一种用于快速筛查宫颈肿瘤的模型及其建立方法
1.本发明具体涉及一种用于快速筛查宫颈肿瘤的模型及其建立方法。
背景技术:
2.宫颈癌被认为是女性中第二常见的恶性肿瘤,是仅次于乳腺癌的全球 癌症死亡的主要原因。我国每年的宫颈癌新发病例已达到11万,占世界总 新发病例的1/3。宫颈上皮内瘤变(cervical intraepithelial neoplasia,cin)与宫 颈癌的发生密切相关,持续的高危型人乳头瘤病毒感染会引发宫颈上皮细 胞低度病变(cin i),之后进一步演变为宫颈高度癌前病变(cin ii、ciniii),并最终发展成宫颈癌,这个过程一般需要8-15年的时间。但也有发展 时间特别快的,在这段时间如果能及时诊断出宫颈癌前病变并采取相应解 决措施,那么便可以及时干预病变,防止朝着不良的方向发展。目前帮助 临床医生及早发现宫颈癌前病变的方法包括细胞病理学、hpv检测和组织 病理学,但这些方法在主观性、成本和时间方面都受到限制。因此,临床 上需要一种客观的、快速的、只需要较少的样本制备的检测方法。
3.ft-ir是一种能够在分子水平上有效地提供生物材料结构和化学组成 信息的光学光谱技术,对分子水平上发生的微妙生化变化很敏感,能够检 测到与疾病发病相对应的光谱变化。在过去的15年里,已经有大量的研究 揭示了ft-ir光谱和机器学习算法在检测各种癌症方面的潜力,其中不乏 有在宫颈癌筛查方面的研究成果。mo等人采用主成分分析(pca)和线性判 别分析(lda)算法,结合血清ft-ir光谱对宫颈癌患者和健康对照组进行识 别,诊断准确率、特异度和敏感度都达到了98%。虽然实验取得了很好的 效果,但忽略了对cin患者的诊断。nordstrom等人基于活检组织部位的紫 外荧光光谱特征,使用多变量算法对正常组织,cin i、cin ii/iii进行鉴 别,cin ii/iii与正常组织分类的敏感性和特异性分别为91%和93%,cin i 与正常组织分类的敏感性和特异性分别为86%和87%。虽然分类结果较为 准确,但该实验可以进一步增加对宫颈高度癌前病变不同阶段的识别。此 外,yang等人提出基于特征融合的方法对宫颈炎、低级别鳞状上皮内病变、 高级别鳞状上皮内病变、宫颈鳞状细胞癌和宫颈腺癌进行分类,knn、elm、 abc-svm、cs-svm、pso-svm、cnn-ltsm分类准确率分别为60.91%、 67.84%、77.64%、78.49%、75.54%和70.72%,较未进行特征融合的原始光 谱分类准确率有所提高。然而,和大多数采用cnn作为特征提取或是分类 器的研究一样,他们没有对cnn的网络结构进行优化,一定程度上限制了 cnn的识别效果。
4.有鉴于此,本发明提出一种新的用于快速筛查宫颈肿瘤的模型,进一 步优化现有的早期筛查模型。
技术实现要素:
5.本发明的目的在于提供一种用于快速筛查宫颈肿瘤的模的建立方法, 通过对pso-cnn算法进行优化,可以提高识别效果。
6.为了实现上述目的,所采用的技术方案为:
7.一种用于快速筛查宫颈肿瘤的模型的建立方法,包括以下步骤:
8.(1)采集不同病变程度的宫颈肿瘤患者的血清样本后,测定并获取傅 立叶红外光谱数据;
9.(2)所述的傅立叶红外光谱数据通过pso-cnn算法建立分类模型,得 所述的用于快速筛查宫颈肿瘤的模型。
10.进一步的,所述的步骤(1)中,不同病变程度包括为宫颈癌、癌前病 变ⅰ级、癌前病变ⅱ级、癌前病变ⅲ级、子宫肌瘤。
11.进一步的,所述的步骤(2)中,pso-cnn算法中用于搜索最优的cnn 结构依次包括以下步骤:粒子群的初始化、单个粒子的适应度评估、测量 两个粒子之间的差异,速度计算和粒子更新。
