一种语音情感识别方法与流程
本发明涉及语音情感识别的技术领域,尤其是指一种基于深度神经网络模型以及特征模糊优化的语音情感识别方法。
背景技术:
人类可以通过很多信号表达情感,如心跳频率、语音、人脸、行为动作等。计算机可以通过分析这些信号中的一个或者多个来识别和获取人类的情感状态,其中语音是日常生活中最重要同时也是最便捷的交流方式。随着计算机多媒体信息处理技术领域以及人工智能领域的快速发展,各研究机构越来越关注如何使计算机识别人的语音情感。
语音的情感识别,属于模式识别领域,但是它又稍微有些不同。例如对于普通的图像识别,给出很多小动物,猫、狗、羊等,进行分类识别,对于特定给出的一张动物图像,我们是可以确定它到底是猫还是狗的,这是精确的。但是,对于语音情感识别方面,很多时候给出一段语音,我们并不能明确地指出这段语音蕴含的情感是高兴的还是惊喜的,它也可能是夹杂多种情感的,从这个角度上来看,语音的情感信息是模糊性质的。
语音情感识别,要获得好的识别效果,最重要的是能够提取出显著的情感特征。近年来在提取特征方面,深度神经网络模型发展十分迅猛,并且提取特征的效果非常好,这主要体现在特征的分类准确率高以及无需人为选择提取哪些特征,具有自动化的特性。鉴于深度神经网络模型的上述优点,近年来语音情感识别方面的技术也是偏向于使用深度神经网络模型,例如深度卷积神经网络模型(Deep Convolutional Neural Networks,简称DCCNs),深度循环神经网络模型(Deep Recurrent Neural Networks,简称DRNNs)等,取得的效果也是相当的好。但是,有一点不足的是,仅仅使用这些深度神经网络模型来提取特征然后进行分类识别,并没有充分考虑和利用语音情感信息的模糊特性,而这一性质在语音情感特征方面是相当重要的。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于深度神经网络模型以及特征模糊优化的语音情感识别方法,该方法使用深度神经网络模型进行情感特征提取,并且针对语音情感信息具有模糊性这一特点,使用模糊优化理论对提取的特征进行优化,并且在模糊理论方面,借鉴深度学习的训练模式来自动构造相应的隶属函数,创新地解决模糊理论中隶属函数在选择上主观性强并且难以确定的问题。
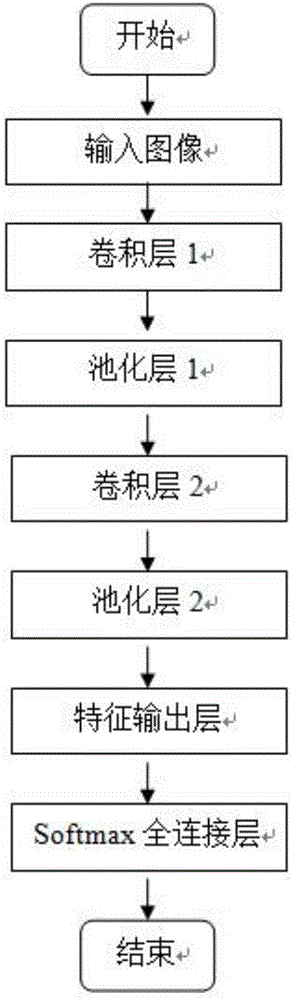
为实现上述目的,本发明所提供的技术方案为:一种语音情感识别方法,包括以下步骤:
1)将语音信号转换成语谱图作为原始输入;
2)训练深度卷积神经网络(DCNNs)来自动提取情感特征;
3)针对每一类情感训练一个栈式自编码器(SAE)并融合所有栈式自编码器自动构造出情感模糊集的隶属函数;
4)对步骤2)中得到的特征使用步骤3)中的模糊优化理论进行特征优化;
5)使用Softmax分类器进行情感分类识别。
在步骤1)中,使用快速傅里叶变换获得语音信号的语谱图,语谱图是一种三维频谱,它是表示语音频谱随时间变化的图形,其纵轴为频率,横轴为时间,任意一个给定频率成分在给定时刻的能量强弱用相应点的色调的深浅来表示。之所以要将语音信号转换成语谱图作为输入,是为了充分利用深度卷积神经网络对于图像特征自动提取的强大特性,而不需要像传统方法那样人为地使用滤波器对语音信号进行特征提取。
在步骤2)中,训练深度卷积神经网络来自动提取情感特征,具体如下:
使用步骤1)得到的语谱图作为训练输入样本,训练一个深度卷积神经网络模型,该模型具有两个卷积层,以及两个池化层,框架结构为:输入层(图像)→第一个卷积层→第一个池化层→第二个卷积层→第二个池化层→特征输出层→Softmax全连接层,其中训练该深度卷积神经网络模型,使用的是有监督的训练方式。
数据在卷积层的输入输出过程如下:所有的语谱图构成一个三维的输入数据,记为其中N代表样本数据总数,n1×n2是每一张输入语谱图的大小,第i张输入图像记为xi,卷积层使用的第j个卷积核记为kij,是一个系数矩阵,大小为l1×l2,经过卷积运算后,输出的图像构成的三维数据记为其中,M是输出的特征图的总数,m1×m2是输出特征图的大小,记第j张输出特征图为yj,卷积计算公式如下:其中bj是一个偏置参数,是二维的卷积运算。
