一种基于语音识别引擎的AR界面交互方法及系统与流程
本发明涉及ar技术领域,具体的涉及一种基于语音识别引擎的ar界面交互方法及系统。
背景技术:
现有的关于增强现实技术(augmentedreality,简称ar)方面的游戏的玩法是玩家通过操作设备界面上的按钮来执行对虚拟角色的行为操作,而这种玩法无法快速达到指挥ar界面上虚拟物体的目的;同时,现有的语音识别技术对大词汇量的识别无法达到很高的识别精度,而在ar游戏中,是不能容许语音指令的出现较高的误检率的,如果出现较高的误检率会降低游戏的可玩性。
技术实现要素:
本发明所要解决的技术问题是提供一种基于语音识别引擎的ar界面交互方法及系统,解决了现有增强现实技术对玩家的语音无法进行识别的问题,不仅能提高ar游戏应用的可玩性,也丰富了人与虚拟现实之间的互动,增强了ar技术产品的趣味性。
本发明解决上述技术问题的技术方案如下:一种基于语音识别引擎的ar界面交互方法,包括以下步骤,
s1,利用语音识别引擎生成语音指令;
s2,识别ar界面中虚拟物体的坐标位置,并使所述ar界面中的虚拟物体在所述坐标位置处根据所述语音指令执行相应的交互行为。
本发明的有益效果是:本发明一种基于语音识别引擎的ar界面交互方法利用语音识别引擎生成语音指令;识别ar界面中虚拟物体的坐标位置,并使所述ar界面中的虚拟物体在所述坐标位置处根据所述语音指令执行相应的交互行为;该方法解决了现有增强现实技术对玩家的语音无法进行识别的问题,丰富了ar应用中人与游戏的交互性,不仅可以通过图片与虚拟物体进行交互,还能通过语音达到对虚拟物体一定行为的控制功能,增强了ar游戏的趣味性与可玩性。
在上述技术方案的基础上,本发明还可以做如下改进。
进一步,所述s1具体为,
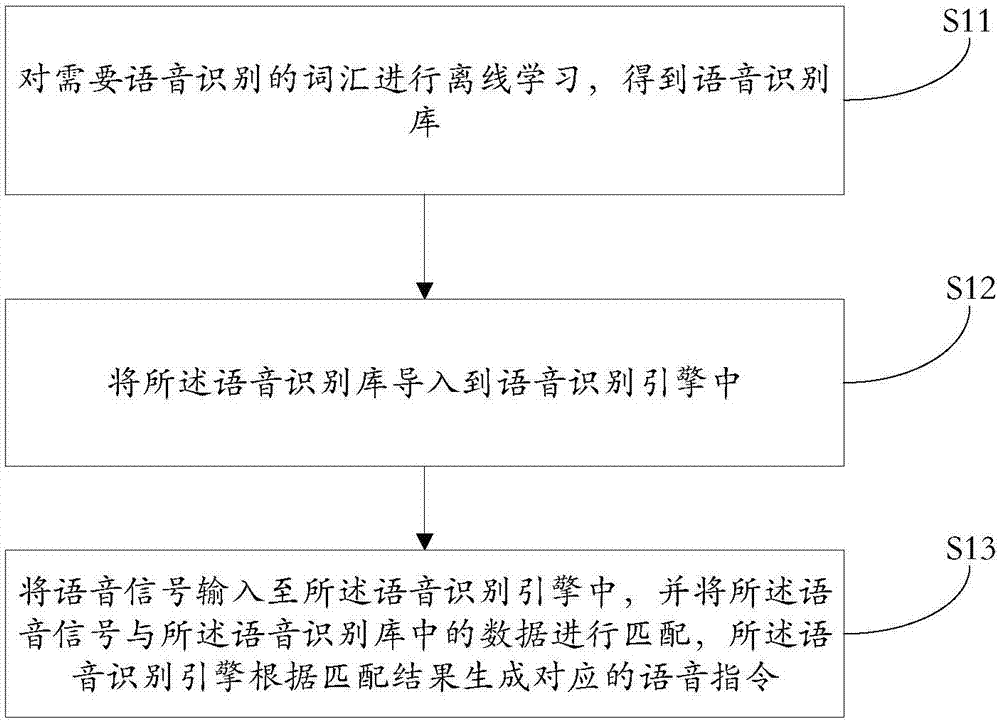
s11,对需要语音识别的词汇进行离线学习,得到语音识别库;
s12,将所述语音识别库导入到语音识别引擎中,
s13,将语音信号输入至所述语音识别引擎中,并将所述语音信号与所述语音识别库中的数据进行匹配,所述语音识别引擎根据匹配结果生成对应的语音指令。
进一步,所述s11具体为,
s111,对需要语音识别的词汇进行标准发音,生成指令音频文件;
s112,通过语音识别引擎离线学习工具对所述指令音频文件进行训练,并提取所述指令音频文件中的特征信息,生成指令文本文件;
s113,对所述指令文本文件进行统计,并提取不同指令文本文件之间先后发生的统计关系;
s114,根据所述统计关系构建语音识别模型,并输出语音识别模型的初始精度参数,
s115,利用参数精度参数对所述语音识别模型进行反复测试,并根据测试结果调节所述初始精度参数,得出最终精度参数;
s116,将所述最终精度参数与所述语音识别模型结合生成语音识别库。
采用上述进一步方案的有益效果是:本发明一种基于语音识别引擎的ar界面交互方法基于语音识别引擎,先对需要离线学习的语音指令的音频文件进行反复的训练和对识别参数的反复调试,以获取到高准确率的语音识别库,提高语音识别的精度。
进一步,所述语音识别引擎是基于pocketsphinx语音识别系统开发。
