声音合成装置、声音合成方法及程序与流程
本发明的实施方式涉及声音合成装置、声音合成方法及程序。
背景技术:
在声音合成中具有这样的需求,对于所生成的合成声音的讲话者,不仅从事前准备的少数候选中进行选择,而且想要重新生成适合于想阅读的内容的讲话者特性或利用者独自的讲话者特性。作为应对此需求的手段,例如提出了根据与讲话者特性相关的参数的操作使生成新的讲话者特性的技术。
随着这种技术的性能提高,在利用者想要自由地生成原创性较高的各种各样的讲话者特性时,可以预见想要把新生成的讲话者特性作为独自的讲话者特性而独占利用的需求高涨。但是,存在与某一利用者生成的讲话者特性相同或者相似的讲话者特性偶然地由其他利用者生成并在实际的产品/服务等中使用的可能性,而不能应对那样的需求。
现有技术文献
专利文献
专利文献1:日本专利第4296231号公报
技术实现要素:
发明要解决的课题
本发明要解决的课题是,提供能够实现讲话者特性的独占利用的声音合成装置、声音合成方法及程序。
用于解决课题的手段
实施方式的声音合成装置具有声音合成部、讲话者参数存储部、可否利用判定部和讲话者参数控制部。声音合成部能够根据与讲话者特性相关的参数的值即讲话者参数值控制合成声音的讲话者特性。讲话者参数存储部存储已登记讲话者参数值。可否利用判定部根据将所输入的讲话者参数值与已登记讲话者参数值分别比较的结果,判定所输入的讲话者参数值的可否利用。讲话者参数控制部禁止或者限制通过所述可否利用判定部被判定为不可以利用的讲话者参数值的利用。
附图说明
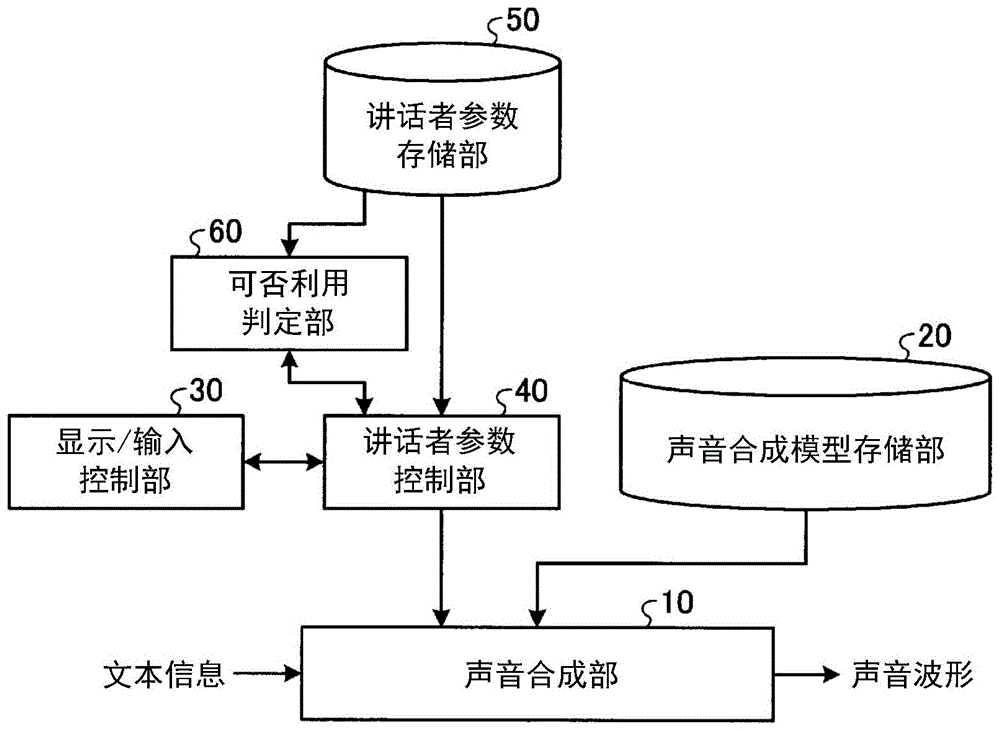
图1是表示有关第1实施方式的声音合成装置的功能性结构例的框图。
图2是表示声音合成部和声音合成模型存储部的结构例的框图。
图3是表示将讲话者参数值转换成子模型的加权的具体例的图。
图4是表示在讲话者参数存储部存储的信息的一例的图。
图5是表示可否利用判定部的处理步骤的一例的流程图。
图6是表示用户界面的画面结构例的图。
图7是表示用户界面的画面结构例的图。
图8是表示用户界面的画面结构例的图。
图9是表示用户界面的画面结构例的图。
图10是表示用户界面的画面结构例的图。
图11是表示用户界面的画面结构例的图。
图12是表示有关第2实施方式的声音合成装置的功能性结构例的框图。
图13是表示可否利用的判定和可否登记的判定的差异的概念图。
图14是表示用户界面的画面结构例的图。
图15是表示用户界面的画面结构例的图。
图16是表示用户界面的画面结构例的图。
图17是表示用户界面的画面结构例的图。
图18是表示用户界面的画面结构例的图。
图19是表示声音合成装置的硬件结构例的框图。
具体实施方式
下面,参照附图对实施方式的声音合成装置、声音合成方法及程序进行详细说明。另外,在下面的说明中,对于具有相同功能的构成要素赋予相同的标号,并适当省略重复的说明。
<第1实施方式>
图1是表示有关第1实施方式的声音合成装置的功能性结构例的框图。如图1所示,本实施方式的声音合成装置具有声音合成部10、声音合成模型存储部20、显示/输入控制部30、讲话者参数控制部40、讲话者参数存储部50和可否利用判定部60。
声音合成部10在被输入文本信息时,使用在声音合成模型存储部20存储的各种模型和规则,生成合成声音的声音波形。此时,如果从讲话者参数控制部40被输入了与讲话者特性相关的参数的值即讲话者参数值,则一面根据所输入的讲话者参数值控制讲话者特性一面生成声音波形。所谓讲话者特性是指讲话者固有的声音的特点,例如包括年龄、洪亮度、硬度、清晰度……这样的多个要素。讲话者参数值例如是与这些讲话者特性的各要素对应的值的集合。
在声音合成模型存储部20存储有声音合成所需要的各种信息,如将声音的音响性特点模型化得到的音响模型、将抑扬顿挫/节奏等韵律模型化得到的韵律模型等。在本实施方式的声音合成装置中,在声音合成模型存储部20还存储有讲话者特性的控制所需要的模型。
在基于hmm(hiddenmarkovmodel:隐马尔可夫模型)的声音合成方式的情况下,在声音合成模型存储部20存储的韵律模型和音响模型是将由文本抽取的文本信息、与韵律和音响等参数序列的对应关系模型化得到的。文本信息通常包括与文本的诵读和声调对应的音韵信息、语句的段落和词类等语言信息,模型包括按照状态在音韵/语言环境下将各参数分类得到的决定树、和对决定树的各叶子节点分配的参数的概率分布。
关于韵律参数有表示声音的高低的音高参数、表示声音的长短的持续时间长度等。另外,关于音响参数有表示声道的特点的声谱参数、表示音源信号的非周期性的程度的非周期性指标等。所谓状态是指以hmm将各参数的时间性变化模型化时的内部状态。通常,各音素区间是以按照不后退地从左到右的状态进行推移的3~5状态的hmm被模型化的,因而包括3~5个的状态。因此,例如在针对音高参数的第一状态的决定树中,音素区间内的开头区间的音高值的概率分布在音韵/语言环境下被分类,以与对象的音素区间相关的音韵/语言信息为基础追寻该决定树,由此能够得到该音素的开头区间的音高参数的概率分布。在参数的概率分布中往往使用正规分布,在这种情况下,用表示分布的中心的平均向量和表示分布的扩展的共分散矩阵进行表述。