数据在池化层的输入输出过程如下:卷积层中获得的输出特征图y作为池化层的输入,记为x,那么对于池化层中第i个输入xi,经过池化运算后得到的输出为yi=sig(pool(xi)),其中,pool(·)是进行池化操作,这里采用的是最大化池化方式,池化窗口大小为m×n,最大化池化操作pool(·)的定义是:对于给定的池化窗口,取里面所有元素中值最大的那个元素来代表这一个窗口区域,sig(·)是sigmoid函数,定义为:sig(x)=1/(1+e(-x))。
在步骤3)中,针对每一类情感训练一个栈式自编码器(SAE)并融合所有栈式自编码器自动构造出情感模糊集的隶属函数。在这一步骤中,首先确定所使用的语音数据集的情感类别N,并将情感作为一个模糊集。运用模糊理论进行特征的模糊优化,最重要的是对模糊集构造出相应的模糊隶属函数来衡量待优化的特征对于每类情感的隶属程度,并使用隶属度最高的那一类情感的模糊规则对特征进行优化,具有选择性优化的特点。对于每一类情感,训练一个相应的栈式自编码器,一共训练N个栈式自编码器。栈式自编码器是一个由多层稀疏自编码器组成的多层神经网络,其前一层自编码器的输出作为其后一层自编码器的输入,进行无监督训练。最后将训练得到的N个栈式自编码器结合起来,构建一个softmax全连接层。考虑到多层神经网络能够逼近任意的非线性函数,将softmax全连接层中连接输入输出层的权值矩阵作为情感模糊集的隶属函数;使用每个栈式自编码器的最后一层稀疏自编码器的连接输入层与隐含层的权值矩阵作为相应类情感选择性特征优化的模糊优化规则。
在步骤4)中,对步骤2)中得到的特征使用步骤3)中的模糊优化理论进行特征优化,具体为:步骤2)得到的每一个样本点的特征,都是一个n×1的一维向量,记为XT(x1,x2......xn),上标T代表向量的转置,步骤3)中得到的每一个栈式自编码器的最后一层稀疏自编码器的连接输入层与隐含层的权值矩阵Wi(m×n)作为特征优化规则,i代表N个栈式自编码器中的第i个;softmax全连接层的权值矩阵W(N×m)作为情感模糊集的隶属函数。对于每一个特征样本点X,都分别使用N类情感的特征优化规则进行Wi(m×n)·X运算,得到N个优化后的特征向量再根据求得相应的N个隶属度μi,最后根据所得的每一类情感隶属度大小来确定使用哪一类情感的特征优化规则,特征优化规则为上述的Wi(m×n)·X,得到最终的用来训练分类器的特征,其中这里的sig是sigmoid函数,定义为:sig(x)=1/(1+e(-x))。
在步骤5)中,使用步骤4)得到的优化后的情感特征来训练一个Softmax分类器来进行语音情感的分类识别,具体如下:
这里的Softmax分类器,包含一个特征输入层,一个类别输出层,是一个两层的模型,记输入为x,输出类别为y,则有计算公式如下:y=softmax(x),其中softmax(·)函数为
其中,xi为第i个输入样本,k为类别数量,p(yi=1|xi;θ)代表的是在当参数矩阵为θ时,输入样本xi属于第1类的概率;θ为待优化的矩阵参数,θ的求解方法为最小化如下的代价函数:
其中,m是输入样本的总数,表达式1{yi=j}的运算规则是:1{值为真的表达式}=1,1{值为假的表达式}=0;yi=j代表的含义是:对于输入样本xi,它的分类类别记为yi,如果yi是第j类,则yi=j的值为真,否则yi=j的值为假;log(·)是指对括号内容取自然对数,最小化J(θ)使用的是随机梯度下降算法。
本发明与现有技术相比,具有如下优点与有益效果:
1、将语音转换成语谱图作为原始输入,借助深度神经网络模型强大的自动提取特征的特性,可以获得鲁棒性强的特征。
2、充分考虑了语音情感的模糊性质,对提取后的情感特征进行选择性的模糊优化,提升特征的显著性。
3、在模糊优化理论方面,创新地模仿深度学习理论的样本训练方式,使用栈式自编码器自动构造情感模糊集的隶属函数,解决了隶属函数难以选择和确定的问题。
附图说明
图1是本发明方法的流程图。
