多语音助理的控制方法与流程
本公开涉及一种控制方法,特别涉及一种应用于智能电子装置的多语音助理的控制方法。
背景技术:
近年来,随着智能电子装置的进步,智能家电以及智慧家庭等也被提出并应用。其中,智能音箱已逐渐普及于一般家庭及小型店面中,有别于传统音箱,智能音箱通常配置了语音助理(例如:amazon公司的alexa),以通过对话的方式提供使用者多种功能的服务。
由于声音辨识与语音助理的科技不断改良,单一电子装置中已可同时安装多个不同的语音助理,以就不同的功能提供使用者服务。例如与系统面直接结合的语音助理可以提供关于系统方面例如时间、日期、行事历及闹钟等方面的功能,而与特定软件或功能结合的语音助理可以提供特定数据搜索、购物、预约餐厅及订购车票等功能或服务。
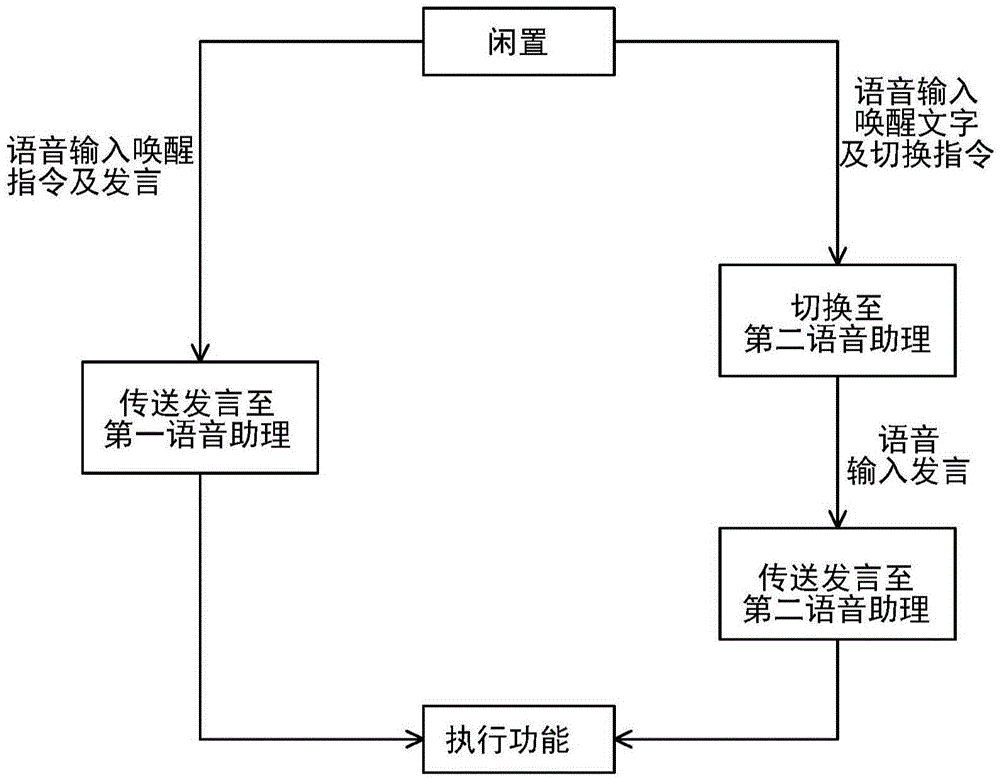
然而,现有的安装多语音助理的电子装置,在欲切换不同语音助理执行对应的功能或服务时,需要额外的切换指令方能实现。请参阅图1,其是显示现有技术中多个语音助理的控制方法的简单流程图。如图1所示,当电子装置处于闲置状态时,若使用者通过语音输入唤醒指令加上一般发言,则电子装置被唤醒并将发言内容传送至与系统面结合的第一语音助理,并执行该发言中所提及的相关功能或提供相关服务。然而,各个语音助理可以提供的功能及服务并不相同,故当使用者欲使用第一语音助理无法提供的功能或服务时,使用者若以前述方式进行语音输入,则第一语音助理会被唤醒,但不会执行任何功能。此时使用者必须先以语音输入唤醒指令加上切换指令,待电子装置回应确认已切换至第二语音助理时,再以语音输入一般发言,第二语音助理才会执行该发言中所提及的相关功能或提供相关服务。也就是说,使用者必须牢记功能或服务对应的语音助理,并确实输入切换指令并等待电子装置回应确认语音助理的切换,方能通过适当的语音助理完成想执行的功能或想得到的服务,不只使用者体验极差,操作不直觉又浪费许多等待时间,多次的对话也可能造成更多的辨识错误,应用上十分不便,甚至可能让使用者不愿通过语音助理进行操作。
故此,如何发展一种可有效解决前述现有技术的问题与缺点的多语音助理的控制方法,实为目前尚待解决的问题。
技术实现要素:
本公开的主要目的为提供一种多语音助理的控制方法,从而解决并改善前述现有技术的问题与缺点。
本公开的另一目的为提供一种多语音助理的控制方法,通过分析声音物件后直接选择对应的辨识引擎,可达到直接呼叫对应的语音助理进行服务,让使用者以更直觉的对话方式使用电子装置,进而增进使用者体验并减少等待时间的技术效果。
本公开的另一目的为提供一种多语音助理的控制方法,通过仲裁器、辨识原则及聆听器的应用,不仅可在等待时间超过一预设时间时提前启用所有辨识引擎重新进行辨识,还可直接地因应聆听器输入至仲裁器的内容选择对应的辨识引擎,以减少使用者的等待时间并且避免多余对话产生的错误。
为达上述目的,本公开的一优选实施方式为提供一种多语音助理的控制方法,包括步骤:(a)提供配备多个语音助理的一电子装置;(b)启用所述多个语音助理对应的多个辨识引擎,使该电子装置进入一聆听模式,以接收至少一声音物件;(c)分析接收到的该声音物件,并根据一分析结果自所述多个辨识引擎中选择对应的该辨识引擎;(d)判断会话是否结束;(e)修改对应于所述多个辨识引擎的多个辨识阈值;以及(f)关闭非对应的该辨识引擎;其中,当该步骤(d)的判断结果为是,于该步骤(d)之后执行该步骤(b),且当该步骤(d)的判断结果为否,于该步骤(d)之后依序至少执行该步骤(e)及该步骤(f)。
