一种基于MEE优化准则的深度神经网络语音增强模型的制作方法
本发明属于本发明属于人工智能语音增强领域,主要涉及深度神经网络在语音声学模型中的应用。
背景技术:
近年来,随着深度神经网络(Deep Neural Network,DNN)在语音识别领域的成功应用,语音增强任务也有了长足的发展。DNN的深层非线性结构可以被设计成一个精细的降噪滤波器,同时基于大数据训练,DNN能充分学习带噪语音和纯净语音之间的复杂的非线性关系。
在基于深度神经网络的语音增强模型中,需要一个代价函数来更新网络权值。在语音增强的回归任务中,一般用最小均方误差MSE准则作为优化准则,其优点是计算简单,但只适用于高斯噪声这样的平稳噪声。因为MSE在测量相似度的时候考虑了全局性,也就是说,待测空间的所有样本点的作用都比较大,尤其针对远离y=x这条线的样本点,MSE将放大这些远离误差分布均值样本点的作用。所以,当误差属于高斯分布时,MSE性能最优。但是在实际问题中,带噪语音中存在许多非平稳噪声,即噪声不属于高斯分布,因此MSE准则在实际问题中的效果通常不是很理想。
相对于MSE的全局性测量,最小误差熵MEE作为一种局部性的相似度测量方法,其相似度主要受核宽度的影响;当选择一个合适的核宽度时,MEE准则的性能曲面不只是固定的曲率,并且在大部分的空间内比MSE性能曲面要平滑。MEE不仅鲁棒性好,而且更适合实际问题中的非高斯噪声。针对MSE准则对非平稳噪声效果不理想的缺陷,因此需要一种基于深度神经网络的语音增强模型,采用MEE优化准则代替传统MSE准则。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于MEE优化准则的深度神经网络语音增强模型,对实际问题中含非平稳噪声的带噪语音降噪具有较好的普适性。
为达到上述目的,本发明提供如下技术方案:
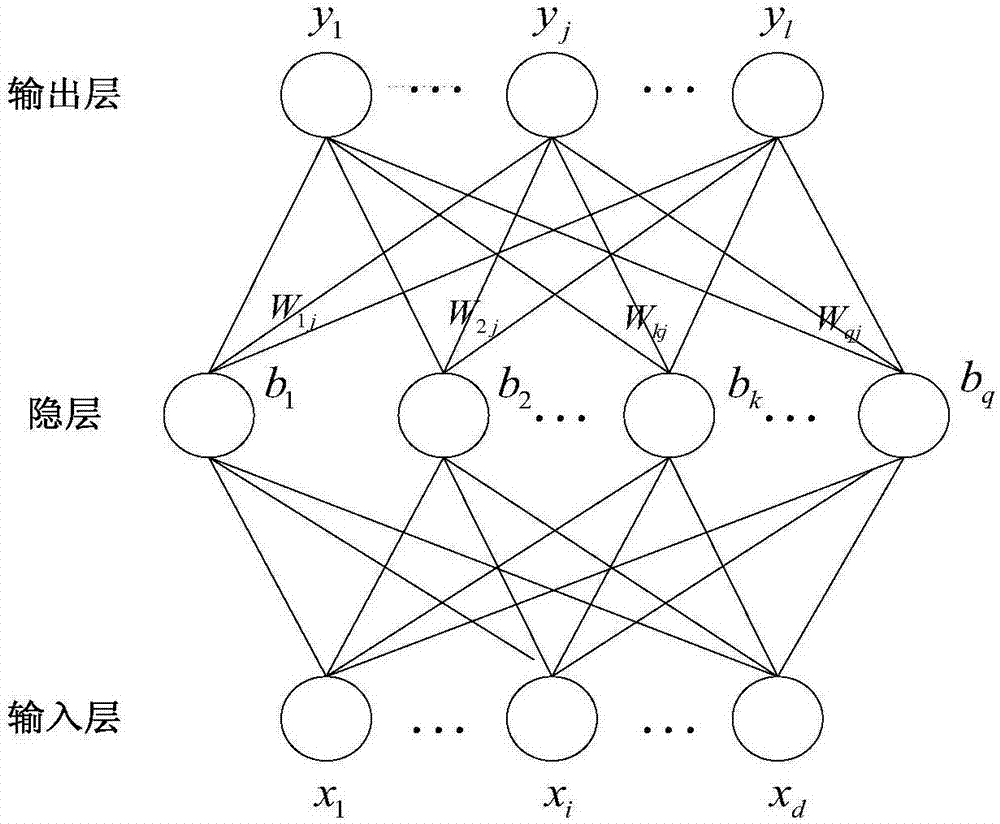
一种基于MEE优化准则的深度神经网络语音增强模型,如图2所示,包括输入层、隐层和输出层;所述隐层层数为3,节点数为1024。
如图1所示,该模型分为训练阶段和增强阶段。
所述训练阶段:将纯净语音和多种类噪声两两相加构建不同信噪比下的混合带噪语音,对混合语音进行特征提取,输入到深度神经网络(Deep Neural Network,,DNN)进行训练。
所述增强阶段:对待测混合语音进行相同特征提取,输入到已经训练好的DNN进行解码,DNN输出对纯净语音的特征的估计,再进行波形重构,得到降噪后的语音文件。
