印刷装置、学习装置及学习方法与流程
本发明涉及印刷装置、学习装置及学习方法。
背景技术:
在印刷装置中存在为了输送印刷介质、滑架等被输送物而使用电机的情况。在通过电机输送被输送物的情况下,通过pid控制等各种方法控制电机,并通过该电机的动作输送被输送物。在控制电机时,存在确定各种控制参数(例如,pid控制中的比例增益,积分增益,微分增益等)的必要。以往,通过试错等来确定控制参数,在该控制参数下工作的印刷装置被推向市场。在这种情况下,由于若电机的停止特性根据外部环境等而变化,则会使被输送物的定位精度降低,以往开发了各种校正技术。例如,在专利文献1中公开有比较电机的实际的停止特性和作为基准的停止特性,从而校正控制参数以获得基准的停止特性的技术(专利文献1)。
专利文献1:日本特开2008-30216号公报
然而,存在即使使用现有技术,也难以根据电机的多年老化或被输送物的特性、使用环境来高精度良地校正控制参数的情况。
技术实现要素:
为了解決上述技术问题的至少一个,具备输送被输送物的电机的印刷装置具备:存储部,存储已学习模型,所述已学习模型基于状态变量而输出所述电机的控制参数,其中,所述状态变量包括所述被输送物的速度、所述被输送物的加速度、所述被输送物的移动量、所述被输送物的移动开始位置、所述印刷装置的周围环境、流过所述电机的电流值、由所述印刷装置印刷的印刷介质的种类、及所述被输送物的累积移动量中的至少一个,所述电机的控制参数是使所述被输送物的输送位置靠近基准的控制参数;以及控制部,根据基于所述已学习模型而获取的所述控制参数来控制所述电机从而进行印刷。根据该结构,能够通过根据印刷装置的状态而最优化的控制参数来控制电机,从而能够长期维持被输送物的输送位置靠近基准的(定位精度高)状态。
此外,也可以构成为,所述已学习模型的学习是通过观测至少一个所述状态变量,并基于所观测到的所述状态变量来确定使所述控制参数变化的行动,并基于所述被输送物的输送位置的与基准之间的偏差来最优化所述控制参数而执行的。即,通过由强化学习来学习已学习模型,能够容易地定义因被输送物的输送位置靠近基准而提高定位精度的最优化的控制参数。
此外,也可以构成为,与所述基准之间的偏差是基于表示通过所述印刷装置具备的相机所拍摄的所述被输送物的输送位置的图像而确定的。根据该结构,能够通过印刷装置所具备的相机来确定在已学习模型的学习中使用的与基准之间的偏差,不必使用其他的装置等测定印刷后的印刷介质。因而,简化与学习相关的工作。
此外,也可以构成为,表示所述被输送物的输送位置的图像是所拍摄的由所述印刷装置对印刷介质印刷的调整图案的图像。如果为该结构,就能够通过评估一定规格的调整图案的印刷结果来确定与基准之间的偏差。
此外,也可以构成为,在所述印刷介质上印刷的对象大于既定大小的情况下视为产生了与所述基准之间的偏差,在所述印刷介质上印刷的对象在所述既定大小以下的情况下视为未产生与所述基准之间的偏差。根据该结构,能够简单地评估被输送物的输送位置与基准之间的偏差。
此外,也可以构成为,所述已学习模型的学习通过以下方式来执行:基于与所述基准之间的偏差越小而越大的报酬,通过反复进行所述状态变量的观测、与该状态变量相应的所述行动的确定、及通过该行动而获得的所述报酬的评估来最优化所述控制参数。根据该结构,通过由强化学习来学习已学习模型,能够容易地定义因被输送物的输送位置靠近基准而提高定位精度的最优化的控制参数。
此外,也可以构成为,所述已学习模型按照所述印刷装置中的每个印刷速度进行学习。根据该结构,能够获取适合印刷装置所采用的每个印刷速度的控制参数。
此外,也可以构成为一种学习装置,是在具备输送被输送物的电机的印刷装置中所参照的已学习模型的学习装置,所述学习装置具备学习部,所述学习部获取所述已学习模型,所述已学习模型为基于状态变量而输出所述电机的控制参数的模型,其中,所述状态变量包括所述被输送物的速度、所述被输送物的加速度、所述被输送物的移动量、所述被输送物的移动开始位置、所述印刷装置的周围环境、流过所述电机的电流值、由所述印刷装置印刷的印刷介质的种类、及所述被输送物的累积移动量中的至少一个,所述电机的控制参数是使所述被输送物的输送位置靠近基准的控制参数。即,本发明也可以作为输出控制参数的已学习模型的学习装置而成立。
此外,也可以构成为一种学习方法,是在具备输送被输送物的电机的印刷装置中所参照的已学习模型的学习方法,所述学习方法获取所述已学习模型,所述已学习模型为基于状态变量而输出所述电机的控制参数的模型,其中,所述状态变量包括所述被输送物的速度、所述被输送物的加速度、所述被输送物的移动量、所述被输送物的移动开始位置、所述印刷装置的周围环境、流过所述电机的电流值、由所述印刷装置印刷的印刷介质的种类、及所述被输送物的累积移动量中的至少一个,所述电机的控制参数是使所述被输送物的输送位置靠近基准的控制参数。即,本发明也可以作为输出控制参数的已学习模型的学习方法而成立。
附图说明
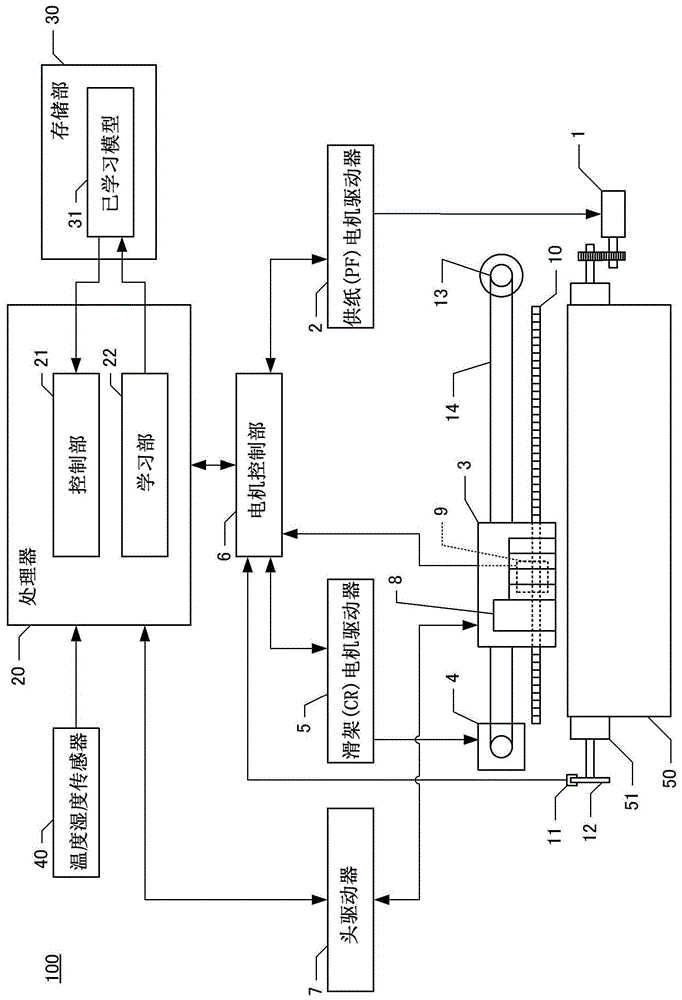
图1是表示印刷装置的结构的图。
图2是表示电机控制部的结构的图。
图3是表示通过强化学习进行学习的例子的图。
图4是表示调整图案的图。
图5是与基准之间的偏差的说明图。
图6是与基准之间的偏差的说明图。
图7是表示多层神经元网络的例子的图。
图8是学习处理的流程图。
图9是印刷处理的流程图。
附图标记说明
