一种通过声音模仿识别人物角色的方法及装置与流程
本发明属于计算机技术领域,尤其涉及一种通过声音模仿识别人物角色的方法及装置。
背景技术:
很多模仿爱好者或者表演者需要对名人、动画人物和动物叫声等声音进行模仿,但是模仿者并不知道自身的模仿水平如何,通常只有通过观众是否能够从其模仿的声音中辨别出所模仿的对象,才能检验出模仿水平,然而观众自身的偏好不同,并不一定能够对模仿者所模仿的对象进行辨别,另外,在平时模仿练习当中也并非能够一直有观众对模仿者的模仿进行辨别,因此,对于模仿者而言,需要找到一种能够随时在模仿过程中对其所模仿的对象进行辨别,以帮助模仿者提高模仿兴趣以及模仿水平。
技术实现要素:
本发明的目的在于提供一种通过声音模仿识别人物角色的方法及装置,旨在解决现有技术中模仿者无法对自身所模仿的对象进行辨别的问题。
一方面,本发明提供了一种通过声音模仿识别人物角色的方法,所述方法包括下述步骤:
在终端获取用户输入的声音,提取所述声音的声音特征;
将所述声音特征在语音库中进行匹配,以得到相匹配的声音特征;
根据所述相匹配的声音特征,发送对应的人物角色媒体信息。
另一方面,本发明提供了一种通过声音模仿识别人物角色的装置,所述装置包括:
第一提取单元,用于在终端获取用户输入的声音,提取所述声音的声音特征;
匹配单元,用于将所述声音特征在语音库中进行匹配,以得到相匹配的声音特征;以及
识别人物角色单元,用于根据所述相匹配的声音特征,发送对应的人物角色媒体信息。
本发明实施例通过对用户的声音提取声音特征,在语音库中进行匹配,从而识别出用户所模仿的人物角色,使得模仿者在没有观众的情况下,得知自身所模仿的人物角色是否能够被识别出,通过输入的声音识别出对应的人物角色,增加互动性,提高了模仿者的模仿兴趣,同时在终端上增加通过声音模仿识别人物角色的功能可以增强用户体验感,带来更多的趣味性。
附图说明
图1是本发明实施例一提供的通过声音模仿识别人物角色的方法的实现流程图;
图2是本发明实施例二提供的通过声音模仿识别人物角色的方法的实现流程图;
图3是本发明实施例三提供的通过声音模仿识别人物角色的装置的结构示意图;以及
图4是本发明实施例四提供的通过声音模仿识别人物角色的装置的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下结合具体实施例对本发明的具体实现进行详细描述:
实施例一:
图1示出了本发明实施例一提供的通过声音模仿识别人物角色的方法的实现流程图,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:
在步骤S101中,在终端获取用户输入的声音,提取声音的声音特征。
在本发明实施例中,终端可以是智能手机、平板电脑和可穿戴设备等,可穿戴设备即直接穿在身上,或是整合到用户的衣服或配件的一种便携式设备,为了便于用户随时能够进行模仿练习并且增加模仿时的便捷性,优选地,对于本发明提出的通过声音模仿识别人物角色的方法可以应用在可穿戴设备上,目前的可穿戴设备功能较为单一,为了方便模仿爱好者或者是儿童可以便于对各种有趣的人物角色的声音进行模仿,将可穿戴设备增加通过声音模仿识别人物角色的功能,增加了可穿戴设备的功能性以及使用价值。以可穿戴设备为例,可穿戴设备上设置有麦克风,以用于采集声音,用户可以对着可穿戴设备上的麦克风发出想要模仿的人物角色的声音,可穿戴设备对麦克风采集到的声音形成声音数据,并提取声音的声音特征,根据提取的声音特征对用户的声音进行识别,以辨别出用户所模仿的人物角色。
进一步地,由于声音模仿依赖于音调以及音色两个特征,因此为了更加准确地、快速地进行识别,需要对声音特征进行针对性的提取。具体地,对声音分别提取音调特征以及音色特征,以得到声音特征。
在步骤S102中,将声音特征在语音库中进行匹配,以得到相匹配的声音特征。
在本发明实施例中,在提取声音特征后,将声音特征在语音库中进行匹配,语音库中包含了人物角色的声音特征以及与人物角色的声音特征所对应的人物媒体信息,将提取的声音特征在与语音库中的人物角色的声音特征进行一一匹配,以得到相匹配的声音特征。
