一种骚扰电话的识别与拦截方法与流程
本发明属于通信技术领域,涉及一种骚扰电话的识别与拦截方法。
背景技术:
随着通信行业的不断发展,广大用户开始逐渐享受到多样化的通信服务。但是与此同时,越来越多的诈骗电话出现在用户的日常生活中,部分地区在节假日期间更是出现诈骗案件频发的态势。频繁发生的诈骗电话不仅扰乱了电信运营的正常秩序,同时给受骗用户带来巨大的财产损失,影响社会的安定与和谐。因此对于骚扰电话进行识别和拦截的研究,具有重要的现实意义。针对骚扰电话行为,运营商虽在持续治理,但依然泛滥;互联网厂商虽也参与了骚扰电话治理,但仅限提醒,且覆盖范围有限。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于信令数据深度挖掘的骚扰电话分析与治理整体解决方法,该方法具有全网覆盖、属性全面、数据精准等特点。
为达到上述目的,本发明提供如下技术方案:
一种骚扰电话的识别与拦截方法,该方法包括以下步骤:
s1:采集通信网信令信息,对采集到的数据进行解码合成、数据去重、协议分析,再根据各种协议规则进行cdr合成;
s2:根据骚扰电话特征选择呼叫频率、接通率、平均振铃时长、被叫时平均通话时间、号码集中度、拨打空号比例、电路交换(circuitswitched,cs)呼叫量与包交换(packetswitched,ps)流量比作为骚扰电话的识别因子;
s3:根据骚扰电话的识别因子采用加权朴素贝叶斯分类算法对所有通话进行分类,识别出骚扰电话和非骚扰电话;
s4:对识别出的骚扰电话进行回拨检验;
s5:拦截骚扰电话。
进一步,所述步骤s1包括以下步骤:
s101:针对不同的通信网络选取不同的采集点;其中固网选择软交换(softswitch,ss),c网选择移动软交换中心(mobileswitchingcenteremulation,msce)、归属位置寄存器(homelocationregister,hlr)、msce之间的cmap信令,msce、ss之间的isup信令,以及msce之间的sip信令,ims网选择代理/询问呼叫会话控制功能(proxy/inquiry-callsessioncontrolfuntion,p/i-cscf);
s102:对信令采集模块捕获的数据进行解码,在物理层和数据链路层完成解码重组后通过驱动回调方式将网络层数据发送至解码合成模块;
s103:提取消息特征字段信息,并封装到呼叫合成信息类中;
s104:交给协议分析器进行呼叫合成与协议关联解码;
s105:将同一用户的同一信令流程中相关联的消息组合在一起,形成完整的信令流程。
进一步,在步骤s2中,所述呼叫频率为主叫号码频繁向一个或多个被叫号码发起呼叫远超过正常范围的频率;
所述接通率为被叫号码接通主叫号码的概率;
所述平均振铃时长为主叫号码完成振铃的平均时间;
所述被叫时平均通话时间为被叫号码回拨后的通话平均时间;
所述号码集中度为骚扰软件自动生成的被叫用户号段区间;
所述拨打空号比例为被叫号码空号数与被叫号码拨打数的比值;
所述cs呼叫量与ps流量比为cs呼叫量与ps流量的比值。
进一步,所述步骤s3具体为:
s301:通过贝叶斯分类器分析呼叫话单,得到主叫号码是骚扰电话的概率p及主叫号码不是骚扰电话的概率p';
s302:通过比较p与p'的大小关系,判断出主叫号码是否是骚扰电话。
进一步,所述步骤s301具体为:
s301a:对于训练样本集合d,假设有p个属性指标n个样本,k表示的样本的第k个属性,第j个样本表示为xj=(xj1+xj2,…,xjp),1≤j≤n,简记x=(x1+x2,…,xp),xi表示第i个属性指标;统计类ci集合中的样本数si、其样本数count(xk)、属性对(xk,xj)的样本数count(xk,xj),1≤k,j≤p;
s301b:计算先验概率p(ci)=si/n,其中n为样本容量,计算
s301c:选取类ci集合中最大的3个条件概率p(xk/ci)、p(xj/ci)、p(xl/ci)的3个属性xk、xj、xl,1≤i,j,k≤p,i、j、k分别表示的样本的第i、j、k个属性,;扫描数据集d,统计类ci集合中包含值(xk,xj,xl)的样本数count(xk,xj,xl),计算
利用公式
确定控制参数β∈(0.1~0.3),使
s301d:计算p(x/ci)(1≤i≤m),m为数据类别,假设数据集有m个类别,表示为c1,c2,…,cm;
s301e:当p(ck/x)>p(ch/x),k≠h时,则x=(x1,x2,…,xp)∈ck。
进一步,所述步骤s4包括以下步骤:
s401:去除确认的非骚扰电话号码,根据系统中建立的白名单对监控系统经过分析筛选出的可疑号码进行剔除;
s402:引入语音识别技术对可疑骚扰电话进行语音匹配,判断是否为骚扰电话;
s403:对语音匹配识别不出的可疑号码进一步提交进行人工甄别。
进一步,所述步骤s402包括以下步骤:
s402a:对语音信号进行预处理;
通过滤波器提升高频分量并消除工频干扰,其系统函数为:
对语音进行分帧处理,分帧采用滑动的优先窗口进行加权,采用的窗口函数为汉明窗,其形式为
采用短时能量和短时过零率相结合的方法进行端点检测,l表示阶数;
s402b:特征提取mfcc;
首先对语音信号进行分帧、加窗,然后作离散傅立叶变换得频谱分布信息,求出频谱平方,即能量谱,再用mel滤波器组进行滤波,得到功率谱;将每个滤波器的输出取对数并进行反离散余弦变换,得到mfcc系数,mfcc系数计算公式:
对mfcc系数进行差分计算得到反映语音动态变化的差分参数;
s402c:模版匹配;
采用动态时间规整dtw算法,确定参考模版和测试模版的时间对应关系,
假设参考模型的特征矢量序列为:{r(1),r(2),…,r(m),…,r(m)},其中m为参考模版语音信号的第m帧,m=1时表示语音帧开始,m=m时表示语音帧结束,即m模版话音的帧数,r(m)为第m帧的特征向量;
假设测试模版的特征矢量序列为:{t(1),t(2),…,t(n),…,t(n)},其中,n为测试模版语音信号的第n帧,n=1时表示话音帧开始,n=m时表示语音帧结束,即m模版话音的帧数,t(n)为第n帧的特征向量;
模板训练阶段,首先对模板录音生成音频列表addlist,然后对模板录音进行预处理,对音频进行去除静音和切分,将音频切分为数个音频片段,将预处理后的音频片段送入声学特征提取模块,将音频片段转换为对应的特征矢量mfcc,作为模板话音的识别特征,生成模板库template;在实验中选择不同类别的录音进行模板训练,丰富模板库;
识别阶段,首先对待测录音生成音频列表wavlist,然后将待测录音的特征矢量与模板库中话音模板逐一进行相似性度量的比较,从而得出最佳的匹配结果。
进一步,所述步骤s5包括以下步骤:
s501:将骚扰电话分为互联互通用户和外省移动用户进行相应处理;
