一种智能面罩及其控制方法与流程
本发明涉及显示技术领域,尤其涉及一种智能面罩及其控制方法。
背景技术:
人们在日常生活和工作中,通常会使用面罩,例如,冬天为了防寒而佩戴口罩;或者,为了避免污染的空气进入呼吸道而佩戴防雾霾口罩;又或者对于医护人员或者实验室人员而言,为了避免对医疗环境或者试验环境收到影响,需要佩戴医用口罩等。
然而,在于佩戴有上述面罩的用户进行交流的过程中,由于面罩挡住了脸颊,因此只能够听到对方的声音,而无法观测到面罩下的表情,从而不利于判断出对方的意图,降低了沟通和交流的效果。
技术实现要素:
本发明的实施例提供一种智能面罩及其控制方法,能够解决对话过程中,佩戴面罩的用户无法使对方看到自己表情的问题。
为达到上述目的,本发明的实施例采用如下技术方案:
本发明实施例的一方面,提供一种智能面罩,包括面罩本体,还包括处理器、显示装置以及面部检测器;所述面部检测器设置于所述面罩本体的内表面,所述面部检测器用于对待测用户的面部动作进行采集;所述处理器与所述面部检测器相连接,所述处理器用于根据采集到的面部动作获取表情图像;所述显示装置与所述处理器相连接,所述显示装置用于接收所述表情图像并进行显示。
优选的,还包括存储器,用于存储预设图像集;所述处理器还与所述存储器相连接,所述处理器用于根据所述面部动作,从所述预设图像集中调取与所述面部动作相匹配的表情图像。
优选的,所述显示装置为第一投影仪,用于将表情图像投影至所述面罩本体的外表面。
优选的,所述显示装置为第二投影仪,用于进行悬浮显示。
优选的,还包括与所述处理器相连接的控制装置;在所述存储器存储有至少两套图像集的情况下,所述控制装置包括模式选择模块和与所述模式选择模块相连接的指令触发模块,当所述模式选择模块处于第一状态时,所述指令触发模块用于向所述处理器发出模式选择指令,所述处理器根据所述模式选择指令,从所述存储器中调取图像集中的表情图像,以通过所述显示装置进行显示;当所述模式选择模块处于第二状态时,所述指令触发模块用于向所述处理器发出模式确定指令,所述处理器根据所述模式确定指令,将所述显示装置显示的表情图像所在的图像集确定为所述预设图像集。
优选的,还包括与所述处理器相连接的控制装置;所述控制装置包括自控模块、动作信号采集模块以及指令触发模块,当所述自控模块处于第一状态时,所述指令触发模块向所述处理器发出自控启动信号,所述处理器根据所述自控启动信号关闭所述面部检测器;当所述自控模块处于第二状态时,所述指令触发模块向所述处理器发出自控解除信号,所述处理器根据所述自控解除信号开启所述面部检测器;当所述面部检测器关闭时,所述动作信号采集模块检测待测用户的动作信号,所述处理器将所述动作信号转换为与所述动作信号相匹配的面部动作,并从所述存储器存储的预设图像集中调取与所述面部动作相匹配的表情图像。
进一步优选的,所述动作信号采集模块包括加速度传感器。
优选的,所述控制装置为可拆卸安装于所述面罩本体上的指环。
优选的,还包括语音识别器,用于对所述待测用户的语音信号进行采集,或者还用于对采集到的语音信号进行处理,并输出与该语音信号相匹配的图像调用指令;所述处理器还与所述语音识别器相连接,所述处理器接收所述语音信号和所述面部动作,并从所述存储器中调取与所述语音信号和所述面部动作相匹配的表情图像;或者,所述处理器接收所述图像调用指令和所述面部动作,并从所述存储器中调取与所述图像调用指令和所述面部动作相匹配的表情图像。
优选的,所述面罩本体内部设置有滤芯,所述智能面罩还包括报警器和两个空气检测仪;其中一个所述空气检测仪设置于所述滤芯内侧,另一个设置于所述滤芯的外侧,所述两个空气检测仪分别用于对滤芯内侧和外侧的空气质量进行测试;所述处理器还与所述空气检测仪和报警器相连接,用于接收两个所述空气检测仪的检测结果,并进行对比,当比较结果小于或等于污染阈值时,所述处理器向报警器发出报警信号,控制所述报警器报警。