进一步地,在语音库中,分别对声音特征中的音调特征以及音色特征进行匹配;
获取与音调特征以及音色特征均匹配的声音特征。
具体地,在对用户输入的声音分别提取音调特征以及音色特征后,在进行匹配时,依次与语音库中的人物角色的声音特征进行匹配,对于每一个人物角色的声音特征,将声音特征中的音调特征以及音色特征分别进行匹配,当声音特征中的音调特征以及音色特征均与人物角色的声音特征中的音调特征以及音色特征所匹配时,确定相匹配的声音特征。
在步骤S103中,根据相匹配的声音特征,发送对应的人物角色媒体信息。
在本发明实施例中,当得到相匹配的声音特征后,根据人物角色的声音特征与人物角色媒体信息建立一一对应的关系,发送对应的人物角色媒体信息。该人物角色媒体信息包括:人物角色的语音信息以及静态或者动态人物角色的形象信息。例如,某个动画人物的语音信息以及动画人物的动画形象信息。
本发明实施例通过对用户的声音提取声音特征,在语音库中进行匹配,从而识别出用户所模仿的人物角色,使得模仿者在没有观众的情况下,得知自身所模仿的人物角色是否能够被识别出,通过输入的声音识别出对应的人物角色,增加互动性,提高了模仿者的模仿兴趣,同时在终端上增加通过声音模仿识别人物角色的功能可以增强用户体验感,带来更多的趣味性。
实施例二:
图2示出了本发明实施例二提供的通过声音模仿识别人物角色的方法的实现流程图,为了便于说明,仅示出了与本发明实施例相关的部分,详述如下:
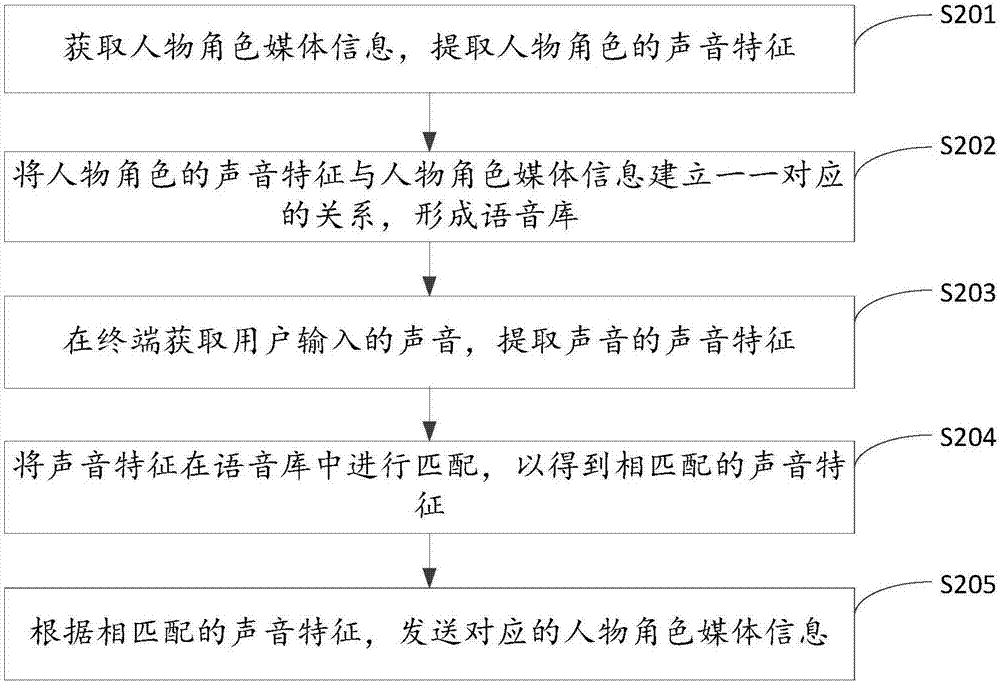
在步骤S201中,获取人物角色媒体信息,提取人物角色的声音特征。
在步骤S202中,将人物角色的声音特征与人物角色媒体信息建立一一对应的关系,形成语音库。
在本发明实施例中,根据用户录制的或者存储的人物角色媒体信息,对该人物角色媒体信息提取人物角色的声音特征,将人物角色的声音特征与人物角色媒体信息建立一一对应的关系,形成语音库。具体地,不同的用户具有自身的模仿偏好,比如说儿童更多的是模仿卡通人物或者动物的声音,表演者更多的是模仿名人的声音,因此,可以对语音库进行分类,得到媒体分类,该媒体分类包括动物角色的媒体信息、卡通人物角色的媒体信息以及名人角色的媒体信息。用户可以根据自身需求,通过录制的或者存储的人物角色媒体信息后在语音库中标记对应的媒体分类,以便后续可以在语音库中选取针对性的媒体信息进行学习以及练习。
在步骤S203中,在终端获取用户输入的声音,提取声音的声音特征。
在步骤S204中,将声音特征在语音库中进行匹配,以得到相匹配的声音特征。
在步骤S205中,根据相匹配的声音特征,发送对应的人物角色媒体信息。
在本发明实施例中,步骤S203—S205的实施方式可对应参考前述实施例一中步骤S101—S103的描述,在此不再赘述。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于一计算机可读取存储介质中,所述的存储介质,如ROM/RAM、磁盘、光盘等。
实施例三:
图3示出了本发明实施例三提供的通过声音模仿识别人物角色的装置的结构示意图,为了便于说明,仅示出了与本发明实施例相关的部分。在本发明实施例中,通过声音模仿识别人物角色的装置包括:第一提取单元31、匹配单元32以及识别人物角色单元33,其中:
第一提取单元31,用于在终端获取用户输入的声音,提取声音的声音特征。
在本发明实施例中,终端可以是智能手机、平板电脑和可穿戴设备等,可穿戴设备即直接穿在身上,或是整合到用户的衣服或配件的一种便携式设备,为了便于用户随时能够进行模仿练习并且增加模仿时的便捷性,优选地,对于本发明提出的通过声音模仿识别人物角色的方法可以应用在可穿戴设备上,目前的可穿戴设备功能较为单一,为了方便模仿爱好者或者是儿童可以便于对各种有趣的人物角色的声音进行模仿,将可穿戴设备增加通过声音模仿识别人物角色的功能,增加了可穿戴设备的功能性以及使用价值。以可穿戴设备为例,可穿戴设备上设置有麦克风,以用于采集声音,用户可以对着可穿戴设备上的麦克风发出想要模仿的人物角色的声音,可穿戴设备对麦克风采集到的声音形成声音数据,并提取声音的声音特征,根据提取的声音特征对用户的声音进行识别,以辨别出用户所模仿的人物角色。
