一种文本相关的声纹密钥生成方法与流程
本发明属于网络空间安全技术领域,涉及一种文本相关的声纹密钥生成方法。
背景技术:
声纹识别技术已是一种比较成熟的生物特征识别技术,随着近几年人工智能技术的迅速发展,声纹识别的准确率也得到了一定程度的提高,在低噪音环境中声纹识别准确率可达到96%以上,已被广泛地应用于身份认证场景中。
随着声纹技术应用的深入,本技术领域内开始尝试从人类声纹中直接提取稳定数字序列作为生物密钥使用,即可以用声纹直接生成各类密钥,与现有的口令、公私钥密码技术无缝融合,可以免去声纹采集和存储过程的不便,以及可能引发的安全性问题,进一步丰富网络认证的手段与方法。
声纹生物密钥技术已有一定程度的研究,如中国发明专利zl201110003202.8基于声纹的文档加密及解密方法,提出了一个从声纹信息中提取稳定密钥序列的方案。但是该方案仅用棋盘法稳定声纹特征值,稳定效果有限且密钥长度不足。中国发明专利zl201410074511.8一种人类声纹生物密钥生成方法,提出了一种提取声纹高斯模型,并将模型特征参数向高维空间投影以获得稳定声纹密钥的技术路线。该方案获得的声纹密钥较前一个专利稳定性有明显提高,但对于高稳定性要求的密钥认证环境,上述技术方案提取声纹生物密钥的稳定性仍有待进一步提高。
技术实现要素:
本发明的目的就是提供一种文本相关的声纹密钥生成方法。
本发明包括声纹密钥训练和声纹密钥提取;声纹密钥训练通过前期采集的声纹样本训练出声纹密钥提取矩阵。声纹密钥提取将待提取声纹样本经预处理后,乘上声纹密钥训练得到的密钥提取矩阵,得到声纹密钥。具体步骤如下:
步骤一、声纹密钥训练,具体步骤为:
第一步,用户对同一个文本信息,一般为1-3个连续的单词,录取自身语音,重复20次以上,次数由用户根据训练情况调整。
第二步,录取10个以上不同用户读取相同文本信息的语音,各重复20次以上;录取10个以上不同用户读取不同文本信息、持续时间相近的语音,各重复20次以上。
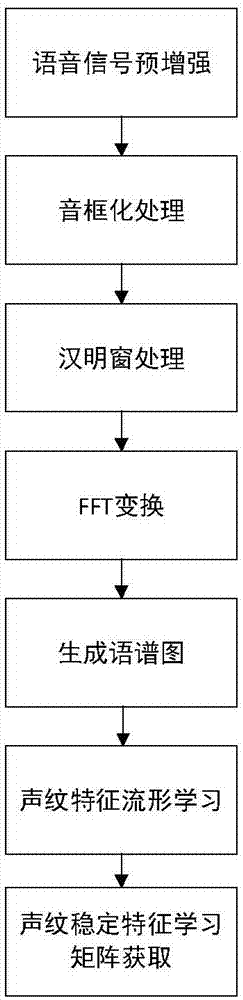
第三步,对第一、二步录取语音进行预处理,提取声纹语谱图具体过程为:
1)预增强(pre-emphasis):
以s1(n)表示语音时域信号,其中n=0、1、2…、n-1,预增强公式为:s(n)=s1(n)–a*s1(n-1),0.9<a<1.0。a为欲加重系数,用以调整欲增强幅度。
2)音框化(framing),即对语音信号分帧。
3)汉明窗(hammingwindowing)处理:
音框化后的语音时域信号为s(n),n=0、1、2…、n-1,表示分为了n段语音信号;那么乘上汉明窗后的语音时域信号为s’(n),见式⑴:
s’(n)=s(n)*w(n)⑴;
得:
4)快速傅立叶转换(fft):
对乘上汉明窗后的语音时域信号s’(n)实施基2fft变换,得到线性频谱x(n,k),基2fft变换为本领域内通用算法;x(n,k)为第n段语音帧的频谱能量密度函数,k对应频谱段,每一段语音帧对应了时间轴上的一个时间片。
5)生成文本相关声纹语谱图:
用时间n作为时间轴坐标,k作为频谱轴坐标,将|x(n,k)|2的值表示为灰度级,显示在相应的坐标点位置上,即构成了声纹语谱图。通过变换10log10(|x(n,k)|2)得到语谱图的db表示。
第四步,对声纹语谱图进行滤波、归一化等预处理,具体滤波方式有高斯、小波、二值化等信号处理领域通用滤波方式,具体采用哪种方式,或几种方式的组合,由用户根据实际测试情况选择。归一化处理指语谱图尺寸统一到固定的长宽大小,语谱图每一个像素点的值统一到0-255范围内,具体方法可均采用本领域内通用方法,如图像尺寸调整可采用matlab函数库中的imresize函数实现。
第五步,对声纹语谱图进行机器学习,得声纹稳定特征学习矩阵,即声纹密钥提取矩阵。
第四步得到的声纹语谱图分成两大类,一类为用户本人的相关文本声纹语谱图,另一类为非用户本人的相关文本与非相关文本混合的对比声纹语谱图,称为正负样本集合。