12.再进一步的,所述的步骤(2)中,粒子群的初始化的过程为:先设置 网络层数范围,再随机选择卷积层、最大池化层、平均池化层和全连接层 作为当前层,并配制其参数后,进行粒子群初始化计算;
13.其中,每个粒子的第一层是卷积层,最后一层是全连接层,中间随机 穿插卷积层、最大池化层、平均池化层和全连接层中的至少一种。
14.再进一步的,所述的步骤(2)中,粒子群的初始化的过程中进行粒子 群初始化计算前获得的架构为:
15.第一层为卷积层,核尺寸为6
×
1,输出通道数为136;
16.第二层为卷积层,核尺寸为6
×
1,输出通道数为90;
17.第三层为卷积层,核尺寸为5
×
1,输出通道数为217;
18.第四层为卷积层,核尺寸为6
×
1,输出通道数为141;
19.第五层为卷积层,核尺寸为3
×
1,输出通道数为197;
20.第六层为全连接层,核神经元个数为82;
21.第七层为全连接层,核神经元个数为5。
22.再进一步的,所述的步骤(2)中,粒子群的初始化的过程中进行粒子 群初始化计算前获得的架构为:
23.第一层为卷积层,核尺寸为6
×
1,输出通道数为51;
24.第二层为平均池化,池化尺寸为3
×
1,步长为2;
25.第三层为卷积层,核尺寸为4
×
1,输出通道数为97;
26.第四层为卷积层,核尺寸为5
×
1,输出通道数为228;
27.第五层为卷积层,核尺寸为5
×
1,输出通道数为228;
28.第六层为全连接层,核神经元个数为279;
29.第七层为全连接层,核神经元个数为5。
30.进一步的,所述的pso-cnn算法中使用的参数包括:粒子群算法参数、 cnn架构初始化参数以及cnn训练参数。
31.再进一步的,所述的粒子群算法参数:迭代次数、种群规模和cg分别 设置为30、10和0.5;
32.所述的cnn架构初始化:最大网络层数设置为15,卷积核个数选择范 围为[3,
256],卷积核尺寸选择范围为[3
×
1,7
×
1],全连接层神经元个数选择范 围为[1,300],输出层神经元个数为5,卷积层生成概率为0.6,池化层生成 概率为0.3,全连接层生成概率为0.1;
[0033]
所述的cnn训练参数:粒子评估时训练epoch数为1,全局最佳粒子 训练epoch数为200,dropout为0.3。
[0034]
进一步的,所述的步骤(2)中,通过以下公式来更新粒子:
[0035][0036][0037]
其中,k为当前迭代次数;和分别表示下一次迭代中粒子i第d 维的速度和位置;cg为阈值;r为在粒子的每一个位置随机生成一个0到1 之间的数。
[0038]
与现有技术相比,本发明的有益效果在于;
[0039]
本发明使用一种优化算法自适应的选取最优的cnn框架,从而快速高 效地实现基于ft-ir技术的宫颈癌早期筛查。在cnn参数优化的领域,多 使用遗传算法和粒子群算法。一般来说,pso比ga更简单且收敛更快, 因为没有交叉和变异操作。此外,由于粒子之间的通信以及随机性,pso 算法也取得了优异的成果。
[0040]
基于粒子群算法参数少、收敛快的特点,本发明使用粒子群算法自动 搭建层数不定、层类参数不定的cnn结构,设计了一种基于ft-ir技术的 宫颈癌早期筛查的cnn模型。使用验证集准确率作为网络训练时的评估依 据,实验结果表明pso-cnn算法获取的cnn结构较其他几种经典cnn 结构在宫颈癌早期肿瘤筛查方面具有更好的检测结果。
附图说明
[0041]
图1为五类血清样本的平均ft-ir光谱;其中,阴影区域代表标准偏 差;
[0042]
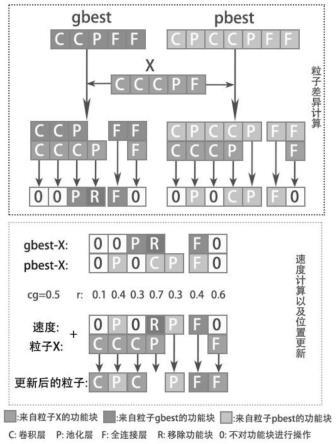
图2为粒子架构更新示意图;
