移动环境下基于异构双MIC的语音识别自适应系统的方法与流程
本发明公开了一种移动环境下基于异构双MIC的语音识别自适应系统的方法,属于语音信号处理技术领域。
背景技术:
随着科技的进步,人机交互已经经历了命令行、图形界面到触摸板的三代变革。现在,为了解放双手操作,我们已经来到语音控制时代的入口,人机交互模式正在发生着巨大的变化。最近的消息显示,各大科技巨头都已经开始布局语音交互领域,业内普遍认为语音作为人类信息最自然、最便捷的交互方式,必将成为新人机交互模式的重要组成部分。
由于移动和便携设备的使用场所十分多变,用户有可能时常处于声音极其嘈杂的环境下,而语音交互的完美实现则有赖于清晰的语音信息接收以及准确的语音识别能力。因此,在大数据和深度学习之外,如何在有噪声的情况下保持良好的语音接收是工程师们面临的一大挑战。而语音降噪技术的发展和强化,也正在推进语音交互时代的到来。
未来的语音识别市场,预计将会有越来越多的公司参与,以后语音识别的性能可能更多的体现在前端技术和语义理解上。机器要与人自然交流,必然就要考虑到用户说话的环境、周围环境的噪音、用户发音不准或者方言等等诸多因素,这就要求前端技术更加精准的模拟人体结构,仿真出机器人听觉系统,以实现解放双手自由对话的目的。
技术实现要素:
本发明提出了一种移动环境下基于异构双MIC的语音识别自适应系统的方法,从语音模拟信号最前端对信号进行优化,实现语音识别自适应。与现有方法相比,即使在信噪比变化剧烈的情况下仍能得到较清晰的语音信号,对语音识别的后续工作起了很好的铺垫作用,减轻了其应用于复杂场景的压力,并且实现简单,具有系统性自适应能力。
本发明为解决其技术问题采用如下技术方案:
步骤(1)结合优选通道与动态调整PA的方式,实现系统结构层的自适应调整前端状态以提高语音识别率;
步骤(1-1)对系统进行初始化,主MIC1主要用于远场拾音及远近距离预测,副MIC2主要用于近场拾音及抗强干扰场景,因而动态绑定主MIC1的PA,副MIC2绑定固定PA值。
步骤(1-2)根据PA的调整需求,由主MIC1当前获取的wav判断下次录音时PA的调整值。
步骤(1-3)由步骤(1-2)得出主MIC1的PA调整值,采用判决反馈的方式重置步骤(1-1)中主MIC1的PA,当前说话人的位置较远时,增大PA,当前说话人的位置较近时,降低PA,实时更新PA值,实现系统性自适应改善录音和识别效果。
步骤(2)终端进入录音模式后,同时启动主、副MIC的录音通道,探测到有语音信号,分析缓存buffer,根据优选规则,选择最优的录音通道;
步骤(2-1)判断主MIC1的噪声能量是否大于预设的能量阀值Main_noise;若是,优选副MIC2录音通道的数据。在噪声能量阈值判断条件下,优选副MIC2录音通道的数据,副MIC2具有拾音距离短且拾音方向窄的特点,其音频信息具有较大抗噪性和抗干扰性。
