一种基于特征融合的语音声效模式检测方法与流程
本发明涉及语音识别领域,特别涉及一种基于特征融合的语音声效模式检测方法。
背景技术:
声音效果(vocaleffort)简称声效,是正常人的一种发音变化的衡量,而这种发音变化是人出于正常交流的需要,根据交流时双方距离的远近或背景噪声的高低自动调整发音方式所产生的。通常将声效由低到高分为五个量级/模式:耳语、轻声、正常、大声、高喊。在现实的环境中,人们不可能一直都在同一种声效水平下交流:在图书馆或者自习室里需要通过耳语的方式交流;在吵杂的场合需要大声说话对方才能听见;而在嘈杂的工厂车间可能就需要通过高喊的方式才能够交流。
声音效果的改变不仅使得声音强度发生变化,还会影响语音信号的其它声学特性。因此,研究不同的声效水平下语音信号声学特性的变化规律并准确地检测出语音信号的声效模式,能够扩大语音识别技术的应用范围,对语音识别的实用化将产生积极的推动作用。此外,声效模式检测对于说话人识别和语音合成等领域的实用化也具有积极的作用。
现有的语音声效模式检测方法通常以语音的声强级、语句时长、帧能量分布以及频谱倾斜为特征来训练检测模型,并利用训练好的模型来识别语音的声效模式。这种方法检测耳语时准确率较高,这是因为耳语在发音时声带很少振动,所以在发音方式上与其它声效模式之间有着显著的区别。但是,其它几种声效模式中相邻的声效模式的语音在发音方式上并未有显著性的差异,反映在语谱上也未有明显的变化,而上述声强级等特征对于发音方式相近的声效模式辨识度较低,并不能提供有效的区分性信息。因此现有的方法对剩下的几种声效模式检测则容易混淆,误识率较高。
技术实现要素:
本发明的目的在于针对现有技术中的声效检测方法在识别耳语以外的其它四种声效模式时精度不高的缺陷,提出一种将元音的谱特征和频率特征相结合的声效模式检测方法,从而提高了所有声效模式的检测精度。
本发明公开了一种基于特征融合的语音声效模式检测方法,其具体包括以下步骤:
步骤1、接收语音信号;
步骤2、检测出所述语音信号中的元音,生成元音集合;
步骤3、提取所述元音集合中每一个元音的谱特征矢量序列;
步骤4、提取所述元音集合中每一个元音的频率特征矢量序列;
步骤5、根据所述元音集合中每一个元音的谱特征矢量序列和频率特征矢量序列生成该元音的声效特征矢量序列;
步骤6、根据所述元音集合中每一个元音的声效特征矢量序列将所述元音集合分别与多个候选声效模式进行匹配,生成每一个候选声效模式的匹配值;
步骤7、将匹配值最大的候选声效模式确定为所述语音信号的声效模式。
上述技术方案中,步骤3提取了每一个元音的谱特征矢量序列,步骤4提取了每一个元音的频率特征矢量序列。这两种基于语音帧的特征对于发音方式相近的声效模式都具有更好的辨识度。其中,谱特征侧重反映了语音信号各频带的语谱情况,频率特征反映了语音信号在各频带的瞬时频率和瞬时幅值的综合情况。因此,基于谱特征和频率特征生成的声效特征矢量序列对于所有的声效模式具有很好的识别能力。