[0043]
图3为pso-cnn算法获得的最优架构;其中,a为第二次获得的cnn 框架,b为第五次获得的cnn框架。
具体实施方式
[0044]
为了进一步阐述本发明一种用于快速筛查宫颈肿瘤的模型及其建立方 法,达到预期发明目的,以下结合较佳实施例,对依据本发明提出的一种 用于快速筛查宫颈肿瘤的模型及其建立方法,其具体实施方式、结构、特 征及其功效,详细说明如后。在下述说明中,不同的“一实施例”或“实施例
”ꢀ
指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或 特点可由任何合适形式组合。
[0045]
在详细阐述本发明一种用于快速筛查宫颈肿瘤的模型及其建立方法之 前,有必要对本发明中提及的相关材料做进一步说明,以达到更好的效果。
[0046]
下面将结合具体的实施例,对本发明一种用于快速筛查宫颈肿瘤的模 型及其建立方法做进一步的详细介绍:
[0047]
本发明在使用粒子群算法(pso)对cnn的网络层架构以及其中的超参 数进行自动选择的基础上,提出一种基于一维ft-ir光谱数据和pso-cnn 的宫颈癌早期肿瘤筛查模型,为未来该领域的cnn框架的选定提供参考。
[0048]
本发明的技术方案为:
[0049]
一种用于快速筛查宫颈肿瘤的模型的建立方法,包括以下步骤:
[0050]
(1)采集不同病变程度的宫颈肿瘤患者的血清样本后,测定并获取傅 立叶红外光谱数据;
[0051]
(2)所述的傅立叶红外光谱数据通过pso-cnn算法建立分类模型,得 所述的用于快速筛查宫颈肿瘤的模型。
[0052]
进一步的,所述的步骤(1)中,不同病变程度包括为宫颈癌、癌前病 变ⅰ级、癌前病变ⅱ级、癌前病变ⅲ级、子宫肌瘤。
[0053]
优选的,所述的步骤(2)中,pso-cnn算法中用于搜索最优的cnn 结构依次包括以下步骤:粒子群的初始化、单个粒子的适应度评估、测量 两个粒子之间的差异,速度计算和粒子更新。
[0054]
进一步优选的,所述的步骤(2)中,粒子群的初始化的过程为:先设 置网络层数范围,再随机选择卷积层、最大池化层、平均池化层和全连接 层作为当前层,并配制其参数后,进行粒子群初始化计算;
[0055]
其中,每个粒子的第一层是卷积层,最后一层是全连接层,中间随机 穿插卷积层、最大池化层、平均池化层和全连接层中的至少一种。
[0056]
进一步优选的,所述的步骤(2)中,粒子群的初始化的过程中进行粒 子群初始化计算前获得的架构为:
[0057]
第一层为卷积层,核尺寸为6
×
1,输出通道数为136;
[0058]
第二层为卷积层,核尺寸为6
×
1,输出通道数为90;
[0059]
第三层为卷积层,核尺寸为5
×
1,输出通道数为217;
[0060]
第四层为卷积层,核尺寸为6
×
1,输出通道数为141;
[0061]
第五层为卷积层,核尺寸为3
×
1,输出通道数为197;
[0062]
第六层为全连接层,核神经元个数为82;
[0063]
第七层为全连接层,核神经元个数为5。
[0064]
进一步优选的,所述的步骤(2)中,粒子群的初始化的过程中进行粒 子群初始化计算前获得的架构为:
[0065]
第一层为卷积层,核尺寸为6
×
1,输出通道数为51;
[0066]
第二层为平均池化,池化尺寸为3
×
1,步长为2;
[0067]
第三层为卷积层,核尺寸为4
×
1,输出通道数为97;
[0068]
第四层为卷积层,核尺寸为5
×
1,输出通道数为228;
[0069]
第五层为卷积层,核尺寸为5
×
1,输出通道数为228;
[0070]
第六层为全连接层,核神经元个数为279;
[0071]
