语音识别装置和语音识别方法与流程
本发明涉及语音识别装置和语音识别方法。
背景技术:
近年来,识别语音并生成文本数据的语音识别装置已经得到实用化。在识别语音并生成文本数据的情况下,语音识别装置有可能产生错误识别。例如,如日本特表2005-507536号公报所记载,公开了修正所识别的文本的技术。
技术实现要素:
根据日本特表2005-507536号公报所记载的技术,修正由于错误识别而产生的文本的修正员通过阅读文本文件并且听取语音,修正被估计为具有缺陷或者不适当的文本段。即,由于需要通过手动作业修正文本,因此存在花费功夫的课题。
本发明的目的在于提供一种能够简单且高精度地识别语音的语音识别装置和语音识别方法。
一个实施方式的语音识别装置具有:取得部,其取得对人发出的语音进行录音而得到的音频流、以及拍摄所述人的至少嘴部而得到的视频流;语音识别部,其根据所述音频流,识别包含所述人发出的辅音在内的语音;辅音估计部,其根据所述视频流的所述人的嘴部的形状,估计所述人发出的辅音;以及辅音确定部,其根据由所述辅音估计部估计出的辅音和由所述语音识别部识别出的辅音,来确定辅音。
根据本发明,可提供一种能够简单且高精度地识别语音的语音识别装置和语音识别方法。
附图说明
图1是用于说明一个实施方式的语音识别装置的结构例的说明图。
图2是用于说明一个实施方式的语音识别装置的拍摄部和语音收集部的配置的例子的说明图。
图3是用于说明一个实施方式的语音识别装置的动作的例子的说明图。
图4是用于说明一个实施方式的语音识别装置的语音识别处理的例子的说明图。
图5是用于说明确定一个实施方式的语音识别装置的辅音发声帧的处理的例子的说明图。
图6是用于说明一个实施方式的语音识别装置的辅音确定处理的例子的说明图。
图7是用于说明一个实施方式的语音识别装置中的项目列表的例子的说明图。
图8是用于说明由一个实施方式的语音识别装置显示的按项目语音识别画面的例子的说明图。
图9是用于说明一个实施方式的语音识别装置的按项目语音识别处理的例子的说明图。
图10是用于说明一个实施方式的语音识别装置的引导显示的例子的说明图。
标号说明
1:语音识别装置;11:CPU;12:ROM;13:RAM;14:非易失性存储器;15:通信部;16:拍摄部;17:语音收集部;18:显示部;19:语音再现部;20:钟表部;21:姿势传感器;22:操作部。
具体实施方式
以下,参照附图对一个实施方式的语音识别装置和语音识别方法详细地进行说明。
图1是示出一个实施方式的语音识别装置1的例子的说明图。语音识别装置1是进行语音的录音、影像的录制和语音的识别的终端。另外,在图1中示出进行语音的录音、影像的录制和语音的识别的结构为一体的例子,但是进行语音的录音和影像的录制的结构和进行语音的识别的结构可以分开。即,语音识别装置的进行语音的录音和影像的录制的结构可以是进行语音的录音和影像的录制并生成文件的记录器(例如IC记录器等)。此外,语音识别装置的进行语音的识别的结构可以构成为放置在云端上并根据所取得的文件来进行语音识别的程序。
语音识别装置1通过进行语音的录音,生成音频流。音频流是表示时间上连续的语音的数据。此外,语音识别装置1通过进行影像的录制,生成视频流。视频流是表示时间上连续的影像(图像)的数据。语音识别装置1使音频流与视频流同步,生成动态图像文件。并且,语音识别装置1根据上述动态图像文件来进行语音识别,生成与人发出的语言对应的文本数据。
如图1所示,语音识别装置1具有CPU 11、ROM 12、RAM 13、非易失性存储器14、通信部15、拍摄部16、语音收集部17、显示部18、语音再现部19、钟表部20、姿势传感器21和操作部22。
CPU 11是执行运算处理的运算元件(例如,处理器)。CPU 11根据在ROM 12中所存储的程序等数据,进行各种处理。CPU 11作为通过执行在ROM 12中所存储的程序而能够执行各种动作的控制部发挥功能。例如,CPU 11通过控制各个部,进行语音的录音、影像的录制和语音的识别。
ROM 12是只读非易失性存储器。ROM 12存储程序和在程序中使用的数据等。
RAM 13是作为工作存储器发挥功能的易失性存储器。RAM 13临时存储CPU 11的处理中的数据等。此外,RAM 13临时存储CPU 11执行的程序。
非易失性存储器14是可存储各种信息的存储介质。非易失性存储器14存储程序以及在程序中使用的数据等。非易失性存储器14例如是固态驱动器(SSD)、硬盘驱动器(HDD)或者其他存储装置。另外,可以设置有能够插入存储卡等存储介质的卡槽等存储器I/F,替代非易失性存储器14。
通信部15是用于与其他设备进行通信的接口。通信部15具有用于与其他设备电连接的端子或者用于与其他设备进行无线通信的通信电路。端子例如是USB端子、LAN连接器或者其他任意有线连接用的端子。通信电路例如具有用于根据Bluetooth(注册商标)或者Wi-Fi(注册商标)等标准而与其他设备进行无线通信的天线、以及信号处理电路。通信部15可以是如下结构:从其他设备接收用于控制语音识别装置1的控制信号,供给到CPU 11。
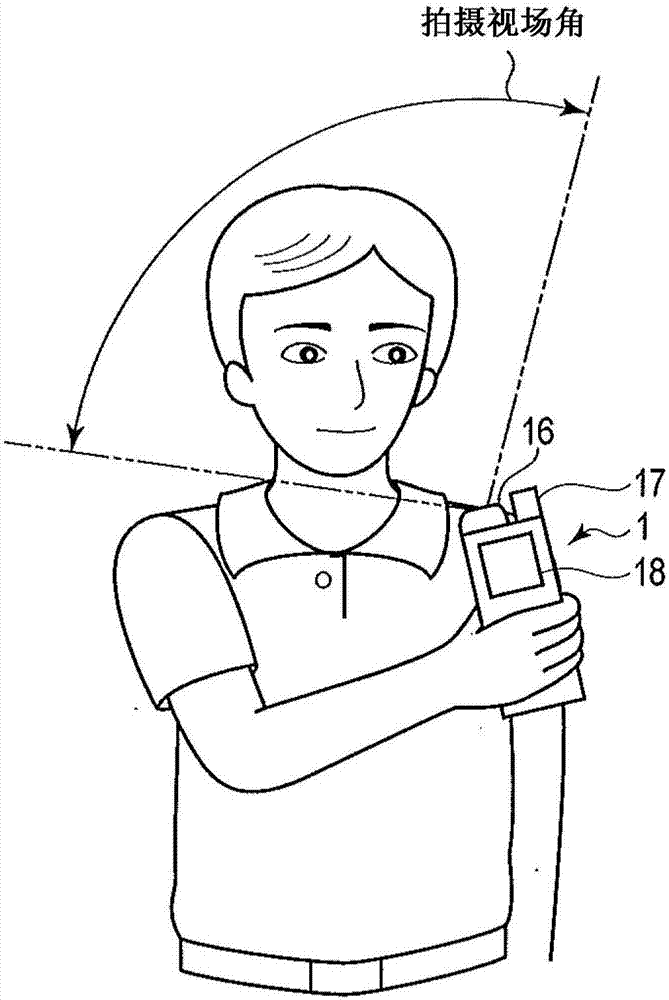
拍摄部16具有取得(拍摄)数字的图像数据的照相机。此外,拍摄部16通过连续取得图像数据,取得图像数据在时间上连续的视频流。视频流具有以1张图像为1个帧的多个帧。拍摄部16具有摄像元件、以及使光在摄像元件上成像的光学系统。
摄像元件具有排列多个像素而构成的摄像面,该像素对光进行光电变换并蓄积电荷。像素生成与入射的光的光量对应的电信号。摄像元件例如由CCD(Charge Coupled Device;电荷耦合器件)图像传感器、CMOS(Complementary Metal Oxide Semiconductor:互补性金属氧化物半导体)图像传感器或者其它摄像元件构成。在排列在摄像面上的多个像素的光所入射的面上设置有滤色器。摄像元件利用设置有不同颜色的滤色器的多个像素,生成彩色的图像信号。
光学系统是组合了多个镜头的合成镜头。光学系统使来自与合成镜头的焦距对应的拍摄视场角内的被摄体的光在摄像元件的摄像面上成像。光学系统例如可以具有焦点调节用的镜头(对焦镜头)。此外,光学系统例如也可以具有焦距调节用的镜头(变焦镜头)。
拍摄部16读出由摄像元件的多个像素生成的电信号,并将电信号转换为数字信号,由此取得数字的图像数据。此外,拍摄部16连续读出由摄像元件的多个像素生成的电信号,并将电信号转换为数字信号,由此生成视频流。
