基于双模型识别的语音领域命令理解方法与流程
本发明涉及人机交互领域中的语言识别技术领域,特别是涉及一张基于双模型识别的语音领域命令理解方法
背景技术:
对话系统是人机交互的一种相当重要的形式,也是自然语言处理过程中的一个关键的研究方向。在语音领域,能否正确解析出用户话语命令是完成用户指定任务的基础,在很多地方比如语音助手、语音平台都有很丰富的应用场景。
对于用户某条话语,目前常使用的条件随机场(crf)模型并不能很好的区分其是否表达了一个语音领域内的意图。crf一般在序列标注、命名实体识别过程表现较好,但在识别语音实体之前,需要判断此用户话语是否表达语音意图,否则可能识别出错,甚至无法识别。
如能够先进行语音意图的识别,可带来两个好处,一是若判断用户话语没有表达语音意图,则不需要进行后续实体提取操作,因为此时已经完成无语音意图解析操作,二是若对用户话语的语音意图不做判断的话,则很有可能一段用户话语没有表现语音意图,但是被错误的提取出了语音实体,比如“刘德华的老婆是谁”这句用户话语,若不先进行语音意图判断操作,则很有可能将“刘德华”识别成歌手实体,从而这句话也被解析成语音意图,而实际上这句话并没有表达语音领域的相关意图。
技术实现要素:
本发明的目的是要提供一种基于双模型识别的语音领域命令理解方法,其中循环神经网络模型的目标是为判断用户的话语是否表达了一个语音领域的意图,如此能够提高识别准确性,降低识别出错率。
为达到上述目的,本发明采用的技术方案是:
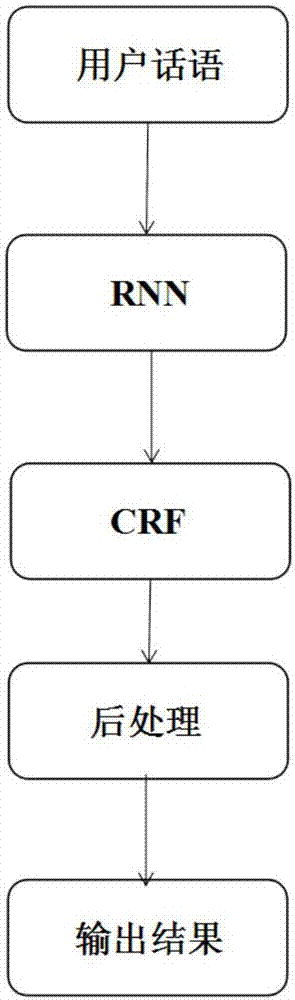
本发明提供了一种基于双模型识别的语音领域命令理解方法,外部输入话语先经循环神经网络模型处理并进行语音意图的判断,在得出判断结果后再经条件随机场模型生成目标序列标签,从而提取出语音实体,所述条件随机场模型再向后处理单元输出所提取到的语音试题的数据,生成最终的控制指令。
对于上述技术方案,申请人还有进一步的实施方案。
进一步地,外部输入话语先经分子处理单元对其进行按字切分后形成初始训练集,再将初始训练集输入所述循环神经网络模型进行处理。
更进一步地,在循环神经网络模型中进行处理的具体步骤如下:
步骤a1:计算第t时刻的隐藏状态ht,ht由上一层的隐藏状态和本层的输入共同决定,
ht=f(uxt+wht-1)其中,xt是第t时刻的输入,f为非线性的激活函数,u、w为变换矩阵;
步骤a2:计算预测标签值s,
s=sigmod(vht),其中,v为变换矩阵,ht为序列最后一个时刻的隐藏状态;
步骤a3:确定分类类型,
根据预测标签值s确定分类,如s为正值则分类为正类,确认外部输入话语为语音意图,继续进入条件随机场模型进行处理,如s为负值则分类为负类,确认外部输入话语为非语音意图,退出此次处理。
进一步地,在条件随机场模型中进行处理时,外部输入为句子序列,输出目标为句子标注序列标签,然后根据标注序列标签提取对应的语音实体。
更进一步地,在条件随机场模型中进行处理的具体步骤如下:
步骤b1:计算转移特征与状态特征的特征值fk(yi-1,yi,x,i),
步骤b2:对转移特征与状态特征在各个位置i求和,记作:
步骤b3:计算转移特征与状态特征的特征值fk(yi-1,yi,x,i)的权值wk,
步骤b4:条件随机场可以表示成:
步骤b5:对于新来输入序列x,通过求解
进一步地,在后处理单元中,根据条件随机场模型预测的目标序列标签提取语音领域实体。
由于上述技术方案运用,本发明与现有技术相比具有下列优点:
本发明的基于双模型识别的语音领域命令理解方法,可通过循环神经网络(rnn)模型对用户话语进行判断,先判断是否含有语音领域相关意图,若判断该话语表达了语音领域相关意图,则使用条件随机场模型(crf)进行相关参数的提取,若判断该话语没有表达语音领域相关意图,则判断结束,不需要进行后续操作,这样就能解决后面语音领域相关参数提取错误导致的意图判断错误的问题,如此能够提高识别准确性,降低识别出错率。
附图说明
后文将参照附图以示例性而非限制性的方式详细描述本发明的一些具体实施例。附图中相同的附图标记标示了相同或类似的部件或部分。本领域技术人员应该理解,这些附图未必是按比例绘制的。附图中:
图1是根据本发明一个实施例的语音领域命令理解方法的处理流程示意图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