第七层为全连接层,核神经元个数为5。
[0072]
优选的,所述的pso-cnn算法中使用的参数包括:粒子群算法参数、 cnn架构初始化参数以及cnn训练参数。
[0073]
进一步优选的,所述的粒子群算法参数:迭代次数、种群规模和cg分 别设置为30、10和0.5;
[0074]
所述的cnn架构初始化:最大网络层数设置为15,卷积核个数选择范 围为[3,256],卷积核尺寸选择范围为[3
×
1,7
×
1],全连接层神经元个数选择范 围为[1,300],输出层神经元个数为5,卷积层生成概率为0.6,池化层生成 概率为0.3,全连接层生成概率为0.1;
[0075]
所述的cnn训练参数:粒子评估时训练epoch数为1,全局最佳粒子 训练epoch数为200,dropout为0.3。
[0076]
优选的,所述的步骤(2)中,通过以下公式来更新粒子:
[0077][0078][0079]
其中,k为当前迭代次数;和分别表示下一次迭代中粒子i第d 维的速度和位置;cg为阈值;r为在粒子的每一个位置随机生成一个0到1 之间的数。
[0080]
实施例1.
[0081]
(1)血清样本获取与光谱采集
[0082]
研究中的病例样本为宫颈癌38例、癌前病变ⅰ级21例、癌前病变
ⅱꢀ
级27例、癌前病变ⅲ级29例、子宫肌瘤30例。所有患者的血清标本在测 试前都保存在-20℃的冰箱中。在测试过程中,血清样本在室温22℃的恒 定环境中自然解冻。随后,将每种血清样品取50μl置于znse晶体上并干 燥以形成均匀的膜,之后进行红外测试。该研究已获得区域伦理委员会批 准。
[0083]
测量光谱时,采用德国布鲁克公司生产的vertex70红外光谱仪和 specac公司的衰减全反射(atr)样本测量附件。atr的样品槽为znse晶 体,入射角为45
°
,三次反射。分束器为kbr。在每次记录光谱数据之前, 使用windowsxp系统上的opus 65软件测量背景数据,然后测量每个样 本数据。测试完成后,将在软件中自动执行傅立叶变换以获得傅立叶红外 光谱数据。其中,扫描范围为600-4000cm-1
,分辨率为8cm-1
,扫描次数 为32。所有患者血清样品均测量3次,共得到435个数据。选择co2补偿作 为补偿参数。
[0084]
(2)数据处理与样本划分
[0085]
实验采用随机划分数据集的方式将每类数据集按照6:2:2的比例划 分训练集、验证集和测试集。为了保证实验结果的可靠性,单个样本的光 谱只包含在训练集、验证集或测试集中。
[0086]
(3)光谱分析
[0087]
图1显示了五类血清样本光谱数据建模前的平均光谱图。其中,用阴 影部分表示了光谱标准偏差。由于不同的光谱吸收峰对应于不同的分子结 构,光谱差异可以反映血清中物质的变化。结合现有的ft-ir光谱研究成 果,列出了与红外吸收带相对应的不同光谱特征峰和归属,如表1所示。
[0088]
随着癌变的发生,癌细胞会产生快速分裂,这与cini、cinii、ciniii、宫颈癌以及
子宫肌瘤光谱在1056cm-1
处的核酸带吸收增加相对应,类 似的还有位于1400cm-1
的吸收峰。此外,有研究表明健康对照组、cini、 cinii/iii和宫颈癌患者中的磷脂酰胆碱、磷脂酰乙醇胺、甘油二酯和游离 脂肪酸存在显著差异,这表明由宫颈癌前病变演变为宫颈癌伴随着脂质的 变化。与脂质相关的光谱吸收峰对应2932cm-1
、2962cm-1
。1539cm-1
和 1647cm-1