1…pf电机;2…pf电机驱动器;3…滑架;4…cr电机;5…cr电机驱动器;6…电机控制部;6a…位置运算部;6b…减法器;6c…目标速度运算部;6d…速度运算部;6e…减法器;6f…比例要素;6g…积分要素;6h…微分要素;6i…加法器;6j…d/a转换器;6k…计时器;6m…加速控制部;7…头驱动器;8…相机;9…编码器;10…编码器用编码板;11…编码器;12…编码器用编码板;13…带轮;14…同步带;20…处理器;21…控制部;22…学习部;30…存储部;31…已学习模型;40…温度湿度传感器;50…印刷介质;51…pf辊。
具体实施方式
以下,参照附图按照以下顺序对本发明的实施方式进行说明。需要说明的是,对各图中对应的组件赋予相同的符号,省略重复的说明。
(1)印刷装置及学习装置的结构:
(2)控制参数的确定:
(2-1)已学习模型的学习:
(2-2)控制参数的学习例:
(3)印刷处理:
(4)其他实施方式:
(1)印刷装置及学习装置的结构:
图1是表示作为本发明的一实施方式的印刷装置及学习装置的概略结构的框图。图1示出的印刷装置100具备进行供纸的供纸电机(以下,也称pf电机。)1、pf电机驱动器2、滑架3、滑架电机(以下,也称cr电机。)4、cr电机驱动器5、电机控制部6及头驱动器7。
另外,印刷装置100具备相机8、(线性)编码器9、(线性)编码器用编码板10、(旋转式)编码器11、(旋转式)编码器用编码板12、带轮13、同步带14、处理器20、存储部30、温度湿度传感器40及输送印刷介质50的pf辊51。当然,在图1中,省略印刷装置100所包括的其他的结构,例如,也可以具备用于防止头的堵塞的控制墨水的吸出的泵等。
温度湿度传感器40输出表示印刷装置100的周围的温度及湿度的信息。在本实施方式中,pf电机1由pf电机驱动器2旋转驱动。若pf电机1旋转后,则经由齿轮等旋转pf辊51并输送印刷介质50。
cr电机4由cr电机驱动器5旋转驱动。若cr电机4正转、反转,则滑架3经由同步带14在直线方向上往复移动。滑架3具备未图示的头,通过头驱动器7的控制喷出多个颜色的墨水的墨滴,在印刷介质50上进行印刷。
这样,在本实施方式中,能够使用滑架3的向直线方向的往复移动和pf辊51的印刷介质的输送而在印刷介质的二维的范围进行印刷。在本实施方式中,将滑架3的移动方向称为主扫描方向,将通过pf辊51的印刷介质的移动方向称为副扫描方向。在本实施方式中,主扫描方向和副扫描方向相互垂直。
头驱动器7生成对滑架3具备的未图示的头施加的电压,并控制对各头的电压供给。向各头供给电压后,喷出与电压相应的墨滴并在印刷介质上进行印刷。
在本实施方式中,滑架3具备相机8。相机8具备未图示的光源和传感器,能够通过光源在印刷介质50被照明的状态下获取印刷介质50的图像。由于相机8安装于滑架3,通过移动滑架3,能够获取主扫描方向的任意位置的图像。在本实施方式中,能够获取进行印刷的印刷介质50或未进行印刷的印刷介质50的图像。
电机控制部6具备向pf电机驱动器2和cr电机驱动器5输出直流电流指令值的回路。pf电机驱动器2旋转驱动在与直流电流指令值相应的电流值下的pf电机1。cr电机驱动器5旋转驱动在与直流电流指令值相应的电流值下的cr电机4。
编码器用编码板10是以预定的间隔形成有狭缝的细长部件,其以与主扫描方向平行的方式固定于印刷装置100内。编码器9固定于与滑架3的编码器用编码板10对应的位置。编码器9通过输出与随着滑架3的移动而横切编码器9的狭缝的数量对应的脉冲而输出表示滑架3的位置的信息。
编码器用编码板12是薄板状的圆形部件,放射状地按每预定的角度形成狭缝,并固定于pf辊51的轴。编码器11固定于编码器用编码板12的外周部分中不妨碍编码器用编码板12的旋转的位置。编码器11通过输出与随着pf辊51的旋转而横切编码器11的狭缝的数量对应的脉冲而输出表示pf辊51的位置(旋转角度)的信息。
处理器20具备未图示的cpu,ram,rom等,能够执行存储于rom等程序。当然,处理器20可以是各种的结构,可以使用asic或gpu等。处理器20通过执行程序来控制印刷装置100的各部。
处理器20能够控制印刷装置100中的各种控制对象。这里,主要说明印刷的控制和用于提高被输送物(印刷介质50及滑架3)的位置精度的控制。当执行这些用于控制的程序后,处理器20作为控制部21发挥作用。在印刷的控制中,通过基于显示印刷对象的图像数据而进行图像处理,控制部21确定喷出到印刷介质50的每个像素的全部墨水的颜色或墨滴的大小等。而且,基于处理结果,控制部21获取用于在印刷介质50上印刷墨滴所必要的pf电机1、cr电机4的时间序列的目标位置及头的驱动定时。
为了将pf电机1、cr电机4配置在目标位置,控制部21向电机控制部6指示控制目标,驱动pf辊51并驱动滑架3。
即,控制部21在使pf辊51旋转来输送印刷介质50时,向电机控制部6输出必要的时间序列的pf电机1的目标位置(目标旋转角度)。电机控制部6输出用于将pf电机1移动到该目标位置的电流值。基于该电流值,pf电机驱动器2驱动pf电机1以使pf电机1成为目标位置。
另外,控制部21在使滑架3进行主扫描时,向电机控制部6输出必要的时间序列的滑架3的目标位置。电机控制部6输出用于使该滑架3向目标位置移动的电流值。基于该电流值,cr电机驱动器5驱动cr电机4以使滑架3成为目标位置。
此外,控制部21在通过图像处理而获得的头的驱动定时,进行用于在印刷介质50记录墨滴的控制。即,控制部21向头驱动器7输出在头的驱动定时及各驱动定时的墨滴的量(墨点的大小)。在该驱动定时,头驱动器7生成用于喷出该量的墨滴的电压,并向各头供给电压。滑架3的头由该电压驱动、喷出墨滴并在印刷介质50上进行印刷。
