一种基于人耳掩蔽效应与贝叶斯估计的改进谱减方法与流程
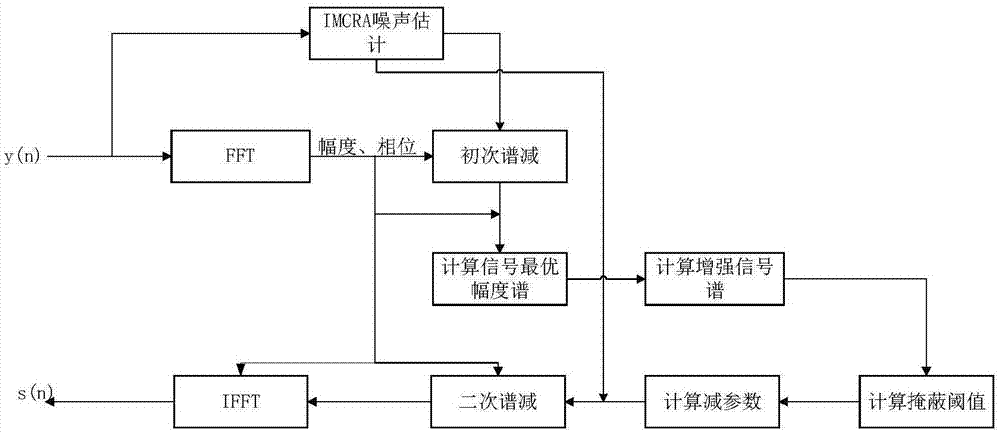
本发明涉及一种基于人耳掩蔽效应与贝叶斯估计的改进谱减方法,属于语音信号处理
技术领域:
。
背景技术:
语音是人与人之间重要的信息交流方式,但在人们利用语音进行交流与通信的过程中,总会受到各种噪声的干扰。带噪语音不仅会增加人的听觉疲劳、降低语音通信质量,而且也会使基于特征参数提取的语音处理系统性能下降。所以,为了减小背景噪声对语音质量的影响,需要进行语音增强来抑制背景噪声。谱减法是一种传统的增强算法,其基本思想是:分别计算带噪语音信号短时幅度谱与估计的噪声信号的短时幅度谱,进行平方运算然后相减。恢复出增强语音信号时将这个结果开方,再插入带噪语音信号的相位,进行反离散傅里叶变换。谱减法的通用形式为:y(ω)为带噪语音的频谱信号,为噪声的频谱信号,为增强语音的频谱信号,p为1是幅度谱减,p为2是功率谱减。谱减法的优点是运算量小,容易实现,增强效果也较好。但因为没有对语音频谱的分布进行假设,谱减法在进行增强处理后,会带来音乐噪声,这不仅对听者在听觉效果上产生一定的干扰影响,还影响后续处理,如语音编码等。因此,如何有效抑制音乐噪声,并权衡考虑增强后的语音失真与去噪效果,是改进谱减法,使其能充分发挥自身优势的重点所在。结合人耳听觉掩蔽效应,是消除谱减法音乐噪声的一个重要思路,有人将谱减公式改进为:yw(ω)为带噪语音的频谱信号,为增强语音的频谱信号,现有的技术方案所使用的噪声估计算法大多不够精确,如话音活动检测(vad)或最小值统计,前者的可靠性会随着信噪比的减小而降低,而后者响应速度慢,这都会影响噪声估计的准确度,降低语音增强的效果。而且当前的技术方案也多存在一个误区,过于注重对音乐噪声的消除,反而影响了语音信号的可懂度,破坏了语音信号,甚至还会降低信噪比。技术实现要素:本发明所要解决的技术问题是克服现有技术的缺陷,提供一种基于人耳掩蔽效应与贝叶斯估计的改进谱减方法,采用改进的最小控制值递归平均算法(imcra)进行噪声估计,对带噪语音进行两次谱减,并于两次谱减之间对语音信号进行基于加权似然比(wlr)失真测度的贝叶斯估计,以此来增强语音信号。为解决上述技术问题,本发明提供一种基于人耳掩蔽效应与贝叶斯估计的改进谱减方法,包括以下步骤:1)采用改进的最小控制值递归平均算法,对原始带噪语音进行噪声估计,得到噪声功率谱估计;2)结合步骤1)求解的噪声功率谱估计对带噪语音信号进行初次谱减;3)对初次谱减后的带噪语音信号进行基于加权似然比失真测度的贝叶斯估计,计算信号增强谱;4)利用人耳掩蔽效应计算第二次谱减的减参数;5)再次采用改进的最小控制值递归平均算法进行噪声估计,利用步骤4)计算的减参数对信号增强谱进行第二次谱减,得到最终的增强语音信号;6)对增强后的语音信号进行反傅里叶变换,得到最终的增强语音。前述的步骤1),噪声功率谱估计的具体求解如下:11)对离散时间带噪语音信号y(n)的m个样本加窗,并进行m点的fft,将带噪语音信号变换到频域,得到带噪语音的频域信号y(λ,k),其中,y(n)=d(n)+x(n),d(n)为噪声信号,x(n)为纯净信号,n代表不同时刻;λ为帧数标记,k,k=0,1,2,…,m-1表示频点;12)对带噪语音的频域信号进行第一次平滑,采用公式(1)计算平滑功率谱s(λ,k),并不断更新其最小值smin(λ,k);s(λ,k)=αss(λ-1,k)+(1-αs)sf(λ,k)(1)其中,αs为平滑因子,其中,w(i