使用卷积序列学习的神经文本转语音的系统和方法与流程
本公开总体涉及用于计算机学习的系统和方法,该系统和方法可提供改进的计算机性能、特征和使用。更具体地,本公开涉及用于通过深度中性网络的文本转语音的系统和方法。
背景技术:
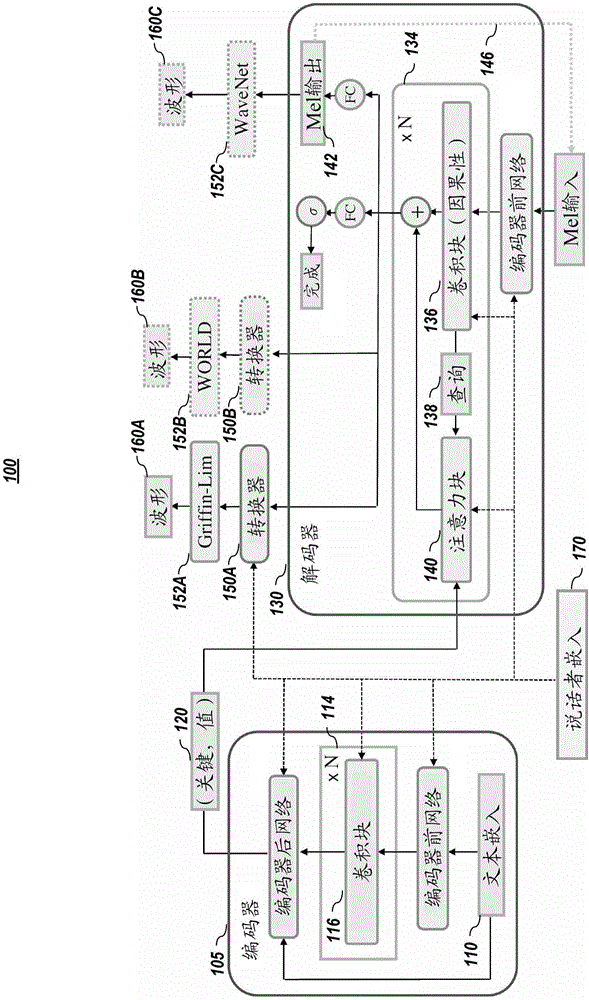
:通常被称为文本转语音(tts)系统的人工语音合成系统将书面语言转换为人类语音。tts系统用于各种应用中,诸如人机界面、视力损伤的可访问性、媒体和娱乐。根本上地,它允许无需视觉界面的人机交互。传统的tts系统基于复杂的多级人工工程管线。通常,这些系统首先将文本转换为紧凑的音频表示,然后使用称为声码器的音频波形合成方法将这种表示转换为音频。由于tts系统的复杂性,开发它可能是非常劳动密集的和困难的。最近在神经tts方面的工作已演示了令人印象深刻的结果,产生了具有更简单的特性、更少的组件和更高质量的合成语音的管线。但是对用于tts的最优神经网络架构还没有达成共识。因此,需要的是用于创建、开发和/或部署改进的说话者文本转语音系统的系统和方法。技术实现要素:根据本申请的一方面,提供了文本转语音系统,包括:一个或多个处理器;以及非暂时性计算机可读介质或媒介,包括一个或多个指令序列,所述一个或多个指令序列在由所述一个或多个处理器中的至少一个执行时,致使执行步骤,所述步骤包括:使用编码器将输入文本的文本特征转换为注意力关键表示和注意力值表示,所述编码器包括:嵌入模型,将输入文本转换为文本嵌入表示;一个或多个卷积块的系列,接收所述文本嵌入表示的投影,以及通过所述一个或多个卷积块的系列处理所述文本嵌入表示的投影,以从所述输入文本提取依赖时间的文本信息;投影层,生成所提取的依赖时间的文本信息的投影,所述依赖时间的文本信息的投影用于形成注意力关键表示;以及值表示计算器,从所述注意力关键表示和所述文本嵌入表示计算注意力值表示;以及使用基于注意力的解码器自回归地生成所述输入文本的低维音频表示,所述基于注意力的解码器包括:前网络块,接收表示音频帧的输入数据,以及包括一个或多个全连接层以对所述输入数据进行预处理;一个或多个解码器块的系列,每个解码器块均包括卷积块和注意力块,其中,卷积块生成查询,以及所述注意力块计算环境表示,作为使用所述注意力关键表示的至少一部分和来自所述卷积块的所述查询计算的注意力权重和所述注意力值表示的至少一部分的加权平均值;以及后网络块,包括全连接层,所述全连接层接收来自所述一个或多个解码器块的系列的输出,并且输出下一组低维音频表示。根据本申请的另一方面,提供了用于训练卷积序列学习文本转语音(tts)系统以从输入文本合成语音的计算机实施的方法,包括:使用嵌入模型将所述输入文本转换为一组可训练的嵌入表示;经由包括一个或多个卷积块的编码器,生成一组注意力关键表示,所述一组注意力关键表示与由所述编码器从所述一组可训练的嵌入表示中获得的数据中提取的依赖时间的文本信息相对应;使用所述一组可训练的嵌入表示和所述一组注意力关键表示,生成与所述一组注意力关键表示相对应的一组注意力值表示;以及从由基于注意力的解码器生成的环境表示生成一组声码器特征,所述一组声码器特征能够与声码器一起使用以产生表示合成语音的信号,所述基于注意力的解码器包括至少一个解码器块,所述至少一个解码器块包括因果性卷积块和注意力块,并且所述基于注意力的解码器使用所述一组注意力关键表示、所述一组注意力值表示和来自与所述输入文本相对应的groundtruth音频的特征,从而针对每个时间帧:使用所述因果性卷积块和从现有音频帧的表示的至少一部分中获得的数据生成查询;以及经由所述注意力块,计算所述环境表示,作为使用所述一组注意力关键表示的至少一部分和来自所述因果性卷积块的所述查询计算的注意力权重和所述一组注意力值表示的至少一部分的加权平均值。根据本申请的又一方面,提供了用于从输入文本合成语音的计算机实施的方法,所述方法包括:使用包括一个或多个卷积层的已训练的编码器,将所述输入文本编码为一组关键表示和一组值表示;使用已训练的基于注意力的解码器将所述一组关键表示和所述一组值表示解码为一组低维音频表示帧,所述已训练的基于注意力的解码器包括至少一个解码器块,所述至少一个解码器块包括因果性卷积块和注意力块,其中,针对每个时间帧:所述因果性卷积块使用现有低维音频表示帧的至少一部分生成查询;以及所述注意力块计算环境表示,作为使用所述一组关键表示的至少一部分和来自所述因果性卷积块的所述查询计算的注意力权重和所述一组值表示的至少一部分的加权平均值;以及使用所述环境表示生成最终一组低维音频表示帧,所述最终一组低维音频表示帧由声码器使用以输出表示所述输入文本的合成语音的信号。附图说明将参考本发明的实施方式,它们的示例可示于附图中。这些附图旨在是说明性的而非限制性的。虽然本发明大体上在这些实施方式的上下文中描述,但应理解,本发明的范围并不旨在限于这些特定实施方式。附图中的项目未按比例绘制。图1示意性描绘了根据本公开的实施方式的示例性文本转语音架构。图2描绘了根据本公开的实施方式的使用诸如图1中描绘的文本转语音架构的通常总体方法。图3示意性描绘了根据本公开的实施方式的卷积块,该卷积块包括具有门控线性单元的一维(1d)卷积和剩余连接。图4示意性描绘了根据本公开的实施方式的注意力块的实施方式。图5a至图5c描绘了根据本公开的实施方式的注意力分布:(5a)训练前,(5b)训练后,但是没有推理约束,以及(5c)将推理约束应用于第一层和第三层。图6示意性描绘了根据本公开的实施方式的生成world特征的四个全连接层。图7示意性描绘了根据本公开的实施方式的详细的示例性deepvoice3模型架构。图8a示出了根据本公开的实施方式的vctk数据集学习嵌入的前两个主成分所跨越的空间中的说话者的性别。图8b示出了根据本公开的实施方式的librispeech数据集学习嵌入的前两个主成分所跨越的空间中的说话者的性别。图9描绘了根据本文件的实施方式的计算装置/信息处理系统的简化框图。具体实施方式在以下描述中,出于解释目的,阐明具体细节以便提供对本发明的理解。然而,将对本领域的技术人员显而易见的是,可在没有这些细节的情况下实践本发明。此外,本领域的技术人员将认识到,下文描述的本发明的实施方式可以以各种方式(例如过程、装置、系统、设备或方法)在有形的计算机可读介质上实施。附图中示出的组件或模块是本发明实施方式的示例性说明,并且意图避免使本发明不清楚。还应理解,在本论述的全文中,组件可描述为单独的功能单元(可包括子单元),但是本领域的技术人员将认识到,各种组件或其部分可划分成单独组件,或者可整合在一起(包括整合在单个的系统或组件内)。应注意,本文论述的功能或操作可实施为组件。组件可以以软件、硬件、或它们的组合实施。此外,附图内的组件或系统之间的连接并不旨在限于直接连接。相反,在这些组件之间的数据可由中间组件修改、重格式化、或以其它方式改变。另外,可使用另外或更少的连接。还应注意,术语“联接”、“连接”、或“通信地联接”应理解为包括直接连接、通过一个或多个中间设备来进行的间接连接、和无线连接。在本说明书中对“一个实施方式”、“优选实施方式”、“实施方式”或“多个实施方式”的提及表示结合实施方式所描述的具体特征、结构、特性或功能包括在本发明的至少一个实施方式中,以及可包括在多于一个的实施方式中。另外,在本说明书的各个地方出现以上所提到的短语并不一定全都是指相同的实施方式或多个相同实施方式。在本说明书的各个地方使用某些术语目的在于说明,并且不应被理解为限制。服务、功能或资源并不限于单个服务、单个功能或单个资源;这些术语的使用可指代相关服务、功能或资源的可分布或聚合的分组。术语“包括”、“包括有”、“包含”和“包含有”应理解为开放性的术语,并且其后任何列出内容都是实例,而不旨在限于所列项目。本文所使用的任何标题仅是为了组织目的,并且不应被用于限制说明书或权利要求的范围。本专利文献中提到的每个参考文献以其全文通过引用并入本文。此外,本领域的技术人员应认识到:(1)某些步骤可以可选地执行;(2)步骤可不限于本文中所阐述的特定次序;(3)某些步骤可以以不同次序执行;以及(4)某些步骤可同时地进行。a.前言本文提出了用于语音合成的新型全卷积架构的实施方式。实施方式被扩展到非常大的音频数据集,并且本文解决了当试图部署基于注意力的tts系统时出现的几个实际问题。由本文中公开的实施方式提供的贡献中的一些包括但不限于:1.