一种基于倍频程信号强度和差异化特征子集的情感语音识别方法与流程
本发明涉及语音识别技术领域,具体说是涉及一种基于倍频程信号强度和差异化特征子集的情感语音识别方法。
背景技术:
1997年,picard发表《情感计算》,标志着情感计算学科正式建立。在《情感计算》中,pichard提出情感计算是与情感相关,且来源于情感或能够对情感施加影响的计算。情感计算研究包括了情感信息的采集与建模、情感的分析和识别、情感理解及情感表达等方面。情感计算自提出后受到了众多专家学者的重视,其研究涉及到统计学、机器学习、模式识别、心理学等多个学科。情感计算对于研究人类情感的各种特性及情绪变化十分重要,同时也促进了不同学科之间的共同发展。情感识别是情感计算的一个重要分支,其研究对于推动情感计算的发展有着重要意义。
语音作为使用频率最高的交流方式,对其进行情感识别的研究一直是领域内研究的重点。
情感语音识别以情感变化与人类语音之间关系为基础,使用计算机对语音信号的特征参数进行提取和分析,最终获取语音信息中所包含情感信息。传统的语音信号分析偏重分析语义,而忽略了语音信号中蕴含的丰富的情感信息。随着情感语音识别技术的发展,对语音信号进行情感识别的技术正在悄然兴起,例如服务机器人,其根据采集到的语音信号、图像信号以及生理信号,对服务对象的情感状态做出实时合理的识别,从而有针对性的提供服务,提高使用满意度。再如,对于承担克服工作的人员由于长期面对客户的电话咨询、投诉,容易产生烦躁的情绪,进而导致工作效率降低,利用语音情感识别技术即可实现对客服人员的情绪状态进行实时监控和分析,作为及时疏导的依据。再如在远程教育平台上应用语音情感识别,对学生的实时情感状态进行监控,便于授课者调整授课方式和时间,以保证授课效率和质量。可见,随着情感语音识别的深入研究,伴随着其理论和人工智能等相关技术的不断发展,情感语音识别将会给人们生产、生活带来极大地便利。因此,研究情感语音识别具有较为重要的意义。
目前语音识别领域中常用以恒定带宽的频程划分为基础,对音频信号进行研究,但这种方法并不适用于情感语音识别,而对语音特征提取不合理,导致情感语音识别准确性不高。因此,亟待寻找一种兼顾效率与可靠性的情感语音识别方法,满足日益增长的使用需求。
技术实现要素:
鉴于已有技术存在的不足,本发明的目的是要提供一种基于倍频程信号强度和差异化特征子集的情感语音识别方法,以实现情感语音的准确识别。
为了实现上述目的,本发明技术方案如下:
一种基于倍频程信号强度和差异化特征子集的情感语音识别方法,其特征在于,步骤包括:
s1对给定语音情感数据集x进行特征提取,以得到原始情感特征集合f,所述原始情感特征集合f对应的情感集合为s,特征提取对象至少包括obsi特征参数及obsir特征参数;
s2利用给定语音情感数据集x的测试集计算特征集合f中每一个特征的fisher分数,根据fisher分数值从小到大对特征进行排名,并使用svm作为分类器,对测试集fisher分数排名在特征总数前10%的特征组成的特征集合使用序列前向选择方法得到区分情感集合s中每一个情感ei与其它情感other的最优特征子集d(ei,other);
s3使用d(ei,other)在部分样本中进行训练识别,得到每种情感的区分度d(ei),所述情感区分度d(ei)表示在训练集中,使用特征子集d(ei,other)对ei和other进行识别的平均识别率;
s4根据情感区分度d(ei)对情感集合s中的情感类型按从大到小的顺序进行排列,得到有序情感集合s;
s5根据有序情感集合s中各情感的顺序,构建svm-rf多级分类器,所述svm-rf分类器包括级联连接且与特征子集一一对应的子分类器,并利用各特征子集实现svm-rf多级分类器训练;
s7利用svm-rf多级分类器模型对测试情感语音进行分类测试,并输出分类结果。