用m=[m1,m2]表示参加训练的正负样本集合,mi=[xi1,xi2,...,xil],i∈{1,2}表示第i类样本集合,i=1为正样本,i=2为负样本;xir∈rd,1≤i≤2,1≤r≤l,xir为一维列向量,由一张声纹语谱图的所有像素点的值形成一个二维矩阵,再将二维矩阵的每一行顺次拼接,得到一维行向量,转置后得到一维列向量xir,xir长度为d,rd表示d维实数域,l表示同一类样本集合中有l张声纹语谱图,即l个列向量。
现在根据两类样本的特点,训练声纹密钥提取矩阵w1,w1∈rd×dz,得式⑵:
其中
令:
求解矩阵(h1-h2)的特征值与特征向量,得到声纹密钥提取矩阵w1,即:(h1-h2)w=λw;w为矩阵(h1-h2)的特征向量,λ为特征值。
由于{w1,w2,...,wdz}为特征向量,分别对应特征值{λ1,λ2,...,λdz},其中λ1≥λ2≥...≥λdz≥0,特征值小于0的特征向量不被纳入矩阵w1的构造。
至此训练出声纹密钥提取矩阵w1。
步骤二、声纹密钥提取,具体步骤为:
第1步,用户录取自身文本相关语音,3秒左右。
第2步,提取声纹语谱图,具体参考步骤一第三步。
第3步,对声纹语谱图进行滤波、归一化等预处理,然后将声纹语谱图转为矩阵形式,并按行顺次拼接,得声纹向量xt。
第4步,用步骤一训练的声纹稳定特征学习矩阵w1,转置后左乘第3步得到的声纹向量xt,即w1t·xt,得dz维声纹特征向量xtz,xtz为稳定后声纹特征向量。
第5步,对xtz的每一维分量进行一次棋盘法运算,进一步稳定声纹特征向量为
棋盘法运算,步骤如下:
对xtz中的每一个维分量记为xtzi;
量化公式见式⑶:
其中,d为棋盘法的格子大小,取正数,具体值可由用户根据经验选定,一般满足λ(x)的取值在0~63之间,xtzi为xtz中的每一个分量,λ(x)为整数值。
λ(x)即xtzi量化后的值,为棋盘格子中最接近xtzi点与坐标原点的格子的坐标值。
第6步,取第五步计算结果向量
本发明利用话者文本相关的语谱图在更充分地表达话者的声音特质的同时,保持前后采样样本具有更稳定的相似性。在此基础上,用机器学习方法从多个语谱图中训练出声纹稳定特征向量提取矩阵,用该矩阵对后续样本进行处理,可提取更稳定的声纹密钥。方法具有稳定性好、简洁、方便使用的特点。
附图说明
图1为本发明声纹密钥训练流程图;
图2为本发明声纹语谱图生成流程图;
图3为本发明声纹语谱图;
图4为本发明声纹密钥提取流程图。
图5为本发明声纹特征机器学习示意图。
具体实施方式
一种文本相关的声纹密钥生成方法包括声纹密钥训练和声纹密钥提取;声纹密钥训练通过前期采集的声纹样本训练出声纹密钥提取矩阵。声纹密钥提取将待提取声纹样本经预处理后,乘上声纹密钥训练得到的密钥提取矩阵,得到声纹密钥。具体步骤如下:
步骤一、声纹密钥训练,如图1所示,具体步骤为:
第一步,用户对同一个文本信息,一般为1-3个连续的单词,录取自身语音,重复20次以上(次数可由用户根据训练情况调整)。
第二步,录取10个以上不同用户读取相同文本信息的语音,各重复20次以上;录取10个以上不同用户读取不同文本信息、持续时间相近的语音,各重复20次以上。
第三步,对第一、二步录取语音进行预处理,如图2和3所示,提取声纹语谱图具体过程为:
1)预增强(pre-emphasis):
以s1(n)表示语音时域信号,其中n=0、1、2…、n-1,预增强公式为:s(n)=s1(n)–a*s1(n-1),0.9<a<1.0。a为欲加重系数,用以调整欲增强幅度。
2)音框化(framing),即对语音信号分帧。
3)汉明窗(hammingwindowing)处理:
音框化后的语音时域信号为s(n),n=0、1、2…、n-1,表示分为了n段语音信号;那么乘上汉明窗后的语音时域信号为s’(n),见式⑴:
s’(n)=s(n)*w(n)⑴;
得:
5)快速傅立叶转换(fft):