附图说明
图1是根据本发明的一种基于特征融合的语音声效模式检测方法的流程图;
图2是根据本发明的一个提取元音的频率特征矢量序列的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
图1为根据本发明的一种基于特征融合的语音声效模式检测方法的流程图。其中,待识别声效模式的语音信号为连续语音,对应一个语句。
步骤101、接收语音信号;
步骤102、检测出所述语音信号中的元音,生成元音集合;
步骤103、提取所述元音集合中每一个元音的谱特征矢量序列;
步骤104、提取所述元音集合中每一个元音的频率特征矢量序列;
步骤105、根据所述元音集合中每一个元音的谱特征矢量序列和频率特征矢量序列生成该元音的声效特征矢量序列;
步骤106、根据所述元音集合中每一个元音的声效特征矢量序列将所述元音集合分别与多个候选声效模式进行匹配,生成每一个候选声效模式的匹配值;
步骤107、将匹配值最大的候选声效模式确定为所述语音信号的声效模式。
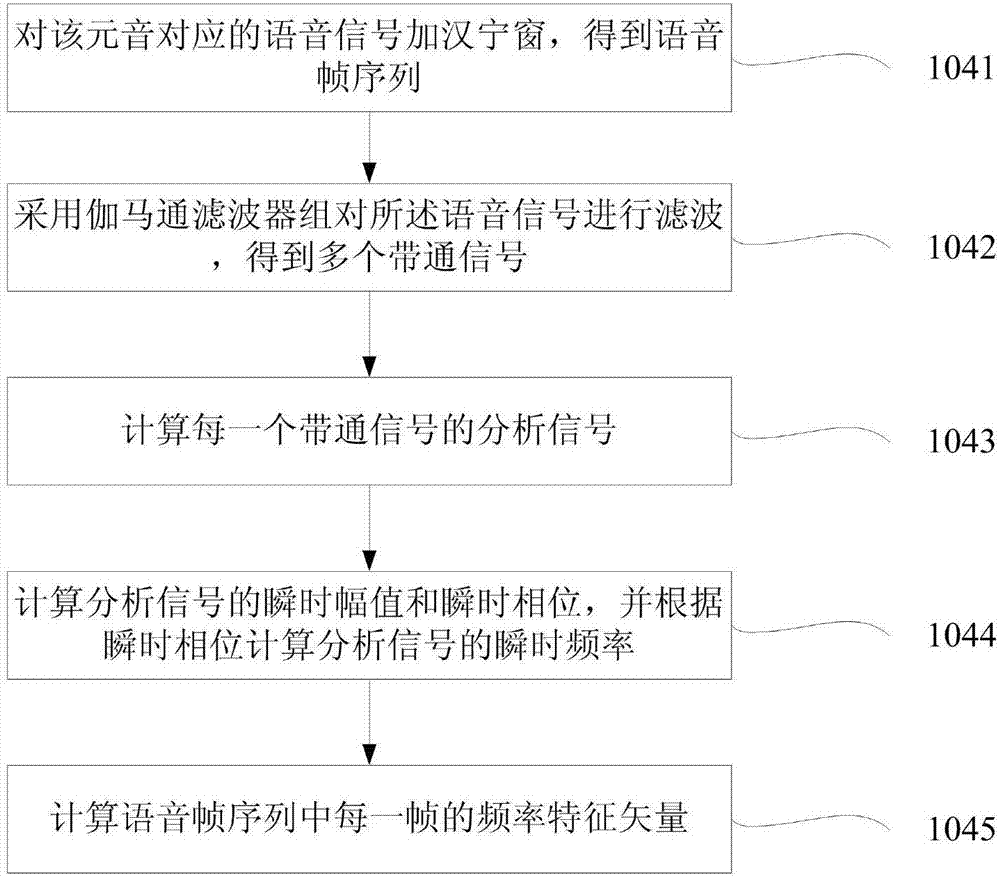
其中,在步骤104中,提取元音集合中每一个元音的频率特征矢量序列具体分为以下几个步骤,如图2所示:
步骤1041、对该元音对应的语音信号s(n)加汉宁窗,得到语音帧序列;
步骤1042、采用伽马通滤波器组对所述语音信号s(n)进行滤波,得到多个带通信号yk(n),k=1,…,n,其中n表示所述伽马通滤波器组包含的伽马通滤波器数量,k表示伽马通滤波器的编号,yk(n)为编号为k的伽马通滤波器输出的带通信号;
步骤1043、计算每一个带通信号yk(n)的分析信号sk(n),所述分析信号sk(n)通过如下公式获取:
其中
步骤1044、计算所述分析信号sk(n)的瞬时幅值ak(n)和瞬时相位,并根据所述瞬时相位计算所述分析信号sk(n)的瞬时频率fk(n);
步骤1045、通过如下公式计算所述语音帧序列中每一帧的频率特征矢量:
其中,i表示所述语音帧序列中的第i帧,f(i)表示第i帧的频率特征矢量,
此外,步骤106中每一个候选声效模式的匹配值通过如下公式确定:
其中,ve表示该候选声效模式,m(ve)表示该候选声效模式的匹配值,vset表示所述元音集合,v表示所述元音集合vset中的某个元音,p(ve|v)表示元音v属于候选声效模式ve的概率。
而p(ve|v)的计算过程如下:
从候选声效模式ve预置的概率模型集合中获取所述元音v对应的概率模型;将所述元音v的声效特征序列输入到所述元音v对应的概率模型,得到所述元音v属于所述候选声效模式ve的概率p(ve|v)。
例如:对于一句话“我和你一起去上课”对应的语音信号,
检测这句话对应的语音信号中包含的元音,生成元音集合:{o、e、i、i、i、u、ang、e};
提取元音集合:{o、e、i、i、i、u、ang、e}中每一个元音的梅尔频率倒谱系数矢量序列,其中每一个梅尔频率倒谱系数矢量包含12个分量;