在声音合成部10中,根据所输入的文本信息,用如上所述的决定树选择针对各参数的各状态的概率分布,根据这些概率分布分别生成概率达到最大的参数序列,根据这些参数序列生成声音波形。在基于通常的hmm的方式的情况下,根据所生成的音高参数和非周期性指标生成音源波形,在该音源波形中叠加滤波特性按照所生成的声谱参数呈时间性变化的声道滤波器,由此生成声音波形。
在本实施方式的声音合成装置的声音合成部10中,根据来自讲话者参数控制部40的讲话者参数值的指定,能够进行讲话者特性的控制。作为实现该控制的方法,例如按照专利文献1所记载的那样,在声音合成模型存储部20存储将音质不同的多个讲话者的声音分别模型化得到的多个音响模型,按照所指定的讲话者参数值选择几个音响模型,通过加权和等对来自所选择的音响模型的音响参数进行插补,由此能够实现期望的讲话者特性。
或者,即使是通过如图2所示的结构的声音合成部10和声音合成模型存储部20,也能够实现讲话者特性的控制。在图2所示的结构中,在声音合成模型存储部20存储有将成为基础的讲话者特性的韵律/音质模型化得到的基础模型、和将因讲话者特性的各要素的差异而形成的韵律/音响参数的差异模型化得到的讲话者特性控制模型。
基础模型可以是表现多个讲话者的平均的讲话者特性的被称为平均声音模型的模型,还可以是表现某一讲话者的讲话者特性的模型。基础模型的具体结构例如与基于上述的hmm的方式的韵律模型和音响模型一样,包括按照状态在音韵/语言环境下将各参数分类得到的决定树、和对决定树的各叶子节点分配的参数的概率分布。
关于讲话者控制模型,可以是包括决定树和对决定树的各叶子节点分配的概率分布的模型,但该模型的概率分布表示与讲话者特性的各要素的差异对应的韵律/音响参数的差异。具体地,包括将基于年龄差异的韵律/音质参数的差异模型化得到的年龄模型、将基于声音的洪亮度的差异的韵律/音质参数的差异模型化得到的洪亮度模型、将基于声音的硬度的差异的韵律/音质参数的差异模型化得到的硬度模型、将基于声音清晰度的差异的韵律/音质参数的差异模型化得到的清晰度模型等子模型。
图2所示的结构的声音合成部10包括选择部11、相加部12、参数生成部13、波形生成部14和加权设定部15。选择部11根据所输入的文本信息,从基础模型和讲话者特性控制模型的各子模型中分别按照决定树选择概率分布。相加部12按照由加权设定部15赋予的各子模型的加权,对由选择部11选择的概率分布的平均值赋予加权并相加,分散是使用基础模型的分散,由此得到反映出讲话者特性控制模型的概率分布。
其中,子模型的加权是由加权设定部15对由讲话者参数控制部40赋予的讲话者参数值进行转换得到的。图3表示一个具体例。在该例中,讲话者参数值和子模型的加权都是各要素与讲话者特性控制模型的各子模型对应,但是值的表述方法不同。讲话者参数值根据要素有连续值和离散性范畴,值的范围也因要素而异,而子模型的加权都是连续值,而且值的范围被规范化为-1.0~1.0。另外,讲话者参数值和子模型的加权的值的表述方法不限于此,两者也不一定不同。
相加部12在各参数的各状态下进行上述的相加处理,对于各参数生成被实施了加权相加的概率分布的序列。
参数生成部13对于声谱参数和音高参数等各参数,根据由相加部12赋予的概率分布的序列,生成概率达到最大的参数序列。波形生成部14根据所生成的参数序列,生成合成声音的声音波形。
如上所述,图2所示的结构的声音合成部10能够按照由讲话者参数控制部40指定的讲话者参数值任意地控制讲话者特性。
返回到图1,显示/输入控制部30可视化地显示对讲话者参数控制部40设定的讲话者参数值,并且对利用者提供利用者可以变更/输入讲话者参数值的用户界面。在利用者利用该用户界面进行变更/输入讲话者参数值的操作时,显示/输入控制部30将与该用户操作对应的讲话者参数值发送给讲话者参数控制部40。并且,在从讲话者参数控制部40返回了与讲话者参数值的利用禁止或者限制相关的信息的情况下,显示/输入控制部30通过用户界面将其内容通知利用者。另外,对于拥有在讲话者参数存储部50存储的已登记讲话者参数值的利用者,通过输入可以确定利用者的信息(利用者信息),还能够输出从讲话者参数存储部50调用所拥有的讲话者参数值的指示。关于用户界面的具体例在后面进行详细说明。
讲话者参数控制部40与显示/输入控制部30和可否利用判定部60协作地进行有关讲话者参数值的处理。例如,在由显示/输入控制部30被赋予了利用者输入的讲话者参数值的情况下,讲话者参数控制部40将该讲话者参数值和利用者信息等转发给可否利用判定部60,使判定讲话者参数值的可否利用。另外,在利用者输入的讲话者参数值被判定为可以利用的情况下,讲话者参数控制部40将该讲话者参数值转发给声音合成部10,使能够用于声音合成中。此外,在利用者输入的讲话者参数值被判定为不可以利用的情况下,讲话者参数控制部40禁止或者限制该讲话者参数值的利用,将与利用的禁止和限制相关的信息转发给显示/输入控制部30。另外,所谓利用的限制是指带条件地许可利用。另外,在由显示/输入控制部30输出了已登记讲话者参数值的调用指示的情况下,讲话者参数控制部40在确定了利用者后,从讲话者参数存储部50提取相应的已登记讲话者参数值,并转发给显示/输入控制部30和声音合成部10。