与现有技术相比,本发明的有益效果:
(1)本发明基于情感语音识别领域的obsi特征,针对svm和rf优点提出一种基于特征选择的svm-rf多级分类器构建算法,根据情感的实际区分度,使用若干个一对多的二分类svm先对较为容易区分的情感进行区分,而对于其中较难区分的情感使用rf进行识别。
(2)本发明在svm-rf多级分类器训练时,对子分类器的特征子集采取差异化策略,最终使svm-rf能够可以用少于rf模型的训练时间,达到与rf近乎相同的性能。通过实验验证了svm-rf多级语音分类器构以较少的模型训练时间,获得了接近rf的识别性能。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明情感语音识别方法流程图;
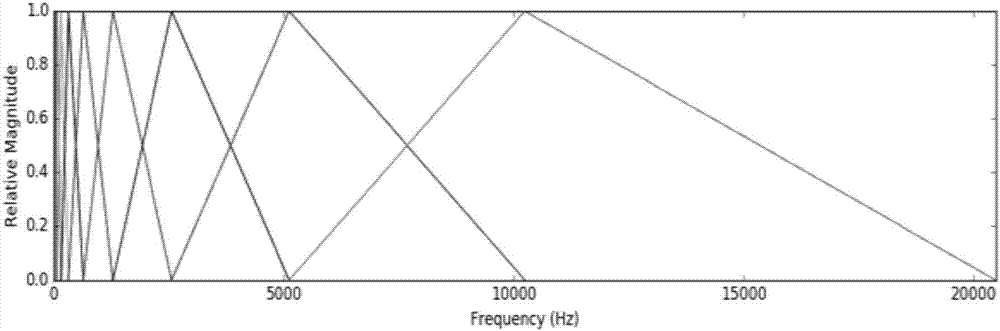
图2为本发明倍频程滤波器组频率响应示意图;
图3为本发明obsi和obsir特征参数计算流程图;
图4为本发明svm-rf改进算法的原理示意图;
图5为本发明实施例svm-rf多级分类器结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明对应的技术原理说明:在声学测量中,对信号做实际频谱分析时,无需采集测量频率范围内的每一个频率点数据,常规做法是将频率范围划分成若干频率段,这样每一个频带被称为一个频程。频程的划分方法有如下两种。一种是恒定带宽,也就是每个频程的带宽相同的;另外一种是恒定带宽比的划分方式,每个频程上下限频率之比为常数。当声压级不变而频率提高一倍时,听起来音调也提高一倍。
倍频程的频带划分方式采用恒定带宽比的形式,本文使每一个频程的上限频率fu是下限频率fl的4倍,即fu=4fl。每个频程的中心频率fc,它与fu和fl的关系如式:
本发明虑到情感语音信号的能量分布情况,提出针对情感语音的
obsi特征的子频带的划分策略。
下面基于上述原理并结合附图以及具体实施例进一步说明本发明的技术方案:
如图1所示为一种基于倍频程信号强度和差异化特征子集的情感语音识别方法,步骤包括:
s1对给定语音情感数据集x进行特征提取,以得到原始情感特征集合f,其情感集合为s,特征提取对象至少包括obsi特征参数及obsir特征参数,还可包括韵律学特征、谱特征等特征,特征提取的步骤包括:
s11对语音信号做至少包括预加重和分帧的预处理,预处理后时域语音信号为xi(n),其中i表示帧序号。
在本发明中,与提取其它语音情感特征相同,首先需要对语音信号进行预加重、分帧做加汉明窗处理等预处理的步骤。预加重是为了对语音信号的高频部分进行加重,以去除口唇辐射的影响,提升语音信号的高频部分。分帧是由于语音是一个非平稳的随机过程,只具有短时平稳性,因此任何语音信号的分析处理都必须建立在短时的基础上。
s12对时域语音信号xi(n)做傅里叶变换可得频域语音信号:
xi(k)=fft[xi(n)](1)。
本发明中对适于语音信号进行傅里叶变换以便后续对情感语音信号的频谱能量进行分析。
s13计算频域语音信号每一帧的频谱能量,计算公式为:
e(i)=|xi(k)|2(2)。
s14将频域语音信号通过由m个三角滤波器构成的倍频程滤波器组,得到每个滤波器的频率响应。
作为本发明中,采用各频带中心频率满足
同时,考虑到人耳可听的频率范围是20hz到20000hz,所以在语音信号处理时可以忽略掉可听频率范围之外的音频分量,因此,作为本发明的优选实施方案,所用倍频滤波器组根据人耳听觉频率范围对各滤波器的频率范围进行划分,相邻子频带的频率范围重叠半个频程,相邻两个频带中心频率同样满足两倍的比例关系。
