一种声音驱动粒子特效的视频处理方法与流程
本发明涉及视频领域,更具体的说,其涉及用于一种声音驱动粒子特效的视频处理方法。
背景技术:
近年来智能手机日益普及,它的功能也越来越强大,在日常生活中使用手机分享自己拍摄的视频也越来越普遍。传统的视频分享的内容在表现力上除了添加一些特效外,很少有能和视频中的声音做互动效果,且在制作特效时也不够便捷、直观。
技术实现要素:
本发明的目的在于提供一种声音驱动粒子特效的视频处理方法,使得整个过程快速流畅、可视化强。
为了解决上述技术问题,本发明的技术方案如下:
一种声音驱动粒子特效的视频处理方法,具体包括如下步骤:
101)选取视频和特效步骤:选择要编辑的视频和粒子特效模板;
102)音视频同步步骤:将步骤101)选择的视频,通过按音频时间进行数据分块,达到音视频效果同步;
103)基于fft快速频谱分析步骤:将对步骤102)的音频信息通过fft进行分析,获取音频参数,并缓存分析结果;所述fft即快速傅里叶变换为dft即离线傅里叶变换的一种改进型快速处理音频信息的方法;
104)音频信息对应粒子步骤:从模板中获得步骤103)得到的音频信息和粒子的参数的对应关系,所述对应关系采用相应的数学映射;
105)粒子特效步骤:根据模板中的驱动处理,来驱动步骤104)中的粒子的参数,并利用ae的粒子特效对相应的粒子特效进行编辑,然后根据粒子的参数导入模拟器进行特定的粒子特效的生成;所述ae为aftereffect即一款图形视频处理软件。
进一步的,所述步骤102)的音频由audio解码器读取出的一段pcm数据即脉冲编码调制数据,并按照音频的时间步进进行数据分块处理。
进一步的,所述步骤103)中的dft采用如下公式(1)进行频谱分析:
其中n为有限长序列的数量,x(n)为有限长序列的表达式,
进一步的,所述fft采用如下公式(2)进行前半部分分析,公式(3)进行后半部分分析:
其中x1(k),x2(k),分别是fft的输入序列表示成偶点序列和奇点序列的n/2点dft。
本发明相比现有技术优点在于:
本发明先利用高精度音频频谱技术分析视频中的声音或音乐,然后针对分析结果,根据事先准备的模板来驱动粒子特效。从而实现声音和粒子的无缝链接,增加视频互动效果。从aftereffect编辑工具直接导出效果导入手机,该方式便捷、效果可视化强。可以在手机app端运行,速度流畅。
附图说明
图1为本发明一种声音驱动粒子特效的视频处理方法的音频分析流程图;
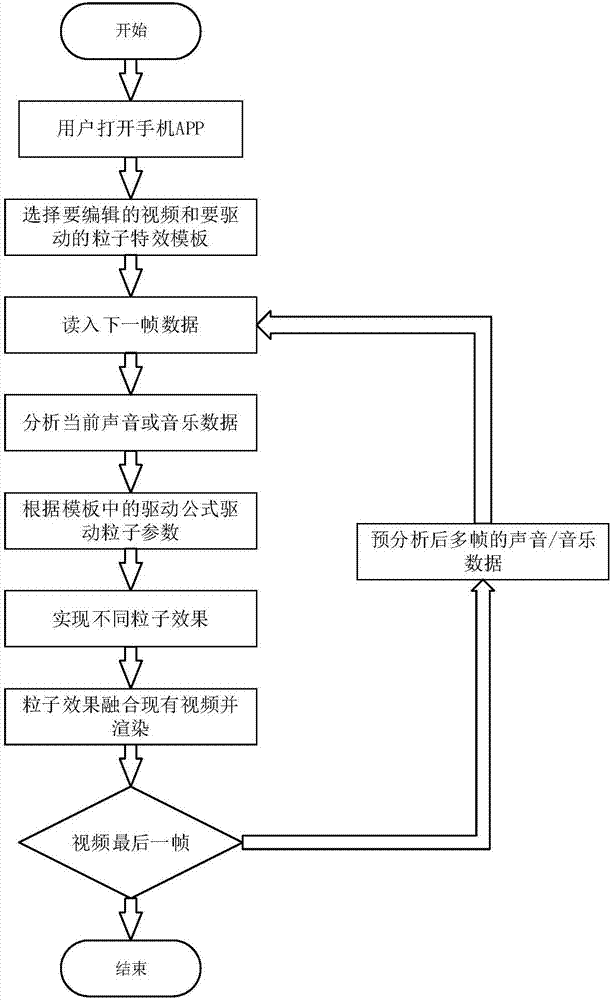
图2为本发明一种声音驱动粒子特效的视频处理方法的手机端处理流程图。
具体实施方式
下面结合附图和具体实施方式对本发明进一步说明。
如图1和图2所示,一种声音驱动粒子特效的视频处理方法,具体包括如下步骤:
101)选取视频和特效步骤:用户选择好要编辑的视频和要驱动起来的粒子特效模板。
102)音视频同步步骤:将步骤101)选择的视频,由audio解码器读取出一段pcm数据即脉冲编码调制数据,也就是音频,并通过按音频时间的时间步进进行数据分块,以此达到音视频效果同步,确保效果体验的实时互动感。
103)基于fft快速频谱分析步骤:将对步骤102)的音频信息通过fft进行分析,获取音频参数,并缓存分析结果;所述fft即快速傅里叶变换为dft即离线傅里叶变换的一种改进型快速处理音频信息的方法。所述dft采用如下公式(1)进行频谱分析:
其中n为有限长序列的数量,x(n)为有限长序列的表达式,
进而dft的表达式可以拆分为如下公式(5):
其中
x1(k)和x2(k)分别是x1(r)和x2(r)的n/2点,从而演化的公式(7):
可以看出,一个n点dft已分解成两个n/2点的dft,他们又组成一个n点dft。而x1(k)和x2(k)以及x1(r)和x2(r)都是n/2点序列,x(k)却有n点。用上述计算得到的只是x(k)的前一半项数结果,要想利用x1(k)和x2(k)得到x(k)的全部的值的话,需利用复指数根的周期性如下公式(8):
从而可以得到如下公式(9):
x1(k+n/2)=x1(k),x2(k+n/2)=x2(k)公式(9)
同时
结合公式(9)和公式(10)可得到完整的n点fft的表达式为,如下公式(2)进行前半部分分析,公式(3)进行后半部分分析:
由此可知
104)音频信息对应粒子步骤:从模板中获得步骤103)得到的音频信息和粒子的参数的对应关系,所述对应关系采用相应的数学映射。例如在模板中定义了音频的音量值与粒子的每秒发射粒子数的数学关系为y=2x+15,所述x为音频的音量值,y为粒子的每秒发射粒子数,则表示某时刻获取的音量值为20,则当前粒子的每秒发射粒子数为55。
105)粒子特效步骤:根据模板中的驱动处理,来驱动步骤104)中的粒子的参数,并利用ae的粒子特效对相应的粒子特效进行编辑,然后根据粒子的参数导入模拟器进行特定的粒子特效的生成,其解决了特效设计的可视化问题,增加便捷性。所述ae为aftereffect即一款图形视频处理软件。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员,在不脱离本发明构思的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!