采用上述进一步方案的有益效果是:基于pocketsphinx语音识别系统开发的语音识别引擎是一个计算量和体积都很小的语音识别引擎,它对小词汇量的识别精度是很高的,并且对性能的销毁很小,反应很快,可以进一步解决现有增强现实技术对玩家的语音无法进行识别的问题。
进一步,在所述s13中,将所述语音信号与所述语音识别库中的数据进行匹配前还包括:对所述语音信号进行过滤处理。
采用上述进一步方案的有益效果是:对语音信号进行过滤处理后再与语音识别库中的数据进行匹配,可以去除语音信号中的噪声,避免干扰,提高匹配的准确率。
基于上述一种基于语音识别引擎的ar界面交互方法,本发明还提供一种基于语音识别引擎的ar界面交互系统。
一种基于语音识别引擎的ar界面交互系统,包括语音识别引擎和ar引擎,
所述语音识别引擎,其用于生成语音指令;
所述ar引擎,其用于识别ar界面中虚拟物体的坐标位置,并使所述ar界面中的虚拟物体在所述坐标位置处根据所述语音指令执行相应的交互行为。
本发明的有益效果是:本发明一种基于语音识别引擎的ar界面交互系统将语音信号在语音识别引擎中生成语音指令并传送到ar引擎中,通过结合ar引擎识别追踪得到ar界面中虚拟物体的坐标位置,对ar界面中虚拟物体进行相应的行为控;该方法解决了现有增强现实技术对玩家的语音无法进行识别的问题,丰富了ar应用中人与游戏的交互性,不仅可以通过图片与虚拟物体进行交互,还能通过语音达到对虚拟物体一定行为的控制功能,增强了ar游戏的趣味性与可玩性。
在上述技术方案的基础上,本发明还可以做如下改进。
进一步,所述语音识别引擎具体用于,
对需要语音识别的词汇进行离线学习,得到语音识别库;
将所述语音识别库导入到语音识别引擎中,
将语音信号输入至所述语音识别引擎中,并将所述语音信号与所述语音识别库中的数据进行匹配,所述语音识别引擎根据匹配结果生成对应的语音指令。
进一步,所述语音识别引擎具体用于,
对需要语音识别的词汇进行标准发音,生成指令音频文件;
通过语音识别引擎离线学习工具对所述指令音频文件进行训练,并提取所述指令音频文件中的特征信息,生成指令文本文件;
对所述指令文本文件进行统计,并提取不同指令文本文件之间先后发生的统计关系;
根据所述统计关系构建语音识别模型,并输出语音识别模型的初始精度参数,
利用参数精度参数对所述语音识别模型进行反复测试,并根据测试结果调节所述初始精度参数,得出最终精度参数;
将所述最终精度参数与所述语音识别模型结合生成语音识别库。
采用上述进一步方案的有益效果是:本发明一种基于语音识别引擎的ar界面交互系统基于语音识别引擎,先对需要离线学习的语音指令的音频文件进行反复的训练和对识别参数的反复调试,以获取到高准确率的语音识别库,提高语音识别的精度。
进一步,所述语音识别引擎是基于pocketsphinx语音识别系统开发。
采用上述进一步方案的有益效果是:基于pocketsphinx语音识别系统开发的语音识别引擎是一个计算量和体积都很小的语音识别引擎,它对小词汇量的识别精度是很高的,并且对性能的销毁很小,反应很快,可以进一步解决现有增强现实技术对玩家的语音无法进行识别的问题。
进一步,在所述语音识别引擎中,将所述语音信号与所述语音识别库中的数据进行匹配前还包括:对所述语音信号进行过滤处理。