进一步,在DNN训练阶段,用误差逆传播(error BackPropagation,BP)算法更新DNN权值;输入通过各个隐层获得的激励响应,隐层的上一层的输出是下一层的输入,直到最后一层获得预测值;预测值和参考信号的差异需要反向传播的错误,根据这个错误来调节DNN的各个权值和偏置。
进一步,定义最小误差熵MEE代价函数的最后实际表达为:
其中,n表示隐层的节点数;e(i)和e(u)分别表示第i个神经元和第u个神经元的错误;错误e=target-output,表示经DNN训练后输出的对纯净语音对数功率谱的估计值与参考值的差异;h表示核宽度,即平滑参数,在本发明中设置为0.01;高斯核函数K表示为:
为了使用BP算法,需要得到梯度Δω的解析表达式;因为(1)式函数是单调递增的,最小化它的操作数,操作数可以表示为:
其中,yk=output;
当i=k时,的导数为:
当u=k时,的导数为:
综合(3)、(4)、(5)式可得:
化简整理(6)式可得:
其中,Wkj表示第j层第k个神经元的权值,net(j)表示为第j层第k个神经元的输入,f(·)是神经元的激活函数,f′(·)代表f(·)的导数;
综上,给定学习率η,用MEE作为代价函数的BP算法中的权值,更新公式(7)可得:
本发明的有益效果在于:本发明提出在基于深度神经网络的语音增强模型中,采用最小误差熵(MEE)优化准则代替传统最小均方误差准则,有效解决了实际问题中含非平稳噪声的带噪语音降噪的问题。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为深度神经网络语音增强系统框图;
图2为BP网络框图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
从TIMIT数据集中选择4620条纯净语音与白噪声,粉红噪声,沃尔沃噪声和汽车噪声相加混合成-5db,5db信噪比下的带噪语音作为训练集。另选200条纯净语音在同样各个信噪比下混合babble噪声和工厂噪声作为测试集。
训练阶段,对训练集语音提特征,特征选择对数功率谱,分别输入到MSE-DNN网络和本发明提出的MEE-DNN网络进行训练。
网络训练完成后,对测试集语音同样提取对数功率谱,再次分别输入到两种不同的DNN网络中,得到对纯净语音对数功率谱的估计,用重叠相加法进行波形重构,得到增强后可测听的语音文件。
MSE-DNN网络增强后语音质量与MEE-DNN网络增强后语音质量对比如表1所示。其中,N1表示Babble噪声,N2表示Factory噪声。
表1
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!