在讲话者参数存储部50存储有各利用者拥有的已登记讲话者参数值。在本实施方式中,通过与图1所示的声音合成装置不同的装置进行讲话者参数值的登记,并假设已登记讲话者参数值被存储在讲话者参数存储部50中。在进行讲话者参数值的登记时,在讲话者参数存储部50中,除已登记讲话者参数值以外,还存储有与已登记讲话者参数值相关的辅助信息。
图4表示在讲话者参数存储部50存储的信息的一例。图4所示的各行表示已登记参数值及其辅助信息,与对已登记参数值唯一地分配的识别信息即讲话者特性id对应地,存储有构成已登记参数值的讲话者特性的各要素的值、该已登记参数值的拥有者和已登记参数值的利用条件等辅助信息。既存在拥有者是公司和部门等团体的情况,如讲话者特性id是0001和0002那样的已登记参数值,也存在拥有者是个人的情况,如讲话者特性id是0003和0004那样的已登记参数值。关于利用条件可以有几种设定,例如讲话者特性id是0001那样的已登记参数值,除拥有者以外的利用全部设为不可以利用,讲话者特性id是0002和0003那样的已登记参数值,根据期间和用途设为可以利用。或者,为了防止被他人拥有而不能利用,还存在不施加利用限制地拥有的情况,如讲话者特性id是0004那样的已登记参数值。
可否利用判定部60在从讲话者参数控制部40被输入由利用者输入的讲话者参数值和利用者信息等时,将它们与在讲话者参数存储部50存储的已登记讲话者参数值及辅助信息分别核对,判定所输入的讲话者参数值可否利用,将判定结果发送给讲话者参数控制部40。
在此,参照图5说明可否利用判定部60的判定方法的一例。图5是表示可否利用判定部60的处理步骤的一例的流程图。可否利用判定部60在从讲话者参数控制部40接收到由利用者输入的讲话者参数值(设为pin={pin(0),pin(1),pin(2),…,pin(c-1)},其中,pin(k)表示第k个要素的值,c表示要素的个数)和利用者信息时(步骤s101),将讲话者特性id的计数器j设定为最初的已登记讲话者参数值(在该例中,j=0001)(步骤s102)。
然后,可否利用判定部60参照讲话者参数存储部50,取得讲话者特性id=j的已登记讲话者参数值及辅助信息(步骤s103),进入后面的步骤s104。在此,将讲话者特性id=j的已登记讲话者参数值设为pj={pj(0),pj(1),pj(2),…,pj(c-1)}。并且,将在讲话者参数存储部50存储的已登记讲话者参数值的总数设为n。
在后面的步骤s104中,可否利用判定部60根据在步骤s101接收的利用者信息和在步骤s103取得的辅助信息,判定输入了讲话者参数值的利用者是否是讲话者特性id=j的已登记讲话者参数值的拥有者(步骤s104)。并且,如果输入了讲话者参数值的利用者是讲话者特性id=j的已登记讲话者参数值的拥有者(步骤s104:是),则进入步骤s109,在不是拥有者的情况下(步骤s104:否),进入步骤s105。
在步骤s105中,可否利用判定部60根据在步骤s103取得的辅助信息,判定利用者对讲话者参数值的利用是否与讲话者特性id=j的已登记讲话者参数值的利用条件抵触(步骤s105),如果不抵触(步骤s105:否),则进入步骤s109,在抵触的情况下(步骤s105:是),进入步骤s106。关于是否与已登记讲话者参数值的利用条件抵触的判定方法,根据在讲话者参数存储部50中作为辅助信息所存储的已登记讲话者参数值的利用条件而不同。例如,在讲话者特性id=j的已登记讲话者参数值的利用条件是不可以利用的情况下,判定为与利用条件抵触。另外,在讲话者特性id=j的已登记讲话者参数值的利用条件是仅在规定期间被设为可以利用的情况下,例如如果当前时刻在该规定期间内,则判定为不与利用条件抵触,如果当前时刻在规定期间外,则判定为与利用条件抵触。
在步骤s106中,可否利用判定部60根据在步骤s101接收的讲话者参数值(由利用者输入的讲话者参数值)和在步骤s103取得的已登记讲话者参数值(讲话者特性id=j的已登记讲话者参数值),使用规定的评价函数计算它们的差异即diff(pin,p(j)),进入后面的步骤s107。
在步骤s107中,可否利用判定部60将在步骤s106中计算出的diff(pin,p(j))的值、与表示已登记讲话者参数值的范围的第1阈值进行比较,在diff(pin,p(j))的值为第1阈值以下的情况下(步骤s107:是)、即利用者输入的讲话者参数值和讲话者特性id=j的已登记讲话者参数值相似的情况下,在步骤s108中,将由利用者输入的讲话者参数值判定为“不可以利用”,将判定结果发送给讲话者参数控制部40并结束处理。另一方面,在diff(pin,p(j))的值超过第1阈值的情况下(步骤s107:否),进入步骤s109。
在步骤s109中,可否利用判定部60确认是否j=n,即,确认与在讲话者参数存储部50存储的所有的已登记讲话者参数值及辅助信息的核对是否完成,如果不是j=n(步骤s109:否),在步骤s110中将讲话者特性id的计数器j递增,然后返回到步骤s103反复进行以后的处理。另一方面,如果是j=n(步骤s109:是),在步骤s111中,将由利用者输入的讲话者参数值判定为“可以利用”,将判定结果发送给讲话者参数控制部40并结束处理。
在此,对在上述步骤s106中使用的两个讲话者参数值p1、p2的差异diff(p1,p2)进行说明。diff(p1,p2)例如按照下述式(1)所示定义为对构成讲话者参数值的讲话者特性的各要素的差异进行加权和。
