一种归一化常Q倒谱特征的回放语音检测方法与流程
本发明涉及回放语音的检测识别方法,具体是指一种归一化常q倒谱特征的回放语音检测方法。
背景技术:
随着现代社会的不断发展,信息安全问题日显突出,其中身份认证在信息安全防护中承担着至关重要的作用。密码是最常见的身份认证方式之一,但其存在容易被遗忘、安全性低等问题,因此国内外学者提出了将人体特征应用于身份认证的生物识别技术,而声纹识别技术就是其中之一。相较于指纹、人脸等生物认证方式,声纹具有易采集、可远程等特点,因而被广泛应用于公安、金融等领域。近年来,随着语音处理技术的快速发展,出现了诸如合成转换、电子变调以及录音回放等声纹伪造攻击手段,对基于声纹的身份认证系统构成了严重威胁。其中录音回放攻击是一种简单且易操作的攻击手段,攻击者通过隐蔽性较高的录音设备,对目标说话人的语音进行偷录,并以偷录的语音来欺骗声纹认证系统。这类攻击由于不需要对回放语音进行额外的操作,从而避免了因修改语音而留下操作痕迹,同时回放语音与原始语音具有较高的相似度,现有的声纹认证系统通常无法正确判断两者之间的差别。
现有技术中针对回放语音的检测方法,按检测原理的不同,可以分为基于语音产生随机性的方法、基于语音信道特性的方法以及基于深度学习的方法:由于同一个人在不同时刻说出相同的内容所产生的语音信息存在较大的随机性,shang等人提出了一种基于语音产生随机性的回放语音检测算法,该算法通过比较原始语音与待测语音在波峰图上的差异,判断其是否为回放语音,在随后的研究中,作者又通过得分归一化的方法对检测算法进行了改进;jakubgalka等则在shang算法的基础上,将波峰图中各频率点的位置关系作为检测特征,但该方法只能应用于文本相关的声纹识别系统中,且检测时长较长,局限性较大;此外,由于回放语音在录制过程中会经过偷录设备的编码和回放设备的解码等环节,同时还会受到偷录时周围环境的影响,因此相比于原始语音会引入更多的失真,基于此,出现了基于语音产生信道的回放语音检测算法,如zhang利用回放语音的失真现象,提出了一种基于静音段梅尔倒谱系数对语音信道进行建模的方法,通过比较待测语音的信道与已建立的模型,进而判断待测语音是否为回放语音;王志峰着重研究低频段的信道噪声,提取了6阶legendre多项式系数及系数所对应的统计特征,在此基础上利用svm训练噪声分类模型,并得到了很好的分类结果;近年来,随着深度学习在计算机视觉、自然语言处理等领域的广泛应用,也有相关学者将尝试将该技术应用于回放语音的检测,lin等通过基于电网频率(enf)的分析对特征进行预处理,并用卷积神经网络(cnn)对原始语音和回放语音进行训练和分类,由于enf仅存在于由电网供电的偷录设备中(比如录音机),同时enf信号提取的准确性会极大地影响检测方法的性能,因此该方法应用范围有较大的局限性。
综上所述,现有技术中所提出的检测方法往往面临需要文本相关、检测时间长等问题,且很少有关于多种翻录回放设备或是不同环境下回放的检测方法。但随着电子设备小型化多样化的发展,实际场景中,声纹认证系统将面临多种录音回放设备的攻击,而不同的设备可能对系统的性能产生不同的影响。鉴于此,有必要提供一种高准确率、高鲁棒性、且高效的回放语音检测方法。