优选的,所述面部检测器包括多个所述压力传感器,其中两个所述压力传感器分别与所述待测用户两颊的位置相对应;其余的所述压力传感器均匀分布于与所述待测用户唇部周边相对应的位置。
本发明实施例的另一方面,提供一种智能面罩的控制方法,包括:面部检测器对待测用户的面部动作进行采集;处理器根据采集到的面部动作获取表情图像;显示装置接收表情图像并进行显示。
优选的,所述处理器根据所述面部动作获取表情图像包括,所述处理器根据所述面部动作,调取与所述面部动作相匹配的表情图像。
优选的,所述对待测用户面部的面部动作进行采集之前,所述方法包括:所述处理器接收模式选择指令,并根据所述模式选择指令,从所述存储器中依次调取图像集中的表情图像,所述显示装置对所述表情图像进行显示;所述处理器接收模式确定指令,并根据所述模式确定指令,将所述显示装置显示的表情图像所在的图像集确定为所述预设图像集。
优选的,所述面部检测器对待测用户面部的面部动作进行采集之前,所述方法包括:所述处理器接收自控解除信号,所述处理器根据所述自控解除信号开启所述面部检测器;或者,所述显示装置接收表情图像并进行显示之前,所述方法包括:所述处理器接收自控启动信号,并根据所述自控启动信号关闭所述面部检测器;所述处理器接收动作信号,且将所述动作信号转换为与所述动作信号相匹配的面部动作,并从所述预设图像集中调取与所述面部动作相匹配的表情图像。
本发明实施例提供一种智能面罩及其控制方法,该智能面罩包括面罩本体,还包括处理器、显示装置以及面部检测器。该面部检测器设置于面罩本体的内表面,面部检测器用于对待测用户的面部动作进行采集。处理器设置于面罩本体上,且与面部检测器相连接。该处理器用于根据采集到的面部动作获取表情图像。显示装置与处理器相连接,该显示装置用于接收上述表情图像并进行显示。这样一来,在用户佩戴有上述智能面罩并与人进行交流的情况下,即使对方无法通过智能面罩观察到佩戴该智能面罩的用户的口、鼻以对其表情进行判断,但是当用户的面部表情发生变化时,该智能面罩的面部检测器可以根据上述表情变化对面板动作进行采集,而处理器可以根据采集结果生成面部动作,并向显示装置输出与该面部动作相匹配的表情图像。因此,通过该显示装置可以将上述表情图像进行显示,以使得与佩戴有上述智能面罩进行对话的人能够通过看到显示装置上显示的表情图像,并直观地了解此刻被面罩覆盖的用户的表情,从而便于理解该用户在对话过程中的意图,增加了人与人交流的畅通性,提高了沟通和交流的效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种智能面罩的结构示意图;
图2为本发明实施例提供的另一种智能面罩的结构示意图;
图3为图1或图2中面部检测器的设置位置示意图;
图4为图3中面部检测器的设置方式示意图;
图5为图1中的显示装置的一种显示方式示意图;
图6为图1中的显示装置的一种显示方式示意图;
图7为本发明实施例提供的一种控制装置的结构示意图;
图8为设置有图7所示的控制装置的智能面罩的一种控制方法流程图;
图9为设置有图7所示的控制装置的智能面罩的另一种控制方法流程图;
图10为本发明实施例提供的设置有语音识别器的智能面罩的控制方法流程图;
图11为本发明实施例提供的一种智能面罩的控制方法流程图。
附图标记:
01-智能面罩;10-智能面罩;11-显示装置;110-第一投影仪;111-第二投影仪;12-处理器;13-面部检测器;130-压力传感器;14-存储器;15-控制装置;16-语音识别器;151-模式选择模块;152-指令触发模块;153-自控模块;154-动作信号采集模块;20-固定带;21-头盔本体。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
