一种基于MFCC语音特征的语音匹配方法及存储介质与流程
本发明涉及语音识别技术领域,具体涉及一种基于mfcc语音特征的语音匹配方法及存储介质。
背景技术
近十几年来,在细化模型的设计、参数提取及优化,以及系统的自适应技术上取得了一些关键进展。语音识别技术越来越成熟,准确率逐步得到提高,并且市场上有相应的语音产品。
在智能录播系统中,不断的提高人机交互体验性更加便于老师不需要管理录播系统,语音命令词识别进而控制录播系统的常用功能,老师可以忘记录播系统的存在,更加专心与教学。老师上课时只需要说声“开始录制”,录播系统就开始录制视频。下课结束时说声“停止录制”即可完成一节课堂的录制。
目前市场上有对应的命令词识别模块,但是大部分的应用都得联网才能实现命令词的识别,这妨碍了命令词识别功能在嵌入式录播系统的应用,小型高效的命令词识别在嵌入式系统里很有前景的。
技术实现要素:
鉴于以上技术问题,本发明的目的在于提供一种基于mfcc语音特征的语音匹配方法及存储介质,解决命令词识别系统不联网状态下语音命令词的语音匹配问题。
本发明采用以下技术方案:
一种基于mfcc语音特征的语音匹配方法,包括以下步骤:
获取有效语音的mfcc特征系数;
将有效语音的mfcc特征系数与预设的若干mfcc特征系数依次进行匹配,得到若干mfcc特征系数对应的若干相似值;所述预设的若干mfcc特征系数为预设的若干命令词对应的mfcc特征系数;
当某一相似值小于预设相似值时,则判断有效语音的mfcc特征系数与该相似值对应的mfcc特征系数匹配成功,并提取匹配成功的mfcc特征系数对应的命令词。
进一步的,将有效语音的mfcc特征系数与预设的若干mfcc特征系数依次进行匹配的步骤具体包括将有效语音的mfcc特征系数与预设的若干mfcc特征系数依次通过dtw相似性算法进行匹配。
进一步的,获取有效语音的mfcc特征系数的步骤具体包括:
对有效语音依次进行分帧和加汉明窗,得到分帧加窗后的有效语音;
对分帧加窗后的有效语音提取mfcc特征系数。
进一步的,对分帧加窗后的有效语音提取mfcc特征系数的步骤具体包括:
对分帧加窗后的有效语音进行fft傅里叶变换,得到有效语音频谱;将有效语音频谱通过滤波器组进行,并计算通过滤波器组的有效语音频谱共振峰;根据得到的共振峰计算有效语音频谱的对数能量值x(m),根据得到的对数能量值x(m)计算有效语音频谱的mfcc特征系数。
进一步的,对有效语音依次进行分帧和加汉明窗,得到分帧加窗的有效语音的步骤包括:
根据预设帧长n和帧移对有效语音进行分帧,得到n帧分帧有效语音;将得到的n帧分帧有效语音均加汉明窗,汉明窗的数值w满足以下公式:
进一步的,所述共振峰hm(k)满足以下公式:
进一步的,所述对数能量值满足以下公式:对数能量值
其中,x(m)为有效语音频谱通过第m个滤波器时的对数能量值,m为滤波器组中滤波器的个数,hm(k)为有效语音频谱中频率为k的频谱通过第m个滤波器时的共振峰,x(k)为有效语音频谱中频率为k的频谱振幅,n为预设帧长,m为自然数;
进一步的,所述mfcc特征系数满足以下公式:
mfcc特征系数
其中,xj为第k阶梅尔特征系数,m为滤波器组中滤波器的个数,n为预设帧长,x(m)为有效语音频谱通过第m个滤波器时的对数能量值,l为mfcc系数的阶数,l、j均为自然数。
进一步的,所述预设的若干命令词根据嵌入式录播系统的老师预先录制的命令词语音获取。
一种计算机存储介质,实现上述的基于mfcc语音特征的语音匹配方法。
相比现有技术,本发明的有益效果在于:
本发明通过将获取的有效语音的mfcc特征系数与预设的若干mfcc特征系数依次进行匹配,得到若干mfcc特征系数对应的若干相似值;预设的若干mfcc特征系数为预设的若干命令词对应的mfcc特征系数;当某一相似值小于预设相似值时,则判断有效语音的mfcc特征系数与该相似值对应的mfcc特征系数匹配成功,并提取匹配成功的mfcc特征系数对应的命令词,从而实现不联网状态下语音命令词的语音匹配。
