追踪噪声源和目标声源的双麦克风降噪系统和方法与流程
本发明属于信号处理领域,特别涉及一种追踪噪声源和目标声源的双麦克风降噪系统和方法。
背景技术:
目前的人工耳蜗降噪技术一般是基于一个全向麦克风,即单麦克风降噪技术或两个全向麦克风,也就是双麦克风降噪技术。其中,单麦克风降噪技术的效果一般很难得到保证。比如传统的谱减法或维纳滤波,会产生语音信号的畸变以及“音乐噪音”,很难提升耳蜗植入者在噪声环境下的言语识别率。而一些最新的基于单麦克风的降噪技术,往往需要很大的运算资源,这都是人工耳蜗或助听器的DSP所无法承受的。
而传统的双麦克风技术,比如延时相加(DS,delay and sum)方法,是根据正前方的语音信号抵达两个麦克风的时间差而进行处理的。可是,考虑到用户体验,人工耳蜗体外机的发展趋势是越做越轻薄,因此两个麦克风的物理距离往往不超过两厘米,这也导致了语音信号抵达两个麦克风的时间差非常短,甚至不到一个采样点的差别。所以传统的DS方法只能稍微提升语音信号的信噪比,效果微乎其微。
在此基础上进行改进的差分麦克风阵列(DMA,differential microphone array)的方法,可以有效提升信号的信噪比,但是只能用来消除提前设定好的方向的噪声(如侧向90度或后向180度),而不能根据外部环境变化来实时地消除噪声。这样结果很有可能会导致噪声不能被有效地消除,而使得耳蜗植入者不能在噪声环境中感知语音信号。
技术实现要素:
有鉴于此,本发明的目的在于提供一种追踪噪声源和目标声源的双麦克风降噪系统和方法,据外部环境,实时追踪噪声源与目标声源的方向,进行定向降噪。
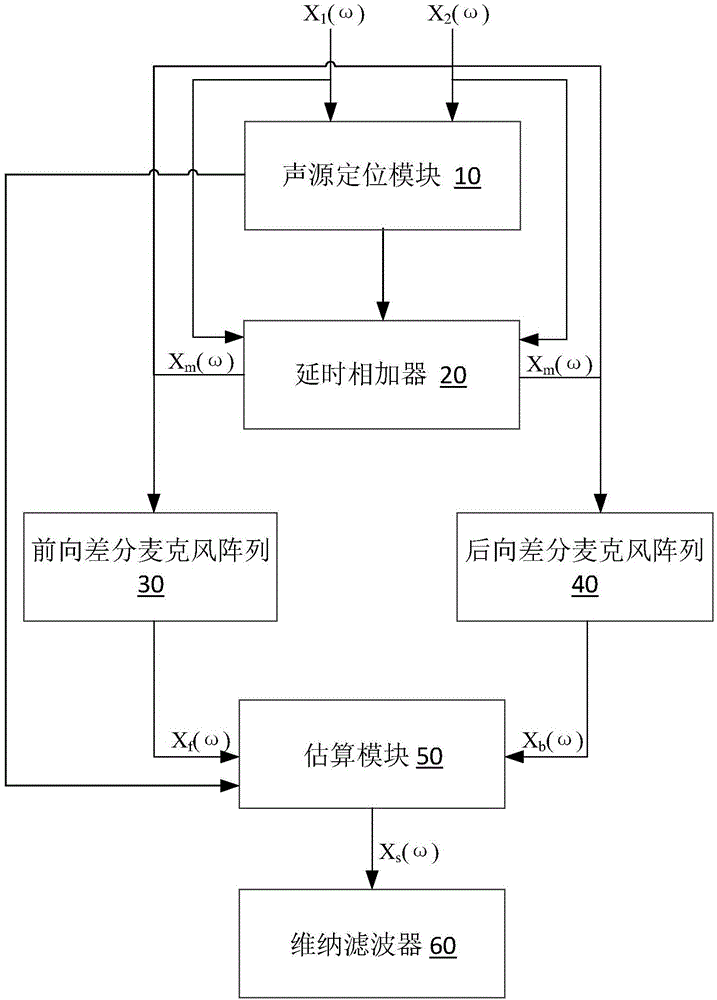
为达到上述目的,本发明提供了一种追踪噪声源和目标声源的双麦克风降噪系统,包括声源定位模块、延时相加器、前向差分麦克风阵列、后向差分麦克风阵列、估算模块和维纳滤波器,其中,
所述声源定位模块的输入为前向和后向麦克风的两路频域信号,对目标声源及噪声源的方向进行计算后输出;
所述延时相加器的输入为声源定位模块输出的目标声源方向、前向和后向麦克风的两路频域信号,输出为两路频域信号经方向识别和延时相加后,信噪比提升的混合信号;
所述前向差分麦克风阵列和后向差分麦克风阵列分别与所述延时相加器连接,二者的输入均为延时相加器输出的混合信号加后向麦克风的频域信号,输出分别为前向信号和后向信号;
所述估算模块与前向差分麦克风阵列和后向差分麦克风阵列以及声源定位模块分别连接,根据三者的输出估算出前向目标信号;
所述维纳滤波器与所述估算模块连接,将前向目标信号进行维纳滤波,输出目标语音信号。
优选地,所述声源定位模块输出的目标声源方向记为θt,噪声源方向记为θn由如下公式获得:
Xθ(ω)=X1(ω)+e-jωτcos(θ)X2(ω);
θt(ω)=θ,当Xθ(ω)=max(Xθ(ω)),且θ=-60°到60°;
θn(ω)=θ,当Xθ(ω)=max(Xθ(ω)),且θ=120°到240°;
其中,Xθ(ω)为不同延时叠加后的混合信号、θ为信号不同的入射角度、θt为目标声源的方向、θn为噪声源的方向、ω为角频率、τ为后向麦克风的延时大小,0°定义为正前方。
优选地,所述延时相加器的输出由如下公式获得:
其中,X1(ω)为前向麦克风的频域信号、X2(ω)为后向麦克风的频域信号、θt为目标声源即前向声源的方向、ω为角频率、τ为后向麦克风的延时大小,Xm(ω)为延时相加器输出的混合信号。
优选地,所述前向差分麦克风阵列输出的前向信号由如下公式获得:
Xf(ω)=Xm(ω)-e-jωτX2(ω)
其中,X2(ω)为后向麦克风的频域信号、ω为角频率、τ为后向麦克风的延时大小、Xm(ω)为延时相加器输出的混合信号、Xf(ω)为前向信号;
后向差分麦克风阵列输出的后向信号由如下公式获得:
Xb(ω)=Xm(ω)-ejωτX2(ω)
其中,X2(ω)为后向麦克风的频域信号、ω为角频率、τ为后向麦克风的延时大小、Xm(ω)为延时相加器输出的混合信号、Xb(ω)为后向信号。
优选地,所述估算模块输出的前向目标信号由如下公式获得:
XS(ω)=Xf(ω)-CXb(ω)
其中,Xf(ω)为前向信号、Xb(ω)为后向信号、C为介于0.1到1之间的常数,由噪声源的方向所决定、Xs(ω)为前向目标信号。
优选地,所述维纳滤波器输出的目标语音信号由如下公式获得:
其中,Xm(ω)为延时相加器输出的混合信号、Xs(ω)为前向目标信号、X2(ω)为后向麦克风的频域信号、S(ω)为目标语音信号。
基于上述目的,本发明还提供了一种追踪噪声源和目标声源的双麦克风降噪方法,包括以下步骤:
前向和后向麦克风的两路频域信号输入声源定位模块,声源定位模块对目标声源及噪声源的方向进行计算后输出;
目标声源方向、前向和后向麦克风的两路频域信号输入延时相加器,进行延时相加及信噪比提升处理,输出混合信号;
混合信号和后向麦克风的频域信号同时输入前向差分麦克风阵列和后向差分麦克风阵列,而后分别输出前向信号和后向信号;
前向信号、后向信号及噪声源的方向一同输入估算模块,估算出前向目标信号;
维纳滤波器与所述估算模块连接,将前向目标信号进行维纳滤波,输出目标语音信号。
优选地,所述声源定位模块输出的目标声源方向记为θt,噪声源方向记为θn,由如下公式获得:
Xθ(ω)=X1(ω)+e-jωτcos(θ)X2(ω);
θt(ω)=θ,当Xθ(ω)=max(Xθ(ω)),且θ=-60°到60°;
θn(ω)=θ,当Xθ(ω)=max(Xθ(ω)),且θ=120°到240°;
其中,Xθ(ω)为不同延时叠加后的混合信号、θ为信号不同的入射角度、θt为目标声源的方向、θn为噪声源的方向、ω为角频率、τ为后向麦克风的延时大小,0°定义为正前方。
优选地,所述延时相加器的输出由如下公式获得:
其中,X1(ω)为前向麦克风的频域信号、X2(ω)为后向麦克风的频域信号、θt为目标声源即前向声源的方向、ω为角频率、τ为后向麦克风的延时大小,Xm(ω)为延时相加器输出的混合信号。
优选地,所述前向差分麦克风阵列输出的前向信号由如下公式获得:
Xf(ω)=Xm(ω)-e-jωτX2(ω)
其中,X2(ω)为后向麦克风的频域信号、ω为角频率、τ为后向麦克风的延时大小、Xm(ω)为延时相加器输出的混合信号、Xf(ω)为前向信号;
后向差分麦克风阵列输出的后向信号由如下公式获得:
Xb(ω)=Xm(ω)-ejωτX2(ω)
其中,X2(ω)为后向麦克风的频域信号、ω为角频率、τ为后向麦克风的延时大小、Xm(ω)为延时相加器输出的混合信号、Xb(ω)为后向信号。