处的强吸收峰分别对应酰胺ii和酰胺i谱带,源于蛋白质中酰胺 基团的振动,随着癌前病变程度的减少,光谱吸收峰强度呈现增加趋势, 宫颈癌患者的血清光谱强度要低于癌前病变患者,这与jusman等的研究结 果一致。综上可知五类样本主要在核酸、脂质和蛋白质带存在差异,对应 光谱物质含量的变化,这为ft-ir光谱结合机器学习算法识别五类样本提 供了可行性和生物学依据。
[0089]
表1人血清主要红外谱带的峰位和归属
[0090][0091]
(4)基于粒子群算法优化卷积神经网络模型搭建
[0092]
cnn是一种多层神经网络,不仅可以分析信号序列的内在信息,还能 克服信号的非线性和复杂性,近年来在计算机视觉领域取得了令人瞩目的 成就。其中,在对分子光谱技术应用于医学诊断的研究中,cnn作为特征 提取和分类器被广泛应用。然而,cnn的结构非常复杂,而且算法的性能 很大程度上取决于cnn的结构,因此如何选取合适的cnn网络结构成为 该领域学者们急需解决的问题。guo等人在固定网络层数及排列的前提下, 使用pso算法对cnn的卷积核参数、池化类型、激活函数、学习率等超 参数进行优化。虽然他们进
一步增加了优化的超参数个数,但是仍未摆脱 固定网络层架构的前提。
[0093]
有鉴于此,本发明的技术方案中采用pso-cnn算法,该粒子群优化算 法可以在不受尺寸限制的情况下,利用可变长度粒子搜索卷积神经网络的 最优架构,实验结果表明通过pso-cnn发现的最佳模型在不使用任何数据 增强技术的情况下可以获得与复杂卷积神经网络架构相媲美的实验结果。 基于此,本发明进一步提出结合pso-cnn算法思想的用于快速筛查宫颈肿 瘤的模型,可以用于辅助宫颈癌早期诊断。
[0094]
①
算法思想
[0095]
cnn中层与层堆叠在一起,使得任何给定层的输出都将成为下一层的 输入,输入与输出之间的对应关系可表示为式(1)。其中:x为输入数据; oi表示第i层的输出;fi(
·
)表示第i层的激活函数;gi(
·
)表示第i层的加权运 算;zi是激活函数之前第i层的加权运算的输出;wi为第i层的权重,b表 示该层的偏置。而cnn主要由卷积层、池化层和全连接层组成,对于不同 的网络层,输出对应着不同的加权运算,如式(2)所示。其中:卷积层的 输出是对其输入和权重的卷积运算;池化层所做的是简化卷积层输出中的 信息,包括最大池化和平均池化;全连接层与传统人工神经网络相似,其 输出是权重乘以输入的函数。
[0096][0097][0098]
粒子群优化算法的基本思想是通过群体中个体之间的协作和信息共享 来寻找最优解。每个粒子都有一个由目标函数决定的适应值,并且知道自 己到目前为止发现的最好位置(pbest)和现在的位置xi。这个可以看作是粒子 自己的飞行经验。除此之外,每个粒子还知道到目前为止整个群体中所有 粒子发现的最好位置(gbest)(gbest是pbest中的最优值)。这个可以看作是粒 子同伴的经验。粒子通过更新自己的速度和位置来跟踪两个极值pbest和 gbest:
[0099][0100][0101]
其中,k为当前迭代次数,和分别表示下一次迭代中粒子i第d 维的速度和位置;ω为惯性权重,因此体现的是粒子继承上一次迭代 速度的能力;c1和c2为学习因子,c1表达粒子对自身记忆的依赖程度,c2决 定粒子群体中其他粒子对粒子本身的影响,他们使每个粒子分别向pbest和 gbest的位置靠近;rand()表示0和1之间服从均匀分布的随机数,用来模 拟自然界中群体行为中的轻微扰动。
[0102]
pso算法收敛速度快且实现简单,因此将每一个粒子视为cnn最优结 构的可能解。每个粒子用离散的网络层功能块组表示,例如:conv|conv| max_pool|conv|fc|fc|,他们
