一种基于嵌入式移动设备的地方口音语音识别系统的制作方法
本发明涉及语音识别领域,具体涉及一种基于嵌入式移动设备的地方口音语音识别系统。
背景技术:
中国的语音识别研究起始于1958年,由中国科学院声学所利用电子管电路识别10个元音。直至1973年才由中国科学院声学所开始计算机语音识别。由于当时条件的限制,中国的语音识别研究工作一直处于缓慢发展的阶段。目前国内使用的语言模型只是一种概率模型,要使计算机确实理解人类的语言并形象表达出来,就必须在识别这一点上取得进展,这是一个相当艰苦的工作。此外,随着硬件资源的不断发展,一些核心算法如特征提取、搜索算法或者自适应算法将有可能进一步改进。
国外ibm的viavoice和asiaworks的spk都需要用户在使用前进行几百句话的训练,以让计算机适应你的声音特征。这必然限制了语音识别技术的进一步应用,大量的训练不仅让用户感到厌烦,而且加大了系统的负担。并且,不能指望将来的消费电子应用产品也针对单个消费者进行训练。因此,必须在自适应方面有进一步的提高,做到不受特定人、口音或者方言的影响,这实际上也意味着对语言模型的进一步改进。现实世界的用户类型是多种多样的,就声音特征来讲有男音、女音和童音的区别,此外,许多人的发音离标准发音差距甚远,这就涉及到对口音或方言的处理。如果语音识别能做到自动适应大多数人的声线特征,那可能比提高一二个百分点识别率更重要。事实上,声音识别的应用前景也因为这一点打了折扣,只有普通话说得很好的用户才可以在其中文版连续语音识别方面取得相对满意的成绩。
当前计算机自动语音识别技术已取得了很大的进展。为确保统计模式匹配的有效性,必须收集大量数据来覆盖出现在语音识别应用中的所有声学方面的变化,如话者的变化、背景噪声、传声器和通信信道的不同影响。识别任务的不同严重制约了此类型技术的发展。在实际应用中不同的语言也会对语音识别的结果产生影响,尤其是中文。中文语音识别是一个非常复杂的任务。除去语音识别技术本身的复杂性,中文方言的复杂性也给语音识别的推广应用带来极大的困难。中国拥有成百上千种方言。到目前为止中文语音识别研究和开发基本只考虑普通话,对于地方口音的识别还为之甚少。
技术实现要素:
本发明所要解决的技术问题是提供一种基于嵌入式移动设备的地方口音语音识别系统,可以在嵌入式移动设备上对地方口音语音进行精准识别。
本发明解决上述技术问题的技术方案如下:一种基于嵌入式移动设备的地方口音语音识别系统,包括集成在嵌入式移动设备上的模型训练模块、特征提取模块和模式匹配模块,
所述模型训练模块用于对地方口音语音进行收集并训练,得出地方口音的词条模型;
所述特征提取模块用于对输入的地方口音中的语音特征进行提取;
所述模式匹配模块用于根据所述词条模型对所述语音特征进行语音匹配计算,得出语音识别结果。
本发明的有益效果是:本发明一种基于嵌入式移动设备的地方口音语音识别系统通过建立地方方言口音汉语普通话语音数据库,在其基础上开展发音变异规律、说话人自适应和非母语说话人口音识别研究,并探索解决多种语言混杂,差异化应用环境,以及不同方言和母语的用户语音识别问题,提高方言口音语音识别率,降低方言人群使用语音识别时学习和训练的难度,减少学习和训练工作量;同时,本系统将语言识别技术引入到各种嵌入式移动设备,可以实现智能互动。
在上述技术方案的基础上,本发明还可以做如下改进。
