一种基于语音的情绪识别方法及装置与流程
本发明涉及一种基于语音的情绪识别方法及装置。
背景技术:
情绪是综合了人的感觉、思想和行为的一种状态,在人与人的交流中发挥着重要作用。情绪是一种综合了人的感觉、思想和行为的状态,它包括人对外界或自身刺激的心理反应,包括伴随这种心理反应的生理反应。在人们的日常工作和生活中,情绪的作用无处不在。在医疗护理中,如果能够知道患者、特别是有表达障碍的患者的情绪状态,就可以根据患者的情绪做出不同的护理措施,提高护理量。在产品开发过程中,如果能够识别出用户使用产品过程中的情绪状态,了解用户体验,就可以改善产品功能,设计出更适合用户需求的产品。在各种人-机交互系统里,如果系统能识别出人的情绪状态,人与机器的交互就会变得更加友好和自然。对情绪进行分析和识别是神经科学、心理学、认知科学、计算机科学和人工智能等领域的一项重要的交叉学科研究课题,因此,对情绪进行识别的方法以供给各个领域使用。
技术实现要素:
本发明要解决的技术问题是提供一种基于语音的情绪识别方法及装置,识别准确率高。
为解决上述问题,本发明采用如下技术方案:
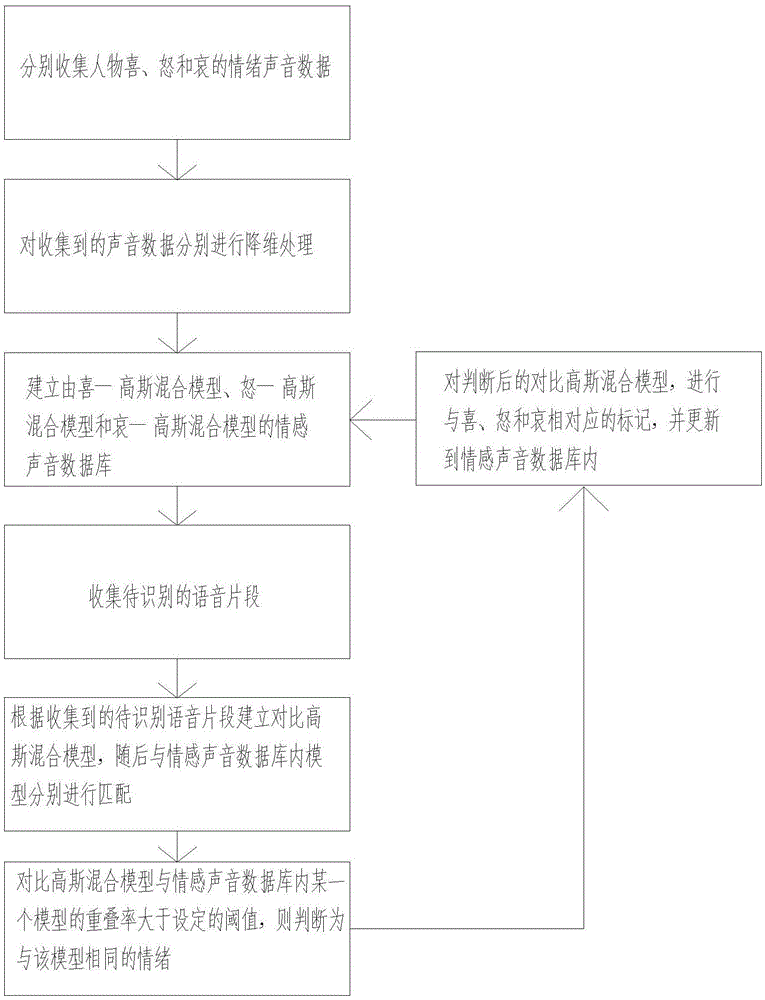
一种基于语音的情绪识别方法,包括以下步骤:
1)分别收集人物喜、怒和哀的情绪声音数据;
2)采用pca算法分别对喜、怒和哀的情绪声音数据分别进行降维处理;
3)然后对降维处理后的喜、怒和哀的情绪声音数据进行端点检测提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数,对特征参数建立高斯混合模型,分别训练出喜、怒和哀的情感声音的高斯混合模型,并建立由喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型的情感声音数据库;
4)收集待识别的语音片段;
5)将收集到的语音片段通过抗混叠滤波、模数变换、预加重预处理以及端点检测,然后提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数后,对特征参数建立对比高斯混合模型,随后与情感声音数据库内的喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型分别进行匹配;
6)对比高斯混合模型与情感声音数据库内的喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型中的某一个模型的重叠率大于设定的阈值,则判断为与该模型相同的情绪。
作为优选,所述阈值的设定值为38-70%。
作为优选,情绪识别方法还具有步骤7)对判断后的对比高斯混合模型,进行与喜、怒和哀情绪相对应的标记,并更新到情感声音数据库内。
作为优选,所述语音片段持续时间为2-6s。
本发明还提供一种基于语音的情绪识别装置,包括
声音采集模块,用于收集待识别的语音片段;
音频处理模块,用于对收集到的人物喜、怒和哀的情绪声音数据进行降维处理,以及对收集到的语音片段进行过抗混叠滤波、模数变换和预加重预处理;
数据处理模块,用于进行端点检测,提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数,对特征参数建立高斯混合模型,分别训练出喜、怒和哀的情感声音的高斯混合模型;
数据库模块,用于存储喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型。
作为优选,所述音频处理模块包含有模数转换器、音频输出器、抗混叠滤波器和预加重电路。
作为优选,所述音频处理模块和数据库模块均与数据处理模块物理连接。
本发明的有益效果为:通过针对声音识别的需要,首先建立三种情绪声音标准数据库,设定声音识别基准。针对三种情绪提取相应声音文件,提取梅尔-频率倒谱系数、共振峰以及过零率等特征参数,搭建三组情绪的高斯混合模型,可以有效的对需要识别的语音分开进行对比,将喜、怒和哀三种情感分开搭建模型,与传统的建模方式相比过程得到简单化,同时采用了单独进行对比的方式,可以有效的提高了识别效率,提升处理处理,解决了当前的语音情绪识别处理过程复杂,实现难度高,准确率低,效率低的技术问题。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种基于语音的情绪识别方法的流程图。