[数式1]
其中,p1={p1(0),p1(1),p1(2),…,p1(c-1)}、p2={p2(0),p2(1),p2(2),…,p2(c-1)},λ(k)表示第k个要素的加权,d(k)(p1(k),p2(k))表示第k个要素的差异。d(k)(p1(k),p2(k))对于用连续值表述的要素可以定义为p1(k)与p2(k)的平方差,对于用离散性范畴表述的要素,如果p1(k)和p2(k)一致则定义为0,除此以外则定义为1等。优选在λ(k)是对讲话者特性的主观性差异的影响越大的要素时加权越大。例如,考虑对针对各种各样的p1和p2的组合生成的声音的讲话者特性的差异进行主观评价,对其结果进行重回归分析,由此求出d(0)(p1(0),p2(0))、…、d(c-1)(p1(c-1),p2(c-1))与主观评价值的关系,使用其结果所得到的重回归式的系数作为加权。
上述的diff(p1,p2)的例子是假设各要素单独地影响到讲话者特性的差异,但如果使用深层学习的方法学习神经网络,则能够估计在某种程度上还反映出各要素间的相互作用的diff(p1,p2),在该神经网络中,根据大量地实施上述的主观评价得到的d(0)(p1(0),p2(0))、…、d(c-1)(p1(c-1),p2(c-1))与主观评价值的多个组合的数据估计diff(p1,p2)。
在上述步骤s107的判定中使用的第1阈值可以是相对于在讲话者参数存储部50存储的全部已登记讲话者参数值都相同的值,也可以因每个已登记讲话者参数值而不同。在这种情况下,在被存储于讲话者参数存储部50的辅助信息中,除图4所示的拥有者和利用条件的信息以外,还包括表示已登记讲话者参数值的登记范围的第1阈值。例如,在拥有者想较广地独占某一特定的已登记讲话者参数值的情况下,如果将与该已登记讲话者参数值对应的第1阈值登记为偏大的值,则能够扩大被判定为不可以利用的范围。
下面,示例通过上述的显示/输入控制部30提供给利用者的用户界面的具体例,说明与利用者的操作对应的声音合成装置的交替动作的一例。
图6~图11是表示通过显示/输入控制部30提供给利用者的用户界面的画面结构例的图。图6~图11所示的画面作为通过显示/输入控制部30可以受理使用了例如键盘或鼠标等输入装置的输入操作的画面,被显示于液晶显示器等显示装置。另外,在此示例的用户界面毕竟是一例,能够进行各种各样的变形和变更。通过显示/输入控制部30提供给利用者的用户界面只要至少是利用者可以输入期望的讲话者参数值的结构即可。
在本实施方式的声音合成装置的起动后,在利用者经过规定的步骤进行注册时,在与声音合成装置连接的显示装置或者利用者的终端具有的显示装置显示有例如图6所示的画面100。该图6所示的画面100包括:文本框101,用于输入成为声音合成的对象的文本信息;拖拽菜单102,用于选择想要利用的讲话者特性;滑动块103a、103b、103c,用于设定声音的大小、讲话速度、声音的高低这些通常的音质的参数;“合成”按钮104,用于指示合成声音的声音波形的生成;“保存”按钮105,用于指示所生成的合成声音的声音波形的保存。在拖拽菜单102中,除事前准备的典型的讲话者特性以外,还准备了利用由利用者作成的讲话者特性的选择肢“作者讲话者”、和利用由利用者过去作成并登记的讲话者特性的选择肢“登记讲话者”。
在从该图6所示的画面100的拖拽菜单102中选择了“稳重的中年男性”、“朝气的年轻女性”、“播音员式的女性”等事前准备的典型的讲话者特性的情况下,利用者通过该画面100上的操作,能够得到适用了与所选择的讲话者对应的讲话者参数值的合成声音的声音波形。即,向文本框101输入成为声音合成的对象的文本信息,根据需要操作滑动块103a、103b、103c调整音质的参数,然后按下“合成”按钮104。由此,通过声音合成部10生成适用了与所选择的讲话者特性对应的讲话者参数值的合成声音的声音波形。并且,在利用者按下“保存”按钮105的情况下,通过声音合成部10生成的合成声音的声音波形被保存在规定的保存地址。
另外,在利用者从图6所示的画面100的拖拽菜单102中进行选择“作成讲话者”的操作时,图6所示的画面100变为图7所示的画面110。该图7所示的画面110是利用者输入期望的讲话者参数值用的画面,包括:雷达图111,将讲话者参数值可视化;文本框112;用于输入利用者信息;文本框113;用于输入视听用文本;“试听”按钮114,用于要求试听使用了在雷达图111示出的讲话者参数值的试听用文本的合成声音;“利用本设定”按钮115,指示将在雷达图111示出的讲话者参数值用于声音合成中。
雷达图111在与讲话者特性的各要素对应的轴上具有用于变更与该要素对应的值的操作符。利用者通过在该雷达图111上操作操作符,能够输入期望的讲话者参数值。通过向文本框113输入试听用文本并按下“试听”按钮114,确认反映了所输入的讲话者参数值的合成声音。
另外,在利用者使用雷达图111输入了期望的讲话者参数值后,向文本框112输入利用者信息并按下“利用本设定”按钮115,利用者输入的讲话者参数值和利用者信息被从显示/输入控制部30转发给讲话者参数控制部40。讲话者参数控制部40在从显示/输入控制部30接收到讲话者参数值和利用者信息时,将这些讲话者参数值和利用者信息转发给可否利用判定部60,委托判定可否利用。可否利用判定部60例如根据上述的方法判定由利用者输入的讲话者参数值的可否利用,将判定结果发送给讲话者参数控制部40。