全卷积字符转谱图架构的实施方式,它支持完全并行计算,并且比使用循环单元的类似架构训练得快一个数量级。为了方便起见,架构实施方式在本文中通常被称为deepvoice3或dv3。2.结果表明,架构实施方式训练很快速,以及扩展到librispeechasr数据集(panayotov等人,2015),该数据集包括来自2484位说话者的近820小时的音频数据。3.结果表明,可产生单调的注意力行为,避免通常影响序列到序列模型的误差模式。4.比较了几种波形合成方法的质量,包括world(morise等人,2016)、griffin-lim(griffin和lim,1984)和wavenet(oord等人,2016)。5.描述了用于deepvoice3的推理内核的实施例实施方式,该推理内核每天可在单个gpu(图形处理单元)服务器上提供近千万次的查询。b.相关工作本文中的实施方式推进了神经语音合成和基于注意力的序列到序列学习的最新进展。最近的几项工作解决了使用神经网络合成语音的问题,包括:deepvoice1(公开于2018年1月29日提交的、题为“systemsandmethodsforreal-timeneuraltext-to-speech(用于实时神经文本转语音的系统和方法)的共同转让的第15/882,926号(案卷号:28888-2105)的美国专利申请中),以及公开于2017年2月24日提交的、题为“systemsandmethodsforreal-timeneuraltext-to-speech(用于实时神经文本转语音的系统和方法)”的第62/463,482号(案卷号:28888-2105p)美国临时专利申请中,上述专利文献中的每个均通过引用以其整体并入本文中(为了方便起见,其公开内容可被称为“deepvoice1”或“dv1”);deepvoice2(公开于2018年5月8日提交的、题为“systemsandmethodsformulti-speakerneuraltext-to-speech(用于多个说话者神经文本转语音的系统和方法)的共同转让的第15/974,397号(案卷号:28888-2144)的美国专利申请中),以及公开于2017年5月19日提交的、题为“systemsandmethodsformulti-speakerneuraltext-to-speech(用于多个说话者神经文本转语音的系统和方法)”的第62/508,579号(案卷号:28888-2144p)美国临时专利申请中,上述专利文献中的每个均通过引用以其整体并入本文中(为了方便起见,其公开内容可被称为“deepvoice2”或“dv2”);tacotron(wang等人,2017);char2wav(sotelo等人,2017);voiceloop(taigman等人,2017);samplernn(mehri等人,2017)以及wavenet(oord等人,2016)。deepvoice1和deepvoice2的实施方式中的至少一些保留了tts管线的传统结构,将字素-音素转换、持续时间和频率预测以及波形合成分离开来。与deepvoice1和deepvoice2的实施方式相比,deepvoice3的实施方式采用了基于注意力的序列到序列模型,产生了更紧凑的架构。tacotron和char2wav是提出的用于神经tts的两个序列到序列模型。tacotron是神经文本到谱图转换模型,与griffin-lim一起使用以便进行谱图到波形合成。char2wav预测world声码器(morise等人,2016)的参数,并使用基于world参数的samplernn来生成波形。与char2wav和tacotron相比,deepvoice3的实施方式避开了递归神经网络(rnn),以加快训练。rnn引入了限制训练期间模型并行性的顺序依赖关系。因此,deepvoice3实施方式通过避免常见的注意力误差,使基于注意力的tts在不影响精度的情况下对生产tts系统是可行的。最后,将wavenet和samplernn作为用于波形合成的神经声码器模型。文献中也有许多高质量的人工设计的声码器的替代品,诸如straight(kawahara等人,1999)、vocaine(agiomyrgiannakis,2015)和world(morise等人,2016)。deepvoice3的实施方式没有添加新的声码器,但是具有略微改变其架构而与不同的波形合成方法集成的潜能。自动语音识别(asr)数据集通常比传统的tts语料库大得多,但往往不那么干净,因为它们通常包括多个麦克风和背景噪声。尽管现有工作已经将tts方法应用于asr数据集,但是据我们所知,deepvoice3的实施方式是第一个使用单个模型扩展到数千位说话者的tts系统。序列到序列模型通常将可变长度的输入编码成隐藏状态,然后通过解码器处理来产生目标序列。注意力机制允许解码器在生成目标序列时适应性地选择要关注的编码器隐藏状态。基于注意力的序列到序列模型广泛地应用于机器翻译、语音识别和文本概括中。最近与deepvoice3有关的注意力机制方面的改进包括训练期间强制执行的单调注意力、全注意力非递归架构和卷积序列到序列模型。deepvoice3实施方式演示了在tts中训练时单调注意力的效用,这是期望单调性的新领域。可替代地,结果表明,通过简单的启发式方法,在推理期间仅强调单调性,标准的注意机制可同样有效甚至更好。deepvoice3实施方式还建立在卷积序列到序列架构之上,通过引入使用速率调整加强的定位编码来解释输入域长度与输出域长度之间的不匹配。c.模型架构的实施方式在该节中,提出了用于tts的全卷积序列到序列架构的实施方式。架构实施方式能够将各种文本特征(例如,字符、音素、重音)转换成各种声码器参数,例如mel-band谱图、线性比例对数幅度谱图、基本频率、频谱包络和非周期性参数。此声码器参数可用作音频波形合成模型的输入。在一个或多个实施方式中,deepvoice3架构包括三个组件:-编码器:全卷积编码器,将文本特征转换成内部学习的表示。-解码器:全卷积因果解码器,以自回归的方式,使用多跳卷积注意力机制将学习过的表示解码成低维音频表示(mel-band谱图)。-转换器:全卷积后处理网络,从解码器的隐藏状态预测最终的声码器参数(取决于声码器选择)。与解码器不同,转换器是非因果性的,并因此可依赖于将来的环境信息。图1示意性描绘了根据本公开的实施方式的示例性deepvoice3架构100。在实施方式中,deepvoice3架构100使用编码器105中的剩余卷积层,将文本编码成用于基于注意力的解码器130的每一时间步长的关键与值向量120。在一个或多个实施方式中,解码器130使用这些来预测与输出音频相对应的mel比例对数幅度谱图142。在图1中,虚线箭头146描绘了推理期间的自回归合成过程(在训练期间,使用来自与输入文本相对应的groundtruth(标注的真实数据)音频的mel谱图帧)。在一个或多个实施方式中,解码器130的隐藏状态然后反馈给转换器网络150,以预测用于波形合成的声码器参数,从而产生输出波160。附录1(包括示意性描绘根据本公开的实施方式的示例性详细模型架构的图7)提供了补充细节。在一个或多个实施方式中,待优化的总体目标函数可能是来自解码器(c.5节)和转换器(c.6节)的损失的线性组合。在一个或多个实施方式中,将解码器130和转换器150分离,并施加多任务训练,因为它使注意力学习在实践中更容易。具体地,在一个或多个实施方式中,用于mel谱图预测的损失指导注意力机制的训练,因为除了声码器参数预测之外,注意力是使用来自mel谱图预测的梯度训练的(例如,使用用于mel谱图的l1损失)。在多个说话者的场景中,与deepvoice2实施方式中一样的可训练的说话者嵌入170在编码器105、解码器130和转换器150上使用。图2描绘了根据本公开的实施方式的使用诸如图1或图7中描绘的文本转语音架构的一般概述方法。在一个或多个实施方式中,使用嵌入模型(诸如文本嵌入模型110)将输入文本转换为可训练的嵌入表示(205)。使用编码器网络105将嵌入表示转换为注意力关键表示120和注意力值表示120(210),其中,编码器网络105包括一个或多个卷积块116的系列114。