语音收集部17具有取得(录制)语音的麦克风。此外,语音收集部17通过连续取得语音,取得语音在时间上连续的音频流。语音收集部17将语音转换为模拟的电信号,并将电信号转换为数字信号,由此取得数字的语音数据。语音收集部17根据所取得的语音数据,生成音频流。即,拍摄部16和语音收集部17作为取得视频流和音频流的取得部发挥功能。
显示部18具有显示画面的显示装置。显示部18根据从CPU 11或者未图示的图形控制器等显示控制部输入的影像信号,将画面显示在显示装置上。
语音再现部19具有对语音进行再现的扬声器。语音再现部19根据从CPU 11或者未图示的语音控制器等语音控制部输入的语音信号,从扬声器输出语音。
钟表部20用于计测时刻。钟表部20向CPU 11供给当前时刻或者与经过时间等时间相关的信息。
姿势传感器21是检测语音识别装置1的未图示的壳体的姿势的传感器。姿势传感器21向CPU 11供给壳体的姿势的检测结果。例如,姿势传感器21是检测壳体的旋转运动的角速度传感器。此外例如,姿势传感器21可以是检测壳体相对于重力方向的朝向和壳体的移位的加速度传感器。
操作部22根据操作部件的操作,生成操作信号。操作部件例如是操作键或者触摸传感器等。触摸传感器取得表示在某一区域内所指定的位置的信息。触摸传感器通过与上述显示部18一体地构成为触摸面板,将表示显示部18上所显示的画面上的被触摸的位置的信号输入到CPU 11。
CPU 11通过执行在ROM 12或者非易失性存储器14等中所存储的程序,使语音识别装置1执行录音处理、语音识别处理、按项目语音识别处理和辞典更新处理等。之后对按项目语音识别处理的项目进行叙述。
录音处理是由语音识别装置1取得音频流和视频流的处理。在进行录音处理的情况下,CPU 11利用语音收集部17生成音频流,利用拍摄部16生成视频流,根据音频流和视频流来生成动态图像文件,将动态图像文件记录到非易失性存储器14中。另外,动态图像文件的视频流可以不在从开始到结束之间与音频流同步。动态图像文件的视频流只要是至少在人发出语音的期间内被录制的即可。例如,CPU 11可以是由通信部15等取得部从外部取得视频流和音频流的结构。
并且,CPU 11也可以是如下结构:在语音识别装置1取得音频流和视频流的情况下,督促拍摄嘴部。例如,CPU 11可以是如下结构:从显示部18或者语音再现部19输出督促将拍摄部16的镜头朝向嘴部的信息。此外并且,CPU 11也可以是如下结构:根据视频流来判定是否拍摄了人的至少嘴部,在未拍摄到人的嘴部的情况下,促使拍摄嘴部。
例如图2所示,拍摄部16的镜头和语音收集部17的麦克风设置在语音识别装置1的壳体的同一面上。假设人在手持着语音识别装置1的状态下发出语音的情况下,将语音收集部17的麦克风朝向嘴部。拍摄部16的镜头设置于与语音收集部17的麦克风相同的面上,由此在将语音收集部17的麦克风朝向了嘴部的情况下,拍摄部16的镜头也朝向人的嘴部。即,如图2所示,在语音识别装置1的拍摄部16的镜头朝向了人的嘴部的情况下,拍摄部16的拍摄视场角中拍摄到人的嘴部。CPU 11通过进行图像识别,判断视频流的帧中是否拍摄到人的嘴部。此外,CPU 11根据姿势传感器21的检测结果,判断是否拍摄到人的嘴部。例如,在由姿势传感器21检测出语音识别装置1的拍摄部16的镜头的光轴比水平更朝向下方的情况下,CPU 11可以判断为未拍摄到人的嘴部。此外,例如,在由姿势传感器21检测出语音识别装置1的拍摄部16的镜头的光轴朝向铅直的情况下,CPU 11可以判断为未拍摄到人的嘴部。
语音识别处理是根据音频流和视频流来生成与人发出的语言对应的文本数据的处理。在进行语音识别处理的情况下,CPU 11对音频流的语音的波形与预先存储的声学模型进行比较,识别元音和辅音等。即,CPU 11作为根据音频流来识别包含人发出的辅音在内的语音的语音识别部发挥功能。
声学模型例如是按照元音和辅音等的语音的每个要素而预先生成的语音的波形。声学模型预先存储到非易失性存储器14或者ROM 12等中。例如,CPU 11对音频流的语音的波形与声学模型的波形进行比较,识别与类似度高的声学模型对应的元音和辅音等。另外,语音识别装置1例如可以是将按照每个语言或者每个项目而不同的多个声学模型预先存储到非易失性存储器14中的结构。
并且,CPU 11根据视频流,识别进行发声的情况下的人的嘴部的形状变化。CPU11根据识别出的嘴部的形状变化,估计人发出的辅音。例如,CPU 11对识别出的嘴部的形状变化与预先存储的嘴形模型进行比较,估计人发出的辅音。即,CPU 11作为根据视频流的人的嘴部的形状来估计人发出的辅音的辅音估计部发挥功能。CPU11使用辅音的估计结果,修正基于音频流的辅音的识别结果。即,CPU 11作为根据辅音的估计结果和基于音频流的辅音的识别结果来确定辅音的辅音确定部发挥功能。
嘴形模型例如表示每个辅音的嘴部的形状变化。嘴形模型预先存储到非易失性存储器14中。例如,CPU 11对识别出的嘴部的形状变化与嘴形模型表示的嘴部的形状变化进行比较,将与类似度高的嘴形模型对应的辅音估计为人发出的辅音。另外,语音识别装置1例如也可以是将按照每个语言或者每个项目而不同的多个嘴形模型预先存储到非易失性存储器14中的结构。此外,嘴形模型例如也可以还包含表示每个元音的嘴部的形状变化的嘴形模型。在该情况下,CPU 11可以对识别出的嘴部的形状变化与嘴形模型表示的嘴部的形状变化进行比较,将与类似度高的嘴形模型对应的母音估计为人发出的母音。例如,在如外语那样平时不使用的语言的教材等中具有使用视频、照片、插图等进行了说明的内容,但这样的图像数据等能够直接用作估计时的示教图像。通过这样的示教图像进行了深层学习的结果是,可以进行上述估计时的判断。
并且,CPU 11根据元音和辅音的识别结果以及预先存储的辞典(单词识别辞典)来识别单词,根据单词的识别结果来生成文本数据。
单词识别辞典是将单词与辅音和元音的组合对应起来而得到的。单词识别辞典预先存储到非易失性存储器14中。CPU 11通过参照单词识别辞典,能够根据辅音和元音的组合来识别单词。即,CPU 11通过参照单词识别辞典,从单词识别辞典中取得与元音和辅音的识别结果对应的单词。另外,语音识别装置1也可以是按照每个语言或者每个项目将不同的多个单词识别辞典预先存储到非易失性存储器14中的结构。例如,语音识别装置1也可以是按照每个项目将多个不同的单词识别辞典预先存储到非易失性存储器14中的结构。
按项目语音识别处理是按照预先设定的每个项目进行录音处理和语音识别处理的处理。项目表示识别对象的语音的种类。项目根据语音识别装置1被应用的领域而适当设定。例如,在语音识别装置1用于医疗领域的口授的情况下,项目是姓名、年龄、性别、患部、诊察结果和日期等。这些项目可以是预先存储的项目,也可以是根据操作部22的操作而生成的项目。这些项目作为项目列表存储到语音识别装置1中。之后对项目列表进行叙述。此外,根据项目,所发出的辅音、元音、单词等存在偏差。因此,如上所述,可以按照每个项目预先存储有单词识别辞典、嘴形模型和声学模型。