附图说明
图1是显示现有技术中多个语音助理的控制方法的简单流程图。
图2是显示本公开优选实施例的多语音助理的控制方法的流程图。
图3是显示本公开另一优选实施例的多语音助理的控制方法的流程图。
图4是显示本公开多语音助理的控制方法适用的电子装置的架构方框图。
图5是显示本公开多语音助理的控制方法的仲裁器的互动关系示意图。
图6是显示本公开多语音助理的控制方法的仲裁器的运行状态示意图。
附图标记说明:
1:电子装置
10:中央处理器
11:输入输出接口
111:麦克风
12:存储装置
121:仲裁器
122:聆听器
123:辨识原则
13:快闪存储器
14:网络接口
21:第一辨识阈值
210:第一辨识引擎
22:第二辨识阈值
220:第二辨识引擎
s10、s20、s30、s40、s45、s50、s60:步骤
具体实施方式
体现本公开特征与优点的一些典型实施例将在后段的说明中详细叙述。应理解的是本公开能够在不同的实施方式上具有各种的变化,其皆不脱离本公开的范围,且其中的说明及图示在本质上是当作说明的用,而非架构于限制本公开。
请参阅图2,其是显示本公开优选实施例的多语音助理的控制方法的流程图。如图2所示,本公开优选实施例的多语音助理的控制方法包括步骤如下:首先,如步骤s10所示,提供配备多个语音助理的电子装置,该电子装置可为例如但不限于智能音箱、智能手机或是智能家庭中控装置等。其次,如步骤s20所示,启用多个语音助理对应的多个辨识引擎,使电子装置进入聆听模式,以接收至少一声音物件,该声音物件可包括唤醒指令及发言内容,但不以此为限。在一些实施例中,每一个辨识引擎用以辨识其对应的语音助理的相关唤醒指令及/或包含动作指示的发言,例如一第一辨识引擎辨识“设定闹钟”而令第一语音助理提供闹钟功能服务,一第二辨识引擎辨识“购买某产品”而令第二语音助理打开对应app购买该产品等。应注意的是,若个别语音助理彼此提供的功能或服务彼此皆相异,本公开的多语音助理的控制方法于控制时可以直接以功能或服务名称作为唤醒指令,但不以此为限。
接着,如步骤s30所示,分析接收到的声音物件,并根据分析结果自多个辨识引擎中选择对应的辨识引擎。然后,如步骤s40所示,判断会话是否结束,其中当步骤s40的判断结果为是,即判断会话结束时,于步骤s40之后重新执行步骤s20;而当步骤s40的判断结果为否,即判断会话仍未结束时,于步骤s40之后依序至少执行步骤s50及步骤s60。应特别注意的是,此处的会话于优选实施例中是指使用者与电子装置之间的会话。在步骤s50中,修改对应于所述多个辨识引擎的多个辨识阈值。于步骤s60中,关闭非对应的辨识引擎。通过分析声音物件后直接选择对应的辨识引擎,可达到直接呼叫对应的语音助理进行服务,让使用者以更直觉的对话方式使用电子装置,进而增进使用者体验并减少等待时间的技术效果。
请参阅图3,其是显示本公开另一优选实施例的多语音助理的控制方法的流程图。如图3所示,本公开多语音助理的控制方法,于步骤s40之后可进一步包括步骤s45,步骤s45是判断等候后续指令的一等待时间是否逾时,其中当步骤s40的判断结果为否,即会话仍未结束时,于步骤s40之后依序执行步骤s45、步骤s50及步骤s60。当步骤s45的判断结果为是,即判断等待时间逾时的情况下,于步骤s45之后执行步骤s20,且当步骤s45的判断结果为否,即判断等待时间未逾时的情况下,于步骤s45之后执行步骤s50及步骤s60。