技术实现要素:
本发明所要解决的技术问题在于克服现有技术的缺陷而提供一种高准确率、高鲁棒性、且高效的归一化常q倒谱特征的回放语音检测方法。
本发明的技术问题通过以下技术方案实现:
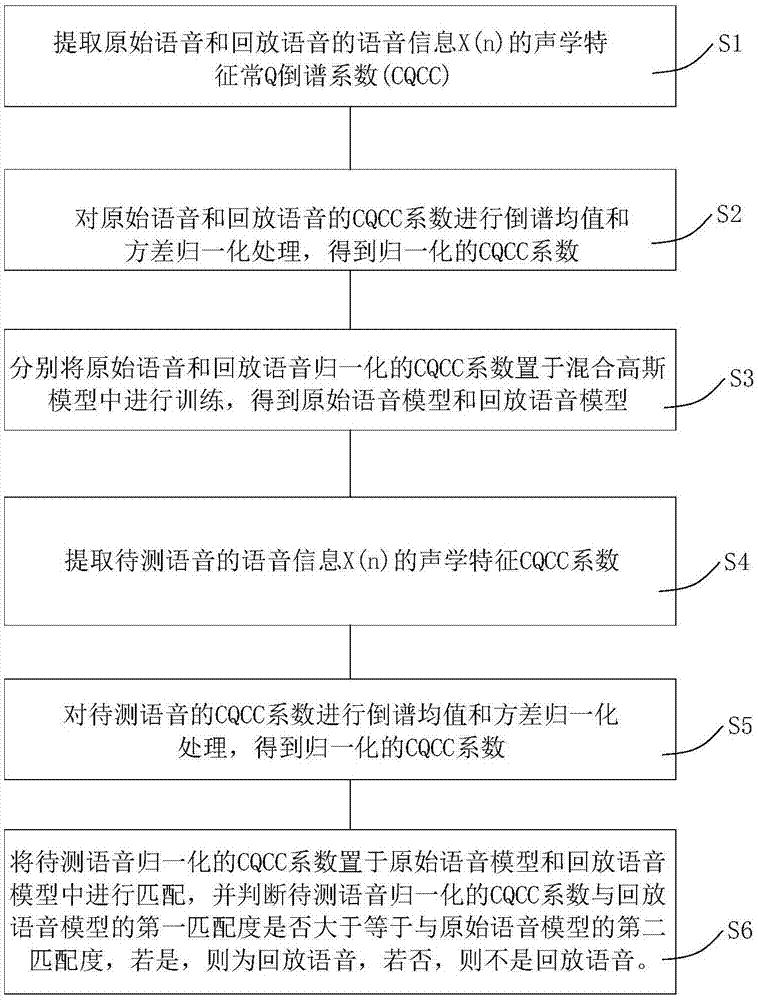
一种归一化常q倒谱特征的回放语音检测方法,包括以下步骤:
s1:提取原始语音和回放语音的语音信息x(n)的声学特征常q倒谱系数(cqcc);
s2:对原始语音和回放语音的cqcc系数进行倒谱均值和方差归一化处理,得到归一化的cqcc系数;
s3:分别将原始语音和回放语音归一化的cqcc系数置于混合高斯模型(gmm)中进行训练,得到原始语音模型和回放语音模型;
s4:提取待测语音的语音信息x(n)的声学特征cqcc系数;
s5:对待测语音的cqcc系数进行倒谱均值和方差归一化处理,得到归一化的cqcc系数;
s6:将待测语音归一化的cqcc系数置于原始语音模型和回放语音模型中进行匹配,并判断待测语音归一化的cqcc系数与回放语音模型的第一匹配度是否大于等于与原始语音模型的第二匹配度,若是,则为回放语音,若否,则不是回放语音。
进一步地,步骤s1中,提取cqcc系数包括对语音信息x(n)做cqt变换得到xcqt(k),计算功率谱得到|xcqt(k)|2,进行对数变换得到log|xcqt(k)|2,进行均匀重采样得到log|xcqt(i)|2,进行dct变换得到cqcc(p).
进一步地,步骤s3中,将归一化的cqcc系数置于混合高斯模型中进行训练得到语音模型,还包括使用混合高斯模型进行加权参数优化,并使用期望最大化算法进行话和高斯模型估计。
进一步地,步骤s1中,提取所述语音信息x(n)的cqcc系数包括:
s1.1:对语音信息x(n)进行常q变化(cqt),公式为
其中,k=1,2,…,k为序列cq谱的频域下标,nk为窗口长度,基函数ak*(n)为复数时频原子,与窗口大小有关,比如hamming窗,
定义
定义带宽bk=fk+1-fk=fk(21/b-1),定义常数
s1.2:对经过cqt的语音信息x(n)进行提取cqcc系数,公式为
其中,q为cqcc系数的下标,i=0,1,…,k-1是xcq在线性分布所对应的下标。
进一步地,步骤s2中,对cqcc系数进行倒谱均值和方差归一化处理包括:
定义xt为t时刻的k维倒谱特征向量,xt(i)代表xt的第i个分量,x={x1,x2,…,xt,…,xt}代表长度为t的语音段,则
其中,均值为μml,
方差为σ,
进一步地,步骤s3中,将归一化的cqcc系数置于混合高斯模型中进行训练,使用混合高斯模型进行加权参数优化,并使用期望最大化算法进行混合高斯模型估计包括:
设训练样本的特征向量为{x1,x2,x3,…,xn},其模型参数集的似然度
根据期望最大化算法,计算使p(x|λk+1)≥p(x|λk)成立的一组最大λ值,最大期望值
进一步地,步骤s6中,将待测语音归一化的cqcc系数置于原始语音模型和回放语音模型中进行匹配的公式为:
其中,p(x|s=s0)表示待测语音归一化的cqcc系数与回放语音模型的匹配度,p(x|s=s1)表示待测语音归一化的cqcc系数与原始语音模型的匹配度。
与现有技术相比,本发明的优点在于:
(1)采用cqcc系数用以表征语音信息的声学特征,cqcc系数是一种被认为可以取代梅尔倒谱系数(mfcc)的新特征,其结合了cqt和倒谱分析,提供了一种与人类感知更密切相关的时频分析方法。与传统的离散傅里叶变化(dft)相比,cqcc系数倾向于在较低的频率捕获更多的语音信息,而在较高的频率捕获更多的时间信息,而这些信息在传统的时频分析中容易丢失,因此cqcc系数可以更为有效地捕获人工操作的痕迹,进而提高语音信息的准确性和算法的精准性。
(2)对cqcc系数进行倒谱均值方差归一化处理,从而提升算法的鲁棒性,用以适应不同语音环境。实际场景中,往往会因为场景中复杂因素(比如背景噪声)的影响,造成测试语音与训练语音发生不匹配的现象,最终导致回放语音检测算法的鲁棒性大幅度下降。为了提高检测算法的鲁棒性,引入倒谱均值及方差归一化用来消除乘性信道噪声在倒谱域造成的偏差和时域的卷积噪声,如信道失真,信道噪声对应于倒谱域的加性偏差。
(3)采用混合高斯模型对处理结果进行分类,通过对参数的不断迭代从而得到最优解,能够很好地刻画数据的概率密度分布,从而做到分类的精准度要求,也使得整个算法更为高效精准。
附图说明
图1为本发明优选实施例归一化常q倒谱特征的回放语音检测方法的流程图;
图2.1为本发明优选实施例的原始语音与回放语音的cqcc系数的特征对比示意图;
图2.2为本发明优选实施例的原始语音与回放语音的归一化的cqcc系数的特征对比示意图;
图3为本发明优选实施例的本算法与传统算法的等错误率曲线示意图;
图4为本发明优选实施例的不同高斯核数下eer波动示意图。
具体实施方式
以下结合附图及实施例对本发明作进一步详细描述。
参阅图1所示,本优选实施例提供一种归一化常q倒谱特征的回放语音检测方法,具体包括以下步骤:
s1:提取原始语音和回放语音的语音信息x(n)的声学特征常q倒谱系数(cqcc);
s2:对原始语音和回放语音的cqcc系数进行倒谱均值和方差归一化处理,得到归一化的cqcc系数;
s3:分别将原始语音和回放语音归一化的cqcc系数置于混合高斯模型(gmm)中进行训练,得到原始语音模型和回放语音模型;
s4:提取待测语音的语音信息x(n)的声学特征cqcc系数;
s5:对待测语音的cqcc系数进行倒谱均值和方差归一化处理,得到归一化的cqcc系数;
s6:将待测语音归一化的cqcc系数置于原始语音模型和回放语音模型中进行匹配,并判断待测语音归一化的cqcc系数与回放语音模型的第一匹配度是否大于等于与原始语音模型的第二匹配度,若是,则为回放语音,若否,则不是回放语音。
进一步地,步骤s1中,提取cqcc系数包括对语音信息x(n)做cqt变换得到xcqt(k),计算功率谱得到|xcqt(k)|2,进行对数变换得到log|xcqt(k)|2,进行均匀重采样得到log|xcqt(i)|2,进行dct变换得到cqcc(p).