在本实施方式中,如上所述,通过依次进行印刷介质50的输送、滑架3的输送及来自头的墨滴的喷出而进行印刷。在这样的印刷中,为了维持印刷品质,有必要将作为被输送物的印刷介质50或滑架3高精度地输送到目标的位置。因此,在本实施方式中的电机控制部6通过反馈控制来控制pf电机1及cr电机4。
图2是表示电机控制部6的结构的框图。为了分别控制pf电机1及cr电机4,在电机控制部6中具备2组相同的回路(但是,控制参数可能不同),这里不对两者进行区别说明。电机控制部6具备位置运算部6a、减法器6b、目标速度运算部6c、速度运算部6d、减法器6e、比例要素6f、积分要素6g、微分要素6h、加法器6i、d/a转换器6j、计时器6k及加速控制部6m。
位置运算部6a检测编码器9、11的输出脉冲,对检测出的输出脉冲的个数计数,并基于该计数值来计算滑架3、pf电机1的位置。减法器6b计算从控制部21发送的目标位置和通过位置运算部6a求得的滑架3、pf电机1的实际位置的位置偏差。
目标速度运算部6c基于作为减法器6b的输出的位置偏差来计算滑架3、pf电机1的目标速度。通过将位置偏差乘以增益kp进行该计算。该增益kp由位置偏差确定。另外,该增益kp的值也可以整理于未图示的表中。
速度运算部6d基于编码器9、11的输出脉冲来计算滑架3、pf电机1的速度。可以在各种方法下进行速度的计算,例如,通过时间计数器计数输出脉冲的沿之间的时间间隔,速度运算部6d能够采用通过将沿之间的距离除以时间计数器的计数值而计算的方法等。减法器6e计算目标速度和由速度运算部6d计算的滑架3、pf电机1的实际速度的速度偏差。
比例要素6f将上述速度偏差乘以常数gp,并输出乘法运算结果。积分要素6g是累加将速度偏差乘以常数gi的结果。微分要素6h是将现在的速度偏差与前一个的速度偏差的差乘以常数gd,并输出乘算结果。比例要素6f、积分要素6g及微分要素6h的计算是按照编码器9、11的输出脉冲的每个周期,例如与输出脉冲的上升沿同步地进行。
比例要素6f、积分要素6g及微分要素6h的输出是在加法器6i中相加而得。而且相加结果,即pf电机1、cr电机4的驱动电流被发送到d/a转换器6j从而被转换为模拟电流。基于该模拟电压,由pf电机驱动器2、cr电机驱动器5驱动pf电机1、cr电机4。
另外,计时器6k及加速控制部6m用于加速控制,使用比例要素6f、积分要素6g及微分要素6h的pid控制用于加速途中的定速及減速控制。
计时器6k基于从控制部21发送的时钟信号而每隔预定时间产生计时器中断信号。在每次接收计时器中断信号时,加速控制部6m在目标电流值上累加预定的电流值(例如20ma),并将累加结果,即加速时的pf电机1、cr电机4的目标电流值发送到d/a转换器6j。与pid控制的情况相同,通过d/a转换器6j将上述目标电流值转换到模拟电流,基于该模拟电流,由pf电机驱动器2、cr电机驱动器5驱动pf电机1、cr电机4。
(2)控制参数的确定:
在以上结构中,通过变化增益kp及常数gp、gi、gd,能够变化pf电机1及cr电机4的动作。因而,这些值是电机的控制参数。在本实施方式中,能够选择印刷装置100中多个印刷速度(例如,与优先画质并在低速下印刷的模型相对的画质低下但高速地印刷的模型),在针对每种印刷速度预先确定控制参数的状态下印刷装置100被推向市场。
但是,在控制参数是固定值的情况下,存在无法成为与印刷装置100的环境变化、pf电机1、cr电机4、同步带14等与时间变化对应的适当的值的情况。在这种情况下,存在印刷介质50及滑架3的输送位置从基准偏离(从控制目标偏离)的情况。因此,在本实施方式中,采用可以变化控制参数的结构以使印刷介质50及滑架3的输送位置靠近基准。
(2-1)已学习模型的学习:
在本实施方式中,处理器20通过参照由机器学习获取的已学习模型来确定控制参数。在本实施方式中,已学习模型是通过强化学习获取的。即,印刷装置100作为学习装置发挥作用,参照由学习获得的已学习模型而进行印刷。以下,对该强化学习进行说明。
需要说明的是,根据本实施方式,通过强化学习的结果、控制参数的变更,能够估计为被输送物的输送位置的精度无法再提高到当前的设定值以上,即,能够实现将输送位置的精度估计为极大的状态。在本实施方式中,将这些状态称为最优化状态,将实现最优化状态的控制参数称为最优化控制参数。
在本实施方式中,通过执行学习程序,印刷装置100作为学习部22发挥作用。学习部22能够观测表示印刷装置100的状态的状态变量。在本实施方式中,状态变量是被输送物的速度、被输送物的加速度、被输送物的移动量、被输送物的移动开始位置、印刷装置的周围环境、流过电机的电流值、在印刷装置中印刷的印刷介质的种类及被输送物的累积移动量。
具体而言,学习部22从电机控制部6的速度运算部6d获取pf电机1的实际速度、滑架3的实际速度,并将其视为被输送物的速度。另外,学习部22获取pf电机1的实际速度及滑架3的实际速度的在既定期间的变化,并将其视为被输送物的加速度。此外,学习部22在预先确定的期间(例如,从向印刷介质50的印刷的开始到现在为止的期间)内,积分pf电机1的实际速度及滑架3的实际速度,并将其视为被输送物的移动量。将该移动量存储于存储部30。
