基于机器学习的同声传译方法及装置与流程
本发明涉及一种数据处理技术领域,尤其涉及一种基于机器学习的同声传译方法及装置。
背景技术:
同声传译是指将在讲话人讲话的同时将讲话人的语言翻译成不同的语言。现有技术的同声传译大都通过人工来实现,然而通过人为实现同声传译往往需要对译员具有较高的要求,导致这部分人才稀缺。目前,越来越多的场合,如国际会议等均需要同声传译,以人工的方式实现同声传译已满足不了市场的需求。近年来,市面上也存在一些翻译产品,如翻译机,利用翻译机可以将讲话翻译成各种语言,但翻译的时间较长,输出机器语言较呆板,导致用户的体验效果差。
有鉴于此,有必要提出对目前的同声传译方法进行进一步的改进。
技术实现要素:
为解决上述至少一技术问题,本发明的主要目的是提供一种基于机器学习的同声传译方法及装置。
为实现上述目的,本发明采用的一个技术方案为:提供一种基于机器学习的同声传译方法,包括:
采集目标人讲话的讲话内容及讲话特征;
利用机器学习并模仿目标人的讲话特征;
将目标人的讲话内容翻译为指定语言的讲话内容;以及
以指定语言输出经机器模仿目标人讲话特征的讲话内容,其中,所述目标人的语言与指定语言为不同语种。
其中,所述利用机器学习并模仿目标人的讲话特征,包括:
将目标人的讲话内容拆解成多个词语和/或单词;
识别并存储目标人讲话时各个词语和/或单词的发音特征;
利用机器学习并模仿目标人对词语和/或单词的发音特征。
其中,所述发音特征包括目标人讲话的音色数据及音调数据。
其中,所述将目标人的讲话内容拆解成多个词语和/或单词,包括:
从多个词语和/或单词中选出至少一关键词语和/或单词;
根据采集的关键词语和/或单词及其音调数据确定目标人的讲话语境;
所述用机器学习并模仿目标人对词语和/或单词的发音特征,包括,
从数据库找出与目标人讲话语境相适应的音译语境;
在基于音译语境的前提下利用机器学习并模仿目标人对词语和/或单词的发音特征。
其中,所述采集目标人讲话的讲话内容及讲话特征之前,包括,
获取对话人讲话的语言信息并识别出对话人的讲话语种;
所述以指定语言输出经机器模仿目标人讲话特征的讲话内容,包括,
将经机器模仿目标人讲话特征的讲话内容自动匹配输出为以对话人所讲语言。
其中,所述以指定语言输出经机器模仿目标人讲话特征的讲话内容,包括:
响应用户的语言切换操作;
以切换后的语言输出经机器模仿目标人讲话特征的讲话内容。
为实现上述目的,本发明采用的另一个技术方案为:提供一种基于机器学习的同声传译装置,包括:
采集模块,用于采集目标人讲话的讲话内容及讲话特征;
学习模块,用于利用机器学习并模仿目标人的讲话特征;
翻译模块,用于将目标人的讲话内容翻译为指定语言的讲话内容;以及
输出模块,用于以指定语言输出经机器模仿目标人讲话特征的讲话内容,其中,所述目标人的语言与指定语言为不同语种。
其中,所述学习模块,具体包括:
拆解单元,用于将目标人的讲话内容拆解成多个词语和/或单词;
识别单元,用于识别并存储目标人讲话时各个词语和/或单词的发音特征;
学习单元,用于利用机器学习并模仿目标人对词语和/或单词的发音特征。
其中,所述输出模块,还用于,
响应用户的语言切换操作;
以切换后的语言输出经机器模仿目标人讲话特征的讲话内容。
其中,所述基于机器学习的同声传译装置通过智能手机、电脑、pad及智能音响来实现。
本发明的技术方案主要包括采集目标人讲话的讲话内容及讲话特征;利用机器学习并模仿目标人的讲话特征;将目标人的讲话内容翻译为指定语言的讲话内容;以及以指定语言输出经机器模仿目标人讲话特征的讲话内容,区别于现有技术采用同声传译成本高的问题以及采用翻译机翻译时间长的问题,本方案通过采集目标人的讲话内容,一方面将讲话内容翻译成指定语言,另一方面获取目标人的讲话特征,通过利用机器学习目标人的讲话特征,实现以指定语言输出经机器模仿目标人讲话特征的讲话内容,能够将翻译结果以目标人的讲话特征输出,使翻译结果更加真切,为用户带来较佳的听觉体验。
