0049]
所述网络融合模块由一层全连接层构成,包括以下步骤:
[0050]
e1)将步骤d2)得到的重构向量输入网络融合模块中,输出最终的分类结果:
[0051][0052]
其中,是在训练阶段需要训练的网络参数,输入训练集、测试集对应的重构向量,分别得到训练集和测试集的最终分类结果和softmax分类器的公式如下:
[0053][0054]
其中,分类任务中的类别t={1,2,...,c}和m={1,2,...,c},h=[h1,h2,...,hc]
t
为输入softmax分类器的向量,h
t
和hm表示输入向量h中的第t个和第m个元素;
[0055]
e2)反向传播计算网络融合模块的损失函数l:
[0056][0057]
其中,l
ce
(
·
)是交叉熵损失函数,yj是样本j的真实标签,为训练样本j最终预测结果,表示中的第m个元素;在训练阶段,需要计算经过网络融合模块后的损失函数,再通过反向传播训练网络融合模块参数;但在测试阶段不需要经过此步骤,在步骤e1)输出最终的分类结果即可。
[0058]
本发明与现有技术相比,具有如下优点与有益效果:
[0059]
1、借助外部知识数据库引入额外的基因之间相互作用信息,利用图卷积神经网络(gcn,graph convolutional network)实现基因之间的信息聚集,充分挖掘多组学数据的隐含表征。
[0060]
2、通过计算训练样本和测试样本、测试样本和测试样本之间的相似度,充分利用了样本的有监督和无监督信息,再通过图卷积神经网络(gcn,graph convolutional network)完成样本层面的信息聚集,有利于提高对癌症患者分类的预测精度。
[0061]
3、通过多模态交叉融合方法实现不同层面的癌症患者信息的融合,再通过网络方法进一步融合并完成癌症患者的预测分类。
[0062]
4、从特征层面和样本层面进行信息聚集,充分挖掘多组学数据、影像数据自身以及不同数据集之间的关联信息,提高对癌症患者分类的预测精度。
附图说明
[0063]
图1为本发明系统的架构图。
[0064]
图2为整合基因网络模块的作用原理图。
[0065]
图3为有监督图卷积模块的作用原理图。
[0066]
图4为融合模块的结构示意图。
具体实施方式
[0067]
下面结合具体实施例对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0068]
本实施例公开了一种基于多组学和影像数据融合的癌症患者分类系统,目的是通过融合癌症患者多组学数据和影像数据的融合来提高对癌症患者的分类预测精度。该系统能完成端到端的多组学数据、影像数据的载入和预处理,利用外部知识数据库引入额外的特征信息对特定组学数据进行特征降维和信息聚集,通过计算癌症患者,即样本之间的相似度来补充额外的样本信息,最终通过一种多模态交叉融合方法实现多组学数据和影像数据分类结果的融合,参见图1所示,其具体包括以下功能模块:
[0069]
数据载入和预处理模块,包括数据载入模块和数据预处理模块。
[0070]
所述数据载入模块实现多组学数据和影像数据的加载,所述多组学数据包括基因组学数据、转录组学数据和表观组学数据,所述多组学数据每行表示在相应特征上每个样本的表达值,每列表示一个样本在对应特征中的表达值,所述影像数据为癌症患者病理图数据;在本实施例中,使用公开癌症数据集tcga中的乳腺癌项目(brca)数据对本发明系统预测效果进行评估,从存储设备载入578名乳腺癌患者的mrna表达数据、dna甲基化数据、mirna表达数据和病理图片数据。
[0071]
所述数据预处理模块的预处理包括样本对齐,特征对齐,对多组学数据空值比例超过全部样本的a%的特征进行删除,而空值比例低于全部样本的b%的值用软件impute2进行填充,去除方差低于阈值的特征,利用软件tcga-assembler对特定组学数据进行特征对齐,利用软件histomicstk对病理图进行分析,利用openslide工具对病理图进行裁剪,每个样本得到z块感兴趣区域(roi,region of interest),z大于或等于1,每个感兴趣区域(roi,region of interest)的像素大小是r1×
r2,其中r1和r2分别对应每个感兴趣区域(roi,region of interest)的长、宽像素值,最后将组学和影像数据按照指定比例进行划分,得到训练集和测试集,经过数据预处理模块后输出的数据由多个样本构成,每个样本包含多种组学数据和多块病理学图片。其实,上述预处理可以归纳为:多组学数据预处理、影
