一种基于弥散张量成像的抑郁症患者疾病恢复的评估方法与流程
本发明涉及疾病恢复的评估方法,具体涉及一种基于弥散张量成像的抑郁症患者疾病恢复的评估方法。
背景技术:
目前,抑郁症患者经过一段时间的治疗后,功能恢复状况的临床诊断主要是临床医生通过症状的缓解,并结合汉密尔顿抑郁量表(hamd)、大体评定量表(gas)等量表,通过医师评估及患者自评得到的。这种方式具有很强的主观性,对临床医生的问询经验有极高的要求。另外,症状的外显往往会迟于脑环路的改变。这些因素都导致难以客观及时地反映患者的真实恢复程度。抑郁症患者经过急性期治疗,脑结构和功能活动水平可以得到一定程度的恢复,但是疾病导致的脑网络损伤靶点和疾病缓解过程的恢复环路可能存在不一致。
技术实现要素:
发明目的:为了解决现有技术中抑郁症患者疾病恢复主观性评估的问题,本发明提出了一种基于弥散张量成像的抑郁症患者疾病恢复的评估方法。
技术方案:本发明所述一种基于弥散张量成像的抑郁症患者疾病恢复的评估方法,包括以下步骤:
(1)构建建模样本的大脑结构网络sn(structuralnetwork);
(2)计算大脑组平均网络中的规格化richclub系数,确定richclub结构;
(3)构建feeder-local子网络;
(4)计算建模样本中每两个样本的feeder-local子网络的相似性度量,构建特征矩阵;
(5)利用支持向量回归,将步骤(4)构建的特征矩阵作为特征集合,采取多项式核函数,构建评估模型。
步骤(1)所述大脑结构网络sn(structuralnetwork)按如下方法构建:对建模样本中每个样本的弥散张量成像的数据,使用自动解剖标记模板(all结构模板),将人脑划分为90个脑区,每个脑区即为所述大脑结构网络的节点,对每两个脑区之间进行纤维素示踪,将纤维素中的水分子扩散各向异性分数(fa)作为每两个脑区之间边的权值。
步骤(2)所述大脑组平均网络按如下方法计算:设定阈值t,n表示建模样本中的样本数目,当所有建模样本的大脑组织网络相同连接位置存在的连接大于tn时,则认定此处的功能连接存在,计算所有建模样本大脑结构网络中非零连接的算数平均数作为大脑组平均网络该条连接的权值,以此类推,得到大脑组平均网络。
所述阈值t为0.3~0.9;在本模型的一个最佳实例中,阈值t为0.7。
步骤(2)所述richclub结构定义如下:
(1)大脑结构网络的richclub系数φw(k)计算方法为:
大脑结构网络是一种以纤维素中的水分子扩散各向异性分数为权值的加权网络;k是指节点的度,度代表了和该节点相关联的边的条数。e>k是度值高于k的连接的数量,w>k是度值高于k的连接的权重之和,
(2)规格化的richclub系数计算方法为:
(3)richclub结构的确定:以某个节点为例,k值满足φnorm(k)>1时即该节点具有richclub特性,具有richclub特性的节点的集合即为richclub结构。
步骤(3)所述构建feeder-local子网络按如下方法构建:将大脑结构网络的节点分为rich节点、non-rich节点,边分为rich边、feeder边、local边,利用feeder边、local边和所有节点构建feeder-local子网络;其中,所述richclub结构内含有的节点即为richclub节点,richclub结构外的节点即为non-richclub节点;用于连接richclub节点的边为richclub边,用于连接richclub节点和non-richclub节点的边为feeder边,用于连接non-richclub节点的边为local边。
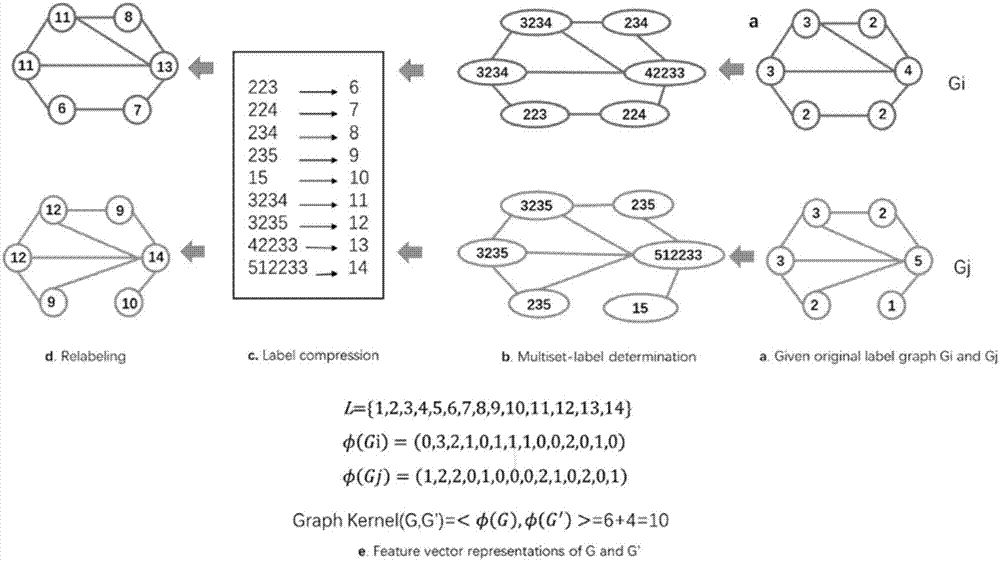
步骤(4)所述特征矩阵通过图核((graphkernel))的方法按如下步骤构建:
(1)针对feeder-local子网络的每个节点,基于其度的大小,给定每个节点初始标签,再根据节点所连接的其他节点情况,给定每个节点增强标签;将初始标签与增强标签混合重新进行标记,得到最终标签集合l={l1,l2,……,ln};l为最终标签的集合,l1,l2,……,ln代表不同的标签,n代表总标签的数量;
(2)针对每个样本的feeder-local子网络g,定义一个特征向量φ(g)用于表示这个子网络内不同标签的特征信息:
φ(g)=(s(g,l1),s(g,l2),…,s(g,ln))
其中,s(g,li)代表第i个标签在feeder-local子网络g中出现的次数,φ(g)代表子网络g中所有标签出现次数的集合;
(3)针对建模样本中每两个样本i和j对应的feeder-local子网络gi、gj,两个子网络的相似性度量定义为两个子网络特征向量φ(g)的内积,
k(gi,gj)=<φ(gi),φ(gj)>
其中,k(gi,gj)越大,说明两个子网络的拓扑结构越相似;
(4)特征矩阵定义为:矩阵的每一个元素代表样本i和样本j的相似性度量k(gi,gj),其表达形式如下:
所述评估模型为:
xi是样本i在特征矩阵中的特征向量,f(xi)代表了给予样本i的特征向量的模型输出值,2i代表样本i的标签,m代表样本总量;ω=(ω1;ω2;……;ωd)为法向量,决定了超平面的方向,d为法向量的个数;b为位移项,决定了超平面与原点之间的距离;c为正则化常数,l.为∈-不敏感损失函数,∈为损失函数的一个参数,表示当预测值f(xi)与yi之间的差别的绝对值大于∈时才计算损失,公式如下:
有益效果:与现有技术相比,本发明的技术优势如下:
(1)本发明以客观的影像学数据来对疾病的恢复过程进行评价,纯数据驱动,完全基于richclub结构分层后的feeder-local子网络的拓扑结构相似性模型研究来判断患者的疾病的恢复程度,不需借助医生或患者的参与,避免了主观因素带来的误差;
(2)根据目前的功能代偿假说,在脑网络分层技术基础上,从脑结构分层网络中提取基于大脑网络拓扑结构的量化指标,为急性期治疗后大脑功能活动水平的恢复程度提供更为有效和及时的评估,为临床优化治疗提供辅助信息,从而保证足程足量的有效治疗,避免过度治疗。
附图说明
图1为本发明采用建模样本构建评估模型的流程示意图;
图2为计算建模样本中每两个样本的feeder-local子网络相似性度量的流程示意图;
图3为新样本进入评估模型获得客观评估的流程示意图。
具体实施方式
本实例选择55例未经治疗的抑郁症患者、55例治疗后的抑郁症患者和55例性别、年龄、受教育程度相匹配的健康对照者,采集三组受试者的弥散张量成像信号,构建了一种基于弥散张量成像的抑郁症患者疾病恢复的评估模型,见图1,包括以下步骤:
(1)利用弥散张量成像技术,构建建模样本的大脑结构网络sn(structuralnetwork):对建模样本中每个样本的弥散张量成像的数据,使用自动解剖标记模板(all结构模板),将人脑划分为90个脑区,每个脑区即为所述大脑结构网络的节点,对每两个脑区之间进行纤维素示踪,将纤维素中的水分子扩散各向异性分数(fa)作为每两个脑区之间边的权值。
(2)计算大脑组平均网络中的规格化richclub系数,确定richclub结构;
其中,大脑组平均网络按如下方法计算:设定阈值t为0.7,n表示建模样本中的样本数目,当所有建模样本的大脑组织网络相同连接位置存在的连接大于tn时,则认定此处的功能连接存在,计算所有建模样本大脑结构网络中非零连接的算数平均数作为大脑组平均网络该条连接的权值,以此类推,得到大脑组平均网络;
其中,所述richclub结构定义如下:
a、加权网络的richclub系数φw(k)计算方法为:
加权网络表示网络的边具有权值的一种网络,大脑结构网络是一种以纤维素中的水分子扩散各向异性分数为权值的加权网络。k是指节点的度,度代表了和该节点相关联的边的条数。e>k是度值高于k的连接的数量,w>k是度值高于k的连接的权重之和,
b、规格化的richclub系数计算方法为:
c、richclub结构的确定:以某个节点为例,k值满足φnorm(k)>1时即该节点具有richclub特性,具有richclub特性的节点的集合即为richclub结构。
(3)依据richclub结构,将大脑结构网络的节点分为rich节点、non-rich节点,边分为rich边、feeder边、local边,利用feeder边、local边和所有节点构建feeder-local子网络;
其中,所述rich节点、non-rich节点、rich边、feeder边和local边的定义方法为:所述richclub结构内含有的节点即为richclub节点,richclub结构外的节点即为non-richclub节点;用于连接richclub节点的边为richclub边,用于连接richclub节点和non-richclub节点的边为feeder边,用于连接non-richclub节点的边为local边。
(4)利用图核(graphkernel)的方法度量建模样本中每两个样本的feeder-local子网络的拓扑结构相似性,构建特征矩阵,见图2:
a、针对feeder-local子网络的每个节点,基于其度的大小,给定每个节点初始标签,再根据节点所连接的其他节点情况,给定每个节点增强标签;将初始标签与增强标签混合重新进行标记,得到最终标签集合l={l1,l2,……,ln};l为最终标签的集合,l1,l2,……,ln代表不同的标签,n代表总标签的数量;
b、针对每个样本的feeder-local子网络g,定义一个特征向量φ(g)用于表示这个子网络内不同标签的特征信息:
φ(g)=(s(g,l1),s(g,l2),…,s(g,ln))
其中,s(g,li)代表第i个标签在feeder-local子网络g中出现的次数,φ(g)代表子网络g中所有标签出现次数的集合;
c、针对建模样本中每两个样本i和j对应的feeder-local子网络gi、gj,两个子网络的相似性度量定义为两个子网络特征向量φ(g)的内积,
k(gi,gj)=<φ(gi),φ(gj)>
其中,k(gi,gj)越大,说明两个子网络的拓扑结构越相似;
d、特征矩阵定义为:矩阵的每一个元素代表样本i和样本j的相似性度量k(gi,gj),其表达形式如下:
(5)利用支持向量回归,将步骤(4)构建的特征矩阵作为特征集合,采取多项式核函数,构建评估模型。支持向量回归的模型构建如下:
xi是样本i在特征矩阵中的特征向量,f(xi)代表了给予样本i的特征向量的模型输出值,yi代表样本i的标签,m代表样本总量;ω=(ω1;ω2;……;ωd)为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离;c为正则化常数,l∈为∈-不敏感损失函数,∈为损失函数的一个参数,表示当预测值f(xi)与yi之间的差别的绝对值大于∈时才计算损失,公式如下:
将待测样本代入上述构建的评估模型中,见图3,根据新个体在模型平面上的分布位置,判断新个体的疾病恢复状态。在图3的新样本预测结果图中,左下角区域代表了治疗前患者的特征分布情况,每个小三角形代表了一个治疗前的患者的特征分布。右上角区域代表了治疗后患者的特征分布情况,每个小空心圆代表了一个治疗后的患者的特征分布。新样本用‘*’所表示,在特征分布空间更加接近于治疗后的患者群体,代表新样本应为治疗后的患者。
- 还没有人留言评论。精彩留言会获得点赞!