进一步,所述词条模型包括声学模型和语言学模型。
进一步,在所述语言学模型中,使用多发音字典对完全发音变异进行建模。
进一步,在所述声学模型中,使用上下文无关部分变异音子模型对部分发音变异进行建模。
进一步,在所述声学模型中,针对数字采用音节作为模型的基元;针对控制命令集或连续语音识别采用上下文右相关的声音和上下文无文的韵母作为模型基元。
采用上述进一步方案的有益效果是:声学模型的建模方法既考虑了音节内的协同发音,又降低了训练基元的数目,在声学模型规模、计算速度和识别率之间达到了平衡,使得本系统可以集成在嵌入式移动设备上。
进一步,在所述模式匹配模块中使用神经网络结构和云技术对所述语音特征进行语音匹配计算。
采用上述进一步方案的有益效果是:使用神经网络结构和云技术可以增加地方口音语音识别的正确性。
附图说明
图1为本发明一种基于嵌入式移动设备的地方口音语音识别系统的结构框图;
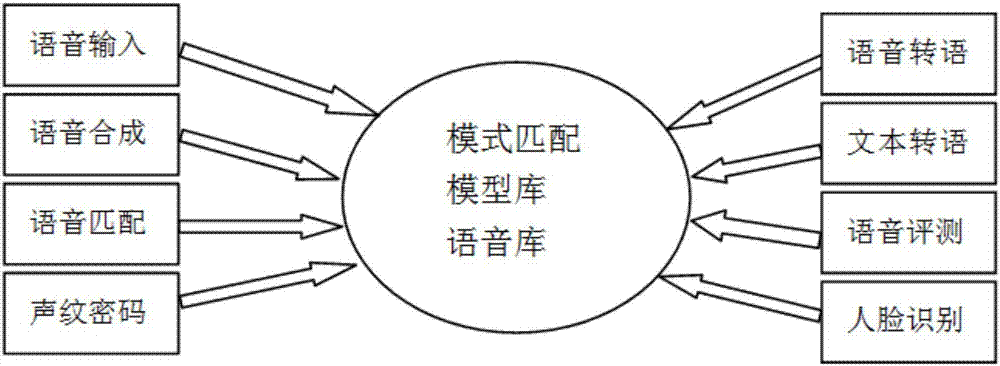
图2为本发明一种基于嵌入式移动设备的地方口音语音识别系统的识别体系。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
如图1所示,一种基于嵌入式移动设备的地方口音语音识别系统,包括集成在嵌入式移动设备上的模型训练模块、特征提取模块和模式匹配模块,所述模型训练模块用于对地方口音语音进行收集并训练,得出地方口音的词条模型;所述特征提取模块用于对输入的地方口音中的语音特征进行提取;所述模式匹配模块用于根据所述词条模型对所述语音特征进行语音匹配计算,得出语音识别结果。
具体的:所述词条模型包括声学模型和语言学模型。在所述语言学模型中,使用多发音字典对完全发音变异进行建模。在所述声学模型中,使用上下文无关部分变异音子模型对部分发音变异进行建模。在所述声学模型中,针对数字采用音节作为模型的基元;针对控制命令集或连续语音识别采用上下文右相关的声音和上下文无文的韵母作为模型基元。在所述模式匹配模块中使用神经网络结构和云技术对所述语音特征进行语音匹配计算。
在本具体实施例中,主要以武汉口音为例进行语音识别。
图2为本发明一种基于嵌入式移动设备的地方口音语音识别系统的识别体系。地方口音通过语音输入进入语音库,从模型库里进行语音匹配和模式匹配,选出匹配的语音合成,加入声纹密码;其中语音识别系统包括语音转语义、文本转语义、语音评测、人脸识别技术;语音识别技术与其他自然语言处理技术如机器翻译及语音合成技术相结合,可以构建出更加复杂的应用。
在本发明的系统中:根据对说话人说话方式的要求,可以对孤立字(词)和连接字进行语音识别;根据对说话人的依赖程度,可以对特定人和非特定人进行语音识别;根据词汇量大小,可以对小词汇量、中等词汇量、大词汇量以及无限词汇量进行语音识别。
在本发明的系统中,语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术三个方面;此外,还涉及到语音识别单元的选取等问题。
本发明的系统主要研究运用语音识别技术来识别武汉方言之间表达和交互,以实现高体验性的智能搜索和体验。本发明的系统主要要解决的问题有嵌入式武汉话语音识别系统中升学模型的建立,武汉话语音及文字的双向识别。使用神经网络结构和云技术增加识别的正确性。语言学模型在音调方面和普通话模型以及北方话模型的运用。