进一步地,步骤s3中,将归一化的cqcc系数置于混合高斯模型中进行训练得到语音模型,还包括使用混合高斯模型进行加权参数优化,并使用期望最大化算法进行话和高斯模型估计。
进一步地,步骤s1中,提取所述语音信息x(n)的cqcc系数包括:
s1.1:对语音信息x(n)进行常q变化(cqt),公式为
定义
定义带宽bk=fk+1-fk=fk(21/b-1),定义常数
s1.2:对经过cqt的语音信息x(n)进行提取cqcc系数,公式为
其中,q为cqcc系数的下标,i=0,1,…,k-1是xcq在线性分布所对应的下标。
进一步地,步骤s2中,对cqcc系数进行倒谱均值和方差归一化处理包括:
定义xt为t时刻的k维倒谱特征向量,xt(i)代表xt的第i个分量,x={x1,x2,…,xt,…,xt}代表长度为t的语音段,则
其中,均值为μml,
方差为σ,
进一步地,步骤s3中,将归一化的cqcc系数置于混合高斯模型中进行训练,使用混合高斯模型进行加权参数优化,并使用期望最大化算法进行混合高斯模型估计包括:
设训练样本的特征向量为{x1,x2,x3,…,xn},其模型参数集的似然度
根据期望最大化算法,计算使p(x|λk+1)≥p(x|λk)成立的一组最大λ值,最大期望值
进一步地,步骤s6中,将待测语音归一化的cqcc系数置于原始语音模型和回放语音模型中进行匹配的公式为:
其中,p(x|s=s0)表示待测语音归一化的cqcc系数与回放语音模型的匹配度,p(x|s=s1)表示待测语音归一化的cqcc系数与原始语音模型的匹配度。
为进一步说明本发明优选实施例方法的可行性和有效性,进行以下实验:
数据库:采用asvspoof2017用以评价所提出算法的性能。该数据库中,训练集共包含4724条语音,其中原始语音有2267条,回放语音有2457条;测试集共包含13306条语音,其中原始语音有1298条,回放语音有12008条。其中,测试集中的回放语音包含比训练集更复杂的场景,例如,不同的回放环境,不同的播放和偷录设备。所有的语音均以16位单声道的wav格式存储,采样频率为16khz。
实验参数设置:最大频率fmax=fnyq,其中fnyq是奈奎斯特频率,大小为fs/2,fs为抽样频率;最小频率fmin=fmax/2oct,oct为一个可调参数,以此来确定fmin,进而确定整个采样范围;采样周期d为16;cqcc系数的特征维度k取19,以确定高阶系数中是否包含对回放语音检测的有用附带信息。
实验过程:
(1)原始语音和回放语音的cqcc系数在归一化之前和归一化之后的特征维度对比
对比实验的结果如图2.1和图2.2所示:仅通过cqcc系数表征原始语音和回放语音的结果差异性不大,但经过倒谱均值和方差归一化处理后的cqcc系数可以很好地表征原始语音和回放语音的差异性,使得对两个语音的判定更容易,进一步表明经过倒谱均值和方差归一化处理后的cqcc系数可以更好地衡量原始语音和回放语音之间的差距。
(2)基于cqcc和基于mfcc算法的等错误概率对比
为显示本算法与传统算法的优越性,进行了对比实验,实验结果如图3所示:将归一化处理加载至基于cqcc的回放语音检测算法中,等错误概率从约23%下降到15%;加载至基于mfcc的回放语音检测算法中,等错误概率从约37%下降到17%。
(3)混合高斯模型(gmm)训练时不同高斯核数下eer的波动情况
考虑到混合高斯模型训练的过程具有一定的随机性,可能收敛于不同的局部最优解,很容易造成最终检测准确率的波动。因此,本实施例进行了50次重复实验,并统计了每次实验高斯核数的波动规律,如图4所示,其柱状图顶端的误差棒表示重复实验中eer波动的方差。首先,增加eer能一定程度上减少因训练造成的波动,但是效果不明显;其次,相同eer条件下,本实施例方案中的特征归一化策略能大幅度减少由于训练引起的算法性能波动。此外,由于归一化处理可以从一定程度上消除信道噪声在倒谱域造成的偏差和时域的卷积噪声,使得冗余的特征参数被处理优化,在使用不同的eer进行训练时,eer均有一定的下降。其中当使用的eer为512时,eer下降幅度最大,约为30%。上述实验结果表明对cqcc特征引入归一化处理可以使特征参数得到进一步优化,从而提高算法的检测性能。
(4)测试文本无关语音
考虑到目前典型的声纹认证系统往往是文本无关的,因此需要对文本无关的语音进行检测。测试数据集中的语音中共包含10条不同的英文短句,从中选择内容相同的语音分别进行测试,最终实验结果如表1所示。
表1不同语音内容eer
由实验结果可知,仅有2组语音(s02和s08)的eer高于平均水平15%,其余的eer均低于平均水平,且不同语音内容之间的波动较小。因此,可以认为本方案的算法在面对不同内容的语音时能保持稳定的表现,具有较高的鲁棒性,可用于文本无关的回放语音检测。
(5)测试不同回放设备语音
实际的声纹认证系统面对的回放语音可能是由不同的设备采集的,回放检测算法在面对不同的回放设备和偷录设备时能否保持稳定是衡量算法性能的重要指标。
表2交叉实验等错误率
从表中可以看出,在偷录设备相同时,回放设备的交叉对算法的性能影响较小,均可以获得较为准确的检测结果。在回放设备相同偷录设备交叉时,算法的表现不及仅回放设备交叉,这说明偷录设备的类型对回放语音的影响更大。当不同偷录设备,不同回放设备交叉时,检测的准确率波动较大,但仍在可接受的范围内。由上述实验结果表明,本方案所提出算法对回放和偷录设备具有较好的鲁棒性。
需要说明的是,本技术领域的普通技术人员应当认识到,以上的实施方式仅是用来说明本发明,而并非用作为对本发明的限定,只要在本发明的实质精神范围之内,对以上实施方式所作的适当改变和变化都落在本发明要求保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!