在此,在可否利用判定部60的判定结果是不可以利用的情况下,讲话者参数控制部40向显示/输入控制部30转发与利用的禁止或限制相关的信息。显示/输入控制部30将从讲话者参数控制部40接收到的信息反映在用户界面的画面中。例如,在从讲话者参数控制部40接收到与利用的禁止相关的信息的情况下,显示/输入控制部30按照图8所示使在画面110上弹出显示错误消息116,通知利用者不能利用所输入的讲话者参数值。并且,在该错误消息116内的“ok”按钮116a被按下时,返回到图7所示的画面110。另外,在从讲话者参数控制部40接收到与利用的限制相关的信息的情况下,显示/输入控制部30例如可以使在画面110上弹出显示提醒消息,通知利用者只能在规定的期间内利用、或者仅限用于非商用目的这样的讲话者参数值可以利用的条件。
另一方面,在可否利用判定部60的判定结果是可以利用的情况下,用户界面的画面从图7所示的画面110变为图9所示的画面120。该图9所示的画面120的基本结构与图6所示的画面100相同,但在拖拽菜单102显示有所选择的“作成讲话者”,在其下面显示有与被判定为可以利用的讲话者参数值对应的雷达图的缩放图121。
利用者使用该画面120向文本框101输入成为声音合成的对象的文本信息,根据需要操作滑动块103a、103b、103c调整音质的参数,然后按下“合成”按钮104。由此,通过声音合成部10生成适用了由利用者输入的讲话者参数值的合成声音的声音波形。并且,在利用者按下“保存”按钮105的情况下,通过声音合成部10生成的合成声音的声音波形被保存在规定的保存地址。
另外,在利用者从图6所示的画面100的拖拽菜单102中进行了选择“登记讲话者”的操作的情况下,图6所示的画面100变为图10所示的画面130。该图10所示的画面130包括:文本框131,用于输入利用者信息;拖拽菜单132,用于选择利用者拥有的已登记讲话者参数值;文本框133,用于输入试听用文本;“试听”按钮134,用于要求试听使用了在拖拽菜单132中选择的已登记讲话者参数值的试听用文本的合成声音;“利用本设定”按钮135,指示将在拖拽菜单132中选择的已登记讲话者参数值用于声音合成中。
在利用者向文本框131输入利用者信息时,在拖拽菜单132可选择地显示有利用者拥有的已登记讲话者参数值的一览。然后,利用者从拖拽菜单132选择期望的已登记讲话者参数值,向文本框133输入试听用文本并按下“试听”按钮134,即可确认反映了所选择的已登记讲话者参数值的合成声音。另外,在利用者从拖拽菜单132选择了期望的已登记讲话者参数值后,并按下“利用本设定”按钮135时,对讲话者参数控制部40设定利用者选择的已登记讲话者参数值,图10所示的画面130变为图11所示的画面140。该图11所示的画面140的基本结构与图6所示的画面100相同,但在拖拽菜单102显示有“登记讲话者”,在其下面显示有与所选择的已登记讲话者参数值对应的雷达图的缩放图141。
利用者使用该画面140向文本框101输入成为声音合成的对象的文本信息,根据需要操作滑动块103a、103b、103c调整音质的参数,然后按下“合成”按钮104。由此,通过声音合成部10生成适用了由利用者选择的已登记讲话者参数值的合成声音的声音波形。并且,在利用者按下“保存”按钮105的情况下,通过声音合成部10生成的合成声音的声音波形被保存在规定的保存地址。
另外,以上说明了选择已登记讲话者参数值并直接利用的例子,但也可以在图7所示的画面110等中进一步调整所选择的已登记讲话者参数值。在这种情况下,利用条件有可能与原来选择的已登记讲话者参数值不同,因而根据调整后的讲话者参数值重新进行可否利用判定,然后决定最终可否利用。
如以上列举具体的示例详细说明的那样,根据本实施方式,根据将所输入的讲话者参数值与已登记讲话者参数值分别比较的结果,判定所输入的讲话者参数值的可否利用,禁止或者限制被判定为不可以利用的讲话者参数值的利用。因此,如果登记表示期望的讲话者特性的讲话者参数值,则能够独占利用该讲话者特性。
<第2实施方式>
下面,对第2实施方式进行说明。在上述的第1实施方式中,以使用与声音合成装置不同的装置进行讲话者参数值的登记为前提,但如果还能够使用进行讲话者参数值的设定或利用的声音合成装置进行讲话者参数值的登记,则利用者的使用便利性提高。因此,在本实施方式中,使声音合成装置具有登记讲话者参数值的功能。
图12是表示有关第2实施方式的声音合成装置的功能性结构例的框图。与图1所示的第1实施方式的结构上的差异在于,被追加了讲话者参数值登记部70。在针对讲话者参数值的登记向利用者收费的情况下,还具有收费处理部80。
在本实施方式中,利用者能够使用通过显示/输入控制部30提供的用户界面,进行所输入的讲话者参数值的可否登记的确认和登记申请。在利用者进行可否登记的确认用的指示时,从显示/输入控制部30向讲话者参数控制部40发送可否登记的确认指示以及登记对象的讲话者参数值和利用者信息等信息,这些信息从讲话者参数控制部40被转发给可否利用判定部60。在本实施方式中,可否利用判定部60具有判定可否登记的功能和计算登记费的功能,在由讲话者参数控制部40被委托可否登记的判定时,参照讲话者参数存储部50判定可否登记,在可以登记的情况下进一步计算登记费,将结果发送给讲话者参数控制部40。并且,可否利用判定部60的判定结果和可以登记时的登记费,从讲话者参数控制部40被转发给显示/输入控制部30,并通过显示/输入控制部30提供的用户界面通知利用者。