此外,学习部22从电机控制部6的位置运算部6a获取开始在印刷介质50上的印刷时的pf电机1的实际位置及滑架3的实际位置,并将其视为被输送物的移动开始位置。此外,学习部22是基于温度湿度传感器40的输出信号获取印刷装置100的周围的温度及湿度,并将其视为印刷装置的周围环境。此外,学习部22基于与pf电机1及cr电机4连接的电流传感器,获取流过各电机的电流值。
此外,学习部22控制相机8并拍摄印刷介质50的空白,基于预先确定的图像处理(例如,模板匹配或傅里叶变换等),从预先确定的种类选择由pf辊51输送的印刷介质50的种类,并将其视为由印刷装置印刷的印刷介质50的种类。此外,学习部22获取存储于存储部30的上述的移动量的累积值,并将其视为被输送物的累积移动量。在本实施方式中,学习部22能够观测在任意的定时的状态变量,并观测初始的状态变量、及变化控制参数后的状态变量。
由于在本实施方式中采用强化学习,学习部22确定基于状态变量变化控制参数的行动,并执行该行动。如果根据该行动后的状态评估报酬,就判明该行动的行动价值。因此,学习部22通过反复进行状态变量的观测、与根据该状态变量的行动的确定及通过该行动得到的报酬的评估,最优化控制参数。
图3是说明根据由智能体和环境构成的强化学习的模型控制参数的学习例的图。图3所示的智能体相当于根据预先确定的策略选择行动a的功能。环境相当于基于已选择智能体的行动a和现在的状态s确定下一个的状态s',基于行动a、状态s及状态s'确定即时报酬r的功能。
在本实施方式中,通过预先确定的策略学习部22选择行动a,并通过反复进行状态的更新的处理,采用算出某一状态s中的某一行动a的行为价值函数q(s,a)的q学习。即,在本例中,通过下述的式(1)更新行为价值函数。而且,在行为价值函数q(s,a)适当地收敛的情况下,将最大化该行为价值函数q(s,a)的行动a视为最适当的行动,将表示该行动a的控制参数视为最优化参数。
【数1】
q(st,at)←q(st,at)+α(rt+1+γmaxa’q(st+1,a’)-q(st,at))…(1)
这里,行为价值函数q(s,a)是在状态s中采取行动a的情况下在将来获得的收益(在本例中是折扣报酬总和)的期待值。报酬是r,状态s、行动a、报酬r的下标t是表示在时间序列下反复进行的试验过程中一次的步骤的编号(称为试验编号),行动确定后若状态变化则递增试验编号。因而,式(1)内的报酬rt+1是在状态st下选择行动at,在状态成为st+1的情况下获得的报酬。α是学习率,γ是折扣率。另外,a'是最大化在状态st+1下获取的行动at+1的中的行为价值函数q(st+1,at+1)的行动,maxa'q(st+1,a')是通过选择行动a'而被最大化的行为价值函数。需要说明的是,可以用各种方法确定试验的间隔,例如,能够采用每一定时间间隔进行试验的结构等。
在控制参数的学习中,变化控制参数相当于行动的确定,将表示学习对象的控制参数和获取的行动的信息预先记录于存储部30。在图3中,示出以与控制参数中的pid控制相关的控制参数为学习对象的例子。
具体而言,在控制参数中,将在pf电机1的控制中使用的常数gp、gi、gd和在cr电机4的控制中使用的常数gp、gi、gd作为学习对象。因而,在该例中,不将pf电机1及cr电机4的增益kp等作为学习对象,当然,也可以将图3所示的控制参数以外的控制参数作为学习对象。
在图3所示的例子中存在在行动中使值増加一定值的行动和使值減少一定值的行动。因而,图3示出的全部6个参数中获取的行动是全部12个(行动a1~行动a12)。在本实施方式中,将用于确定各行动的信息(行动的id,在各行动中的増減量等)记录于存储部30。
在图3所示的例子中基于被输送物的输送位置的与基准之间的偏差确定报酬。在本实施方式中,基于由相机8拍摄的表示被输送物的输送位置的图像确定与基准之间的偏差。在本实施方式中,表示被输送物的输送位置的图像是拍摄由印刷装置100印刷于印刷介质50的调整图案的图像。
即,学习部22在作为行动a变化了控制参数后,控制电机控制部6或头驱动器7等在印刷介质50上印刷既定的调整图案。需要说明的是,调整图案如果是用于明确印刷介质50的输送位置或滑架3的输送位置的图案,可以使用各种图案。
在本实施方式中调整图案是由直线构成的图案,在印刷在介质50上的对象(直线)大于既定大小的情况下视为产生了与基准之间的偏差。另外,在印刷在介质50上的对象在既定大小以下的情况下视为未产生与基准之间的偏差。
图4是表示调整图案的例子的图,在该例子中,通过具有共通的中心的大小不同的2个长方形和较大的长方形的对角线构成调整图案。这样,在印刷由线构成的图形时,在被输送物的输送位置未偏离基准且被高精度地控制后,将线表现为既定的宽度以内的线。但是,若被输送物的输送位置偏离基准,则使线比既定的宽度粗,若偏差较大则线分离。
因此,在本实施方式中学习部22控制相机8,通过相机8拍摄该调整图案。图5及图6是用于说明拍摄结果的图。在图5及图6中,横轴表示像素单位的位置,纵轴表示亮度的级别。在本例中,由于假设了在白色的印刷介质50上印刷由黑色的线构成的调整图案的例子,因此如图5及图6所示,拍摄到的线的部分亮度低下。在本实施方式中,将亮度比阈值th小部分视为调整图案的像。
在这些例子中,将线的理想的宽度通过范围z表示。在图5中,由相机8测定的调整图案的线比范围z粗,可知被输送物的输送位置偏离基准。在图6中,由相机8测定的调整图案的线与范围z同等,亮度比阈值th小的部分存在于范围z的附近(既定距离以内)。因而,在图6所示的例中,可知被输送物的输送位置较大地偏离基准。
