一种基于文本无关的短语音说话人确认方法与流程
本发明涉及人工智能、模式识别技术领域中的声纹识别技术,具体涉及一种基于文本无关的短语音说话人确认方法。
背景技术:
声纹识别技术是一门将计算机、生物统计学、生物传感器等多种学科相结合的综合学科,该技术主要是通过每个人独特的先天生理特征或者后天的行为特性对人的身份进行识别的技术。声纹识别(voiceprintrecognition)又被称为说话人识别,是一种生物识别技术,该技术主要通过人的声音中包含的特征信息对说话人身份进行自动识别的技术。
在声纹识别技术的实际应用过程中,经常会面临语音数据较短、数据量稀缺的情况。短语音问题对说话人识别的影响主要表现在:当训练语音不足时,对说话人特征参数的分布情况刻画不完整,进而影响声纹模型的准确性。
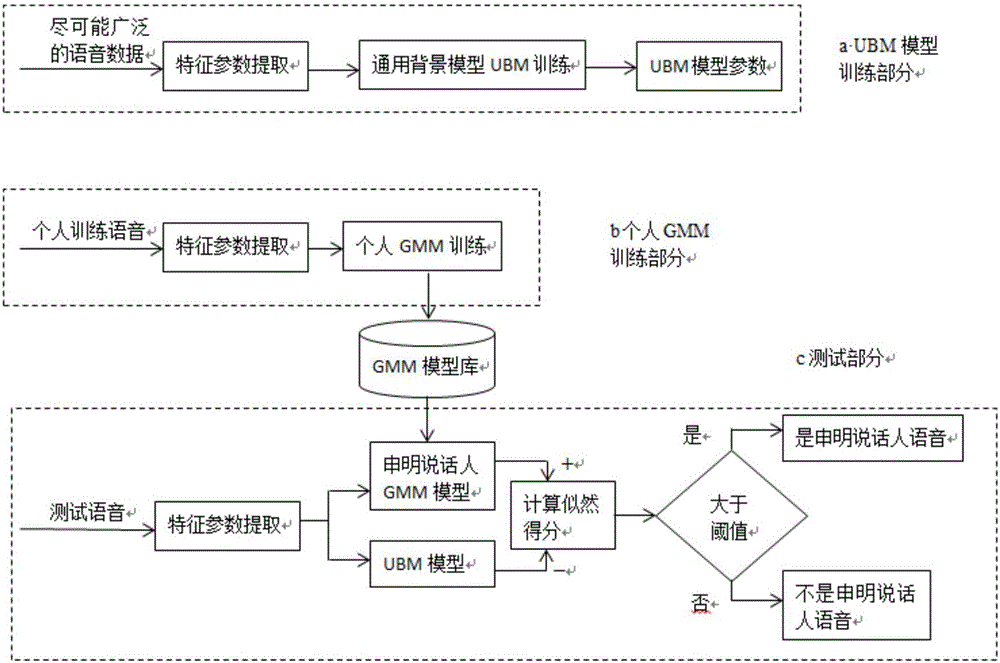
在声纹识别系统中,比较经典的声纹模型有:动态时间规整模型(dtw)、矢量量化模型(vq)、隐马尔可夫模型(hmm)、高斯混合模型(gmm)、支持向量机模型(svm)等。对于短语音问题,普遍采用ubm-map-gmm模型,该模型的基本原理如图1所示。该模型可以在一定程度上解决短时语音问题,但该模型也有其自身的缺点。在该模型中,经过自适应得到的说话人声纹模型强制服从ubm的统一分布,当语音数据进一步变短(有效语音低于10s)时,由于训练数据不充分,很多高斯分量没有得到充分的学习,自适应得到的说话人模型与ubm模型差异并不大,从而给声纹识别带来了极大的困难。
针对ubm-map-gmm声纹识别系统计算量大、运行速度慢的情况,目前有研究者提出了一些改进的方法,这些方法在不同程度上降低了声纹识别系统识别过程中存在的计算量。一种是高斯分量的核心挑选算法,该算法将各个ubm的高斯分量组织成树的结构,在语音测试阶段通过树形结构快速挑选出与测试语音帧相似度高的若干高斯分量,该方法降低了识别系统所需的运算量,同时由于通过高斯分量搜索未必能找到真正似然得分最高的前若干个高斯分量,因此导致系统识别性能有一定程度的降低。另一种是快速计算似然得分的方法,即针对一帧语音,首先计算该帧语音在ubm中每个高斯分量的得分,并根据高分优先的方法筛选出前c个分量进行标记,在对测试语音在个人gmm上进行计算时,只计算gmm模型中与ubm对应的c个高斯分量下的似然得分,因此该方法可以减少系统在语音测试时的计算量,尽快做出识别结果,然而,该模型在语音训练时仍然需要基于ubm为每个说话人建立高阶的声纹模型gmm,在训练模型阶段仍然需要进行大量计算。
技术实现要素:
鉴于上述方法所存在的问题,本发明提出一种基于文本无关的短语音说话人确认方法,将从降低声纹模型gmm阶数的角度上对模型做出改进,从而降低声纹识别系统的等错误率及计算复杂度。
本发明的技术方案如下:
一种基于文本无关的短语音说话人确认方法,其特征在于包括:
(1)基于ubm-cm-map-gmm模型的说话人确认的个人gmm训练:对ubm模型中的高斯分量根据训练语音的得分进行高分优先的选取方法,为每个说话人建立自己的cm模型;在训练过程中,首先采用大量的不同的说话者语音进行训练得到ubm模型,使得该模型表征所有说话人声学特征分布的公共特性;然后利用目标说话人训练语音首先计算每一帧特征矢量在通用背景模型ubm中的每个高斯分量上的得分,在此基础上计算训练语音中所有语音帧在ubm模型每个高斯分量上的得分,根据得分高低选择出前若干个高得分的高斯分量并进行组合得到个人cm,将cm作为训练目标说话人声纹模型的初值;最后,利用该初值基于map训练方法对初始模型进行调整进而得到说话人声纹模型gmm;