步骤(2-2)判断主MIC1的语音能量Main_veng是大于预设的削波能量阀值Main_vmax或是大于预设的语音最低能量阀值Main_vmin。若大于预设的削波能量阀值Main_vmax,优选副MIC2录音通道的数据,当主MIC1削波时,应选数据信息完好的副MIC2;若大于预设的语音最低能量阀值Main_vmin,优选主MIC1录音通道的数据。
步骤(2-3)判断副MIC2的语音能量Sub_veng是大于预设的语音最低能量阀值Sub_vmin或是大于预设的静音最高能量阀值Sub_mmax。若小于预设的静音最高能量阀值Sub_mmax,优选主MIC1录音通道的数据,当副MIC2录音音量较小时,可能用户离得较远,音量过小影响识别率,应选适应距离较大的主MIC1;若大于预设的语音最低能量阀值Sub_vmin,优选副MIC2录音通道的数据。
步骤(2-4)计算主MIC1的信噪比和副MIC2的信噪比,优选信噪比较高的录音通道的数据。
步骤(2-5)在相关判断条件下,优选副MIC2录音通道的数据。当优选主MIC1和优选副MIC2的条件同时成立时,优选副MIC2,其音频数据具有抗噪性和抗干扰性,有益于提高识别率。
步骤(3)由步骤(2)判断出最优录音通道后,识别最优通道的语音数据,并保存录音文件,无论最优通道是否为主MIC1,对其wav进行分析,判断下次录音时主MIC1的PA调整值;
步骤(3-1)识别最优通道的语音数据时,当判断当前说话结束,给出识别结果,并保存wav录音文件,对MIC1的wav分析,判断当前说话人的位置远近程度,主MIC1的PA调整值。
步骤(3-2)判断主MIC1的wav中最大能量值eng_max是否大于预设的削波能量阀值eng_thresh1;若是,根据eng_max与eng_thresh1的比值,调整PA,降低主MIC1的模拟增益。
步骤(3-3)判断主MIC1的wav中最大能量值eng_max是否小于预设的最低语音能量阀值eng_thresh2;若是,根据eng_max与eng_thresh2的比值,调整PA,增大主MIC1的模拟增益。
本发明的有益效果在于:
(1)本发明中公开的移动环境下基于异构双MIC的语音识别自适应系统的方法,可以随着说话人远近距离和环境噪声的变化,自动选择最合适的模型进行识别,显著提升准确率。
(2)本发明公开的从语音模拟信号最前端对信号进行优化,实现语音识别自适应的方法,对前端异构的双MIC的架构要求较大,从原始模拟信号本身对语音和噪声信号做了提升和抑制处理,避免了相关算法的缺陷,适用于各种应用场景。
附图说明
图1是本发明所述的利用异构双MIC优选识别自适应系统的方法示意图;
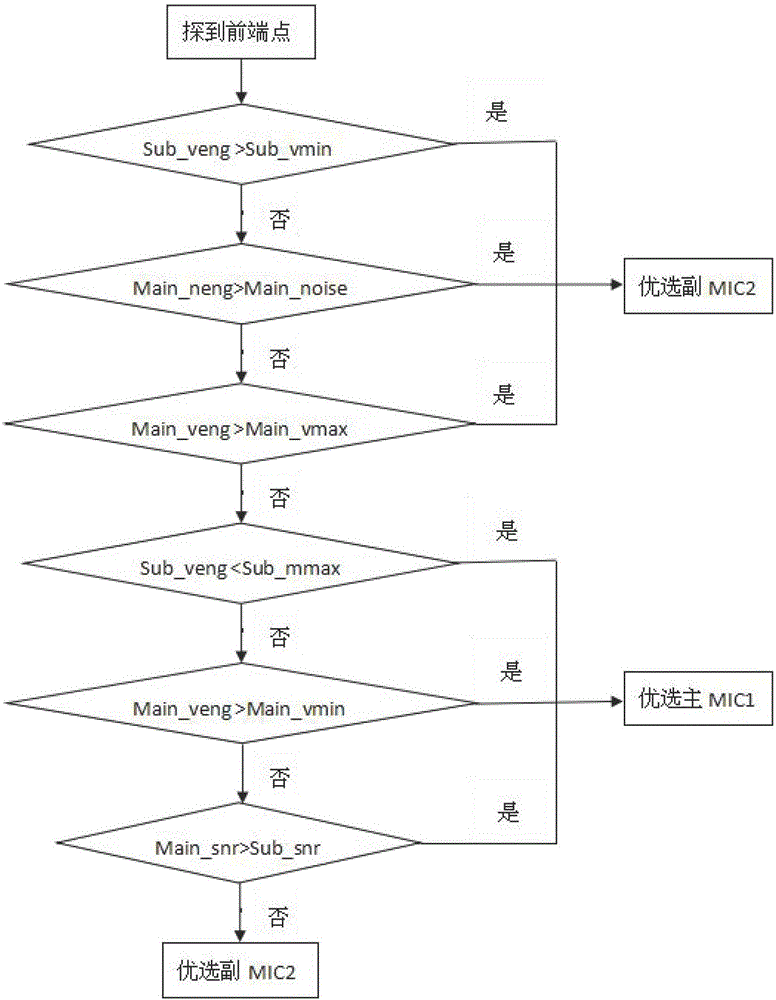
图2为异构双MIC的优选判断方法流程图;
图3为调整PA的方法示意图;
图4是本发明所述移动终端的结构示意框图。
具体实施方式
下面结合附图对本发明作进一步阐述:
如附图1及附图4所示,本发明所述的移动终端包括:PA绑定模块、优选模块和更新模块。初始化设定全向主MIC1和定向副MIC2的PA值,主MIC1实现动态绑定PA,副MIC2绑定固定PA值;绑定PA模块后,进入优选模块,首先需要设定主副MIC的优选识别规则,并当终端进入录音模式时,同时启动主、副MIC的录音通道,并一直保持录音状态;实时检测主副MIC是否有语音端点特征,若是,则根据优选规则,选出最优音频通道的数据进行语音识别,直到出现语音后端点,给出识别结果;最后,进入更新模块,根据当前主MIC1产生wav信息软控制主MIC1硬件PA,实现主MIC1录音通道PA的动态调整。
其中,优选规则如附图2所示。当探测到前端点后,根据主MIC1和副MIC2的语音能量、噪声能量、信噪比等判断出具有更高语音清晰度和辨识度的录音通道。
IF Main_veng>Main_noise Flag_channel=2
ELSEIF Sub_veng>Sub_vmin Flag_channel=2
ELSEIF Main_veng>Main_vmax Flag_channel=2
ELSEIF Sub_veng<Sub_mmax Flag_channel=1
ELSEIF Main_veng>Main_vmin Flag_channel=1
ELSEIF Main_snr>Sub_snr Flag_channel=1
ELSE Flag_channel=2
其中:
Main_noise表示主MIC1的噪声能量阀值;
Main_veng表示主MIC1的语音能量值;
Main_vmax表示主MIC1的削波能量阀值;
Main_vmin表示主MIC1的语音最低能量阀值;
Sub_veng表示副MIC2的语音能量值;
Sub_vmin表示副MIC2的语音最低能量阀值;
Sub_mmax表示副MIC2的静音最高能量阀值;
Main_snr表示主MIC1的信噪比;
Sub_snr表示副MIC2的信噪比;
Flag_channel表示优选通道,
Flag_channel=1表示优选主MIC1,
Flag_channel=2表示优选副MIC2。
由主MIC1产生的wav信息软控制主MIC1的硬件PA,实现主MIC1录音通道PA动态调整的方法如附图3所示。当主MIC1产生wav,对wav分析,判断主MIC1的PA值是否合适。若wav中最大能量值eng_max大于预设的削波能量阀值eng_thresh1,降低主MIC1的模拟增益PA,实现PA快速降低;若wav中最大能量值eng_max小于预设的最低语音能量阀值eng_thresh2,增大主MIC1的模拟增益PA,实现PA缓慢提高,当eng_max非常小时,PA将快速提高。其实现如下:
其中:
eng_max表示主MIC1的wav中最大能量值;
eng_thresh1表示主MIC1的削波能量阀值;
eng_thresh2表示主MIC1的最低语音能量阀值;
PA表示主MIC1下次录音时的PA变化量;
step_down表示PA降低时调整的步长;
step_up表示PA增大时调整的步长。
以上所述实施例,只是本发明的较佳实例,并非来限制本发明的实施范围,故凡依本发明申请专利范围所述的构造、特征及原理所做的等效变化或修饰,均应包括于本发明专利申请范围内。
- 还没有人留言评论。精彩留言会获得点赞!