s502:对于互联互通用户,将该号码的相关信息发送至话务网管系统通过话务网管系统在关口局设置黑名单进行屏蔽;对于外省移动用户,监控系统判断该主叫号码所在地址,若位于省内交换机,则通过话务网管系统向省内端局设置黑名单进行屏蔽,否则,监控系统判断该主叫号码在所在地为外省端局,将该号码的相关信息发送至汇接局通过话务网管系统向移动软交换长途汇接局设置黑名单进行屏蔽。
本发明的有益效果在于:首先通过软件系统利用数据挖掘技术主动对疑似骚扰电话进行识别监控,提升了骚扰电话识别准确率;其次引入语音匹配技术对已经筛选出的意思骚扰电话进行回拨确认,提升了回拨检测效率,降低客服人员的工作量;最后对于已确定的骚扰电话在对用户造成不良影响前,切断通话,减少了通信网络资源的浪费以及对用户可能造成的损失。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明流程图;
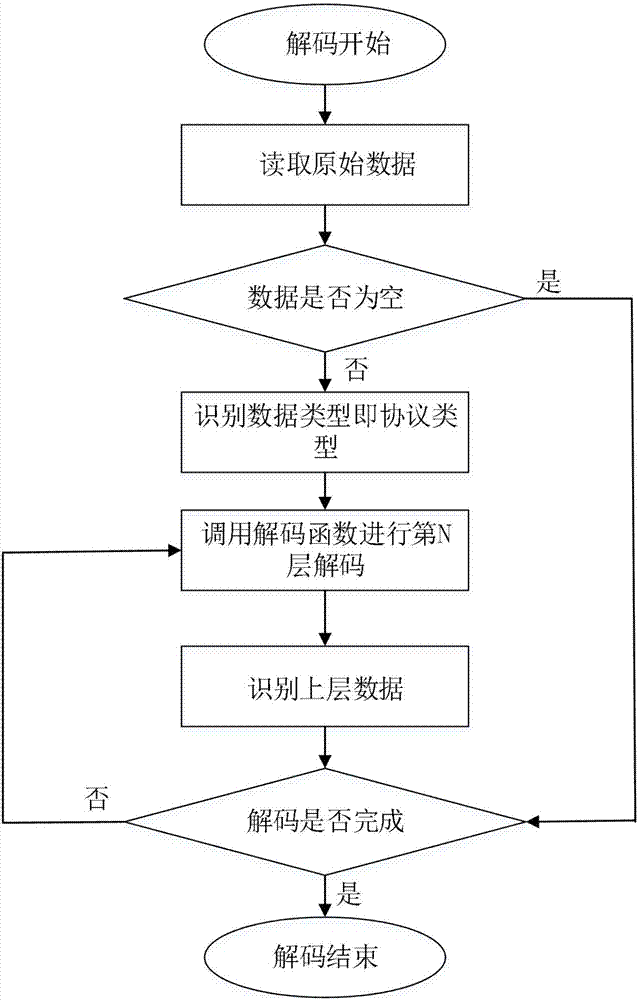
图2为数据解码流程图;
图3为数据合成流程图;
图4为回拨检测流程图;
图5为语音识别基本流程图;
图6为mfcc提取流程图;
图7为骚扰电话拦截流程框图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
如图1所示,本实施例包括以下步骤:
s1:采集通信网信令信息,原始数据经过解码合成、数据去重、协议分析,再根据各种协议规则进行cdr合成;
s2:根据骚扰电话特征选择呼叫频率、接通率、平均振铃时长、被叫时平均通话时间、号码集中度、拨打空号比例、cs呼叫量与ps流量比作为骚扰电话的识别因子;
s3:根据骚扰电话的识别因子采用加权朴素贝叶斯分类算法对所有通话进行分类,识别出骚扰电话和非骚扰电话;
s4:然后对识别出的骚扰电话进行回拨检验。
s5:最后进行骚扰电话的拦截。
进一步的,所述步骤s1中对数据进行采集和预处理,包括针对不同的通信子网络选择不同的采集方案,固网选择ss,c网选择msce与hlr,msce之间的cmap信令,msce与ss之间的isup信令,以及msce与msce之间的sip信令,ims网络选择p/i-cscf;对信令采集模块捕获的数据进行解码,在物理层和数据链路层完成解码重组后通过驱动回调方式将网络层数据发送至解码合成模块,提取消息特征字段信息,并封装到呼叫合成信息类中,再交给协议分析器进行呼叫合成与协议关联解码。协议合成将同一用户的同一信令流程中相关联的消息组合在一起,形成完整的信令流程。
进一步的,所述步骤s2中,根据大量训练数据的统计分析选择呼叫频率、接通率、平均振铃时长、被叫时平均通话时间、号码集中度、拨打空号比例、cs呼叫量与ps流量比作为骚扰电话的识别因子。
进一步的,所述步骤s3中选择用加权朴素贝叶斯分类算法对所有通话进行分类,识别出骚扰电话和非骚扰电话,包括,数据集中有p个属性指标n个样本,第j个样本表示为xj=(xj1,xj2,…,xjp),1≤j≤n,简记xj=(x1,x2,…,xp),xi表示第i个属性指标。假设m类别,表示为c1,c2,…,cm,判别样本x=(x1,x2,…,xp)属于类别ck(1≤k≤m)的概率可由贝叶斯公式计算。需要计算:
判别规则:当p(ck/x)>p(ch/x),k≠h时,则x=(x1,x2,…,xp)∈ck,在本实施例中p=7,m=2。
对于式(1)需要假设p个属性是相互独立的,但实际问题中独立假设一般不能成立。本方法基于属性相关性分析在公式(1)中加权种系数以放松独立性的假设,即将式(1)修改为