(2)基于ubm-cm-map-gmm模型的说话人确认的语音测试:在语音测试阶段,计算测试语音在说话人声纹模型gmm上的得分与测试语音在竞争者模型cm上的似然得分;然后基于似然得分,根据系统判决规则输出识别结果。
本发明是一种基于ubm-cm-map-gmm的识别方法。在短语音说话人识别中,ubm-cm-map-gmm模型不仅缩短了系统的识别时间,而且也降低了系统的等错误率。ubm-cm-map-gmm模型在个人gmm混合度为通用背景模型ubm的一半时,系统性能最佳。总之,改进的说话人确认方法克服了传统ubm-map-gmm模型将所有说话人的声纹模型gmm服从同一模型结构的缺点,不仅减少了识别系统的计算量而且也提升了系统的识别性能。
附图说明
图1是基于ubm-map-gmm模型架构的说话人确认流程图;
图2是本发明基于ubm-cm-map-gmm模型的说话人确认基本流程图;
图3是本发明ubm-cm-map-gmm模型中个人gmm的训练过程示意图;
图4是本发明的说话人语音测试流程图。
具体实施方式
本发明主要针对ubm-map-gmm模型存在的计算量大、部分高斯分量对识别性能影响等问题,提出了基于ubm-cm-map-gmm的识别方法,这种方法主要是基于ubm-map-gmm系统中存在说话人语音训练不充分进而影响最终判决结果的情况,对ubm模型的高斯分量进行筛选,为每个说话人建立自己有针对性的低阶ubm,即竞争者模型cm,然后基于低阶ubm,利用训练语音为每个说话人建立自己的声纹模型gmm。这种识别方法的主要目的是:有效提高段语音说话人识别的性能,而且在降低cm和gmm混合度基础上,减少说话人识别在语音测试阶段的时间耗费。
ubm-cm-map-gmm模型的主要思想是:针对低得分高斯分量会对声纹识别系统识别性能的负面影响,将低得分高斯分量删减掉,只选择得分高的高斯分量,这些得分高的高斯分量可以理解为由接近目标说话人声纹特征信息的多个说话人的语音训练得到,将这些高得分的高斯分量进行组合,从而为每个目标说话人建立自己的竞争者模型cm(cohortmodels),该模型中的各个高斯分量能更加准确的对说话人的声纹特征信息进行描述,然后基于每个说话人的cm模型通过map自适应得到说话人的声纹模型gmm。
在一定程度上来讲,该模型不仅保留了ubm模型的思想,同时又引进了竞争者模型的竞争思想。在ubm-cm-map-gmm模型中,ubm模型仍然代表了说话人语音特征分布的公共特性,同时认为高区分性高斯分量能够更加精确的表征说话人的语音特征信息,借鉴了竞争性思想,从ubm中取出高得分的高斯分量进行组合得到每个说话人的针对性ubm即cm模型,使得该针对性ubm模型与说话人的声纹模型更加逼近,最后基于针对性ubm模型即cm模型自适应得到说话人的声纹模型gmm,所以ubm-cm-map-gmm模型架构是在ubm-map-gmm模型架构的基础上结合竞争者模型进行改进优化的声纹模型。
本发明基于ubm-cm-map-gmm模型的说话人确认方法流程如图2所示,包括:
一、基于ubm-cm-map-gmm模型的说话人确认的个人gmm训练:
基于ubm-cm-map-gmm模型架构的声纹确认方法对声纹模型进行训练过程如图3所示,主要训练思想是对ubm模型中的高斯分量根据训练语音的得分进行高分优先的选取方法,为每个说话人建立自己的cm模型。在训练过程中,首先,采用大量的不同的说话者语音进行训练得到ubm模型,使得该模型表征所有说话人声学特征分布的公共特性;然后利用目标说话人训练语音首先计算每一帧特征矢量在通用背景模型ubm中的每个高斯分量上的得分,在此基础上计算训练语音中所有语音帧在ubm模型每个高斯分量上的得分,根据得分高低选择出前若干个高得分的高斯分量并进行组合得到个人cm,将cm作为训练目标说话人声纹模型的初值;最后,利用该初值基于map训练方法对初始模型进行调整进而得到说话人声纹模型gmm。