图2是深度卷积神经网络模型的流程图。
图3是稀疏自编码器模型图。
图4是栈式自编码器模型图。
图5是构造隶属函数的流程图。
具体实施方式
下面结合具体实施例对本发明作进一步说明。
本实施例所提供的语音情感识别方法,具体是基于深度神经网络模型以及特征模糊优化,如图1所示,该语音情感识别方法包括以下步骤:
1)将语音信号转换成语谱图作为原始输入;
2)训练深度卷积神经网络(DCNNs)来自动提取情感特征;
3)针对每一类情感训练一个栈式自编码器(SAE)并融合所有栈式自编码器自动构造出情感模糊集的隶属函数;
4)对步骤2)中得到的特征使用步骤3)中的模糊优化理论进行特征优化;
5)使用Softmax分类器进行情感分类识别。
在步骤1)中,所述的将语音信号转换成语谱图作为原始输入,具体如下:
本实施所使用的语音数据集具有六类情感,分别是:愤怒,恐惧,高兴,平静,悲伤,惊喜,每段语音是wav的格式,对语音使用快速傅里叶变换获得语音信号的语谱图,语谱图是一种三维频谱,它是表示语音频谱随时间变化的图形,其纵轴为频率,横轴为时间,任意一个给定频率成分在给定时刻的能量强弱用相应点的色调的深浅来表示。获得语谱图的流程为:
1.1)对语音信号进行加窗分帧处理
语音信号具有短时平稳性,一般是10--30ms内可以认为语音信号近似不变,这样就可以把语音信号分为一些短段来来进行处理,这就是分帧。语音信号的分帧是采用可移动的有限长度的窗口进行加权的方法来实现。在分帧时,使用的是交叠分段的方法,前一帧和后一帧之间会有重叠,交叠部分称为帧移。在本实施里面,对每段语音使用汉明窗函数进行分帧,每帧为25ms,帧移为10ms。汉明窗函数如下:
其中,N为汉明窗的窗长,α一般取值为0.46。
1.2)对分帧后的语音片段使用快速傅里叶变换来获得语谱图
快速傅里叶变换(fft)可以将语音的时域信号转换成频域信号,将一段语音信号记为x,则根据y=fft(x)得到转换后的频域信号y,这里得到的y是一个二维向量,值为复数,要获得语谱图中频率的能量表示,对y进行共轭运算并进行对数能量转换(log-power),最后使用matlab画图显示出语音信号的语谱图。对数能量转换公式为convert_p=10*log10(abs(p)),其中,p为转换前的能量值,convert_p为转换后的对数能量值,abs()代表取绝对值。
之所以要将语音信号转换成语谱图作为输入,是为了充分利用深度卷积神经网络对于图像特征自动提取的强大特性,而不需要像传统方法那样人为地使用滤波器对语音信号进行特征提取,如使用的比较多的传统的MFCC(Mel频率倒谱系数的缩写)特征,它就是将经过加窗预处理的语音信号进行快速傅里叶变换,将时域信号变成频域信号,从而得到了信号的功率谱;然后进行滤波,滤波器通过的区域大概是人类听力的区域;最后再通过离散余弦变换去除各维信号之间的相关性,将信号映射到低维空间,最后得到相关特征。而使用频谱图的方式后续再提特征,就可以避免了人为选择滤波器等相关操作,尽量保持了样本数据的原始性。
在步骤2)中,所述的训练深度卷积神经网络(DCNNs)来自动提取情感特征,具体如下:
使用步骤1)得到的语谱图作为训练输入样本,训练一个深度卷积神经网络模型,如图2所示,该模型具有两个卷积层以及两个池化层,框架结构为:输入层(图像)→第一个卷积层→第一个池化层→第二个卷积层→第二个池化层→特征输出层→Softmax全连接层。训练该深度卷积神经网络模型,使用的是有监督的训练方式。
数据在卷积层的输入输出过程如下:所有的语谱图构成一个三维的输入数据,记为其中N代表样本数据总数,n1×n2是每一张输入语谱图的大小,在这里是80x60像素,第i张输入图像记为xi,卷积层使用的第j个卷积核记为kij,大小记为l1×l2,是一个系数矩阵,在本实施中第一个卷积层使用20个卷积核,大小是9x9,第二个卷积层使用40个卷积核,大小是7x7。经过卷积运算后,输出的图像构成的三维数据记为其中,M是输出的特征图的总数,m1×m2是输出特征图的大小,记第j张输出特征图为yj,卷积计算公式如下:其中bj是一个偏置参数,是二维的卷积运算。