优选地,所述估算模块输出的前向目标信号由如下公式获得:
XS(ω)=Xf(ω)-CXb(ω)
其中,Xf(ω)为前向信号、Xb(ω)为后向信号、C为介于0.1到1之间的常数,由噪声源的方向所决定、Xs(ω)为前向目标信号。
优选地,所述维纳滤波器输出的目标语音信号由如下公式获得:
其中,Xm(ω)为延时相加器输出的混合信号、Xs(ω)为前向目标信号、X2(ω)为后向麦克风的频域信号、S(ω)为目标语音信号。
本发明的有益效果在于:有效提升前向信号(目标语音信号)的信噪比,同时抑制侧向或后向干扰(噪声)信号的强度,使得耳蜗植入者可以在噪声环境中感知和理解语音信号。并且,此技术可以根据周围环境,实时追踪噪声源与目标声源的方位,做到定向降噪。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统结构示意图;
图2为本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统中前向与后向差分麦克风阵列的极坐标增益曲线;
图3为本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统中估算模块输出的极坐标增益曲线与声源定位模块判定的目标声源方向;
图4为采用本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统的输入噪声信号输入输出波形图;
图5为采用本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统的输入语音信号输入输出波形图;
图6为本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪方法的步骤流程图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
参见图1,所示为本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统,包括声源定位模块10、延时相加器20、前向差分麦克风阵列30、后向差分麦克风阵列40、估算模块50和维纳滤波器60,其中,
所述声源定位模块10的输入为前向和后向麦克风的两路频域信号,对目标声源及噪声源的方向进行计算后输出;
所述延时相加器20的输入为声源定位模块10输出的目标声源方向、前向和后向麦克风的两路频域信号,输出为两路频域信号经方向识别和延时相加后,信噪比提升的混合信号;
所述前向差分麦克风阵列30和后向差分麦克风阵列40分别与所述延时相加器20连接,二者的输入均为延时相加器20输出的混合信号加后向麦克风的频域信号,输出分别为前向信号和后向信号;
所述估算模块50与前向差分麦克风阵列30和后向差分麦克风阵列40以及声源定位模块10分别连接,根据三者的输出估算出前向目标信号;
所述维纳滤波器60与所述估算模块50连接,将前向目标信号进行维纳滤波,输出目标语音信号。
进一步地,所述声源定位模块10输出的目标声源方向记为θt,噪声源方向记为θn由如下公式获得:
Xθ(ω)=X1(ω)+e-jωτcos(θ)X2(ω);