在进行按项目语音识别处理的情况下,CPU 11按照每个预先设定的项目督促发声,按照每个项目由语音识别装置1取得音频流和视频流。CPU 11根据音频流、视频流以及与项目对应的辞典,识别人发出的单词。
具体而言,CPU 11选择预先设定的多个项目中的1个项目。CPU 11从显示部18或者语音再现部19输出督促将拍摄部16的镜头朝向嘴部的信息和表示所选择的项目的信息,利用拍摄部16和语音收集部17取得音频流和视频流。
CPU 11对音频流的语音的波形与预先存储的声学模型进行比较,识别元音和辅音等。CPU 11根据视频流,识别进行发声的情况下的人的嘴部的形状变化。CPU 11根据识别出的嘴部的形状变化和嘴形模型,估计人发出的辅音。CPU 11使用辅音的估计结果,修正基于音频流的辅音的识别结果。
CPU 11根据元音和辅音的识别结果和单词识别辞典来识别单词,根据单词的识别结果来生成文本数据。在该情况下,CPU 11参照与所选择的项目对应的单词识别辞典,识别与元音和辅音的识别结果对应的单词,根据单词的识别结果来生成文本数据。
辞典更新处理是进行上述的单词识别辞典、声学模型和嘴形模型等的更新的处理。例如,在经由通信部15从其他设备接收到了单词识别辞典、声学模型和嘴形模型的情况下,CPU 11将接收到的单词识别辞典、声学模型和嘴形模型覆盖到在非易失性存储器14中存储的单词识别辞典、声学模型和嘴形模型。另外,单词识别辞典、声学模型和嘴形模型也可以单独地进行更新。此外,在无需单词识别辞典、声学模型和嘴形模型的更新的情况下,单词识别辞典、声学模型和嘴形模型可以不存储到非易失性存储器14,而是存储到ROM 12中。
图3是示出语音识别装置1的动作的例子的流程图。语音识别装置1的CPU 11根据操作部22的操作或者经由通信部15而输入的控制信号,执行各种动作。
首先,CPU 11判断是否执行录音处理(步骤S11)。在由操作部22输入了执行录音处理的操作的情况或者通过通信部15输入了对执行录音处理进行指示的信息的情况下,CPU 11判断为执行录音处理。在判断为执行录音处理的情况下(步骤S11:是),CPU 11执行利用拍摄部16和语音收集部17取得音频流和视频流的录音处理(步骤S12)。
接着,CPU 11判断是否执行语音识别处理(步骤S13)。在由操作部22输入了执行语音识别处理的操作的情况或者通过通信部15输入了对执行语音识别处理进行指示的信息的情况下,CPU 11判断为执行语音识别处理。在判断为执行语音识别处理的情况下(步骤S13:是),CPU 11根据取得的音频流和视频流,执行语音识别处理(步骤S14)。
接着,CPU 11判断是否执行按项目语音识别处理(步骤S15)。在由操作部22输入了执行按项目语音识别处理的操作的情况或者通过通信部15输入了对执行按项目语音识别处理进行指示的信息的情况下,CPU 11判断为执行按项目语音识别处理。在判断为执行按项目语音识别处理的情况下(步骤S15:是),CPU 11执行如下的按项目语音识别处理:由拍摄部16和语音收集部17按照每个项目取得音频流和视频流,根据取得的音频流和视频流,按照每个项目来解析语音(步骤S16)。
接着,CPU 11判断是否执行辞典更新处理(步骤S17)。在判断为执行辞典更新处理的情况下(步骤S17:是),CPU 11利用经由通信部15而取得的单词识别辞典、声学模型和嘴形模型等,执行辞典更新处理(步骤S18)。
在执行了录音处理的情况、执行了语音识别处理的情况、执行了按项目语音识别处理的情况或者在步骤S17中判断为不执行辞典更新处理的情况下(步骤S17:否),CPU 11结束处理。此外,在执行了录音处理的情况、执行了语音识别处理的情况、执行了按项目语音识别处理的情况或者在步骤S17中判断为不执行辞典更新处理的情况下(步骤S17:否),CPU 11也可以返回步骤S11的处理。
图4是示出语音识别装置1执行的语音识别处理的例子的流程图。另外,这里示出语音识别装置1根据已经通过录音处理生成的动态图像文件的音频流和视频流来进行语音识别的例子。但是,录音处理和语音识别也可以同时进行。即,语音识别装置1也可以是根据通过录音处理而依次生成的音频流和视频流来进行语音识别处理的结构。
首先,语音识别装置1的CPU 11取得音频流(步骤S21)。例如,CPU 11通过再现动态图像文件,取得音频流。
CPU 11取得视频流(步骤S22)。例如,CPU 11通过再现动态图像文件,取得视频流。
CPU 11根据所取得的音频流,进行语音识别(步骤S23)。例如,CPU 11对音频流的语音的波形与声学模型进行比较,识别元音和辅音等。
CPU 11进行如下的辅音确定处理:根据基于音频流的元音和辅音的识别结果、以及视频流,确定辅音(步骤S24)。由此,CPU 11从音频流和视频流中识别元音和辅音。
以下,对辅音确定处理进行说明。
元音和辅音根据舌头的形状、嘴唇的形状和额的开闭度等而发生变化。元音是能够伴随声带的震动而持续一定时间的有声语音。辅音是通过在嘴部中妨碍空气的流动而发出的语音。例如,日语的音韵由无声爆破音、无声破擦音、无声摩擦音、鼻音、半元音或者流音等辅音、元音构成。
元音根据舌头的形状、嘴唇的形状和额的开闭度等而确定。与此相对,辅音根据用于改变嘴中的空气的流动的舌头的运动和形状、下巴的运动和形状以及气息的控制等随时间的变化而确定。因此,根据元音的发声时的嘴唇的形状来确定元音比辅音的确定更容易。
此外,作为利用气息的控制进行区分的辅音的例子,有利用持续时间的长短进行区分的长辅音和短辅音等。此外,作为利用气息的控制进行区分的辅音的例子,有由于瞬间猛烈的气息而产生的爆破音和浊音。这样的气息的控制有时根据语言、地域差异和个人差异等而不同。因此,人有可能无法准确地进行气息的控制。例如,即便同样是日本人,根据地方的不同,有时未准确区分“h”和“c”、“l”和“r”等辅音。此外,例如,在某一人发出母语中未被区分的辅音的情况下,有时难以模拟母语者的舌头的运动和形状、额的运动和形状以及气息的控制。因此,在人为了想强调辅音的不同而发声的情况下,人的表情有可能发生变化(僵硬等)。即,通过控制舌头或下巴或气息的随时间变化,不仅嘴部的形状,而且面部全体的表情、以及姿势的变化也容易引起空气的流动,考虑这样的图像的变化信息而读取发声者的意图是非常重要且有效的,因此,在元音的判定基础上考虑进图像的判定会起到效果。
根据如上所述的理由,仅通过语音难以准确识别辅音和元音。因此,语音识别装置1通过解析从头辅音到元音的过程,提高辅音的识别的准确性。