本发明以人耳可听频率的起始频率20hz作为倍频程滤波器组中第一个滤波器的起始频率,采用倍频程的划分方式,各频带的带宽是不同的,低频部分带宽小一些,而高频部分的带宽相对较大。这样的划分方式也符合人的声音在高频部分的携带信息相对较少的特点,在语音情感分析时对低频部分进行详细描述,高频部分粗略描述。本文根据相邻子频带重叠半个频程的原则,对相邻滤波器的频率范围进行划分,相邻滤波器频率范围重叠半个频程,第一滤波器下限频率为20hz、中心频率为40hz、上限频率为80hz,则第m个滤波器的中心频率可根据以下公式计算:
f(m)=2m-1f(1)=40×2m-1(1≤m≤m)(3)
本发明倍频滤波器组子频带频率范围如表1所示:
表1倍频程子频带中心频率和频率范围
根据人耳听觉特性对人耳可听频率范围进行划分得到9个相邻重叠的子频带。对于发明改进频带划分方式以适应情感语音的obsi频程频带信号强度(octavebandsignalintensities,obsi)及其衍生特征倍频程频带信号强度比(octavebandsignalintensitiesratio,obsir)。
所述倍频滤波器组中,第m个滤波器频率响应hm(k)根据以下公式得出:
如图2所示为根据上式计算处的每个滤波器的响应结果。
s15根据每个滤波器的频率响应计算语音信号的obsi特征参数和obsir特征参数。计算语音信号的obsi特征参数和obsir特征参数的步骤包括:
1)计算每个滤波器输出的对数能量,其中第m个滤波器输出的对数能量为s(m),计算公式如下:
上述各滤波器输出的对数能量即为obsi特征参数:
obsi(m)=s(m),1≤m≤m(6);
2)计算语音信号各滤波器频带上的能量e(m),计算公式如下:
其中,n为语音信号分帧的帧长;
3)计算相邻滤波器频带上的能量比ratio(m):
其中e(m-1)为第m-1个子频带的能量。
上述各能量比的对数即为obsir特征参数,即:
obsir(m)=ln(e(m)),1<m≤m(9)。
由前面的子频带划分情况可以得出obsi特征有9个特征参数,而由obsi和obsir的关系可得,obsir特征有8个特征参数。如图3所示为obsi和obsir特征参数的计算流程过程。
s2利用给定语音情感数据集x的测试集计算特征集合f中每一个特征的fisher分数,根据fisher分数值从小到大对特征进行排名,并使用svm作为分类器,对测试集fisher分数排名在特征总数前10%的特征组成的特征集合使用序列前向选择方法得到区分情感集合s中每一个情感ei与其它情感other的最优特征子集d(ei,other)。
s3使用d(ei,other)在部分样本中进行训练识别,得到每种情感的区分度d(ei),所述情感区分度d(ei)表示在训练集中,使用特征子集d(ei,other)对ei和other进行识别的平均识别率;
s4根据情感区分度d(ei)对情感集合s中的情感类型按从大到小的顺序进行排列,得到有序情感集合s;
s5根据有序情感集合s中各情感的顺序,构建svm-rf多级分类器,所述svm-rf分类器包括级联连接且与特征子集一一对应的子分类器,并利用各特征子集实现svm-rf多级分类器训练;
常规分类算法众多,其中比较适宜语音情感分类的算法包括支持向量机(svm)和随机森里(rf)。从支持向量机和随机森林在常用情感数据库上识别表现来看,随机森林相对更佳,但由于其本身是一种集成学习方法,从结构上来看它由许多基分类器构成,这导致其在训练模型时,要比支持向量机耗费更长的时间。本发明给出了一种结合svm和rf优点的svm-rf改进多分类器构建算法,如图4所示,为本发明svm-rf的改进算法的原理示意,其主要思路:采用若干一对多的二分类svm,用于区分已有情感中相对较为容易区分的情感,而对于其中较难区分的情感则使用rf进行识别。在svm-rf算法中,给出一种训练子分类器的特征子集差异化策略,其目的使svm-rf能够可以用少于单纯rf模型的训练时间,而达到接近rf的识别性能。