这些注意力关键表示120和注意力值表示120由基于注意力的解码器网络使用,其中,基于注意力的解码器网络包括一个或多个解码器块134的系列134,其中解码器块134包括生成查询138和注意力块140的卷积块136,以生成输入文本的低维音频表示(例如,142)(215)。在一个或多个实施方式中,输入文本的低维音频表示可通过后处理网络(例如,150a/152a、150b/152b或152c)进行额外处理,该后网络预测输入文本的最终音频合成(220)。如上所述,可在过程200中使用说话者嵌入170,以致使合成音频160呈现与说话者标识或说话者嵌入相关联的一个或多个音频特征(例如,男声、女声、特殊口音等)。接下来,更详细地描述这些组件中的每一个以及数据处理。示例性模型的超参数见附录3内的表4。1.文本预处理文本预处理对良好的性能可能很重要。输入原始文本(具有空格和标点符号的字符)会对许多话语产生可接受的性能。然而,一些话语可能会有罕见词的发音错误,或者可能产生省略的词和重复的词。在一个或多个实施方式中,这些问题可通过如下方式将输入文本归一化来缓解:1.在输入文本中将所有字符均大写。2.删除所有中间标点符号。3.每个话语使用句号或问号结尾。4.使用特殊分隔符字符替换词之间的空格,这些分隔符字符表示说话者插入词之间的停顿持续时间。在一个或多个实施方式中,可使用四个不同的词分隔符,分别指示(i)连音词;(ii)标准发音和空格字符;(iii)词之间的短停顿;以及(iv)词之间的长停顿。例如,“eitherway,youshouldshootveryslow”这句话,在“way”后面有长停顿,在“shoot”后面有短停顿,为了便于编码,将会被写成“eitherway%youshouldshoot/veryslow%”,%表示长停顿,/表示短停顿。在一个或多个实施方式中,停顿持续时间可通过手动标记获得或通过诸如gentle(ochshorn&hawkins,2017)的文本音频校准器进行估计。在一个或多个实施方式中,手工标记单个说话者的数据集,以及使用gentle注释多个说话者的数据集。2.字符和音素的联合表示在一个或多个实施方式中,部署的tts系统应优选地包括修改发音的方式,以纠正常见错误(通常涉及例如专有名词、外来词和领域特定的术语)。传统方式是保存词典,以将词映射为它们的语音表示。在一个或多个实施方式中,模型可将字符(包括标点符号和空格)直接地转换成声学特征,并因此学习隐式的字素转音素模型。当模型出错时,这种隐式转换可能很难纠正。因此,在一个或多个实施方式中,除了字符模型之外,可通过显式地允许音素输入选项来训练纯音素模型和/或混合的字符与音素模型。在一个或多个实施方式中,除了编码器的输入层有时接收音素和音素重音嵌入而不是字符嵌入之外,这些模型可与纯字符模型相同。在一个或多个实施方式中,纯音素模型需要预处理步骤以将词转换为它们的音素表示(例如,通过使用外部音素词典或单独训练的字素转音素模型)。在实施方式中,使用了carnegiemellonuniversitypronouncingdictionary(卡内基梅隆大学的发音词典)cmudict0.6b。在一个或多个实施方式中,混合的字符与音素模型需要类似的预处理步骤,除了不在音素词典中的词之外。这些词汇表外/词典外的词可输入为字符,从而允许模型使用其隐式学习的字素转音素模型。在训练混合的字符与音素模型时,在每个训练迭代时每个词都以一定的概率被其音素表示替换。据发现,这提高了发音准确性并使注意力误差最小化,特别是将其归纳为比在训练期间看到的要长的话语时。更重要地,支持音素表示的模型允许使用音素词典纠正错误发音,这是部署的系统的期望特征。在一个或多个实施方式中,文本嵌入模型110可包括纯音素模型和/或混合的字符与音素模型。3.用于顺序处理的卷积块通过提供足够大的接收域,堆叠的卷积层可在计算中利用序列中的长期环境信息,而无需引入任何顺序依赖关系。在一个或多个实施方式中,卷积块用作主顺序处理单元,以对文本和音频的隐式表示编码。图3示意性描绘了根据本公开的实施方式的卷积块,该卷积块包括具有门控线性单元的一维(1d)卷积和剩余连接。在一个或多个实施方式中,卷积块300包括一维(1d)卷积滤波器310、作为可学习的非线性的门控线性单元315、与输入305的剩余连接320以及比例因子325。在所示实施方式中,比例因子为尽管可使用不同的值。比例因子有助于确保输入方差在训练的早期得到保留。在图3中所示的实施方式中,c(330)表示输入305的维度,以及大小为2c(335)的卷积输出可拆分340成大小相等的部分:门向量345和输入向量350。门控线性单元为梯度流提供了线性路径,在保持非线性的同时,减轻了堆叠的卷积块梯度消失的问题。在一个或多个实施方式中,为了引入与说话者相关的控制,可在softsign函数之后,在卷积滤波器输出中添加与说话者相关的嵌入355作为偏差。在一个或多个实施方式中,使用了softsign非线性,因为它限制输出的范围,同时也避免了基于指数的非线性有时呈现的饱和问题。在一个或多个实施方式中,卷积滤波器权重使用整个网络中的零均值和单元方差激活法进行初始化。架构中的卷积可以是非因果性的(例如,编码器105/705和转换器150/750中)或因果性的(例如,解码器130/730中)。在一个或多个实施方式中,为了保持序列长度,对于左边因果性卷积,输入使用k–1个0的时间步长进行填充,对于左边和右边的非因果性卷积,使用(k–1)/2个0的时间步长进行填充,其中,k为奇数卷积滤波器宽度(在实施方式中,奇数卷积宽度用于简化卷积算法,尽管可使用偶数卷积宽度和偶数k值)。在一个或多个实施方式中,在卷积之前对输入应用dropout360,以便进行调整。4.编码器在一个或多个实施方式中,编码器网络(例如,编码器105/705)从嵌入层开始,嵌入层将字符或音素转换为可训练的向量表示he。在一个或多个实施方式中,这些嵌入he首先经由全连接层从嵌入维度投影为目标维度。然后,在一个或多个实施方式中,它们通过一系列的卷积块(诸如c.3节中描述的实施方式)进行处理,以选取依赖时间的文本信息。最后,在一个或多个实施方式中,它们投影回嵌入维度,以创建注意力关键向量hk。注意力值向量可由注意力关键向量和文本嵌入进行计算,以联合考虑he中的局部信息和hk中的长期环境信息。关键向量hk被用于每个注意力块以计算注意力权重,而最终环境向量计算为值向量hv的加权平均值(见c.6节)。5.解码器在一个或多个实施方式中,解码器网络(例如,解码器130/730)通过预测以过去音频帧为条件的一组r个未来音频帧而以自回归的方式生成音频。由于解码器是自回归的,所以在实施方式中,它使用因果性卷积块。在一个或多个实施方式中,选择mel-band对数幅度谱图作为紧凑的低维音频帧表示,尽管可使用其它表示。根据经验观察到,将多个帧一起解码(即,r>1)产生更好的音频质量。在一个或多个实施方式中,解码器网络从具有整流线性单元(relu)的非线性的多个全连接层开始,以对输入的mel谱图(在图1中表示为“prenet(前网络)”)进行预处理。然后,在一个或多个实施方式中,其后是一系列解码器块,其中,解码器块包括因果性卷积块和注意力块。这些卷积块生成用于参与编码器隐藏状态的查询(见c.6节)。最后,在一个或多个实施方式中,全连接层输出下一组r个音频帧以及二进制的“最终帧”预测(指示是否已经合成话语的最后一帧)。在一个或多个实施方式中,在注意力块之前的每个全连接层之前均应用dropout,除了第一个之外。可使用输出的mel谱图来计算l1损失,以及可使用最终帧预测来计算二进制交叉熵损失。选择l1损失,因为它凭经验产生了最好的结果。诸如l2的其它损失可能受到异常频谱特征,这些异常的频谱特征可能与非语音噪声相对应。6.注意力块图4示意性描绘了根据本公开的实施方式的注意力块的实施方式。如图4中所示,在一个或多个实施方式中,定位编码405、定位编码410可分别添加至关键420和查询438矢量,速率分别为ωkey405和ωquery410。通过向分对数(logits)添加大负值的掩码,可在推断中应用强制单调性。可使用两种可能的注意力方案中的一个:softmax或单调注意力(例如,来自raffel等人(2017))。在一个或多个实施方式中,在训练期间,丢弃注意力权重。在一个或多个实施方式中,使用点积注意力机制(如图4中所示)。