利用者对于被判定为可以登记的讲话者参数值,能够使用通过显示/输入控制部30提供的用户界面进行登记申请。在需要登记费的情况下,收费处理部80被通知登记费,收费处理部80对利用者进行收费处理。如果缴款被确认,其结果由收费处理部80被通知显示/输入控制部30,从显示/输入控制部30向讲话者参数控制部40发送讲话者参数值和利用者信息、有关利用条件的信息,这些信息与登记指示一起从讲话者参数控制部40被转发给讲话者参数登记部70。讲话者参数登记部70按照来自讲话者参数控制部40的登记指示,将所指定的讲话者参数值与利用者信息和利用条件等辅助信息一起存储在讲话者参数存储部50中。
可否利用判定部60对讲话者参数值的可否登记的判定,基本上是按照与可否利用的判定相同的方法进行判定,但与可否利用的判定不同的是,考虑登记对象的讲话者参数值的登记范围。图13表示可否利用的判定与可否登记的判定的差异。图13(a)表示可否利用的判定的概念图,图13(b)表示可否登记的判定的概念图。图中的x表示讲话者参数值,虚线表示讲话者参数值的登记范围,diff(pin,p(j))表示讲话者参数值之间的差异,thre(j)表示用于示出已登记讲话者参数值p(j)的登记范围的第1阈值,threin表示用于示出登记对象的讲话者参数值pin的登记范围的第2阈值。在图13(a)所示的可否利用的判定中,只要判定讲话者参数值pin是否被包含在已登记讲话者参数值p(j)的登记范围中即可,而在图13(b)所示的可否登记的判定中,需要考虑已登记讲话者参数值p(j)的登记范围和登记对象的讲话者参数值pin的登记范围重叠的可能性。
当在可否登记的判定中不允许登记范围的重叠的情况下,可否利用判定部60在与图5所示的流程图的步骤s107相当的判定中,例如使用下述式(2)所示的条件式,在满足该条件式的情况下判定为不可登记。
diff(pin,p(j))≤(thre(j)+threin)……(2)
另一方面,在登记范围重叠时,在已登记讲话者参数值的拥有者优先利用重叠的范围的情况下,可否利用判定部60与可否利用的判定一样地使用下述式(3)所示的条件式判定可否登记,在虽然被判定为可以登记但是满足上述式(2)的条件式的情况下,判定为带条件地可以登记。在这种情况下,可否利用判定部60通过使用了由显示/输入控制部30提供的用户界面的通知,询问利用者是否在调整了讲话者参数值和登记范围后进行登记。
diff(pin,p(j))≤thre(j)……(3)
例如,可否利用判定部60求出被调整成使满足下述式(4)的讲话者参数值pinsubset。
diff(pinsubset,p(j))>(thre(j)+threin)(j=0,1,…,c-1)……(4)
并且,可否利用判定部60将该调整后的讲话者参数值pinsubset转发给讲话者参数控制部40,同时向讲话者参数控制部40申请是否登记该被调整后的讲话者参数值pinsubset的询问。根据该申请,讲话者参数控制部40指示显示/输入控制部30询问利用者是否登记被调整后的参数值pinsubset,通过显示/输入控制部30提供的用户界面进行针对利用者的询问。并且,在利用者进行了被调整后的讲话者参数值pinsubset的登记申请时,讲话者参数控制部40指示讲话者参数登记部70登记被调整后的讲话者参数值pinsubset。
或者,也可以是,可否利用判定部60求出以满足下述式(5)的方式而减小的第2阈值的替代方案(即,缩窄讲话者参数的登记范围的替代方案)threinsubset。
diff(pin,p(j))>(thre(j)+threinsubset)(j=0,1,…,c-1)……(5)
在这种情况下,可否利用判定部60将该替代方案threinsubset转发给讲话者参数控制部40,同时向讲话者参数控制部40申请是否缩窄登记范围登记讲话者参数值pin的询问。根据该申请,讲话者参数控制部40指示显示/输入控制部30询问利用者是否缩窄登记范围登记讲话者参数值pin,通过显示/输入控制部30提供的用户界面进行针对利用者的询问。并且,在利用者进行了缩窄登记范围的讲话者参数值pin的登记申请时,讲话者参数控制部40指示讲话者参数登记部70登记缩窄登记范围的讲话者参数值pin。
另外,在判定为可以登记登记对象的讲话者参数值的情况下,可否利用判定部60计算登记对象的讲话者参数值的登记费。可否利用判定部60例如根据在讲话者参数存储部50存储的已登记讲话者参数值的分布等,能够计算诸如越是具有人气的讲话者特性越高的登记费。即,根据位于登记对象的讲话者参数值的周边区域的已登记讲话者参数值的个数决定登记费。具体地,对于规定的dadj求出诸如下述式(6)的p(j)的个数,使用诸如相对于该个数单调递增的函数计算登记费。
diff(pin,p(j))≤dadj……(6)
或者,不仅考虑已登记的讲话者参数值的个数,而且还考虑所输入的讲话者参数值和其周边的值的利用频次计算登记费。在这种情况下,由所有利用者利用的参数值的历史信息也被记录在讲话者参数存储部50中。