本发明在构建svm-rf多级分类器时,首先利用本发明特征选择算法,对原始特征集合进行特征选择,然后构建区分不同情感的最优特征子集,进而对情感的区分度进行评估。本发明中,情感区分度定义如下:对于两类情感ei和ej,若原始特征集合f中区分它们的最优特征子集为d(ei,ej),则定义ei和ej的情感区分度表示在训练集中,使用特征子集d(ei,ej)对ei和ej进行识别的平均识别率。作为本发明较佳的实施方式,svm-rf多级分类器中的svm子分类器采用一对多的方式,因此要对数据库所有情感中的每一种情感区分度进行评估,在评估每一种情感ei的区分度时,将其它所有情感视为一类,记为other,则情感ei的区分度d(ei)实际上为d(ei,other)。而不将svm直接在训练集上对所有情感进行分类得到识别率作为每种情感的区分度的原因是,通过这种方式得到的情感区分度,会因为没有使用针对具体分类任务的最优特征子集,而导致情感区分度结果上存在差别,继而会影响到后续多级分类器中的子分类器构建顺序。
获得最优特征子集后,计算一对多形式下不同情感的具体区分度。然后对数据库情感集合中,情感按照区分度高低进行排序,得到有序情感集合s。将有序情感集合s作为svm-rf中子分类器构建顺序的参照标准。
对于图4中所示的svm-rf构建环节,本发明采用决策树形式对其子分类器进行构建,且采取情感可区分性先易后难的策略,首先对易于区分的情感进行分类。第一个svm子分类器的任务是区分出情感集合中区分度最高的情感,第二个svm子分类对区分度次高的情感进行分类,以此类推,直到情感集合中尚未进行区分的剩余情感中,最高区分度小于预先设定的阈值λ时,将剩下的所有情感识别使用随机森林完成。
阈值λ需要根据所有情感区分度进行适当选取,以保证svm-rf的整体识别率。设置阈值λ,是因为考虑到决策树构建方式的缺点,即当决策树上某一个结点上的判断出现错误时,接下来的子分类器无论给出什么样的预测结果都是错误的。因而当树的深度很深时,会导致多类分类器的识别性能的下降。因此,在svm-rf中svm子分类器构建过程中,当剩余情感集合s中,具有最大区分度的情感的区分度小于一定阈值λ时,将不再使用svm进行构建,即假设情感集合s中剩余m类情感,则使用随机森林完成对这m类情感的区分,最后通过级联svm和rf的方式得到多级分类器。
本发明svm-rf分类器的构建过程中,为进一步提升所构建的svm-rf分类器的整体性能,考虑区分不同情感最优特征子集的差异性,采取子分类器对应特征子集差异化策略,即svm-rf中不同的子分类器使用从原始特征子集f中所选取的不同特征子集进行训练,每个特征子集的选取原则是使用此特征子集能使得子分类器在特定情感分类任务上达到性能最优。对于svm-rf中的svm子分类器所使用的特征子集,结合具体的分类任务,使用特征选择算法,如fisher分数值和分类器联合的wrapper式特征选择算法,以svm作为特征子集评价分类器,选出合适的特征子集。对于svm-rf中的随机森林子分类器,由于随机森林是包含一定数量基分类器的集成学习方法,以它作为分类器进行wrapper式的特征选择较为耗时,故选择fisher分数值排名较高的部分特征作为随机森林训练时使用的特征子集。
对于子分类器对应特征子集采取差异化策略,以便区分不同情感集合的最佳特征子集存在的差异性,这也是在评估情感区分度时,利用最佳区分特征子集上得到结果的原因。例如:能够最大区分情感集合1和情感集合2之间最优特征子集,对于情感集合3和情感4来说并不一定是最优的,因此本发明提出了综合考虑特征子集差异性的svm-rf多级分类器构建方式。将使用训练集得到的针对不同子分类器分类任务的最优特征子集用于各子分类器的训练,完成整个多级分类器的训练过程。