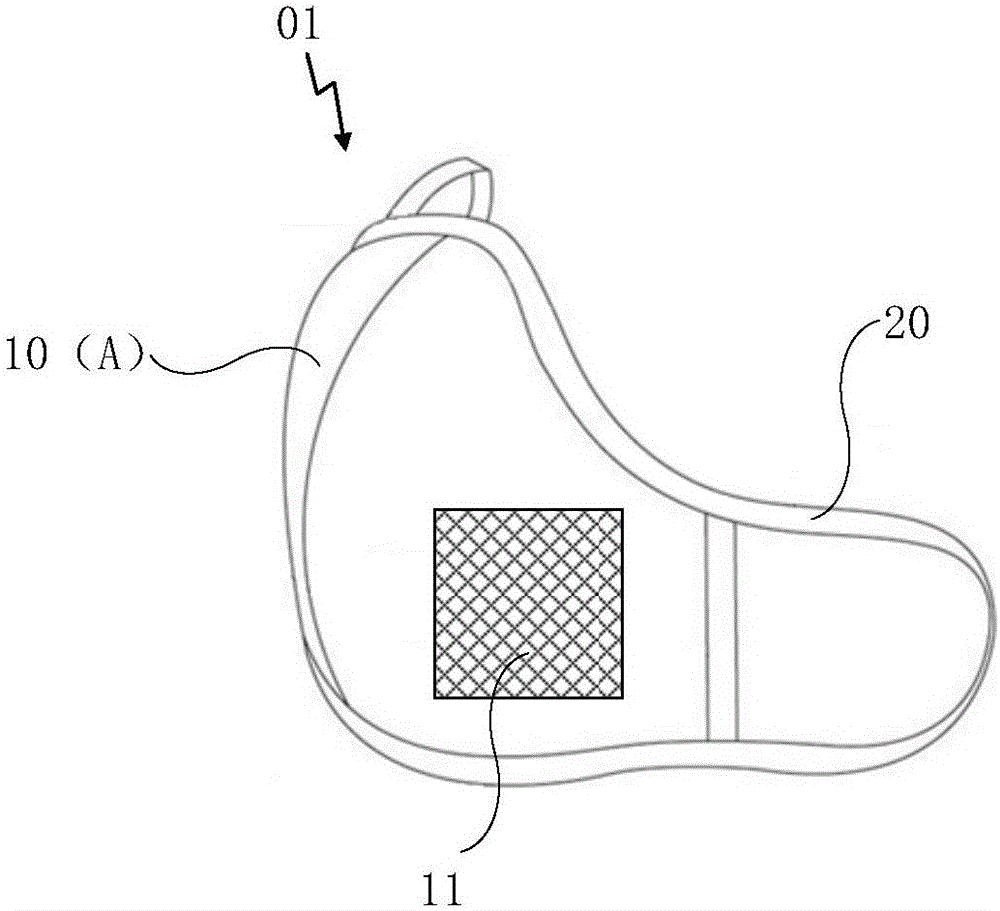
本发明实施例提供一种智能面罩01,如图1或图2所示包括面罩本体10。
需要说明的是,本发明对智能面罩01的应用场景不做限定,例如该智能面罩01可以如图1所示为口罩,而面罩本体10为该口罩中除了耳部固定带20以外的其余部分。在此情况下,用户可以在冬天或雾霾天佩戴该口罩,或者在清洁环境要求较高的医院或者餐厅等环境下佩戴上述口罩,以避免口、鼻与外部环境相接触。又例如,该智能面罩01可以如图2所示为头盔,该头盔包括头盔本体21,以及安装于所述头盔本体21上的面罩本体10,其中,为了避免遮挡用户视线,该面罩本体10对应用户双眼的位置由透明材料构成。在此情况下,当用户在海洋或湖泊中进行潜水时、处于太空环境中时或者处于有毒环境中时,可以佩戴上述头盔,避免整个面部与外界环境相接触。
其中,上述口罩或者头盔在对应用户口、鼻位置处采用通常采用不透明材质,因此他人无法观测到佩戴有上述口罩或头盔的用户的口、鼻。
当然,上述仅仅是对智能面罩01应用场景的具体说明,其他应用场景在此不再一一赘述。
此外,上述智能面罩01如图3所示,还包括处理器12以及面部检测器13。
具体的,面部检测器13如图3所示,设置于面罩本体10的内表面B,面部检测器13用于对待测用户的面部动作进行采集。其中,面罩本体10的内表面B与如图1所示的外表面A为相对的两个表面。当用户佩戴该智能面罩01时,该面罩本体10的内表面B相对于外表面A而言,靠近待测用户的面部。
此外,处理器12与面部检测器13相连接。该处理器12用于根据采集到的面部动作获取表情图像。其中,本发明对处理器12的设置位置不做限定。例如,当该智能面罩01为如图1所示的口罩时,上述处理器12可以设置于面罩本体10上(例如内表面B、外表面A或者面罩本体10的内部)。又或者,当该智能面罩01为如图2所示的头盔时,上述处理器12除了可以设置于面罩本体10上以外,还可以设置于头盔本体21上。
需要说明的是,上述待测用户的面部动作是指,待测用户的面部表情发生变化时,面部肌肉的收缩或舒展。
其中,当待测用户佩戴该智能面罩01时,上述面罩本体10与用户的面部接触较紧密,例如该面罩本体10为口罩的一部分时,上述面部检测器13如图4所示,可以包括多个压力传感器130,每一个压力传感器130分别位于待测用户面部的不同位置。由于用户的面部表情发生变化时,面颊和唇部位置的肌肉变化最为明显,因此优选的,其中两个压力传感器130分别与待测用户两颊的位置相对应,而其余的压力传感器130均匀分布于与该待测用户唇部周边相对应的位置。当用户佩戴上述智能面罩时,上述各个压力传感器130可以与待测用户的面部相接触。
在此情况下,待测用户的面部表情发生变化时,位于不同位置的压力传感器130受到的压力不同,并分别将采集到的压力值传输至处理器12。例如,当待测用户微笑时,两颊的肌肉鼓起,而唇部的肌肉舒张,因此位于两颊位置的压力传感器130受到的压力较大,而位于唇部的压力传感器130受到的压力较小。基于此,该处理器12根据接受到的各个压力数据,得出每一个压力传感器130所检测位置处面部肌肉的肌电图,然后再结合每一个压力传感器130的设置位置,获取能够与所述待测用户真实表情相匹配的表情图像。
或者,当待测用户佩戴该智能面罩01时,上述面罩本体10与用户的面部之间还具有空隙,例如该面罩本体10为头盔的一部分时,上述面部检测器13可以包括多个分别位于待测用户面部的不同位置得距离传感器,例如红外距离传感器。该多个距离传感器的位置设置方式可以与上述压力传感器130的位置设置方式相同。在此情况下,待测用户的面部表情发生变化时,随着面部肌肉的收缩和舒张,位于不同位置的距离传感器检测到的距离不同。因此处理器12同样可以根据距离传感器的检测结果得出上述各个检测位置处面部肌肉的肌电图,并最终获取到与所述待测用户真实表情相匹配的表情图像。