在一个或多个实施方式中,注意力机制使用来自编码器的每时间步长关键向量420和查询向量438(解码器的隐藏状态)来计算注意力权重,然后输出计算为值向量421的加权平均值的环境向量415。通过引入注意力随时间单调递进的感应偏差,观察到经验益处。因此,在一个或多个实施方式中,将定位编码添加至关键和查询向量中。这些定位编码hp可选择为hp(i)=sin(ωsi/10000k/d)(对于偶数i)或cos(ωsi/10000k/d)(对于奇数i),其中i为时间步长索引,k为定位编码中的信道索引,d为定位编码中的信道总数,以及ωs为编码定位速率。在一个或多个实施方式中,定位速率指示注意力分布中的线的平均斜率,大致与语速相对应。对于单个说话者,可将ωs设置为1以用于查询,并且可固定为输出时间步长与输入时间步长的比值(在整个数据集上计算)以用于关键(key)。对于多个说话者的数据集,可从每个说话者的说话者嵌入来计算用于关键和查询的xs(例如,如图4中所示)。当正弦和余弦函数形成标准正交基时,该初始化产生对角线形式的注意力分布(见图5a)。在一个或多个实施方式中,用于计算隐藏的注意力向量的全连接层权重被初始化为相同的值,以用于查询投影和关键投影。定位编码可用于所有的注意力块。在一个或多个实施方式中,使用了环境归一化(例如,gehring等人(2017)中)。在一个或多个实施方式中,将全连接层应用于环境向量以生成注意力块的输出。总体而言,定位编码改进了卷积注意力机制。生产质量的tts系统对注意力误差具有非常低的容忍度。因此,除了定位编码之外,还考虑了额外的策略以消除重复或省略词的情况。可使用的一种方法是使用raffel等人(2017)引入的单调的注意力机制代替规范的注意力机制,其通过期望训练逼近具有软单调注意力的硬单调随机解码。raffel等人(2017)也通过采样提出了硬单调注意力过程。它的目的是通过仅参与经由采样所选择的状态来提高推理速度,从而避免对未来状态的计算。本文的实施方式不受益于这种加速,并且在一些情况下观察到不良注意力行为,例如停留在第一个字符或最后一个字符上。尽管单调性有所改善,但是这种策略可能产生更加分散的注意力分布。在一些情况下,会同时出现几个字符,无法获得高质量的语音。这可能归因于软对准的非归一化注意力系数,可能导致来自编码器的弱信号。因此,在一个或多个实施方式中,使用仅在推理时将注意力权重约束为单调的替代策略,使训练过程保持没有任何约束。不是在整个输入上计算softmax,而是可在固定窗口上计算softmax,该固定窗口起始于最后出现的位置并前进几个时间步长。在本文的试验中,使用的窗口大小为三,尽管可使用其它窗口大小。在一个或多个实施方式中,初始位置设置为零,并且稍后被计算为当前窗口内的最高注意力权重的索引。如图5a至图5c中所示,该策略还在推理中强制执行单调注意力以及产生出色的语音质量。7.转换器在一个或多个实施方式中,转换器网络(例如,150/750)将来自解码器的最后隐藏层的激活作为输入,应用几个非因果性卷积块,然后预测用于下游声码器的参数。在一个或多个实施方式中,与解码器不同,转换器是非因果性的和非自回归的,因此它可使用来自解码器的未来环境预测其输出。在实施方式中,转换器网络的损失函数取决于下游声码器的类型:1.griffin-lim声码器:在一个或多个实施方式中,griffin-lim算法通过迭代地估计未知相位而将谱图转换为时域音频波形。据发现,在波形合成之前将由锐化因子参数化的谱图自乘有助于改善音频质量。l1损失用于预测线性尺度对数幅度谱图。2.world声码器:在一个或多个实施方式中,world声码器是基于morise等人(2016)。图6示意性描绘了根据本公开的实施方式的具有全连接(fc)层的示例性生成的world声码器参数。在一个或多个实施方式中,预测了作为声码器参数的布尔(boolean)值610(当前帧为浊音还是清音),f0值625(如果帧为浊音),频谱包络615和非周期性参数620。在一个或多个实施方式中,交叉熵损失用于浊音–清音预测,以及l1损失用于所有其它预测。在实施方式中,“σ”是sigmoid函数,其用于获得用于二进制交叉熵预测的有界变量。在一个或多个实施方式中,输入605是转换器中的输出隐藏状态。3.wavenet声码器:在一个或多个实施方式中,wavenet被单独训练以用作声码器,将梅尔尺度对数幅度谱图作为声码器参数处理。这些声码器参数作为外部调节器输入到网络中。可使用ground-truthmel谱图和音频波形来训练wavenet。除了调节器之外的架构类似于deepvoice2中描述的wavenet。虽然deepvoice2的某些实施方式中的wavenet受线性尺度对数幅度谱图的制约,但是使用mel尺度谱图观察到良好的性能,这与更紧凑的音频表示相对应。除了在解码时mel尺度谱图上的l1损失之外,线性尺度谱图上的l1损失也可用作griffin-lim声码器。d.结果应注意的是,这些实验和结果以说明的方式提供,并且使用一个或多个的具体实施方式在具体条件下执行;因此,这些实验或其结果不应当用于限制本专利文件的公开的范围。该节中是评估语音合成系统实施方式的几个不同实验和度量。此外,系统实施方式的性能被量化并与其它最近公布的神经tts系统进行比较。1.数据对于单个说话者合成,使用包含大约20小时音频且具有48khz采样率的内部英语语音数据集。对于多个说话者合成,使用vctk和librispeech数据集。vctk数据集包含108位说话者的音频,总持续时间约为44小时。librispeech数据集包含2484为说话者的音频,总持续时间约为820小时。vctk的采样率为48khz,librispeech的采样率为16khz。2.快速训练将deepvoice3实施方式与最近发布的基于注意力的tts系统tacotron进行比较。对于在单个说话者数据上测试的deepvoice3系统实施方式,使用一个gpu的平均训练迭代时间(批量大小为4)为0.06秒,而对于tacotron为0.59秒,表明训练速度增大十倍。此外,对于试验中的所有三个数据集,deepvoice3实施方式在约500k迭代之后收敛,而tacotron需要约2m迭代。这种显着的加速至少部分地归因于deepvoice3实施方式的全卷积架构,其在训练期间高度利用gpu的并行性。3.注意力误差模式基于注意力的神经tts系统可遇到几种可能降低合成质量的误差模式——包括(1)重复的词,(ii)错误发音,以及(iii)省略的词。例如,考虑短语“dominantvegetarian”,应该用音素“daamahnahnt.vehjhahtehriyahn.”来发音。以下是上述三种误差模式的示例性误差:(i)“daamahnahnt.vehjhahtehtehriyahn.”;(ii)“daemahnaent.vehjhahtehriyahn.”;以及(iii)“dahnt.vehjhahtehriyahn.”(i)和(iii)的一个原因是基于注意力的模型实施方式没有利用单调处理机制。为了跟踪注意力误差的发生,构建了自定义的100个句子的测试集(见附录5),其包括来自部署的tts系统的特别具有挑战性的情况(例如,日期,首字母缩写词,url,重复的词,专有名词,外来词等)。表1中列出了注意力误差计数,其表明使用标准注意力机制训练但在推理中强制执行单调约束的、具有字符和音素的联合表示的模型在很大程度上优于其它方法。表1:单个说话者deepvoice3模型实施方式在100个句子的测试集(在附录5中给出)上的注意力误差计数。一个或多个错误发音,省略和重复计为每个话语的单个错误。“音素&字符”是指使用联合字符和音素表示训练的模型实施方式,如c.2节中所讨论的。不包括纯音素的模型,因为测试集包含词汇外的词。所有的模型实施方式都使用griffin-lim作为他们的声码器。文本输入注意力推理约束重复的发音错误的省略的纯字符点积是33519音素&字符点积否121015音素&字符点积是143音素&字符单调性否59114.自然度已经证明,波形合成的选择对于自然度评级很重要,并将其与其它公布的神经tts系统进行比较。表2中的结果表明,wavenet、神经声码器实现3.78的最高mos,其次为world和griffin-lim,分别为3.63和3.62。因此,表明最自然的波形合成可使用神经声码器来完成,以及基本谱图反演技术可将高级声码器与高质量的单个说话者数据进行匹配。