s7利用svm-rf多级分类器模型对测试情感语音进行分类测试,并输出分类结果。
本发明使用训练好的多级分类器模型对测试数据进行预测时,svm-rf多级分类器中的各个子分类器也相应地选择各自用到的特征来完成预测过程。
下面以具体的实现数据对本发明做进一步论述:本发明以ubuntu16.04lts为实验平台,程序语言使用python,版本2.7.12。为验证本发明的有效性,在casia数据库上对6类情感进行了实验,对于分类模型,借助了基于python的机器学习库scikit-learn0.18。
其中针对数据集提取的特征如表2所示:
表2情感语音特征表
1、实验参数设定:本发明使用的分类器及其主要参数设置如下:
1)支持向量机:核函数选择高斯核函数,惩罚系数为1。
2)随机森林中基分类器的个数设为200个。
2、情感区分度实验与分析:为了得到不同情感的区分度,以便后续完成svm-rf语音情感多级分类器的构建。本文在casia数据库上进行了实验,从casia数据库1200个数据中选取600个语音数据,用于评估数据库中6类情感的区分度。使用本文第三章给出的特征选择算法,选出训练svm-rf中各子分类器所需要的特征子集。从600个语音数据中选取70%用于训练,30%用于验证。
在特征选择时,使用如fisher分数,对fisher分数排名前对排名前200的特征构成的特征子集进行基于策略b的子集搜索,得到每类情感区分其它另外5类情感的最佳特征子集,同时也得到数据库中高兴、生气、悲伤、惊讶、中性和害怕6类情感的区分度,结果如表3所示:
表3前200名特征进行搜索得到的casia数据库中6种情感的区分度
表3显示了从所有情感当中只区分出一种情感是比较容易的,即便是相对难区分出的害怕情感,也有92.67%的区分度,悲伤对其它5类情感的区分度为93.17%,高兴对于其它5类情感的区分度为93.92%,这三种情感的区分度相对较低,均在93%左右。中性和惊讶情感的区分度在97%以上,生气情感的区分度也较高,为95.00%。同时从表中可以看出区分不同情感的最佳特征子集在特征维数是不同的,区分生气与其它5类情感的最优特征子集维数为83,而区分悲伤与其它情感之间的最优特征子集维数为36,这也验证了区分不同情感的最优特征子集是不同的,即在最优特征子集上存在差异性。
使用特征选择算法,如fisher分数,对fisher分数排名前300的特征组成的特征集合中,使用svm分类器作为评价分类器、基于策略b进行子集搜索,所选出的从6类情感中区分每1类情感的最优特征子集维数及6种情感的区分度:
表4前300名特征进行搜索得到的casia数据库中6种情感的区分度
表4显示了相比于表2中对排名前200个特征做特征选择的结果,表4.2从前300个特征选择出来的特征子集识别性能有一定的提高,如区分生气和其它情感的的最优特征子集的特征维数由83增加到125,但区分度只由95%增加到95.17%。另外如害怕情感,与之对应地最佳特征子集中特征数量由42增加到57,区分度由92.67%提高到93.08%。整体上看,部分情感的区分度虽然有所提高,但为了减少计算量,本文下面实验采用从排名前200的特征中进行特征选择,选择出最佳特征子集,完成相关实验。