θt(ω)=θ,当Xθ(ω)=max(Xθ(ω)),且θ=-60°到60°;
θn(ω)=θ,当Xθ(ω)=max(Xθ(ω)),且θ=120°到240°;
其中,Xθ(ω)为不同延时叠加后的混合信号、θ为信号不同的入射角度、θt为目标声源的方向、θn为噪声源的方向、ω为角频率、τ为后向麦克风的延时大小,0°定义为正前方。
进一步地,所述延时相加器20的输出由如下公式获得:
其中,X1(ω)为前向麦克风的频域信号、X2(ω)为后向麦克风的频域信号、θt为目标声源即前向声源的方向、ω为角频率、τ为后向麦克风的延时大小,Xm(ω)为延时相加器20输出的混合信号。
进一步地,所述前向差分麦克风阵列30输出的前向信号由如下公式获得:
Xf(ω)=Xm(ω)-e-jωτX2(ω)
其中,X2(ω)为后向麦克风的频域信号、ω为角频率、τ为后向麦克风的延时大小、Xm(ω)为延时相加器20输出的混合信号、Xf(ω)为前向信号;
后向差分麦克风阵列40输出的后向信号由如下公式获得:
Xb(ω)=Xm(ω)-ejωτX2(ω)
其中,X2(ω)为后向麦克风的频域信号、ω为角频率、τ为后向麦克风的延时大小、Xm(ω)为延时相加器20输出的混合信号、Xb(ω)为后向信号。
进一步地,所述估算模块50输出的前向目标信号由如下公式获得:
XS(ω)=Xf(ω)-CXb(ω)
其中,Xf(ω)为前向信号、Xb(ω)为后向信号、C为介于0.1到1之间的常数,由噪声源的方向所决定、Xs(ω)为前向目标信号。
进一步地,所述维纳滤波器60输出的目标语音信号由如下公式获得:
其中,Xm(ω)为延时相加器20输出的混合信号、Xs(ω)为前向目标信号、X2(ω)为后向麦克风的频域信号、S(ω)为目标语音信号。
首先,进行目标声源与噪声源的定位。其中,Xθ为不同延时叠加后的混合信号,θ为信号不同的入射角度。声源定位模块10需要遍历在不同入射角度下的混合信号的强度,然后在正前方120度(-60到60度)以及正后方120度(120到240度)的范围内分别检测出相应的信号能量的峰值,对应于目标声源(θt)与噪声源(θn)的方向。
图2为本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统中前向与后向差分麦克风阵列输出的极坐标增益曲线:曲线1为前向信号Xf(ω)的极坐标增益曲线、曲线2为后向信号Xb(ω)的极坐标增益曲线;
图3为本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统中估算模块输出的极坐标增益曲线:使用前后向的两路输出信号Xf(ω)和Xb(ω),估算前向目标信号Xs(ω),当C=0.2时,噪声源为135°,曲线3为Xs(ω)的极坐标增益曲线、曲线4为目标声源的定位方向,30°;
为了说明本发明的有益效果,判定其是否对噪声进行了有效地去除,通过下述两种测试的波形来进行说明及验证。
参见图4,为采用本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统的输入噪声信号输入输出波形图:当噪声信号为来自135°的语谱噪声时,降噪前(曲线51),降噪后(曲线71)的信号与无噪信号(曲线61)对比图,此处截取的为纯噪声片段,因此降噪处理降低了噪声信号的幅度。
