一种领域自适应语音识别方法和装置与流程
本公开涉及语音识别领域,特别涉及一种领域自适应语音识别方法和装置。
背景技术:
语音识别是实现人工智能的基础,很多机器人、物联网、移动设备都采用语音作为交互入口。由于行业的多样化以及口语的多样化,语音识别需要的行业录音和标注数据相对较为缺乏,导致语音识别系统在应用于不同领域时识别准确率很低。现有的语音识别系统通常仅适用于某个特定领域或应用场景,例如仅适用于娱乐领域,或者仅适用于一般闲聊场景。当更换领域或应用场景时,需要重新选择音频数据,并基于重新选择的音频数据重新训练语音识别模型。这样的语音识别系统通常具有以下缺点:(1)效率低下,录制音频数据所需要的时间可达到几百至上千小时,效果迭代需要时间较长;(2)成本较高,录制的音频数据需要进行人工标注,人工标注消耗资金,且工时越长成本越高;(3)效果较差,重新录制的音频数据不一定完整覆盖全部音节,导致语音识别模型的识别效果较差。
技术实现要素:
本发明的目的是提供一种领域自适应语音识别方法,该方法能够克服现有语音识别方法应用于不同领域时效率和准确率较低的问题。
相应的,本发明实施例还提供一种领域自适应语音识别装置,用以保证上述方法的实现及应用。
为了解决上述问题,本发明实施例公开了一种领域自适应语音识别方法,包括:
基于初始音频语料进行训练,建立初始声学模型,以及基于初始文本语料进行训练,建立初始语言模型;
进行行业领域语料搜集和处理,基于处理后的行业领域语料进行训练,建立行业领域语言模型;
基于所述初始语言模型和所述行业领域语言模型进行适配计算,建立混合语言模型;
基于处理后的行业领域语料进行音素聚类,根据音素聚类结果进行训练,建立聚类声学模型;
对所述初始声学模型和所述聚类声学模型进行融合,建立融合声学模型;
接收输入的语音信号,基于所述融合声学模型和混合语言模型确定所述语音信号对应的词语序列。
优选地,所述初始语言模型是二元n-gram语言模型。
优选地,所述进行行业领域语料搜集和处理,基于处理后的行业领域语料进行训练,建立行业领域语言模型包括:
搜集与所述行业领域相关的语料,从所述语料中提取句子文本和专有名词;
对所述专有名词进行分类整理,建立专有名词词表;
基于所述专有名词词表对所述句子文本进行专有名词标注和替换,得到包含专有名词词表标记词的句子文本;
以所述包含专有名词词表标记词的句子文本作为训练语料进行训练,建立行业领域语言模型。
优选地,所述基于所述初始语言模型和所述行业领域语言模型进行适配计算,建立混合语言模型包括:
对所述初始语言模型和所述行业领域语言模型进行概率加权计算,建立混合语言模型。
优选地,对所述初始语言模型和所述行业领域语言模型进行概率加权计算,建立混合语言模型包括:
当初始文本语料和行业领域语料中都包含词语组合wi-1wi时,或者当初始文本语料中包含词语组合wi-1wi且行业领域语料中不包含词语组合wi-1wi时,按照以下公式(1)计算所述混合语言模型对应的条件概率:
p_mix(wi|wi-1)={xm*old_count(wi-1,wi)+ym*new_count(wi-1,wi)}/{xm*old_count(wi-1)+ym*new_count(wi-1)}(1)
其中,
xm=old_total_count/(old_total_count+new_total_count),
ym=new_total_count/(old_total_count+new_total_count),
其中,p_mix(wi|wi-1)表示所述混合语言模型对应的条件概率,wi-1和wi表示词语序列w中的两个相邻词语,w=w1w2…wn,1<i≤n,xm、ym分别表示针对所述初始语言模型和所述行业领域语言模型设置的加权系数,old_count(wi-1,wi)表示在所述初始文本语料中词语组合wi-1wi出现的次数,old_cout(wi-1)表示在所述初始文本语料中词语wi-1出现的次数,new_count(wi-1,wi)表示在所述行业领域语料中词语组合wi-1wi出现的次数,new_cout(wi-1)表示在所述行业领域语料中词语wi-1出现的次数,old_total_count表示所述初始文本语料中的总词数,new_total_count表示所述行业领域语料中的总词数。
优选地,对所述初始语言模型和所述行业领域语言模型进行概率加权计算,建立混合语言模型包括:
当初始文本语料中不包含词语组合wi-1wi且行业领域语料中包含词语组合wi-1wi时,按照以下公式(2)计算所述混合语言模型对应的条件概率:
p_mix(wi|wi-1)=p_new(wi|wi-1)(2)
其中,p_mix(wi|wi-1)表示所述混合语言模型对应的条件概率,wi-1和wi表示词语序列w中的两个相邻词语,w=w1w2…wn,1<i≤n,p_new(wi|wi-1)表示所述行业领域语言模型对应的条件概率。