进一步的,预设的若干命令词根据嵌入式录播系统的老师预先录制的命令词语音获取,这样,命令词可根据老师的说话特点,将老师说的命令词语音作为匹配模板,进一步提高了语音命令词语音匹配的准确率。
附图说明
图1为本发明基于mfcc语音特征的语音匹配方法的流程示意图;
图2为本发明的获取有效语音的mfcc特征系数的流程示意图;
图3为获取待识别语音的有效语音的流程示意图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例:
实施例:
如图1所示,本发明的基于mfcc语音特征的语音匹配方法包括:
步骤s200:获取有效语音的mfcc特征系数;(mfcc,即mel频率倒谱系数的缩写);
具体的,如图2所示,获取有效语音的mfcc特征系数的步骤具体包括:
步骤s2001:对有效语音依次进行分帧和加汉明窗,得到分帧加窗后的有效语音;
步骤s2002:对分帧加窗后的有效语音提取mfcc特征系数;
对分帧加窗后的有效语音提取mfcc特征系数的步骤具体包括:
步骤s20021:对分帧加窗后的有效语音进行fft傅里叶变换,得到有效语音频谱;
步骤s20022:将有效语音频谱通过滤波器组进行,并计算通过滤波器组的有效语音频谱共振峰;
步骤s20023:根据得到的共振峰计算有效语音频谱的对数能量值x(m);
步骤s20024:根据得到的对数能量值x(m)计算有效语音频谱的mfcc特征系数。
对有效语音依次进行分帧和加汉明窗,得到分帧加窗的有效语音的步骤包括:
根据预设帧长n和帧移对有效语音进行分帧,得到n帧分帧有效语音;将得到的n帧分帧有效语音均加汉明窗,汉明窗的数值w满足以下公式:
所述共振峰hm(k)满足以下公式:
所述对数能量值满足以下公式:对数能量值
其中,x(m)为有效语音频谱通过第m个滤波器时的对数能量值,m为滤波器组中滤波器的个数,hm(k)为有效语音频谱中频率为k的频谱通过第m个滤波器时的共振峰,x(k)为有效语音频谱中频率为k的频谱振幅,n为预设帧长,m为自然数;
所述mfcc特征系数满足以下公式:
mfcc特征系数
其中,xj为第k阶梅尔特征系数,m为滤波器组中滤波器的个数,n为预设帧长,x(m)为有效语音频谱通过第m个滤波器时的对数能量值,l为mfcc系数的阶数,l、j均为自然数。
作为实施例:所述滤波器组为三角滤波器组,所述三角滤波器组包括若干个三角滤波器,滤波器的个数为26个。
本发明通过对有效语音进行分帧,对每帧加汉明窗以减少频率的泄露,再对每帧进行fft傅里叶变换,得到有效语音频谱,将有效语音频谱使用了26个三角滤波器,对每帧经过fft傅里叶变换后的数据进行三角滤波以模拟人耳的掩蔽效应。最后对每帧进行dct离散余弦变换即可得到每帧语音的mfcc梅尔特征系数。
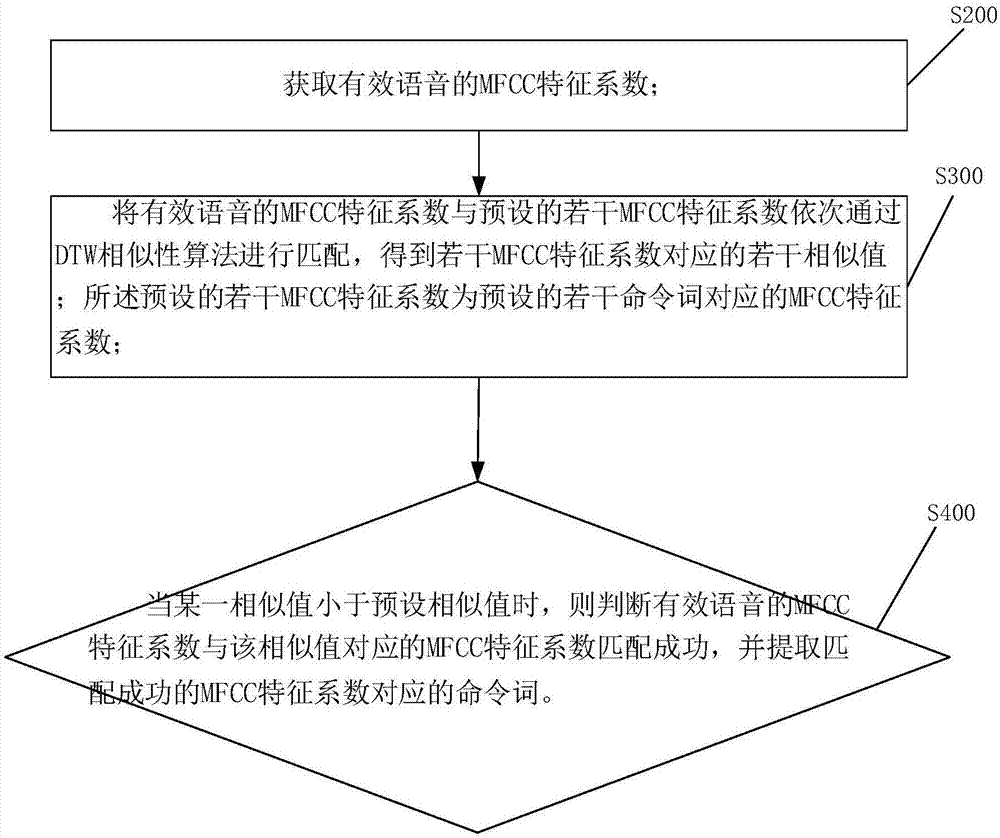
步骤s300:将有效语音的mfcc特征系数与预设的若干mfcc特征系数依次通过dtw相似性算法进行匹配,得到若干mfcc特征系数对应的若干相似值;所述预设的若干mfcc特征系数为预设的若干命令词对应的mfcc特征系数;所述预设的若干命令词根据嵌入式录播系统的老师预先录制的命令词语音获取。
步骤s400:当某一相似值小于预设相似值时,则判断有效语音的mfcc特征系数与该相似值对应的mfcc特征系数匹配成功,并提取匹配成功的mfcc特征系数对应的命令词。
通过将有效语音的mfcc特征系数与预设的命令词的mfcc特征系数使用dtw匹配算法进行匹配,实现将相似度控制在相似值的阈值以内的命令词匹配上。
本发明用于在命令词识别系统不联网状态下语音命令词的语音匹配问题,命令词的识别方法,包括:步骤s100:获取待识别语音的有效语音;步骤s200:将有效语音进行基于mfcc语音特征的语音匹配。
具体的,获取待识别语音的有效语音的步骤包括,如图3所示:
获取待识别语音的开始点和结束点;所述待识别语音的有效语音为以所述开始点开始,并以所述结束点结束的完整语音;