图2为本发明提供的一种基于语音的情绪识别装置的连接框图。
图中:
1、声音采集模块;2、音频处理模块;3、数据处理模块;4、数据库模块;5、模数转换器;6、音频输出器;7、抗混叠滤波器;8、预加重电路。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
实施例1
如图1所示,一种基于语音的情绪识别方法,包括以下步骤:
1)分别收集人物喜、怒和哀的情绪声音数据;
2)采用pca算法分别对喜、怒和哀的情绪声音数据分别进行降维处理;
3)然后对降维处理后的喜、怒和哀的情绪声音数据进行端点检测提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数,对特征参数建立高斯混合模型,分别训练出喜、怒和哀的情感声音的高斯混合模型,并建立由喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型的情感声音数据库;
4)收集待识别的语音片段;
5)将收集到的语音片段通过抗混叠滤波、模数变换、预加重预处理以及端点检测,然后提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数后,对特征参数建立对比高斯混合模型,随后与情感声音数据库内的喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型分别进行匹配;
6)对比高斯混合模型与情感声音数据库内的喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型中的某一个模型的重叠率大于设定的阈值,则判断为与该模型相同的情绪。
在本实施例中,所述阈值的设定值为45%。
在本实施例中,所述语音片段持续时间为2s。
如图2所示,本实施例还提供一种基于语音的情绪识别装置,包括
声音采集模块1,用于收集待识别的语音片段;
音频处理模块2,用于对收集到的人物喜、怒和哀的情绪声音数据进行降维处理,以及对收集到的语音片段进行过抗混叠滤波、模数变换和预加重预处理;
数据处理模块3,用于进行端点检测,提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数,对特征参数建立高斯混合模型,分别训练出喜、怒和哀的情感声音的高斯混合模型;
数据库模块4,用于存储喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型。
在本实施例中,所述音频处理模块2包含有模数转换器5、音频输出器6、抗混叠滤波器7和预加重电路8。
在本实施例中,所述音频处理模块2和数据库模块4均与数据处理模块3物理连接。
实施例2
如图1所示,一种基于语音的情绪识别方法,包括以下步骤:
1)分别收集人物喜、怒和哀的情绪声音数据;
2)采用pca算法分别对喜、怒和哀的情绪声音数据分别进行降维处理;
3)然后对降维处理后的喜、怒和哀的情绪声音数据进行端点检测提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数,对特征参数建立高斯混合模型,分别训练出喜、怒和哀的情感声音的高斯混合模型,并建立由喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型的情感声音数据库;
4)收集待识别的语音片段;
5)将收集到的语音片段通过抗混叠滤波、模数变换、预加重预处理以及端点检测,然后提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数后,对特征参数建立对比高斯混合模型,随后与情感声音数据库内的喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型分别进行匹配;
6)对比高斯混合模型与情感声音数据库内的喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型中的某一个模型的重叠率大于设定的阈值,则判断为与该模型相同的情绪。
在本实施例中,所述阈值的设定值为70%。