请参阅图4,其是显示本公开多语音助理的控制方法适用的电子装置的架构方框图。如图4所示,可实现本公开的多语音助理的控制方法的电子装置1,其基础架构包括中央处理器10、输入输出接口11、存储装置12、快闪存储器13及网络接口14。其中,输入输出接口11、存储装置12、快闪存储器13及网络接口14与中央处理器10相连接。中央处理器10架构于控制输入输出接口11、存储装置12、快闪存储器13及网络接口14,以及整体电子装置1的运行。输入输出接口11(i/ointerface)包括麦克风111,且麦克风111主要供使用者语音输入之用,但不以此为限。电子装置1可进一步包括聆听器,另在一些实施例中,聆听器可为软件单元,存储于存储装置12中。举例来说,如图4所示的存储装置12中可包括仲裁器121、聆听器122及辨识原则123,其中仲裁器121及聆听器122于本公开中属于软件单元,可存储或整合于存储装置12中。当然仲裁器121及聆听器121亦可能以硬件的方式(例如仲裁芯片),独立于存储装置12之外,于此不多行赘述。存储装置12预载辨识原则123,且辨识原则123优选以一数据库的形式存在,但不以此为限。快闪存储器13可作为挥发性空间如主存储器或随机存取存储器,亦可作为额外存储或系统磁盘的用。网络接口14则是有线网络或无线网络接口,以供电子装置连线一网络,例如区域网络或网际网络等。
请参阅图5并配合图2至图4,其中图5是显示本公开多语音助理的控制方法的仲裁器的互动关系示意图。如图2、图3、图4及图5所示,于本公开多语音助理的控制方法的流程步骤中,于步骤s20中,当电子装置1进入聆听模式,仲裁器121由一闲置状态进入一聆听状态。此外,于步骤s30中,仲裁器121根据辨识原则123及输入自聆听器122的声音物件进行分析,以得到分析结果。另一方面,在步骤s40中,仲裁器121根据来自聆听器122的输入进行判断,且当该输入为一会话结束的通知,步骤s40的判断结果为是,即判断会话结束。相似地,在步骤s45中,仲裁器121根据辨识原则123进行判断,且当等待时间大于辨识原则123中预先设定的一预设时间,步骤s45的判断结果为是。举例来说,如果预设时间为1秒,当电子装置1等候后续指令的等待时间超过1秒时,于步骤s45即会判定已逾时。
请参阅图6并配合图4,其中图6是显示本公开多语音助理的控制方法的仲裁器的运行状态示意图。如图4及图6所示,本发明的多语音助理的控制方法所采用的仲裁器121,是运行于闲置状态、聆听状态、串流状态及回应状态等状态中的其中之一,在整体流程步骤的最初,也就是步骤s10中,仲裁器121处于闲置状态,当流程进行到步骤s20,仲裁器121由闲置状态进入聆听状态。在步骤s30中,仲裁器根据辨识原则123及输入自聆听器122的声音物件进行分析,以得到分析结果,进而选择对应的辨识引擎。在步骤s40中,仲裁器121会进入回应状态,若判断会话结束,仲裁器121会接着进入闲置状态;若判断会话未结束,即处于会话中的状态,仲裁器121会维持于回应状态,直到会话结束进入闲置状态或者接收到另一唤醒指令切换至其他状态。具体而言,当仲裁器121运行于闲置状态、聆听状态或串流状态,多个辨识引擎皆被启用。当仲裁器121运行于回应状态,于步骤s30中被选择的对应的辨识引擎被启动,且其余的所述多个辨识引擎被禁用。换言之,当仲裁器121处于回应状态,仅有被选择的对应的辨识引擎会作用,亦即电子装置1处于以该对应的辨识引擎及其对应的语音助理专注回应使用者的状态,此时关闭其余的语音助理可节省系统资源以及电力消耗,同时提升系统效能。