在本实施方式中,通过亮度比阈值th小的范围,评估这些与基准之间的偏差。具体而言,学习部22获取从亮度小于阈值th的范围减去了表示线的宽度的范围z的剩余的δz来作为与基准之间的偏差。当然,可以在调整图案上的多个位置评估或统计与基准之间的偏差。另外,也可以基于在印刷介质50的多个位置印刷的调整图案获取与基准之间的偏差。
无论在任何情况下,学习部22都将报酬设定为与基准之间的偏差δz越小则报酬越大(例如,1/δz等)。当然,也可以用各种方法定义报酬,例如,可以是采取在偏差δz比阈值小的情况下+1,比阈值大的情况下-1这样的报酬,也能够采用其他各种定义。
现在的状态s下采用了行动a的情况下的下一个的状态s'是进行作为行动a的参数的变化后操作印刷装置100,能够通过观测状态变量确定学习部22。即,学习部22通过观测印刷介质50的速度或印刷装置100的周围的温度等而获取显示这些的值,来作为状态变量。
(2-2)控制参数的学习例:
接着,说明控制参数的学习例。将表示在学习的过程中参照的变量或函数的信息存储于存储部30。即,学习部22采用通过反复进行状态变量的观测、与该状态变量对应的行动的确定、及通过该行动得到的报酬的评估而使行为价值函数q(s,a)收敛的结构。因此,在本例中,依次将学习的过程中状态变量、行动及报酬的时间序列的值记录于存储部30。
行为价值函数q(s,a)可以用各种方法算出,也可以基于多次的试验算出,在本实施方式中采用作为近似地算出行为价值函数q(s,a)的一个方法的dqn(deepq-network)。在dqn中,使用多层神经元网络估计行为价值函数q(s,a)。在本例中,采用输入状态s并输出可以选择的行动的数量n个的行为价值函数q(s,a)的值的多层神经元网络。
图7是示意性地表示在本例中采用的多层神经元网络的图。在图7中,多层神经元网络将m个(m是2以上的整数)状态变量作为输入,将n个(n是2以上的整数)行为价值函数q的值作为输出。例如,在如图3所示的例子中,由于印刷介质的速度或温度等状态变量存在合计13个,所以m=13,将m个状态变量的值输入到多层神经元网络。在图7中,将试验编号t中的m个状态表示为s1t~smt。
n个是可以选择的行动a的数量,多层神经元网络的输出是在已输入的状态s中选择确定的行动a的情况下的行为价值函数q的值。在图7中,可将在试验编号t中可以选择的行动a1t~ant的各个中的行为价值函数q表示为q(st,a1t)~q(st,ant)。包含在该q中的st是代表输入的状态s1t~smt而显示的文字。在如图3所示的例子中,由于能够选择12个行动,所以n=12。当然,行动a的内容或数量(n的值),状态s的内容或数(m的值)也可以根据试验编号t而变化。
图7所示的多层神经元网络执行与各层的各节点中直前的层的输入(1层目中是状态s)相对的权重w的乘法运算和偏置b的加法运算,是根据必要而执行获得通过活性化函数的输出的(成为次的层的输入)计算的模型。在本例中,存在p个(p是1以上的整数)层dl,在各层中存在多个节点。
图7所示的多层神经元网络通过在各层中的权重w和偏置b,确定活性化函数及层的顺序等。因此,在本实施方式中,用于确定该多层神经元网络的参数(用于从输入获得输出的必要的信息)记录于存储部30。需要说明的是,在学习时,在用于确定多层神经元网络的参数的中更新可变的值(例如,权重w和偏置b)。这里,将在学习的过程中变化得到的多层神经元网络的参数表示为θ。使用该θ,上述的行为价值函数q(st,a1t)~q(st,ant)能够表示为q(st,a1t;θt)~q(st,ant;θt)。
接着,按照图8所示流程图说明学习处理的顺序。控制参数的学习处理是在印刷装置100中执行每个印刷速度(印刷模型)。若学习处理开始,则学习部22初始化学习信息(步骤s100)。即,学习部22确定在开始学习时参照的θ的初始值。初始值可以用各种方法确定,例如,在过去不进行学习的情况下,可以将任意的值或随机值等作为θ的初始值。
在过去进行学习的情况下,将该已学习的θ采用为初始值。另外,在在过去类似的条件(印刷介质的种类等)中进行学习的情况下,也可以将该学习中的θ作为初始值。过去的学习可以是用户使用印刷装置100而进行的,也可以是印刷装置100的制造者在印刷装置100的销售前进行的。在这种情况下,也可以是制造者根据对象物或工作的种类准备多个初始值的设定,而用户在学习时选择初始值的结构。若确定θ的初始值,则该初始值作为现在的θ的值和作为学习信息而存储于存储部30。
接着,学习部22初始化控制参数(步骤s105)。这里,由于pid控制涉及的控制参数是学习对象,所以学习部22初始化pid控制涉及的控制参数。即,学习部22将最后驱动印刷装置100时使用的pid控制涉及的控制参数(在出厂后的首次驱动时是出厂时设定的控制参数)设定为初始值。将初始化的控制参数作为现在的控制参数存储于存储部30。
接着,学习部22观测状态变量(步骤s110)。即,学习部22向电机控制部6指示现在的控制参数,并通过该现在的控制参数驱动pf电机1及cr电机4来控制印刷装置100。学习部22在控制后的状态下获取如图3所示的印刷介质50的速度或温度等。
接着,学习部22算出行动价值(步骤s115)。即,学习部22参照存储于存储部30的学习信息获取θ,向显示存储于存储部30的学习信息的多层神经元网络输入最新的状态变量,并算出n个行为价值函数q(st,a1t;θt)~q(st,ant;θt)。