例如,在某一人发出母语中未被区分的辅音(例如“l”和“r”)的情况下,假设在使嘴部放松的状态下发出“l”,在使嘴唇突出的状态发出“r”。在这样的情况下,有时在语音中难以区分“l”与“r”的差异。但是,如上所述,估计“l”和“r”舌头的形状、嘴唇的形状和额的开闭度等上不同。因此,语音识别装置1通过使用从辅音的发声到元音的发声的辅音发声帧来解析人的嘴部的形状变化,提高辅音的识别的准确性。当然,作为嘴部形状的变化的部分不仅是一瞬间的嘴形的离散的时间序列变化,也可以是连续的变化、直到变为特定的嘴部形状为止的图像变化的过程、嘴部的变化,还可以是面部的下半部分的变化,也可以是如是否使面部僵硬等面部全体的变化、表情的变化这样的图像变化。如上所述,不仅使用对嘴部等的发声重要的部位的基本变化,也可以使用嘴部的附近或协作地运动的人体部位的图像。在嘴部的特定部分的阴影或对比度不足而不能完全判定该变化图像的情况下,也可以并用或者代用额部分的图像、嘴部的周围的褶皱、下垂的情况、面部的僵硬的阴影变化等。形状变化多数时候是元音等向特定形状的收敛过程,但有时伴随振幅或振动。并且,也可以一并采用各种各样的因数或数值,或者根据特定的状况而代用其他图像解析方法。此外,也可以对面部的特定部位照射特定的图案光,观察其变化。在如日语那样在辅音之后接着元音的情况较多的语言中,可以重视到元音的过程,但以辅音结束的语言也较多。在该情况下,也可以在不依赖元音的情况下检测振动或上下唇的打开方式、形状,来对声带进行类推。在该情况下,说话者尝试将舌尖放到上前牙的后牙龈或上前牙的前端的、仅用舌前端控制空气的流动等,因此只要能够根据嘴部的间隙等检测舌头的位置的图像,则是可靠的,但也可以根据表情进行推测。
图5是用于说明确定辅音发声帧的处理的说明图。图5的(a)和(b)的横轴表示时间。这里,为了简单说明上述变化中的基本部位的基本考虑方法,用如嘴部的开口面积的观点进行了说明,但也可以进一步一并采用各种各样的因数或数值,或者根据特定的状况而代用其他图像解析方法。如果这样的图像部位或变量变多,则还具有利用人工智能的深层学习等的方法,但以能够使用流程图或转变图等进行说明的方式特意进行简单的说明。图5的(a)的纵轴表示人的嘴部的开口面积。即,图5的曲线图41表示人将某一音韵发声为“ra”的情况下的人的嘴部的开口面积的变化。图5的(b)的纵轴表示人将某一音韵发声为“ra”的情况下的人的嘴部的横宽与纵宽之比。例如,图5的(b)的纵轴表示人的嘴部的纵宽与横宽之比。即,图5的曲线图42表示人的嘴部的横宽与纵宽之比的变化。即,图5的曲线图41和曲线图42表示人的嘴部的形状变化。此外,图5的(c)示出至少拍摄到了进行发声的人的嘴部的帧连续的视频流的例子。
首先,CPU 11检测元音。CPU 11例如根据音频流和声学模型来检测元音。此外,CPU 11也可以是根据视频流和嘴形模型来检测元音的结构。此外,CPU 11也可以是根据视频流来检测进行发声的人的喉咙的震动并根据检测出的喉咙的震动来检测元音的结构。如上所述,不仅可以使用嘴部等对发声重要的部位的基本变化,也可以使用嘴部的附近或协作地运动的人体部位的图像,这里,使用了喉咙。但是,喉咙有时不具有对比度,变化也小,因此在不能完全判定其震动图像的情况下,可以用额部分的图像、嘴部的周围的褶皱、下垂的程度、面颊的变化、面部的僵硬的阴影变化等代用。这里用如振动这样的观点进行了说明,但未必一定需要多次引起振幅,也包含1次的振幅变化等。除了该振幅或振动以外,也可以一并采用各种各样的因数或数值,或者根据特定的状况而代用其他图像解析方法。此外,也可以对喉咙、嘴角或脸颊等照射特定的图案光,观察其变化。这样,不仅使用语音的信息,还并用图像信息来判定元音。
例如,假设在定时t2,检测出元音(在本例子中为“a”)。在该情况下,CPU 11根据从比定时t2靠前的定时t1到定时t2之间的视频流,确定辅音发声帧。CPU 11从定时t1到定时t2的帧中确定至少1个以上的帧,作为发出了辅音(在本例子中为“r”)的辅音发声帧。另外,CPU 11也可以是如下结构:确定从定时t1到定时t2的全部帧作为辅音发声帧。
定时t1例如是比定时t2靠前规定时间的定时。定时t1可以是CPU 11根据视频流而决定的定时。例如,CPU 11将从定时t2起规定时间以内且开口面积成为了规定值以上的定时决定为定时t1。此外,例如,CPU 11也可以将从定时t2起规定时间以内且嘴部的横宽与纵宽之比成为了规定值以上的定时决定为定时t1。此外,例如,CPU 11也可以从音频流中检测从定时t2起规定时间以内且录音了规定音量以上的语音的定时,将检测出的定时决定为定时t1。此外,例如,CPU 11也可以将比以下的各个定时中的任意定时靠前规定时间的定时决定为定时t1:从定时t2起规定时间以内且开口面积成为了规定值以上的定时、嘴部的横宽与纵宽之比成为了规定值以上的定时和录音了规定的音量以上的语音的定时。推测开口面积成为了规定值以上的定时、嘴部的横宽与纵宽之比成为了规定值以上的定时和录音了规定音量以上的语音的定时分别接近人开始发声的定时。因此,通过如上所述决定定时t1,能够将人开始发声的定时作为辅音发声帧的起始。
图6是用于说明与图4的步骤S26对应的辅音确定处理的说明图。
CPU 11根据基于音频流的语音识别的结果,检测与元音对应的定时(步骤S41)。
CPU 11根据与检测出的元音对应的定时,确定辅音发声帧,该辅音发声帧是视频流中的被估计发出了辅音的帧(步骤S42)。
CPU 11识别所确定的辅音发声帧中的人的嘴部的形状变化,根据识别出的人的嘴部的形状变化以及嘴形模型,估计辅音(步骤S43)。CPU 11对识别出的嘴部的形状变化与嘴形模型表示的嘴部的形状变化进行比较,将与类似度高的嘴形模型对应的辅音估计为人发出的辅音。
嘴部的形状变化可以是1个辅音发声帧中的开口面积,也可以是1个辅音发声帧中的嘴部的横宽与纵宽之比,也可以是组合了1个辅音发声帧中的开口面积和嘴部的横宽与纵宽之比并进行了数值化而得到的值。
此外,嘴部的形状变化可以表示多个辅音发声帧中的开口面积的变化,也可以表示多个辅音发声帧中的嘴部的横宽与纵宽之比的变化,也可以是组合了多个辅音发声帧中的开口面积的变化和嘴部的横宽与纵宽之比的变化并进行了数值化而得到的值。
CPU 11对基于嘴部的形状变化的辅音的估计结果与基于语音识别的辅音的识别结果进行比较(步骤S44)。
CPU 11判断基于嘴部的形状变化的辅音的估计结果与基于语音识别的辅音的识别结果的比较结果是否为一致(步骤S45)。