像数据预处理模块和数据集划分,具体如下:
[0072]
多组学数据预处理包括:
[0073]
样本对齐:只保留同时含有四种数据的样本,其它样本删除;
[0074]
特征删除:对多组学数据中空值超过20%的特征进行删除,同时去除方差低于阈值的特征;
[0075]
数据填充:特征缺失低于20%的空值用软件impute2进行填充;
[0076]
基因映射:为了使基因-基因相互作用信息可以作用在dna甲基化数据中,利用tcga-assembler将对dna甲基化中的特征进行基因映射,保留dna甲基化数据中成功映射的特征。
[0077]
影像数据预处理包括以下步骤:
[0078]
利用软件histomicstk对病理图进行分析病理图片是否存在异常;
[0079]
利用openslide工具对病理图进行裁剪,每个样本得到数目不定的roi,每个roi的像素大小是224
×
224。
[0080]
数据集划分步骤包括:将80%的样本作为训练集对模型参数进行训练,20%的样本作为测试集对训练好的模型进行性能评估;经过数据集划分模块后,输出的三种多组学数据训练集(462个样本)和测试集(116个样本)在同一矩阵中,其中前462行数据作为训练样本,463~578行数据作为测试样本,训练集和测试集样本总数一共为578个样本;同时影像数据中的训练、测试样本与多组学数据中对应的训练、测试样本对应。
[0081]
所述多组学处理模块包括整合基因网络模块和有监督图卷积模块。
[0082]
所述整合基因网络模块利用外部数据库hint引入基因之间相互作用信息,通过图卷积神经网络(gcn,graph convolutional network)实现多个组学数据特征层面的信息聚集和特征筛选,其作用原理见图2所示,步骤如下:
[0083]
1)利用外部数据库hint提供的智人二元物理相互作用数据集构建基因之间的邻接矩阵a
(g)
∈r
(p
×
p)
,r为实数集,p=2000为基因数目;
[0084]
2)利用邻接矩阵a
(g)
构建gcn获得特征空间的邻居信息:
[0085][0086]
其中,u={1,2,3},x
(1)
、x
(2)
和x
(3)
分别表示mrna表达数据、dna甲基化数据和mirna表达数据,为经过预处理的组学u的训练数据或测试数据,在此模块中,训练数据集和测试数据集的邻接矩阵是一样的,为组学u的表征,σ(
·
)为激活函数relu(
·
)=max(0,
·
),max(0,
·
)表示取0和
·
中较大的数,
⊙
为阿达玛乘积,为组学u在gcn训练过程中需要学习的参数,整合基因网络模块只在训练阶段学习gcn的参数,mirna表达数据无法通过tcga-assembler进行基因映射,所以mirna表达数据在整合基因网络模块没有改变。
[0087]
所述有监督图卷积模块,其作用原理见图3所示,利用样本-样本之间的余弦相似性构建样本邻接矩阵a
(s)
,训练有监督图卷积模块参数,得到每个组学的初步预测分类结果,有监督图卷积模块是对样本进行信息聚集,步骤如下:
[0088]
1)依据样本之间的相似性构建邻接矩阵a
(s)
;
[0089]
1.1)在训练阶段,计算训练集中的样本之间的余弦相似度,得到训练样本的邻接
矩阵r为实数集,n
tr
=462为测试集样本数目:
[0090][0091]
其中表示样本i和样本j的邻接矩阵,表示样本i和样本j之间的余弦相似度,xi和xi分别为样本i和样本j在组学中的表达值,||
·
||2表示对
·
进行2-范数操作,是邻接矩阵的度矩阵,i表示单位矩阵,ε通过给定的参数k确定,k表示每个节点保留的平均边数,包括自连接,其公式如下:
[0092][0093]
其中,δ(
·
)为指示函数,当sim(xi,xj)≥ε时,δ(
·
)=1,否则,δ(
·
)=0,n为样本数,即节点数,在同一数据集上的所有实验中都采用相同的k值,在本实例乳腺癌数据集中k=5;
[0094]
1.2)在测试阶段,计算训练样本和测试样本、测试样本和测试样本之间的余弦相似度,依据步骤1.1)的公式更换训练集成测试集,得到测试集的邻接矩阵r为实数集,n=578为总样本数目;
[0095]
2)构建有监督图卷积模块的gcn:
[0096]
2.1)在训练阶段,有监督图卷积模块的gcn的构建公式如下:
[0097][0098][0099]
其中,为组学u经过整合基因网络模块后的表征,为经过步骤b1.1)得到的样本之间的邻接矩阵,和为组学u在有监督图卷积模块的gcn训练过程中所需学习的参数,和为有监督图卷积模块组学u的隐含表征;
[0100]
2.2)在测试阶段,将步骤1.2)获得的测试样本邻接矩阵和经过整合基因网络模块后的测试集输入已经构建好的gcn中进行样本信息聚集,获得测试集的组学表征;
[0101]
3)获得每个组学数据的初步预测分类结果:
[0102][0103]
其中,表示经过有监督图卷积模块后的训练集或者测试集的预测标签,n
tr
=462、n
te
=116分别是训练集和测试集中的样本数,c=5是分类任务中的类别数目,为构建softmax分类器过程中需要学习的参数,softmax分类器的公式如下:
[0104][0105]
其中,分类任务中的类别t={1,2,...,c}和m={1,2,...,c},h=[h1,...,hc]
t
为输入softmax分类器的向量,h
t
和hm表示输入向量h中的第t个和第m个元素;
[0106]
构建有监督图卷积模块的损失函数如下:
[0107][0108]
其中,l
ce
(
·
)是交叉熵损失函数,表示组学i样本j的独热编码预测标签,表示中的第m个元素,yj是数据集中的真实标签。
[0109]
所述图片处理模块,利用cnn提取病理图片的深度特征,获得影像数据对癌症患者的初步分类结果。所述cnn由6个卷积层、池化层和全连接层构成,其中卷积层的核大小为3
×
3,每个卷积层有64个特征图,池化层大小是2
×
2,最后一层采用全连接层,输出样本的影像数据初步分类结果,包括以下步骤:
[0110]
1)在训练阶段,将预处理好的大小为224
×
224的训练集中的病理图片his
tr
输入cnn中,cnn通过卷积层提取病理图片his
tr
的深层特征,通过池化层对数据进行降维,避免过拟合,通过全连接层输出结果再通过反向传播调整网络结构参数,通过不断训练得到最优网络参数,训练过程为避免过拟合采用dropout机制;
[0111]
2)在测试阶段,将预处理好的大小为224
×
224的测试集中的病理图片his
te
输入已经训练好的cnn模型中,输出图片处理模块的初步预测分类结果
[0112]
所述融合模块,其结构见图4所示,包括初步交叉融合模块和网络融合模块。所述初步交叉融合模块先构建多模态数据交叉融合向量,再将多模态数据交叉融合向量重构得到重构向量,最后网络融合模块输出融合后的分类结果。
[0113]
所述初步交叉融合模块具体执行以下操作:
[0114]
1)构建多模态数据交叉融合向量:
[0115][0116]
其中,是训练集或测试集的多模态数据交叉融合向量,r为实数集,n
tr
=462、n
te
=116分别是训练集和测试集中的样本数,c=5是分类任务中的类别数目,u=3为组学数目,为以组学u为输入经过有监督图卷积模块后训练集或测试集的初步预测分类结果,为以病理图为输入经过图片处理模块后训练集或测试集的初步预测分类结果;
[0117]
2)将步骤1)得到的多模态数据交叉融合向量进行重构,得到训练集或测试集的重构向量
[0118]
所述网络融合模块由一层全连接层构成,包括以下步骤:
[0119]
1)将经过初步交叉融合模块得到的重构向量输入网络融合模块中,输出最终的分类结果:
[0120][0121]
其中,是在训练阶段需要训练的网络参数,输入训练集、测试集对应的重构向量v,分别得到训练集和测试集的最终分类结果和softmax分类器的公式如下:
[0122][0123]
其中,分类任务中的类别t={1,2,...,c}和m={1,2,...,c},h=[h1,...,hc]
t
为输入softmax分类器的向量,h
t
和hm表示输入向量h中的第t个和第m个元素;
[0124]
2)反向传播计算网络融合模块的损失函数:
[0125][0126]
其中,l
ce
(
·
)是交叉熵损失函数,yj是样本j的真实标签,为训练样本j最终预测结果,表示中的第m个元素;在训练阶段,需要计算经过网络融合模块后的损失函数,再通过反向传播训练网络融合模块参数;但在测试阶段不需要经过此步骤,在步骤1)输出最终的分类结果即可。
[0127]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1