附图说明
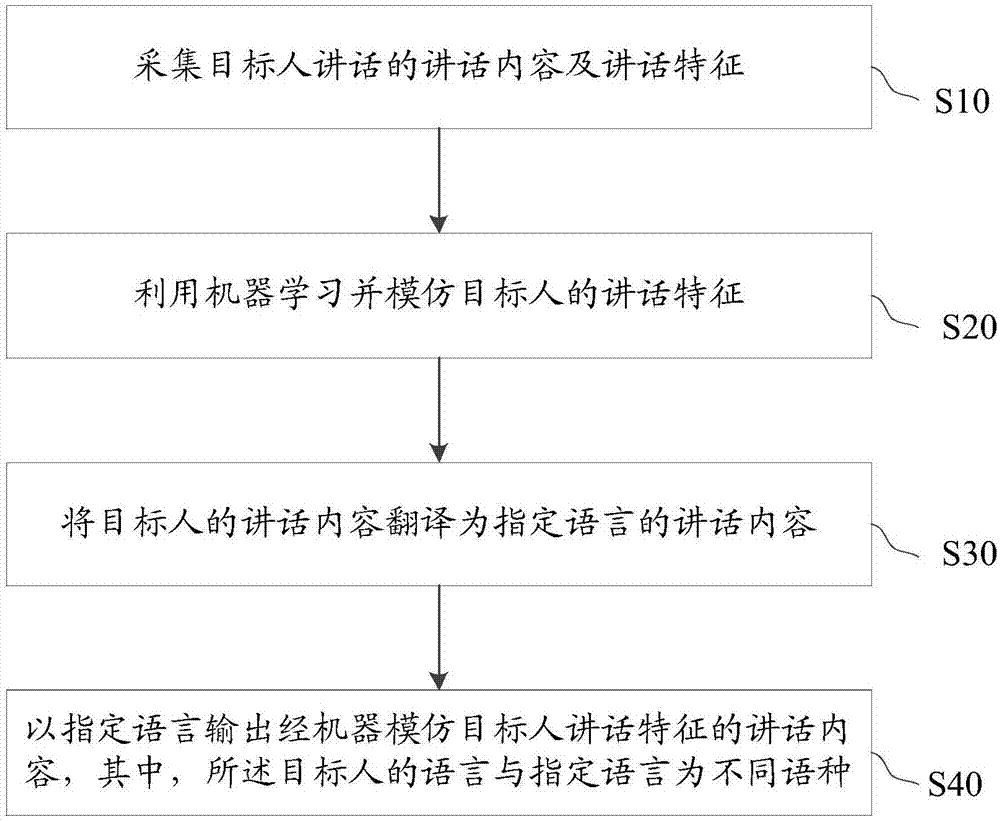
图1为本发明一实施例基于机器学习的同声传译方法的方法流程图;
图2为本发明中步骤s20的具体流程图;
图3为本发明一实施例基于机器学习的同声传译装置的模块方框图;
图4为本发明中学习模块的方框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明,本发明中涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
请参照图1,图1为本发明一实施例基于机器学习的同声传译方法的方法流程图。在本发明实施例中,该基于机器学习的同声传译方法,包括:
步骤s10、采集目标人讲话的讲话内容及讲话特征;
步骤s20、利用机器学习并模仿目标人的讲话特征;
步骤s30、将目标人的讲话内容翻译为指定语言的讲话内容;以及
步骤s40、以指定语言输出经机器模仿目标人讲话特征的讲话内容,其中,所述目标人的语言与指定语言为不同语种。
本实施例中,在采集目标人的讲话的同时,还可以采集对话人的讲话语音。目标人与对话人所将语言为不同的语种。该讲话内容为目标人的语言文字特征,讲话特征为语音特征。利用机器学习和模仿目标人的讲话特征,如此,可以使翻译结果具有目标人的语言特征,而不是机器人内置的其他语音。目标人的讲话内容可以通过机器翻译成指定语言的讲话内容,结合机器学习和模仿目标人的讲话特征,从而可以输出具有以目标人的讲话特征的翻译结果,使翻译结果更加真切,用户带来较佳的听觉体验。
本方案通过采集目标人讲话的讲话内容及讲话特征;利用机器学习并模仿目标人的讲话特征;将目标人的讲话内容翻译为指定语言的讲话内容;以及以指定语言输出经机器模仿目标人讲话特征的讲话内容,区别于现有技术采用同声传译成本高的问题以及采用翻译机翻译时间长的问题,本方案通过采集目标人的讲话内容,一方面将讲话内容翻译成指定语言,另一方面获取目标人的讲话特征,通过利用机器学习目标人的讲话特征,实现以指定语言输出经机器模仿目标人讲话特征的讲话内容,能够将翻译结果以目标人的讲话特征输出,使翻译结果更加真切,为用户带来较佳的听觉体验。
请参照图2,图2为本发明中步骤s20的具体流程图。在一具体的实施例中,所述利用机器学习并模仿目标人的讲话特征的步骤,包括:
步骤s21、将目标人的讲话内容拆解成多个词语和/或单词;
步骤s22、识别并存储目标人讲话时各个词语和/或单词的发音特征;
步骤s23、利用机器学习并模仿目标人对词语和/或单词的发音特征。
本实施例中,采集的讲话内容可以拆解成多个词语、多个单词或多个词语与单词的组合,通过多个词语、多个单词或多个词语与单词的组合可以比较准确的识别出目标人的讲话内容,以方便后续的翻译结果。在识别讲话内容后,还可以对目标人的发音特征进行学习及模仿。进一步的,所述发音特征包括目标人讲话的音色数据及音调数据,如此,经机器输出的翻译结果为具有目标人讲话特征的不同语言。
在一具体的实施方式中,所述将目标人的讲话内容拆解成多个词语和/或单词,包括:
从多个词语和/或单词中选出至少一关键词语和/或单词;
根据采集的关键词语和/或单词及其音调数据确定目标人的讲话语境;
所述用机器学习并模仿目标人对词语和/或单词的发音特征,包括,
从数据库找出与目标人讲话语境相适应的音译语境;
在基于音译语境的前提下利用机器学习并模仿目标人对词语和/或单词的发音特征。
进一步的,还可以根据讲话内容的发音特征确定目标人的讲话语境,然后通过讲话语境与多个词语、多个单词或多个词语与单词的组合准确识别讲话内容。在确定目标人的讲话语境后,还可以自动匹配出数据库中的目标语境,该目标语境即为机器识别的音译语境,结合上述音译语境可以准确识别及翻译同一词语在不同语境下释义。