进一步的,基于卡方拟合统计量的构造思想构造样本属性指标xk、xj之间的相关系数。定义1:在类ci集合中,定义样本x的属性指标xk与xj的相关系数:
其中,count(xk,xj)、count(xk)分别表示在类ci集合中属性对(xk,xj)和xk出现的频数,si为当前类中的样本总数,在xk、xj相互独立的假定下,count(xk)·count(xk)/si可以估计理论频数sip((xk,xj)/ci)。
定义2:在类ci集合中,定义xk与xj的权重系数:
特别地,当xk与xj之间相互独立时,有
进一步的,计算出向来那个之间的加权系数。假设向量x=(x1,x2,…,xp),则向量x的相关度定义为:
显然wex的值越大,称向量x具有较大的相关性。特别地,如果x1,x2,…,xp间相互独立,则wex=1,因此可由wex来决定式(1)中的权重系数,但需要由样本去估计wex。通过分析可知,向量的相关度与两两属性之间的相关度成正比,定义向量的相关度估计:
其中,
进一步的,所述步骤s4中对识别出的疑似骚扰电话进行检测确认。监控系统中分析筛选出的可疑号码,会通过boss(business&operationsupportsystem)系统的接口传递给省客服系统,对于客服系统中已有的白名单,直接进行过滤处理,排除在骚扰电话号码之外,无需进行回拨确认。如果疑似号码在客服系统的黑名单之中,直接交由拦截系统进行拦截处理,也无需进行回拨处理。
进一步的,对于不在客服系统黑、白名单中的疑似骚扰电话号码,需要进行回拨确认,根据骚扰电话的一些特点,我们采用了语音识别技术进行智能识别,减少人工克服的工作量,并提高工作效率。
进一步的,对于语音识别系统不能识别的疑似骚扰电话需要进行人工回拨,以减少错误拦截的可能性。
进一步的,所述步骤s5中对于骚扰电话的拦截,根据骚扰号码以及呼叫位置,将其分为几种不同的情况进行相应的拦截处理。
1.数据采集和预处理
针对不同的通信网络选取不同的采集点,固网选择ss,c网选择msce与hlr,msce之间的cmap信令,msce与ss之间的isup信令,以及msce与msce之间的sip信令,ims网络选择p/i-cscf。
对采集到的数据进行预处理,主要是将采集到的信令信息进行协议分析,根据各种协议的规则进行cdr(calldetailrecord,呼叫详细记录)合成。解码合成模块实现对信令采集模块捕获的数据进行解码,在物理层和数据链路层完成解码重组后通过驱动回调方式将网络层数据发送至解码合成模块。解码流程如图2所示。
协议合成是将同一用户的同一信令流程中相关联的消息组合在一起,形成完整的信令流程。该模块按照协议类型,合成本协议事务详细记录,并提取协议类型、关联主键及取值、事务开始时间、事务结束时间等用于关联分析的关键信息,进一步合成关联分析cdr,发送到多协议关联分析模块。cdr合成流程如图3所示。
2.分类识别因子的选择
骚扰电话识别因子的选择。骚扰电话存在以下特点(我们选取这些识别因子作为骚扰电话分类是别的主要指标):
(1)呼叫频率高;主叫号码存在较高的呼叫频率,远远超过正常使用的频率范围。主叫号码频繁向一个(针对特定受众进行骚扰)或多个(针对大范围受众进行骚扰)被叫号码发起呼叫。
(2)接通率低;对于被叫来说,作为骚扰电话的主叫一般是陌生号码,很多情况下会直接挂断。