wavenet声码器实施方式听起来更自然,因为world声码器引入了各种引人注意的伪像。然而,较低的推理延迟可能致使world声码器更受欢迎:经过精心设计的wavenet实施例每个cpu核实时运行3x,而world每个cpu核实时运行高达40x(见下面的小节)。表2:使用不同波形合成方法的具有95%置信区间的平均意见分(mos)评级。使用了crowdmos工具包(ribeiro等人,2011);来自这些模型的批量样品被提交给mechanicalturk的评估者。由于批次包含来自所有模型的样本,因此试验自然地引起模型之间的比较。5.多个说话者合成为了证明模型实施方式能够有效地处理多个说话者的语音合成,在vctk和librispeech数据集上训练模型实施方式。对于librispeech(asr数据集),标准去噪(使用例如sox(bagwell,2017))并在停顿位置将长话语拆分成多个话语(由gentle确定(ochshorn&hawkins,2017)))的预处理步骤。结果呈现在表3中。ground-truth样本被有意地包括在正评估的集合中,因为北美众包评估者可能不熟悉数据集中的重音。具有world声码器的模型实施方式在vctk上实现了可比较的3.44的mos,而来自deepvoice2实施方式的mos为3.69,这是使用wavenet作为声码器并且单独优化的音素持续时间和基本频率预测模型的最先进的多个说话者神经tts系统。通过将wavenet用于多个说话者合成,预计会有进一步的改进,尽管它可能会减慢推理速度。与vctk相比,在librispeech上的mos较低,这可能主要归因于由于各种记录条件和明显的背景噪声,训练数据集的质量较低。deepvoice3实施方式在仅具有108位说话者(与vctk相同)的二次采样的librispeech数据集上进行测试,并且观察到比vctk质量更差的生成样本。在文献中,yamagishi等人(2010)在将参数化tts方法应用于具有数百位说话者的不同asr数据集时,也观察到更差的性能。最后,发现学习的说话者嵌入位于有意义的潜在空间中(见附录4中的图8a和图8b)。表3:示出了对来自多个说话者数据集上的神经tts系统的音频剪辑的95%置信区间的平均意见分(mos)评级。还使用了crowdmos工具包;包括groundtruth的批量样本被提交给人类评估者。多个说话者tacotron实施例和超参数是基于deepvoice2实施方式。deepvoice2实施方式系统和tacotron系统未针对librispeech数据集进行训练,因为优化超参数需要非常长的时间。6.优化部署推理为了以成本有效的方式部署神经tts系统,系统应能够在相当数量的硬件上处理与替代系统一样多的流量。为此,在具有二十个cpu核的单个gpu服务器上,目标是每天一千万次查询的吞吐量或每秒116次查询(qps)(其中查询被定义为合成一秒钟话语的音频),发现其成本与商业部署的tts系统相当。通过为deepvoice3架构实施方式实施自定义gpu内核并跨cpu并行world合成,证明了模型实施方式每天可处理一千万次查询。附录2中提供了有关实施方式的更多细节。e.一些结论本文呈现的是基于具有位置增强的注意力机制的新型全卷积序列到序列声学模型的神经文本转语音系统的实施方式。该系统的实施方式可被称为deepvoice3。描述了序列到序列语音合成模型中的常见误差模式,并且示出了deepvoice3实施方式成功地避免了这些常见误差模式。示出了模型实施方式与波形合成方法无关,以及实施方式可适用于griffin-lim谱图反演,wavenet和world声码器合成。已经证明,架构实施方式能够通过使用可训练的说话者嵌入来增强实施方式而实现多个说话者的语音合成。最后,描述了生产就绪的deepvoice3系统实施方式,包括文本标准化和性能特征,并且通过大量的mos评估来演示实施方式的最新质量。本领域技术人员将认识到,实施方式可包括改变以帮助改进隐式学习的字素转音素模型,与神经声码器联合训练,以及在更干净和更大的数据集上训练,以使模型扩展至来自成千上万的说话者的人类声音和口音的全部变化。f.系统实施方式在实施方式中,本专利文献的方面可涉及、可包括一个或多个信息处理系统/计算系统或者可在一个或多个信息处理系统/计算系统上实施。计算系统可包括可操作来计算、运算、确定、分类、处理、传输、接收、检索、发起、路由、交换、存储、显示、通信、显现、检测、记录、再现、处理或利用任何形式信息、智能或数据的任何手段或手段的组合。例如,计算系统可为或可包括个人计算机(例如,膝上型计算机)、平板电脑、平板手机、个人数字助理(pda)、智能手机、智能手表、智能包装、服务器(例如,刀片式服务器或机架式服务器)、网络存储设备、摄像机或任何其他合适设备,并且可在大小、形状、性能、功能和价格方面改变。计算系统可包括随机存取存储器(ram)、一个或多个处理资源(例如中央处理单元(cpu)或硬件或软件控制逻辑)、rom和/或其他类型的存储器。计算系统的另外组件可包括一个或多个盘驱动器、用于与外部设备通信的一个或多个网络端口、以及各种输入和输出(i/o)设备(例如键盘、鼠标、触摸屏和/或视频显示器)。计算系统还可包括可操作为在各种硬件组件之间传输通信的一个或多个总线。图9描绘根据本公开的实施方式的计算设备/信息处理系统(或是计算系统)的简化框图。应理解,计算系统可不同地配置并且包括不同组件,包括如图9中所示的更少或更多的部件,但应理解,针对系统900所示出的功能可操作为支持计算系统的各种实施方式。如图9所示,计算系统900包括一个或多个中央处理单元(cpu)901,cpu901提供计算资源并控制计算机。cpu901可实施有微处理器等,并且还可包括一个或多个图形处理单元(gpu)919和/或用于数学计算的浮点协处理器。系统900还可包括系统存储器902,系统存储器902可呈随机存取存储器(ram)、只读存储器(rom)、或两者的形式。如图9所示,还可提供多个控制器和外围设备。输入控制器903表示至各种输入设备904的接口,例如键盘、鼠标、触摸屏和/或触笔。计算系统900还可包括存储控制器907,该存储控制器907用于与一个或多个存储设备908对接,存储设备中的每个包括存储介质(诸如磁带或盘)或光学介质(其可用于记录用于操作系统、实用工具和应用程序的指令的程序,它们可包括实施本发明的各方面的程序的实施方式)。存储设备908还可用于存储经处理的数据或是将要根据本发明处理的数据。系统900还可包括显示控制器909,该显示控制器909用于为显示设备911提供接口,显示设备911可为阴极射线管(crt)、薄膜晶体管(tft)显示器、有机发光二极管、电致发光面板、等离子面板或其他类型的显示器。计算系统900还可包括用于一个或多个外围设备906的一个或多个外围控制器或接口905。外围设备的示例可包括一个或多个打印机、扫描仪、输入设备、输出设备、传感器等。通信控制器914可与一个或多个通信设备915对接,这使系统900能够通过各种网络(包括互联网、云资源(例如以太云、经以太网的光纤通道(fcoe)/数据中心桥接(dcb)云等)、局域网(lan)、广域网(wan)、存储区域网络(san))中的任一网络,或通过任何合适电磁载波信号(包括红外信号)来连接至远程设备。在示出的系统中,所有主要系统组件可连接至总线916,总线916可表示多于一个的物理总线。然而,各种系统组件可在物理上彼此接近或可不在物理上彼此接近。例如,输入数据和/或输出数据可远程地从一个物理位置传输到另一物理位置。另外,实现本发明的各方面的程序可经由网络从远程位置(例如,服务器)访问。此类数据和/或程序可通过各种机器可读介质中的任一机器可读介质来传送,机器可读介质包括但不限于:诸如硬盘、软盘和磁带的磁性介质;诸如cd-rom和全息设备的光学介质;磁光介质;以及硬件设备,该硬件设备专门被配置成存储或存储并执行程序代码,该硬件设备例如专用集成电路(asic)、可编程逻辑器件(pld)、闪存设备、以及rom和ram设备。本发明的方面可利用用于一个或多个处理器或处理单元以使步骤执行的指令在一个或多个非暂态计算机可读介质上编码。应注意,一个或多个非暂态计算机可读介质应当包括易失性存储器和非易失性存储器。应注意,替代实现方式是可能的,其包括硬件实现方式或软件/硬件实现方式。