符合预先设定cnn网络层的排列规则。pso 优化cnn网络结构过程中的适应度函数设置为验证集的分类准确率。本发 明的cnn架构的搭建使用keras框架实现。由于keras框架具有高封装性, 在粒子初始化、粒子更新过程中使用keras框架构建卷积神经网络简单易行。
[0103]
②
算法流程
[0104]
该算法由一个粒子群优化算法框架组成,除了有效的cnn表示之外还 包括以下五个步骤用于搜索最优的cnn结构:粒子群的初始化、单个粒子 的适应度评估、测量两个粒子之间的差异,速度计算和粒子更新。
[0105]
粒子群初始化网络结构时需要设置网络层数范围,本实施例最小网络 层数和最大网络层数分别设置为3和20。确定网络层数后随机选择卷积层、 最大池化层、平均池化层和全连接层作为当前层,这里需要满足设定的网 络排列规则:每个粒子的第一层必须是卷积层,最后一层必须是全连接层, 中间随机穿插卷积层、最大池化层、平均池化层和全连接层。此外,一旦 选择全连接层作为当前层,后面只能是全连接层。随机选取卷积层、池化 层和全连接层的概率分别为0.6、0.3和0.1。粒子群初始化算法实现步骤如 表2所示。在选择卷积层的同时随机在[3,256]范围内配置卷积核的数目、 在[3
×
1,7
×
1]范围内生成卷积核尺寸。选择池化层时池化滤波器尺寸设置为 3
×
1,采样步长为2。全连接层的神经元个数的最大值设置为300,最后一 层输出层神经元个数为5。
[0106]
表2 pso-cnn算法初始化粒子群
[0107][0108][0109]
此外,需要定义一个函数用来评估粒子对应架构的适应度,即验证集 的准确率作为评估依据。在由一个粒子直接编译成一个完整的cnn架构时, 本实施例设置卷积层和全连接层的激活函数为relu,最后一层输出层的激活 函数为softmax。为了使神经网络在各层的中间输出数值更稳定,我们对卷 积层和全连接层都做了批量归一化。全连接层之间dropout的比例设置为 0.5。
[0110]
为了找到全局最优解的位置,粒子需要在已知pbest、gbest和自己当前 位置的情况下进行位置更新,由公式(3)和公式(4)可知,这里首先需 要解决的便是粒子差异的计算,即pbest-x和gbest-x。因此我们需要指定粒 子差异计算规则。为了避免在卷积层和池化层之间出现全连接层,求解粒 子差异时,会将全连接层单独分离出来,之后对比粒子之间的层类型。如 果粒子层类型相同,则为0,如果不同,则为第一个粒子的层类型。此外, 如
果两个粒子的层数不同,且第一个粒子的层数比第二个粒子层数多,则 在对应位置添加第一个粒子多的层类型,反之若第一个粒子的层数少于第 二个粒子层数,则移除第二个粒子对应的层类型。
[0111]
在明确粒子差异的计算规则之后便可进行速度计算从而更新位置。由 于需要对cnn架构进行寻优,且是在不使用实值编码的情况下对粒子进行 更新。因此,需要对公式(3)进行改进。本实施例舍弃其中的惯性权重部 分,并且设置一个选择阈值cg,在粒子的每一个位置随机生成一个0到1 之间的数r,当r≤cg时,取pbest-x作为更新后的速度,反之,速度更新为 gbest-x。公式(3)可改写为(5)。我们根据公式(5)和公式(4)更新粒 子,由公式(4)可知,新的粒子由原粒子和速度相加构成。当速度为p、 c或者f时,对原粒子的功能块进行替换操作;当速度为0时保留原来粒 子的功能块;当速度为r时,移除原粒子对应的功能块。粒子架构更新流 程如图2所示。
[0112][0113]
(5)实验建模及模型对比
[0114]
pso-cnn算法使用的参数可以分成三类:粒子群算法参数、cnn架构 初始化以及cnn训练参数。
[0115]