)为hanning窗函数,lw为i的取值上限;最小值smin(λ,k)的更新如下:首先设置一个临时变量stmp(λ,k),初始化stmp(0,k)=s(0,k),如果当前帧数λ能够被d整除,则smin(λ,k)根据公式(3)进行更新,同时将stmp(λ,k)设为s(λ,k):smin(λ,k)=min{stmp(λ-1,k),s(λ,k)}(3)如果当前帧数λ不能够被d整除,那么先依据公式(4)更新smin(λ,k),同时再根据公式(5)更新临时变量stmp(λ,k):smin(λ,k)=min{smin(λ-1,k),s(λ,k)}(4)stmp(λ,k)=min{stmp(λ-1,k),s(λ,k)}(5)13)利用smin(λ,k),通过公式(6)计算指示函数i(λ,k):其中,γ0与ζ0为阈值参数,且其中,bmin表示最小噪声估计的偏差;14)根据指示函数i(λ,k)进行第二次平滑,利用公式(8)、公式(9)计算平滑功率谱密度并实时更新最小值15)利用通过公式(10)、公式(11)计算不存在语音的先验概率q(λ,k):其中,γ1,为阈值参数;16)计算语音存在概率p(λ,k):其中,γk(λ)和ξk(λ)分别为频点k的后验信噪比与先验信噪比,其中,是前一帧经过补偿后的噪声功率谱估计,αq为权重因子,为对数增益函数,为一个指数积分,t为积分变量;17)利用语音存在概率p(λ,k)通过公式(16)计算平滑参数αd(λ,k),并根据公式(17)和公式(18)更新噪声谱,其中,为计算的噪声功率谱估计,为经过补偿后的噪声功率谱估计,αi取0.8,βi为偏差补偿因子,取1.47。前述的步骤2),初次谱减后的功率谱如下:其中,为初次谱减后的功率谱,|y(w)|2为原始带噪语音的功率谱,w表示频率变量,噪声功率谱估计即步骤1)中的前述的步骤3),计算信号增强谱具体过程如下:31)采用加权似然比作为贝叶斯估计的失真测度,计算初次谱减后信号的最优幅度谱,其中,贝叶斯估计的失真测度为:其中,xk为纯净信号谱在频点k的幅度,为噪声估计谱在频点k的幅度;将贝叶斯风险对求导,得到下式:其中,bk=e[xk|y(ωk)],为最小均方误差估计,p(xk|y(ωk))为xk的后验概率密度函数,表示已知带噪语音谱y(ωk)存在概率下,纯净信号谱xk的存在概率,ωk即频点k处的频率值,其中,ρk为ωk处后验信噪比,vk=ρkψk/(1+ψk),ψk为ωk处先验信噪比,ψk=a+(1-a)max[ρk-1,0],a为一个权重因子;对公式(21)求零点得到信号最优幅度谱32)利用最优幅度谱构建频点k的信号增强谱其中,θy(k)为频点k处的相位;33)将所有频点处的信号增强谱叠加,得到最终的信号增强谱前述的步骤4),第二次谱减的减参数的计算过程为:41)计算关键频带的能量bi:其中,bhi、bli分为关键频带i的频率上限和下限,i=1,…,imax,imax取决于采样频率fs,p(w)为经过初次谱减和基于加权似然比失真测度的贝叶斯估计后信号的功率谱;42)计算扩展频谱ci:ci=sij*bi其中,sij为扩展矩阵,其中,δ=i-j,i,j=1,…,imax,i是被掩蔽信号的bark频率,j是掩蔽信号的bark频率;43)计算噪声掩蔽阈值,具体包括:431)引入音调系数αto:其中,sfm为谱平坦测度,sfmdbmax=-60db,gm、am分为功率谱p(w)的几何平均与算数平均;432)定义每个bark段i掩蔽能量的偏移函数oi:oi=αto(14.5+i)+(1-αto)5.5(25)433)计