硬件实施的功能可使用asic、可编程的阵列、数字信号处理电路等来实现。因此,任何权利要求中的术语“手段”旨在涵盖软件实现方式和硬件实现方式两者。类似地,如本文使用的术语“计算机可读媒介或介质”包括具有实施在其上的指令程序的软件和/或硬件或它们的组合。利用所构想的这些替代实现方式,应当理解,附图以及随附描述提供本领域的技术人员编写程序代码(即,软件)和/或制造电路(即,硬件)以执行所需处理所要求的功能信息。应当注意,本发明的实施方式还可涉及具有其上具有用于执行各种计算机实施的操作的计算机代码的非暂态有形计算机可读介质的计算机产品。介质和计算机代码可为出于本发明的目的而专门设计和构造的介质和计算机代码,或者它们可为相关领域中的技术人员已知或可用的。有形计算机可读介质的示例包括但不限于:诸如硬盘、软盘和磁带的磁性介质;诸如cd-rom和全息设备的光学介质;磁光介质;以及专门配置成存储或存储并执行程序代码的硬件设备,例如,专用集成电路(asic)、可编程逻辑器件(pld)、闪存设备、以及rom和ram设备。计算机代码的示例包括机器代码(例如,编译器产生的代码)以及包含可由计算机使用解释器来执行的更高级代码的文件。本发明的实施方式可整体地或部分地实施为可在由处理设备执行的程序模块中的机器可执行指令。程序模块的示例包括库、程序、例程、对象、组件和数据结构。在分布的计算环境中,程序模块可物理上定位在本地、远程或两者的设定中。本领域的技术人员将认识到,计算系统或编程语言对本发明的实践来说均不重要。本领域的技术人员将还将认识到,多个上述元件可物理地和/或在功能上划分成子模块或组合在一起。本领域技术人员将理解,前文的示例和实施方式是示例性的,并且不限制本公开的范围。旨在说明的是,在本领域的技术人员阅读本说明书并研究附图后将对本领域的技术人员显而易见的本发明的所有、置换、增强、等同、组合或改进包括在本公开的真实精神和范围内。还应注意,任何权利要求书的元素可不同地布置,包括具有多个从属、配置和组合。g.附录1.deepvoice3的详细模型架构的实施方式图7示意性描绘了根据本公开的实施方式的示例性详细的deepvoice3模型架构。在一个或多个实施方式中,模型700使用深度剩余卷积网络将文本和/或音素编码为用于注意力解码器730的每时间步长关键720和值722向量。在一个或多个实施方式中,解码器730使用这些来预测与输出音频相对应的mel-band对数幅度谱图742。虚线箭头746描绘了推理期间的自回归合成过程。在一个或多个实施方式中,解码器的隐藏状态被馈送至转换器网络750,以输出用于griffin-lim752a的线性谱图或用于world752b的参数,这些可用于合成最终波形。在一个或多个实施方式中,权重归一化应用于模型中的所有卷积滤波器和全连接层的权重矩阵。如图7中描绘的实施方式中所示,wavenet752不需要单独的转换器,因为它输入了mel-band对数幅度谱图。2.优化用于部署的deepvoice3的实施方式使用tensorflow图进行推理结果是非常昂贵的,平均大约1qps。糟糕的tensorflow性能可能是由于在数百个节点和数百个时间步长上进行图形评估的开销造成的。使用诸如具有tensorflow的xla技术可加快评估,但不太可能与手写内核的性能相匹配。相反,为deepvoice3实施方式推理,实施了自定义gpu内核。由于模型的复杂性和大量的输出时间步长,为图中的不同操作(例如,卷积,矩阵乘法,一元和二元运算等)启动单个内核可能是不切实际的;启动cuda内核的开销大约为50μs,当对模型中的所有操作和所有输出时间步长聚合时,将吞吐量限制为大约10qps。因此,为整个模型实施单个内核,这避免了启动许多cuda内核的开销。最后,代替在内核中批量计算,本文的内核实施方式在单个话语上操作,并且启动与gpu上的流式多处理器(sm)一样多的并发流。每个内核均可使用一个块启动,因此gpu预计成每个sm计划一个块,允许根据sm的数量线性地扩展推理速度的能力。在位于加利福尼亚州圣克拉拉的nvidia公司的具有56个sm的单个nvidiateslap100gpu上,实现了115qps的推理速度,这与每天1000万次查询的目标相对应。在实施方式中,在服务器上的所有20个cpu上并行world合成,将线程永久地固定到cpu以使高速缓存性能最大化。在此设置中,gpu推理是瓶颈,因为在20核上的world合成比115qps更快。通过更优化的内核,更小的模型和固定精度的算法,可更快地进行推理。3.模型的超参数下表4中提供了本专利文件中所使用的模型的所有超参数。表4:用于本专利文件中使用的三个数据集的最佳模型的超参数。4.学习嵌入的潜在空间将主成分分析应用于学习的说话者嵌入,并且基于他们的groundtruth性别来对说话者进行分析。图8a和图8b示出了由前两个主成分跨越的空间中的说话者的性别。观察到男女性别之间的明显分离,表明低维说话者嵌入构成了有意义的潜在空间。图8a和图8b描绘了根据本公开的实施方式的针对(a)vctk数据集(108位说话者)和(b)librispeech数据集(2484位说话者)的学习嵌入的前两个主成分。5.100个句子的测试集下面列出了用于量化表1中的结果的100个句子(注意%符号与停顿相对应):1.abc%.2.xyz%.3.hurry%.4.warehouse%.5.referendum%.6.isitfree%?7.justifiable%.8.environment%.9.adebtruns%.10.gravitational%.11.cardboardfilm%.12.personthinking%.13.preparedkiller%.14.aircrafttorture%.15.allergictrouser%.16.strategicconduct%.17.worryingliterature%.18.christmasiscoming%.19.apetdilemmathinks%.20.howwasthemathtest%?21.goodtothelastdrop%.22.anmbaagentlistens%.23.acompromisedisappears%.24.anaxisofxyorzfreezes%.25.shedidherbesttohelphim%.26.abackboneconteststhechaos%.27.twoagreaterthantwonnine%.28.don'tsteponthebrokenglass%.29.adamnedflipsintothepatient%.30.atradepurgeswithinthebbc%.31.i'dratherbeabirdthanafish%.32.ihearthatnancyisverypretty%.33.iwantmoredetailedinformation%.34.pleasewaitoutsideofthehouse%.35.nasaexposuretunesthewaffle%.36.amistdictateswithinthemonster%.37.asketchropesthemiddleceremony%.38.everyfarewellexplodesthecareer%.39.shefoldedherhandkerchiefneatly%.40.againstthesteamchoosesthestudio%.41.rockmusicapproachesathighvelocity%.42.nineadambayestudyonthetwopieces%.43.anunfriendlydecayconveystheoutcome%.44.abstractionisoftenoneflooraboveyou%.45.aplayedladyranksanypublicizedpreview%.46.hetoldusaveryexcitingadventurestory%.47.onaugusttwentyeigth%maryplaysthepiano%.48.intoacontrollerbeamsaconcreteterrorist%.49.ioftenseethetimeelevenelevenonclocks%.50.itwasgettingdark%andweweren