对乘上汉明窗后的语音时域信号s’(n)实施基2fft变换,得到线性频谱x(n,k),基2fft变换为本领域内通用算法;x(n,k)为第n段语音帧的频谱能量密度函数,k对应频谱段,每一段语音帧对应了时间轴上的一个时间片。
5)生成文本相关声纹语谱图:
用时间n作为时间轴坐标,k作为频谱轴坐标,将|x(n,k)|2的值表示为灰度级,显示在相应的坐标点位置上,即构成了声纹语谱图。通过变换10log10(|x(n,k)|2)得到语谱图的db表示。
第四步,对声纹语谱图进行滤波、归一化等预处理,具体滤波方式有高斯、小波、二值化等信号处理领域通用滤波方式,具体采用哪种方式,或几种方式的组合,由用户根据实际测试情况选择。归一化处理指语谱图尺寸统一到固定的长宽大小,语谱图每一个像素点的值统一到0-255范围内,具体方法可均采用本领域内通用方法,如图像尺寸调整可采用matlab函数库中的imresize函数实现。
第五步,对声纹语谱图进行机器学习,得声纹稳定特征学习矩阵,即声纹密钥提取矩阵。
第四步得到的声纹语谱图分成两大类,一类为用户本人的相关文本声纹语谱图,另一类为非用户本人的相关文本与非相关文本混合的对比声纹语谱图,称为正负样本集合。
用m=[m1,m2]表示参加训练的正负样本集合,mi=[xi1,xi2,...,xil],i∈{1,2}表示第i类样本集合,i=1为正样本,i=2为负样本;xir∈rd,1≤i≤2,1≤r≤l,xir为一维列向量,由一张声纹语谱图的所有像素点的值形成一个二维矩阵,再将二维矩阵的每一行顺次拼接,得到一维行向量,转置后得到一维列向量xir,xir长度为d,rd表示d维实数域,l表示同一类样本集合中有l张声纹语谱图,即l个列向量。
现在根据两类样本的特点,训练声纹密钥提取矩阵w1,w1∈rd×dz,得式⑵:
其中
令:
求解矩阵(h1-h2)的特征值与特征向量,得到声纹密钥提取矩阵w1,即:(h1-h2)w=λw;w为矩阵(h1-h2)的特征向量,λ为特征值。
由于{w1,w2,...,wdz}为特征向量,分别对应特征值{λ1,λ2,...,λdz},其中λ1≥λ2≥...≥λdz≥0,特征值小于0的特征向量不被纳入矩阵w1的构造。
至此训练出声纹密钥提取矩阵w1。
步骤二、声纹密钥提取,如图4所示,具体步骤为:
第1步,用户录取自身文本相关语音,3秒左右。
第2步,提取声纹语谱图,具体参考步骤一第三步。
第3步,对声纹语谱图进行滤波、归一化等预处理,然后将声纹语谱图转为矩阵形式,并按行顺次拼接,得声纹向量xt。
第4步,用步骤一训练的声纹稳定特征学习矩阵w1,转置后左乘第3步得到的声纹向量xt,即w1t·xt,得dz维声纹特征向量xtz,xtz为稳定后声纹特征向量。
第5步,对xtz的每一维分量进行一次棋盘法运算,进一步稳定声纹特征向量为
棋盘法运算,步骤如下:
对xtz中的每一个维分量记为xtzi;
量化公式见式⑶:
其中,d为棋盘法的格子大小,取正数,具体值可由用户根据经验选定,一般满足λ(x)的取值在0~63之间,xtzi为xtz中的每一个分量,λ(x)为整数值。
λ(x)即xtzi量化后的值,为棋盘格子中最接近xtzi点与坐标原点的格子的坐标值。
第6步,取第五步计算结果向量
本发明利用同一个话者文本相关语音声纹频谱具有较高相似性的特点,从文本相关语音中提取声纹语谱图,同一个话者同一段文本经多次采样得到的多张声纹语谱图具有较高的相似性,同时,不同话者同一段文本提取的声纹语谱图之间有较明显的差异。提取声纹语谱图后,通过如图5所示的机器学习方法从多张声纹语谱图中提取出共有特征信息,经过分段量化后,得到文本相关声纹密钥。声纹密钥无需服务端保留生物特征模板,具有更高的安全性,并可以与aes、rsa等通用网络加解密算法融合,方便用户使用。该方法能够获得更稳定的声纹密钥,声纹密钥提取准确率大于95%,密钥长度可达256bit。
- 还没有人留言评论。精彩留言会获得点赞!