当然,上述仅仅是对面部检测器13结构和设置位置的举例说明,其他事例在此不再一一赘述。
此外,该智能面罩01如图1或图2所示,还包括显示装置11,该显示装置11与处理器12相连接。该显示装置用于对上述处理器12获取到的表情图像进行显示。
需要说明的是,上述显示装置11可以可拆卸安装,例如通过架子安装于该智能面罩01的面罩本体10上。
其中,该显示装置11可以为柔性显示装置。或者,如图5所示,该显示装置11为第一投影仪110,用于将表情图像C投影至面罩本体10的外表面。
需要说明的是,使得面罩本体10能够具有足够的空间用于承载表情图像C,优选的,上述第一投影仪110可以设置于面罩本体10的边缘位置,例如图5中设置于面罩本体10的左边缘。在此情况下,第一投影仪110沿图5箭头所示方向向右投射,并将表情图像C投影于面罩本体10的外表面。基于此,当将第一投影仪110设置于面罩本体10的右、上或下边缘时,投影方向同理可得,此处不再赘述。
此外,还可以在面罩本体10的相对两侧分别设置两个第一投影仪110,使得两个第一投影仪110沿相反反向进行投影,并且分别投影后的图形叠加为一个完整的表情图像C,以提高表情图像C显示的清晰度。
需要说明的是,本文中,“左”、“右”、“上”以及“下”等方位术语是相对于附图中的面罩本体示意置放的方位来定义的,应当理解到,这些方向性术语是相对的概念,它们用于相对于的描述和澄清,其可以根据面罩本体所放置的方位的变化而相应地发生变化。
此外,由于面罩本体10外表面的颜色并不限于纯色,因此当面罩本体10外表面的为彩色或具有花型时,设置上述第一投影仪110进行表情图像C显示的效果并不理想。因此优选的,该显示装置11可以如图6所示为第二投影仪111,该用于第二投影仪111进行悬浮显示。
具体的,该第二投影仪111可以选定面罩本体10前方的一部分空气进行电离处理,然后将上述表情图像C沿上述电离方向(图6中的箭头所述方向)投影于电离后的空气上,以实现悬浮显示。
在此情况下,当面罩本体10的外表面为彩色且具有花型时,可以通过第二投影仪111将表情图像C投影至背景单一(例如背景为天空)的空气中进行悬浮显示,可以避免将表情图像C直接投影至彩色或具有花型的面罩本体10外表面,而导致表情图像C与彩色图案或花型相叠加,使得表情图像不清晰的问题。
需要说明的是,上述第一投影仪110和/或第二投影仪111可以设置于面罩本体10的外部,也可以设置于面罩本体10的内部。并且当第一投影仪110和第二投影仪111设置于面罩本体10的内部时,可以仅将覆盖第一投影仪110和第二投影仪111的面罩本体10采用透明材料构成,以使得第一投影仪110和第二投影仪111发出的光线能够透过面罩本体10出射。
综上所述,在用户佩戴有上述智能面罩并与人进行交流的情况下,即使对方无法通过智能面罩观察到佩戴该智能面罩的用户的口、鼻以对其表情进行判断,但是当用户的面部表情发生变化时,该智能面罩的面部检测器可以根据上述表情变化对面板动作进行采集,而处理器可以根据采集结果生成面部动作,并向显示装置输出与该面部动作相匹配的表情图像。因此,通过该显示装置可以将上述表情图像进行显示,以使得与佩戴有上述智能面罩进行对话的人能够通过看到显示装置上显示的表情图像,并直观地了解此刻被面罩覆盖的用户的表情,从而便于理解该用户在对话过程中的意图,增加了人与人交流的畅通性,提高了沟通和交流的效果。