提取元音集合:{o、e、i、i、i、u、ang、e}中每一个元音的频率特征矢量序列;以上述元音集合中的第一个元音o为例,其频率特征矢量序列的提取过程如下:
对元音o对应的语音信号so(n)加汉宁窗,得到了一个包含15帧的语音帧序列,其中窗长25ms,帧移10ms;采用伽马通滤波器组对所述语音信号so(n)进行滤波,得到多个带通信号yk(n),k=1,…,27,其中27表示伽马通滤波器组包含的伽马通滤波器数量,k表示伽马通滤波器的编号,yk(n)为编号为k的伽马通滤波器输出的带通信号;计算每一个带通信号yk(n)的分析信号sk(n),分析信号sk(n)通过如下公式获取:
其中
其中,i表示所述语音帧序列中的第i帧,f(i)表示第i帧的频率特征矢量,
根据元音集合:{o、e、i、i、i、u、ang、e}中每一个元音的梅尔频率倒谱系数矢量序列和频率特征矢量序列生成该元音的声效特征矢量序列;以上述元音集合中的第一个元音o为例,元音o包含15个语音帧,将每一帧的梅尔频率倒谱系数矢量和频率特征矢量相连接,生成了该帧的总体特征矢量。由于每一帧的梅尔频率倒谱系数矢量包含12个分量,每一帧的频率特征矢量包含了27个分量,所以该帧的总体特征矢量包含了39个分量。而15个语音帧的总体特征矢量就形成了元音o的总体特征矢量序列。然后利用主成份分析方法对元音o的总体特征矢量序列进行降维,得到元音o的声效特征矢量序列,其中每一个声效特征矢量包含了22个分量。
元音集合:{o、e、i、i、i、u、ang、e}中每一个元音的声效特征矢量序列计算出来以后,在步骤106中通过如下公式计算每一个候选声效模式的匹配值:
其中,ve表示一种候选声效模式,假如为‘高喊’,则mve表示高喊声效模式的匹配值,vset表示元音集合{o、e、i、i、i、u、ang、e},v表示所述元音集合vset中的某个元音,假如当前v的值具体为元音集合vset中的第一个元音o,p(ve|v)表示元音o属于候选声效模式‘高喊’的概率。
p(ve|v)的计算过程如下:
从候选声效模式‘高喊’预置的概率模型集合中获取元音o对应的概率模型;将所述元音o的声效特征序列输入到所述元音o对应的概率模型,得到元音o属于候选声效模式‘高喊’的概率p(ve|v)。其中,所有候选声效模式预置的概率模型都采用隐马尔可夫模型。
上述方案中,步骤103提取了元音的谱特征矢量序列,步骤104提取了元音的频率特征矢量序列。这两种基于语音帧的特征对于发音方式相近的声效模式都具有更好的辨识度。其中,谱特征侧重反映了语音信号各频带的语谱情况,频率特征反映了语音信号在各频带的瞬时频率和瞬时幅值的综合情况。因此,将谱特征和频率特征相结合生成的声效特征矢量序列对于所有的声效模式具有更好的识别能力。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!