在判断为基于嘴部的形状变化的辅音的估计结果与基于语音识别的辅音的识别结果的比较结果为一致的情况下(步骤S45:是),CPU 11根据一致的比较结果,确定辅音(步骤S46)。即,CPU 11采用基于嘴部的形状变化的辅音的估计结果和基于语音识别的辅音的识别结果,确定辅音,结束辅音确定处理。
在判断出基于嘴部的形状变化的辅音的估计结果与基于语音识别的辅音的识别结果的比较结果为不一致的情况下(步骤S45:否),CPU 11采用基于嘴部的形状变化的辅音的估计结果和基于语音识别的辅音的识别结果中的任意一方来确定辅音(步骤S47),结束辅音确定处理。另外,CPU 11采用基于嘴部的形状变化的辅音的估计结果与基于语音识别的辅音的识别结果中预先设定的一方。此外,CPU 11也可以是如下结构:在进行基于嘴部的形状变化的辅音的估计和基于语音识别的辅音的识别时,按照每个辅音计算得分(score),按照每个辅音对计算出的得分进行相加,根据相加所得的得分来确定辅音。
此外,在语音识别装置1为按照每个语言或者每个项目存储不同的多个嘴形模型的结构的情况下,CPU 11也可以是如下结构:判断识别对象的语音的语言或者项目,使用与判断出的语言或者项目对应的嘴形模型来执行步骤S43的处理。
另外,CPU 11根据操作部22的操作输入或者经由通信部15而从其他设备供给的信息等,判断识别对象的语音的语言或者项目。
在完成上述的辅音确定处理后,CPU 11转移到图4的步骤S25的处理。即,CPU11根据通过语音识别而识别出的元音和通过辅音确定处理而确定出的辅音,判断是否能够识别单词(步骤S25)。例如,CPU 11根据通过语音识别而识别出的元音和通过辅音确定处理而确定出的辅音、以及单词识别辞典,判断是否能够识别单词。具体而言,CPU 11参照单词识别辞典,判断能否从单词识别辞典取得与通过语音识别而识别出的元音和通过辅音确定处理而确定出的辅音的组合对应的单词。
在判断为根据通过语音识别而识别出的元音和通过辅音确定处理而确定出的辅音无法识别单词的情况下(步骤S25:否),CPU 11转移到步骤S21的处理,再次执行步骤S21至步骤S25。
此外,在判断为根据通过语音识别而识别出的元音和通过辅音确定处理而确定出的辅音能够识别单词的情况下(步骤S25:是),CPU 11通过从单词识别辞典取得与通过语音识别而识别出的元音和通过辅音确定处理而确定出的辅音对应的单词,识别单词(步骤S26)。
CPU 11根据单词的识别结果,生成文本数据(步骤S27)。
CPU 11判断是否结束语音识别处理(步骤S28)。在判断为不结束语音识别处理的情况下(步骤S28:否),CPU 11转移到步骤S21的处理,再次执行步骤S21至步骤S27。
在判断为结束语音识别处理的情况下(步骤S28:是),CPU 11结束图4的语音识别处理。例如,在进行了语音识别处理直至音频流和视频流的结尾的情况下,CPU11判断为结束语音识别处理。此外,在输入了结束语音识别处理的操作的情况下,CPU 11判断为结束语音识别处理。
另外在语音识别装置1为按照每个语言或者每个项目存储不同的多个声学模型的结构的情况下,CPU 11也可以是如下结构:判断识别对象的语音的语言或者项目,使用与判断出的语言或者项目对应的声学模型来执行步骤S23的处理。
此外,在语音识别装置1为按照每个语言或者每个项目存储不同的多个单词识别辞典的结构的情况下,CPU 11也可以是如下结构:判断识别对象的语音的语言或者项目,使用与判断出的语言或者项目对应的单词识别辞典来执行步骤S27和步骤S26的处理。
另外,CPU 11根据操作部22的操作输入或者经由通信部15而从其他设备供给的信息等,判断识别对象的语音的语言或者项目。
根据上述结构,语音识别装置1从音频流中识别辅音和元音,根据基于音频流的元音的识别结果来确定在与音频流同步的视频流中发出辅音的辅音发声帧。并且,语音识别装置1根据辅音发声帧中的人的嘴部形状的变化,估计人发出的辅音。由此,语音识别装置1能够根据基于音频流的辅音的识别结果和基于视频流的辅音的估计结果,确定辅音。其结果,语音识别装置1能够提高语音识别的精度。
接着,对按项目语音识别处理进行说明。
说明作为语音识别装置1是根据依次生成的音频流和视频流来进行按项目语音识别处理的结构。因此,语音识别装置1预先存储项目列表,该项目列表表示进行按项目语音识别处理的项目。如上所述,项目表示识别对象的语音的种类。项目列表表示识别对象的语音的种类的一览、即项目的一览。项目列表可以是预先存储的,也可以是根据操作部22的操作而生成的。此外,项目列表构成为能够根据操作部22的操作进行修正。
图7示出项目列表的例子。在本例子中,对语音识别装置1用于医疗领域的口授的例子进行说明。如图7所示,项目例如是姓名、年龄、性别、患部、诊察结果和日期等。
此外,例如,对项目列表中的项目设定了优先级。在图7的例子中,按照姓名、年龄、性别、患部、诊察结果、日期的顺序设定了从高到低的优先级。例如,CPU 11按照优先级从高到低的顺序进行语音识别处理。
此外,例如,对项目列表中的各项目对应有各种特征。例如,与项目列表中的各项目对应的特征是表示该项目是怎样的项目的信息(第1特征)。例如,第1特征是用于使CPU 11判断识别结果的单词是否是适当的单词的信息。在判断为识别结果的单词是与第1特征的设定对应的单词的情况下,CPU 11判断为识别结果的单词是适当的。例如,在项目是“姓名”的情况下,无法使CPU 11判断单词是否是适当的单词,因此第1特征设定为空白。此外,例如,在项目是“年龄”的情况下,作为第1特征,设定了表示年龄的数字等。此外,例如,在项目是“性别”的情况下,作为第1特征,设定了表示性别的单词。此外,例如,在项目是“患部”的情况下,作为第1特征,设定了表示患部的特定单词(即表示患部的列表的患部辞典)。此外,例如,在项目是“诊察结果”的情况下,作为第1特征,设定了表示诊察结果的特定单词(即按照科室类别设定了诊察结果的列表的科室类别辞典)。此外,例如,在项目是“日期”的情况下,作为第1特征,设定了表示日期的单词。
此外,例如,与项目列表中的各项目对应的特征是表示对该项目进行录音处理的时间的信息(第2特征)。在对某一项目进行录音处理的情况下,CPU 11仅在与该项目对应的第2特征表示的时间内进行录音处理。例如,在项目是“姓名”的情况下,作为第2特征,设定了“最大5秒”。此外,例如,在项目是“年龄”的情况下,作为第2特征,设定了“最大1秒”。此外,例如,在项目是“性别”的情况下,作为第2特征,设定了“最大1秒”。此外,例如,在项目是“患部”的情况下,作为第2特征,设定了“最大2秒”。此外,例如,在项目是“诊察结果”的情况下,作为第2特征,设定了“最大数量”。此外,例如,在项目是“日期”的情况下,作为第2特征,设定了“最大1秒”。