获取待识别语音的开始点和结束点包括以下步骤:
步骤s1001:根据预设的采样频率和采样大小对待识别语音依次进行采样,得到若干采样音频数据,所述采样音频数据对应待识别语音的若干采样点;并将所有采样音频数据依次通过fft傅里叶变换得到若干采样频谱。
步骤s1002:获取所有采样频谱频率位于100~1000hz的能量值;并将所述能量值依次与预设能量值n1进行对比;
步骤s1003:获取所有采样频谱频率位于300~1000hz频段内的能量方差;并将所述能量方差依次与预设能量值n2进行对比;
步骤s1004:当采样频谱频率中频率位于300~1000hz频段获取的能量值大于预设能量值n1,且获取的能量方差大于预设能量值n2时,则判断该采样频谱对应的采样点位于有效语音的范围;
步骤s1005:将位于完整语音的范围的所有采样点按时序排列,得到按时序排列的完整语音的采样点序列,以有效语音的采样点序列中的第一采样点为有效语音的开始点;
步骤s1006:当采样频谱频率中频率位于300~1000hz频段获取的能量值未大于预设能量值n1或获取的能量方差未大于预设能量值n2时,则判断该采样频谱对应的采样点位于噪音的范围;
步骤s1007:将位于噪音的范围的采样点、且采样点采样时间位于有效语音的开始点之后的所有采样点按时序排列,得到按时序排列的噪音的采样点序列,以噪音的采样点序列中第一采样点为有效语音的结束点。所述按时序排列是指按照采样点在待识别语音中的出现的时间先后顺序。采样点采样时间先后顺序也是以采样点在待识别语音中的出现的时间先后顺序依次进行采样。
数字化的声音数据就是音频数据。在数字化声音时有两个重要的指标,即采样频率和采样大小。采样频率即单位时间内的采样次数,采样频率越大,采样点之间的间隔越小,数字化得到的声音就越逼真,但相应的数据量增大,处理起来就越困难;采样大小即记录每次样本值大小的数值的位数,它决定采样的动态变化范围,位数越多,所能记录声音的变化程度就越细腻,所得的数据量也越大。优选的,预设的采样大小为2048个音频数据。如果采样大小太小,这样得到的这段音频会不准确,频率分辨率过低,需要通过fft傅里叶变换补零,补零的情况会耗费cpu资源及耗时,采样过多也会耗时,因此,采用了采样大小2048个音频数据,既保证了分辨率的精度,也不会过多耗费cpu资源。
将一段语音从时域转为频域,这段语音这时就有可量化的参数,(人声的频率范围)判断是否有这段语音是否有人声的频率同时对应的频率能量值是多少。本发明的发明点进一步通过将频段的能量方差与预设能量值n2进行对比,提高了对待识别语音开始点和结束点判断的准确率,大部分在100-1000hz的噪音各个频段的能量值相差不大,因此这些噪音方差值比较小。
调节n1和n2值,值越小,越灵敏,很容易触发程序判断为这段语音就是人声不是噪音,但是误触发的概率会越大。根据项目多方面的测试,当预设能量值n1设置为38000-60000j,预设能量值n2设置为30-70j时,大大提高了开始点和结束点检测的准确率。
本发明中,待识别语音主要是指语音命令词,本发明主要是用于嵌入式录播系统的老师的命令词语音识别。
本发明还提供一种计算机可读存储介质,其上存储有计算机程序,可以存储在该计算机可读取存储介质中。基于这样的理解,本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一计算机可读存储介质中,该计算机程序在被微处理器执行时,可实现上述各个方法实施例的步骤。其中,所述计算机程序包括计算机程序代码,所述计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,所述计算机可读介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
对本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!