优选地,所述基于处理后的行业领域语料进行音素聚类,根据音素聚类结果进行训练,建立聚类声学模型包括:
将所述专有名词词表中的专有名词的发音添加到所述专有名词词表中;
对所述专有名词的发音进行音素扩展;
针对音素扩展结果进行音素聚类;
基于音素聚类结果进行训练,建立聚类声学模型。
优选地,所述对所述初始声学模型和聚类声学模型进行融合,建立融合声学模型包括:
对所述初始声学模型和聚类声学模型进行转移概率的加权计算,建立融合声学模型。
优选地,对所述初始声学模型和聚类声学模型进行转移概率的加权计算,建立融合声学模型包括:
当所述初始声学模型和聚类声学模型中都包含状态转移a->b时,或者所述初始声学模型包含且所述聚类声学模型中不包含状态转移a->b时,按照以下公式(4)计算所述融合声学模型对应的转移概率:
p_ron(a->b)={xr*old_countr(a->b)+yr*new_countr(a->b)}/{xr*old_countr(a)+yr*new_countr(a)}(4)
其中,
xr=old_total_countr/(old_total_countr+new_total_countr),
yr=new_total_countr/(old_total_countr+new_total_countr),
其中,p_ron(a->b)表示所述融合声学模型对应的转移概率,a->b表示状态a转移到状态b,状态是指一个音素或者多个音素的聚类,xr、yr分别表示针对初始声学模型和聚类声学模型设置的加权系数,old_countr(a->b)表示在初始声学模型中a->b的转移频次,new_countr(a->b)表示在聚类声学模型中a->b的转移频次,old_countr(a)表示在所述初始音频语料中状态a出现的频次,new_countr(a)表示在所述音素聚类结果中状态a出现的频次,old_total_countr表示所述初始音频语料中的总状态数,new_total_countr表示所述音素聚类结果中的总状态数。
优选地,对所述初始声学模型和聚类声学模型进行转移概率的加权计算,建立融合声学模型包括:
当所述初始声学模型不包含且所述聚类声学模型中包含状态转移a->b时,按照以下公式(5)计算所述融合声学模型对应的转移概率:
p_ron(a->b)=p_newr(a->b)(5)
其中,p_ron(a->b)表示所述融合声学模型对应的转移概率,a->b表示状态a转移到状态b,状态是指一个音素或者多个音素的聚类,p_newr(a->b)表示所述聚类声学模型对应的转移概率。
优选地,所述基于所述融合声学模型和混合语言模型确定所述语音信号对应的词语序列包括:
求取概率p(w|x)最高时的词语序列w;
其中:
p(w|x)=argmax_wp(x|w)*p(w)
其中,x表示所述语音信号,w表示所述词语序列,p(x|w)表示所述融合声学模型对应的条件概率,p(w)表示所述混合语言模型对应的概率。
本发明实施例还提供一种领域自适应语音识别装置,包括:
初始建模模块,用于基于初始音频语料进行训练,建立初始声学模型,以及用于基于初始文本语料进行训练,建立初始语言模型;
行业领域语言模型建模模块,用于进行行业领域语料搜集和处理,基于处理后的行业领域语料进行训练,建立行业领域语言模型;
混合语言模型建模模块,用于基于所述初始语言模型和所述行业领域语言模型进行适配计算,建立混合语言模型;
聚类声学模型建模模块,用于基于处理后的行业领域语料进行音素聚类,根据音素聚类结果进行训练,建立聚类声学模型;
融合声学模型建模模块,用于对所述初始声学模型和聚类声学模型进行融合,建立融合声学模型;
解码模块,用于接收输入的语音信号,基于所述融合声学模型和混合语言模型确定所述语音信号对应的词语序列。
优选地,所述初始语言模型是二元n-gram语言模型。
优选地,所述进行行业领域语料搜集和处理,基于处理后的行业领域语料进行训练,建立行业领域语言模型包括:
搜集与所述行业领域相关的语料,从所述语料中提取句子文本和专有名词;
对所述专有名词进行分类整理,建立专有名词词表;
基于所述专有名词词表对所述句子文本进行专有名词标注和替换,得到包含专有名词词表标记词的句子文本;
以所述包含专有名词词表标记词的句子文本作为训练语料进行训练,建立行业领域语言模型。
优选地,所述基于所述初始语言模型和所述行业领域语言模型进行适配计算,建立混合语言模型包括:
对所述初始语言模型和所述行业领域语言模型进行概率加权计算,建立混合语言模型。
优选地,对所述初始语言模型和所述行业领域语言模型进行概率加权计算,建立混合语言模型包括:
当初始文本语料和行业领域语料中都包含词语组合wi-1wi时,或者当初始文本语料中包含词语组合wi-1wi且行业领域语料中不包含词语组合wi-1wi时,按照以下公式(1)计算所述混合语言模型对应的条件概率:
p_mix(wi|wi-1)={xm*old_count(wi-1,wi)+ym*new_count(wi-1,wi)}/{xm*old_count(wi-1)+ym*new_count(wi-1)}(1)
其中,
xm=old_total_count/(old_total_count+new_total_count),
ym=new_total_count/(old_total_count+new_total_count),
其中,p_mix(wi|wi-1)表示所述混合语言模型对应的条件概率,wi-1和wi表示词语序列w中的两个相邻词语,w=w1w2…wn,1<i≤n,xm、ym分别表示针对所述初始语言模型和所述行业领域语言模型设置的加权系数,old_count(wi-1,wi)表示在所述初始文本语料中词语组合wi-1wi出现的次数,old_cout(wi-1)表示在所述初始文本语料中词语wi-1出现的次数,new_count(wi-1,wi)表示在所述行业领域语料中词语组合wi-1wi出现的次数,new_cout(wi-1)表示在所述行业领域语料中词语wi-1出现的次数,old_total_count表示所述初始文本语料中的总词数,new_total_count表示所述行业领域语料中的总词数。
优选地,对所述初始语言模型和所述行业领域语言模型进行概率加权计算,建立混合语言模型包括:
当初始文本语料中不包含词语组合wi-1wi且行业领域语料中包含词语组合wi-1wi时,按照以下公式(2)计算所述混合语言模型对应的条件概率:
p_mix(wi|wi-1)=p_new(wi|wi-1)(2)
其中,p_mix(wi|wi-1)表示所述混合语言模型对应的条件概率,wi-1和wi表示词语序列w中的两个相邻词语,w=w1w2…wn,1<i≤n,p_new(wi|wi-1)表示所述行业领域语言模型对应的条件概率。
优选地,所述基于处理后的行业领域语料进行音素聚类,根据音素聚类结果进行训练,建立聚类声学模型包括:
将所述专有名词词表中的专有名词的发音添加到所述专有名词词表中;
对所述专有名词的发音进行音素扩展;
针对音素扩展结果进行音素聚类;
基于音素聚类结果进行训练,建立聚类声学模型。
优选地,所述对所述初始声学模型和聚类声学模型进行融合,建立融合声学模型包括:
对所述初始声学模型和聚类声学模型进行转移概率的加权计算,建立融合声学模型。
优选地,对所述初始声学模型和聚类声学模型进行转移概率的加权计算,建立融合声学模型包括:
当所述初始声学模型和聚类声学模型中都包含状态转移a->b时,或者所述初始声学模型包含且所述聚类声学模型中不包含状态转移a->b时,按照以下公式(4)计算所述融合声学模型对应的转移概率:
p_ron(a->b)={xr*old_countr(a->b)+yr*new_countr(a->b)}/{xr*old_countr(a)+yr*new_countr(a)}(4)
其中,
xr=old_total_countr/(old_total_countr+new_total_countr),
yr=new_total_countr/(old_total_countr+new_total_countr),
其中,p_ron(a->b)表示所述融合声学模型对应的转移概率,a->b表示状态a转移到状态b,状态是指一个音素或者多个音素的聚类,xr、yr分别表示针对初始声学模型和聚类声学模型设置的加权系数,old_countr(a->b)表示在初始声学模型中a->b的转移频次,new_countr(a->b)表示在聚类声学模型中a->b的转移频次,old_countr(a)表示在所述初始音频语料中状态a出现的频次,new_countr(a)表示在所述音素聚类结果中状态a出现的频次,old_total_countr表示所述初始音频语料中的总状态数,new_total_countr表示所述音素聚类结果中的总状态数。
优选地,对所述初始声学模型和聚类声学模型进行转移概率的加权计算,建立融合声学模型包括:
当所述初始声学模型不包含且所述聚类声学模型中包含状态转移a->b时,按照以下公式(5)计算所述融合声学模型对应的转移概率:
p_ron(a->b)=p_newr(a->b)(5)
其中,p_ron(a->b)表示所述融合声学模型对应的转移概率,a->b表示状态a转移到状态b,状态是指一个音素或者多个音素的聚类,p_newr(a->b)表示所述聚类声学模型对应的转移概率。
优选地,所述基于所述融合声学模型和混合语言模型确定所述语音信号对应的词语序列包括:
求取概率p(w|x)最高时的词语序列w;
其中:
p(w|x)=argmax_wp(x|w)*p(w)
其中,x表示所述语音信号,w表示所述词语序列,p(x|w)表示所述融合声学模型对应的条件概率,p(w)表示所述混合语言模型对应的概率。
与现有技术相比,本发明实施例具有以下优点:
通过来自通用领域的初始语料和来自于特定行业领域的行业领域语料进行训练,分别建立适应于通用领域和行业领域的声学模型和语言模型,并对适应于不同领域的模型进行融合,从而实现能够适应于不同行业领域的语音识别方法。
使用少量行业领域数据,即可实现这些行业领域中的自适应语音识别,提高了语音识别方法在行业领域切换时的适应性和准确性,并能够达到实用标准。
附图说明
通过结合附图对本公开示例性实施方式进行更详细的描述,本公开的上述以及其它目的、特征和优势将变得更加明显,其中,在本公开示例性实施方式中,相同的参考标号通常代表相同部件。
图1显示根据本发明实施例的领域自适应语音识别方法的流程图;
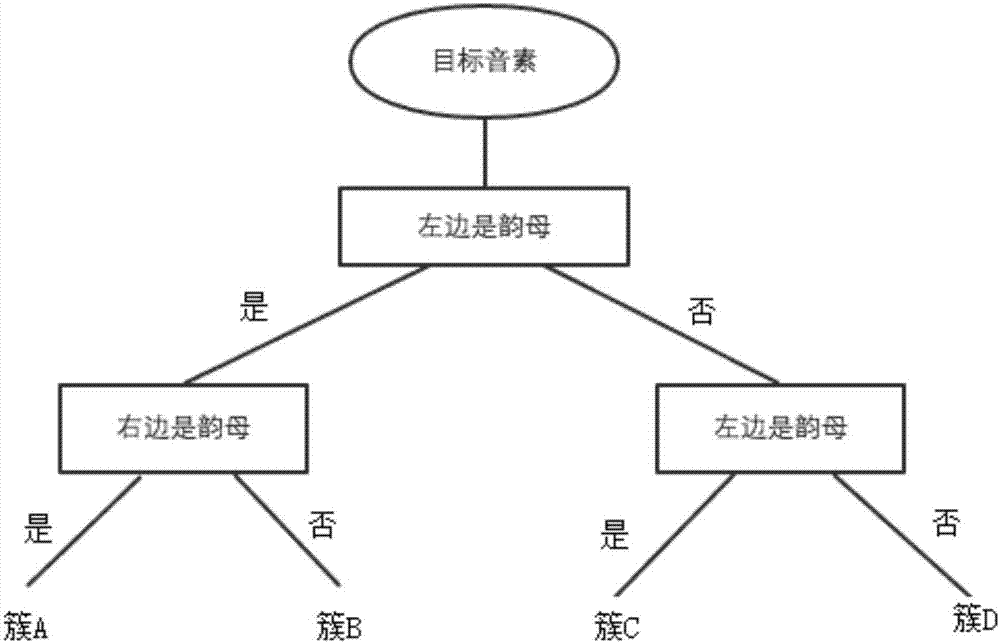
图2显示根据本发明实施例的音素聚类中选用的决策树模型的示意图;
图3显示根据本发明实施例的领域自适应语音识别装置的框图。
具体实施方式
下面将参照附图更详细地描述本公开的优选实施方式。虽然附图中显示了本公开的优选实施方式,然而应该理解,可以各种形式实现本公开而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
图1显示根据本发明实施例的领域自适应语音识别方法的流程图,如图1所示,该方法具体包括以下步骤:
步骤1:基于初始音频语料进行训练,建立初始声学模型,以及基于初始文本语料进行训练,建立初始语言模型
在执行实施例的领域自适应语音识别方法时,首先选择音频语料(也称初始音频语料),然后基于选择的音频语料进行训练,以建立初始声学模型。初始音频语料选自通用领域,通用领域指一般性的应用领域(例如日常生活领域),其是相对于专业的行业领域(例如化工行业、电子行业、金融行业等)而言。音频语料是音频数据文件,其包括音频信号。以下给出几个音频数据文件的示例:
声学模型是音频信号到文本形式的音素或音节的条件概率p(x|w),即给定文本形式的音素或音节w的条件下,发出音频信号x的概率。
在实施例中,选择训练语料之后,使用声学模型开源工具基于选择的训练语料进行训练,建立相应的声学模型。目前常用的声学模型开源工具包括htk、cmusphinx、kaldi等。以kaldi为例,将音频数据文件(wav)、标注文件(data.map.txt)、音素词典(lexicon.txt)存储于指定位置,然后运行训练命令run.sh,即可得到二进制的声学模型文件final.mdl。
基于训练语料通过声学模型开源工具建立声学模型是本领域的现有技术,在此不再对其细节进行展开解释。
在步骤1中,还基于初始文本语料进行训练,建立初始语言模型。在此,语言模型指由多个词语组合而成的句子能够语言成句的概率。
句子(即词语序列)w可以表示为n个词语w1、w2…wn的组合,即:
w=w1w2…wn,其中w1-wn分别表示一个词语。
则句子w的语言成句概率p(w)可以表示为:
p(w)=p(w1w2...wn)
根据n-gram语言模型或者dnn(deepneuralnetwork)模型,可以计算句子w的语言成句概率p(w)。在常用的n-gram模型中,认为第n个词的概率只依赖于前面n-1个词,而与其他任何词不相关。那么以n-gram模型的二元概率模型为例:
p(w1...wn)=p(w1)*p(w2|w1)*...*p(wn|wn-1)
其中,先验概率p(w1)可以通过以下公式计算得到:
p(w1)=conut(w1)/total_count
其中,conut(w1)表示词语w1在训练语料中出现的次数,total_count表示训练语料中的总词数。
条件概率p(wn|wn-1)可以通过以下公式计算得到:
p(wn|wn-1)=count(wn-1,wn)/count(wn-1)
其中,count(wn-1,wn)表示词语组合wn-1wn在训练语料中出现的次数,count(wn-1)表示词语wn-1在训练语料中出现的次数。
例如,选择的初始文本语料包括以下3个句子:
“把声音开大一点”
“声音大点”
“今天几号了”
则总词数total_conut为11
所计算的先验概率如下:
p(“把”)=count(“把”)/total_count=1/11
p(“声音”)=count(“声音”)/total_count=2/11
...
所计算的二元条件概率如下:
p(声音|把)=count(把声音)/count(把)=1/1=1
p(开|声音)=count(声音开)/count(声音)=1/2=0.5
...