此外,例如,与项目列表中的各项目对应的特征是表示该项目的单词数和音节数等的信息(第3特征)。例如,第3特征是用于使CPU 11判断识别结果的单词是否是适当的单词的信息。在判断为识别结果的单词数和音节数与第3特征的设定对应的情况下,CPU 11判断为识别结果的单词是适当的。例如,在项目是“姓名”的情况下,作为第3特征,设定了“直到单词几个、音节几个为止”。此外,例如,在项目是“年龄”的情况下,作为第3特征,设定了“直到单词3个、音节3个为止”。此外,例如,在项目是“性别”的情况下,作为第3特征,设定了“直到单词1个、音节2个为止”。此外,例如,在项目是“患部”的情况下,作为第3特征,设定了“直到单词几个、各单词的音节几个为止”。此外,例如,在项目是“诊察结果”或者“日期”的情况下,难以通过单词数和音节数判断识别结果是否适当,因此作为第3特征,设定了空白(无限定)。
在执行按项目语音识别处理的情况下,CPU 11与上述项目列表相应地将用于执行按项目语音识别处理的画面(按项目语音识别画面)51显示在显示部18上。
图8示出按项目语音识别画面51的例子。按项目语音识别画面51具有第1显示栏52、第2显示栏53、第3显示栏54、第4显示栏55、第5显示栏56、第6显示栏57、第7显示栏58、第8显示栏59、开始按钮60、第1指示器61、第2指示器62、第3指示器63、第4指示器64、第5指示器65、第6指示器66、上传按钮67和结束按钮68等显示。第1显示栏52、第2显示栏53、第3显示栏54、第4显示栏55、第5显示栏56、第6显示栏57、第7显示栏58、第8显示栏59、开始按钮60、第1指示器61、第2指示器62、第3指示器63、第4指示器64、第5指示器65、第6指示器66、上传按钮67和结束按钮68分别以能够利用操作部22进行选择操作的状态显示在按项目语音识别画面51上。
CPU 11与项目列表中包含的项目相应地将第1显示栏52、第2显示栏53、第3显示栏54、第4显示栏55、第5显示栏56和第6显示栏57显示在按项目语音识别画面51上。另外,这里,对CPU 11根据图7所示的项目列表来显示按项目语音识别画面51的例子进行说明。
第1显示栏52是显示作为“姓名”的项目的语音识别结果的文本数据的区域。在选择了第1显示栏52的状态下利用操作部22进行了字符串的输入操作的情况下,CPU 11根据操作部22的操作输入,编辑“姓名”的项目的语音识别。
第2显示栏53是显示作为“年龄”的项目的语音识别结果的文本数据的区域。在选择了第2显示栏53的状态下利用操作部22进行了字符串的输入操作的情况下,CPU 11根据操作部22的操作输入,编辑“年龄”的项目的语音识别。
第3显示栏54是显示作为“性别”的项目的语音识别结果的文本数据的区域。在选择了第3显示栏54的状态下利用操作部22进行了字符串的输入操作的情况下,CPU 11根据操作部22的操作输入,编辑“性别”的项目的语音识别。
第4显示栏55是显示作为“患部”的项目的语音识别结果的文本数据的区域。在选择了第4显示栏55的状态下利用操作部22进行了字符串的输入操作的情况下,CPU 11根据操作部22的操作输入,编辑“患部”的项目的语音识别。
第5显示栏56是显示作为“诊察结果”的项目的语音识别结果的文本数据的区域。在选择了第5显示栏56的状态下利用操作部22进行了字符串的输入操作的情况下,CPU 11根据操作部22的操作输入,编辑“诊察结果”的项目的语音识别。
第6显示栏57是显示作为“日期”的项目的语音识别结果的文本数据的区域。在选择了第6显示栏57的状态下利用操作部22进行了字符串的输入操作的情况下,CPU 11根据操作部22的操作输入,编辑“日期”的项目的语音识别。
第7显示栏58是显示表示文件的发送目的地的信息的区域,该文件包含按项目语音识别处理的结果。在选择了第7显示栏58的状态下通过操作部22进行了字符串的输入操作的情况下,CPU 11根据操作部22的操作输入,编辑文件的发送目的地。发送目的地是可经由通信部15进行通信的其他设备。例如,发送目的地是可经由通信部15进行通信的、设置在网络上的服务器。
第8显示栏59是显示包含按项目语音识别处理的结果、且发送给第7显示栏58所示的发送目的地的文件的文件名称的区域。在选择了第8显示栏59的情况下,CPU11将可发送的文件的列表显示在显示部18上。CPU 11根据操作部22的操作,选择发送给第7显示栏58所显示的发送目的地的文件。CPU 11将所选择的文件的文件名称显示到第8显示栏59。
开始按钮60是能够根据操作部22的操作进行选择的按钮。在选择了开始按钮60的情况下,CPU 11执行按项目语音识别处理。例如,在选择了开始按钮60的情况下,CPU 11依次执行项目列表中包含的全部项目的按项目语音识别处理。更具体而言,在选择了开始按钮60的情况下,CPU 11按照优先级从高到低的顺序,即按照“姓名”、“年龄”、“性别”、“患部”、“诊察结果”、“日期”的顺序,执行按项目语音识别处理。
首先,在对“姓名”执行按项目语音识别处理的情况下,CPU 11将执行按项目语音识别处理的项目为“姓名”的消息显示到显示部18上。并且,CPU 11在第2特征表示的时间期间,进行音频流和视频流的取得和基于音频流的语音识别,取得辅音和元音的识别结果。CPU 11根据辅音和元音的识别结果来识别单词,判断单词的识别结果是否是与对应于“姓名”的第1特征和第3特征的设定相应的结果。在判断为单词的识别结果不与对应于“姓名”的第1特征和第3特征的设定相应的情况下,CPU 11根据视频流来估计人发出的辅音,修正元音和辅音的识别结果。CPU 11根据修正后的元音和辅音的识别结果,再次识别单词,再次判断单词的识别结果是否与对应于“姓名”的第1特征和第3特征的设定相应。在判断为单词的识别结果与对应于“姓名”的第1特征和第3特征的设定相应的情况下,CPU 11根据单词的识别结果生成文本数据,转移到下一项目的按项目语音识别处理。
CPU 11按照项目列表的每个项目执行该一系列的按项目语音识别处理。在针对项目列表的全部项目进行了按项目语音识别处理的情况下,CPU 11生成包含按项目语音识别处理的结果的文件。并且,在生成了包含按项目语音识别处理的结果的文件的情况下,CPU 11使第8显示栏59显示所生成的文件。
第1指示器61至第6指示器66是表示各项目的按项目语音识别处理的状态的显示。CPU 11将表示未执行按项目语音识别处理的显示、表示按项目语音识别处理正在执行中的显示和表示按项目语音识别处理已完成的显示中的任意显示作为第1指示器61至第6指示器66进行显示。