需要说明的是,该处理器12根据面部检测器13采集到的面部动作获取表情图像C可以是,该处理器12根据面部动作直接通过图像处理生成表情图像C,或者当上述智能面罩10具有与上述处理器12相连接的存储器14(如图8所示)时,该还处理器12可以根据上述面部动作从该存储器14存储的预设图像集中,调取与上述面部动作相匹配的表情图像C,在此情况下,该处理器12无需生成上述表情图像C,只需要根据面部检测器13采集到的信号即上述面部动作,进行信号匹配,从而在存储器14中调取与该面部动作相匹配的表情图像C。这样一来,能够减少处理器12的计算量,达到提高信息处理效率的目的。
其中,上述预设图像集是指预先设定的由多个表情图像C构成的图像集。
进一步的,当上述存储器14存储有至少两套图像集,且每个图像集包括同一类别多个表情图像时,用户可以在佩戴该智能面罩01之前,根据个人喜好选择一图像集作为上述预设图像集,以便于佩戴该智能面罩01后,该智能面罩01显示的图像均为属于用户已选择的图像集。
其中,上述每个图像集包括同一类别多个表情图像是指,每个图像集包括均为一卡通人物的一套表情图像集,或者为一公众人物的一套表情图像集,又或者为待测用户自己的一套表情图像集。该表情图像集中包括分别对应喜、怒、哀、乐等情绪的多个表情图像。
在此基础上,为了设置上述预设图像集,该智能面罩01还可以包括与该处理器11相连接,如图7所示的控制装置15。
该控制装置30包括模式选择模块151以及与该模式选择模块151相连接的指令触发模块152(如图8所示)。
在此情况下,当模式选择模块151处于第一状态时,该指令触发模块用于向处理器12发出模式选择指令。该处理器12根据模式选择指令,从存储器14中调取图像集中的表情图像,以通过显示装置11进行显示。
这样一来,当用户佩戴上述智能面罩01之前,可以根据个人喜好对存储器14中存储有至少两套图像集进行选择。具体的,用户触发模式选择模块151使其处于第一状态,此时用户能够通过投影至面罩本体10上的表情图像,或者悬浮显示于空中的表情图像,并根据自己的个人喜好进行选择。
此外,当上述模式选择模块151处于第二状态时,上述指令触发模块用于向处理器12发出模式确定指令,该处理器12根据模式确定指令,将显示装置11显示的表情图像所在的图像集确定为上述预设图像集。
需要说明的是,处理器12可以控制显示的表情图像进行自动更换,或者,用户可以通过手势例如向右或左滑动,更换显示的表情图像。又或者,当上述控制装置30设置有触控模块时,用户可以通过触控操作,更换显示的表情图像。当用户发现喜欢的表情图像时,可以控制模式选择模块151处于第二状态。
这样一来,用户通过观察显示装置11显示的表情图像,当确定出于个人喜好相匹配的表情图像时,可以触发模式选择模块151使其处于第二状态,此时处理器12将显示装置11显示的表情图像所在的图像集确定为上述预设图像集。之后,当用户佩戴该智能面罩01后,该智能面罩01显示的表情图像均为属于用户已选择的图像集,即显示的表情图像均处于上述确定出的预设图像集中的图像。
需要说明的是,模式选择模块151可以包括一按键本体,当用户单次按压该按键本体时,该模式选择模块151处于上述第一状态,从使得智能面罩01进入预设图像集的选择状态。当双次按压该按键本体时,该模式选择模块151处于上述第二状态,从使得智能面罩01进入预设图像集的选择状态。
或者,该模式选择模块151可以包括方向传感器,从而能够通过用户的手势,使其进入第一或第二状态。例如当用户手持该控制装置15且向左摆动时,该模式选择模块151处于上述第一状态,当用户手持该控制装置15且向右摆动时,该模式选择模块151处于上述第二状态。又或者,该模式选择模块151可以包括加速度传感器,也能够通过用户的手势,使其进入第一或第二状态。例如当用户手持该控制装置15摆动两次时,该模式选择模块151处于上述第一状态,当用户手持该控制装置15摆动两次时,该模式选择模块151处于上述第二状态。其他手势控制方式,在此不再一一赘述。