算扩展后的掩蔽阈值ti:ti=10log10(ci)-0.1oi(26)434)将ti转换回扩展前的bark域,得到t′i(w),并将其与安静时人耳的绝对听觉阈值对比,得到最终的听觉掩蔽阈值tfinal(w):tfinal(w)=max[ti′(w),tq(w)](27)其中,tq(w)为绝对听觉阈值,44)计算减参数α和β,其中,α表示过衰减因子,β表示谱底限,α和β统称为减参数,αmin=1,αmax=6,βmin=0,βmax=0.02,tmax,tmin分别代表掩蔽阈值按帧更新的最大、最小值。前述的步骤5),第二次谱减后的功率谱为:其中,y(w)为经过初次谱减和基于wlr的贝叶斯估计后信号的频谱信号,为最终的增强语音的功率谱,g(w)为改进的增益函数,其中,为再次进行最小控制值递归平均算法的噪声估计谱,ε与τ为加权因子,本发明所达到的有益效果为:1.本发明采用改进的最小控制值递归平均算法(imcra),克服了低信噪比环境下噪声估计不准确的缺陷,并能快速响应噪声谱的变化,在提高噪声估计准确度的同时,最小化语音失真,达到了更好的增强效果。2.有别于常用的一次谱减,本发明进行了两次谱减,并在两次谱减之间使用了基于加权似然比(wlr)失真测度的贝叶斯估计,以此来计算信号的最优幅度谱,减少残留噪声,达到对语音信号的增强。3.本发明的第二次谱减采用了滤波谱减,并对滤波谱减的增益函数进行了改进,为减参数α,β进行了加权,并通过实验调节参数,在保证甚至提高消噪效果的前提下,尽可能地提高语音可懂度。附图说明图1为本发明的方法流程图。具体实施方式下面对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。如图1所示,本发明的具体实现步骤如下:第一步:对带噪语音进行最小控制值递归平均算法(imcra)噪声估计,具体包括以下步骤:11)令y(n)=d(n)+x(n)来表示离散时间带噪语音信号,其中,d(n)为噪声信号,x(n)为纯净信号,n代表不同时刻。假定x(n)与d(n)是统计独立并具有零均值。对y(n)的m个样本加窗,并进行m点的fft,将带噪语音变换到频域,得到带噪语音的频域信号y(λ,k),其中,λ为帧数标记,k(k=0,1,2,…,m-1)表示频点。12)对带噪语音的频域信号进行第一次平滑,采用公式(1)计算平滑功率谱s(λ,k),并不断更新其最小值smin(λ,k)。s(λ,k)=αss(λ-1,k)+(1-αs)sf(λ,k)(1)其中,αs为平滑因子,且其中,lw为i的取值上限,为正整数,w(i)为hanning窗函数,为了系统的性能,窗长取2lw+1。此处lw=1,αs=0.9。局部最小值smin(λ,k)通过在一个d帧的固定窗口长度上,与过去每一个s(λ,k)值进行对比得到。首先设置一个临时变量stmp(λ,k),初始化stmp(0,k)=s(0,k)。如果当前帧数λ可以被d整除,则smin(λ,k)根据公式(3)进行更新,同时将stmp(λ,k)设为s(λ,k)。smin(λ,k)=min{stmp(λ-1,k),s(λ,k)}(3)如果当前帧数λ不可以被d整除,那么先依据公式(4)更新smin(λ,k),同时再根据公式(5)更新临时变量stmp(λ,k),为下一帧的最小值搜索做准备。smin(λ,k)=min{smin(λ-1,k),s(λ,k)}(4)stmp(λ,k)=min{stmp(λ-1,k),s(λ,k)}(5)13)利用smin(λ,k),通过公式(6)计算指示函数i(λ,k)进行话音活动检测。