3、svm-rf算法与svm和rf的性能对比与分析,上文提到,本实施例在使用最佳特征子集的前提下,得到的情感区分度由高到低的顺序为中性(97.08%)、惊讶(97.08%)、生气(95.00%)、高兴(93.92%)、悲伤(93.17%)和害怕(92.67%)。因此,按照本发明构建svm-rf语音情感多级分类器所采用的先易后难原则,考虑不同情感的区分度情况,首先使用三个二分类svm,依次对中性、惊讶和生气进行区分,对于区分度相差不多且相对较低的高兴、悲伤和害怕三种情感,则使用随机森林进行区分,随机森林使用排名前。本文采用决策树形式的构建方式,参照表2得到的情感区分度排名,因此决策树的根节点是第一个svm分类器,它用来区分中性情感,并且使用区分中性情感的特征子集用于分类器的训练;同样地对于svm-rf语音情感多级分类器中的第二个svm子分类器,它用来区分情感区分度第二高的惊讶情感,且使用区分惊讶情感的最优特征子集用于第二个svm分类器的训练;第三个分类对生气情感进行区分,并且同样使用对应的特征子集进行训练。对于rf分类器,它对剩下的害怕、悲伤和高兴三种情感进行区分,用到的特征子集同样与它的分类任务所匹配。最终,构建的svm-rf多级分类器结构如图5所示。其中,特征子集1,特征子集2,特征子集3,特征子集4分别是区分中性、惊讶、生气的最优特征子集以及对fisher分数排名前200的特征组成的特征子集。
4、对比分析,为了验证本发明的有效性,采用一对多svm分类器作为对比,通过对6类情感进行特征选择得到的特征子集,与本发明构建的多级分类器进行对比。使用相同特征子集svm分类器对应的特征维数是57个。在casia数据库上进行10次10折交叉验证,得到的实验结果如表5所示:
表5不同分类器的识别结果
由表5可知本发明svm-rf算法在10次10折交叉实验中,取得的平均识别率为83.06%,而不考虑最佳特征子集差异性、使用相同特征子集训练的一对多svm分类器的识别率为82.23%,本章算法平均识别率相比一对多svm提高了0.83%。svm-rf2中svm子分类器使用特征子集和一对多svm的特征子集是相同的,其平均识别率为81.01%,显然它的平均识别率比对子分类器的特征子集采取差异化策略的svm-rf低2.05%,验证了特征子集差异化策略的合理性。相比rf,svm-rf要低1.1%。
为了对比svm,rf,svm-rf,svm-rf2四种分类算法的运行时间,在casia数据库上进行了十次十折交叉验证,每一次十折交叉实验的平均运行时间如表6所示:
表6运行时间比较
由表6可以看出svm-rf的运行时间明显少于rf模型的训练时间,svm-rf的一次十折交叉验证平均需要13.73s的时间,而rf一次十折交叉验证平均需要的时间是29.75s。实验验证了svm-rf的模型训练时间确实要少于rf的模型训练时间,但因为引入了rf的原因,使得svm-rf的模型时间要比svm模型训练时间多许多。
从casia数据库中选取前900个样本数据用于训练、后300个样本用于测试,使用svm和svm-rf两种算法对6种情感进行识别,得到的情感混淆矩阵如表7和表8所示:
表7使用svm识别的混淆矩阵
表8使用svm-rf识别的混淆矩阵
由表7和8所示的混淆矩阵进行对比,可以看出本文构建的svm-rf多级分类器对害怕和高兴的识别效果有所提升,对各自50个测试样本的识别数分别从34、38都提高到41;此次实验svm的识别率为82.67%,而本文构建的svm-rf级联的多级分类器的识别率为85.67%。实验验证了考虑最佳特征子集差异性所构建多级分类器,能够进一步提高语音情感的识别率。
本发明基于情感语音识别领域obsi、obsir特征参数,针对svm和rf的特点提出一种基于特征选择的svm-rf多级分类器构建算法,根据情感的实际区分度,使用若干个一对多的二分类svm先对较为容易区分的情感进行区分,而对于其中较难区分的情感使用rf进行识别。同时在svm-rf中,对用于训练子分类器的特征子集采取差异化策略,最终使svm-rf能够可以用少于rf模型的训练时间,达到与rf近乎相同的性能。通过实验验证了svm-rf多级语音分类器构以较少的模型训练时间,获得了接近rf的识别性能。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!