数据在池化层的输入输出过程如下:卷积层中获得的输出特征图y作为池化层的输入,记为x,那么对于池化层中第i个输入xi,经过池化运算后得到的输出为yi=sig(pool(xi)),其中,pool(·)是进行池化操作,这里采用的是最大化池化方式,池化窗口大小选择为(2x2)和(3x2)。sig(·)是sigmoid函数,定义为:sig(x)=1/(1+e(-x))。
在步骤3)中,所述的针对每一类情感训练一个栈式自编码器(SAE)并融合所有栈式自编码器自动构造出情感模糊集的隶属函数,具体如下:
在本识别方法里面,所使用语音情感识别数据集有六类情感,分别是:愤怒,恐惧,高兴,平静,悲伤,惊喜,在这一步骤中,将情感作为一个模糊集,然后构造出该模糊集相应的模糊隶属函数来衡量待优化的特征对于每类情感的隶属程度,并使用隶属度最高的那一类情感的模糊规则对特征进行选择性优化。如图5所示,自动构造隶属函数如下:对于每一类情感,训练一个相应的栈式自编码器,一共训练六个栈式自编码器;栈式自编码器一个由多层稀疏自编码器组成的多层神经网络,如图4所示,其前一层自编码器的输出作为其后一层自编码器的输入,进行无监督训练;稀疏自编码器如图3所示,是一个三层的神经网络,一个输入层,一个隐含层以及一个输出层,对于一个输入样本,自编码器神经网络尝试学习一个h(W,b)(x)≈x的函数,其中W是权值矩阵,b是偏置参数。最后将训练得到的六个栈式自编码器结合起来,构建一个softmax全连接层。考虑到多层神经网络能够逼近任意的非线性函数,将softmax全连接层中连接输入输出层的权值矩阵作为情感模糊集的隶属函数;使用每个栈式自编码器的最后一层稀疏自编码器的连接输入层与隐含层的权值矩阵作为相应类情感选择性特征优化的模糊优化规则。每个栈式自编码器都是使用相应类情感的数据训练出来的,其后融合在一起构造出的模糊隶属函数对于不同类情感之间具有良好的区分度,用来对特征进行模糊优化具有良好效果。
在步骤4)中,所述的对步骤2)中得到的特征使用步骤3)中的模糊优化理论进行特征优化,具体如下:
步骤2)得到的每一个样本点的特征,都是一个600×1的一维向量,记为XT(x1,x2......x600),步骤3)中得到的第i个栈式自编码器的最后一层稀疏自编码器的连接输入层与隐含层的权值矩阵Wi(300×600)作为特征优化规则,softmax全连接层的权值矩阵W(6×300)作为情感模糊集的隶属函数,对于每一个特征向量X,使用每一个Wi(300×600)进行运算,得到每一类情感优化后的特征向量i的取值为1--6,从而再根据求得相应的隶属度μi,最后根据所得的六类情感隶属度大小来确定使用哪一类情感的特征优化规则,特征优化计算为得到最终的用来训练分类器的特征。
在步骤5)中,所述的使用Softmax分类器进行情感分类识别,具体如下:
这里的Softmax分类器,包含一个特征输入层,输入层的每个输入特征向量大小是300x1;一个类别输出层,有6类,是一个两层的模型。记输入为x,输出类别为y,则有计算公式如下:y=softmax(x),其中softmax(·)函数为
其中,xi为第i个输入样本;k为类别数量,这里取值为6;p(yi=1|xi;θ)代表的是在当参数矩阵为θ时,输入样本xi属于第1类的概率;θ为待优化的矩阵参数,θ的求解方法为最小化如下的代价函数:
其中,m是输入样本的总数,表达式1{yi=j}的运算规则是:1{值为真的表达式}=1,1{值为假的表达式}=0;yi=j代表的含义是:对于输入样本xi,它的分类类别记为yi,如果yi是第j类,则yi=j的值为真,否则yi=j的值为假;log(·)是指对括号内容取自然对数,最小化J(θ)使用的是随机梯度下降算法。
综上所述,本发明方法为语音情感识别在特征提取和优化方面提供了新的方法,充分利用了语音情感信息本身所具有的模糊特性,对提取的特征进行优化,获得显著性更好的情感特征,提高语音情感分类识别的准确率,值得推广。
以上所述实施例只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!