此外,下面所描述的本发明不同实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。
本实施例描述了一种基于双模型识别的语音领域命令理解方法,外部输入话语先经循环神经网络模型处理并进行语音意图的判断,在得出判断结果后再经条件随机场模型生成目标序列标签,从而提取出语音实体,所述条件随机场模型再向后处理单元输出所提取到的语音试题的数据,生成最终的控制指令。
外部输入话语先经分子处理单元对其进行按字切分后形成初始训练集,再将初始训练集输入所述循环神经网络模型进行处理,在循环神经网络模型中进行处理的具体步骤如下:
步骤a1:计算第t时刻的隐藏状态ht,ht由上一层的隐藏状态和本层的输入共同决定,
ht=f(uxt+wht-1)其中,xt是第t时刻的输入,f为非线性的激活函数,u、w为变换矩阵;
步骤a2:计算预测标签值s,
s=sigmod(vht),其中,v为变换矩阵,ht为序列最后一个时刻的隐藏状态;
步骤a3:确定分类类型,
根据预测标签值s确定分类,如s为正值则分类为正类,确认外部输入话语为语音意图,继续进入条件随机场模型进行处理,如s为负值则分类为负类,确认外部输入话语为非语音意图,退出此次处理。
进一步地,在条件随机场模型中进行处理时,外部输入为句子序列,输出目标为句子标注序列标签,然后根据标注序列标签提取对应的语音实体。
更进一步地,在条件随机场模型中进行处理的具体步骤如下:
步骤b1:计算转移特征与状态特征的特征值fk(yi-1,yi,x,i),
步骤b2:对转移特征与状态特征在各个位置i求和,记作:
步骤b3:计算转移特征与状态特征的特征值fk(yi-1,yi,x,i)的权值wk,
步骤b4:条件随机场可以表示成:
步骤b5:对于新来输入序列x,通过求解
进一步地,在后处理单元中,根据条件随机场模型预测的目标序列标签提取语音领域实体。
下面以一具体语句为例来说明双模型识别的数据集训练过程。
训练数据集类型如下:
请播放周杰伦的稻香artist:周杰伦,song:稻香刘德华的老婆是谁no-music
........
对于训练数据集合,我们分别训练rnn和crf模型:
(1)rnn模型训练过程:
对于训练集中的no-music(无语音意图),则标记为负样本标签0,否则标记为正样本标签1。
即训练数据转换为以下格式:
请播放周杰伦的稻香1
刘德华的老婆是谁0
构建好训练集之后,rnn模型训练过程如上。
预测过程:
对于新的话语句子:唱一首稻香
首先分字处理:唱一首稻香
然后从预训练好的字向量得到所有字的向量,然后按时刻先后输入到rnn模型,最后得到序列最后一个时刻的隐藏状态为ht,通过y=sigmod(vht)计算得到意图识别结果y。
(2)crf模型训练过程:
在crf模型训练过程中,数据格式变换成以下格式:
请播放周杰伦的稻香oooa-ba-ia-eos-bs-e
刘德华的老婆是谁oooooooo
对于每一条输入样本,输入为序列,输出目标也为序列,符号标记如上。再对输入序列每个字进行字性标注,会得到一个三列的序列,第一列为按字切分的输入序列,第二列为字的字性,第三列为输出目标标签序列。然后我们定义了特征函数
特征函数比如:如果此位置为“杰”且对应的标注序列为a-i,那么这个特征函数为1,否则为0。然后通过训练集,求出所有特征函数的值,然后优化
预测过程,输入预测话语句子:唱一首稻香
我们通过式子:
比如,这里我们得到的y'为:ooos-bs-e
(3)后处理
通过后处理,我们得到该话语语音领域实体为:歌曲:稻香。
综上可知,本发明的基于双模型识别的语音领域命令理解方法,可通过循环神经网络(rnn)模型对用户话语进行判断,先判断是否含有语音领域相关意图,若判断该话语表达了语音领域相关意图,则使用条件随机场模型(crf)进行相关参数的提取,若判断该话语没有表达语音领域相关意图,则判断结束,不需要进行后续操作,这样就能解决后面语音领域相关参数提取错误导致的意图判断错误的问题,如此能够提高识别准确性,降低识别出错率。
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围,凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!