下面,示例通过本实施方式的显示/输入控制部30提供给利用者的用户界面的具体例,说明与讲话者参数的登记相关的声音合成制作的交替动作的一例。
在本实施方式中,在利用者从图6所示的画面100的拖拽菜单102中进行选择“作成讲话者”的操作时,图6所示的画面100变为图14所示的画面210。该图14所示的画面210是相对于图7所示的画面110追加了“登记本设定的利用权限”按钮211的结构,该按钮211用于指示在雷达图111中示出的讲话者参数值的可否登记的确认。
在利用者使用图14所示的画面210的雷达图111输入了期望的讲话者参数值后、并按下“登记本设定的利用权限”按钮211时,利用者输入的讲话者参数值和利用者信息等与可否登记的确认指示一起从显示/输入控制部30被发送给讲话者参数控制部40。
讲话者参数控制部40将从显示/输入控制部30接收到的讲话者参数值转发给可否利用判定部60,并委托该讲话者参数值的可否登记的判定。可否利用判定部60根据来自讲话者参数控制部40的委托,例如根据上述的方法判定讲话者参数值的可否登记,将判定结果发送给讲话者参数控制部40。
在此,在可否利用判定部60的判定结果是可以登记的情况下,由讲话者参数控制部40将表示讲话者参数值可以登记的确认结果通知显示/输入控制部30,用户界面的画面从图14所示的画面210变为图15所示的画面220。该图15所示的画面220是利用者进行讲话者参数值的登记申请的画面,包括:雷达图的缩放图221,表示登记对象的讲话者参数值;文本框222,用于输入登记者名称;复选按钮223,用于选择登记者类别;文本框224,用于输入登记条件;输入栏225,用于输入登记期间;复选按钮226,用于选择登记范围;“确认声音合成”按钮227,用于确认适用了用复选按钮226选择的登记范围的讲话者参数值时的合成声音;“登记费计算”按钮228,用于指示登记费的计算;登记费显示区229,用于显示所计算的登记费;“登记”按钮230,用于进行登记申请;“取消”按钮231,用于指示登记处理的取消。
利用者能够在该图15所示的画面220上输入讲话者参数值的登记所需要的各种信息。例如,能够选择用复选按钮226登记的讲话者参数值的登记范围。讲话者参数值的登记范围与上述的第1阈值相当,通常在扩大登记范围时登记费较高,在缩窄登记范围时登记费较低。在这种结构的情况下,在讲话者参数值的登记时,表示所选择的登记范围的第1阈值作为辅助信息被存储在讲话者参数存储部50中。
另外,在利用者按下“登记费计算”按钮228时,通过可否利用判定部60所计算出的登记费被显示在登记费显示区229。利用者能够参照在该登记费显示区229显示的登记费决定是否进行登记申请。并且,在利用者按下“登记”按钮230时进行收费处理部80的收费处理,在缴款被确认时,根据来自讲话者参数控制部40的登记指示,讲话者参数登记部70进行讲话者参数值的登记处理,登记对象的讲话者参数值和辅助信息被存储在讲话者参数存储部50中。并且,在利用者按下“取消”按钮231的情况下,讲话者参数值的登记处理被取消,返回到图14所示的画面210。
另一方面,在可否利用判定部60的判定结果是不可以登记的情况下,从讲话者参数控制部40向显示/输入控制部30通知表示讲话者参数值不可以登记的确认结果。在这种情况下,显示/输入控制部30例如按照图16所示,在画面210上弹出显示错误消息212,通知利用者不能登记讲话者参数值。并且,在该错误消息212内的“ok”按钮212a被按下时,返回到图14所示的画面210。
另外,在判定结果是带条件地可以登记的情况下,可否利用判定部60例如计算上述被调整后的参数值,向讲话者参数控制部40申请是否登记被调整后的讲话者参数值的询问。讲话者参数控制部40指示显示/输入控制部30询问是否登记被调整后的讲话者参数值。在这种情况下,显示/输入控制部30例如按照图17所示在画面210上弹出显示确认消息213,询问是否登记被调整后的讲话者参数值。并且,在该确认消息213内的“是”按钮213a被按下时,变为图15所示的画面220。另一方面,在确认消息213内的“否”按钮213b被按下时,返回到图14所示的画面210。
另外,可否利用判定部60在判定结果是带条件地可以登记的情况下,还可以按照以上所述求出缩窄讲话者参数的登记范围的替代方案,向讲话者参数控制部40申请是否缩窄登记范围登记讲话者参数值的询问。在这种情况下,显示/输入控制部30例如按照图18所示在画面210上弹出显示确认消息214,询问是否缩窄登记范围登记讲话者参数值。并且,在该确认消息214内的“是”按钮214a被按下时,变为图15所示的画面220。此时,用于选择画面220的登记范围的复选按钮226被固定为“缩窄”的选择肢。另一方面,在该确认消息214内的“否”按钮214b被按下时,返回到图14所示的画面210。
如以上说明的那样,根据本实施方式,还能够按照利用者的操作进行讲话者参数值的登记,因而能够提高利用者的使用便利性。并且,还能够适当地进行讲话者参数的登记所需的登记费的收费处理等。