参见图5为采用本发明实施例的一种追踪噪声源和目标声源的双麦克风降噪系统的输入语音信号输入输出波形图:当噪声信号为来自180°的语谱噪声时,降噪前(曲线52),降噪后(曲线72)的信号与原始语音信号(曲线62)对比图,此处截取的为纯语音片段,因此降噪处理后的信号幅度仍然很接近原始信号的幅度,语音信号并未受到降噪算法的影响。
与上述系统对应的,本发明还提供了一种追踪噪声源和目标声源的双麦克风降噪方法,其流程图参见图6,包括以下步骤:
S101,前向和后向麦克风的两路频域信号输入声源定位模块,声源定位模块对目标声源及噪声源的方向进行判断计算后输出;
S102,目标声源方向、前向和后向麦克风的两路频域信号输入延时相加器,进行延时相加及信噪比提升处理,输出混合信号;
S103,混合信号和后向麦克风的频域信号同时输入前向差分麦克风阵列和后向差分麦克风阵列,而后分别输出前向信号和后向信号;
S104,前向信号、后向信号及噪声源的方向一同输入估算模块,估算出前向目标信号;
S105,维纳滤波器与所述估算模块连接,将前向目标信号进行维纳滤波,输出目标语音信号。
进一步地,S101所述声源定位模块输出的目标声源方向记为θt,噪声源方向记为θn,由如下公式获得:
Xθ(ω)=X1(ω)+e-jωτcos(θ)X2(ω);
θt(ω)=θ,当Xθ(ω)=max(Xθ(ω)),且θ=-60°到60°;
θn(ω)=θ,当Xθ(ω)=max(Xθ(ω)),且θ=120°到240°;
其中,Xθ(ω)为不同延时叠加后的混合信号、θ为信号不同的入射角度、θt为目标声源的方向、θn为噪声源的方向、ω为角频率、τ为后向麦克风的延时大小,0°定义为正前方。
进一步地,S102所述延时相加器的输出由如下公式获得:
其中,X1(ω)为前向麦克风的频域信号、X2(ω)为后向麦克风的频域信号、θt为目标声源即前向声源的方向、ω为角频率、τ为后向麦克风的延时大小,Xm(ω)为延时相加器输出的混合信号。
进一步地,S103所述前向差分麦克风阵列输出的前向信号由如下公式获得:
Xf(ω)=Xm(ω)-e-jωτX2(ω)
其中,X2(ω)为后向麦克风的频域信号、ω为角频率、τ为后向麦克风的延时大小、Xm(ω)为延时相加器输出的混合信号、Xf(ω)为前向信号;
后向差分麦克风阵列输出的后向信号由如下公式获得:
Xb(ω)=Xm(ω)-ejωτX2(ω)
其中,X2(ω)为后向麦克风的频域信号、ω为角频率、τ为后向麦克风的延时大小、Xm(ω)为延时相加器输出的混合信号、Xb(ω)为后向信号。
进一步地,S104所述估算模块输出的前向目标信号由如下公式获得:
XS(ω)=Xf(ω)-CXb(ω)
其中,Xf(ω)为前向信号、Xb(ω)为后向信号、C为介于0.1到1之间的常数,由噪声源的方向所决定、Xs(ω)为前向目标信号。
进一步地,S105所述维纳滤波器输出的目标语音信号由如下公式获得:
其中,Xm(ω)为延时相加器输出的混合信号、Xs(ω)为前向目标信号、X2(ω)为后向麦克风的频域信号、S(ω)为目标语音信号。
具体实施例参照上述系统实施例,在此不赘述。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!