第1指示器61是表示“姓名”的按项目语音识别处理的状态的显示。第2指示器62是表示“年龄”的按项目语音识别处理的状态的显示。第3指示器63是表示“性别”的按项目语音识别处理的状态的显示。第4指示器64是表示“患部”的按项目语音识别处理的状态的显示。第5指示器65是表示“诊察结果”的按项目语音识别处理的状态的显示。第6指示器66是表示“日期”的按项目语音识别处理的状态的显示。
图8示出了针对“姓名”、“年龄”和“性别”完成了按项目语音识别处理,针对“患部”按项目语音识别处理正在执行中,针对“诊察结果”和“日期”未执行按项目语音识别处理的例子。在该情况下,CPU 11显示表示未执行按项目语音识别处理的显示,作为第1指示器61至第3指示器63。此外,CPU 11显示表示按项目语音识别处理正在执行中的显示,作为第4指示器64。此外,CPU 11显示表示按项目语音识别处理已完成的显示,作为第5指示器65和第6指示器66。此外,CPU 11也可以是如下结构:在选择了第1指示器61至第6指示器66中的任意一个的情况下,再次执行与所选择的指示器对应的项目的按项目语音识别处理。
上传按钮67是能够根据操作部22的操作而进行选择的按钮。在选择了上传按钮67的情况下,CPU 11进行通过通信部15将显示于第8显示栏59的文件发送到显示于第7显示栏58的发送目的地的上传。
结束按钮68是能够根据操作部22的操作而进行选择的按钮。在选择了结束按钮68的情况下,CPU 11结束按项目语音识别处理。此外,CPU 11也可以在进行按项目语音识别处理并存在识别结果的状态下选择了结束按钮68的情况下,将使用户选择是否舍弃识别结果的按钮显示在按项目语音识别画面51上。
通过在显示部18上显示上述按项目语音识别画面51,CPU 11能够使语音识别装置1的用户确认进行录音处理的情况、项目的一览、未执行按项目语音识别处理的项目、按项目语音识别处理正在执行中的项目、按项目语音识别处理已完成的项目、文件的发送目的地和要发送的文件等。并且,CPU 11能够根据按项目语音识别画面51上的操作,进行按项目语音识别处理的结果的修正、文件的发送目的地的设定和要发送的文件的选择等。其结果,语音识别装置1能够提高用户的便利性。
图9是示出语音识别装置1执行的按项目语音识别处理的具体例的流程图。
在执行按项目语音识别处理的情况下,CPU 11首先识别项目列表,该项目列表是进行语音识别的项目的列表(步骤S51)。
CPU 11根据识别出的项目列表,使显示部18显示如图8那样的按项目语音识别画面51(步骤S52)。
在显示了按项目语音识别画面51时,CPU 11开始按项目语音识别处理中的各项目的录音处理和语音识别处理(步骤S53)。例如,在按项目语音识别画面51中选择了开始按钮60的情况下,CPU 11开始各项目的录音处理和语音识别处理。此外,例如,CPU 11也可以是这样的结构:在按项目语音识别画面51中选择了第1指示器61至第6指示器66中的任意一个的情况下,开始与所选择的指示器对应的项目的录音处理和语音识别处理。另外,CPU 11也可以是这样的结构:不显示如图8的按项目语音识别画面51,自动开始各项目的录音处理和语音识别处理。
CPU 11判断项目列表中是否存在未输入项目(步骤S54)。例如,在项目列表中存在未进行语音识别的项目的情况下,CPU 11判断为存在未输入项目。
在判断为存在未输入项目的情况下(步骤S54:是),CPU 11选择未输入项目中的1个作为语音识别的对象的项目,利用语音收集部17取得音频流(步骤S55)。并且,CPU 11也可以将表示所选择的项目是什么项目的信息显示到显示部18上。
此外,CPU 11利用拍摄部16取得视频流(步骤S56)。即,CPU 11利用拍摄部16拍摄进行发声的人的嘴角,取得视频流。CPU 11可以根据视频流来判定是否拍摄了人的至少嘴部,在未拍摄到人的嘴部的情况下,督促拍摄嘴部。
CPU 11根据所取得的音频流,进行语音识别(步骤S57)。例如,CPU 11对与所选择的项目对应的声学模型与音频流的语音的波形进行比较,识别元音和辅音等。此外,CPU 11也可以是如下结构:对非易失性存储器14中存储的多个声学模型与音频流的语音的波形进行比较,识别元音和辅音等。
CPU 11根据在步骤S55中开始录音处理之后的经过时间,判断是否经过了与所选择的项目对应的规定时间(进行录音处理的时间)(步骤S58)。即,CPU 11判断是否进行了与在步骤S55中选择出的项目对应的第2特征表示的时间的录音处理。
在判断为未经过与项目对应的规定时间的情况下(步骤S58:否),CPU 11判定有无混乱(步骤S59)。在正在发声的人说话结巴的情况下,CPU 11检测混乱(例如语音的中断)。例如,在规定时间内未检测出规定音量以上的语音的情况下,CPU 11检测混乱。
在检测出混乱的情况下(步骤S59:是),CPU 11进行如下的引导显示:将表示正在进行录音处理的项目的信息显示到显示部18上(步骤S60)。图10是用于说明引导显示的例子的说明图。CPU 11例如使表示正在进行录音处理的项目的引导显示69与按项目语音识别画面51重叠地显示。由此,在进行发声的人忘记了项目的情况等下,语音识别装置1能够使进行发声的人识别在进行录音处理的项目。另外,CPU11也可以是如下结构:在检测出混乱的情况下,从语音再现部19输出表示正在进行录音处理的项目的语音。在步骤S59中未检测到混乱的情况(步骤S59:否)或者在步骤S60中进行了引导显示的情况下,CPU 11转移到步骤S55,反复进行步骤S55至步骤S60的处理。此外并且,CPU 11也可以是如下结构:在每次开始按项目语音识别处理中的每个项目的录音处理时,将表示项目的引导显示69显示到显示部18上。
此外,在进行按项目语音识别处理中的录音处理的情况下,语音识别装置1的CPU 11也可以将表示录音处理执行中的显示显示到显示部18上。具体而言,CPU 11可以利用按项目语音识别画面51上的第1指示器61至第6指示器66来表示在步骤S55和步骤S56的执行中正在执行录音处理。由此,语音识别装置1能够使进行发声的人确认正在录音处理执行中。
此外并且,CPU 11也可以是如下结构:在检测出混乱的情况下,利用拍摄部16拍摄人的嘴部的图像。在语音中断的定时,估计人未进行辅音和元音的发声。因此,估计语音中断的定时的人的嘴部是未因发声而发生变形的基准的嘴部形状。在检测出语音的中断的情况下,CPU 11取得由拍摄部16拍摄的人的嘴部的图像,作为基准面部图像。CPU 11可以使用该基准面部图像,对图5中的人的嘴部的开口面积进行归一化。例如,CPU 11可以计算视频流中的各帧中的人的嘴部的开口面积与基准面部图像中的人的嘴部的开口面积之比,将图5的曲线图41置换为计算出的比值。