在ubm-cm-map-gmm模型中个人gmm的具体计算步骤如下:
1.采用大量不同说话人的语音采用em算法训练得到通用背景模型ubm。
2.利用目标说话人训练语音首先计算每一帧特征矢量xk在通用背景模型ubm中的每个高斯分量λui上的得分pi(xk|λui)。
3.然后计算训练语音中所有语音帧在ubm模型每个高斯分量λui上的得分pi(x|λui),计算公式如下:
其中,xk为训练语音中的第k帧特征矢量;pi(xk|λui)=ωibi(xk|λi),表示第k帧特征矢量在ubm模型第i个高斯分量上的概率bi(xk|λi)与第i个高斯分量混合权重ωi的乘积;li(λui)表示该训练语音在通用背景模型λui中第i个高斯分量上的得分;n表示语音帧的数量。
4.比较通用背景模型λu中所有高斯分量上训练语音x的得分,选出分数最高的前q个高斯分量,并将这q个高斯分量进行组合形成目标说话人的竞争者模型cm。在组合cm的过程中,只需对各个高斯分量的权重进行更新即可。设
5.在训练说话人声纹模型时,首先从模型数据库中查找出目标说话人的cm模型,然后基于cm模型通过map训练方法对cm模型参数进行调整,最终得到说话人的声纹模型gmm。
map自适应算法主要是通过训练语音对cm模型的均值向量进行调整。
当采用从ubm模型中挑选出的高斯分量的组合作cm模型为训练声纹模型的初始值时,随着参与训练声纹模型的高斯分量数的减少,训练语音在cm模型上的总得分也会相应降低,进而导致训练语音与cm模型中的各个高斯分量的后验概率值变大。随着后验概率值得变大,map训练方法中的自适应调整因子也会增大,(由于本文在map自适应过程中只对均值进行调整,因此,在此我们只考虑均值对应的调整因子αim的变化),即均值自适应因子αim变大。调整因子αim的变大,会使得自适应训练的个人声纹模型gmm中包含的cm模型中的语音特征信息越来越少,对cm模型中均值的调整幅度增大,使得声纹模型gmm更加依赖于训练语音,与cm模型差距越来越大,同时,更逼近说话人训练语音声纹特征的分布,训练得到的声纹模型与训练语音越接近,进而准确刻画说话人的语音特征分布信息。
二、基于ubm-cm-map-gmm模型的说话人确认的语音测试:
在基于ubm-cm-map-gmm模型架构的声纹确认系统中,语音测试流程如图4所示。在语音测试阶段,需要计算测试语音在说话人声纹模型gmm上的得分与测试语音在竞争者模型cm上的似然得分。在改进的说话人确认方法中,对于每个已经建立声纹模型的说话人,个人声纹模型gmm和个人竞争者模型cm都已经被存储在了数据库中,因此,在进行语音测试时,首要任务就是将这两个模型从数据库中查找出来,然后基于似然得分,根据系统判决规则输出识别结果。
基于ubm-cm-map-gmm模型架构的声纹确认方法中,在测试阶段,对测试语音的具体测试流程如下:
1.对测试语音预处理并提取特征参数。
2.计算测试语音特征参数在声明说话人声纹模型gmm上的得分。
3.计算测试语音特征参数在声明说话人的竞争者模型cm上的得分。
4.计算测试语音特征参数在gmm和cm上得分的比值并取对数,作为测试语音的最终得分。
5.将测试语音的最终得分与声纹识别系统设置的阈值进行比较并作出判决,进而得出声纹识别系统最终的识别结果。
- 还没有人留言评论。精彩留言会获得点赞!