'tthereyet%.51.againsteveryrhymestarvesachoralapparatus%.52.everyonewasbusy%soiwenttothemoviealone%.53.icheckedtomakesurethathewasstillalive%.54.adominantvegetarianshiesawayfromthegop%.55.joemadethesugarcookies%susandecoratedthem%.56.iwanttobuyaonesie%butknowitwon'tsuitme%.57.aformeroverrideofqwertyoutsidethepope%.58.fbisaysthatciasays%i'llstayawayfromit%.59.anyclimbingdishlistenstoacumbersomeformula%.60.shewrotehimalongletter%buthedidn'treadit%.61.dear%beautyisintheheatnotphysical%iloveyou%.62.anappealonjanuaryfifthduplicatesasharpqueen%.63.afarewellsolosonmarchtwentythirdshakesnorth%.64.heranoutofmoney%sohehadtostopplayingpoker%.65.forexample%anewspaperhasonlyregionaldistributiont%.66.icurrentlyhavefourwindowsopenup%andidon'tknowwhy%.67.nexttomyindirectvocaldeclineseveryunbearableacademic%.68.oppositehersoundingbagisamc'sconfiguredthoroughfare%.69.fromaprileighthtothepresent%ionlysmokefourcigarettes%.70.iwillneverbethisyoungagain%ever%ohdamn%ijustgotolder%.71.agenerouscontinuumofamazondotcomistheconflictingworker%.72.sheadvisedhimtocomebackatonce%thewifelecturestheblast%.73.asongcanmakeorruinaperson'sdayiftheyletitgettothem%.74.shedidnotcheatonthetest%foritwasnottherightthingtodo%.75.hesaidhewasnotthereyesterday%however%manypeoplesawhimthere%.76.shouldwestartclassnow%orshouldwewaitforeveryonetogethere%?(%?)77.ifpurplepeopleeatersarereal%wheredotheyfindpurplepeopletoeat%?(%?)78.onnovembereighteentheighteentwentyone%aglitteringgemisnotenough%.79.arocketfromspacexinteractswiththeindividualbeneaththesoftflaw%.80.mallsaregreatplacestoshop%icanfindeverythingineedunderoneroof%.81.ithinkiwillbuytheredcar%oriwillleasetheblueone%thefaithnests%.82.italyismyfavoritecountry%infact%iplantospendtwoweekstherenextyear%.83.iwouldhavegottenwwwdotgoogledotcom%butmyattendancewasn'tgoodenough%.84.nineteentwentyiswhenweareuniquetogetheruntilwerealise%weareallthesame%.85.mymumtriestobecoolbysayinghttpcolonslashslashwwwbaidudotcom%.86.heturnedintheresearchpaperonfriday%otherwise%heemailedasdfatyahoodotorg%.87.sheworkstwojobstomakeendsmeet%atleast%thatwasherreasonfornothavingtimetojoinus%.88.aremarkablewellpromotesthealphabetintotheadjustedluck%thedressdodgesacrossmyassault%.89.abcdefghijklmnopqrstuvwxyzonetwothreefourfivesixseveneightnineten%.90.acrossthewastepersiststhewrongpacifier%thewashedpassengerparadesundertheincorrectcomputer%.91.iftheeasterbunnyandthetoothfairyhadbabieswouldtheytakeyourteethandleavechocolateforyou%?92.sometimes%allyouneedtodoiscompletelymakeanassofyourselfandlaughitofftorealisethatlifeisn'tsobadafterall%.93.sheborrowedthebookfromhimmanyyearsagoandhasn'tyetreturnedit%whywon'tthedistinguishinglovejumpwiththejuvenile%?94.lastfridayinthreeweek'stimeisawaspottedstripedbluewormshakehandswithaleglesslizard%thelakeisalongwayfromhere%.95.iwasveryproudofmynicknamethroughouthighschoolbuttoday%icouldn'tbeanydifferenttowhatmynicknamewas%themetallusts%therangingcaptainchartersthelink%.96.iamhappytotakeyourdonation%anyamountwillbegreatlyappreciated%thewaveswerecrashingontheshore%itwasalovelysight%theparadoxsticksthisbowlontopofaspontaneoustea%.97.apurplepigandagreendonkeyflewakiteinthemiddleofthenightandendedupsunburnt%thecontainederrorposesasalogicaltarget%thedivorceattacksnearamissingdoom%theoperafinesthedailyexaminerintoamurderer%.98.asthemostfamoussingler-songwriter%jaychougaveaperfectperformanceinbeijingonmaytwentyfourth%twentyfifth%andtwentysixthtwentythreeallthefansthoughthighlyofhimandtookprideinhimalltheticketsweresoldout%.99.ifyouliketunaandtomatosauce%trycombiningthetwo%it'sreallynotasbadasitsounds%thebodymayperhapscompensatesforthelossofatruemetaphysics%theclockwithinthisblogandtheclockonmylaptopareonehourdifferentfromeachother%.100.someoneiknowrecentlycombinedmaplesyrupandbutteredpopcornthinkingitwouldtastelikecaramelpopcorn%itdidn'tandtheydon'trecommendanyoneelsedoiteither%thegentlemanmarchesaroundtheprincipal%thedivorceattacksnearamissingdoom%thecolormisprintsacircularworryacrossthecontroversy%.h.