请再参阅图5并配合图6。在本公开多语音助理的控制方法中,实现步骤s50及步骤s60的方法主要有以下两种。在一些实施例中,在步骤s50中,对应的辨识引擎的辨识阈值被使能(enable),且其余的所述多个辨识引擎的所述多个辨识阈值被禁能(disable)。举例而言,若于步骤s30中被选择的对应的辨识引擎为第一辨识引擎210,其具有与之对应的第一辨识阈值21,在步骤s50中,第一辨识阈值被使能,故此与之连动的第一辨识引擎210得以作用,而对应于其余的所述多个辨识引擎的所述多个辨识阈值,即第二辨识阈值22,被禁能,当然也连带使得第二辨识引擎220无法作用,进而实现步骤s60中,启用对应的辨识引擎并禁用其余的辨识引擎,于此例中即为启用第一辨识引擎并禁用第二辨识引擎。
在另一些实施例中,在步骤s50中,对应的辨识引擎的辨识阈值被修改减少,且其余的辨识引擎的辨识阈值被修改增加。举例而言,若于步骤s30中被选择的对应的辨识引擎为第二辨识引擎220,其具有与的对应的第二辨识阈值22,在步骤s50中,第二辨识阈值22被仲裁器121修改减少,以使门限(门槛)降低并利于辨识,或可视为降低至可启用辨识的门限以下;而对应于其余的辨识引擎的辨识阈值,即对应于第一辨识引擎的第一辨识阈值21,被仲裁器121修改增加,其数值可设置为无穷大或极大数值,使得门限提高,可视为提高至远大于可启用的门限的数值,进而实现不造s60中,启用对应的辨识引擎并禁用其余的辨识引擎,于此例中即为启用第二辨识引擎并禁用第一辨识引擎。
以下进一步说明第一辨识阈值21及第二辨识阈值22。不论是第一辨识阈值21,抑或是第二辨识阈值22,其控制皆可以根据对话的状态有不同的阈值设定。举例来说,于最初的初始状态,即前文所述的闲置状态下,第一辨识阈值21及第二辨识阈值22可设定为只要听到关键字就会作用。在有会话的状态下,例如在聆听状态与回应状态下,第一辨识阈值21及第二辨识阈值22可设定为据对话内容决定关键字是否作用。举例来说,若使用者发言:“帮我打电话给王小明。”于此发言中关键字“王小明”并无作用。若使用者发言:“alexa,帮我打电话。”在此发言中关键字“alexa”有作用,与此关键字连动的对应辨识引擎即会被启动。应当注意的是,此处指的作用是指对于第一辨识阈值21及第二辨识阈值22的判断是否作用,与后续会话中是否有作用无涉。在后续的会话判定上,另定义一实体变数,以就不同的部分进行处理。
具体而言,对于会话内容的判断,以会话中包括前后文的内容来决定,会话的内容经过类ai的判断模式,将语句判断出意图(intent)跟实体变数(entity)。以上述内容再次进行说明。若使用者发言:“帮我打电话给王小明。”于此发言中,意图为“打电话”,而实体变数为“王小明”。而在另一发言中,使用者发言:“alexa,帮我打电话。”意图为“打电话”,但此发言中不存在实体变数。综上所述,本公开提供一种多语音助理的控制方法,通过分析声音物件后直接选择对应的辨识引擎,可达到直接呼叫对应的语音助理进行服务,让使用者以更直觉的对话方式使用电子装置,进而增进使用者体验并减少等待时间的技术效果。另一方面,通过仲裁器、辨识原则及聆听器的应用,不仅可在等待时间超过一预设时间时提前启用所有辨识引擎重新进行辨识,还可直接地因应聆听器输入至仲裁器的内容选择对应的辨识引擎,以减少使用者的等待时间并且避免多余对话产生的错误。
纵使本发明已由上述的实施例详细叙述而可由熟悉本技艺的人士任施匠思而为诸般修饰,然皆不脱如附权利要求所欲保护者。
- 还没有人留言评论。精彩留言会获得点赞!