(3)平均振铃时间短:诱发骚扰的特点就是诱导用户进行回拨,因此在完成第一次振铃后,骚扰软件即会中止呼叫。
(4)被叫时平均通话时间短:一般情况下,被诱导的用户在回拨后发现是在播放骚扰信息时,会尽快挂断电话。
(5)号码集中度高:诱发骚扰是通过软件进行发起的,其目标用户号码是通过号段设置自动生成的。
(6)拨打空号比例大:由于存在用户销户、换号、挂失、欠费停机等情况,号码段中存在很多空号。被叫号码是用软件根据号段自动生成,因此会出现主叫号码拨打空号比例大的情况。
(7)cs呼叫量与ps流量严重不对等:由于骚扰电话作为特殊用途的电话,cs呼叫量和ps流量一般会严重不对等。
3.分类算法的实施
根据加权朴素贝叶斯分类算法对所有通话进行分类,识别出骚扰电话和非骚扰电话;
算法步骤:
步骤1:对于训练样本集合d,统计类ci集合中的样本数si,属性xk的样本数count(xk),属性对(xk,xj)的样本数count(xk,xj)。
步骤2:计算先验概率p(ci)=si/n(n为样本容量),计算
步骤3:选取类ci集合中最大的3个条件概率p(xk/ci)、p(xj/ci)、p(xl/ci)的3个属性xk、xj、xl。扫描数据集d,统计类ci集合中包含值(xk,xj,xl)的样本数count(xk,xj,xl)。类似于公式(2)和(3),计算
利用公式(5)计算
步骤4:利用公式(5)和(6),计算p(x/ci)(1≤i≤m)。
步骤5:当p(ck/x)>p(ch/x),k≠h时,则x=(x1,x2,…,xp)∈ck。
4.对识别出的骚扰电话进行回拨检验
对筛选出的灰名单需要进行回拨检测,以减少错误拦截所造成的损失。回拨检测流程如图4所示。
白名单去除
信令监测系统在接口机上定时产生问题呼叫数据记录,并通过ftp的方式将文件定时发送至骚扰电话监测服务器上;监控系统经过分析筛选出可疑号码;然后将可疑号码生成话单文件,通过boss(business&operationsupportsystem)系统的接口传递给省客服系统。
系统中建立有白名单,过滤掉移动运营商的vip(钻、金、银卡)用户、被误停导致投诉的正常通信客户以及移动公司内部员工号码,同时还过滤掉移动业务平台外的短号、其他各种正常业务的外呼平台号码,这些号码排除在骚扰电话号码之外,无需给省客服人员回拨确认。
语音识别
疑似骚扰电话主要分为忙音、来电提醒等提示音和代孕、假中奖、诈骗类等骚扰电话,通过对录音的内容进行分类和识别,发现骚扰电话重复性很高,可以引入话音识别技术进行处理。语音识别流程如图5所示。
话音识别系统本质上是一种模版匹配系统,包括预处理、端点检测、特征提取、模版库、模版匹配等基本单元。
(1)预处理
语音信号的预处理包括预加重、分帧和加窗三个步骤。其主要目的是对语音信号采样、去噪、便于后期的特征提取。
预加重通过滤波器提升高频分量并消除工频干扰,常用一阶数字滤波器实现,其系统函数为:
为了得到短时平稳信号,要对语音进行分帧处理,分帧采用滑动的优先窗口进行加权,保持话音流的连续性。采用的窗口函数为汉明窗,其形式:
话音的端点检测就是根据某些特征参数准确地判断出话音的起点和终点,排除话音的噪音段、静音段等。常用的端点检测参数是短时能量和短时过零率。为提取有效的话音信号,通常采用短时能量和短时过零率相结合的方法进行端点检测。
(2)特征提取(mfcc)
mfcc的提取流程如图6示。
mel频率表示公式为:mel(f)=2595×lg(1+f/700),式中f为频率,单位为hz.
