一种利用长短期记忆模型递归神经网络的语音识别方法与流程
本发明涉及语音识别领域,尤其是涉及了一种利用长短期记忆模型递归神经网络的语音识别方法。
背景技术:
语音识别常用于各种智能设备智能家居等领域中,迄今为止语音识别的误差较大,效果不理想。递归神经网络(RNNs)模型可以用来对两个序列之间的关系进行建模。但是,传统的RNNs,标注序列和输入的序列是一一对应的。不适合语音识别中的序列建模:识别出的字符序列或者音素序列长度远小于输入的特征帧序列。所以不能直接用RNN来建模。
本发明采用递归神经网络(RNNs),通过端到端的训练方法,采用连接时间分类(CTC)训练RNNs,这些结合长短期记忆模型LSTM单元,效果很好。结合多层表达在深度网络中证明有效,使用灵活。根据TIMIT语音识别基准,深长短期记忆RNNs实现16.8%的测试集误差。传统的语音识别系统,是由语音模型、词典、语言模型构成的,而其中的语音模型和语言模型是分别训练的,这就造成每一部分的训练目标都与整个系统的训练目标不一致。而本专利从语音特征(输入端)到文字串(输出端)就只有一个神经网络模型(这就叫“端到端”模型),可以直接用WER的某种代理作为目标函数来训练这个神经网络,避免花费无用功去优化个别的目标函数。
技术实现要素:
针对网络性能在语音识别的问题和传统语音识别系统每一部分的训练目标都与整个系统的训练目标不一致等问题,本发明的目的在于提供一种利用长短期记忆模型递归神经网络的语音识别方法,可以通过训练获取模型参数,之后用于语音和文本数据的识别。
为解决上述问题,本发明提供一种利用长短期记忆模型递归神经网络的语音识别方法,其主要内容包括:
(一)训练
(二)识别
其中,所述的一种利用长短期记忆模型递归神经网络的语音识别方法,通过端到端的训练方法,和长短期记忆模型(LSTM)结合,实现了16.8%的测试集误差,使用灵活,效果好。
其中,所述的递归神经网络(RNNs),给定输入序列x=(x1,…,xT),计算隐藏的向量序列h=(h1,…,hT),通过以下方程t=1~T输出向量序列y=(y1,…,yT),
yt=Whyht+by
W表示重量矩阵,代表输入-隐藏重量矩阵,b代表偏差向量,bh是指隐藏偏差向量,是指隐藏层功能,通常是一个sigmoid函数的对应元素的应用。
其中,所述的含LSTM单元,使用的是双向LSTM,得到双向LSTM的步骤如下:
(1)长短期记忆模型(LSTM)架构,使用内置的存储单元来存储信息,更好地发现和利用深度范围的内容,是由以下的复合函数实现:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
ht=ottanh(ct)
σ是逻辑sigmoid函数,I,f,o和c分别为输入门,forget门,输出门和激活载体,所有这些都和隐藏的向量h相同的大小;
(2)深度卷积RNNs的一个缺点是他们只能够利用以前的背景,在语音识别中,所有的话语都在一次被转录,双向RNNs(BRNNs)在两个方向上有两个独立的隐藏层处理数据,然后提供给相同的输出层;BRNN计算前置隐藏序列向后隐藏序列输出序列y通过重复后置层,t=1~T,前置层t=1~T然后更新输出层:
结合BRNNS和LSTM给出了双向LSTM,在两个输入方向上获得远距离内容,深度RNNs可以通过堆叠彼此的顶部的多个递归神经网络隐层来获得,随着一个层的输出序列,形成下一个的输入序列;