此外,CPU 11也可以在进行按项目语音识别处理中的录音处理的期间内,根据姿势传感器21的检测结果来检测从语音识别装置1的拍摄部16的镜头朝向进行发声的人的姿势向显示部18朝向进行发声的人的姿势的变化。即,CPU 11可以检测进行发声的人探头观察显示部18的情况。具体而言,CPU 11判断在图9的步骤S55至步骤S58之间,进行发声的人是否探头观察显示部18。并且,CPU 11也可以是如下结构:在检测出进行发声的人探头观察显示部18的情况下,使显示部18显示引导显示69。由此,语音识别装置1能够使进行发声的人确认正进行按项目语音识别处理的项目。
在步骤S58中判断为经过了与项目对应的规定时间的情况下(步骤S58:是),CPU 11通过从与所选择的项目对应的单词识别辞典中取得与辅音和元音的识别结果对应的单词,识别单词(步骤S61)。
CPU 11判断单词的识别结果是否妥当(步骤S62)。如上所述,CPU 11判断步骤S61中的单词的识别结果是否是与在步骤S55中选择出的项目对应的单词。即,CPU 11判断步骤S61中的单词的识别结果是否是与在步骤S55中选择出的项目所对应的第1特征对应的单词、是否是与第3特征对应的单词数和句节数等。
在判断为单词的识别结果不妥当的情况下(步骤S62:否),CPU 11进行与图4的步骤S24相同的辅音确定处理(步骤S63),转移到步骤S61的处理。即,CPU 11进行图6的辅音确定处理,再次进行单词的识别。由此,CPU 11使用基于视频流的辅音的估计结果,修正基于音频流的辅音的识别结果,根据修正后的辅音和元音的识别结果来进行单词的识别。
在判断为单词的识别结果妥当的情况下(步骤S62:是),CPU 11根据单词的识别结果来生成文本数据(步骤S64),转移到步骤S54的处理。在转移到步骤S54的处理时,CPU 11再次判断在项目列表中是否存在未输入项目。此外,在针对1个项目已完成了按项目语音识别处理的情况下,CPU 11将第1指示器61至第6指示器66中的、与按项目语音识别处理已完成的项目对应的指示器切换为表示按项目语音识别处理已完成的显示。并且,在判断为存在未输入项目的情况下,CPU 11将第1指示器61至第6指示器66中的、与下一个进行按项目语音识别处理的项目对应的指示器切换为表示正在执行按项目语音识别处理中的显示。由此,语音识别装置1能够使进行发声的人确认下一个进行按项目语音识别处理的项目。
在步骤S54中判断为不存在未输入项目的情况下(步骤S54:否),CPU 11生成包含按项目语音识别处理的结果的文件(步骤S65)。该文件例如包含音频流和文本数据。此外,该文件还可以包含视频流。
CPU 11将所生成的文件保存到非易失性存储器14中(步骤S66),结束按项目语音识别处理。
并且,CPU 11可以根据按项目语音识别画面51上的操作而上传所生成的文件。即,在通过按项目语音识别处理生成了文件以后,在按项目语音识别画面51中选择了上传按钮67的情况下,CPU 11进行利用通信部15将第8显示栏59中显示的文件发送到第7显示栏58中显示的发送目的地的上传。
根据上述结构,语音识别装置1通过按照每个项目进行录音处理,取得音频流和视频流。语音识别装置1从音频流中识别辅音和元音,根据辅音和元音的识别结果来识别单词。语音识别装置1判断单词的识别结果是否是适合项目的结果。在判断为单词的识别结果是不适合项目的结果的情况下,语音识别装置1根据视频流来估计辅音,使用辅音的估计结果来修正基于音频流的辅音和元音的识别结果。语音识别装置1根据修正后的辅音和元音的识别结果,再次识别单词。由此,在单词的识别结果不是适合项目的结果的情况下,语音识别装置1能够使用基于视频流的辅音的估计结果,再次识别单词。其结果,语音识别装置1能够提高语音识别的精度。
另外,如上所述,语音识别装置1通过在选择了进行语音识别的项目以后进行录音处理和语音识别,能够选择与项目对应的单词识别辞典、声学模型和嘴形模型等。由此,语音识别装置1能够提高语音识别的精度。
此外,语音识别装置1通过按照每个项目进行语音识别,能够使发声的开端的检测变得容易。由此,语音识别装置1能够提高发声的开端的辅音的识别精度。此外,语音识别装置1也可以根据最初的辅音,根据预先设定的学习模式来推测后续的元音和辅音、以及单词等。由此,语音识别装置1能够有效地进行语音识别。
此外,语音识别装置1也可以是如下结构:不预先选择项目,而进行录音处理和语音识别,根据这些结果来选择项目,使用与所选择的项目对应的嘴形模型进行辅音确定处理。例如,语音识别装置1的CPU 11通过根据通过语音识别而识别出的辅音和元音的组合而与对应于多个项目的单词识别辞典进行对照,识别单词,选择与收录有识别出的单词的单词识别辞典对应的项目。并且,语音识别装置1的CPU 11根据识别出单词而选择项目,使用与所选择的项目对应的嘴形模型进行辅音确定处理。由此,语音识别装置1即使在未预先设定项目的状态下,也能够提高语音识别的精度。
另外,在上述的实施方式中,对声学模型是按照元音和辅音等的每个语音要素而预先生成的语音波形进行了说明,但不限于该结构。声学模型可以是按照每个单词而预先生成的语音波形。在声学模型是按照每个单词而预先生成的语音波形的情况下,CPU 11通过对从音频流提取出的波形与声学模型的波形进行比较,能够识别单词。
另外,在上述各实施方式中所说明的功能可以通过使计算机读入程序而实现,也可以利用硬件实现。当然,在不考虑上下文的连贯性等的情况下,仅通过有限的语音的信息,难以进行高精度的语音识别,因此也可以考虑除了此时输入的语音以外的上下文的连贯性或发声的背景等。在这样的情况下,产生如下情况:图像或语音的输入信息的放大、或最好包含其他信息并综合性判断各种各样的信息或变量。在这样的情况下,可以对作为对人工智能有用的判断依据的信息(如果能够反馈口授结果,在结果良好的情况下输入有效的信息或者参考失败时的信息,则成为示教信息)较多地进行深层学习。如果是这样的学习,则嘴部的形状等也即使没有意识到严格的数值化或图案化,也能够进行相同效果的语音识别。但是,即使是这样的机械学习,只要包含本申请的技术特征,当然能够是本申请的保护范围。
以上参照上述各实施方式对本发明进行了说明,但本发明不限定于上述各实施方式,本发明中也包含适当组合或置换了各实施方式的结构的内容。此外,还能够基于本领域人员的知识适当改变各实施方式中的组合或处理的顺序或对实施方式施加各种设计变更等变形,施加了这样的变形的实施方式也包含在本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!