粒子群算法参数主要有迭代次数、种群规模以及更新速度时设置的选 择阈值。其中,较大的迭代次数会增加找到全局最优解的概率。种群规模 对算法的性能也有影响,并且这种影响并不是简单的线性关系,当群体规 模到达一定程度后,再增加群体规模对算法性能的提升有限,反而增加运 算量;但群体规模不能过小,过小的群体规模将无法体现出群智能优化算 法的智能性,导致算法性能严重受损。在综合考虑算法性能和计算量的情 况下,将迭代次数和种群规模分别设置为30和10。
[0116]
cnn架构初始化参数控制着粒子搜索的大小。为了防止生成复杂的粒 子架构,在粒子初始化之前将最大网络层数设置为15。卷积输出通道数、 卷积核尺寸以及全连接层神经元个数在给定范围内初始化并以一定概率生 成卷积层、池化层和全连接层。最后一类参数包含粒子评估时训练的epoch 数和全局最佳粒子训练的epoch数,为了减少整体训练时间,设定粒子评估 时训练的epoch数为1。使用dropout随机丢弃全连接层中的神经元,每个 神经元以0.3的概率被丢弃防止出现过拟合。pso-cnn算法中所有参数设 置如表3所示。
[0117]
表3 pso-cnn算法参数设置
[0118][0119][0120]
五次运行pso-cnn算法寻得的gbest网络架构的建模结果如表4所示。 第二次和第五次获得的cnn框架的测试集平均精度更高,五分类的平均准 确率分别为87.2%、82.6%,这两次寻优得到的最优框架如图3所示。
[0121]
本发明使用的pso-cnn算法中的结构没有在任何关于该问题的领域 知识的情况下发现。尽管该算法在小数据集上进行了测试,但本实施例的 实验结果表明pso-cnn算法寻得的cnn网络架构在血清ft-ir光谱数据 集上对宫颈癌患者进行早期诊断的可行性。
[0122]
表4 pso-cnn算法五次建模结果
[0123][0124]
本实施例将pso-cnn算法第二次和第五次得到的网络架构与经典的 lenet、
alexnet、vgg16和googlenet网络结构进行准确率的比较,实验 结果如表5所示。从表5可以看出pso-cnn算法的测试集准确率要高于其 他四种经典的网络架构,展现了该算法寻得的网络结构的优越性。此外, 所使用的pso-cnn本应该可以达到比这里更好的效果。从表3可以看出由 pso-cnn算法生成的全连接层中最多只有300个神经元,与在全连接层中 使用4096个神经元的vgg16相比,这个数字要小得多。这主要是由于可 用的硬件不允许搜索更复杂的网络。除此之外,也无法运行具有大量粒子 的算法以进行更多迭代。更多的粒子将帮助算法探索更多的cnn架构。 因此,这也大大限制了pso-cnn算法的性能。但同时,这说明了本发明的 技术方案可以通过更少的数据就得到结果。
[0125]
表5 pso-cnn模型与其他经典模型对比
[0126][0127]
基于粒子群算法参数少、收敛快的特点,本发明使用粒子群算法自动 搭建层数不定、层类参数不定的cnn结构,设计了一种基于ft-ir技术的 宫颈癌早期筛查的cnn模型。使用验证集准确率作为网络训练时的评估依 据,实验结果表明pso-cnn算法获取的cnn结构较其他几种经典cnn 结构在宫颈癌早期肿瘤筛查方面具有更好的检测结果。这表明本发明使用 的pso-cnn结构寻优方法在ft-ir技术方面的有效性,可以为后续癌症诊 断选取cnn结构提供参考价值。
[0128]
以上所述,仅是本发明实施例的较佳实施例而已,并非对本发明实施 例作任何形式上的限制,依据本发明实施例的技术实质对以上实施例所作 的任何简单修改、等同变化与修饰,均仍属于本发明实施例技术方案的范 围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1