mfcc的提取过程中,首先对话音信号进行分帧、加窗,然后作离散傅立叶变换得频谱分布信息,求出频谱平方,即能量谱,再用mel滤波器组(通常为三角形带通滤波器)进行滤波,得到功率谱。将每个滤波器的输出取对数并进行反离散余弦变换,得到mfcc系数,mfcc系数计算公式:
由于mfcc只反映了话音参数的静态特性,需对mfcc系数进行差分计算得到反映话音动态变化的差分参数。
(3)模版匹配
在模版匹配的过程中,为了确定参考模版和测试模版的时间对应关系,采用动态时间规整dtw算法,
假设参考模型的特征矢量序列为:{r(1),r(2),…,r(m),…,r(m)},其中m为参考模版语音信号的第m帧,m=1时表示语音帧开始,m=m时表示语音帧结束,即m模版话音的帧数,并且r(m)为第m帧的特征向量。
测试模版的特征矢量序列为:{t(1),t(2),…,t(n),…,t(n)},其中,n为测试模版语音信号的第n帧,n=1时表示话音帧开始,n=m时表示语音帧结束,即m模版话音的帧数,并且t(n)为第n帧的特征向量。
dtw就是通过寻找一个时间规整函数,将测试矢量的时间轴非线性的映射到参考模板的时间轴上。
模板训练过程中,首先对模板录音生成音频列表addlist,然后对模板录音进行预处理,对音频进行去除静音和切分,将音频切分为数个音频片段,将预处理后的音频片段送入声学特征提取模块,将音频片段转换为对应的特征矢量mfcc,作为模板话音的识别特征,生成模板库template。为了增强系统的鲁棒性和话音识别的准确率,在实验中选择不同类别的录音进行模板训练,不断丰富模板库。在识别阶段,首先也需要对待测录音生成音频列表wavlist,然后对待测录音进行预处理和特征提取,提取话音的特征矢量mfcc,最后进行音频匹配,即将待测录音的特征矢量与模板库中话音模板逐一进行相似性度量的比较,从而得出最佳的匹配结果。
客服回拨:对于语音匹配识别不出的可疑号码进一步提交进行人工甄别。
5.骚扰电话的拦截
根据骚扰号码以及呼叫位置,将其分为几种不同的情况进行相应的拦截处理。骚扰电话拦截流程如图7所示。
当客服人员确认该骚扰电话号码为省内移动用户时,将该号码的相关信息发送至系统通过系统关闭骚扰电话号码语音呼叫功能,并短信告知。
当客服人员确认该骚扰电话号码为互联互通用户时,将该号码的相关信息发送至话务网管系统通过话务网管系统在关口局设置黑名单进行屏蔽。当客服人员确认该骚扰电话号码为外省移动用户时,监控系统判断该主叫号码所在地址,如为省内交换机,则通过话务网管系统向省内端局设置黑名单进行屏蔽否则监控系统判断该主叫号码在所在地为外省端局,将该号码的相关信息发送至汇接局通过话务网管系统向移动软交换长途汇接局设置黑名单进行屏蔽。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!