在一具体的实施方式中,所述采集目标人讲话的讲话内容及讲话特征之前,包括,
获取对话人讲话的语言信息并识别出对话人的讲话语种;
所述以指定语言输出经机器模仿目标人讲话特征的讲话内容,包括,
将经机器模仿目标人讲话特征的讲话内容自动匹配输出为以对话人所讲语言。
本实施例中,可以通过获取对话人讲话的语言信息并识别出对话人的讲话语种,可以将对话人的讲话语种作为指定语言,目标人讲话语种为待翻译语言,利用机器可以直接对待翻译语言进行翻译,并且可以直接将待翻译语言自动翻译成指定语言,无需手动操作。
在一具体的实施方式中,所述以指定语言输出经机器模仿目标人讲话特征的讲话内容,包括:
响应用户的语言切换操作;
以切换后的语言输出经机器模仿目标人讲话特征的讲话内容。
本实施例中,还可以通过手动切换将目标人的讲话内容翻译成其他的语言,可以是一种也可以是多种,以满足用户的需求。
请参照图3,图3为本发明一实施例基于机器学习的同声传译装置的模块方框图。本发明的实施例中,该基于机器学习的同声传译装置,包括:
采集模块10,用于采集目标人讲话的讲话内容及讲话特征;
学习模块20,用于利用机器学习并模仿目标人的讲话特征;
翻译模块30,用于将目标人的讲话内容翻译为指定语言的讲话内容;以及
输出模块40,用于以指定语言输出经机器模仿目标人讲话特征的讲话内容,其中,所述目标人的语言与指定语言为不同语种。
本实施例中,采集模块10,在采集目标人的讲话的同时,还可以采集对话人的讲话语音。目标人与对话人所将语言为不同的语种。该讲话内容为目标人的语言文字特征,讲话特征为语音特征。机器可以通过学习模块20学习和模仿目标人的讲话特征,如此,可以使翻译结果具有目标人的语言特征,而不是机器人内置的其他语音。翻译模块30,在目标人的讲话内容可以通过机器翻译成指定语言的讲话内容,结合机器学习和模仿目标人的讲话特征,从而可以通过输出模块40,输出具有以目标人的讲话特征的翻译结果,使翻译结果更加真切,用户带来较佳的听觉体验。
请参照图4,图4为本发明中学习模块20的方框图。在一具体的实施方式中,所述学习模块20,具体包括:
拆解单元21,用于将目标人的讲话内容拆解成多个词语和/或单词;
识别单元22,用于识别并存储目标人讲话时各个词语和/或单词的发音特征;
学习单元23,用于利用机器学习并模仿目标人对词语和/或单词的发音特征。
本实施例中,通过拆解单元21,可以将采集的讲话内容可以拆解成多个词语、多个单词或多个词语与单词的组合,识别单元22可以通过多个词语、多个单词或多个词语与单词的组合可以比较准确的识别出目标人的讲话内容,以方便后续的翻译结果。在识别讲话内容后,还可以通过学习单元23对目标人的发音特征进行学习及模仿。进一步的,所述发音特征包括目标人讲话的音色数据及音调数据,如此,经机器输出的翻译结果为具有目标人讲话特征的不同语言。
在一具体的实施方式中,所述输出模块40,还用于,
响应用户的语言切换操作;
以切换后的语言输出经机器模仿目标人讲话特征的讲话内容。
本实施例中,输出模块40可以响应用户的语言切换操作,将识别后的具有目标人讲话特征的讲话内容翻译成一种或多种语言。
在一具体的实施例方式中,所述基于机器学习的同声传译装置通过智能手机、电脑、pad及智能音响来实现。可以理解的,除了上述的装置,本装置还可以集成设置于其他数码产品中,以方便用户的使用。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是在本发明的发明构思下,利用本发明说明书及附图内容所作的等效结构变换,或直接/间接运用在其他相关的技术领域均包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!