在与讲话者参数值的登记相关的本实施方式中,对登记时的收费的结构进行了说明,但也可以在与利用了讲话者参数值的合成声音的利用相关的第1实施方式中设置在利用时进行收费的结构。在这种情况下,通过对讲话者参数值的登记条件设置他人的利用费设定的项目,能够设定利用费。还可以是其它任何方式,例如与登记范围一样地预先设定包括免费的多个收费模式进行选择的方式、登记者自由设定的方式。该项目的设定值例如作为图4所示的信息的一部分被存储在讲话者参数存储部50中,由此在可否利用判定部60进行判定时,根据对相应的讲话者特性id设定的条件,一起地显示可否利用和利用费,由此能够对利用者通知利用费。在利用被设定了利用费的讲话者参数值的情况下,能够与登记时一样地利用收费功能来应对。
<第3实施方式>
下面,对第3实施方式进行说明。在上述的第1实施方式中,使用讲话者参数值自身求出所输入的讲话者参数值与已登记讲话者参数值的差异,在这种情况下,在讲话者参数的定义和值的类型由于声音合成模型的更新等而变化的情况下,将不能进行变更前后的讲话者参数值的比较,导致在变更前所登记的讲话者参数值在变更后不能使用。因此,在本实施方式中,在求出所输入的讲话者参数值与已登记讲话者参数值的差异时,不使用其值自身,而将进行比较的讲话者参数值分别映射在共同的其它的参数空间中,在该参数空间中计算差异。
本实施方式的声音合成装置的结构与图1所示的第1实施方式的结构或者图12所示的第2实施方式的结构相同。但是,在本实施方式中,可否利用判定部60在计算所输入的讲话者参数值与已登记讲话者参数值的差异时,将这些进行比较的讲话者参数值分别映射在共同的参数空间中。并且,在该参数空间中计算两者的差异。
在将进行比较的讲话者参数值设为p1sa和p2sb(分别是参数空间sa、sb的参数)、将映射在共同的参数空间sx中的函数设为mapsa→sx()、mapsb→sx()时,按照下述式(7)所示,在映射空间中计算这些讲话者参数值之间的差异diff(p1sa,p2sb)。
diff(p1sa,p2sb)=diffsx(mapsa→sx(p1sa),mapsb→sx(p2sb))……(7)
其中,diffsx表示被映射在参数空间sx中的讲话者参数值之间的差异。
通过使用这样的方法,即使是讲话者参数的定义和值的类型不同的讲话者参数之间,也能够计算差异。并且,即使是定义和值的类型相同的讲话者参数之间,在映射地点的空间是比原来的讲话者参数空间更直接地表示讲话者特性的空间的情况下,通过用该方法求出差异,也能够求出更适当的差异。例如,将映射地点的讲话者参数空间设为对数振幅声谱的向量空间等、可以直接地表示讲话者特性并根据各种各样的讲话者参数值进行计算的通用的参数空间即可。
<补充说明>
上述的各实施方式的声音合成装置例如能够使用通用的计算机作为基本硬件来实现。即,上述的各实施方式的声音合成装置的各部分的功能能够通过使在通用的计算机安装的处理器执行程序来实现。此时,声音合成装置可以通过预先将上述的程序安装于计算机来实现,还可以将上述的程序存储在cd-rom等存储介质中或者通过网络来发布上述的程序,将该程序适当地安装于计算机来实现。
图19是表示声音合成装置的硬件结构例的框图。声音合成装置例如具有如图19所示作为普通的计算机的硬件结构,该计算机具有cpu(centralproccessingunit,中央处理单元)等处理器1、ram(randomaccessmemory,随机存取存储器)或rom(readonlymemory,只读存储器)等存储器2、hdd(harddiskdrive,硬盘驱动)或ssd(solidstatedrive,固态驱动)等存储装置3、设备i/f4、与装置外部进行通信的通信i/f5、和连接这些各部分的总线9,设备i/f4连接液晶显示器等显示装置6、和键盘、鼠标、触摸屏等输入装置7、输出声音的扬声器8这些设备。
在声音合成装置具有如图19所示的硬件结构的情况下,例如通过由处理器1利用存储器2读出并执行在存储装置3等存储的程序,能够实现上述的声音合成部10、显示/输入控制部30、讲话者参数控制部40、可否利用判定部60、讲话者参数登记部70、收费处理部80等的功能。并且,声音合成模型存储部20和讲话者参数存储部50能够使用存储装置3实现。
另外,上述的声音合成装置的各部分的功能的一部分或者全部功能还能够通过asic(applicationspecificintegratedcircuit,专用集成电路)或fpga(fieldprogrammablegatearray,可现场编程门阵列)等专用的硬件(非通用的处理器,而是专用的处理器)来实现。此外,还可以是使用多个处理器实现上述的各部分的功能的结构。
另外,实施方式的声音合成装置还可以构成为使用多台计算机,将上述的各部分的功能分散在多台计算机中来实现的系统。此外,实施方式的声音合成装置还可以是在云系统上工作的假想设备。
以上说明了本发明的实施方式,但在此说明的实施方式是作为例子提示的,并非意图限定发明的范围。在此说明的新的实施方式能够以其他各种各样的形态实施,在不脱离发明的主旨的范围内能够进行各种各样的省略、替换、变更。在此说明的实施方式及其变形包含在发明的范围或主旨中,并且包含在权利要求书所记载的发明和其等价的范围中。
标号说明
10声音合成部
11选择部
12相加部
20声音合成模型存储部
30显示/输入控制部
40讲话者参数控制部
50讲话者参数存储部
60可否利用判定部
70讲话者参数登记部
80收费处理部
- 还没有人留言评论。精彩留言会获得点赞!