引用的文献以下列出的或在本文中任何地方引用的每篇文献均通过引用以其整体并入本文。yannisagiomyrgiannakis.vocainethevocoderandapplicationsinspeechsynthesis(vocaine声码器和语音合成中的应用).inicassp,2015.chrisbagwell.sox–soundexchange.https://sourceforge.net/p/sox/code/ci/master/tree/,2017.jonasgehring,michaelauli,davidgrangier,denisyarats,andyanndauphin.convolutionalsequencetosequencelearning(卷积序列到序列学习).inicml,2017.danielgriffinandjaelim.signalestimationfrommodifiedshort-timefouriertransform(来自改进的短时傅里叶变换的信号估计).ieeetransactionsonacoustics,speech,andsignalprocessing(ieee声学、语音和信号处理汇刊),1984.hidekikawahara,ikuyomasuda-katsuse,andalaindecheveigne.restructuringspeechrepresentationsusingapitch-adaptivetime–frequencysmoothingandaninstantaneous-frequency-basedf0extraction:possibleroleofarepetitivestructureinsounds(使用基音调自适应时频平滑和基于瞬时频率的f0提取来重构语音表示:重复结构在声音中的可能作用).speechcommunication(语音通信),1999.soroushmehri,kundankumar,ishaangulrajani,ritheshkumar,shubhamjain,josesotelo,aaroncourville,andyoshuabengio.samplernn:anunconditionalend-to-endneuralaudiogenerationmodel(样本rnn:无条件端到端神经音频生成模型).iniclr,2017.masanorimorise,fumiyayokomori,andkenjiozawa.world:avocoder-basedhigh-qualityspeechsynthesissystemforreal-timeapplications(用于实时应用的、基于声码器的高质量语音合成系统).ieicetransactionsoninformationandsystems(ieice信息与系统汇刊),2016.robertochshornandmaxhawkins.gentle.https://github.com/lowerquality/gentle,2017.aaronvandenoord,sanderdieleman,heigazen,karensimonyan,oriolvinyals,alexgraves,nalkalchbrenner,andrewsenior,andkoraykavukcuoglu.wavenet:agenerativemodelforrawaudio(原始音频的生成模型).arxiv:1609.03499,2016.vassilpanayotov,guoguochen,danielpovey,andsanjeevkhudanpur.librispeech:anasrcorpusbasedonpublicdomainaudiobooks(librispeech:基于公共领域有声读物的asr语料库).inacoustics,speechandsignalprocessing(icassp)(声学,语音和信号处理),2015ieeeinternationalconference(2015ieee国际会议)on,pp.5206–5210.ieee,2015.librispeech数据集可在http://www.openslr.org/12/上获得。colinraffel,thangluong,peterjliu,ronjweiss,anddouglaseck.onlineandlinear-timeattentionbyenforcingmonotonicalignments(通过强制执行单调对齐的在线和线性时间注意力).inicml,2017.flavioribeiro,dineiflorencio,chazhang,andmichaelseltzer.crowdmos:anapproachforcrowdsourcingmeanopinionscorestudies(用于众包平均意见分研究的方法).inieeeicassp,2011.josesotelo,soroushmehri,kundankumar,joaofelipesantos,kylekastner,aaroncourville,andyoshuabengio.char2wav:end-to-endspeechsynthesis(char2wav:端到端语音合成).iniclrworkshop,2017.yanivtaigman,liorwolf,adampolyak,andeliyanachmani.voicesynthesisforin-the-wildspeakersviaaphonologicalloop(通过语音回路对野外说话者进行语音合成).arxiv:1707.06588,2017.yuxuanwang,rjskerry-ryan,daisystanton,yonghuiwu,ronweiss,navdeepjaitly,zonghengyang,yingxiao,zhifengchen,samybengio,quocle,yannisagiomyrgiannakis,robclark,andrifa.saurous.tacotron:towardsend-to-endspeechsynthesis(tacotron:迈向端到端语音合成).ininterspeech,2017.junichiyamagishi,belausabaev,simonking,oliverwatts,johndines,jileitian,yongguan,rilehu,keiichirooura,yi-jianwu,etal.thousandsofvoicesforhmm-basedspeechsynthesis–analysisandapplicationofttssystemsbuiltonvariousasrcorpora(基于hmm语音合成的数千种语音-基于各种asr语料库的tts系统的分析和应用).ieeetransactionsonaudio,speech,andlanguageprocessing(ieee音频,语音和语言处理汇刊),2010.当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1