其中,γ0与ζ0为阈值参数,且其中,因子bmin代表了最小噪声估计的偏差,bmin取1.66,γ0取4.6,ζ0取1.67。14)根据指示函数i(λ,k)进行第二次平滑,利用公式(8)、公式(9)计算平滑功率谱密度并实时更新最小值的更新原理同smin(λ,k)。15)利用通过公式(10)、公式(11)计算不存在语音的先验概率q(λ,k),其中,γ1,为阈值参数,γ1=3,bmin取1.66。16)分别计算后验信噪比γk(λ)和先验信噪比ξk(λ),并结合不存在语音的先验概率q(λ,k),通过公式(12)计算语音存在概率p(λ,k),其中,γk(λ)和ξk(λ)分别为频点k的后验与先验snr,分别由公式(13)和(14)计算而得:其中,是前一帧经过补偿后的噪声功率谱估计,αq为权重因子,用来平衡降噪与语音失真,取0.92,为对数增益函数,为一个指数积分,t为积分变量。17)利用语音存在概率p(λ,k)通过公式(16)计算平滑参数αd(λ,k),并根据公式(17)和公式(18)更新噪声谱。其中,即噪声功率谱估计,为了避免谱估计过低,将乘上一个偏差补偿因子βi,得到最终的补偿后的噪声功率谱估计此处,αi取0.8,βi为偏差补偿因子,取1.47。第二步:利用imcra计算出的噪声功率谱估计进行第一次谱减,谱减后的功率谱形如公式(19):其中,|y(w)|2为原始带噪语音的功率谱,为第一次谱减后的功率谱,w表示频率变量,噪声功率谱估计即第一步中的第三步:对第一次谱减后的带噪语音信号进行基于加权似然比(wlr)失真测度的贝叶斯估计,具体如下:31)采用加权似然比(wlr)作为贝叶斯估计的失真测度,计算第一次谱减后信号的最优幅度谱,wlr失真测度由公式(20)表示:其中,xk为纯净信号谱在频点k的幅度,为噪声估计谱在频点k的幅度。将贝叶斯风险对求导,得到下面的非线性公式(21):其中,bk=e[xk|y(ωk)],为最小均方误差估计(mmse),p(xk|y(ωk))为xk的后验概率密度函数,表示已知频点k的带噪语音谱y(ωk)存在概率下,纯净信号谱xk的存在概率,其中,ωk即频点k处的频率值,ρk为ωk处后验信噪比,ρk=|y(ωk)|2/(|y(ωk)|2-|xk|2),vk=ρkψk/(1+ψk),ψk为ωk处先验信噪比,ψk=a+(1-a)max[ρk-1,0],a为一个权重因子,a=0.98。对公式(21)求零点得到信号最优估计幅度谱。32)利用上一步得出的最优估计幅度谱构建信号增强谱其中,θy(k)为在频率点k处的相位。最后,将所有频点处的信号增强谱叠加,得到最终的信号增强谱第四步:利用人耳掩蔽效应计算第二次谱减的减参数α,β41)计算关键频带的能量。人耳对同一关键频带内的频率成分具有相同的感知程度,根将经过第一次谱减和基于wlr的贝叶斯估计后信号的功率谱p(w)按频段逐一划分,据公式(22)叠加每一关键频带内的功率谱得到关键频带i内的能量bi。关键频带的划分如表1所示,其中,为第三步求得的信号增强谱,bhi、bli分为关键频带i的频率上限和下限,i=1,…,imax,imax取决于采样频率fs,本发明采用fs=8khz,imax基于整个系统,取到21。表1关键频带42)引入扩展函数,计算扩展频谱。扩展函数符合abs(j-i)≤25,其中,i是被掩蔽信号的bark频率,j是掩蔽信号的bark频率。其扩展矩阵sij形式如公式(23):其中,δ=i-j,i,j=1,…,imax。将sij与bi卷积得到扩展频谱:ci=sij*bi。43)计算噪声掩蔽阈值。