然而,由于上述智能面罩01显示的表情图像C与面部检测器13检测到的待测用户的面部动作相匹配,而有些情况下,用户并不希望自己的真实表情通过智能面罩01进行显示。例如当用户由于某种原因无法大笑或微笑时,该智能面罩01将无法显示出大笑或微笑的表情图像。
为了解决上述问题,上述智能面罩01可以包括控制装置15,该控制装置15包括如图7所示的自控模块153,且还包括如图9所示的动作信号采集模块154以及指令触发模块152。
在此情况下,当自控模块153处于第一状态时,指令触发模块152向处理器12发出自控启动信号,该处理器12根据自控启动信号关闭上述面部检测器13。
当自控模块153处于第二状态时,指令触发模块152向处理器12发出自控解除信号,该处理器12根据自控解除信号开启面部检测器13。
需要说明的是,上述处理器12根据自控启动信号对面部检测器13进行关闭可以是,处理器12根据自控启动信号,控制供电部件停止向面部检测器13进行供电,以使得面部检测器13处于关闭状态。或者,还可以是处理器12将面部检测器13向该处理器12提供的检测信号进行屏蔽,使得该处理器12接受面部检测器13输出信号的功能失效。
当面部检测器13关闭时,上述动作信号采集模块154检测待测用户的动作信号,该处理器12将动作信号转换为与该动作信号相匹配的面部动作,并从存储器14存储的预设图像集中调取与面部动作相匹配的表情图像。
其中,上述动作信号采集模块154可以为加速度传感器,在此情况下,上述动作信号可以为用户的手势,当用户手势发生变化时该加速度传感器检测到的加速度不同。例如,当用户手持该控制装置15摆动两次时,动作信号采集模块154向处理器12输出与摆动两次的手势相匹配的第一加速度数据(即第一动作信号),处理器12能够将上述第一加速度数据转换为与该加速度相匹配的面部动作,例如微笑,然后从存储器14中调取与微笑相匹配的表情图像。或者,又例如,当用户手持该控制装置15摆动三次时,动作信号采集模块154向处理器12输出与摆动三次的手势相匹配的第二加速度数据(即第二动作信号),处理器12能够将上述第二加速度数据转换为与该加速度相匹配的面部动作,例如大笑,然后从存储器14中调取与大笑相匹配的表情图像。这样一来,由于面部检测器13关闭,因此佩戴有该智能面罩01的用户无需再通过面部检测器13将自己的真实表情进行显示,而是通过手势达到控制显示表情图像的目的。
进一步的,为了方便用户携带上述控制装置15,优选的,如图7所示,上述控制装置15可以为可拆卸安装于上述面罩本体10上的指环。当用户需要使用控制装置15时,可以将上述指环套于手指上。
在此基础上,为了进一步提高通过该智能面罩01显示出的表情图像与待测用户(即佩戴上述智能面罩01的用户)想表达的表情之间的匹配程度,该智能面罩01还包括语音识别器16(如图10),其中该语音识别器16可以通过可拆卸的方式设置上述面罩本体10上,或者当上述智能面罩01如图2所示为头盔时,该语音识别器16还可以安装于头盔本体21上。或者当该智能面罩01还包括控制装置15时,该语音识别器16也可以安装于该控制装置15上,本发明对此不做限定。
在此情况下,该语音识别器16用于对待测用户的语音信号进行采集,或者该语音识别器16还用于对采集到的语音信息进行处理,并向处理器12发送与该语音信息相匹配的图像调用指令。
基于此,上述处理器12还与该语音识别器16相连接,该处理器12可以接收上述语音识别器16输出的语音信号以及面部检测器13采集到的面部动作,并从存储器14中调取与该语音信号和面部动作相匹配的表情图像。