需要说明的是,最新的状态变量是初次执行时的步骤s110,第二次以后的执行时的步骤s125的观测结果。另外,试验编号t是在初次执行时取0,第二次以后的执行时取1以上的值。在过去未实施学习处理的情况下,由于未最优化存储于存储部30的学习信息显示的θ,所以作为行为价值函数q的值可以是不正确的值,通过反复进行步骤s115以后的处理,逐渐最优化行为价值函数q。另外,在步骤s115以后的处理的反复进行中,状态s、行动a及报酬r与各试验编号t对应地存储于存储部30,能够在任意的定时下参照。
接着,学习部22选择并执行行动(步骤s120)。在本实施方式中,进行将最大化行为价值函数q(s,a)的行动a视为最佳行动的处理。因此,学习部22确定在步骤s115中算出的n个行为价值函数q(st,a1t;θt)~q(st,ant;θt)的值中的最大的值。而且,学习部22选择赋予最大的值的行动。例如,如果在n个行为价值函数q(st,a1t;θt)~q(st,ant;θt)的中的q(st,ant;θt)是最大值,学习部22选择行动ant。
若选择行动,则学习部22变化与该行动对应的控制参数。例如,在如图3所示的例子中,在选择将pf电机1的比例要素中的常数gp増加一定值的行动a1的情况下,学习部22将常数gp増加一定值。在进行控制参数的变化后,学习部22参照该控制参数控制印刷装置100并印刷调整图案。
接着,学习部22观测状态变量(步骤s125)。即,学习部22进行与在步骤s110中的状态变量的观测相同的处理,获取图3所示的印刷介质50的速度或温度等,作为状态变量。需要说明的是,在现在的试验编号是t的情况下(在选择的行动是at的情况下),在步骤s125获取的状态s是st+1。
接着,学习部22评估报酬(步骤s130)。即,学习部22控制相机8(可以根据需要输送滑架3或印刷介质50)来拍摄调整图案。然后,学习部22基于调整图案的像获取与基准之间的偏差δz,并根据δz获取报酬。需要说明的是,在现在的试验编号是t的情况下,在步骤s130中获取的报酬r是rt+1。
在本实施方式中以式(1)所示的行为价值函数q的更新为目标,为了适当地更新行为价值函数q,必须最优化表示行为价值函数q的多层神经元网络(最优化θ)。为了根据图7所示的多层神经元网络适当地输出行为价值函数q,作为该输出的目标的教师数据是必要的。即,期望通过改善θ以最小化多层神经元网络的输出和目标的误差,来最优化多层神经元网络。
但是,在本实施方式中,在未完成学习的阶段中没有行为价值函数q的时,难以确定目标。因此,在本实施方式中,式(1)的第二项,通过最小化所谓的td误差(temporaldifference,时序差分)的目标函数实施表示多层神经元网络的θ的改善。即,以(rt+1+γmaxa'q(st+1,a';θt))为目标,学习θ以最小化目标和q(st,at;θt)的误差。但是,由于目标(rt+1+γmaxa'q(st+1,a';θt))包含学习对象,在本实施方式中,在一定程度的试验次数中固定目标(例如,固定为最后学习的θ(初次学习时是θ的初始值))。在本实施方式中,预先确定作为固定目标的试验次数的既定次数
为了在这样的前提下进行学习,若在步骤s130中评估报酬,则学习部22算出目标函数(步骤s135)。即,学习部22算出用于评估试验的各个中的td误差的目标函数(例如,与td误差的平方的期待值成比例的函数或td误差的平方的总和等)。需要说明的是,由于在固定目标的状态下算出td误差,将固定的目标表示为(rt+1+γmaxa'q(st+1,a';θ-)),td误差是(rt+1+γmaxa'q(st+1,a';θ-)-q(st,at;θt))。在该td误差的式中报酬rt+1是根据行动at在步骤s130中得到的报酬。
另外,maxa'q(st+1,a';θ-)是输出中的最大值,该输出是将通过行动at在步骤s125算出的状态st+1作为通过固定的θ-而确定的多层神经元网络的输入的情况下而获得的。q(st,at;θt)是输出中与行动at对应的输出的值,该输出中与行动at对应的输出的值是将选择行动at前的状态st作为通过试验编号t的阶段的θt而确定的多层神经元网络的输入的情况下获得的。
若算出目标函数,则学习部22判定学习是否结束(步骤s140)。在本实施方式中,预先确定了用于判定td误差是否足够小的阈值,在目标函数是阈值以下的情况下,学习部22判定学习是否结束。
在步骤s140中未判定为学习已结束的情况下,学习部22更新行动价值(步骤s145)。即,学习部22基于根据td误差的θ而产生的偏微分来确定用于减小目标函数的θ的变化,并使θ变化。当然,这里,能够用各种方法变化θ,例如,能够采用rmsprop等梯度下降法。另外,也可以适当地实施根据学习率等调整。根据以上的处理,能够变化θ以使行为价值函数q接近目标。
但是,在本实施方式中,由于如上所述地固定目标,学习部22还进行是否更新目标的判定。具体而言,学习部22判定是否进行了既定次数的试验(步骤s150),在步骤s150中,在判定为进行了既定次数的试验的情况下,学习部22更新目标(步骤s155)。即,学习部22将算出目标时参照的θ更新为最新的θ。此后,学习部22反复进行步骤s115以后的处理。另一方面,在步骤s150中,如果未判定为进行了既定次数的试验,学习部22跳过步骤s155而反复进行步骤s115以后的处理。
在步骤s140中判定为学习结束的情况下,学习部22更新存储于存储部30的学习信息(步骤s160)。即,学习部22将通过学习获得的θ作为通过印刷装置100印刷时应该参照的已学习模型31而存储于存储部30。包括该θ的已学习模型31存储于存储部30,控制部21能够在印刷前获取对现在的印刷装置100的最优化的控制参数。