在本实施例中,情绪识别方法还具有步骤7)对判断后的对比高斯混合模型,进行与喜、怒和哀情绪相对应的标记,并更新到情感声音数据库内。
在本实施例中,所述语音片段持续时间为6s。
如图2所示,本实施例还提供一种基于语音的情绪识别装置,包括
声音采集模块1,用于收集待识别的语音片段;
音频处理模块2,用于对收集到的人物喜、怒和哀的情绪声音数据进行降维处理,以及对收集到的语音片段进行过抗混叠滤波、模数变换和预加重预处理;
数据处理模块3,用于进行端点检测,提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数,对特征参数建立高斯混合模型,分别训练出喜、怒和哀的情感声音的高斯混合模型;
数据库模块4,用于存储喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型。
在本实施例中,所述音频处理模块2包含有模数转换器5、音频输出器6、抗混叠滤波器7和预加重电路8。
在本实施例中,所述音频处理模块2和数据库模块4均与数据处理模块3物理连接。
实施例3
如图1所示,一种基于语音的情绪识别方法,包括以下步骤:
1)分别收集人物喜、怒和哀的情绪声音数据;
2)采用pca算法分别对喜、怒和哀的情绪声音数据分别进行降维处理;
3)然后对降维处理后的喜、怒和哀的情绪声音数据进行端点检测提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数,对特征参数建立高斯混合模型,分别训练出喜、怒和哀的情感声音的高斯混合模型,并建立由喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型的情感声音数据库;
4)收集待识别的语音片段;
5)将收集到的语音片段通过抗混叠滤波、模数变换、预加重预处理以及端点检测,然后提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数后,对特征参数建立对比高斯混合模型,随后与情感声音数据库内的喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型分别进行匹配;
6)对比高斯混合模型与情感声音数据库内的喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型中的某一个模型的重叠率大于设定的阈值,则判断为与该模型相同的情绪。
在本实施例中,所述阈值的设定值为60%。
在本实施例中,情绪识别方法还具有步骤7)对判断后的对比高斯混合模型,进行与喜、怒和哀情绪相对应的标记,并更新到情感声音数据库内。
在本实施例中,所述语音片段持续时间为5s。
如图所示,本实施例还提供一种基于语音的情绪识别装置,包括声音采集模块1,用于收集待识别的语音片段;
音频处理模块2,用于对收集到的人物喜、怒和哀的情绪声音数据进行降维处理,以及对收集到的语音片段进行过抗混叠滤波、模数变换和预加重预处理;
数据处理模块3,用于进行端点检测,提取出梅尔-频率倒谱系数、共振峰和过零率三个特征参数,对特征参数建立高斯混合模型,分别训练出喜、怒和哀的情感声音的高斯混合模型;
数据库模块4,用于存储喜-高斯混合模型、怒-高斯混合模型和哀-高斯混合模型。
在本实施例中,所述音频处理模块2包含有模数转换器5、音频输出器6、抗混叠滤波器7和预加重电路8。
在本实施例中,所述音频处理模块2和数据库模块4均与数据处理模块3物理连接。
本发明的有益效果为:通过针对声音识别的需要,首先建立三种情绪声音标准数据库,设定声音识别基准。针对三种情绪提取相应声音文件,提取梅尔-频率倒谱系数、共振峰以及过零率等特征参数,搭建三组情绪的高斯混合模型,可以有效的对需要识别的语音分开进行对比,将喜、怒和哀三种情感分开搭建模型,与传统的建模方式相比过程得到简单化,同时采用了单独进行对比的方式,可以有效的提高了识别效率,提升处理处理,解决了当前的语音情绪识别处理过程复杂,实现难度高,准确率低,效率低的技术问题
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何不经过创造性劳动想到的变化或替换,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!