(3)假设相同的隐藏层函数用于堆叠中的所有n层,隐藏的向量序列hn通过n=1~N和t=1~T的迭代计算获得:
定义h0=x,网络输出yt
双向深RNNs通过更换每一个隐藏序列hn前向序列和后向序列实现,保证每一个隐藏层收到前向层和后向层的输入;如果LSTM应用于隐藏层,我们得到双向LSTM,是这里用到的主要的结构,双向LSTM效果明显好于单向LSTM。
其中,所述的训练,包括语音数据和文本数据,声学模型和语言模型,RNN传感器,解码,模型参数。
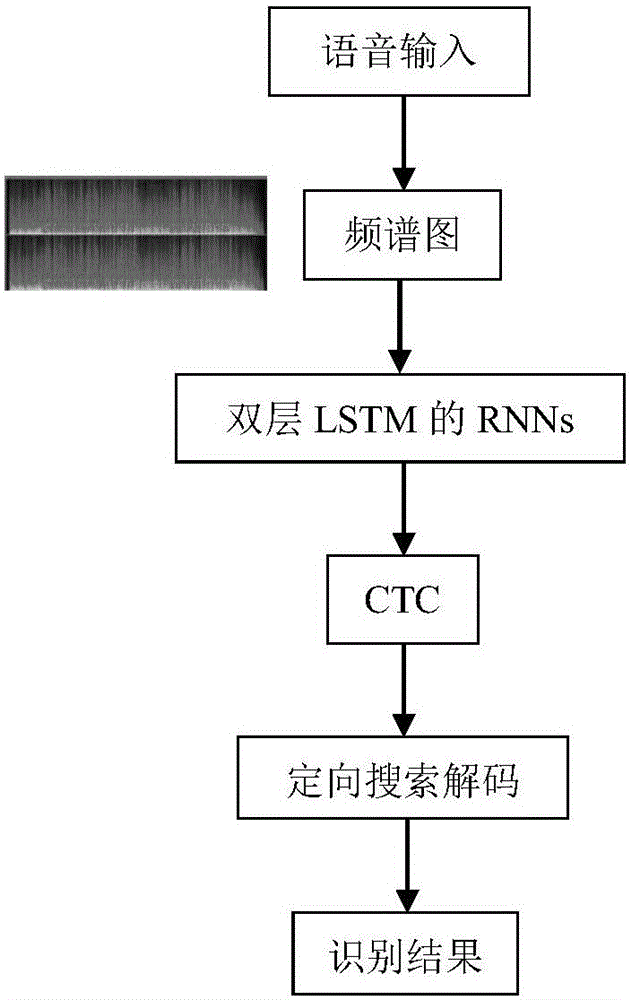
其中,所述的识别,包括语音输入,频谱图,双层LSTM的RNNs,CTC,定向搜索解码,识别结果。
进一步的,所述的语音数据和文本数据,是对语音数据和文本数据进行训练。
进一步的,所述的声学模型和语言模型,是将语音数据和文本数据利用声学模型和语言模型处理。
进一步的,所述的RNN传感器,它预测每个音素和之前音素的对应,从而产生一个共同训练的声学和语言模型,RNN传感器对每一个输入间隔t和输出时间间隔u的每个组合确定了一个单独的分布Pr(k|t,u),对于一个长度U和目标序列z,全套的TU共同决定了x和z之间的所有可能的排列,可以通过向前-向后的算法来决定logPr(z|x);RNN传感器可以从随机初始权重训练。
进一步的,所述的解码,是RNN传感器通过定向搜索解码,产生一个转录的n-best列表,定向搜索作为传感器,随着输出标签概率Pr(k|t,u)的改进,不依赖于以前的输出,因此Pr(k|t,u)=Pr(k|t),我们发现定向搜索比CTC前缀搜索更快更有效,注意转录的n-best列表起初通过长度归一化log概率分类logPr(y)/|y|。
进一步的,所述的模型参数,是使用RNN传感器进行解码形成的,利用训练好的参数对识别模型进行初始化。
进一步的,所述的频谱图,是通过将语音输入通过傅立叶变换转化得到的。
进一步的,所述的双层LSTM的RNNs,是在转化为频谱图后将利用含LSTM单元的RNNs网络进行定向搜索解码。
进一步的,所述的接时间分类(CTC),定义了一个只基于声学输入序列x的音素序列的分布,它是一个声学模型,在输入序列过程中在每一时间步使用软件函数层来定义的输出分布Pr(k|t),分布覆盖了K音节加上额外的空白符号代表非输出,因此软件函数层尺寸为K+1;这个结果定义了输入和输出序列之间的连线分布,CTC使用前置-后置算法来总结所有的排列可能,确定给出的输入序列中目标序列的正常化概率Pr(z|x),采用馈入隐藏激活代替将两种网络组成一个独立的前馈输出网络,输出用softmax函数使其正常化,产生Pr(k|t,u),用和代表CTC网络的最高的向前和向后的隐藏序列,p代表预测网络的隐藏序列,在每一步t,u,输出网络通过馈入和到一个线性层生成向量lt,然后馈入lt和pu到隐层函数生成ht,u,最后馈入ht,u,到一个尺寸为K+1的softmax层来确定Pr(k|t,u)
ht,u=tanh(Wlhlt,u+Wpbpu+bh)
yt,u=Whyht,u+by
yt,u[k]是指长度为K+1的非正常化输出向量的第kth元素,为了简化,我们限制所有的非输出层为相同的尺寸然而,它们是可以独立变化的;