为了判别当前信号为纯音特性还是类噪,引入音调系数αto如公式(24)所示:其中,sfm为谱平坦测度,sfmdbmax=-60db,gm、am分为功率谱p(w)的几何平均与算数平均。αto=0代表当前信号被认作纯音信号,αto=1则代表当前信号被认作纯噪声,实际信号居于二者之间。之后利用公式(25)定义每个bark段i掩蔽能量的偏移函数oi:oi=αto(14.5+i)+(1-αto)5.5(25)其中,(14.5+i)db表示纯音信号掩蔽了噪声,5.5db反之。最后,扩展后的掩蔽阈值如公式(26):将ti转换回扩展前的bark域,得到t′i(w),并将其与安静时人耳的绝对听觉阈值对比,得到最终的听觉掩蔽阈值tfinal(w):tfinal(w)=max[ti′(w),tq(w)](27)其中,tq(w)为绝对听觉阈值,表达形式如公式(28):44)减参数α,β基于听觉掩蔽阈值tfinal(w)来调节,即公式(29),(30)。其中,α表示过衰减因子,β表示谱底限,αmin=1,αmax=6,βmin=0,βmax=0.02。tmax,tmin分别代表掩蔽阈值按帧更新的最大、最小值。第五步:进行二次谱减51)在二次谱减之前再次进行imcra噪声估计,过程同第一步,得到噪声估计谱52)二次谱减采用滤波形式的谱减算法,形如公式(31),其中,改进的增益函数g(w)由公式(32)得出,其中,y(w)为经过第一次谱减和基于wlr的贝叶斯估计后信号的频谱信号,为最终的增强语音的功率谱,α,β由第四步求出,ε与τ为提高增强效果的加权因子,本发明依实验效果ε取0.5,τ取2,而第六步:对二次谱减后的信号进行ifft,得到最终的增强语音s(n)。实施例本发明与另两种算法进行了对比,具体如下:方法一:传统谱减法,参见berouti,m.,schwartz,m.,andmakhoul,j.(1979).enhancementofspeechcorruptedbyacousticnoise.proc.ieeeint.conf.acoust.,speech,signalprocessing,208-211。方法二:基于人耳掩蔽效应的谱减法,使用语音活动检测(vad)估计噪声,谱减法为未改进的滤波谱减,参见蔡汉添,袁波涛.一种基于听觉掩蔽模型的语音增强算法[j].通信学报,2002(8):93-98。方法三:本发明方法分别使用这三种方法对信噪比为-5db,0db,5db的带噪语音进行增强,噪声类型为白噪声。其中pesq值用来衡量语音的可懂度。pesq(perceptualevaluationofspeechquality)即:主观语音质量评估。itu-tp.862建议书提供的客观mos值评价方法。表2[-5db]噪声增强后的信噪比增强后的pesq值方法一1.831.35方法二2.931.24方法三3.711.60注:初始pesq为1.58表3[0db]噪声增强后的信噪比增强后的pesq值方法一5.751.80方法二5.241.72方法三7.051.92注:初始pesq为1.75表4[5db]噪声增强后的信噪比增强后的pesq值方法一9.992.17方法二6.841.92方法三10.672.21注:初始pesq为1.92综合表2,表3,表4可以看出,本发明所实现的算法所取得的增强效果是最好的,尤其在低信噪比情况下,做到了在提高算法消噪效果的同时,保护甚至是提高了语音的可懂度。以上所述仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1