步骤2:进行行业领域语料搜集和处理,并基于处理后的行业领域语料进行训练,得到行业领域语言模型
在实施例中,为使语音识别方法能够适应于特定的行业领域,通过以下步骤进行行业领域语料搜集和处理,并基于处理后的语料进行训练,得到行业领域语言模型:
步骤2.1搜集与行业领域相关的语料,从语料中提取句子文本和专有名词;
步骤2.2对专有名词进行分类整理,建立专有名词词表;
对提取的专有名词进行分类整理,从而建立专有名词词表。例如,可以通过人工方式对提取的专有名词进行分类整理,从而建立娱乐领域的人名词表,医疗领域的疾病名称词表等。
步骤2.3基于专有名词词表对句子文本进行专有名词标注和替换,以得到包含专有名词词表标记词的句子文本
基于获得的专有名词词表,使用模板匹配或序列标注算法,对提取的句子文本进行专有名词标注和替换,以得到包含专有名词词表标记词的句子文本。
对句子文本进行专有名词标注是指将句子文本中属于某个专有名词词表的词语用指示该专有名词词表的标记词进行标注。以模板匹配算法为例,使用模板“[人物]说相声”对于以下句子文本进行专有名词标注:
岳云鹏说相声
我喜欢听相声
郭德纲说相声
标注结果为:
[岳云鹏/n_per]说相声
[郭德纲/n_per]说相声
其中,“岳云鹏”、“郭德纲”是关于娱乐领域人名的专有名词词表中列举的专有名词,“n_per”是指示该专有名词词表的标记词。
然后,用上述标记词替换句子文本中被标注的专有名词,得到包含专有名词词表标记词的句子文本(也称为混合句子文本)。
例如,经过替换后,上述句子文本转换为:
n_per说相声
我喜欢听相声
n_per说相声
步骤2.4以包含专有名词词表标记词的句子文本作为训练语料进行训练,建立行业领域语言模型
以步骤2.3获得的包含专有名词词表标记的句子文本作为训练语料进行训练,训练后得到行业领域语言模型,行业领域语言模型特别适用于该行业领域。例如,可以基于步骤2.3获得的混合句子文本,计算先验概率p(n_per)、p(说),并计算条件概率p(说|n_ner)、p(相声|说)。
步骤3:基于初始语言模型和行业领域语言模型进行适配计算,建立混合语言模型
本步骤的目的是得到既能适用于通用领域、又能适用于特定行业领域的混合语言模型。
建立混合语言模型的方法有两种:第一种方法是数据混合方法,即将步骤1中的初始文本语料和步骤2中的混合句子文本混合起来作为训练语料,统一进行语言模型训练,从而得到混合语言模型。由于这样的训练语料既包括初始文本语料,又包括行业领域语料,因此经过训练之后的混合语言模型既能适用于通用领域、又能适用于行业领域。这种方法较容易理解,但并不是本发明的重点。
另一种方法是模型融合方法,即对步骤1的初始语言模型和步骤2的行业领域语言模型进行适配计算,从而建立混合语言模型。由于混合语言模型通过初始语言模型和行业领域语言模型的适配计算而获得,因此其既能适用于通用领域、又能适用于行业领域。
以下以n-gram语言模型为例,详细描述通过模型融合方法建立混合语言模型的过程,其是通过对初始语言模型和行业领域语言模型进行概率加权计算实现的。根据词语组合在不同语料中出现的情况,分别采用不同的概率加权算法计算混合语言模型对应的概率值,如下详述。
在步骤1中提到,对于n-gram模型,句子w的语言成句概率p(w)=p(w1)*p(w2|w1)*...*p(wn|wn-1)。对于其中的条件概率p(wi|wi-1),1<i≤n,在初始语言模型中,将其表示为:
p_old(wi|wi-1)=old_count(wi-1,wi)/old_cout(wi-1)
其中,p_old(wi|wi-1)表示初始语言模型中的条件概率,old_count(wi-1,wi)表示在初始文本语料中词语组合wi-1wi出现的次数,old_cout(wi-1)表示在初始文本语料中词语wi-1出现的次数。
在行业领域语言模型中,条件概率p(wi|wi-1)表示为:
p_new(wi|wi-1)=new_count(wi-1,wi)/new_count(wi-1)
其中,p_new(wi|wi-1)表示行业领域语言模型中的条件概率,new_count(wi-1,wi)表示在行业领域语料中词语组合wi-1wi出现的次数,new_cout(wi-1)表示在行业领域训练语料中词语wi-1出现的次数。
a.当初始文本语料和行业领域语料中都包含词语组合wi-1wi时,按照以下公式(1)进行初始语言模型和行业领域语言模型的概率加权计算,获得混合语言模型对应的条件概率:
p_mix(wi|wi-1)={xm*old_count(wi-1,wi)+ym*new_count(wi-1,wi)}/{xm*old_count(wi-1)+ym*new_count(wi-1)}(1)
其中,p_mix(wi|wi-1)表示混合语言模型对应的条件概率,xm、ym分别表示针对初始语言模型和行业领域语言模型设置的加权系数。
其中:
xm=old_total_count/(old_total_count+new_total_count),
ym=new_total_count/(old_total_count+new_total_count),
其中,old_total_count表示初始文本语料中的总词数,new_total_count表示行业领域语料中的总词数。
b.当初始文本语料不包含词语组合wi-1wi且行业领域语料包含词语组合wi-1wi时,按照以下公式(2)计算混合语言模型对应的条件概率:
p_mix(wi|wi-1)=p_new(wi|wi-1)(2)。
c.或者当初始文本语料中包含词语组合wi-1wi且行业领域语料中不包含词语组合wi-1wi时,按照以下公式(3)进行初始语言模型和行业领域语言模型的概率加权计算,获得混合语言模型对应的条件概率:
p_mix(wi|wi-1)={xm*old_count(wi-1,wi)+ym*new_count(wi-1,wi)}/{xm*old_count(wi-1)+ym*new_count(wi-1)}(3)
公式(3)的形式与公式(1)相同,在实际应用时也可以将这两种情况进行合并处理。
例如,如步骤1所述,初始文本语料包括以下3个句子:
“把声音开大一点”
“声音大点”
“今天几号了”
假设在步骤2中搜集的行业领域语料中包括以下3个句子:
“扁桃体发炎吃什么药”
“眼睛睁大一点”
“肚子不舒服”
那么按照以下方法计算混合语言模型对应的条件概率:
a.对于初始文本语料和行业领域语料中都包含的词语组合“大一点”,通过统计可知:
old_count(大一点)=1,
new_count(大一点)=1,
old_count(大)=2,
new_count(大)=1,
old_total_count=11,
new_total_count=12,
xm=11/(11+12)=0.48,ym=12/(11+12)=0.52
则对于混合语言模型,按照公式(1)计算条件概率如下:
p_mix(一点|大)=(0.48*1+0.52*1)/(0.48*2+0.52*1)=0.68
b.对于初始文本语料中不包含且行业领域语料中包含的词语组合“扁桃体发炎”,对于混合语言模型,按照公式(2)计算条件概率如下:
p(发炎|扁桃体)=count(扁桃体发炎)/count(扁桃体)=1/1=1
c.对于初始文本语料中包含且行业领域语料中不包含的词语组合“大点”,对于混合语言模型,按照公式(3)计算条件概率如下:
p(点|大)=(xm*old_count(大点)+ym*new_count(大点))/(xm*old_count(大)+ym*new_count(大))=(0.48*1+0.52*0)/(0.48*2+0.52*1)=0.32
步骤4:基于处理后的行业领域语料进行音素聚类,根据音素聚类结果进行训练,建立聚类声学模型
步骤4具体包括以下步骤:
步骤4.1将专有名词词表中的专有名词的发音添加到该专有名词词表中。
在步骤2中,已经从行业领域语料中提取专有名词并建立专有名词词表。在本步骤中,将专有名词词表中的专有名词的发音添加到对应的词表中,以进行声学词汇扩展,其中专有名词的发音包括其音节和声调。例如,将疾病名称对应的专有名词词表中的专有名词的发音添加到该专有名词词表中:
扁桃体bian3tao2ti3
发炎fa1yan2
步骤4.2对专有名词的发音进行音素扩展。
将专有名词的发音进行音素扩展,以获得该发音所对应的音素。操作过程中,通常进行单音素和三音素的音素扩展,例如在步骤4.1的示例中,经过音素扩展后可以得到:
单音素有:b、ian3、t、ao2等等;
三音素有:b-ian3-t、ian3-t-ao2、ao2-t-i3等等。
如果使用声学模型开源工具进行声学模型的训练,可以将音素扩展所获得的音素添加到音素词典中,以在后续训练中使用。
步骤4.3针对音素扩展结果进行音素聚类。
对步骤4.2获得的音素扩展结果进行音素聚类,进行音素聚类的方法很多,例如可用决策树的方法对其进行聚类,即针对专有名词词表中的专有名词的发音对应音素的所有状态都建立一个决策树模型。如果之前建立了多个专有名词词表,那么分别针对所建立的每个专有名词词表,对其中的专有名词的发音对应的音素进行音素聚类。
图2显示了针对步骤4.1和4.2中的示例建立的决策树模型。对于三音素ian3-t-ao2和ao2-t-i3,根据决策树模型按照以下过程进行音素聚类:
-目标音素:t
-判断,左边是否韵母。
-是,走左支路。
-判断,右边是否韵母。
-是,走左支路。
得到结果簇a,即ian3-t-ao2和ao2-t-i3均可归为一个状态。
进行音素聚类的作用在于通过将同类音素归为一类,可以避免模型参数过多的问题,提高模型的训练效率。
目前还有其他进行音素聚类的方法,其属于现有技术,在此不再赘述。
步骤4.4基于音素聚类结果进行训练,建立聚类声学模型。
根据上步结果,将多个音素聚类为一个状态。基于音素聚类结果,应用步骤1的方法进行训练,可以建立聚类声学模型。
步骤5:对初始声学模型和聚类声学模型进行融合,建立融合声学模型。
与步骤3的过程类似,对初始声学模型和聚类声学模型进行融合,调整状态间的转移概率,得到融合声学模型。
在步骤1中提到,声学模型是音频信号到文本形式的音素或音节的条件概率p(x|w),即给定文本形式的音素或音节w的条件下,发出音频信号x的概率。一般可基于现有模型(例如隐马尔科夫模型),利用现有的声学模型开源工具训练获得声学模型。在常用的现有模型中,条件概率p(x|w)是通过发射概率和转移概率获得的。在本步骤中,通过对初始声学模型和聚类声学模型进行融合,调整状态间的转移概率,来获得融合声学模型输出的条件概率p(x|w)。在本方法中,并不对发射概率进行调整。这里所说的“状态”对应于一个音素或者步骤4中的多个音素的聚类。
具体来说,对于融合声学模型,按照以下方法计算状态间的转移概率:
a.对于初始声学模型和聚类声学模型中都包含的状态转移a->b(状态a转移到状态b),按照以下公式(4)计算状态间的转移概率:
p_ron(a->b)={xr*old_countr(a->b)+yr*new_countr(a->b)}/{xr*old_countr(a)+yr*new_countr(a)}(4)
其中,p_ron(a->b)表示融合声学模型对应的转移概率,xr、yr分别表示针对初始声学模型和聚类声学模型设置的加权系数,old_countr(a->b)表示在初始声学模型中a->b的转移频次,new_countr(a->b)表示在聚类声学模型中a->b的转移频次,old_countr(a)表示在初始音频语料中状态a出现的频次,new_countr(a)表示在音素聚类结果中状态a出现的频次。
在公式(4)中:
xr=old_total_countr/(old_total_countr+new_total_countr),
yr=new_total_countr/(old_total_countr+new_total_countr),
其中,old_total_countr表示初始音频语料中的总状态数,new_total_countr表示音素聚类结果中的总状态数。
b.对于初始声学模型不包含且聚类声学模型中包含的状态转移a->b(状态a转移到状态b),按照以下公式(5)计算状态间的转移概率:
p_ron(a->b)=p_newr(a->b)(5)
其中,p_newr(a->b)表示聚类声学模型中状态转移a->b所对应的转移概率。
c.对于初始声学模型包含且聚类声学模型中不包含的状态转移a->b(状态a转移到状态b),按照以下公式(6)计算融合声学模型对应的转移概率:
p_ron(a->b)={xr*old_countr(a->b)+yr*new_countr(a->b)}/{xr*old_countr(a)+yr*new_countr(a)}(6)
示例:
初始声学模型的状态间的转移频次如下:
聚类声学模型的状态间的转移频次如下
a.对于聚类声学模型和初始声学模型都包含的状态转移“1->a”,通过统计可知:
old_countr(1->a)=6,
new_countr(1->a)=1,
old_countr(1)=10,
new_countr(1)=3,
old_total_countr=11,
new_total_countr=5,
xr=11/(11+5)=0.69,yr=5/(11+5)=0.31
则计算融合声学模型所对应的转移概率如下:
p_newr(1->a)=(0.69*6+0.31*1)/(0.69*10+0.31*5)=0.53
b.对于初始声学模型中不包含但聚类声学模型中包含的状态转移“2->1”,计算融合声学模型对应的转移概率如下:
p_newr(2->1)=count_newr(2->1)/count_newr(2)=1/1=1
c.对于聚类声学模型中不包含但初始声学模型中包含的状态转移“1->b”,计算融合声学模型对应的转移概率如下:
p_newr(1->b)=xr*count_newr(1->b)/(xr*count_oldr(1)+yr*count_newr(1))=0.69*2/(0.69*10+0.31*3)=0.18
获得融合声学模型对应的转移概率之后,即可根据转移概率计算条件概率p(x|w),这是本领域的现有技术,在此不再赘述。
步骤6:接收输入的语音信号,基于融合声学模型和混合语言模型确定语音信号对应的词语序列
当接收到输入的语音信号x时,基于融合声学模型和混合语言模型进行求解,即求取概率p(w|x)最高时的词语序列w,该词语序列w就是语音信号x对应的词语序列,其中:
p(w|x)=argmax_wp(x|w)*p(w)
其中,p(x|w)表示融合声学模型对应的条件概率,在常用的语音识别模型(例如隐含马尔科夫模型)中对应解码算法中的发射概率,p(w)表示混合语言模型对应的概率,对应语音识别模型解码算法中的转移概率。使用现有的解码算法,例如维特比解码算法,即可求出概率p(w|x)最高时的词语序列w,即输入的语音信号x对应的词语序列。
本发明实施例还提供一种领域自适应语音识别装置,如图3所示,包括:
初始建模模块301,用于基于初始音频语料进行训练,建立初始声学模型,以及用于基于初始文本语料进行训练,建立初始语言模型;
行业领域语言模型建模模块302,用于进行行业领域语料搜集和处理,基于处理后的行业领域语料进行训练,建立行业领域语言模型;
混合语言模型建模模块303,用于基于所述初始语言模型和所述行业领域语言模型进行适配计算,建立混合语言模型;
聚类声学模型建模模块304,用于基于处理后的行业领域语料进行音素聚类,根据音素聚类结果进行训练,建立聚类声学模型;
融合声学模型建模模块305,用于对所述初始声学模型和聚类声学模型进行融合,建立融合声学模型;
解码模块306,用于接收输入的语音信号,基于所述融合声学模型和混合语言模型确定所述语音信号对应的词语序列。
优选地,所述初始语言模型是二元n-gram语言模型。
优选地,所述进行行业领域语料搜集和处理,基于处理后的行业领域语料进行训练,建立行业领域语言模型包括:
搜集与所述行业领域相关的语料,从所述语料中提取句子文本和专有名词;
对所述专有名词进行分类整理,建立专有名词词表;
基于所述专有名词词表对所述句子文本进行专有名词标注和替换,得到包含专有名词词表标记词的句子文本;
以所述包含专有名词词表标记词的句子文本作为训练语料进行训练,建立行业领域语言模型。
优选地,所述基于所述初始语言模型和所述行业领域语言模型进行适配计算,建立混合语言模型包括:
对所述初始语言模型和所述行业领域语言模型进行概率加权计算,建立混合语言模型。
优选地,对所述初始语言模型和所述行业领域语言模型进行概率加权计算,建立混合语言模型包括:
当初始文本语料和行业领域语料中都包含词语组合wi-1wi时,或者当初始文本语料中包含词语组合wi-1wi且行业领域语料中不包含词语组合wi-1wi时,按照以下公式(1)计算所述混合语言模型对应的条件概率:
p_mix(wi|wi-1)={xm*old_count(wi-1,wi)+ym*new_count(wi-1,wi)}/{xm*old_count(wi-1)+ym*new_count(wi-1)}(1)
其中,
xm=old_total_count/(old_total_count+new_total_count),
ym=new_total_count/(old_total_count+new_total_count),
其中,p_mix(wi|wi-1)表示所述混合语言模型对应的条件概率,wi-1和wi表示词语序列w中的两个相邻词语,w=w1w2…wn,1<i≤n,xm、ym分别表示针对所述初始语言模型和所述行业领域语言模型设置的加权系数,old_count(wi-1,wi)表示在所述初始文本语料中词语组合wi-1wi出现的次数,old_cout(wi-1)表示在所述初始文本语料中词语wi-1出现的次数,new_count(wi-1,wi)表示在所述行业领域语料中词语组合wi-1wi出现的次数,new_cout(wi-1)表示在所述行业领域语料中词语wi-1出现的次数,old_total_count表示所述初始文本语料中的总词数,new_total_count表示所述行业领域语料中的总词数。
优选地,对所述初始语言模型和所述行业领域语言模型进行概率加权计算,建立混合语言模型包括:
当初始文本语料中不包含词语组合wi-1wi且行业领域语料中包含词语组合wi-1wi时,按照以下公式(2)计算所述混合语言模型对应的条件概率:
p_mix(wi|wi-1)=p_new(wi|wi-1)(2)
其中,p_mix(wi|wi-1)表示所述混合语言模型中的条件概率,wi-1和wi表示词语序列w中的两个相邻词语,w=w1w2…wn,1<i≤n,p_new(wi|wi-1)表示所述行业领域语言模型中的条件概率。
优选地,所述基于处理后的行业领域语料进行音素聚类,根据音素聚类结果进行训练,建立聚类声学模型包括:
将所述专有名词词表中的专有名词的发音添加到所述专有名词词表中;
对所述专有名词的发音进行音素扩展;
针对音素扩展结果进行音素聚类;
基于音素聚类结果进行训练,建立聚类声学模型。
优选地,所述对所述初始声学模型和聚类声学模型进行融合,建立融合声学模型包括:
对所述初始声学模型和聚类声学模型进行转移概率的加权计算,建立融合声学模型。
优选地,对所述初始声学模型和聚类声学模型进行转移概率的加权计算,建立融合声学模型包括:
当所述初始声学模型和聚类声学模型中都包含状态转移a->b时,或者所述初始声学模型包含且所述聚类声学模型中不包含状态转移a->b时,按照以下公式(4)计算所述融合声学模型对应的转移概率:
p_ron(a->b)={xr*old_countr(a->b)+yr*new_countr(a->b)}/{xr*old_countr(a)+yr*new_countr(a)}(4)
其中,
xr=old_total_countr/(old_total_countr+new_total_countr),
yr=new_total_countr/(old_total_countr+new_total_countr),
其中,p_ron(a->b)表示所述融合声学模型对应的转移概率,a->b表示状态a转移到状态b,状态是指一个音素或者多个音素的聚类,xr、yr分别表示针对初始声学模型和聚类声学模型设置的加权系数,old_countr(a->b)表示在初始声学模型中a->b的转移频次,new_countr(a->b)表示在聚类声学模型中a->b的转移频次,old_countr(a)表示在所述初始音频语料中状态a出现的频次,new_countr(a)表示在所述音素聚类结果中状态a出现的频次,old_total_countr表示所述初始音频语料中的总状态数,new_total_countr表示所述音素聚类结果中的总状态数。
优选地,对所述初始声学模型和聚类声学模型进行转移概率的加权计算,建立融合声学模型包括:
当所述初始声学模型不包含且所述聚类声学模型中包含状态转移a->b时,按照以下公式(5)计算所述融合声学模型对应的转移概率:
p_ron(a->b)=p_newr(a->b)(5)
其中,p_ron(a->b)表示所述融合声学模型对应的转移概率,a->b表示状态a转移到状态b,状态是指一个音素或者多个音素的聚类,p_newr(a->b)表示所述聚类声学模型对应的转移概率。
优选地,基于所述融合声学模型和混合语言模型确定所述语音信号对应的词语序列包括:
求取概率p(w|x)最高时的词语序列w;
其中:
p(w|x)=argmax_wp(x|w)*p(w)
其中,x表示所述语音信号,w表示所述词语序列,p(x|w)表示所述融合声学模型对应的条件概率,p(w)表示所述混合语言模型对应的概率。
以上对本发明所提供的方法和装置进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!