用CTC训练的RNNs通常是双向的,为了确保每个Pr(k|t)依据全部的输入序列,不止是输入到t,这里,我们关注深度双向网络,Pr(k|t)的定义如下:
这里yt[k]是K+1非正常输出向量yt的kth元素,N是指双向级别的数量。
进一步的,所述的定向搜索解码是使用傅立叶变换对数据集进行解码滤波器,音素识别实验TIMIT语料库进行,隐藏层的数量为1~5。
进一步的,所述的识别结果,深度网络的优势非常明显,CTC的错误率从23.9%降到了18.4%,隐藏层的数量从1增加到了5。
进一步的,所述的训练,是利用随机梯度下降训练所有的网络,学习率为10-4,动量0.9,随机初始权值[-0.1,0.1],从开发集中的最高log-概率点开始,再用高斯权重噪声训练(σ=0.075),直到开发集中音素错误率最低。
进一步的,所述的识别,是使用TIMIT语料库进行,定向搜索解码的定向宽度为100。
附图说明
图1是本发明训练过程的流程图。
图2是本发明识别过程的流程图。
图3是长短期记忆模型(LSTM)记忆单元。
图4是双向RNNs(BRNNs)在两个方向上的两个独立的隐藏层处理数据。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明训练过程的流程图,包括语音数据和文本数据,声学模型和语言模型,RNN传感器,解码,模型参数。
语音数据和文本数据,是对语音数据和文本数据进行训练。
声学模型和语言模型,是将语音数据和文本数据利用声学模型和语言模型处理。
RNN传感器预测每个音素和之前音素的对应,从而产生一个共同训练的声学和语言模型,RNN传感器对每一个输入间隔t和输出时间间隔u的每个组合确定了一个单独的分布Pr(k|t,u),对于一个长度U和目标序列z,全套的TU共同决定了x和z之间的所有可能的排列,可以通过向前-向后的算法来决定logPr(z|x);RNN传感器可以从随机初始权重训练。
RNN传感器通过定向搜索解码,产生一个转录的n-best列表,定向搜索作为传感器,随着输出标签概率Pr(k|t,u)的改进,不依赖于以前的输出,因此Pr(k|t,u)=Pr(k|t),我们发现定向搜索比CTC前缀搜索更快更有效,注意转录的n-best列表起初通过长度归一化log概率分类logPr(y)/|y|。
模型参数,是使用RNN传感器进行解码形成的,利用训练好的参数对识别模型进行初始化。
训练过程利用随机梯度下降训练所有的网络,学习率为10-4,动量0.9,随机初始权值[-0.1,0.1],从开发集中的最高log-概率点开始,再用高斯权重噪声训练(σ=0.075),直到开发集中音素错误率最低。
图2是本发明识别过程的流程图,包括语音输入,频谱图,双层LSTM的RNNs,CTC,定向搜索解码,识别结果。
频谱图,是将语音输入通过傅立叶变换转化为频谱图。
双层LSTM的RNNs,是转化为频谱图后将利用含LSTM单元的RNNs网络进行定向搜索解码。
连接时间分类(CTC)定义了一个只基于声学输入序列x的音素序列的分布,它是一个声学模型,在输入序列过程中在每一时间步使用软件函数层来定义的输出分布Pr(k|t),分布覆盖了K音节加上额外的空白符号代表非输出,因此软件函数层尺寸为K+1;这个结果定义了输入和输出序列之间的连线分布,CTC使用前置-后置算法来总结所有的排列可能,确定给出的输入序列中目标序列的正常化概率Pr(z|x),采用馈入隐藏激活代替将两种网络组成一个独立的前馈输出网络,输出用softmax函数使其正常化,产生Pr(k|t,u),用和代表CTC网络的最高的向前和向后的隐藏序列,p代表预测网络的隐藏序列,在每一步t,u,输出网络通过馈入和到一个线性层生成向量lt,然后馈入lt和pu到隐层函数生成ht,u,最后馈入ht,u,到一个尺寸为K+1的softmax层来确定Pr(k|t,u)