进一步地,由于声音模仿依赖于音调以及音色两个特征,因此为了更加准确地、快速地进行识别,需要对声音特征进行针对性的提取。具体地,第一提取单元具体用于对声音分别提取音调特征以及音色特征,以得到声音特征。
匹配单元32,用于将声音特征在语音库中进行匹配,以得到相匹配的声音特征。
在本发明实施例中,在提取声音特征后,将声音特征在语音库中进行匹配,语音库中包含了人物角色的声音特征以及与人物角色的声音特征所对应的人物媒体信息,将提取的声音特征在与语音库中的人物角色的声音特征进行一一匹配,以得到相匹配的声音特征。
进一步地,匹配单元32包括:
第一匹配单元321,用于在语音库中,分别对声音特征中的音调特征以及音色特征进行匹配;以及
第二匹配单元322,用于获取与音调特征以及音色特征均匹配的声音特征。
具体地,在对用户输入的声音分别提取音调特征以及音色特征后,在进行匹配时,依次与语音库中的人物角色的声音特征进行匹配,对于每一个人物角色的声音特征,将声音特征中的音调特征以及音色特征分别进行匹配,当声音特征中的音调特征以及音色特征均与人物角色的声音特征中的音调特征以及音色特征所匹配时,确定相匹配的声音特征。
识别人物角色单元33,用于根据相匹配的声音特征,发送对应的人物角色媒体信息。
在本发明实施例中,当得到相匹配的声音特征后,根据人物角色的声音特征与人物角色媒体信息建立一一对应的关系,发送对应的人物角色媒体信息。该人物角色媒体信息包括:人物角色的语音信息以及静态或者动态人物角色的形象信息。例如,某个动画人物的语音信息以及动画人物的动画形象信息。
实施例四:
图4示出了本发明实施例四提供的通过声音模仿识别人物角色的装置的结构示意图,为了便于说明,仅示出了与本发明实施例相关的部分。在本发明实施例中,通过声音模仿识别人物角色的装置包括:
第二提取单元41,用于获取人物角色媒体信息,提取所述人物角色的声音特征。
语音库形成单元42,用于将人物角色的声音特征与人物角色媒体信息建立一一对应的关系,形成语音库。
第一提取单元43,用于在终端获取用户输入的声音,提取声音的声音特征。
匹配单元44,用于将声音特征在语音库中进行匹配,以得到相匹配的声音特征。
识别人物角色单元45,用于根据相匹配的声音特征,发送对应的人物角色媒体信息。
在本发明实施例中,根据用户录制的或者存储的人物角色媒体信息,对该人物角色媒体信息提取人物角色的声音特征,将人物角色的声音特征与人物角色媒体信息建立一一对应的关系,形成语音库。具体地,不同的用户具有自身的模仿偏好,比如说儿童更多的是模仿卡通人物或者动物的声音,表演者更多的是模仿名人的声音,因此,可以对语音库进行分类,得到媒体分类,该媒体分类包括动物角色的媒体信息、卡通人物角色的媒体信息以及名人角色的媒体信息。用户可以根据自身需求,通过录制的或者存储的人物角色媒体信息后在语音库中标记对应的媒体分类,以便后续可以在语音库中选取针对性的媒体信息进行学习以及练习。
本发明实施例通过对用户的声音提取声音特征,在语音库中进行匹配,从而识别出用户所模仿的人物角色,使得模仿者在没有观众的情况下,得知自身所模仿的人物角色是否能够被识别出,通过输入的声音识别出对应的人物角色,增加互动性,提高了模仿者的模仿兴趣,同时在终端上增加通过声音模仿识别人物角色的功能可以增强用户体验感,带来更多的趣味性。
在本发明实施例中,通过声音模仿识别人物角色的装置各单元可由相应的硬件或软件单元实现,各单元可以为独立的软、硬件单元,也可以集成为一个软、硬件单元,在此不用以限制本发明。该装置各单元的实施方式具体可参考前述实施例一的描述,在此不再赘述。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!