采用上述进一步方案的有益效果是:对语音信号进行过滤处理后再与语音识别库中的数据进行匹配,可以去除语音信号中的噪声,避免干扰,提高匹配的准确率。
附图说明
图1为本发明一种基于语音识别引擎的ar界面交互方法的整体流程图;
图2为本发明一种基于语音识别引擎的ar界面交互方法中生成语音指令的流程图;
图3为本发明一种基于语音识别引擎的ar界面交互方法中对需要语音识别的词汇进行离线学习得到语音识别库的流程图;
图4为本发明一种基于语音识别引擎的ar界面交互系统的结构框图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
如图1所示,一种基于语音识别引擎的ar界面交互方法,包括以下步骤,
s1,利用语音识别引擎生成语音指令;
s2,识别ar界面中虚拟物体的坐标位置,并使所述ar界面中的虚拟物体在所述坐标位置处根据所述语音指令执行相应的交互行为。
在本具体实施例中,所述s1具体为,如图2所示,
s11,对需要语音识别的词汇进行离线学习,得到语音识别库;
s12,将所述语音识别库导入到语音识别引擎中,
s13,将语音信号输入至所述语音识别引擎中,并将所述语音信号与所述语音识别库中的数据进行匹配,所述语音识别引擎根据匹配结果生成对应的语音指令。
在本具体实施例中,所述s11中,对需要语音识别的词汇进行离线学习得到语音识别库的具体步骤为,如图3所示,
s111,对需要语音识别的词汇进行标准发音,生成指令音频文件;
s112,通过语音识别引擎离线学习工具对所述指令音频文件进行训练,并提取所述指令音频文件中的特征信息,生成指令文本文件;
s113,对所述指令文本文件进行统计,并提取不同指令文本文件之间先后发生的统计关系;
s114,根据所述统计关系构建语音识别模型,并输出语音识别模型的初始精度参数,
s115,利用参数精度参数对所述语音识别模型进行反复测试,并根据测试结果调节所述初始精度参数,得出最终精度参数;
s116,将所述最终精度参数与所述语音识别模型结合生成语音识别库。
在本具体实施例中,所述语音识别引擎是基于pocketsphinx语音识别系统开发。
在本具体实施例中,在所述s13中,将所述语音信号与所述语音识别库中的数据进行匹配前还包括对所述语音信号进行过滤处理。
下面对本发明一种基于语音识别引擎的ar界面交互方法以ar游戏为例进行说明。
具体的例如:
利用本发明的方法开发的一款ar游戏应用中,可以实现对玩家的士兵进行简单指挥操作的功能,依次为命令士兵优先攻击前方的敌人,优先攻击左边的敌人,优先攻击右边的敌人,向后防御这4条指令,而拿着ar道具(如开发的玩具枪)体验ar游戏的玩家无法快速的通过手动的操作移动端的相应按钮来达到指挥的士兵功能。利用本发明的方法开发的语音识别引擎可以快速精确的响应向前攻击,向左攻击,向右攻击,向后防御这4条简单的语音指令,做到这一点就需要,先通过测试人员对语音指令的词汇的进行标准发音,生成指令音频文件;通过语音识别引擎离线学习工具对所述指令音频文件进行训练,并提取所述指令音频文件中的特征信息,生成指令文本文件;对所述指令文本文件进行统计,并提取不同指令文本文件之间先后发生的统计关系;根据所述统计关系构建语音识别模型,并输出语音识别模型的初始精度参数,利用参数精度参数对所述语音识别模型进行反复测试,并根据测试结果调节所述初始精度参数,得出最终精度参数;将所述最终精度参数与所述语音识别模型结合生成语音识别库。