ht,u=tanh(Wlhlt,u+Wpbpu+bh)
yt,u=Whyht,u+by
yt,u[k]是指长度为K+1的非正常化输出向量的第kth元素,为了简化,我们限制所有的非输出层为相同的尺寸然而,它们是可以独立变化的;
用CTC训练的RNNs通常是双向的,为了确保每个Pr(k|t)依据全部的输入序列,不止是输入到t,这里,我们关注深度双向网络,Pr(k|t)的定义如下:
这里yt[k]是K+1非正常输出向量yt的kth元素,N是指双向级别的数量。
定向搜索解码,是使用傅立叶变换对数据集进行解码滤波器,音素识别实验TIMIT语料库进行,隐藏层的数量为1~5。
识别结果,深度网络的优势非常明显,CTC的错误率从23.9%降到了18.4%,隐藏层的数量从1增加到了5。
识别过程使用TIMIT语料库进行,定向搜索解码的定向宽度为100。
图3是长短期记忆模型(LSTM)记忆单元。图4是双向RNNs(BRNNs)在两个方向上的两个独立的隐藏层处理数据。
给定输入序列x=(x1,…,xT),计算隐藏的向量序列h=(h1,…,hT),通过以下方程t=1~T输出向量序列y=(y1,…,yT),
yt=Whyht+by
W表示重量矩阵,代表输入-隐藏重量矩阵,b代表偏差向量,bh是指隐藏偏差向量,是指隐藏层功能,通常是一个sigmoid函数的对应元素的应用。
得到双向LSTM的步骤如下:
(1)长短期记忆模型(LSTM)架构,使用内置的存储单元来存储信息,更好地发现和利用深度范围的内容,如图3所示,是由以下的复合函数实现:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
ht=ottanh(ct)
σ是逻辑sigmoid函数,I,f,o和c分别为输入门,forget门,输出门和激活载体,所有这些都和隐藏的向量h相同的大小;
(2)深度卷积RNNs的一个缺点是他们只能够利用以前的背景,在语音识别中,所有的话语都在一次被转录,双向RNNs(BRNNs)在两个方向上有两个独立的隐藏层处理数据,然后提供给相同的输出层;如图4所示,BRNN计算前置隐藏序列向后隐藏序列输出序列y通过重复后置层,t=1~T,前置层t=1~T然后更新输出层:
结合BRNNS和LSTM给出了双向LSTM,在两个输入方向上获得远距离内容,深度RNNs可以通过堆叠彼此的顶部的多个递归神经网络隐层来获得,随着一个层的输出序列,形成下一个的输入序列;
(3)假设相同的隐藏层函数用于堆叠中的所有n层,隐藏的向量序列hn通过n=1~N和t=1~T的迭代计算获得:
定义h0=x,网络输出yt
双向深RNNs通过更换每一个隐藏序列hn前向序列和后向序列实现,保证每一个隐藏层收到前向层和后向层的输入;如果LSTM应用于隐藏层,我们得到双向LSTM,是这里用到的主要的结构,双向LSTM效果明显好于单向LSTM。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!