(3)印刷处理:
在已学习模型31已存储于存储部30的状态下,控制部21能够使用最优化的控制参数来控制印刷装置100。图9是表示在印刷装置100中进行印刷时的印刷处理的流程图。印刷处理是使用者将存储于未图示的计算机或外部存储介质等图像数据指定为印刷对象,在已指定印刷速度(印刷模型)的状态下执行。
若开始印刷处理,则控制部21获取图像数据(步骤s200)。即,控制部21从使用者已指定的未图示的计算机或外部存储介质等获取图像数据。接着,控制部21实施图像处理(步骤s205)。即,控制部21执行用于将表示图像数据的图像变换为由每个像素的墨滴的记录的有无表现的印刷数据的图像处理。该图像处理也可以采用公知的方法,例如,通过色转换处理或γ转换处理等来实现。
接着,控制部21获取状态变量(步骤s210)。即,控制部21从电机控制部6的速度运算部6d获取pf电机1的实际速度及滑架3的实际速度,并将其视为被输送物的速度。另外,学习部22获取pf电机1的实际速度及滑架3的实际速度在既定期间的变化,并将其视为被输送物的加速度。此外,学习部22在预先确定的期间(例如,从向印刷介质50的印刷的开始至现在为止的期间)内,积分pf电机1的实际速度及滑架3的实际速度,并将其视为被输送物的移动量。该移动量被存储于存储部30。
此外,学习部22从电机控制部6的位置运算部6a获取在印刷介质50上开始印刷时的pf电机1的实际位置及滑架3的实际位置,并将其视为被输送物的移动开始位置。此外,学习部22基于温度湿度传感器40的输出信号获取印刷装置100的周围的温度及湿度,并将其视为印刷装置的周围环境。此外,学习部22基于连接pf电机1及cr电机4的电流传感器,获取流过各电机的电流值。
此外,学习部22控制相机8并拍摄印刷介质50的空白,基于预先确定的图像处理(例如,模板匹配或傅里叶变换等),从预先确定的种类选择由pf辊51输送的印刷介质50的种类,视为在印刷装置中印刷的印刷介质50的种类。此外,学习部22获取存储于存储部30的上述的移动量的累积值,并将其视为被输送物的累积移动量。
接着,控制部21确定控制参数(步骤s215)。即,控制部21参照已学习模型31,将在步骤s210中获取的状态变量作为输入而计算输出q(s,a)。另外,控制部21选择在输出q(s,a)中提供最大值的行动a。而且,在选择了行动a的情况下,控制部21确定控制参数,以成为与进行了行动a的状态相当的值。
接着,控制部21执行印刷控制(步骤s220)。即,控制部21基于在步骤s205中获得的数据获取用于印刷图像的必要的pf电机1、cr电机4的时间序列的目标位置及头的驱动定时。而且,为了将pf电机1、cr电机4配置到目标位置,控制部21向电机控制部6指示控制目标、驱动pf辊51并驱动滑架3。需要说明的是,在本实施方式中,为了在每次进行既定范围的印刷时最优化控制参数,在步骤s220中,进行用于印刷既定范围的印刷控制。
接着,控制部21判定印刷是否结束(步骤s225)。即,控制部21在基于在步骤s205中获得的数据的全部进行印刷的情况下,判定为印刷已结束。在步骤s225中,在判定为印刷未结束的情况下,控制部21反复进行步骤s210以后的处理。即,在本实施方式中,在通过既定范围的印刷变化状态变量的情况下,通过追踪该变化最优化控制参数。
另一方面,在步骤s225中,在判定为印刷已结束的情况下,控制部21结束印刷处理。根据以上的结构,能够选择最大化行为价值函数q的行动a同时执行印刷。该行为价值函数q是通过上述的处理,反复进行多次的试验,最终被最优化。而且,该试验通过学习部22自动进行,能够容易地执行许多难以人为实施的程度的试验。因而,根据本实施方式,能够以比人为确定的控制参数高的概率最优化控制参数。
而且,通过根据最优化的控制参数进行印刷,能够以使得被输送物的输送位置靠近基准(提高定位精度)的方式来进行控制。另外,能够长时间地维持被输送物的输送位置靠近基准(定位精度高)的状态。需要说明的是,在本实施方式中,每次进行既定范围的印刷则变更控制参数,当然,控制参数的变更频率是任意的,例如,可以是在1张印刷介质50的印刷过程中固定控制参数的结构等。
(4)其他实施方式:
以上的实施方式是用于实施本发明的一例,能够采用其他各种实施方式。例如,印刷装置及学习装置也可以是具备传真通信功能等复合机。另外,印刷装置及学习装置也可以由多个装置构成。例如,可以由与存储已学习模型31的装置和通过控制部21进行印刷的装置不同的装置构成。
当然,也可以由与印刷装置和学习装置不同的装置构成。在由与印刷装置和学习装置不同的装置构成的情况下,学习装置从多个印刷装置收集状态变量,通过在各印刷装置中进行行动,可以机器学习能够适用于多个印刷装置的已学习模型31。此外,可以省略上述的实施方式的一部分的结构,也可以变动或省略处理的顺序。
印刷装置具备输送被输送物的电机。即,印刷装置具备通过电机的驱动力输送伴随印刷而变动位置的被输送物的结构。被输送物可以是通过电机的驱动量输送的物体,并不限定于上述的实施方式那样的印刷介质、滑架。例如,在adf(automaticdocumentfeeder,自动进纸器)或盒等部件通过电机的驱动力移动的情况下,这些部件也可以成为被输送物。
状态变量可以包括被输送物的速度、被输送物的加速度、被输送物的移动量、被输送物的移动开始位置、印刷装置的周围环境、流过电机的电流值、由印刷装置印刷的印刷介质的种类、及被输送物的累积移动量的至少一个,也可以是任意多个的组合。当然,也可以在状态变量中包括其他的要素。另外,可以成为状态变量的要素中也包括可以成为控制参数的要素。例如,被输送物的速度或被输送物的加速度等也可以成为控制参数(控制目标)。