把学习得到语音识别库导入到语音识别引擎中,从而实现对人发出的语音指令进行识别的功能;其具体方法是玩家标准的说出对应的语音指令如向前攻击,移动设备获取到相应的音频数据,输入到语音识别引擎中去,进行去燥等相应的过滤处理后,把音频数据与语音识别库里的数据做匹配,得到匹配结果后传送到ar引擎中,通过ar引擎对其做响应。
ar系统通过对指定图片的识别追踪可以稳定的获取到虚拟物体向现实世界中的位置信息,语音识别引擎传入的语音识别结果进行分析判断后转化为对游戏士兵的指挥操作指令。
本发明的方法使得增强现实技术获得了语音识别功能系统,增强人与虚拟现实之间的互动,增强了ar游戏的趣味性和可玩性;如玩家在拿着玩具枪体验ar游戏时,不再需要像传统游戏那样,必须通过操作移动端界面上的按钮来执行对虚拟角色的行为操作,而是通过自身的移动与语音指令来执行对ar游戏中虚拟角色的行为操作。
基于上述一种基于语音识别引擎的ar界面交互方法,本发明还提供一种基于语音识别引擎的ar界面交互系统。
如图4所示,一种基于语音识别引擎的ar界面交互系统,包括语音识别引擎和ar引擎,
所述语音识别引擎,其用于生成语音指令;
所述ar引擎,其用于识别ar界面中虚拟物体的坐标位置,并使所述ar界面中的虚拟物体在所述坐标位置处根据所述语音指令执行相应的交互行为。
在本具体实施例中,所述语音识别引擎具体用于,
对需要语音识别的词汇进行离线学习,得到语音识别库;
将所述语音识别库导入到语音识别引擎中,
将语音信号输入至所述语音识别引擎中,并将所述语音信号与所述语音识别库中的数据进行匹配,所述语音识别引擎根据匹配结果生成对应的语音指令。
在本具体实施例中,所述语音识别引擎具体用于,
对需要语音识别的词汇进行标准发音,生成指令音频文件;
通过语音识别引擎离线学习工具对所述指令音频文件进行训练,并提取所述指令音频文件中的特征信息,生成指令文本文件;
对所述指令文本文件进行统计,并提取不同指令文本文件之间先后发生的统计关系;
根据所述统计关系构建语音识别模型,并输出语音识别模型的初始精度参数,
利用参数精度参数对所述语音识别模型进行反复测试,并根据测试结果调节所述初始精度参数,得出最终精度参数;
将所述最终精度参数与所述语音识别模型结合生成语音识别库。
在本具体实施例中,所述语音识别引擎是基于pocketsphinx语音识别系统开发。
在本具体实施例中,在所述语音识别引擎中,将所述语音信号与所述语音识别库中的数据进行匹配前还包括:对所述语音信号进行过滤处理。
本发明一种基于语音识别引擎的ar界面交互系统将语音信号在语音识别引擎中生成语音指令并传送到ar引擎中,通过结合ar引擎识别追踪得到ar界面中虚拟物体的坐标位置,对ar界面中虚拟物体进行相应的行为控;该方法解决了现有增强现实技术对玩家的语音无法进行识别的问题,丰富了ar应用中人与游戏的交互性,不仅可以通过图片与虚拟物体进行交互,还能通过语音达到对虚拟物体一定行为的控制功能,增强了ar游戏的趣味性与可玩性。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!