本系统研究并建立嵌入式武汉话语音识别系统的声学模型和语言学模型。当前,当武汉话语音识别引擎集成到嵌入式移动设备――手机上还是为数不多。其难度在于嵌入式移动设备的内存容量少,计算能力低,嵌入式移动设备上的武汉话语音识别系统需要特别的声学建模。本系统将对相关数据库采用不同的基元进行建模:
1.针对数字,采用了音节作为模型的基元;
2.对于控制命令集或连续语音识别采用了上下文右相关的声音和上下文无文的韵母作为模型基元。
这种建模方法既考虑了音节内的协同发音,又降低了训练基元的数目,在声学模型规模、计算速度和识别率之间达到了平衡。
在本发明的系统中,根据湖北境内人群说普通话时明显带有地方口音的语言使用现状,建立一个以研究非母语说话人汉语连续语音识别为目的的,不同口音的汉语普通话语音数据库,并在其基础上开展了发音变异规律、说话人自适应和非母语说话人口音识别研究。
基于本发明的系统,让手机平台不受地方口音影响,能正确识别各地方口音。语音识别引擎能集成到嵌入式移动设备。研究形成一套比较实用的说话人地方口音自适应方案,为今后在这方面的进一步研究开发工作奠定基础。
通过在语音层使用多发音字典对完全发音变异进行建模,在声学层分别使用上下文无关部分变异音子模型(partialchangephonemodel,pcpm)对部分发音变异进行建模,从而探究了语音层和声学层发音变异模型的特征、区别和联系,并将它们整合到语音识别系统的不同部分中,实现对发音变异的分层处理。应用分层发音变异模型,对带方言口音汉语普通话朗读语音进行测试,提高识别结果。分别使用带有湖北部分地方口音的普通话进行实验,从实验结果对汉语不同方言口音之间发音变异的区别和关联进行分析。
语音识别技术(autospeechrecognize,简称asr)所要解决的问题是让机器能够“听懂”人类的语音,将语音中包含的文字信息“提取”出来,相当于给机器安装上“耳朵”,使其具备“能听”的功能。
本发明提供了更为精准智能语音识别技术,具备高识别准确率、高识别速度、领域模型可定制、支持多种处理模式等功能,同时为将来具有sdk开发简单、开发包资源占用小等优势。能够实时、准确地对输入的语音进行识别与文本转写。并通过不断收集到的语料,进行模型的优化训练,不断的提高模型的覆盖率和识别的准确性。
其应用价值在于:
1)精准识别,识别引擎语义上下文自修正。
2)人机交互持久,持续录音,连续识别,过滤无效语音。
3)基于语义的智能断句随时可打断,支持主动式交互。
4)上下文对话,上下文理解,基于内容提问,多对话场景管理,跨场景信息共享长时记忆。
5)个性化可拓展,产品特性定制用户个性化支持交互模式可扩展。
本发明一种基于嵌入式移动设备的地方口音语音识别系统通过建立地方方言口音汉语普通话语音数据库,在其基础上开展发音变异规律、说话人自适应和非母语说话人口音识别研究,并探索解决多种语言混杂,差异化应用环境,以及不同方言和母语的用户语音识别问题,提高方言口音语音识别率,降低方言人群使用语音识别时学习和训练的难度,减少学习和训练工作量;同时,本系统将语言识别技术引入到各种嵌入式移动设备,可以实现智能互动。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!