具体的,例如,在语音识别器16仅用于对待测用户的语音信号进行采集情况下,当用户大笑时,处理器12接收面部检测器13采集到的面部动作,并从存储器14中调取与大笑相匹配的表情图像,并通过显示装置11进行显示。此外,语音识别器16对笑声进行采集,该处理器12接收上述语音识别器16输出的语音信号,并将显示装置11显示的大笑表情图像延时几秒,提高了显示的图像表情与待测用户想表达的表情之间的匹配程度。
或者,该处理器12可以接收上述语音识别器16输出的图像调用指令以及面部检测器13采集到的面部动作,并从存储器14中调取与该图像调用指令和面部动作相匹配的表情图像。
具体的,例如,在语音识别器16用于对待测用户的语音信号进行采集以外,还用于对采集到的语音信息进行处理,并向处理器12发送与该语音信息相匹配的指令情况下,当用户说出语音“么么哒”时,处理器12接收面部检测器13采集到的面部动作,并从存储器14中调取与用户表达“么么哒”时的愉快的情绪相匹配的表情图像,例如微笑、爱心、大笑等。在此基础上,语音识别器16对用户的语音进行采集,并根据语音信息输图像调用指令,该处理器12接收上述图像调用指令,从上述多个愉快的表情中选取爱心图像,以通过显示装置11进行显示。
或者,当用户采用上述控制装置15通过处理器12关闭上述面部检测器13后,在处理器12于与该语音识别器16相连接的情况下,处理器12除了接收上述语音识别器16输出的语音信号以外,还接收动作信号采集模块154输出的待测用户的动作信号,并将该动作信号转换为与该动作信号相匹配的面部动作,然后处理器12从存储器14中调取与该语音信号和面部动作相匹配的表情图像。
进一步的,为了减少外界污染的空气呼吸至人体,优选的,上述面罩本体10内部可以设置滤芯(图中未示出)。具体的,当该智能面罩01可以如图1所示为口罩时,上述面罩本体10通常采用柔性且具备透气性的材料构成,此时可以将滤芯设置于面罩本体10的夹层中。或者,当该智能面罩01可以如图2所示为头盔时,通常面罩本体10通常采硬质材料构成,当将滤芯设置于面罩本体10的夹层中后,还需要在面罩本体10的内外表面且对应滤芯的位置开设多个出气孔。
在此基础上,该智能面罩01还可以包括报警器和两个空气检测仪(上述部件图中未示出)。其中一个空气检测仪设置于滤芯内侧,另一个设置于滤芯的外侧,上述两个空气检测仪分别用于对滤芯内侧和外侧的空气质量进行测试。此外,上述处理器12还与空气检测仪和报警器相连接,用于接收两个空气检测仪的检测结果,并进行对比,当比较结果小于或等于污染阈值时,处理器12向报警器发出报警信号,控制报警器报警。
需要说明的是,上述污染阈值可以根据需要进行设定。上述处理器12还与空气检测仪和报警器相连接,用于接收两个空气检测仪的检测结果,并进行对比是指,在空气检测仪检测数值与污染程度呈正比的情况下,处理器12可以将设置于滤芯外侧的空气质量的检测数值与滤芯内侧的空气质量的检测数值相减,当上述差值小于污染阈值时,表示滤芯内侧的空气质量以接近污染指数,在此情况下,报警器会通过亮灯或者震动的方式进行报警,提醒用户跟换滤芯。
本发明实施例提供一种用于控制上述任意一种智能面罩的方法,如图11所示,可以包括:
S101、如图3所示的面部检测器13对待测用户的面部动作进行采集。
S102、处理器12根据采集到的面部动作获取表情图像。
S103、显示装置11接收上述表情图像并进行显示。
这样一来,在用户佩戴有上述智能面罩并与人进行交流的情况下,的用户的面部表情发生变化时,面部检测器可以根据上述表情变化对面板动作进行采集,而处理器可以根据采集结果生成面部动作,并向显示装置输出与该面部动作相匹配的表情图像。在此情况下,在通过显示装置将上述表情图像进行显示,以使得与佩戴有上述智能面罩进行对话的人能够通过看到显示装置上显示的表情图像,了解此刻被面罩覆盖的用户的表情,从而便于理解该用户在对话过程中的意图,沟通和交流的效果。