被输送物的速度或加速度及移动量只要是基于被输送物的每个时间的位置确定的量即可,不限定于基于编码器的输出确定的结构。例如,也可以基于确定被输送物的位置的光学传感器的输出确定速度或加速度及移动量。移动量也可以在既定的期间内测量,在该意味上与累积移动量不同。既定的期间是例如,举例某一印刷介质的从印刷开始到印刷结束的期间等。
被输送物的移动开始位置只要是在既定的触发中的被输送物的位置即可,例如,可以是印刷开始时触发,也可以是在双向印刷中滑架开始往动之前或开始复动之前等。印刷装置的周围环境只要是可以对被输送物或电机、印刷装置的部品等动作施加影响的环境即可,不限定于温度或湿度。例如,可以将振动的有无或印刷装置的设置场所的硬度等作为周围环境,可以将各种要素作为周围环境。需要说明的是,测定温度或湿度等周围环境的场所可以是各种场所。
印刷介质的种类是构成印刷介质的材质等,除通过相机确定的结构以外,可以采用各种的结构。例如,可以由使用者指定,也可以设计用于检测印刷介质的种类的传感器。
控制参数只要是通过变化参数来变动电机的控制内容的参数即可。已学习模型只需要能够输出参数即可,该参数是在该控制参数中,在以状态变量所示的状态中,使被输送物的输送位置靠近基准的参数。当然,与已学习模型输出的控制参数相比,存在控制参数使被输送物的输送位置靠近基准的效果更好。但是,通过进行在通过已学习模型输出的控制参数下的控制,或者通过反复进行控制参数的更新,只要是进行使被输送物的输送位置比现在更接近基准的学习即可。
状态变量只要是表示根据变化控制参数的结果获得的状态即可,可以是数值,也可以是标记,还可以是表示各种状态的符号。已学习模型只要是通过输入状态变量而输出控制参数那样的数式模型即可,除了通过强化学习学习的已学习模型以外,能够采用各种模型。
即,机器学习只要是使用样本数据来学习更好的参数的处理即可,除上述的强化学习以外,能够采用通过监督学习或聚类等各种方法来学习各参数的结构。已学习模型不限定于上述的实施方式,例如,也可以是将nn(neuralnetwork,神经网络),cnn(convolutionalneuralnetwork,卷积神经网络),rnn(recurrentneuralnetwork,递归神经网络)等各种神经元网络作为已学习模型学习的结构,也可以是将组合这些模型的模型作为已学习模型学习的结构。
控制部只要通过基于已学习模型获取的控制参数控制电机并进行印刷即可。即,控制部只要变化控制参数并通过变化后的控制参数操作电机并在印刷装置执行印刷即可。当然,作为用于印刷的控制,可以进行各种控制,例如,可以进行各种图像处理,双向印刷的有无或墨点的控制,根据印刷速度的调色剂量的调整等,根据印刷装置的结构等各种控制。
强化学习中的行动只要是变化控制参数的行动即可。即,将变化控制参数的处理视为行动,以可以变化电机的控制内容。在上述的实施方式以外,获取的行动的选项可以是各种方式。例如,将变化上述的实施方式pid控制中的比例增益、积分增益、微分增益的中的一个既定量的处理作为行动,也可以将变化这些增益的两种以上的行动作为选项。另外,其他的控制,例如,可以将变化加速度控制的控制目标的处理作为行动的选项,也可以将变化目标位置或目标速度的处理作为行动的选项。
此外,在上述的学习处理中,每次试验时都根据θ的更新来更新行动价值,直到进行既定次数的试验为止而固定目标,也可以在进行多次的试验之后进行θ的更新。例如,举例直到进行第一既定次数的试验为止而固定目标,且直到进行第二既定次数(<第一既定次数)的试验为止而固定θ的结构。在这种情况下,是在第二既定次数的试验后基于第二既定次数的样本更新θ,此外在试验次数超过第一既定次数的情况下按最新的θ更新目标的结构。
此外,在学习处理中,可以采用公知的各种方法,例如,也可以进行体验再现或报酬的裁剪(clipping)等。此外,在图7中,存在p个层dl(p是1以上的整数),在各层中存在多个节点,各层的结构能够采用各种的结构。例如,层的数量或节点的数量能够采用各种数,作为活性化函数能够采用各种函数,网络结构可以是卷积神经元网络结构等。另外,输入或输出的方式不限定于图7所示的例,例如,可以采用至少使用输入状态s和行动a的结构或将最大化行为价值函数q的行动a作为独热(one-hot)向量输出的结构的例子。
在上述的实施方式中,基于行为价值函数按贪心(greedy)策略进行行动并试验,且通过最优化行为价值函数,将与最优化的行为价值函数相对的贪心策略视为最优策略。该处理即所谓的价值反复法,也可以通过其他的方法,例如,策略反复法进行学习。此外,在状态s、行动a、报酬r等各种变量中,可以进行各种正规化。
作为机器学习的方法,采用各种方法,可以通过基于行为价值函数q的ε-greedy策略进行试验。另外,作为强化学习的方法并不限定于上述那样的q学习,也可以使用sarsa等方法。另外,可以使用分别将策略的模型和行为价值函数的模型进行模型化的方法,例如,actor-critic算法。如果使用行动-评价(actor-critic)算法,也可以定义作为表示策略的行动(actor)的μ(s;θ)和作为表示行为价值函数的评价(critic)的q(s,a;θ),并根据向μ(s;θ)添加噪音的策略来生成行动并试验,通过基于试验结果来更新行动和评价从而学习策略和行为价值函数的结构。
- 还没有人留言评论。精彩留言会获得点赞!