需要说明的是,该处理器12根据面部动作获取表情图像C可以是,该处理器12根据面部动作直接通过图像处理生成表情图像C,或者当上述处理器与存储有预设图像集的存储器14相连接时,上述步骤S102包括:该处理器12根据所述面部动作,从该预设图像集中调取与面部动作相匹配的表情图像。
进一步的,当上述存储器14存储有至少两套图像集,且每个图像集包括同一类别多个表情图像时,用户可以在佩戴该智能面罩01之前,根据个人喜好选择一图像集作为上述预设图像集,以便于佩戴该智能面罩01后,该智能面罩01显示的图像均为属于用户已选择的图像集。
在此基础上,为了设置上述预设图像集,在该智能面罩01包括如图7所示的控制装置15,且控制装置15如图8所示,包括模式选择模块151以及指令触发模块152的情况下,上述步骤S101之前,该控制方法包括:
首先,处理器12接收模式选择指令,并根据模式选择指令,从存储器14中依次调取图像集中的表情图像,显示装置11对表情图像进行显示。
这样一来,当用户佩戴上述智能面罩01之前,可以根据个人喜好对存储器14中存储有至少两套图像集进行选择。具体的,用户触发模式选择模块151使其处于第一状态,此时用户能够通过投影至面罩本体10上的表情图像,或者悬浮显示于空中的表情图像,并根据自己的个人喜好进行选择。
然后,处理器12接收模式确定指令,并根据模式确定指令,将显示装置11显示的表情图像所在的图像集确定为预设图像集。
这样一来,用户通过观察显示装置11显示的表情图像,当确定出于个人喜好相匹配的表情图像时,可以触发模式选择模块151使其处于第二状态,此时处理器12将显示装置11显示的表情图像所在的图像集确定为上述预设图像集。之后,当用户佩戴该智能面罩01后,该智能面罩01显示的表情图像均为属于用户已选择的图像集,即显示的表情图像均处于上述确定出的预设图像集中的图像。
然而,由于上述智能面罩01显示的表情图像C与面部检测器13检测到的待测用户的面部动作相匹配,而有些情况下,用户并不希望自己的真实表情通过智能面罩01进行显示。例如当用户由于某种原因无法大笑或微笑时,该智能面罩01将无法显示出大笑或微笑的表情图像。
为了解决上述问题,在处理器还与控制装置15相连接,且该控制装置15包括如图7所示的自控模块153,还包括如图9所示的动作信号采集模块154以及指令触发模块152的情况下,上述步骤S101之前,所述方法包括:
处理器12接收自控解除信号,处理器12根据自控解除信号开启面部检测器13。然后执行上述步骤S102和S103。
或者,
在上述步骤S103之前,上述控制方法包括:首先,处理器12接收自控启动信号,并根据自控启动信号关闭面部检测器13。
然后,处理器12接收动作信号,且将动作信号转换为与动作信号相匹配的面部动作,并从预设图像集中调取与面部动作相匹配的表情图像。
具体的,当用户手持该控制装置15摆动两次时,处理器12接收与摆动两次的手势相匹配的第一动作信号,处理器12能够将上述第一动作信号转换为与其相匹配的面部动作,例如微笑,然后从预设图像集中调取与微笑相匹配的表情图像。或者,又例如,当用户手持该控制装置15摆动三次时,处理器12接收与摆动三次的手势相匹配的第一动作信号,处理器12能够将上述第一动作信号转换为与其相匹配的面部动作,例如大笑,然后从预设图像集中调取与大笑相匹配的表情图像。这样一来,由于面部检测器13关闭,因此佩戴有该智能面罩01的用户无需再通过面部检测器13将自己的真实表情进行显示,而是通过手势达到控制显示表情图像的目的。
本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于一计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!